はじめに
- 自己紹介 : Pythonでデータ分析とかNLPしてます。
- Attention, Self Attention, Transformerを簡単にまとめます。
- 間違いがあったらぜひコメントお願いします。
モチベーション
- BERT(Google翻訳で使われてる言語モデル)を理解したい。
- BERT : 双方向Transformerを用いた言語モデル。分散表現を獲得でき、様々なタスクに応用可能。
- Transformer : Self Attentionを用いたモデル。CNNとRNNの進化系みたいなもの。
- Self Attention : Attentionの一種。
- Attention : 複数個の入力の内、どこを注目すべきか学習する仕組み。
- 分散表現 : 文・単語・文字等を、低次元(100〜1000次元くらい)のベクトルで表現したもの。
- BERTを理解するためには分散表現, Attention, Self Attention, Transformerを理解する必要が有る。
Organization
- 以下の流れで説明を進めます。(BERTの説明はしません)
- 分散表現
- Attention
- Transformer
分散表現
- 文・単語・文章等を、「スパースでなく、低次元(100〜1000次元くらい)」のベクトルで表現したものです。
- 記事が長くなったのでこちらに分けました。
Attention
- 複数個の入力の内、どこを注目すべきか学習する仕組みの事です。
- まずAttentionの歴史と基本的な構造を説明し、その後派生系を紹介します。
Attentionの歴史 -seq2seqと組み合わせて機械翻訳-
- Attentionが注目を浴びたのは、seq2seqと組み合わせたモデルが機械翻訳で良い成績を残したからです。
- 既存のseq2seqは、EncoderRNNの最終time stepのhidden stateのみをDecoderに渡していました。
- Attentionモデルでは、Encoderの全てのhidden stateを用います。
- 「Encoderの各hidden stateの内、どこに注意を向けるか」を表現しているため、Attentionと呼ばれます。
- 従来のseq2seqと、Attentionを組み合わせたモデルの違いを図示します。
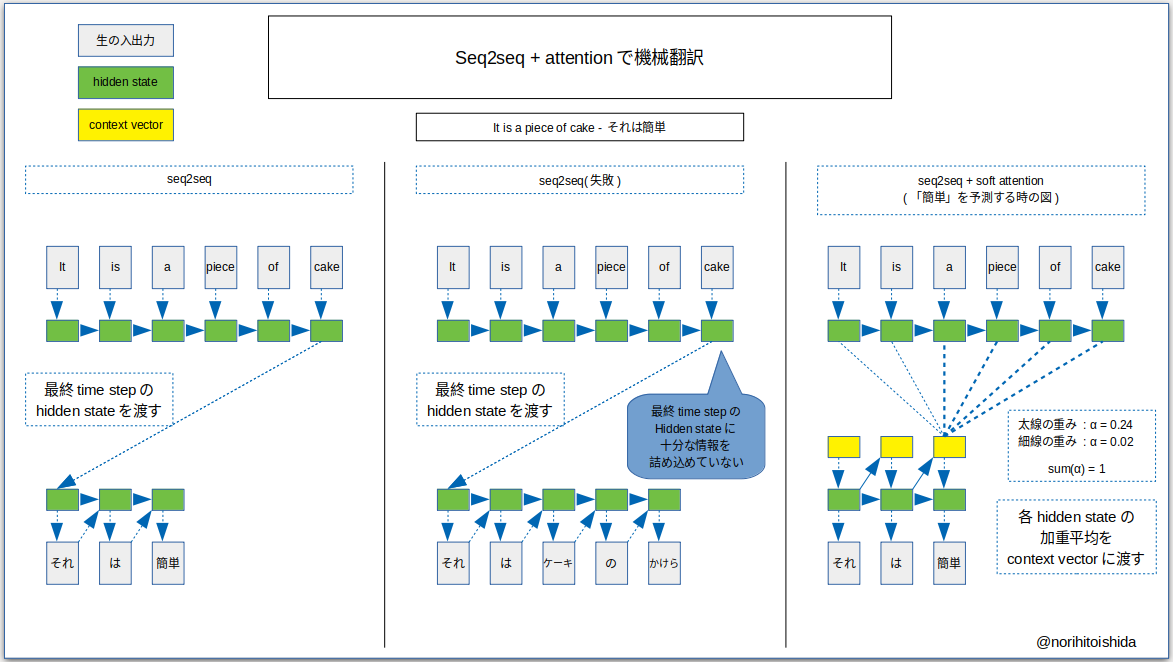
- 上図では「It is a piece of cake」を「それは簡単」に変換しようとしています。
- 左カラムは既存のseq2seqでの成功例です。
- 中央カラムは最終time stepのhidden stateにうまく情報が詰め込めておらず、翻訳に失敗しています。
