目次
- DBとはなにか
- SQLとはなにか
- クエリを書く前の心構え
- SQLの基本形
- データを絞る (where句)
- テーブルをつなげる (join)
- 結果を集計する (goup by)
- 順番を制御する (order by)
- 最後に
DBとはなにか
データを入れておく箱。
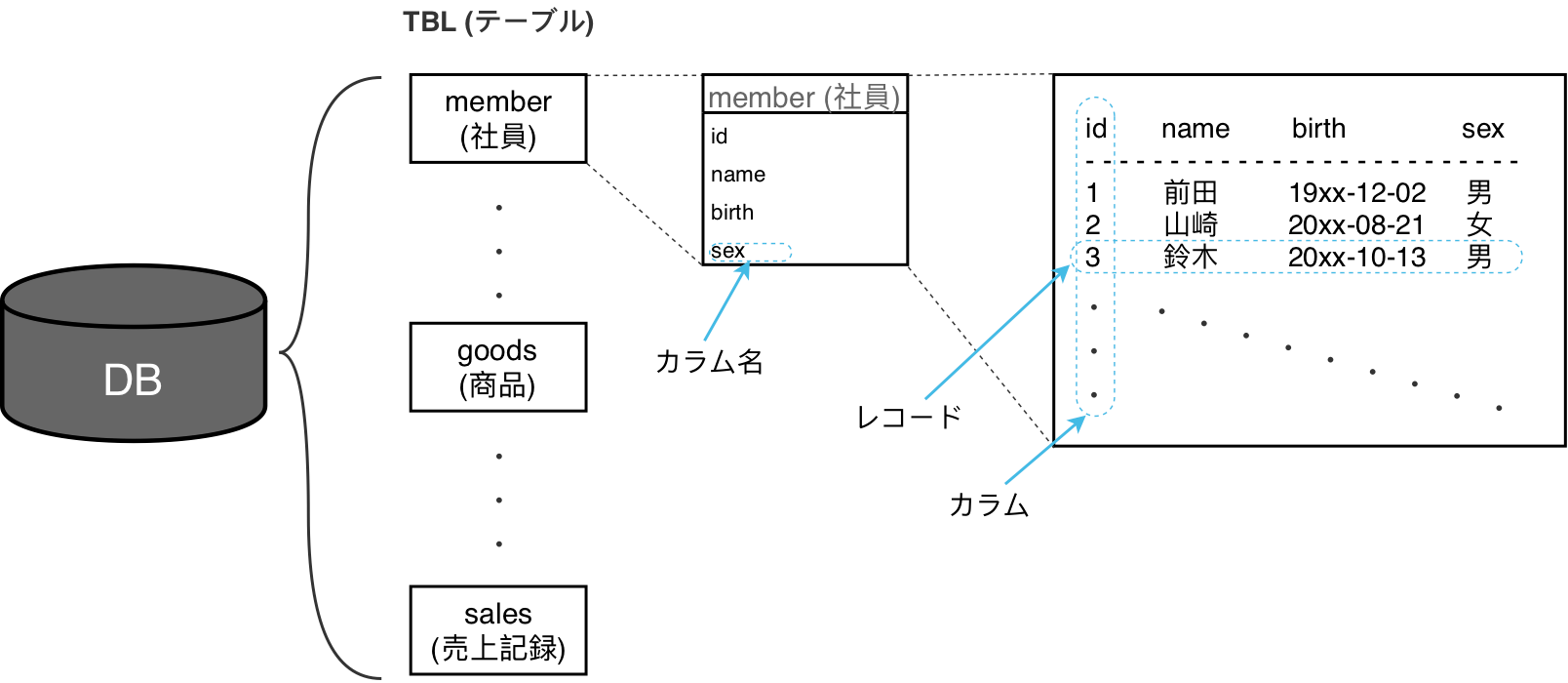
どんな要素で成り立っている?
- テーブル
- データをまとめた表
- 表の集まりがDB
- カラム
- 縦 / 列のこと
- レコード
- 横 / 行のこと
イメージ
SQLとはなにか
なんの略?
SQL : Structured Query Language
- Structured
- 構造化された
- Query
- 問い合わせ
- Language
- 言語
なにするために使うの?
