この記事は、Supershipグループ Advent Calendar 2021の15日目の記事になります。
Supership データアナリティクス部の ps010 です。普段は広告・マーケティング領域で、分析業務や広告セグメントの作成を担当しています。
記事の目的
この記事では、Attention機構(以下、Attention)の仕組みの理解を目的とします。
Attentionは深層学習の幅広い分野で用いられ、発展の著しい自然言語分野においてエポックメーキングとなった技術です。前回取り上げたTabnetでも使われていて興味を持ったので、この機会にまとめてみました。
今回は、Attentionをイメージしやすいように、以下の方針で解説をしていきます。
- 深層学習の基本知識を持っている人を対象とします。
- わかりやすさを重視して、Attentionの仕組みを図解します。
- 以下の分野で、どのように使われているのかを紹介します。
- CNNの画像認識
- seq2seqの機械翻訳
- Transformerの機械翻訳
- Vision Transformerの画像認識
Attentionとは
- 入力されたデータのどこに注目すべきか、動的に特定する仕組みです。
- 自然言語を中心に発展した深層学習の要素技術の1つで、Attentionを用いたTransformerやその後継の言語モデルは、機械翻訳や文章生成などの分野でSoTA(最高水準の精度)を達成しています。
- 画像認識や時系列データにも応用されています。
理解しやすさのために、構造のシンプルな画像認識のAttentionから説明を進めます。
CNNの画像認識におけるAttention
画像領域のAttention
CNNによる画像認識において、認識に関係のない背景などの情報が影響を与えることがあります。様々な工夫が考えられますが、Attentionを用いることで、関係ある領域に注目させるような機能を実装することができます。
例えば、犬を分類したい場合、画像を前景と背景に分けて、前景のみにフォーカスして学習を行います(photo-ac フリー素材使用)。

単純な例で説明すると、CNNから2層程度のConv層と活性化関数のブロックを分岐して、元の出力と掛け合わせます。幅や高さはそのままでチャネル数が1のAttention用のブロックです。

ブロックの最後の活性化関数にSigmoidを用いることで、元の特徴量に0~1の値が掛け合わされます。すると、注目すべき領域の値はそのままに、それ以外は0に近い値となり、注目したい領域に特化した学習が可能になります。
画像の特徴のAttention
次に、画像の特徴に対するAttention「SENet」を紹介します。CNNでは、対象の輪郭やテクスチャなどの特徴をチャネル毎に抽出して学習を進めています。

SENetは、CNNのチャネルに対してSEブロックというAttentionを適用したアーキテクチャです1。

チャネル間の重みを学習した後に、元の特徴量マップに掛け合わせることで、注目すべき特徴に特化した学習が可能になります。
CNNベースの画像認識におけるAttentionの説明は以上です。
なお、昨年話題になったVision Transformerは、CNNの畳み込みを用いずTransformerのエンコーダをベースに作られています。
では次に、自然言語におけるAttentnionを説明します。
自然言語におけるAttention
seq2seqを用いた機械翻訳でのAttention
seq2seqを用いた機械翻訳では、エンコーダは最終ステップのhidden statusを固定長ベクトルの形式でしかデコーダに渡せないため、文章が長くなると必要な情報をもれなく伝えるのが難しくなります。これは人が翻訳する時もあり得ることで、日本語で聞いた話を記憶して、新たに英語の文章を作ると正確性は落ちやすくなります。

