加筆修正のコメント等あれば、遠慮なく教えてください。
本記事は、初心者の初心者による初心者のためのニューラルネットワーク#5〜(ひと休み):分類問題における学習とは編〜の続きとなります。
1. なぜ人はニューラルネットワークを学ぶのか
今や日常生活の様々な場面に用いられている、機械学習のコアの部分だからです。(多分)
2. 本記事の目的
本記事では、ニューラルネットワークを実装する上で施されている工夫について理論的な説明を詳しくしていきます。
3. 前記事の要約
初心者の初心者による初心者のためのニューラルネットワーク〜理論:順伝播編〜では、ニューラルネットワークの基本概念、基本構造そしてアルゴリズム①である順伝播(forward-propagation)について説明しました。
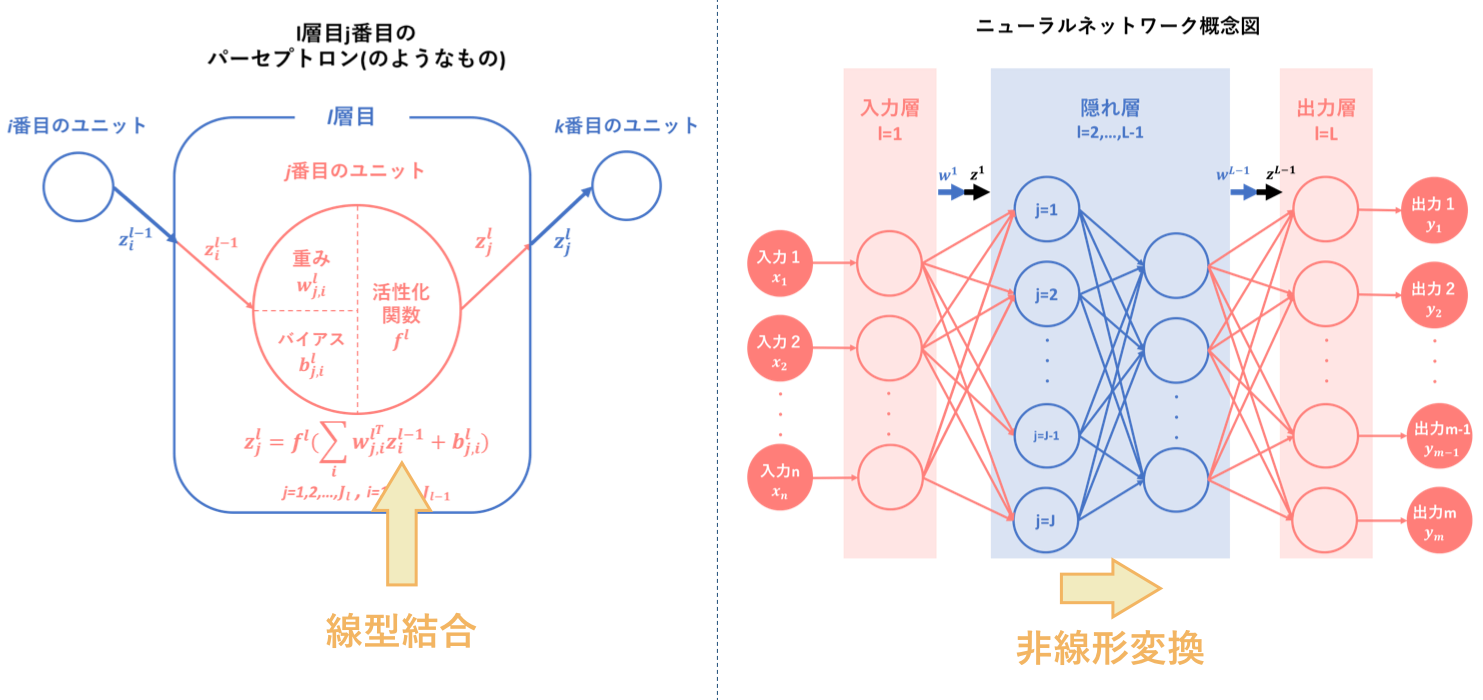
その要約として以下の図をあげます。ニューラルネットワークとは、『パーセプトロン(のようなもの)を基に人間の脳神経系のニューロンを数理モデル化したもの』のことであり、『線型結合と非線形変換を繰り返す合成関数 $f(w,x)$によって入力から出力を表すモデル』です。
そして、ニューラルネットワークの目的は最適パラメータの発見であり、そのために学習を繰り返すことによって予測出力を最適化するようなパラメータを導出します。
順伝播は、その学習アルゴリズムの一つ目でした。
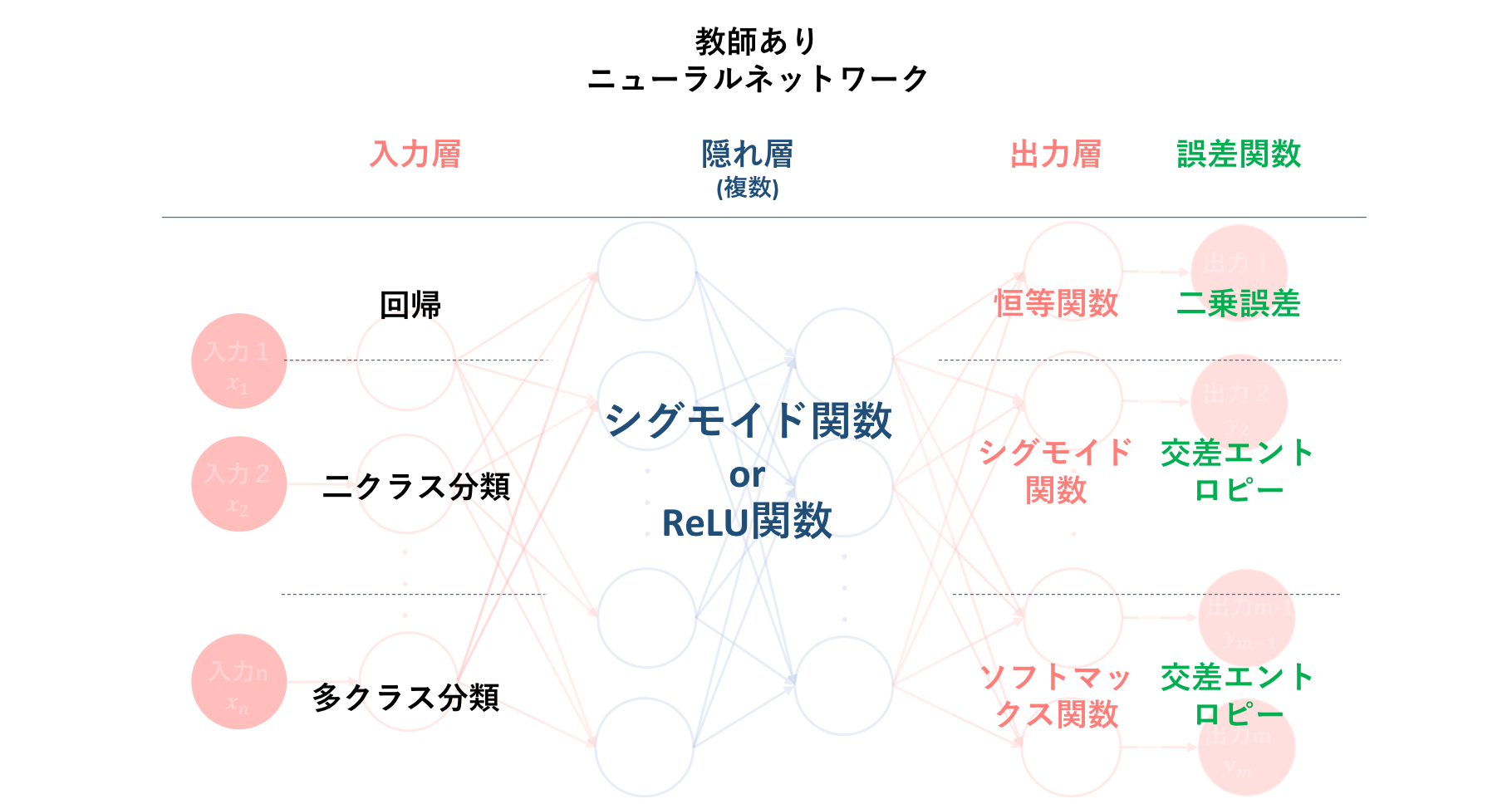
そして続く初心者の初心者による初心者のためのニューラルネットワーク〜理論:誤差計算編〜では、アルゴリズム②である出力値と教師信号のずれの程度を表すための誤差計算について説明しました。そして、こちらはアルゴリズム②には含まれない部分ですが、誤差関数と密接に関係する多層パーセプトロン内の活性化関数の種類とその使用場面についての説明も行いました。
以下の図は、それらの誤差関数および活性化関数の種類と、それぞれどのような問題に対し用いることが一般的なのかをまとめたものになります。
これに基づいた誤差計算は、学習アルゴリズムの二つ目でした。
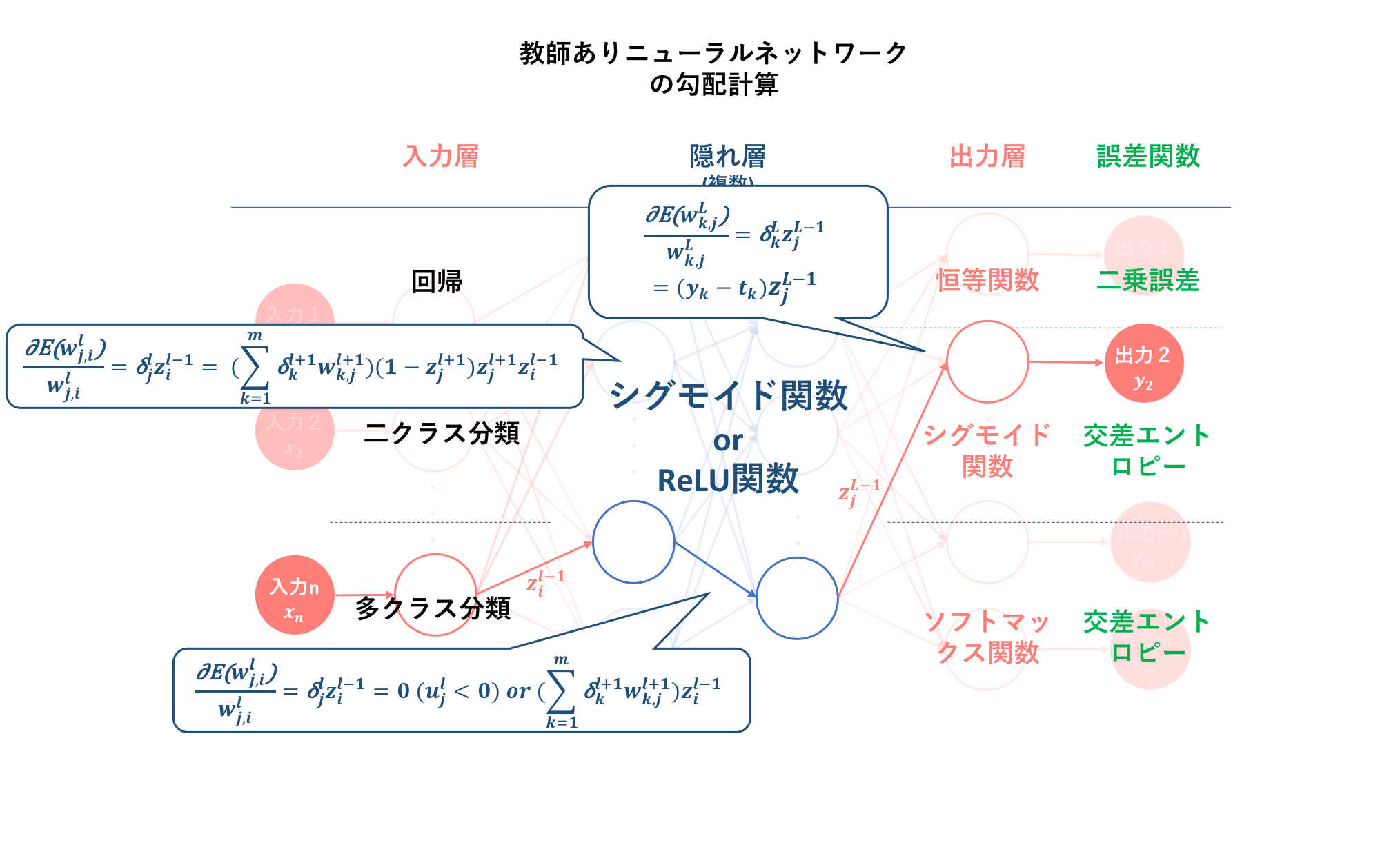
そして、初心者の初心者による初心者のためのニューラルネットワーク#3〜理論:逆伝播編〜では、誤差を最小化するための学習方法として勾配降下法を適用するために、各層における誤差関数の重みに対する勾配の計算方法を導出しました。その結果、$l$層の勾配を算出するには$l+1$層の誤差信号及び$l$層への入力値を求める必要があることが分かりました。これによって、勾配降下法の多層パーセプトロン(この記事ではニューラルネットワークと同義)への適用には、あらかじめ
