はじめに
XenonPyのチュートリアルのVisualizationについて解説します。
- XenonPyの概要とチュートリアルの一部(Sample dataとData access)の解説についてはこちら
- XenonPyのチュートリアルのDescriptor calculationの解説についてこちら
※マテリアルズインフォマティクス関係の内容を他にも投稿していますので、よろしければこちらの一覧から他の投稿も見て頂けますと幸いです。
可視化
公式ドキュメントの"Visualization"に沿って解説します。
環境
- conda 4.9.2
- python 3.7.1
- xenonpy 0.4.4
Descriptor heatmap(ヒートマップによる可視化)
記述子と目的とする特性の相関を理解するために、記述子はヒートマップを用いて可視化することができます。composition(組成に関する情報)を記述子とし、density(密度)を目的特性として以下で可視化の方法を説明していきます。コードの詳細は後述しているので参考にして下さい。
まずは記述子を計算(生成)していきます。サンプルデータの取得に関してはこちらの投稿を参考にして下さい。
from xenonpy.datatools import preset
from xenonpy.descriptor import Compositions
samples = preset.mp_samples
cal = Compositions()
descriptor = cal.transform(samples['composition'])
目的特性(density)の値順に記述子をソートしていきます。
# 目的特性を指定
property_ = 'density'
