はじめに
XenonPyのチュートリアルのDescriptor calculationについて解説します。
※マテリアルズインフォマティクス関係の内容を他にも投稿していますので、よろしければこちらの一覧から他の投稿も見て頂けますと幸いです。
記述子計算
公式ドキュメントの"Descriptor calculation"に沿って解説します。
- XenonPyには記述子計算のインターフェイスが含まれています
- 4つのタイプに分類される計15個のFeaturizerを計算することができる
この投稿では"Composition"と"Structure"タイプの記述子計算について解説いたします。
環境
- conda 4.9.2
- python 3.7.1
- xenonpy 0.4.4
Compositional descriptors(組成に関する記述子)
XenonPyでは58個の元素レベルの特徴量("elements_completed")から290個の組成に関する特徴量(compositional features)を計算することが可能です。
from xenonpy.descriptor import Compositions
cal = Compositions()
cal
Compositions:
|- composition:
| |- Counting
| |- WeightedAverage
| |- WeightedSum
| |- WeightedVariance
| |- GeometricMean
| |- HarmonicMean
| |- MaxPooling
| |- MinPooling
Compositionsには、Countingをはじめとする8つのfeaturizerが含まれていることが分かります。それぞれのfeaturizerの定義はこちらを参考にして下さい。この計算機を使うことで化合物の組成に関する情報を得ることができます。
サンプルデータを例に使い方を以下に示します。
from xenonpy.datatools import preset
samples = preset.mp_samples
comps = samples['composition']
descriptor = cal.transform(comps)
descriptor
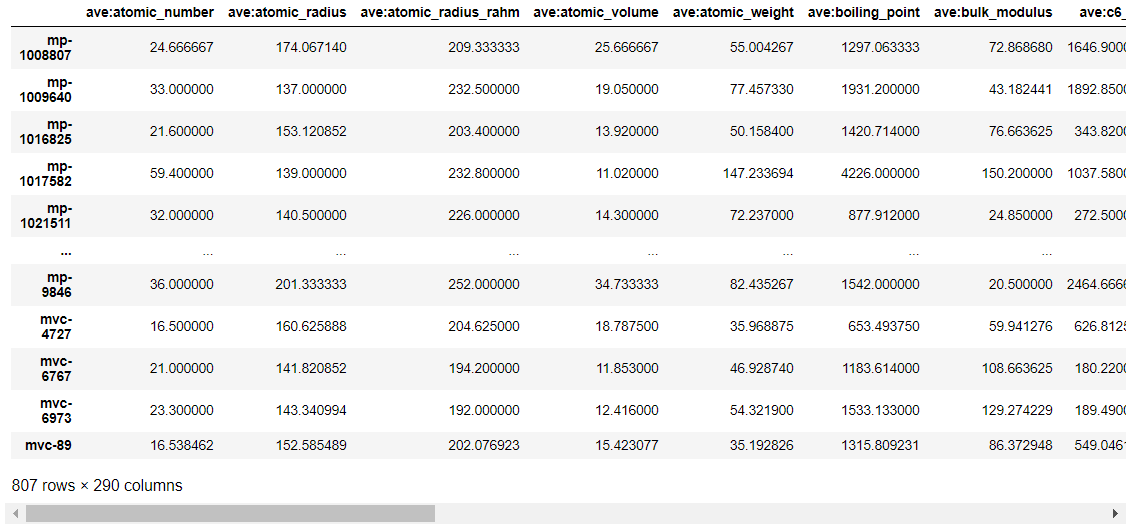
807個の化合物それぞれに対して、290個の記述子が得られたことが分かります。
ここで、変換前のサンプルデータを確認してみます。
samples
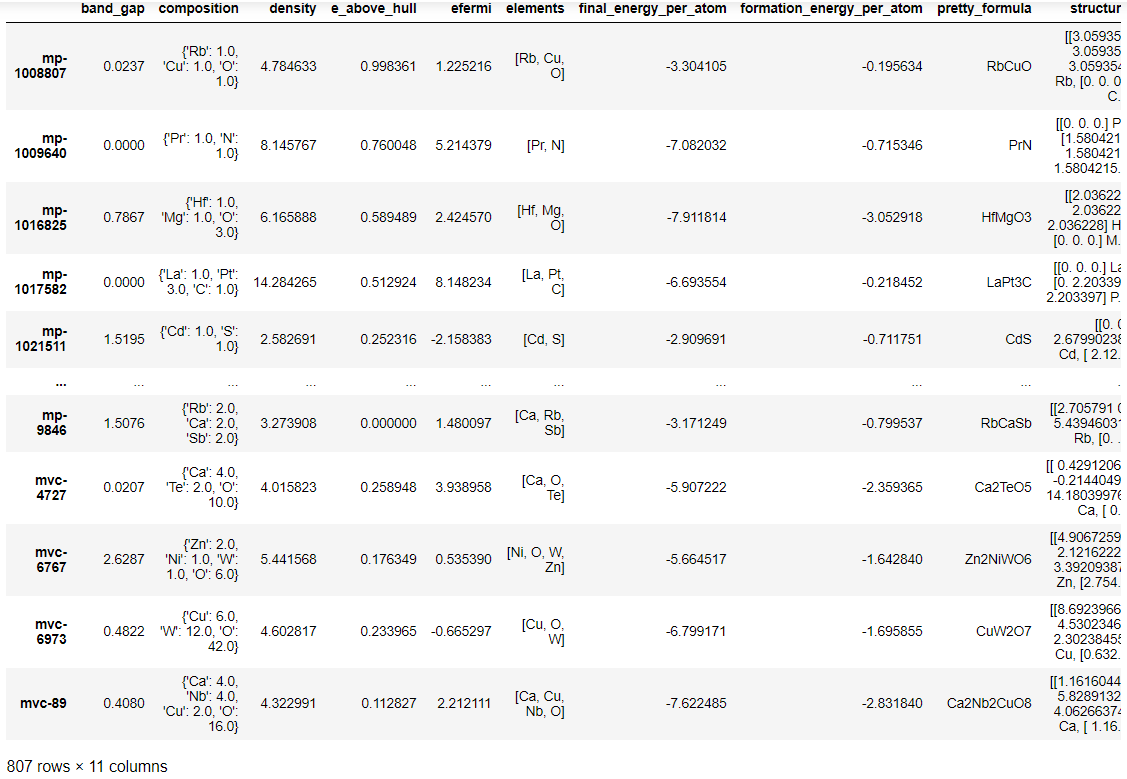
次に.transformに入力したデータを確認してみます。
samples['composition']
mp-1008807 {'Rb': 1.0, 'Cu': 1.0, 'O': 1.0}
mp-1009640 {'Pr': 1.0, 'N': 1.0}
mp-1016825 {'Hf': 1.0, 'Mg': 1.0, 'O': 3.0}
mp-1017582 {'La': 1.0, 'Pt': 3.0, 'C': 1.0}
mp-1021511 {'Cd': 1.0, 'S': 1.0}
...