そこで、デコーダから入力系列のhidden statusのベクトルを直接参照できるようにしたのが、seq2seqのAttentionです。処理ステップ毎に関連する入力系列を選んで、翻訳に反映する方法です。系列の選び方はいくつかありますが、内積を使って説明します。
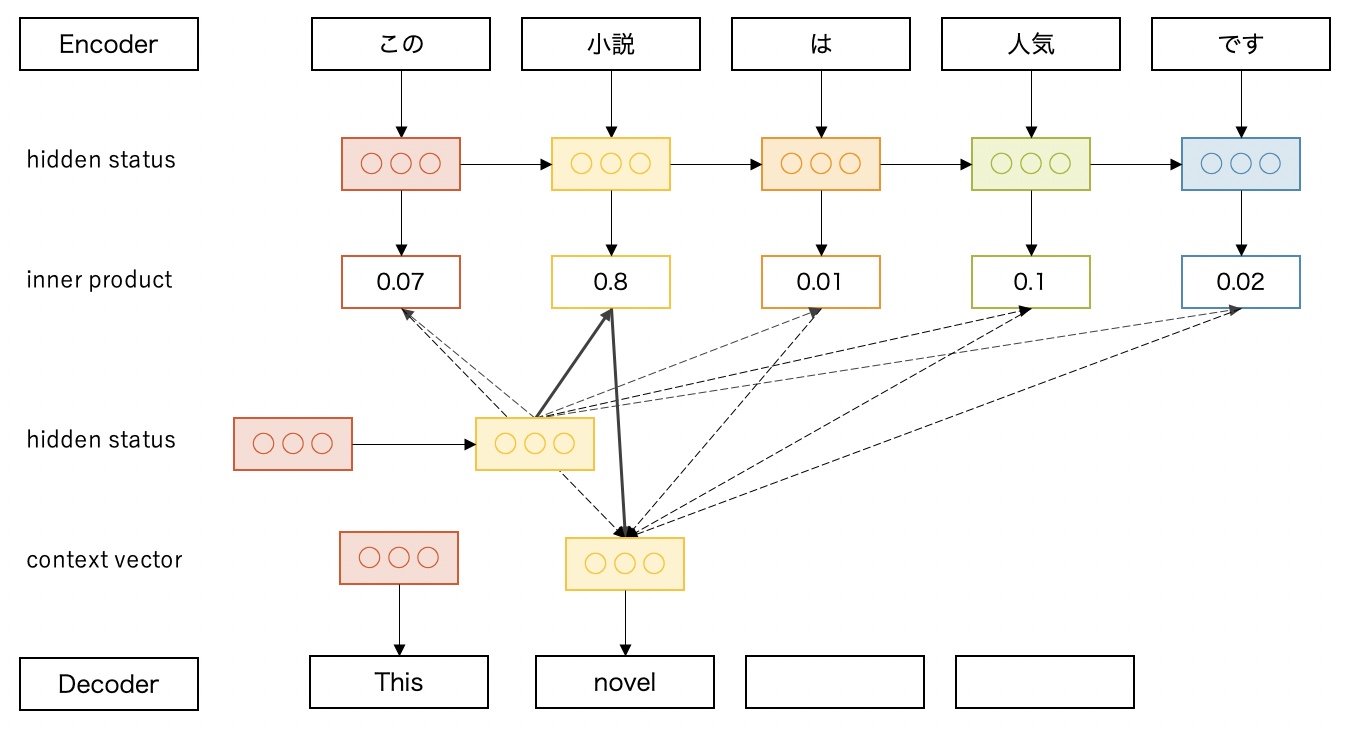
ここでは2ステップ目を処理中です。2つ目のhidden status(黄色)と入力系列全てのhidden statusの内積をとり、softmaxで正規化します。内積に入力系列のベクトルを乗算した重み付き和をcontext vectorとして算出し、最終的に出力を選びます。
今回は「小説」の内積が0.8で最も高いのでこれが反映され、「novel」が出力されています。
Query-Key-Valueを用いた機械翻訳でのAttention(Transformer)
次は、Transformerで用いられるAttentionについて説明します。
Transformerでは、QueryとKey-Valueペアを用いて出力をマッピングする Scaled Dot-Product Attention(スケール化内積Attention)という仕組みを使っています(図は論文2より)。
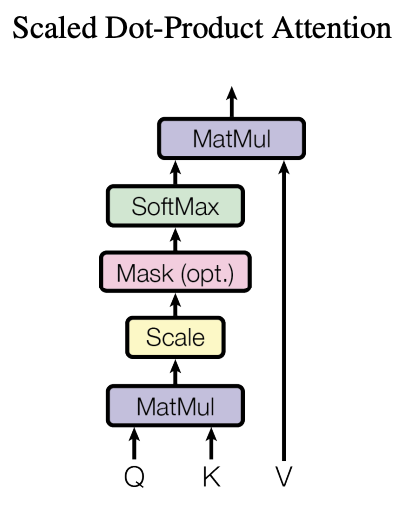
図のQはQuery、KはKey、VはValueです。Queryは探索対象、Key-Valueは探索の元データで、探索用途のKeyと本体のValueに分離することでより高い表現力を得ることができます。3。Query、Key、Valueおよび出力は全てベクトルで、出力はValueの重み付き和として計算されます。各Valueに割り当てられる重みは、Queryと対応するKeyの類似度から計算されます。類似度の計算式はこちらです。
$$Attention(Q, K, V ) = softmax\Bigl(\frac{QK^T}{\sqrt{d_k}}\Bigr)V$$
QueryとKeyの要素毎の内積を算出してSoftmaxで正規化します。内積をそのまま正規化するとQueryとKeyの次元数$d_k$が大きくなるほどSoftmaxのlogitが飽和してしまう為、$\sqrt{d_k}$で除算することで勾配消失を防ぎます。このようにしてQueryに関する情報をKeyとの関連度から検索して、翻訳に反映させます。
では次に、この仕組みで作られた2種類のAttentionについて、具体例を用いて説明します。
Source-Target型Attention
Source-Target型Attentionは、seq2seqと同じくエンコーダ・デコーダ構造を持ちます。Transformerのデコーダ側で実装されており、Queryはデコーダから、Key-Valueのペアはエンコーダから情報を受け取ります。サンプルを使って説明します。

