いまさらの話題なのですが、以下の記事を読んで、マジかよ!
深層学習はガウス過程 - 作って遊ぶ機械学習
って思ったのですが、言ってる意味が良くわからなかったので、統計学苦手な私が、統計学苦手な人向けにガウス過程とそれによる回帰がなんとなく分かった気になれる記事を書いてみようと思います。個人的な学習メモの意味合いもあります。
なお、上記記事にも書いてありますが、深層学習 == ガウス過程 というのは誇張表現で、そのようにモデル?できる場合が(結構)ある、という話のようです。
免責事項
- 数学用語の使い方や、用語、数学的表現の仕方が誤っている可能性があります
- ガウス過程での回帰についてなんちゃって解説?しますが、それがそのまま深層学習と同じものを表現しているわけではおそらくないです(ここはYes とも No と言い切れない程度に自信がないです)
- ガウス過程での回帰ではカーネル関数というのが重要なのですが、上記の記事によると、深層学習で利用されている活性化関数とかに応じてカーネル関数も変えないと少なくとも同じものを表現したことにはならないようなので、単一のカーネル関数しか用いていないこの記事での回帰コードは、当然のことながら、深層学習のモデル一般と同じもの、とかいう話にはなり得ません
- ちゃんと理解したい方は、冒頭の記事を頭から終わりまで、数式も含めてしっかり読んで、理解することをおすすめします。分からない記号や用語が出てきたら、それについてもちゃんとした解説なり教科書で勉強した方がいいです。話題の発端となっている論文も公開されているようなので、それを読むのも良いでしょう
- 誤っているところがあればご指摘お願いします!
ガウス過程とは
いきなりタイトルの「コードから」というのから外れるのですが、これを説明しないのはさすがにダメだろ、ということで、私の理解したガウス過程について説明します!
解説
ある一次線形和(一次結合)で構成される関数 f(X) = w{1}x{1} + w{2}x{2} + w{3}x{3} ・・・w{N}x{N}
(f(X)はスカラ、x{n} はスカラ、Xはスカラ値のリスト(N要素のベクトル)、w{n}はスカラ値で、w{1}~w{N}は正規分布に従っている)
があったときに、任意の値から成るベクトルXを関数 f に与えた時の算出結果である f(X) が正規分布に従うとき、この関数 f をガウス過程である、という。
ということらしいです。
(常識かもしれませんがガウス分布と正規分布は同じ分布を指す言葉です)
wは各項の係数で重み、というような意味合いですね(Weight)。
過程とかいうから時系列でうんぬんというのをイメージしますが、必ずしもそういうもんでもないみたいです。
ちなみに、ブラウン運動としても知られるウィーナー過程というのもガウス過程(各点を求める関数がガウス過程)だそうです。
ちょっと考えてみると、確かにガウス過程であることの要件を満たしてます。
ガウス過程を理解するのに参考になったページや資料
カーネル関数とは
- 正直うまく説明できません。ある空間からある空間への写像だと思っているのですが、それってただの関数じゃね?という気もしており。。。
- カーネル関数によると
パラメトリックな線形モデルの多くは同値の双対表現の形に表すことができます。予測も訓練データ点を中心として定義される カーネル関数 (kernel function) の線形結合を用いて行われます。
あらかじめ定義された非線型の 特徴空間 (ffeature space) への写像 Φ(x) に基づくモデルにおけるカーネル関数は次の関係になります。
k(x, x') = \phi(x)^T \phi(x')
ということです。はい。
ガウス過程での回帰で用いられるカーネルトリックというやつの理解の参考になったページや資料
ガウス過程で回帰
一言でいうと、教師データから、教師データとして情報をもらっていない区間も含めて値の分布 (x を決めた時の y の値のがどうなっているか) を推測する!ということみたいです。はい。
でも、そう言われても・・・という感じだと思うので、以降解説?します。
最初に、私が作った Google Colabolatory上で実行した(動作する)Jupyter Notebook を閲覧権限で用意してありますのでご参考まで
https://colab.research.google.com/drive/149PDrbbzwVT2encJoMc_ZrV8H-4g0K0t
**※**閲覧権限しかないので、コード実行をしたい場合は自分のGoogle Driveにコピーして、それをGoogle Colaboratoryで開く形で使ってください
補足: 上記 Notebook には、多次元入力 (2次元) の場合のコードも含まれています。アドバンスドな内容?を知りたければそちらもご参照ください(参考にさせてもらった記事のリンクも貼ってあります)
Google Colaboratoryとかよくわからんという方はgithubにも同じものを置いてあるのでそちらをどうぞ。
https://github.com/ryogrid/ryogridJupyterNotebooks/blob/master/gaussian_process_regression_linked_from_qiita.ipynb
参考にさせていただいたページ (大変助かりました。ありがとうございます!)
