はじめに
最近、KaggleでTabnetというニューラルネットワークモデルが流行っていると知りました。
テーブルデータコンペといえばGBDT最強のイメージでしたが、ここでもニューラルネットワークモデルが台頭しつつあるようです。そこで今回は、Tabnetについて
- どんな嬉しさがあるのか
- どのように使うのか
という観点から、論文の要点とリポジトリの使い方について調べてみました。
Tabnetとは
概要
Tabnetは、テーブルデータ向けのニューラルネットワークモデルです。
決定木ベースのモデルの解釈可能性を持ちつつ、 大規模なテーブルデータに対して高精度な学習が可能です。
特徴量の作成を必要としないエンドツーエンドの学習モデルです。
リファレンス
論文
Tabnetの論文は、Google Cloud AIチームによって発表されました。
TabnetはGoogle Cloud AI Platform の組み込みアルゴリズムとして提供されています。
リポジトリ
論文をベースに開発された非公式のリポジトリがあります。
pytorchで実装されていて、コンペでよく使われます。pipやpoetryからインストール可能です。
今回は、このリポジトリの使い方を紹介します。
論文のポイント紹介
では、Tabnetがどんな目的で作られ、どんな特徴を持つのか、論文からポイントを絞ってご紹介します。
1. Tabnetの狙い
近年、テーブルデータでは決定木ベースのモデルが成功を収めてきました。
これは、テーブルデータによくある超平面の境界を持つ決定多様体に対して表現上の効率が良いこと、解釈可能性が高いこと、トレーニングが速いことに起因します。
一方、深層ニューラルネットワーク(DNN)のエンドツーエンドの学習がうまくいくと、次のような利点があります。
- 大規模データセットでのパフォーマンス向上
- 表形式に加えて、画像など複数のデータタイプを効率的に符号化できる
- 特徴量エンジニアリングの必要性を軽減できる
- ドメイン適応、生成的モデリングなど、多くのアプリケーションシナリオを適用できる表現学習を可能にする
そこで、決定木ベースとDNNの利点を取り入れたアーキテクチャとして、TabNetが提案されました。主な貢献は下記の通りです。
主な貢献
- 前処理なしで、勾配降下法に基づく最適化によりエンドツーエンドの学習が可能
- 各決定ステップで特徴を選択するために逐次注目を使用。インスタンスごとに最も顕著な特徴に学習能力を使うため、効率的な学習が可能