DB操作をするために使う。
- データを抽出, 集計する
- ( テーブルを作成, 削除する )
- ( データを挿入, 更新する )
下2つは、最初のうちは使いません。
とくに、削除や消去は心が踊りますが、絶対に使わないでください!
クエリを書く前の心構え
弊社マーケの中で、随一のクエリ力をもつR.N氏からの金言を借用します。
要点
- 事業の持続的な成長には競争優位を築くことが必要
- 競争優位を築くには、ユーザーの課題、事業の課題を明確に捉えることが必要
- 課題を捉えるためには、自社・市場のデータを活用する力が求められている
- データを活用する力の一つが、データを期待通り抽出する技術
- それが、SQLである。
書く前に
- 用途、期待結果を明らかにする。
- どのような目的のために書くのかが曖昧なままでは正解がないため、当然書けません。
- 目的を満たす期待結果が曖昧なままでは…(同上)
-
複雑な要件であったり、期待結果のイメージが困難な場合は仕様書を書きます。
- どのテーブルからどんな情報をどのように持ってきて、どういうアウトプットにするのかを書き出して整理する。
- 人に依頼するときは極力仕様書を書いたほうが良いと思います。認識のズレやタスク量を可視化することができます。
- 要件を要素に分解する。
- 要件をいくつかの要素に分解します。
- 慣れないときは、一度日本語の文章をそのまま書き出してみて、修飾、被修飾、主語述語の関係を書き出してみるといいと思います。
- 要件をいくつかの要素に分解します。
SQLの基本形
基本構文
基本として
- select
- from
- where
を覚えましょう。
こんな感じで書きます。
select
{{ column }}
from
{{ table }}
where
{{ condition }}
select句, from句, where句の順番は決まっています。
select句
どのカラムが欲しいか
from句
どのテーブルのデータを参照したいか
where句
どの条件にあてはまるレコードが欲しいか
実行順序のイメージ
- from句のテーブルを持ってくる
- where句の条件にあわせて必要なレコードをふるいにかける
- select句で指定されたカラムのデータを抽出する
クエリを書く際の上から下とはちょっと異なるので注意。
コーディングスタイル
大文字・小文字はSQLには基本的には影響を与えません。(一部例外あり)
テーブル名やselectなどは、大文字で書いても小文字で書いても同じ動作をします。
インデントもつけてもつけなくても。改行もしても、しなくても。
著者は、クックパッド開発者ブログ - 分析SQLのコーディングスタイルを参考にしています。
実例用テーブル定義
前提情報 `テーブル.カラム名` の表記は、複数テーブルにおいて同じカラム名が使われているときに、どのカラムかを明示するために使われます。 ただ、著者は、カラム名が被っていない場合もあえて明示的に `テーブル.カラム名` の表記を使用しています。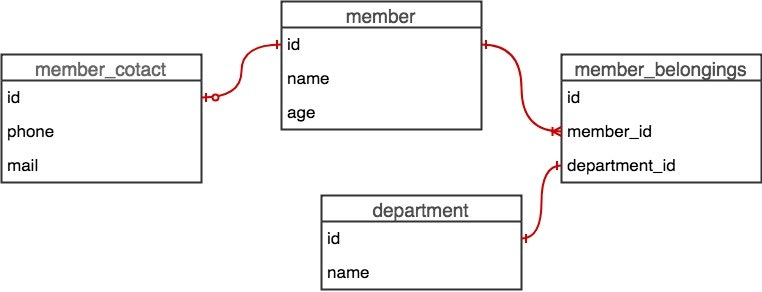
Table: member (社員)
| id | name | age |
|---|---|---|
| int | varchar | int |
Table: member_contact (社員_連絡先)
- member_contact.id = member.id
| id | phone | |
|---|---|---|
| int | varchar | varchar |
Table: member_belongings (社員_所属)
member : member_belongings = 1 : N
- member_belongings.member_id = member.id
- member_belongings.department_id = department.id
| id | member_id | department_id |
|---|---|---|
| int | int | int |
Table: department (部署)
| id | name |
|---|---|
| int | carchar |
データを絞る (where句)
条件式
条件を指定するために使用される論理式のことを条件式といい、結果は true(真) または false(偽) で返ってきます。
例)
- 1 = 1 → true
- 1 = 2 → false
- 3 < 2 → false
ここで、 = や < を演算子と言います。
基本的な演算子
| 演算子 | 使用例 | 意味( trueを返す条件) |
|---|---|---|
| = | a = b | a と b は等しい |
| <> | a <> b | a と b は等しくない |
| != | a != b | a と b は等しくない |
| < | a < b | a は b より小さい |
| <= | a <= b | a は b 以下 |
| > | a > b | a は b より大きい |
| >= | a >= b | a は b 以上 |
ちょっとランク上の演算子
この他にもありますので、必要に応じて使って覚えてください。
| 演算子 | 使用例 | 意味( trueを返す条件) |
|---|---|---|
| is null | a is null | a は NULL である |
| is not null | a is not null | a は NULL ではない |
