シリーズ目次
- 機械学習の理論を理解せずに tensorflow で オセロ AI を作ってみた ~導入編~
- 機械学習の理論を理解せずに tensorflow で オセロ AI を作ってみた ~実装編~
- [機械学習の理論を理解せずに tensorflow で オセロ AI を作ってみた ~いざ対戦編~]
(http://qiita.com/sasaco/items/f9aa608860eebb3026c1) - [機械学習の理論を理解しようとしてから オセロ AI を作ってみた 〜再始動‼〜]
(https://qiita.com/sasaco/items/5e102063c256bf56e396) - 機械学習の理論を理解しようとしてから オセロ AI を作ってみた 〜何これ Alpha Zero 編〜
- 機械学習の理論を理解しようと エクセルでニュートラルネットワークを作ってみた 〜画像認識 mnist 編〜
前回の続き...
オセロのAI を作ってみましたが、結果惨敗でした。強くならない
そうこうしているうちに Alpha Zero というものが発表されて
しかもそれを オセロに書き換えた人がいて
・ AlphaGo Zeroの手法でリバーシの強化学習をやってみる
今回は、この記事で紹介されているソースコードの理解を深めるため 自分に解説記事を書きます。
何これ Alpha Zero
私が本シリーズを試行錯誤している間に Alpha Zero なるものが出た
このAlphaGo Zeroの手法でリバーシの強化学習をやってみるは
self, opt, eval の3つのWorkerとplay_guiというお試し対戦モードで構成されているそうです。
-
selfは最善モデル同士の自己対戦で訓練データを生成します。 -
optはモデルの学習をさせ、次世代モデルを生成します。 -
evalは次世代モデルが最善モデルより優れているかを評価します。もし優れていれば、最善モデルを置き換えます。 -
play_guiは 最善モデルと対戦します。
環境構築などについては元記事を参照してください
self (最善モデル同士の自己対戦で訓練データを生成する)モード
実行方法
エントリーは 下記の関数(run.py)に 引数をつけて呼び出します
python src/reversi_zero/run.py self
いろいろ経由して
run.py → manager.py → self_play.py ここで最善モデル同士の自己対戦を行います。
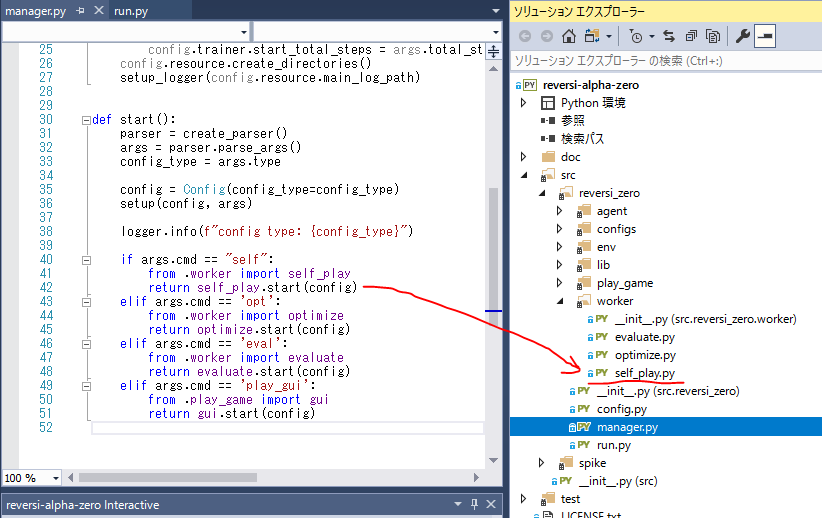
実行すると、最善モデルによる自己対戦を開始します。
重要な動作だけ抜き出すと
- スタート
- もし、最善モデルが存在しない場合は、ランダムな初期モデルを作成し、それを最善モデルとします。
- 無限に繰り返す
- 自己対戦を開始する
- 盤面をリセットする
- 2人のAIを呼び出す
- 対戦が終了するまで繰り返す
- AIに次の手を選択させる
- 対戦終了,対戦履歴を保存する
- 対戦履歴を保存する
- 黒の手と白の手をまとめる
- バッファに追加する
- ファイルに保存する
- バッファをクリアする
- 自己対戦を開始する
重要なソースコードだけ抜き出すと
from reversi_zero.env.reversi_env import ReversiEnv, Player
def start(config: Config):
return SelfPlayWorker(config, env=ReversiEnv()).start()
class SelfPlayWorker:
''' ↓ これが実際のスタート '''
def start(self):
if self.model is None:
'''もし、最善モデルが存在しない場合は、ランダムな初期モデルを作成し、それを最善モデルとします。'''
self.model = self.load_model()
''' 無限に繰り返す '''
while True:
''' 自己対戦を開始する '''
env = self.start_game(idx)
''' 自己対戦を開始する '''
def start_game(self, idx):
''' 盤面をリセットする '''
self.env.reset()
''' 2人のAIを呼び出す '''
self.black = ReversiPlayer(self.config, self.model, enable_resign=enable_resign)
self.white = ReversiPlayer(self.config, self.model, enable_resign=enable_resign)
''' 対戦が終了するまで繰り返す '''
while not self.env.done:
''' AIに次の手を選択させる '''
