シリーズ目次
- 機械学習の理論を理解せずに tensorflow で オセロ AI を作ってみた ~導入編~
- 機械学習の理論を理解せずに tensorflow で オセロ AI を作ってみた ~実装編~
- 機械学習の理論を理解せずに tensorflow で オセロ AI を作ってみた ~いざ対戦編~
- 機械学習の理論を理解しようとしてから オセロ AI を作ってみた 〜再始動‼〜
- 機械学習の理論を理解しようとしてから オセロ AI を作ってみた 〜何これ Alpha Zero 編〜
- 機械学習の理論を理解しようと エクセルでニュートラルネットワークを作ってみた 〜画像認識 mnist 編〜
前回の続き...
この分野では門外漢の私が、「機械学習の理論」をまったく勉強せずに
オセロのAI を作ってみようと思います。
参考にしたサイトはこちら
・ DQNをKerasとTensorFlowとOpenAI Gymで実装する
・ Training TensorFlow neural network to play Tic-Tac-Toe game using one-step Q-learning algorithm.
強化学習の基礎
「機械学習の理論」をまったく勉強せずにオセロのAI を作るのですが
実装するのに必要な最低限の知識をまとめておきます。
ファイル構成と役割り
ファイル構成と役割りはこのような感じです。
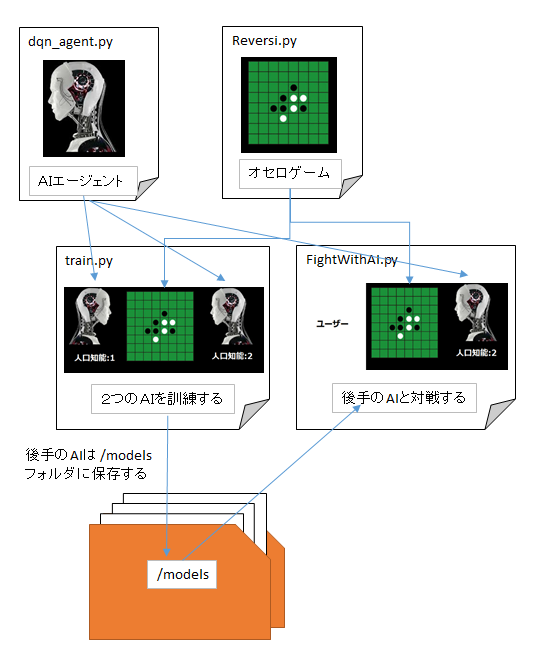
- train.py --- AI の訓練を行う
- Reversi.py --- オセロゲームの管理
- dqn_agent.py --- AI の訓練の管理
- FightWithAI.py --- ユーザーとの対戦
全体のアルゴリズム
今回実装するDQNのアルゴリズムはこのような感じです。

この流れを頭に入れておけば、これから説明するものも、どこの何のことを言っているのかが分かると思います。
オセロゲームの仕様
オセロゲームおよびAI の訓練で用いる盤面は
下図のNoを振った2次元配列を用いて行います。

self.screen[0~7][0~7]
AIが選択できる動作は上図の 0~63 の番号を選択することです。
self.enable_actions[0~63]
AI の訓練
AI の訓練 は、players[0] と players[1] が オセロ対戦をn_epochs = 1000回行い、
最後に後攻の players[1] のAI を保存します。
AIに対する報酬
- ゲームに勝ったら 報酬(reward)=1 とする
- それ以外は 報酬(reward)=0
訓練方法
2体の AI で対戦するのですが、相手のターンでも行動したことにしないと
終局までのストーリーがつながらない(Q値が伝達しない)ので
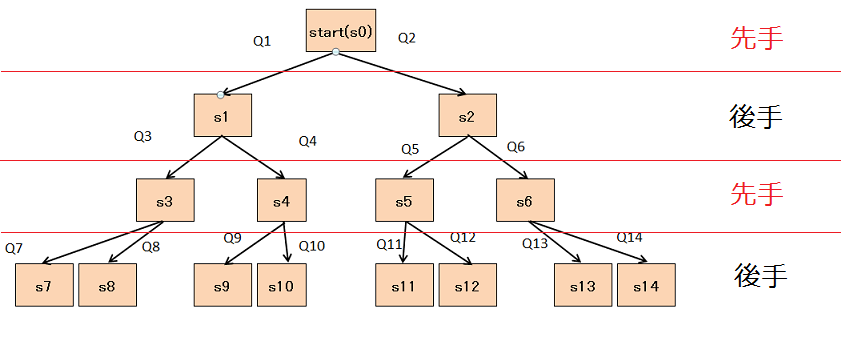
すべてのターンで両者行動します
今回は、ゲームの進行とは別に置いていい番号全て「Dに推移を保存」することにしました。
# targets に このターンで置いていい番号が全て入っている
for tr in targets:
#現状を複製
tmp = copy.deepcopy(env)
#行動
tmp.update(tr, playerID[i])
#終了判定
win = tmp.winner()
end = tmp.isEnd()
#行動した後の盤面
state_X = tmp.screen
#行動した後の置いていい番号
target_X = tmp.get_enables(playerID[i+1])
# 両者行動
for j in range(0, len(players)):
reword = 0
if end == True:
if win == playerID[j]:
# 勝ったら報酬1を得る
reword = 1
# 両者「Dに推移を保存」
players[j].store_experience(state, targets, tr, reword, state_X, target_X, end)
players[j].experience_replay()
DQNのアルゴリズムのうち下記の部分は dqn_agent.py が行っています。
- Dに推移(si,ai,ri,si+1,tarminal)を保存
- Dからランダムに推移のミニパッチ(si,ai,ri,si+1,tarminal)をサンプル
- 教師信号 yi=ri+γmax Q(si+1, a:θ)
- Q Networkのパラメータθについて(yi-Q(si, ai;θ))^2 で勾配法を実行
- 定期的に Target Network をリセット Q=Q
参考にしたサイトの まるパクリ なのでわけは分かっていませんが