- 選択マスクの視覚化によってより解釈しやすい意思決定が可能
- 様々なドメインの分類および回帰問題のデータセットで、他の学習モデル以上の精度を記録
- 教師なしの事前学習でマスクした特徴の予測を行い、大幅に性能を向上
2. 特徴
上記を踏まえて、Tabnetの特徴を5つご紹介します。
2.1. どのように事前学習するか
下は事前学習の構成図です。
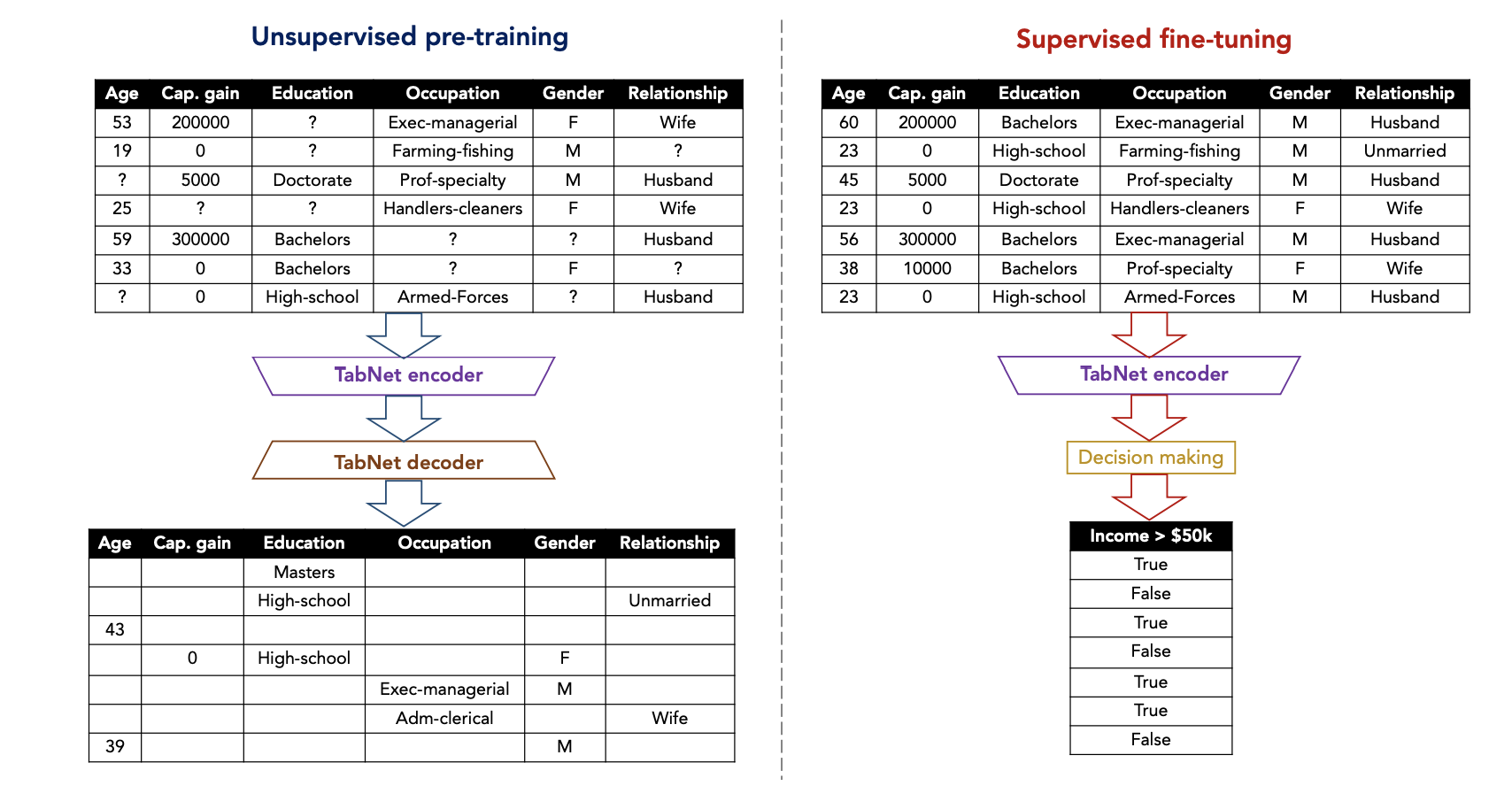
(出典: TabNet: Attentive Interpretable Tabular Learning 1)
左の図のエンコーダ部分で特徴の一部にマスクをして学習し、デコーダ部分でマスクの予測を行わせて事前学習をします。その後、右の本学習で、事前学習で得た重みを用いて転移学習をします。
2.2. どのように決定木を模倣しているのか
下は決定木の模倣のコンセプト(左)と対応する決定多様体(右)です。
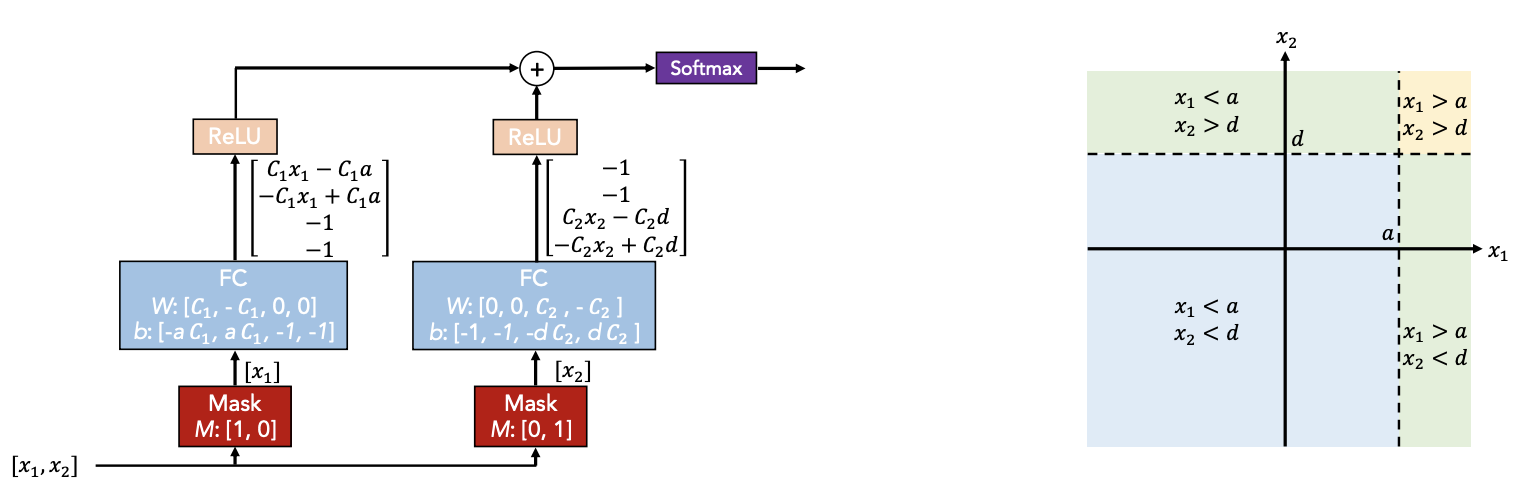
(出典: TabNet: Attentive Interpretable Tabular Learning 1)
DNNの構成要素を用いて決定木モデルを模倣しています。
図では、二つの特徴量からマスクで特徴を選択し、各特徴に線形変換と非線形処理を加えて決定領域を選択してます。選択した複数の領域を加算により線形結合的に集約します。
2.3. 逐次注目の仕組み
下は全体の構成図です。上段がエンコーダとデコーダ、下段がパーツの構成図になります。
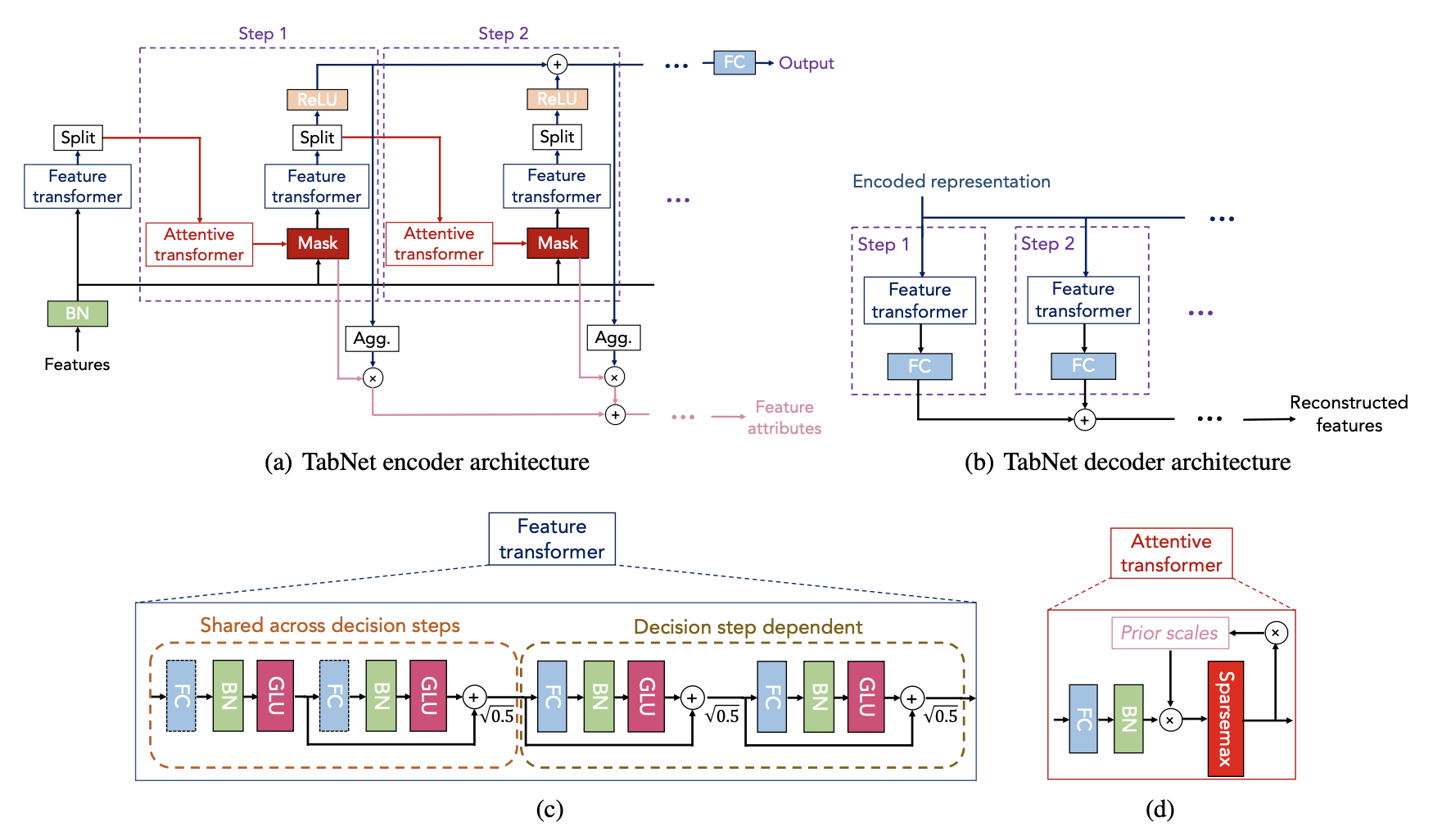
(出典: TabNet: Attentive Interpretable Tabular Learning 1)
左上の図にstep1、step2とあるのが各決定ステップです。ユーザーが指定した回数分、実行します。
前のステップで処理された特徴にAttentionを適用してマスクを取得し、各決定ステップでどの特徴を推論するかを選択します。最も顕著な特徴をインスタンスごとに選択するため、モデルのパラメータ効率が向上します。
2.4. 解釈可能性の高さ
各決定ステップで取得したマスクをグラフとして出力できます。
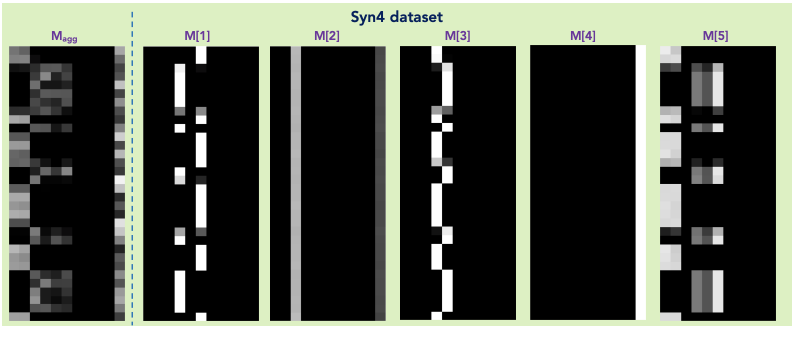
(出典: TabNet: Attentive Interpretable Tabular Learning 1)