if self.env.next_player == Player.black:
action = self.black.action(observation.black, observation.white)
else:
action = self.white.action(observation.white, observation.black)
observation, info = self.env.step(action)
''' 対戦終了,対戦履歴を保存する '''
self.save_play_data(write=idx % self.config.play_data.nb_game_in_file == 0)
return self.env
''' 対戦履歴を保存する '''
def save_play_data(self, write=True):
''' 黒の手と白の手をまとめる '''
data = self.black.moves + self.white.moves
''' バッファに追加する '''
self.buffer += data
''' ファイルに保存する '''
write_game_data_to_file(path, self.buffer)
''' バッファをクリアする '''
self.buffer = []
'''最善モデルをファイルからロードする'''
def load_model(self):
from reversi_zero.agent.model import ReversiModel
model = ReversiModel(self.config)
if self.config.opts.new or not load_best_model_weight(model):
model.build()
save_as_best_model(model)
return model
結果
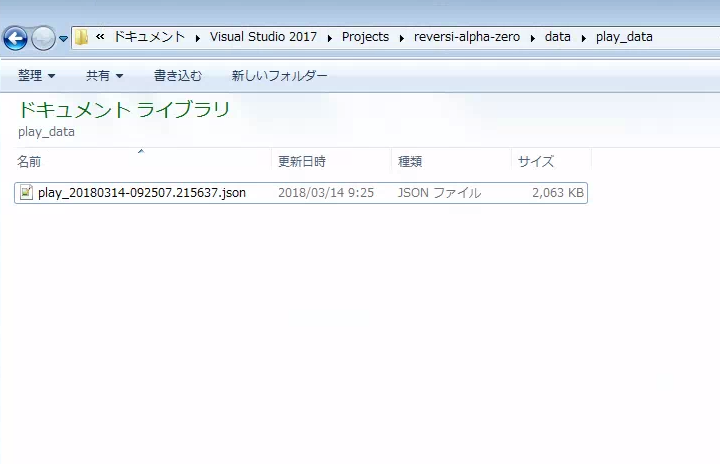
100 ゲーム(self.config.play_data.nb_game_in_file) 毎に
フォルダ reversi-alpha-zero\data\play_data 内に play_*.json というファイルが生成されます

opt (モデルの学習をさせ、次世代モデルを生成する)モード
実行方法
エントリーは 下記の関数(run.py)に 引数をつけて呼び出します
python src/reversi_zero/run.py opt
いろいろ経由して
run.py → manager.py → optimize.py ここでモデルの学習,次世代モデルの生成を行います。
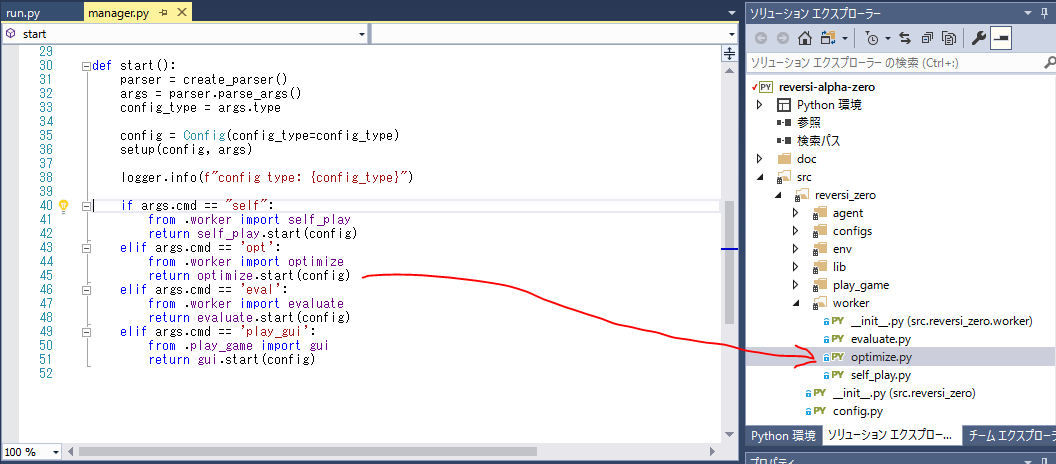
実行すると、モデルの学習を開始します。
重要な動作だけ抜き出すと
- スタート
- 最善モデルをファイルからロードする
- モデルの学習する
- 学習モデルの学習率(learning rate)やloss などのパラメータ設定
- 対戦履歴を読み込む
- 無限に繰り返す
- 学習率を更新する
重要なソースコードだけ抜き出すと
from reversi_zero.env.reversi_env import ReversiEnv, Player
def start(config: Config):
return OptimizeWorker(config).start()
class OptimizeWorker:
''' ↓ これが実際のスタート '''
def start(self):
'''最善モデルをファイルからロードする'''
self.model = self.load_model()
'''モデルの学習する'''
self.training()
''' モデルの学習する '''
def training(self):
''' 学習モデルの学習率(learning rate)やloss などのパラメータ設定 '''
self.compile_model()
''' 対戦履歴を読み込む '''
self.load_play_data()
while True:
''' 学習率を更新する '''
self.update_learning_rate(total_steps)
''' 学習率を更新する '''
steps = self.train_epoch(self.config.trainer.epoch_to_checkpoint)
total_steps += steps
if last_save_step + self.config.trainer.save_model_steps < total_steps:
self.save_current_model()
last_save_step = total_steps