def store_experience(self, state, targets, action, reward, state_1, targets_1, terminal):
self.D.append((state, targets, action, reward, state_1, targets_1, terminal))
>>
def experience_replay(self):
state_minibatch = []
y_minibatch = []
>>
# sample random minibatch
minibatch_size = min(len(self.D), self.minibatch_size)
minibatch_indexes = np.random.randint(0, len(self.D), minibatch_size)
>>
for j in minibatch_indexes:
state_j, targets_j, action_j, reward_j, state_j_1, targets_j_1, terminal = self.D[j]
action_j_index = self.enable_actions.index(action_j)
>>
y_j = self.Q_values(state_j)
>>
if terminal:
y_j[action_j_index] = reward_j
else:
# reward_j + gamma * max_action' Q(state', action')
qvalue, action = self.select_enable_action(state_j_1, targets_j_1)
y_j[action_j_index] = reward_j + self.discount_factor * qvalue
>>
state_minibatch.append(state_j)
y_minibatch.append(y_j)
>>
# training
self.sess.run(self.training, feed_dict={self.x: state_minibatch, self.y_: y_minibatch})
>>
# for log
self.current_loss = self.sess.run(self.loss, feed_dict={self.x: state_minibatch, self.y_: y_minibatch})
>>
| 変数名 | 内容 |
|---|---|
| state | 盤面( = Reversi.screen[0~7][0~7] ) |
| targets | 置いていい番号 |
| action | 選択した行動 |
| reward | 行動に対する報酬 0~1 |
| state_1 | 行動した後の盤面 |
| targets_1 | 行動した後の置いていい番号 |
| terminal | ゲームが終了=True |
実装
AI の訓練 は、players[0] と players[1] が オセロ対戦をn_epochs = 1000回行い、
最後に後攻の players[1] のAI を保存します。
# parameters
n_epochs = 1000
# environment, agent
env = Reversi()
# playerID
playerID = [env.Black, env.White, env.Black]
# player agent
players = []
# player[0]= env.Black
players.append(DQNAgent(env.enable_actions, env.name, env.screen_n_rows, env.screen_n_cols))
# player[1]= env.White
players.append(DQNAgent(env.enable_actions, env.name, env.screen_n_rows, env.screen_n_cols))
この
DQNAgent(env.enable_actions, env.name, env.screen_n_rows, env.screen_n_cols)部分が、
- Replay Memory D の初期化
- Q NetworkQ をランダムな重みθで初期化
- Target NetworkQ を初期化 θ^=θ
で、dqn_agent.py が行っています。
class DQNAgent:
>>
def __init__(self, enable_actions, environment_name, rows, cols):
... 省略 ...