- 上図の右カラムは「簡単」を出力しようとしている時の図です。
- 「a」「piece」「of」「cake」に注意を向けています。
- Encoderの全てのhidden stateの加重平均とDecoderの前time stepのhidden stateを元に、context vectorを計算します。
- それを用いて現time stepのhidden stateを計算し、出力を生成します。
- このモデルのよい所は、「入力の中でキーワードがどれだけ離れていても、情報を拾える」という点です。
- RNNの「time stepが進むに連れて、情報が失われる」という弱点を克服できています。
Attentionの構造
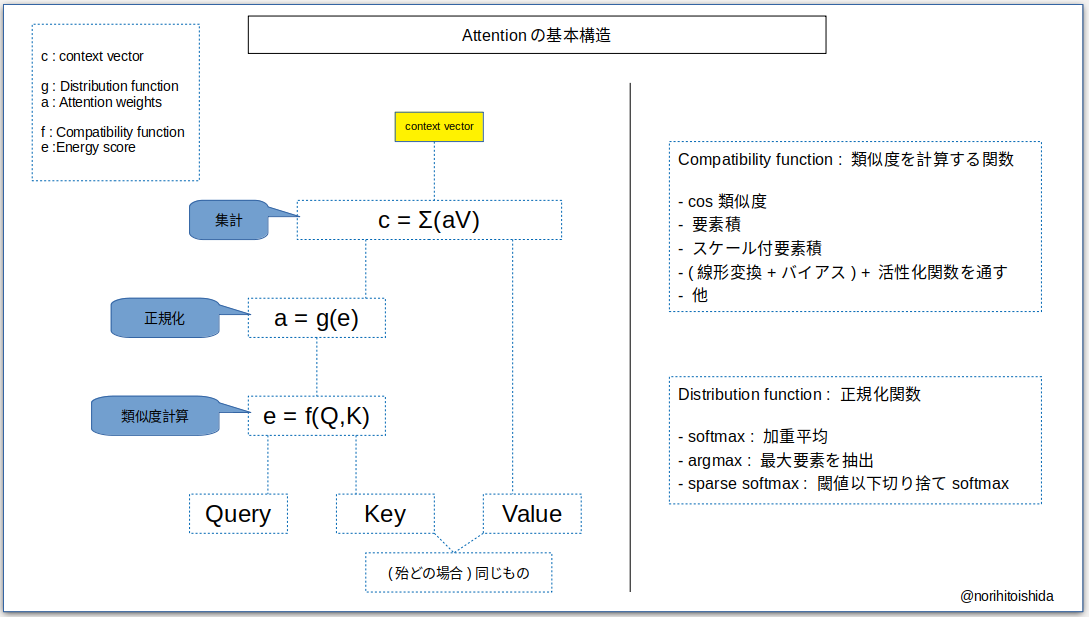
- Attentionのキーワードは「Query」「Key」「Value」です。
- Query : 「これに関係するものは何か」を知りたい要素です。
- 上記の例で言えば「簡単」の1つ前の「は」のhidden stateがqueryです。
- Key : 「これらの中のどれに注意を向ければよいか」を知りたい要素です。
- 上記の例で言えばEncoderの全てのhidden stateです。
- Value : 多くの場合Keyと同じ要素です。queryとkeyから計算した重みを掛けるために使われます。
- Attentionの計算は次のような手順で行われます。
- queryとkeyのエネルギーe(類似度、重要さ)をCompatibility functionで計算します。
- eをDistribution functionで正規化し、Attention weights aを計算します。
- aとValueの各要素の積を取り、context vectorを計算します。
- 上記のタスク(「It is a piece of cake」→「それは簡単」の「簡単」を生成するステップ)を可視化します。
- hidden stateは100次元とします。
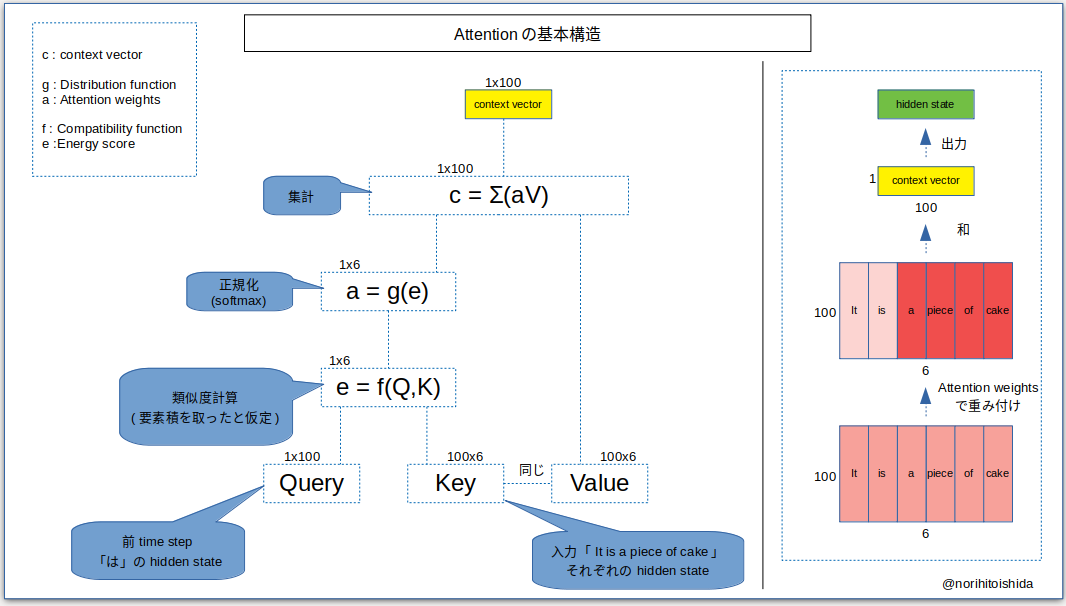
- 以上の手順で、「は」の次の単語に関係がありそうなのは「a」「piece 」「of」「cake」だという事がわかります。
Attentionの分類 (1) Compatibility function (類似度計算)
- 類似度を測る指標として様々なMetricが用いられています。
| Metric | 式 | メリット | Reference |
|---|---|---|---|
| dot-product | $q^{T}K$ | 計算量軽 | Luong et al., 2015 |