・ 順伝搬による各層の出力の算出
・ 出力値と教師信号の比較による誤差信号の算出
という二つのフェーズ、すなわち多層パーセプトロンアルゴリズムの①, ②をパスしなくてはいけないことが分かりました。
以下の図は、それぞれの活性化関数及び誤差関数を用いた場合の勾配の計算式を示したものです。なお、前記事の議論から、誤差信号は三つの出力関数には依らないということが分かっています。
この勾配の導出が、学習アルゴリズムの三つ目でした。
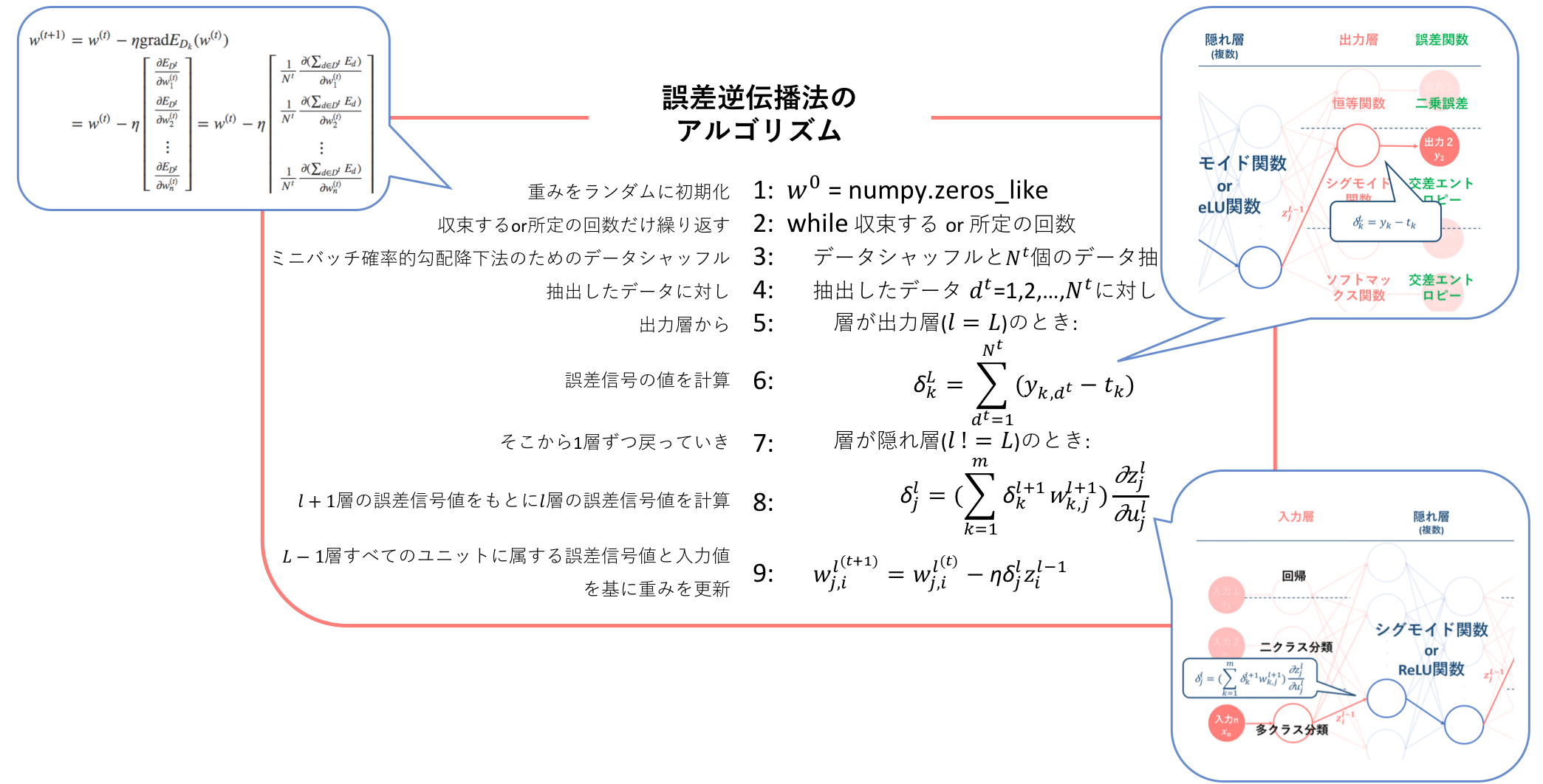
そして、学習アルゴリズムの最後である初心者の初心者による初心者のためのニューラルネットワーク#4〜理論:パラメータ更新編〜では、#3.で導出した誤差関数$E$の重み$w$に対する勾配式を勾配降下法に適用することによって、重み$w$の更新式を導出しました。そして、この逆伝播からパラメータ更新までのフローを表した手法を誤差逆伝播法(backpropagation)とし、そのアルゴリズムを示しました。そして、この誤差逆伝播法のアルゴリズムこそが、ニューラルネットワークの学習アルゴリズムになります。
引き続いての初心者の初心者による初心者のためのニューラルネットワーク#5〜(ひと休み):分類問題における学習とは編〜では、それ以前と内容が連動しているわけではなく、分類問題における学習の根幹役割について再確認しました。線形分離不可能な分類問題においては、**『線形分離可能な写像先高次元空間の発見』そして『その空間内での線形分離』**が学習の肝となります。これは、『$n$次元空間に$(n−1)$次元の非線形分離超平面を設けることは、$(n+a)$次元空間に$(n+a−1)$次元の線形分離超平面を設けることで補うことができる』ことによります。
4. ニューラルネットワークにおける学習の工夫
さて、それでは実装サイドの説明に入っていきましょう。と言っても、本章で説明するのはあくまでニューラルネットワークを現実問題に適用する場合に必要となる考え方であって、理論の域です。
また、入力Xはpandasのdataframe型を想定しています。
4.1. 正規化 (Normalization)
引用サイト:
ニューラルネットワークの学習の工夫
主成分分析と固有値問題
Batch Normalization:ニューラルネットワークの学習を加速させる汎用的で強力な手法
4.1.1. 正規化 (Normalization)