# Replay Memory D の初期化
self.D = deque(maxlen=self.replay_memory_size)
... 省略 ...
>>
def init_model(self):
# input layer (rows x cols)
self.x = tf.placeholder(tf.float32, [None, self.rows, self.cols])
>>
# flatten (rows x cols)
size = self.rows * self.cols
x_flat = tf.reshape(self.x, [-1, size])
>>
# Q NetworkQ をランダムな重みθで初期化
W_fc1 = tf.Variable(tf.truncated_normal([size, size], stddev=0.01))
b_fc1 = tf.Variable(tf.zeros([size]))
h_fc1 = tf.nn.relu(tf.matmul(x_flat, W_fc1) + b_fc1)
>>
# Target NetworkQ を初期化 θ^=θ
W_out = tf.Variable(tf.truncated_normal([size, self.n_actions], stddev=0.01))
b_out = tf.Variable(tf.zeros([self.n_actions]))
self.y = tf.matmul(h_fc1, W_out) + b_out
>>
# loss function
self.y_ = tf.placeholder(tf.float32, [None, self.n_actions])
self.loss = tf.reduce_mean(tf.square(self.y_ - self.y))
>>
# train operation
optimizer = tf.train.RMSPropOptimizer(self.learning_rate)
self.training = optimizer.minimize(self.loss)
>>
# saver
self.saver = tf.train.Saver()
>>
# session
self.sess = tf.Session()
self.sess.run(tf.initialize_all_variables())
for e in range(n_epochs):
# reset
env.reset()
terminal = False
- for episode =1, M do
- 初期画面x1,前処理し初期状態s1を作る
while terminal == False: # 1エピソードが終わるまでループ
for i in range(0, len(players)):
state = env.screen
targets = env.get_enables(playerID[i])
if len(targets) > 0:
# どこかに置く場所がある場合
# ← ここで、前述のすべての手を「Dに保存」しています
# 行動を選択
action = players[i].select_action(state, targets, players[i].exploration)
# 行動を実行
env.update(action, playerID[i])
- while not terminal
- 行動選択
行動選択
agent.select_action(state_t, targets, agent.exploration)は、
dqn_agent.py が行っています。
- 行動選択
- ランダムに行動 ai
- または ai= argmax Q(s1, a:θ)
def Q_values(self, state):
# Q(state, action) of all actions
return self.sess.run(self.y, feed_dict={self.x: [state]})[0]
>>
def select_action(self, state, targets, epsilon):
>>
if np.random.rand() <= epsilon:
# random
return np.random.choice(targets)
else:
# max_action Q(state, action)
qvalue, action = self.select_enable_action(state, targets)
return action
>>
#その盤面(state)で, 置いていい場所(targets)からQ値が最大となるQ値と番号を返す
def select_enable_action(self, state, targets):
Qs = self.Q_values(state)
#descend = np.sort(Qs)
index = np.argsort(Qs)
for action in reversed(index):
if action in targets:
break
# max_action Q(state, action)
qvalue = Qs[action]
>>
return qvalue, action
- 行動aiを実行し、報酬riと次の画面xi+1と終了判定 tarminalを観測
- 前処理し次の状態si+1を作る
最後に後手のAIを保存します
# 行動を実行した結果
terminal = env.isEnd()
w = env.winner()
print("EPOCH: {:03d}/{:03d} | WIN: player{:1d}".format(
e, n_epochs, w))
# 保存は後攻のplayer2 を保存する。
players[1].save_model()
ソースはここにおいておきます。
$ git clone https://github.com/sasaco/tf-dqn-reversi.git
次回は、いざ対戦編についてお届けします。