| additive | $act(W_{1}K+W_{2}q+b)$ | q,Kの次元が合って無くてもOK | Bahdanau et al., 2015 |
| general又は bilinear |
$q^{T}WK$ | q,Kの次元が合って無くてもOK | Luong et al., 2015 |
| scaled dot | $\frac{q^{T}K}{\sqrt{d_{k}}}$ | 計算量軽 softmaxの勾配消失対策 |
Vaswani et al., 2017 |
- Transformerで用いられているのはscaled dotです。
- スケール係数を掛ける事で勾配消失を軽減し、層を深くする事が可能になっています。
- $act$は活性化関数です。$tanh$, ReLU, SELUなど様々な手法が試されています。
Attentionの分類 (2) Distribution function (重み計算)
- エネルギーeを正規化してAttention weights aに変換する手法を紹介します。
- aの和は1になります。
| 手法 | 特徴 | メリット | Reference |
|---|---|---|---|
| soft attention | softmax | 微分可能 | Luong et al., 2015 |
| hard attention | argmax | 推論時計算量軽 | Xu et al., 2015 |
| local attention | argmaxの付近を見る | softとhardのいいとこ取り | Luong et al., 2015 |
| sparse softmax | 閾値以下切捨て+softmax | ノイズ除去 | Martins & Astudillo, 2016 |
- Transformerで用いられているのはsoftmaxです。
- argmaxは微分不可なので誤差逆伝播法が使えません。(方策勾配法や変分法を使う)
Attentionの分類 (3) Multiplicity (多重度)
- 入出力の系統数・次元数のことをMultiplicity (多重度)といいます。
| 手法 | 特徴 | Reference |
|---|---|---|
| Self | Q,K,Vが全て同じ |
Cheng et al., 2016 Parikh et al., 2016 |
| Co | 複数入力 | Lu et al., 2016 |
| Multi-Head | 複数attentionを並列計算、結合 | Vaswani et al., 2017 |