**正規化は学習データ$\{x_1,...,x_N\}$に対して、値が0〜1の範囲に収まるように加工を施すことです。**場合によっては−1〜1にすることもあります。方法は単純で、学習データの中で最も大きな値(あるいは最も大きな絶対値)を取り出し、全てのデータをその値で割るだけです。
$α = max\{x_1,...,x_N\}$
$X \leftarrow \{\frac{x_1}{α},...,\frac{x_N}{α}\}$
def normalize(X):
normalized_X = X/X.max()
return normalized_X
各次元が(身長、体重、体脂肪率)などになっていた場合は、成分毎に意味合いが全く異なるため、一般的には各成分毎に正規化をする(身長は身長だけで正規化する)ことが必要になります。
4.1.2. 標準化 (Standardization)
標準化も正規化同様取りうる値の範囲を制限するように入力データを加工をしますが、正規化ほど厳密に値の範囲を指定しません。**標準化では入力データの平均を0に分散を1にするような加工を施します。**これにより、データは概ね−1〜1の範囲に留まりますが、この範囲を飛び出るデータも出てきます。
$\mu = \frac{1}{N}\sum_i^{N}x_i$
$\sigma^2 = \frac{1}{N}\sum_i^{N}(x_i−μ)^{2}$
$X \leftarrow \frac{x−\mu}{\sigma}$
def standardize(X):
mean = X.mean()
deviation = X - mean #偏差=データと平均の差
variance = np.square(deviation).mean() #分散=偏差の二乗の平均
standard_deviation = np.sqrt(variance) #標準偏差=分散の平方根
standardized_X = deviation / standard_deviation
return standardized_X
OR
import sklearn
from sklearn import preprocessing
standardized_X = preprocessing.scale(X)
観測して集めたデータは必ずしも範囲が明確ではないため、統計的なパラメータを使ってこのような加工をするのが一般的です。なので一般に「正規化」と言ったら、この「標準化」を指すことが多いです。
4.1.3. 無相関化
無相関化は多次元データの各成分$x=(x_1,x_2,...,x_d)^T$が何らかの関係を持っている場合に、その関係性を解消することに使われます。