| is | a is boolean_value | a は boolean_value(true or false)である |
| is not | a is not boolean_value | a は boolean_value(true or false) ではない |
| in | a in ( values... ) | a は ()内のいずれかに等しい |
| not in | a not in ( values... ) | a は ()内のいずれにも等しくない |
複数条件
条件が複数の場合は
- and : かつ
- or : または
を用いて、条件を増やしていきます。
さらに、 () を用いることで入れ子にすることも可能です。
実例
select内で * を使用するとfrom句内で指定したテーブルの全カラムを抽出します。
テーブル名.* は、指定したテーブルにおける全カラムをい抽出します。
なお、この書き方は非常に重たいので、基本的には使用しないよう心がけましょう。
select
member.* -- memberテーブルの全カラムを抽出
from
member
where
( member.id <> 1 and member.age > 35 )
or (
member.name is not null
and member.id in( 2, 3, 4, 5, 6, 7 )
)
どういう意味かわかりますか? (クリックで開く)
正直普通はこんな書き方しないです。ww
id が 1でなく、ageが35より大きい もしくは、nameがNULLではなく、idが2,3,4,5,6,7のいずれかですね。
なお、 -- コメント でコメント文を記入することができます。
コメントだらけにする必要はありませんが、レビューしてもらう人のためにも、明日の自分のためにも活用していきましょう。
テーブルをつなげる (join)
なぜつなげるのか?
さて、一つのテーブルからデータを取り出せました。
社員のデータですね。
これで満足ですか? 不十分ですよね。
データを抽出・集計するとなると、
- 各社員の名前と連絡先の一覧がほしい
- 各部署の社員年齢分布を知りたい
とかですよね。
どうする?
さて、ひとつのテーブルのデータでは太刀打ちできません。
どうしますか?
テーブルをつなげ(連結させ)ましょう。
どうやって?
関連するテーブル同士には、連携するためのキーがあります。
Table: member_contact (社員_連絡先)
- member_contact.id = member.id
Table: member_belongings (社員_所属)
- member_belongings.member_id = member.id
- member_belongings.department_id = department.id
と書いたものです。
これを、つなぐために JOIN という文言を使います。
JOINの種類
今日は、 left outer join のみ使用します。
- 内部結合
- inner join
- 外部結合
- left outer join
- right outer join
詳しくは
- SQL素人でも分かるテーブル結合(inner joinとouter join)
- SQL | 分かりにくい JOIN / INNER JOIN / OUTER JOIN / LEFT JOIN / RIGHT JOIN の違い
実例1
社員と社員_連絡先をつなぎ、名前と電話番号の一覧を作成しましょう。
なお、select句の中で、 カラム名 as 名称 と as をつけてあげることで、データを抽出したときのカラム名を変更することができます。
select
member.name as "社員名"
, member_contact as "電話番号"
from
member
left outer join
member_contact
on member.id = member_contact.member_id
なお、joinするキーを設定している on a = b において、著者は
- a(左辺) : 親(起点)になるテーブルの値
- b(右辺) : 子(従属)になるテーブルの値
になるように記述しています。
特に決まりはありませんし、無視してもSQLは正常に動作します。
ただ、エラーが発生したときの保守性や他の人が見たときのわかりやすさを考えてクエリを書くことを考えて、個人的には上記の決まりを定めています。
実例2
さらに、上記に加えて、所属も出したくなりました。
select
member.name as "社員名"
, department.name as "部署"
, member_contact.phone as "電話番号"
from
member
left outer join
member_contact
on member.id = member_contact.member_id
left outer join
member_belongings
on member.id = member_belongings.member_id
left outer join
department
on member_belongings.department_id = department.id
departmentのところのインデントはなくても正常に動作します。
クエリの見た目が、テーブルを連結させている状態をイメージできるようにインデントを使っています。
こうしておくことで、一つのテーブルをfrom句から削除した際に関連するテーブルなどがわかるので、非常に便利です。
結果を集計する (goup by)
いつ使う?
