Pandasで表を抽出したいがraise ValueError("No tables found") ValueError: No tables foundが出る
解決したいこと
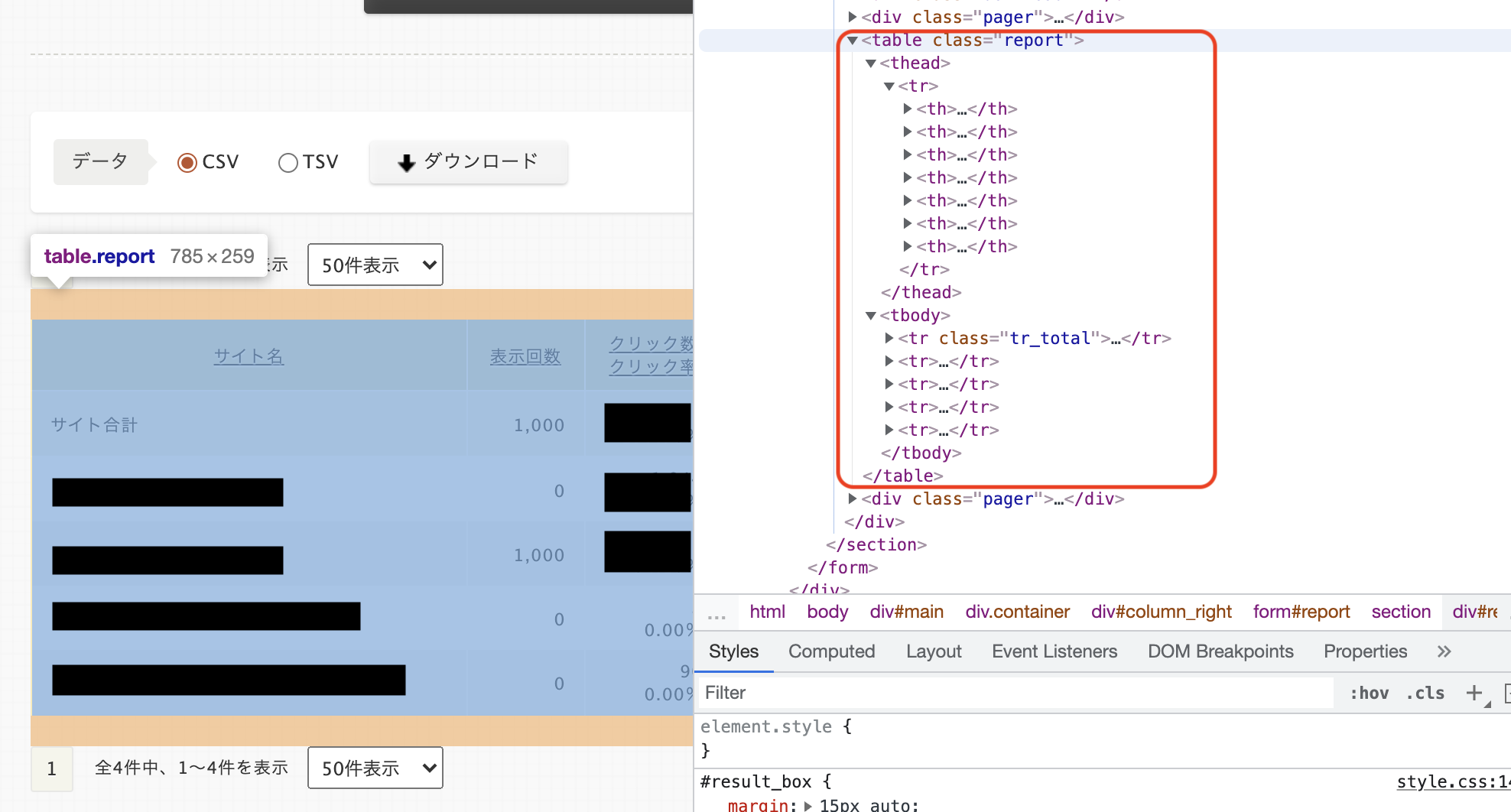
pandasを使って表示されているページの以下の表を取得したいです。
tableがあるのにtableがないとのエラーが表示されてしまいます。
解決方法を教えてください。

発生している問題・エラー
raise ValueError("No tables found")
ValueError: No tables found
該当するソースコード
#レポートを抽出
reportlist2 = driver.find_element_by_xpath("/html/body/div[2]/div/div[2]/form/section/div[3]/table")
print(reportlist2.text)
import pandas as pd
cur_url = driver.current_url
dfs = pd.read_html(cur_url)
print(len(dfs))
print(dfs[0].head())
自分で試したこと
他のサイトでpandasでの表の抽出は以下のコードで成功しています。
同様の考え方で取得してみたのですがうまくいきません。
import pandas as pd
url = 'https://info.finance.yahoo.co.jp/ranking/?kd=4'
dfs = pd.read_html(url)
print(len(dfs))
print(dfs[0].head())
該当ページはログインが必要で、seleniumを使用してたどり着いております。
また、cur_url = driver.current_urlで該当ページのURLは取得できております。
以下のコードで表の中身を取得することはできたのですがpandasでも取得できるようになりたいと考えておりますので何かヒントなどあればよろしくお願いいたします。
reportlist2 = driver.find_element_by_xpath("/html/body/div[2]/div/div[2]/form/section/div[3]/table")
print(reportlist2.text)
0 likes