# 欠損値のあるデータを除き(今回のデータに欠損値はない)、目的特性である"density"の小さい順に並べ替える
prop = samples[property_].dropna()
sorted_prop = prop.sort_values()
# densityの小さい順に生成した記述子を並べる
sorted_desc = descriptor.loc[sorted_prop.index]
- .dropna()で欠損値のある行を削除しています
最後にヒートマップを描きます。
from xenonpy.visualization import DescriptorHeatmap
heatmap = DescriptorHeatmap(
bc=True, # use box-cox transform
save=dict(fname='heatmap_density', dpi=200, bbox_inches='tight'), # save figure to file
figsize=(70, 10))
heatmap.fit(sorted_desc)
heatmap.draw(sorted_prop)
- Box-Cox変換とは、変数のスケールを変えて分布を正規分布(ガウス分布)の形に変えてくれる変換

ヒートマップの見方
生成されるヒートマップ自体が非常に小さくて見にくいので、まずは左側にフォーカスしてみます。
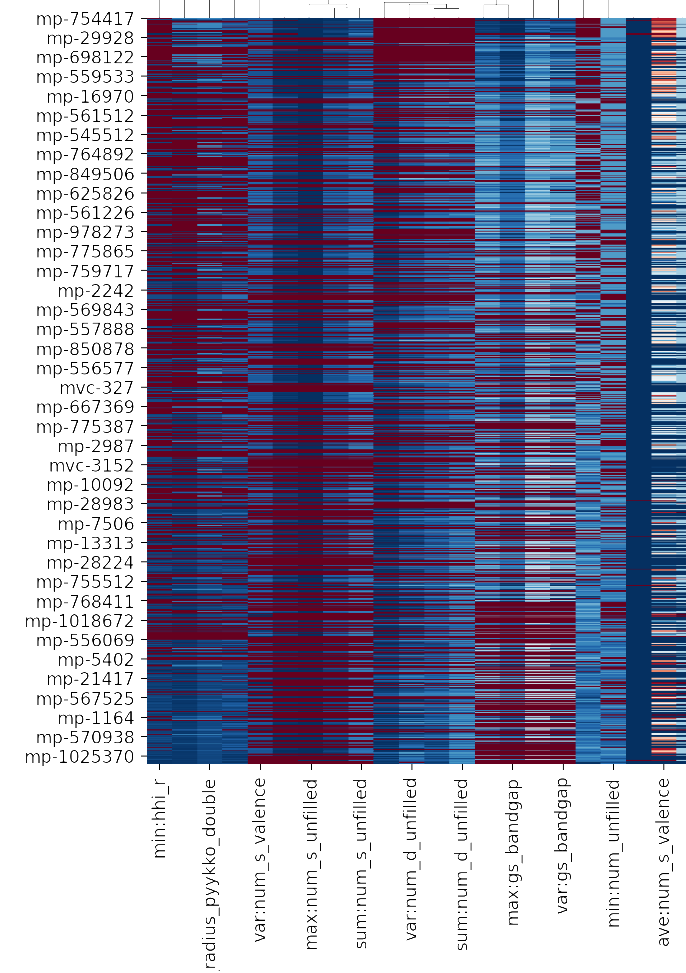
横軸には生成した290個の記述子が並んでいます。(並びは当初の順番と変わっている)縦軸は密度の小さい順にサンプル化合物が並べられています。 コードの解説で後述しますが、化合物mp-754417は密度が0.241653とデータセットの中で最小です。
続いてヒートマップの左上を見ていきます。