| Label-wise | クラスごとに注意分布を計算 | Barbieri et al., 2018 |
- Transformerで用いられているのはSelf AttentionとMulti-Head Attentionです。
- co-attentionの例 : 提示した写真に関する質問をするVisual Question Answering等。
- Self Attentionを用いる事で、自分自身のどの部分に注目すればよいかわかります。
- 例えば、以下のようなQ&Aタスクがあるとします。
- 「私はトムの部屋に入りました。(略)。彼の部屋を出ました。この『彼』とは誰?」
- この時、文中で彼〜トムの距離が遠ければどうなってしまうでしょうか。
- CNNでは畳み込めないため、「彼=トム」の情報を手に入れられません。
- RNNでは距離が遠すぎるため、「部屋の主=トム」の情報を忘れてしまう可能性があります。
- Self Attentionならば、彼とトム間のAttention weightを大きくする事で「彼=トム」と理解出来ます。
- Self Attentionは簡単に言うと「離れた所も畳み込めるCNN」の様なものです。
- (あくまでイメージです。詳細は論文を読んで下さい)
- 例えば、以下のようなQ&Aタスクがあるとします。
Transformer
- Transformerを簡単に説明すると、CNNやRNNの進化系です。
- 並列に計算できるRNN
- 離れた所も畳み込めるCNN
- その代わりメモリ消費量が大きくなった
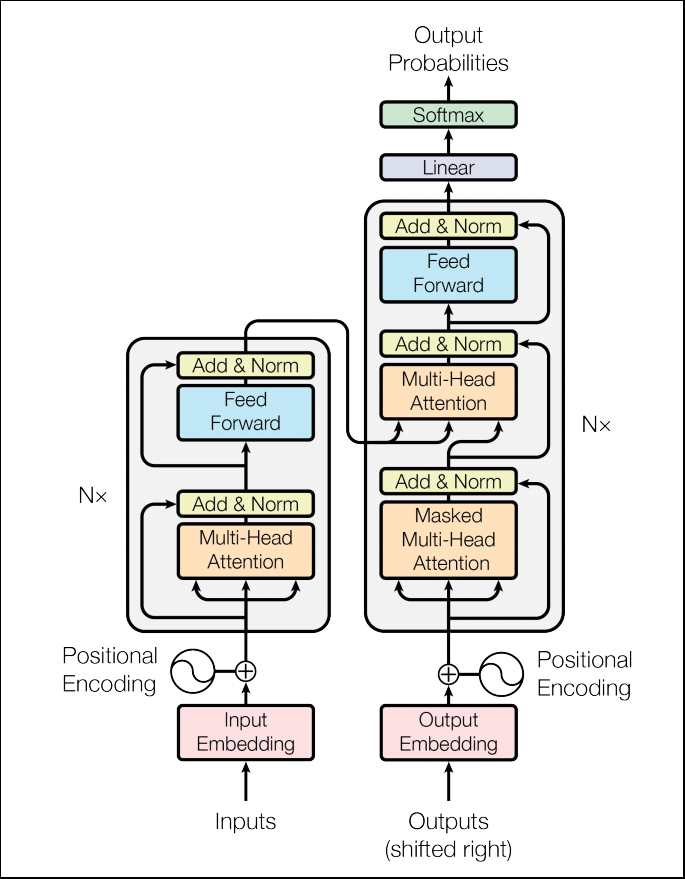
- Transformerの概観図です。(元論文より引用)
- Transformerの全てのhidden stateは$d_{model}=512$次元です。
- これは途中にResidual connectionが入り、次元を揃えておくほうが効率が良いためです。
- Transformerの理解のために、以下のコンポーネントを説明します。
- Position Encoder
- Self Attention
- Multi-Head Attention
- Scaled Dot-Product Attention
- Masked Multi-Head Attention
Position Encoder
- 上記で、TransformerではSelf AttentionとMulti-Head Attentionを使用していると説明しました。
- また、Self Attentionに「離れた所も畳み込めるCNN」の様な性能があると説明しました。
- ではなぜ「並列に計算できるRNN」の様な性能があるのでしょうか?