上図の右5つはi番目の決定ステップのマスク、左は全てのマスクを集計したものです。
マスクの横軸はステップで使用した特徴量、縦軸はデータの各行です。色の濃淡が重要度を表していて、色が白いほど重要度が高くなります。
例えば、M[4]では一番右の列が全て白くなっていますが、これは「ステップ4では、一番右の特徴量が全てのデータにとって重要だった」ということを表しています。
2.5. 精度の高さ
論文では、現実の複数のデータセットについて決定木ベースや他のニューラルネットワークモデルと比較実験をしています。
実験の結果を見ると、Tabnetは全てのケースで他のモデルと同等以上の精度を出しています。
【実験されたタスク】
分類、回帰、ルールベース優位、モデルサイズが小さいケース、
属性と時系列データを使った売上予測など
Tabnetの使い方
次に、非公式リポジトリの実装例に沿って使い方を説明します。実装例は複数あるので用途に合わせて選んでください(以下は事前学習の実装例)。
1. 使用する機能の紹介
1.1. 前処理
事前にカテゴリー特徴量の数値変換とnull補完が必要です。
実装例では、カテゴリー特徴量をデータ型とユニーク数で識別しているので、必要に応じて変更をします。
# Simple preprocessing
nunique = train.nunique()
types = train.dtypes
categorical_columns = []
categorical_dims = {}
for col in train.columns:
if types[col] == 'object' or nunique[col] < 200:
print(col, train[col].nunique())
l_enc = LabelEncoder()
train[col] = train[col].fillna("VV_likely")
train[col] = l_enc.fit_transform(train[col].values)
categorical_columns.append(col)
categorical_dims[col] = len(l_enc.classes_)
else:
train.fillna(train.loc[train_indices, col].mean(), inplace=True)