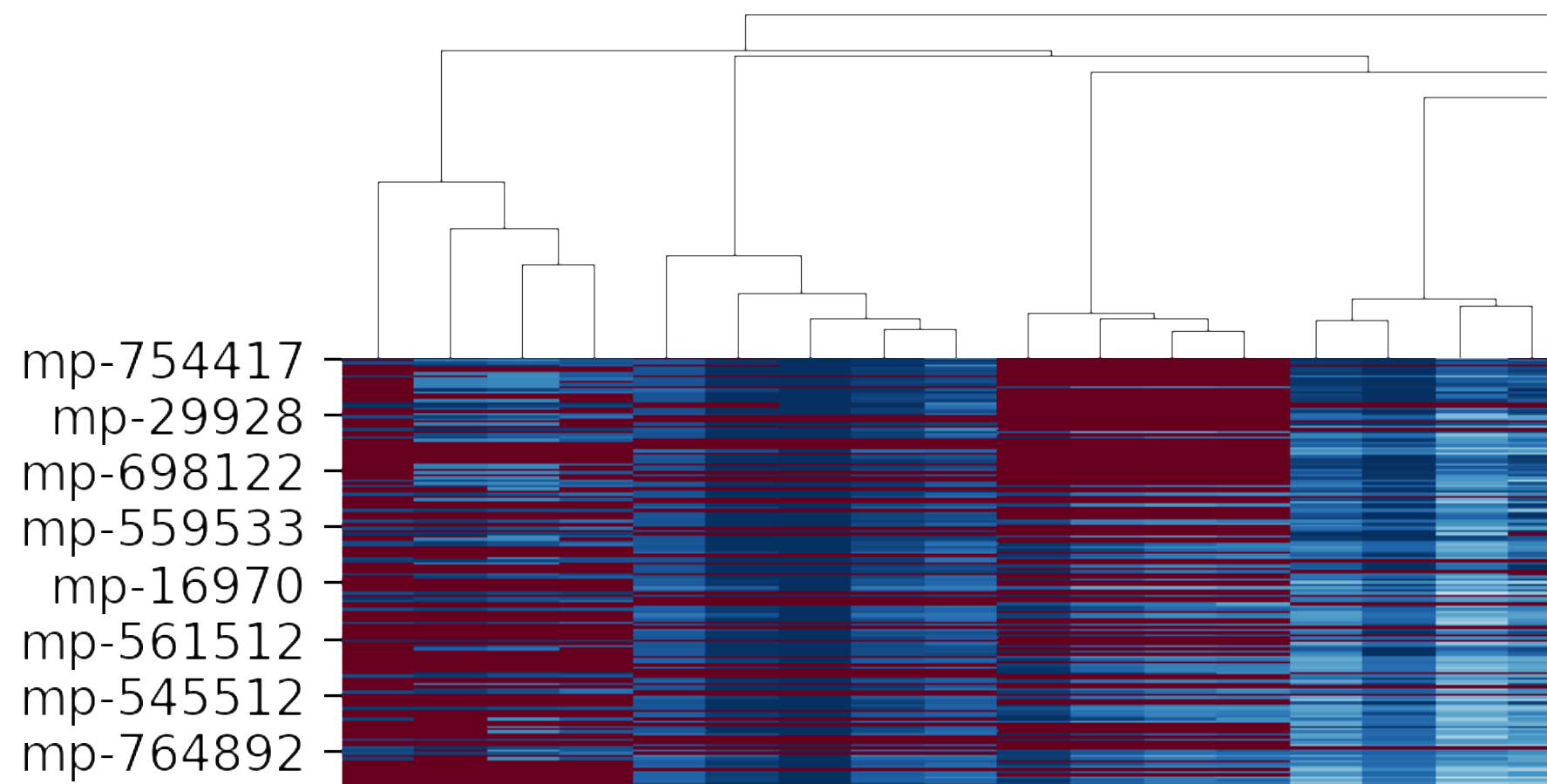
記述子が樹形図のように表されていることが分かります。よって隣接する記述子はある程度性質が似ているものであり、性質ごとにまとまりをもって記述子が横軸に配置されていることが分かります。
次にヒートマップの右側を見ていきます。
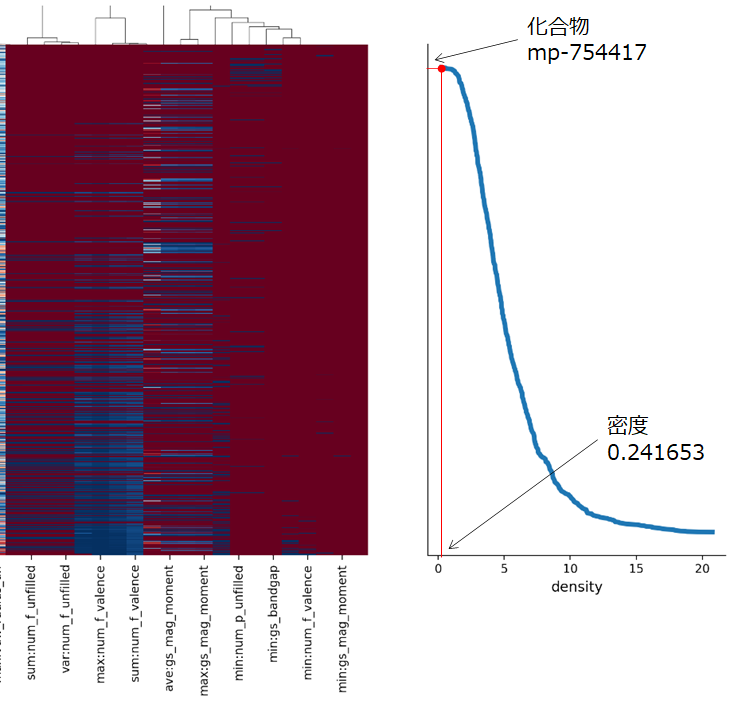
グラフは目的特性の分布を表しています。グラフの縦軸はヒートマップの縦軸の化合物と対応しています。例えば、縦軸の一番上の化合物mp-754417は密度が0.241653といった感じで読み取ります。また、データセットの中で最も密度が大きい化合物の密度は20強(実際は化合物mp-265の20.760335)であることが分かります。
最後にヒートマップ全体を見ます。以下は公式ページの画像です。
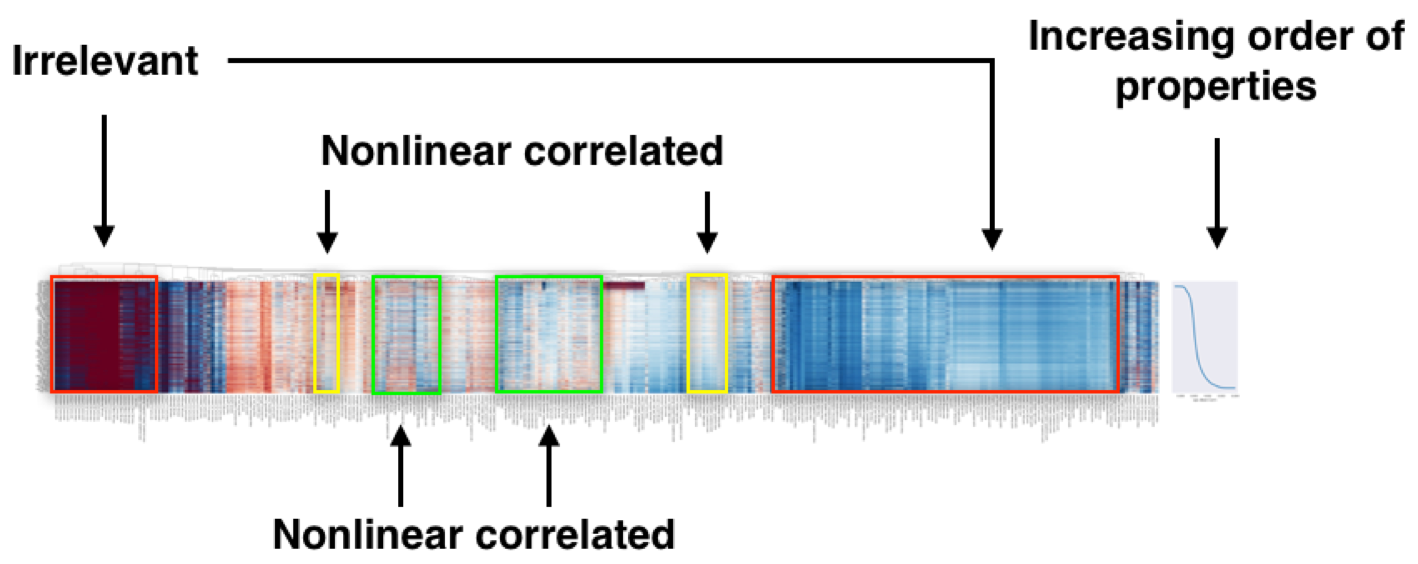
ヒートマップを作成することでどの記述子が目的特性と相関があるのか(予測に有用なのか)視覚的に認識することができます。相関のある記述子はヒートマップの上下方向で特徴的なパターン(例えば線形関係がある場合は単調増加や単調減少)を示しますが、相関のない記述子はそのような特徴を示しません。上記のヒートマップでは"Irrelevant"の部分の記述子は予測に対して有用でなく、"Nonlinear correlated"の部分の記述子は目的特性に対して非線形な相関を持つ記述子と読み取ります。
コードの解説
大まかにやっていることを示すと以下の通りです。

記述子生成の部分です。
samples
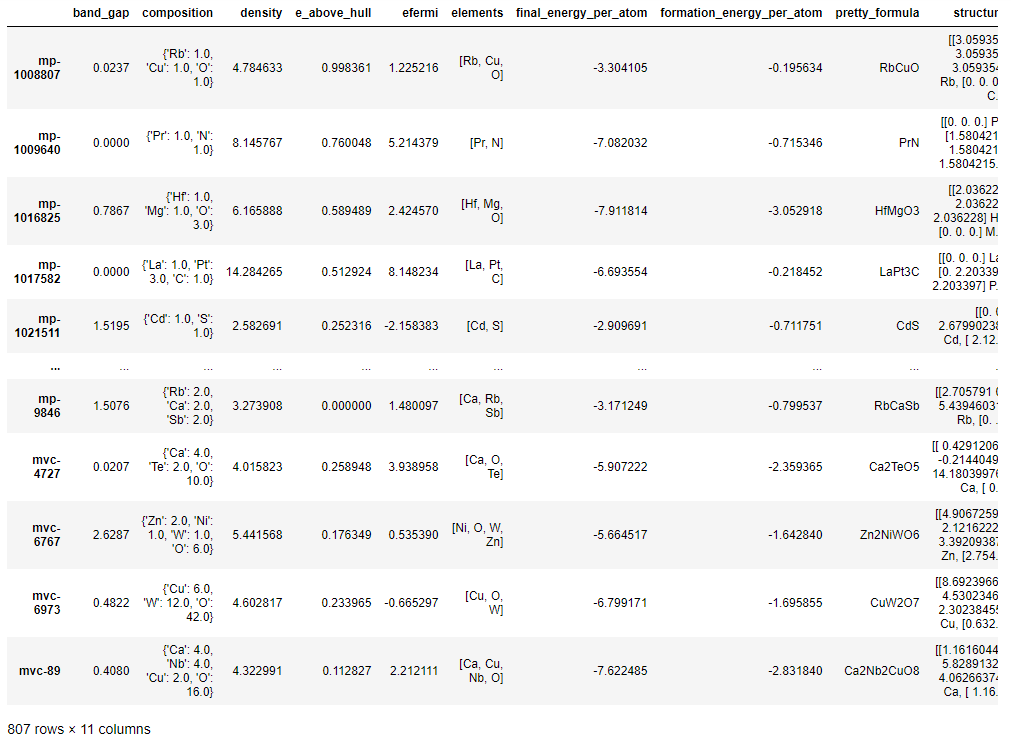