- [Fitting Gaussian Process Models in Python]
(https://blog.dominodatalab.com/fitting-gaussian-process-models-python/) - [pythonでガウス過程を実装する。パラメータの調整はマルコフ連鎖モンテカルロ法(MCMC)を使う - Qiita]
(https://qiita.com/phyblas/items/d756803ec932ab621c56) - Gaussian processes
コードを眺めて、どこで学習が行われているのかを考えてみる
上の2つめのリンク先にあるコードを少しいじったコード(コード全体は上にリンクしているJupyter Notebook にあります)が分かりやすい感じなのでそれを見てみます。
1スカラ入力、1スカラ出力の関数を回帰するコードです。
肝心かなと思うところだけ抜粋しており、グラフのプロットのところなどは省略しています。
import numpy as np
class BasicKernel:
def __init__(self, param):
self.param = param
def __call__(self,x, y):
a, w = self.param
#return a * np.exp( -0.5 * w * np.subtract.outer(x, y)**2)
return a * np.exp( -0.5 * w * (x - y)**2)
theta = [1, 20]
x0 = np.arange(0, 10, 0.5)
y0 = np.sin(x0)
x1 = np.linspace(0, 10, 40)
kernel = BasicKernel(theta)
# 逆行列が求まらない行列を回避するためのノイズ用行列
# 対角に以降の算出結果に影響を起きない程度のノイズ値を持つ正方行列
# これを加算することで加算された行列はランク落ちが回避できる
noise_mat = np.eye(20) * 0.001
k00 = kernel(*np.meshgrid(x0,x0))
k00 = k00 + noise_mat
k00_inv = np.linalg.inv(k00) # 逆行列
k01 = kernel(*np.meshgrid(x0, x1,indexing='ij'))
k01_T = k01.T
k11 = kernel(*np.meshgrid(x1, x1))
mu = k01_T.dot(k00_inv.dot(y0)) #予測したyの値のベクトル
- _call_: カーネル関数の実体です。ガウシアンRBFと呼ばれる関数のようです
- kernel: 上の_call_の参照を保持しており、カーネル関数呼び出しとして用いられています。一変数しかとっていないように見えますが、2つの行列を引数としてとっています。
- theta: カーネル関数のためのパラメータでカーネル関数の中の a と w に対応します
- x0: 教師データのX座標のベクトル
- y0: 教師データのy座標のベクトル。このコードにおいては、x0を与えた sin関数の値にしている
- x1: 予測したい箇所のx座標のベクトル(予測したいx座標(スカラ)が複数あるのでベクトルになっているだけ)
- noise_mat: 省略
- (少し飛んで) mu: 予測したyの値のベクトル
ここからが難しいところですが...
まず *np.meshgrid(x,y) という関数はなんぞや、というところなのですが、結論から言うと、x(長さm) と y(長さn) という一次元ベクトルから、行列としてみた時に、x が 行とした並んだ行列、y が 列として並んだ行列 の2つを要素として持つリストが返ります。行列のサイズは n x m になるようです(ndarrayのshapeで確認するとそうなる)。
元々は、例えば、x と y で z を求めるような関数があって、zを3次元グラフにプロットしようとしたときに、 x と y の全組み合わせ(x と y はベクトルを用意するとする)、言い換えると格子点とかなるらしいですが、を求めるときとかに使うためのユーティリティ関数です。
https://docs.scipy.org/doc/numpy/reference/generated/numpy.meshgrid.html
以下でK〇〇という変数名の変数はカーネル関数を用いて各要素を計算することで求まる共分散行列・・・だそうです。
ですよ!
- K00: (x0を行として持つ行列 - x0を列として持つ行列) をカーネル関数に入力して得られた行列(各要素にカーネル関数が適用されている)
- k00_inv: K00の逆行列
-
k01: (x0を行として持つ行列 - x1を列として持つ行列) をカーネル関数に入力して得られた行列
- 教師データを持っている(yの値を知っている) x のベクトルと予測したい x の座標を入力として meshgrid関数で作成した行列 x 2 を用いている、ところが重要だと思う
- k01_T: K01を転置した行列
と登場人物については説明してみましたと。
で、数式とか無視してコードを眺めると、
( [コードを参考にさせていただいた記事]
(https://qiita.com/phyblas/items/d756803ec932ab621c56) の数式との対応を見てももちろんよいです。ただ、一部、個人的に読みづらかったので変数名をいじったりしているので、そこはご注意ください)
予測結果(予測したyの値のベクトル mu ) は以下の式で算出されています。
mu = k01_T.dot(k00_inv.dot(y0))
えっ、それだけの話で(お前の解説とやらは)終わり?って思われそうなのですが、
- 上記の式で y0 は教師データの y の値のベクトルなので学習後(ということにする) に(予測時点において) 既知です
- k00_inv も 教師データのxの値のベクトルからだけ(予測したいx座標やy座標とは独立で)求まる値なので学習後に求めておけるものです
- k01_T は 転置する前の K01 を求めるのに、予測したい x座標のベクトルである x1 を使っているため、予測の段階にならないと求まらないものです。ただ、求めるときには 教師データの xの値のベクトルである x0 を利用します。
整理すると、
- k00_inv.dot(y0) という部分は教師データが全て与えられた時点で求められるものであり、このプログラムを拡張したものを学習器として利用することを考えてみた場合、この部分は予測モデルを構成する一要素として、予測時に備えて計算しておくことが想定されます
- k01_T を求めるために x0 も必要なので、これも予測モデルを構成する一要素として保持しておくことが想定されます
で、結論ですが、学習により得た知識(?)は
- k00_inv.dot(y0) を計算したもの、と、x0 に蓄積されている!!!
ということになるのかと思います。
なお、mu の算出コード
mu = k01_T.dot(k00_inv.dot(y0))
は参考にさせていただいた記事の数式に照らすと、
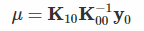
に対応しています(k01_Tという変数名は元々はk10でした)。
ちゃんと対応してますね!
ということで、結構長文で疲れてきたのでこれぐらいで。
以上!