# Define categorical features for categorical embeddings
features = [col for col in train.columns if col not in unused_feat+[target]]
cat_idxs = [i for i, f in enumerate(features) if f in categorical_columns]
cat_dims = [categorical_dims[f] for i, f in enumerate(features) if f in categorical_columns]
なお、実装例の下記の箇所は、train[col].fillna とカラム指定すべき所が抜けているので、注意が必要です。
train.fillna(train.loc[train_indices, col].mean(), inplace=True)
1.2 学習(分類、回帰)
scikit-learnに似た形式で簡単に設定できます。分類と回帰で異なるクラスが用意されています。
from pytorch_tabnet.tab_model import TabNetClassifier, TabNetRegressor
clf = TabNetClassifier() #TabNetRegressor()
clf.fit(
X_train, Y_train,
eval_set=[(X_valid, y_valid)]
)
preds = clf.predict(X_test)
1.3. 事前学習
事前学習を行う場合、本学習のfrom_unsupervisedというパラメータに事前学習のモデル(ここではunsupervised_model)を設定します。
# 事前学習
unsupervised_model = TabNetPretrainer(
optimizer_fn=torch.optim.Adam,
optimizer_params=dict(lr=2e-2),
mask_type='entmax' # "sparsemax"
)
unsupervised_model.fit(
X_train=X_train,
eval_set=[X_valid],
pretraining_ratio=0.8,
)
# 本学習
clf = TabNetClassifier(
optimizer_fn=torch.optim.Adam,