- その理由は「Position Encoder」という仕組みに有ります。
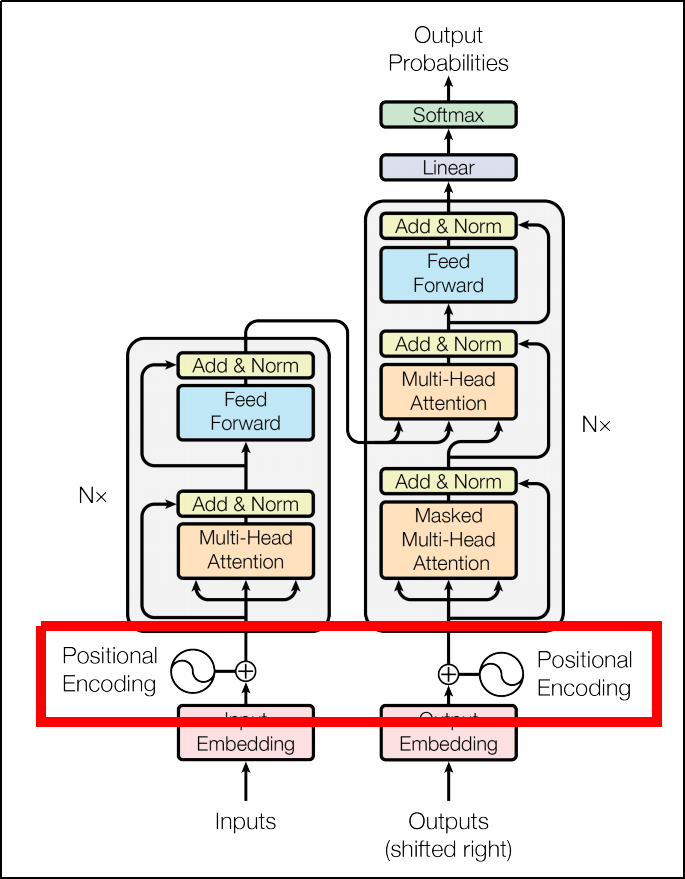
- 文などのシーケンシャルなオブジェクトは、(当たり前ですが)シーケンシャルにモデルに入力する必要が有りました。
- 各要素に「あなたはN番目」とタグを付ける事で、逐次処理を並列に行おうというアイデアがPosition Encoderです。
- 具体的には、周波数が違うsin関数・cos関数の値を埋め込みベクトルに足すことで、位置情報を与えています。
- 学習・推論を大幅に高速化できる利点がありますが、代わりに大量のメモリを消費してしまいます。
Self Attention
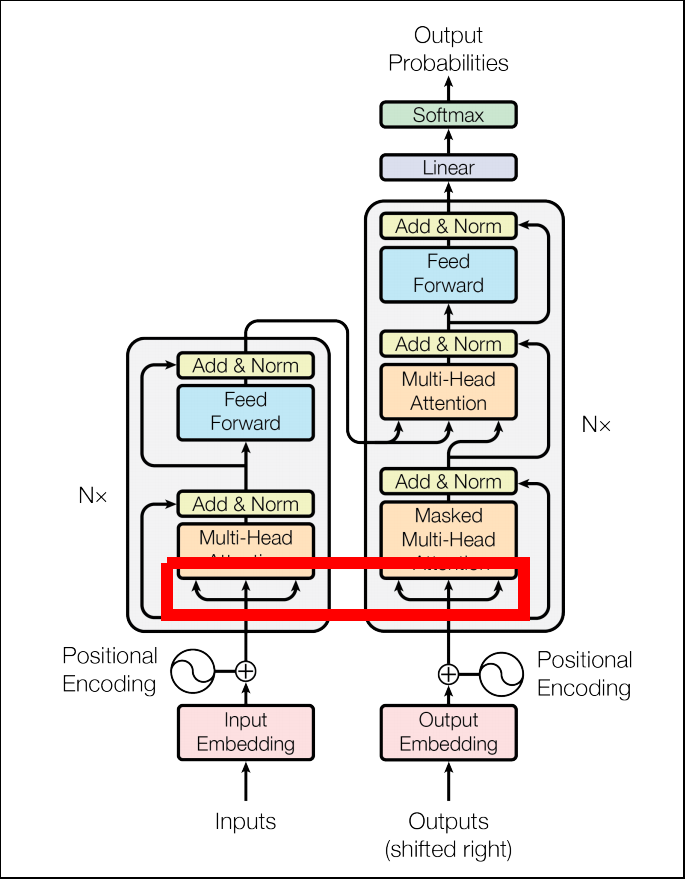
- Attentionの項目で説明した通り、Self Attentionは自分自身の要素間の類似度、重要度を計算する仕組みです。
- Transformerには3種類のMulti-Head Attentionがあります。
- そのうち、EncoderのMulti-Head Attention、DecoderのMasked Multi-Head Attentionに使われています。
- 上記の例で言うと、「a piece of cake」がお互いに重要度が高い、と認識しておく事が出来ます。
Multi-Head Attention
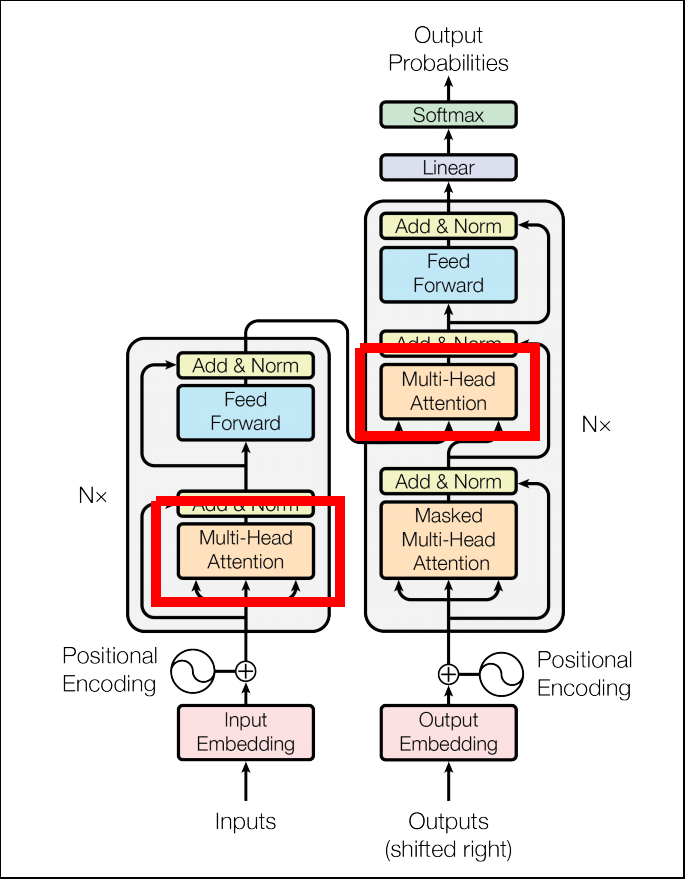