例えば天候に関するデータ(雲の量、気温、紫外線量)などが集まったとすれば、明らかにデータの各成分は何らかの関係性を持っています。
このような場合に、
新しい指標1=A×雲の量+B×気温
新しい指標2=C×雲の量+D×紫外線量
という計算をして、新しい指標1と新しい指標2が無相関にしてみます(そのようなABCDを見つける)。
この新しい指標は物理的に何を意味しているかは定かでないにしても、天候に関するデータから遊園地の来場者数を予測したい場合に置いて、役立つ指標が出来上がるかもしれません。
また、出来上がった指標のうち、重要な指標はごく少数かもしれません。この前処理は主成分分析と全く同等のもので、新しい指標のことを主成分と呼びます。
主成分を少数取り出せば特徴抽出として使えますが、全ての成分を残しても構いません。
この無相関化は主成分分析 (Principal Component Analysis; PCA)にも大きく関連します。詳しい説明についてはニューラルネットワークの教師なし学習:次元削減のところで行おうと思いますが、無相関化も主成分分析もその大枠のステップ自体は同じであり、それは以下からなります。
- ある方向に射影した時のデータの分散を計算する ← 分散共分散行列が必要になる
- 分散が最大になるような方向を見つける ← 固有値問題に落とし込めるので、固有ベクトルを求める
- その方向に写像する ← 固有ベクトルは回転行列となるので、元データXとの内積を計算する
def uncorrelate(X):
sigma = np.cov(X, rowvar=0) #分散共分散行列を求める
_, S = np.linalg.eig(sigma) #それを元に固有値,固有ベクトルを得る
df_S = pd.DataFrame(S) #dataframe型に変換
uncorrelated_X = df_S.T.dot(X.values.T).T #固有ベクトルを転置し内積をとり写像させる
return uncorrelated_X
ここで、最後に線形変換を行うとき、転置行列を写像しなければいけないようです。この理由については申し訳ないのですが分かりませんでした。どなたか知見のある方がいらっしゃれば教えて頂ければ幸いです。
4.1.4. 白色化
無相関化して出来上がった新たな指標(主成分)は、各成分毎に全く取りうる値の範囲が異なります。特徴抽出(主成分分析)が目的であれば、無相関化したデータを用いるのがベターでしょう。
しかし、あくまで無相関にしたいだけであったならば、成分毎に値の大きさが全く異なるのは不都合である場合があるので、取りうる値の範囲を制限したいということになります。