if last_load_data_step + self.config.trainer.load_data_steps < total_steps:
self.load_play_data()
last_load_data_step = total_steps
'''最善モデルをファイルからロードする'''
def load_model(self):
from reversi_zero.agent.model import ReversiModel
model = ReversiModel(self.config)
rc = self.config.resource
dirs = get_next_generation_model_dirs(rc)
if not dirs:
logger.debug(f"loading best model")
if not load_best_model_weight(model):
raise RuntimeError(f"Best model can not loaded!")
else:
latest_dir = dirs[-1]
logger.debug(f"loading latest model")
config_path = os.path.join(latest_dir, rc.next_generation_model_config_filename)
weight_path = os.path.join(latest_dir, rc.next_generation_model_weight_filename)
model.load(config_path, weight_path)
return model
''' 学習モデルの学習率(learning rate)やloss などのパラメータ設定 '''
def compile_model(self):
self.optimizer = SGD(lr=1e-2, momentum=0.9)
losses = [objective_function_for_policy, objective_function_for_value]
self.model.model.compile(optimizer=self.optimizer, loss=losses)
''' 対戦履歴を読み込む '''
def load_play_data(self):
filenames = get_game_data_filenames(self.config.resource)
updated = False
for filename in filenames:
if filename in self.loaded_filenames:
continue
self.load_data_from_file(filename)
updated = True
for filename in (self.loaded_filenames - set(filenames)):
self.unload_data_of_file(filename)
updated = True
if updated:
logger.debug("updating training dataset")
self.dataset = self.collect_all_loaded_data()
''' 学習率を更新する '''
def update_learning_rate(self, total_steps):
# The deepmind paper says
# ~400k: 1e-2
# 400k~600k: 1e-3
# 600k~: 1e-4
if total_steps < 100000:
lr = 1e-2
elif total_steps < 500000:
lr = 1e-3
elif total_steps < 900000:
lr = 1e-4
else:
lr = 2.5e-5 # means (1e-4 / 4): the paper batch size=2048, ours is 512.
K.set_value(self.optimizer.lr, lr)
''' 学習率を更新する '''
def train_epoch(self, epochs):
tc = self.config.trainer
state_ary, policy_ary, z_ary = self.dataset
''' agent\model\class ReversiModel より from keras.engine.training の .fit '''
self.model.model.fit(state_ary, [policy_ary, z_ary],
batch_size=tc.batch_size,
epochs=epochs)
steps = (state_ary.shape[0] // tc.batch_size) * epochs
return steps