サンプルデータには11個の特徴量が含まれています。今回はdensityを目的特性とし、以下のようにcompositionを用いて記述子を生成します。
descriptor = cal.transform(samples['composition'])
descriptor
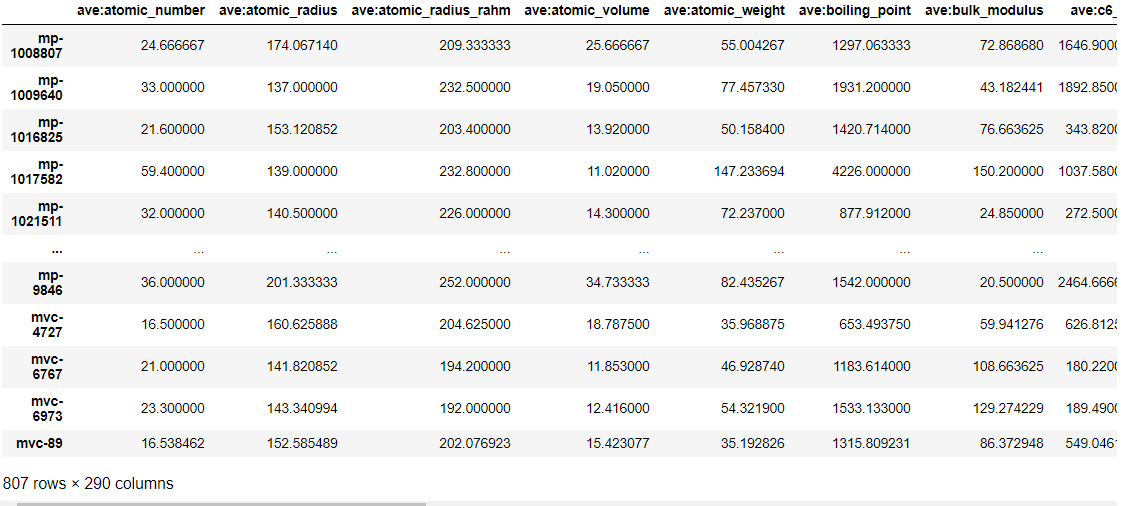
各化合物に対して290個の記述子が生成されていることが分かります。
目的特性の値順に記述子をソートする部分です。
property_ = 'density'
prop = samples[property_].dropna()
sorted_prop = prop.sort_values()
sorted_prop
mp-754417 0.241653
mp-707454 0.584481
mp-569787 0.618365
mp-974920 1.030260
mp-995220 1.110575
...
mp-1841 17.869855
mp-13100 17.948420
mp-312 18.376969
mp-91 18.854008
mp-265 20.760335
Name: density, Length: 807, dtype: float64
目的特性として密度を指定し、サンプルデータの中から密度を抜き出し、小さい順に並べています。
目的特性を変えてみてトライ
目的特性をdenity→efermiに変更して、ヒートマップを描いてみます。
# 1.calculate descriptors(記述子計算)
from xenonpy.datatools import preset
from xenonpy.descriptor import Compositions
samples = preset.mp_samples
cal = Compositions()
descriptor = cal.transform(samples['composition'])
# 2.sort descriptors by property values(目的特性でソート)
property_ = 'efermi'
prop = samples[property_].dropna()
sorted_prop = prop.sort_values()
sorted_desc = descriptor.loc[sorted_prop.index]
# 3.draw the heatmap(ヒートマップを描く)
from xenonpy.visualization import DescriptorHeatmap
heatmap = DescriptorHeatmap(
bc=True,
save=dict(fname='heatmap_efermi', dpi=200, bbox_inches='tight'),
figsize=(70, 10))
heatmap.fit(sorted_desc)
heatmap.draw(sorted_prop)

ヒートマップ自体に大きな変化は見られませんでした。
目的特性をdenity→band_gapに変更したヒートマップも作成してみました。以下に比較として、目的特性をdensity, efermi, band_gapとした際のヒートマップをそれぞれ順番に示します。
目的特性:density

目的特性:efermi

目的特性:band_gap

まとめ
XenonPyのチュートリアルのVisualizationについて解説しました。
XenonPyシリーズは一度これにて終了としますが、以下のリンクなど見て学習を続けていく予定です。何かアウトプットがあればまた更新します。