- Attentionの項目で説明した通り、Multi-Head Attentionは並列に複数のattentionを計算、結合する仕組みです。
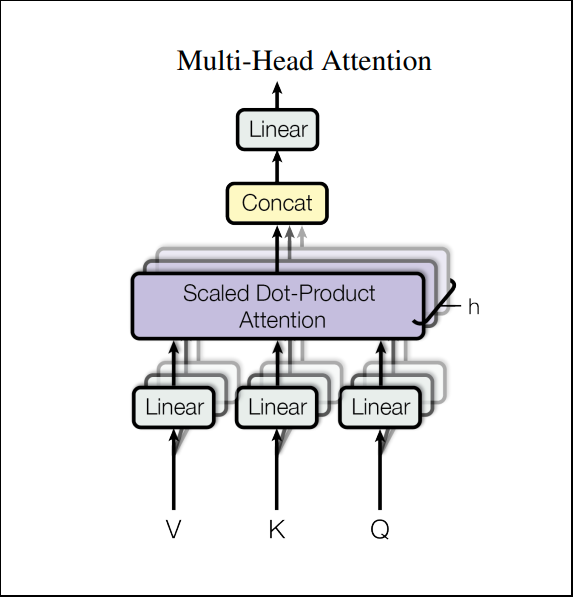
- Transformerでは8個の並列計算を行い($h=8$)、結合時はベクトルをconcatしています。
- Multi-Headにする利点は、それぞれ異なる情報をエンコードできるからです。
- Single-Headでは取りこぼしてしまう情報も、Multi-Headであれば十分にカバーすることが出来ます。
Scaled Dot-Product Attention
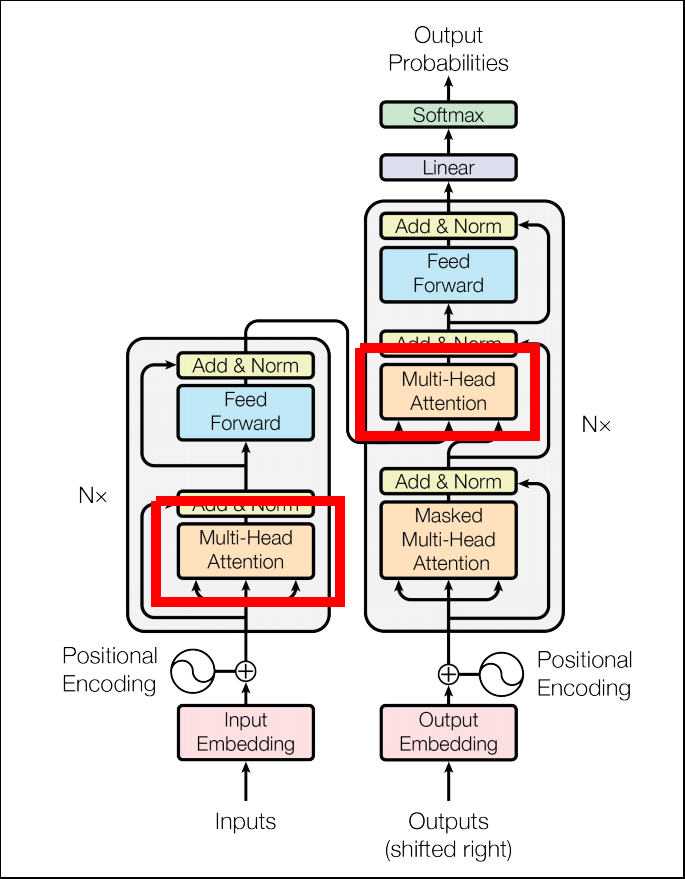
- Attentionの項目で説明した通り、類似度計算のためのCompatibility functionには種類が有ります。
- TransformerではScaled Dot-Product Attentionを使用しています。
- Dot-Product Attentionは計算量が軽いメリットがありますが、Keyの次元が大きいとsoftmaxの勾配が消失してしまいます。
- そこで、全体を$\sqrt{d_{k}}$で割ることでスケールし、勾配消失を軽減しています。
Masked Multi-Head Attention
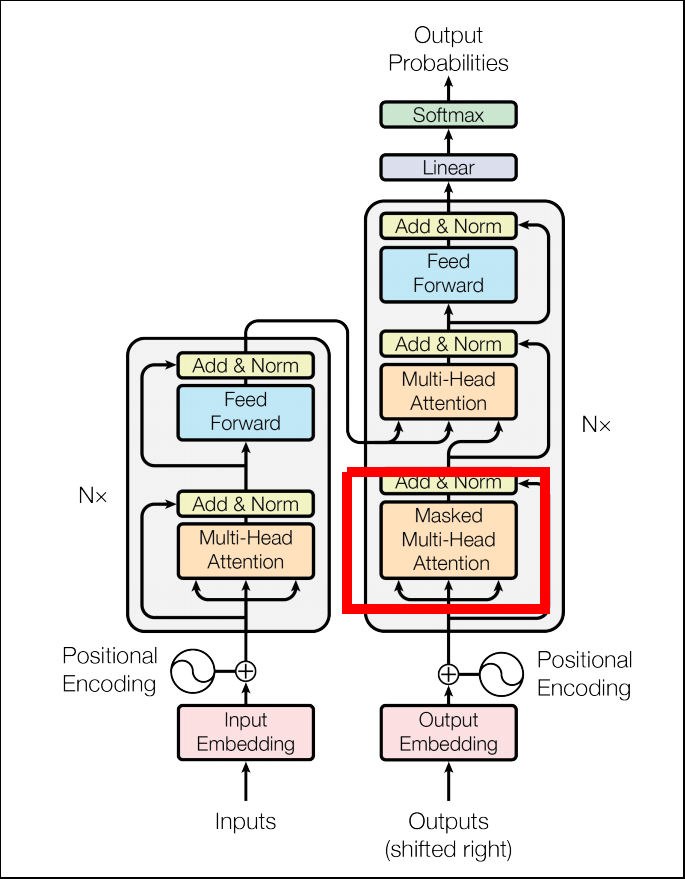