データ分析といえば
- 合計
- 平均
- カウント(個数を数える)
といったことをするんだろうな、と思いますよね。
そう、その時に使います。
集計関数 と group by
集計関数は、合計や平均を勝手にやってくれー!とお願いするための関数です。
集計関数を使用するときは、どのカラムを集計から除外するのかを明示してあげる必要があり、このためにgroup byを使います。
(わかりやすさのために集計から除外するのかと書きましたが、著者的に基準にしてあげるか、という考え方が好きです。)
やってみましょう
各部署の社員の平均年齢を計算するケースを考えましょう。
この時、抽出されるべきデータは
- 部署id
- 部署名
- 平均( 社員年齢 )
です。
集計関数が使われるべきデータは社員の年齢です。
では、集計, 集約から除外されるべきデータはどれでしょうか?
部署idと部署名です。
集計関数
SQLにはたくさん集計関数があります。
そして、SQLの種類によっても実は少し書き方やできること、結果が違うことがあります。
適宜、調べながら対応していきましょう。
よく使うものを記載します。
| 名称 | 使用例 | 役割 |
|---|---|---|
| sum | sum( a ) | a の合計。 |
| avg | avg( a ) | a の平均。 |
| count | count( a ) | a の個数。 |
| max | max( a ) | a の最大値。 |
| max_by | max_by( a, b ) | b が最大の a の値。prestoでしか使えません! |
| min | min( a ) | a の最小値。 |
| min_by | min_by( a, b ) | b が最小の a の値。prestoでしか使えません! |
実例
各部署の
- 人数
- 平均年齢
- 最年長者の年齢
- 最年長者の名前
を取得してみましょう。
select
department.name as "部署名"
, avg( member.age ) as "平均年齢"
, max( member.age ) as "最年長者の年齢"
, max_by( member.name, member.age ) as "最年長者の名前"
from
member
left outer join
member_belongings
on member.id = member_belongings.member_id
left outer join
department
on member_belongings.department_id = department.id
group by
department.name
順番を制御する (order by)
いつ使う?
順番を並び替えたいときってありますよね。
値が大きい順、小さい順。
どうする?
order byを使います。
order by カラム (順序)
になります。
順序に入るのは、asc(昇順), desc(降順)です。
実例
select
department.id as department_id
, max( member.age ) as "最年長者の年齢"
from
member
left outer join
member_belongings
on member.id = member_belongings.member_id
left outer join
department
on member_belongings.department_id = department.id
group by
department.id
order by
department.id desc
最後に
SQLの可能性がわかるようになってきたでしょうか?
データを出している自分をイメージできていれば、嬉しいです。
ただ、まだSQLの門を開いてちょっと踏み出した所です。
目的の手段化は避けたいところですが、SQL自体がパズルのようで非常に面白いです。
ぜひ、業務に直結しないことであっても、色々勉強して、トライしてみてください。
参考
SQLデータ分析入門#1『SQLってなんだ』 - Qiita
SQLデータ分析入門#2『SELECT ~ FROM ~ を理解する』 - Qiita
SQLデータ分析入門#3『WHERE句を理解する』 - Qiita
SQLデータ分析入門#4『LIMIT句を理解する』 - Qiita
SQLデータ分析入門#5『集計関数を理解する』 - Qiita
SQLデータ分析入門#6『結果の順番をいい感じにする』 - Qiita
SQLデータ分析入門#7『複数のテーブルにまたがって集計する』 - Qiita
SQLデータ分析入門#8『基本的な関数を知る』 - Qiita
逆引きSQL構文集
これならわかる SQL入門の入門
クックパッド開発者ブログ - 分析SQLのコーディングスタイル