そこで無相関化して出来上がった新たなデータに対して、標準化を適応するのが白色化です。
通常、無相関化の処理を行う時点で平均は0に直され、分散は固有値問題を解いた際に得られるため、無相関化の処理の中で白色化の処理を簡単に追加することが可能です。
def whiten(X):
uncorrelated_X = uncorrelate(X) #無相関化
whitened_X = standardize(uncorrelated_X) #標準化
return whitened_X
4.1.5. バッチ正規化 (Batch normalization)
さて、これまでの説明は正規化や標準化といったデータの前処理におけるものでしたが、データセットだけ正規化されていても、ネットワーク内部で分散が偏ってしまいます。
そこでバッチ正規化では、入力層だけでなく各層ごとに正規化(=標準化)を行います。
バッチ正規化には二種類あり、各層に入力が入る直前に標準化を行う場合もあれば、層が出力を行った直後に標準化を行う場合もあります。これらの違いは、線形変換と標準化の順序をどうするかというところです。
ある層の計算は、以下のように線形変換をしてバイアスを加えた後に活性化関数を作用させることで達成されます。
$$y=f(Wx+b)$$
ここでバッチ正規化の処理をBN(・)で表現するとして、
$$y=f(W(BN(x))+b)$$$$or$$$$y=f(BN(Wx+b))$$
の違いです。ラダーネットワークでは後者の方法が取られていますが、必ずしもこちらが良いとは限らないようです。
また、バッチ正規化を行うメリットとしては、
-
大きな学習係数が使える
学習係数を上げるとパラメータの値によって、勾配消失・爆発することが分かっていました。バッチ正規化では、伝播中パラメータの値に影響を受けなくなります。結果的に学習係数を上げることができ、学習の収束速度が向上します。 -
正則化効果がある
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shiftによれば、- L2正則化の必要性が下がる
- Dropoutの必要性が下がる
-
初期値にそれほど依存しない
ニューラルネットワークの重みの初期値がそれほど性能に影響を与えなくなります。
import tflearn
from tflearn.layers.normalization import batch_normalization
network = batch_normalization(network)