optimizer_params=dict(lr=2e-2),
scheduler_params={"step_size":10, # how to use learning rate scheduler
"gamma":0.9},
scheduler_fn=torch.optim.lr_scheduler.StepLR,
mask_type='sparsemax' # This will be overwritten if using pretrain model
)
clf.fit(
X_train=X_train, y_train=y_train,
eval_set=[(X_train, y_train), (X_valid, y_valid)],
eval_name=['train', 'valid'],
eval_metric=['auc'],
from_unsupervised=unsupervised_model
)
1.4. パラメータ
各種パラメータはリポジトリにまとめられています。
Tabnetに前処理を任せる場合、カテゴリー特徴量をembedding加工するための cat_idxs, cat_dims, cat_emb_dimの設定が必要なので、ご留意ください。
2. コードサンプル
KaggleのTitanicをTabnetで試してみました。LightGBMも同じ条件で作成しています。
Titanic: Comparison of Tabnet and Lightgbm
実装例とパラメータの説明を参考にすれば、設定に不自由はありません。個人的にはカテゴリー特徴量の取り扱いの理解に少し時間がかかりました。
3. LightGBMとの比較
上記のTitanicの2つの実験結果を比較します。対象は精度と特徴重要度です。
実験条件
Tabnetは事前学習を行い、LightGBMのパラメータは初期設定で実験しました。
交差検証はStratified 5-fold、Out of Foldは交差検証に準じます。LBはtestデータの5-foldの予測確率を平均し、閾値を0.5にしてます。
CPUで実行し、Tabnetの実行時間には事前学習も含めました。
結果: 精度と時間
Out of FoldではLightGBM、LBではTabnetの方が高い精度となりました。
CPUではTabnetの方が大幅に時間がかかりました。
| 項目 | Tabnet | LightGBM |
|---|---|---|