mp-9846 {'Rb': 2.0, 'Ca': 2.0, 'Sb': 2.0}
mvc-4727 {'Ca': 4.0, 'Te': 2.0, 'O': 10.0}
mvc-6767 {'Zn': 2.0, 'Ni': 1.0, 'W': 1.0, 'O': 6.0}
mvc-6973 {'Cu': 6.0, 'W': 12.0, 'O': 42.0}
mvc-89 {'Ca': 4.0, 'Nb': 4.0, 'Cu': 2.0, 'O': 16.0}
Name: composition, Length: 807, dtype: object
transformメソッドはpymatgen.Structureオブジェクトか上記のような組成の辞書形式のデータ(例:{‘H’:2,‘O’:1})を受け取ることができます。ですので、以下のように自ら指定する任意の化合物に関して記述子を得ることが可能です。例として、H2o、LiF、CO2の記述子を取得してみます。
# 任意の化合物を定義
H2O = {'H': 2.0, 'O': 1.0}
LiF = {'Li': 1.0, 'F': 1.0}
CO2 = {'C': 1.0, 'O': 2.0}
# 辞書形式データをtransformメソッドに受け渡す
df = cal.transform([H2O, LiF, CO2])
df.index = ["H2O", "LiF", "CO2"]
df

Structural descriptors(構造に関する記述子)
XenonPyでは構造に関する特徴量も計算可能です。
from xenonpy.descriptor import Structures
cal = Structures()
cal
Structures:
|- structure:
| |- RadialDistributionFunction
| |- OrbitalFieldMatrix
Structuresには、RadialDistributionFunction(RDF:動径分布関数)とOrbitalFieldMatrix(OFM)の2つのfeaturizerが含まれていることが分かります。Compositional descriptorsと同様にサンプルデータに対して適用してみます。
descriptor = cal.transform(samples)
descriptor
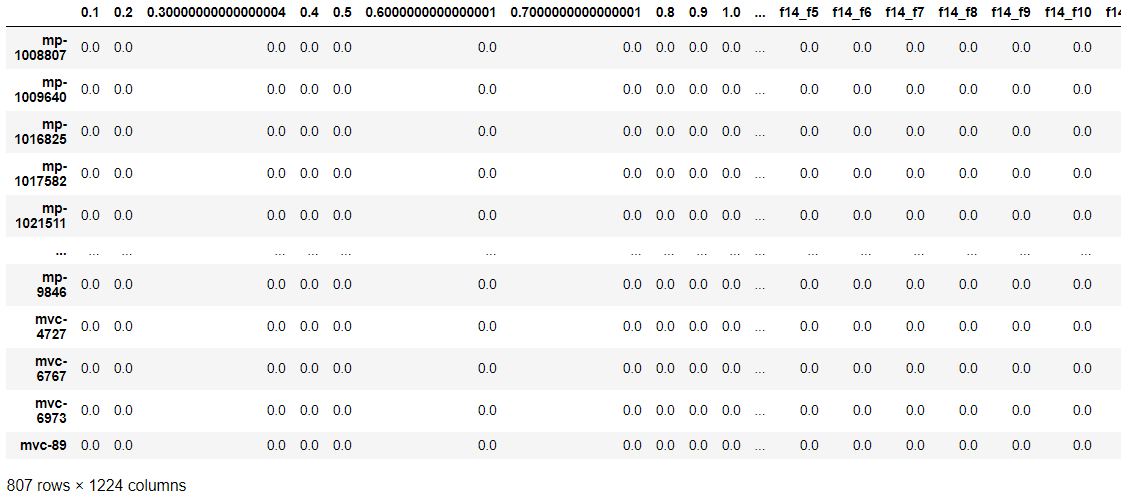
公式ドキュメントを参照するとmatminerと互換性があると記述があります。
まとめ
**XenonPyのチュートリアルのDescriptor calculationについて解説しました。**続編はこちらです。