このコードをニューラルネット構成のアルゴリズムに組み込むことによって、バッチ正規化が行われます。
4.2. 正則化 (Regularization)
引用サイト:
ニューラルネットワークの学習の工夫
正則化とは、過学習を防いだり未知パラメータ数が方程式よりも多い不良設定問題を解いたりするために、パラメータに制約を課す手法のことを指します。
分類にしても回帰にしても、入出力関係$y=f(w,x)$について$w$を上手く調整するのが目的です。しかしこの際に$w$が際限なく自由に値を取れてしまっては、トレーニングデータに対して過学習してしまう危険性があります。
正則化では、$w$に対して何らかの制約を入れることによって過学習を防ぎます。
学習が損失関数$L(w)$を最小化するという形で定式化されている場合、この損失関数に加えて正則化項$λR(w)$を追加します。
一般的な形としては、
$$L(w)+λR(w)$$
という表現になり、$λ$は正則化の強さを決める度合いです。メインはあくまで第一項の方であるため、通常$λ$は0.001〜0.1などと小さな値が設定されます。
最小化をする際に、Lの方を小さくできた(学習が進んだ)としても、Rの方をあまり大きくするのはダメですよという制約を入れていることになります。
4.2.1. L1正則化 (L1 regularization)
$L1$正則化は、パラメータ$w$の成分が0となりやすいように制約を入れます。この正則化によって、学習データが膨大な次元を持っていたとしても不要な成分を落としてくれるため、過学習が抑えられることが期待できます。最小化するための損失関数は、
$$L(w)+λ|w|_1$$
$$|w|_1=w_1+w_2+...+w_n$$
という形になります。$|w|_1$は$w$の$L^1$ノルムと呼ばれ、各成分の絶対値の和を表します。したがってこの値を小さくするためには、多くの成分が0になる必要があります。
4.2.2. L2正則化 (L2 regularization)
$L2$正則化は、パラメータ$w$をベクトルと見たときに、ベクトルがあまりに大きくなることを防ぐ制約を入れます。最小化するための損失関数は、
$$L(w)+λ|w|_2$$
$$|w|_2=\sqrt{w_1^2+w_2^2+...+w_n^2}$$
という形になります。$|w|_2$は$w$の$L^2$ノルムと呼ばれ、各成分の二乗を考慮することになるため、極端に大きな成分が現れるのを防いでくれます。
4.2.3. Elastic-Net
Elastic-Netは特に特別な概念ではなく、L1正則化とL2正則化を両方入れるものです。最小化するための損失関数は、