- Position Encoderを使うことによって、未来の情報を受け取ってしまうことになります。(leak)
- そこで未来の情報を隠してleakを防ぐという仕組みです。
- 具体的にはエネルギーeを$-\infty$にして、softmaxを取った際にAttention weightが0になるようにします。
Transformer全体の構造
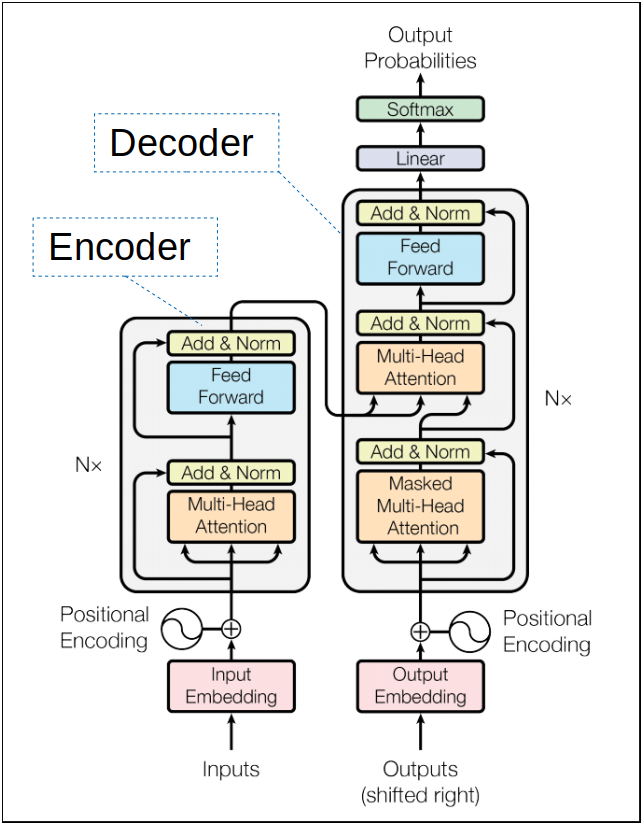
- Transformerでは上で紹介したMulti-Head Attention等の後にFFNNが使用されています。
- 上記のEncoderとDecoderが6層ずつ積み重なっています。
- よって、実際のEncoderの挙動は以下のようになります。
- Embeddingレイヤによって入力を512次元に圧縮
- Position Encoderレイヤによって位置情報を付加
- Multi-Head AttentionでSelf Attentionを計算
- residual connectionと要素和を取り、Layer normで正規化
- FFNNで変換
- residual connectionと要素和を取り、Layer normで正規化
- 3〜6を6層繰り返す
- Decoderの挙動は以下のようになります。
- Embeddingレイヤによって入力512次元に圧縮
- Position Encoderレイヤによって位置情報を付加
- Masked Multi-Head AttentionでSelf Attentionを計算
- residual connectionと要素和を取り、Layer normで正規化
- その出力をqueryに、Encoderの出力をKeyとValueにしてMulti-Head AttentionでAttentionを計算
- residual connectionと要素和を取り、Layer normで正規化
- FFNNで変換
- residual connectionと要素和を取り、Layer normで正規化
- 3〜8を6層繰り返す
- 線形変換+softmaxで各ラベルの予測確率を計算
記事を書いた感想
- 私の知る限り日本語で一番丁寧にTransformerを解説しているRyobotさんのテックブログより易しく書こうと思ったら非常に長くなってしまいました。
- Multi-Headがキチンとそれぞれ別の情報をエンコードしてくれるのかな…?と思いました。(定性的な可視化しかしていないので)
- と思ったらこちらの論文Multi-Head Attention with Disagreement Regularization(Li et al., 2018)で「disagreement regularization」というものが提案されていました。
- 「(最大化したい)目的関数にヘッドの出力間のcos類似度を組み込む」等、各Headが別の情報をエンコードする工夫がなされています。賢いな〜