| OOF ROC-AUC | 0.8554 | 0.8786 |
| OOF Accuracy | 0.8103 | 0.8305 |
| LB Accuracy | 0.7703 | 0.7631 |
| Time(s) | 91.3 s | 1.2 s |
結果: 特徴量重要度
左がTabnet、右がLightGBMです。
Tabnetはカテゴリー特徴量、LightGBMはFareとAgeが上位に入りました。LightGBMは上位2つに偏っています。論文では特徴量重要度の度合いや並び順は他のモデルと似ているとありましたが、今回は大きく異なりました。
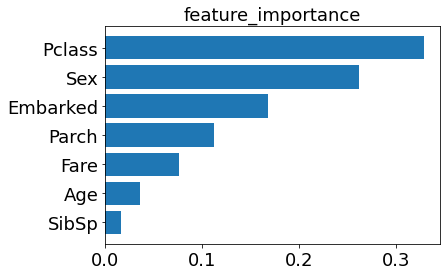
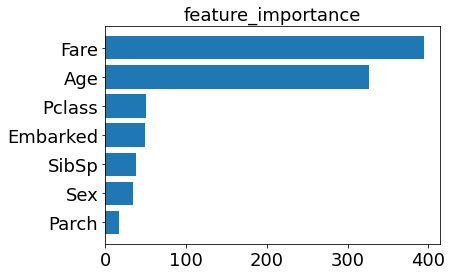
(左図: Tabnet、 右図: LightGBM)
ちなみに、Tabnetのマスクはこんな感じでした。
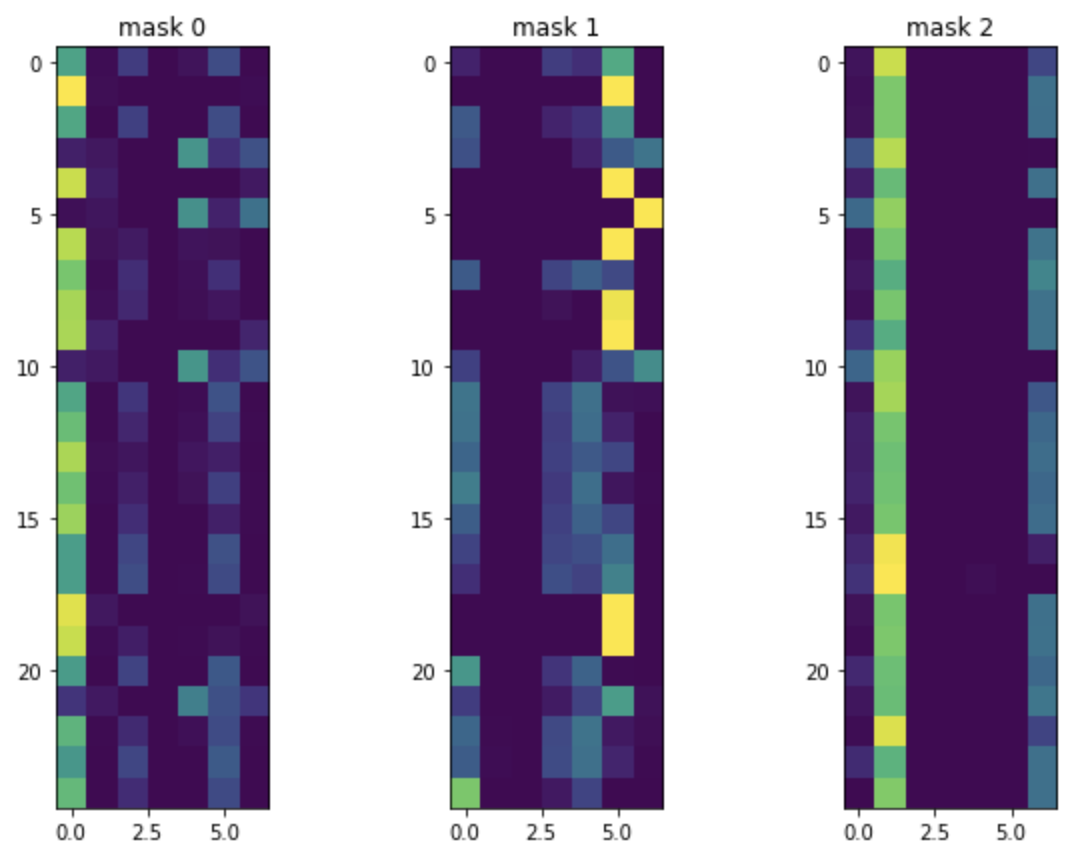
左から Pclass, Sex, Age, SibSp, Parch, Fare, Embarkedの順です。
PclassとSexと右端のEmberkedの色が反転しているのがわかります。
まとめ
今回は論文のポイント紹介と、TabnetとLightGBMの比較実験を行いました。
論文の主張通り、特徴量作成なしにエンドツーエンドで学習ができること、予測精度はLightGBMに匹敵することが確認できました。
これにより、前処理の負担が軽減されたり、画像など複数のデータタイプと効率的に符号化できたりなど、多くの利点が想定されます。テーブルデータ学習の分野での技術革新が期待でき、とても楽しみです。
反面、事前学習を含めた実行時間は、CPU環境ではLightGBMに遠く及びません。
特徴量重要度の相違については、データ依存の問題なのか、前処理やアルゴリズムによる違いなのか、知りたい所です。
GPUでどの程度改善するか、特徴量重要度の相違が何に起因するのか、機会があれば試してみたいと思います。
参照
- TabNetとは一体何者なのか?
- 【kaggle】TabNetの使い方
- TabNetを使えるようになりたい【追記①lgbmとstacking(ちょっと上がる)】
- TabNetを頑張って調べて見たりする遊び(1/2)
- PyTorchでのTabNetの実装
- 勾配ブースティング決定木ってなんぞや
- 勾配降下法ってなんだろう