$$L(w)+λ\{α|w_1|+(1−α)|w_2|\}$$
ここで、$λ$はいつもどおり正則化の強さを決める係数です。αはL1正則化とL2正則化をどれだけの割合で混ぜ込むかを決める係数です。細かいこと気にしなければとりあえず、両方ぶち込んで適当にそれぞれ係数決めればいいです。単純に正則化を入れまくってるものだと思えば、当然分類問題でも応用可能です。
4.3. ドロップアウト (Dropout)
ドロップアウトとは、ニューラルネットワークを学習する際に、ある更新で層の中のノードのうちのいくつかを無効にして(そもそも存在しないかのように扱って)学習を行い、次の更新では別のノードを無効にして学習を行うことを繰り返すことによって、過学習を防ぐ手法のことです。
要するに、情報の伝達をあえて断ち切り、少数の情報だけで学習を行うようにする手法です。
ある層の出力$y$に対して以下の線形変換がなされるとき、
$$y=f(Wx+b)$$ドロップアウトはこのときの$y$の成分を一定の割合で0にしてしまいます。
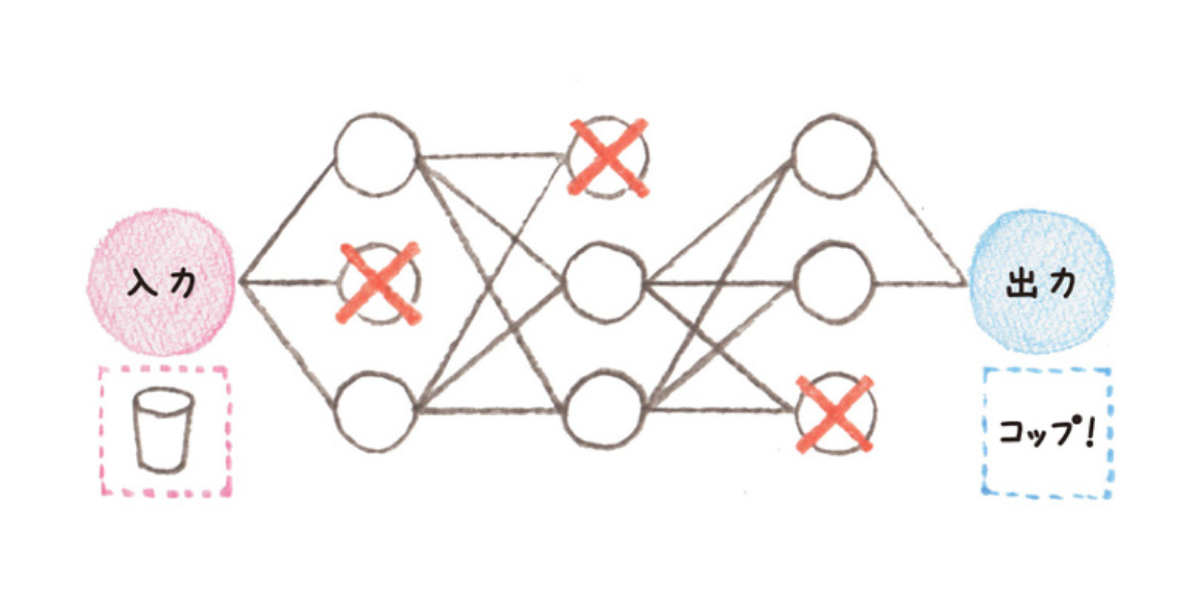
(画像出典:ディープラーニングを支える黒魔術「ドロップアウト」)
厳密には、ドロップアウトによる不活性化の選択は、各層に対してドロップ確率$p$が付与されるわけではなく、ドロップアウトを仕込んだ層の各ノードごとに対して掛けられます。よってユニット数は、中間層の数を揃えていたとしても、ドロップアウトを混入させることで変化します。
これによって、学習を行う度に選択されるユニットが大きく異なり、アンサンブル学習における精度向上に寄与します。
ドロップアウトによって、単体での性能がちょっと低くなりますが、互いを補い合える「弱学習器」を寄せ集めることで精度の向上を図ることがアンサンブル学習の基本的な考えです。
しかし実際にテストデータを分類させる際には、全てのユニットを用いることに注意してください。
4.4. アーリーストッピング (Early stopping)
アーリーストッピングもまた、過学習を防ぐための手法の一つです。
ただ他の手法と異なる点として、アーリーストッピングは過学習に陥る前に学習そのものを打ち切るという点が挙げられます。
アーリーストッピングは、学習データの一部を学習用(訓練データ)と評価用(検証データ)に分けます。そして、学習中に評価データを用いた精度算出およびパラメータを保存し、過学習の傾向が見え始めた時点で学習を打ち切ります。

(画像出典:見て試してわかる機械学習アルゴリズムの仕組み 機械学習図鑑)