ここでは、2つ目のQueryに着目します。Queryは1つ前のデコーダから、KeyとValueはエンコーダから同じ単語のベクトル(この 小説 は 人気 です)を受け取り、QueryとKeyベクトルの類似度からValueの重み付き和を算出します。2つ目のQueryは「小説」との類似度が最も高く、それが重視されて出力に「novel」が選ばれます。
Self-Attention
Self-AttentionもQueryとKey-Valueペアで構成されますが、2つの系列から情報を受け取って対応関係を調べるのではなく、1つの系列の中で自身を特徴づける単語を検索します。Transformerではエンコーダとデコーダの初期段階で使われています。サンプルを使って説明します。

Query、Key、Valueは同じ系列の同じ単語ベクトル(この 小説 は 人気 です)を受け取ります。2つ目のQueryベクトル小説に着目すると、類似度が高いKeyは人気と小説です。これらが小説ベクトルの特徴としてValueの重み付け和に反映されます。
以上がTransformerの翻訳におけるAttentionになります。
次は、このSelf-Attentionを画像認識に応用したVision TransformerのAttentionについて説明します。
Query-Key-Valueを用いた画像認識でのAttention(Vision Transformer)
Self-Attention
Vision Transformerは、CNNの畳み込みを用いず Transformerのエンコーダ、つまりはSelf Attentionで画像認識を行うモデルです。では、2次元の画像をTransformerでどのように学習するのでしょうか。

こちらはVision Transformerのアーキテクチャです(図は論文4より)。2次元の画像を学習するには、系列データへの変換が必要なため、下記の処理を施しています。
- 画像をP×PのN枚のパッチに分割する
- パッチを1次元に平坦化し、線形射影でTransformerが扱う潜在ベクトルと同次元に埋め込む
- パッチに画像の位置情報を付与する
このようにして、Self-AttentionのQuery、Key、Valueにパッチのベクトルが渡されます。計算はTransformerと同じです。サンプルをご覧ください(photo-ac フリー素材使用)。

2つ目のQueryベクトル刺身に着目すると、類似度が高いKeyは5つ目のしょうゆ皿と3つ目の箸、そして刺身です。これらが刺身ベクトルの特徴として重み付き和に反映されます。
まとめ
今回は、各分野でのAttention機構の使われ方について、図解しました。
SEブロックのようなコンポーネントとして便利に使える一方で、Attentionだけでネットワークを構成することも可能で、とても汎用性の高い技術だとわかりました。
中でも、Self-Attentionの自らを特徴づける機能が興味深く、Transformerの後継モデルについても引き続き調べてみたいと思います。
また、今回取り上げることができませんでしたが、Transformerはその計算効率の高さも魅力です。機会があれば、Transformerの記事も書いてみたいです。
最後に宣伝
Supershipではプロダクト開発やサービス開発に関わる人を絶賛募集しております。
ご興味がある方は以下リンクよりご確認ください。
Supershipグループ 採用サイト
是非ともよろしくお願いします。
![]()
参照
ブログ
- 《日経Robo》自己注意機構:Self-Attention、画像生成や機械翻訳など多くの問題で最高精度
- 深層学習入門:画像分類(5)Attention 機構
- ILSVRC 2017 画像分類 Top の手法 Squeeze-and-Excitation Networks
- 作って理解する Transformer / Attention
- ざっくり理解する分散表現, Attention, Self Attention, Transformer
- 深層学習界の大前提Transformerの論文解説!
- 論文解説 Attention Is All You Need (Transformer)
- 画像認識の革新モデル!脱CNNを果たしたVision Transformerを徹底解説!
- 画像認識の大革命。AI界で話題爆発中の「Vision Transformer」を解説!
- Transformer で画像認識をやってみる ~ Vision Transformer ~ | GMOインターネットグループ 次世代システム研究室
You Tube
- Deep Learning入門:Attention(注意)
- 【深層学習】Attention - 全領域に応用され最高精度を叩き出す注意機構の仕組み【ディープラーニングの世界 vol. 24
- 【深層学習】SENet - 「圧縮興奮機構」による性能向上【ディープラーニングの世界 vol. 19】
書籍
-
論文『Squeeze-and-Excitation Networks』(Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu)
CNNの一種ResNetで得られた特徴量マップに対し、SEブロックでGlobal Average Poolingを適用して、幅・高さ・チャネルを1×1×チャネル数に変換し、チャネル毎の代表値を算出します。それに2層の全結合層と非線形処理を適用して、どこのチャネルに注目すべきかを選びます。 ↩ -
論文『Attention Is All You Need』(Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin) ↩
-
Key-Valueモデルの説明はこちらのブログ(『自然言語処理の必須知識 Transformer を徹底解説!』)が詳しいです。 ↩
-
論文『An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale』(Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby) ↩