上図では、学習回数がある閾値を超えると、訓練データでの精度は向上している一方で、検証データでの精度は低下しています。アーリーストッピングでは、これを過学習と捉え、検証データにおける精度が最も高いパラメーターを保存することで、過学習を防ぎます。
4.5. 勾配降下オプティマイザ
引用サイト:
勾配降下法の最適化アルゴリズムを概観する
今更聞けないディープラーニングの話【ユニット・層・正則化・ドロップアウト】
しかし、仮にニューラルネットの設計や、正則化が上手く働いていても、かならずしも学習結果が良くなるとは限りません。ニューラルネットは基本的に勾配法と呼ばれる方法で、損失関数を減少させる方向に少しずつ進んでいきます。しかし、学習の開始地点から、本来到達したい地点まで、損失関数が綺麗に減少していくとは限りません。
ニューラルネットは$w$を少しずつ調整しながら、学習データを表現できるように学習を進めていくのですが、進んでいく過程に、その周りよりは損失関数が小さくなる地点が存在し、そこにハマってしまうのです。
このような局所解や鞍点というのは勾配法にとっては偽物の解として振る舞います。そして、ニューラルネットには鞍点が非常に多く存在するようです。
このような問題に対処するための勾配降下法の最適化アルゴリズムとして、以下が挙げられています。
- モメンタム法
- AdaGrad
- RMSProp
- Adam
詳細については別記事で取り上げたいと思いますが、一般的にはAdamが用いられることが多いようです。
4.6. ノイズ混入
ニューラルネットを学習させる際に,わざと入力データにランダムにノイズを混入させる手法として扱われています。
5. ニューラルネットワークにだって色々あるの
ニューラルネットワークの中間層を多層にする手法として、畳み込みニューラルネットワーク (Convolutional Neural Network: CNN)や再帰型ニューラルネットワーク (Recurrent Neural Network: RNN) があります。CNNとは、畳み込み層(フィルタリングをして特徴量を取り出す層)とプーリング層(フィルタの結果から選択する層)を交互に繰り返すことでデータの特徴を抽出し、最後に全結合層で認識を行う手法です。一方RNNとは、中間層において、中間層の結果を自ら再度入力に用いることで、文脈理解を可能にする手法です。単純化すると、CNNが順次処理、RNNが再帰処理ということになるでしょうか。
6. 参照
今更聞けないディープラーニングの話【ユニット・層・正則化・ドロップアウト】
ニューラルネットワークの学習の工夫
勾配降下法の最適化アルゴリズムを概観する