はじめに
XenonPyの概要とチュートリアルの一部(Sample dataとData access)について解説します。
※マテリアルズインフォマティクス関係の内容を他にも投稿していますので、よろしければこちらの一覧から他の投稿も見て頂けますと幸いです。
XenonPyとは?
様々な化合物のデータベースかつMIに有用な予測モデルが含まれたツールで、MaterialsProjectで取得した記述子から新たに記述子を生成する際に使用することができます。
XenonPyには、低分子、高分子、無機材料の45種類の特性を対象に約14万個の機械学習の予測モデルが構築されています。マテリアルズインフォマティクスの様々なタスクを実行する機械学習アルゴリズムが実装されており、ユーザーはAPI経由でXenonPy.MDLの訓練済みモデルを再利用(転移学習)し、材料設計の様々なワークフローを構築可能です。
インストール方法
インストール方法はこちらに記載があります。XenonPyはPyTorch,pymatgen,rdkitの3つライブラリと依存関係にあるので、XenonPyインストール前にはこれら3つのインストールが必要となります。
使い方
公式チュートリアルに従って、XenonPyの使い方を解説していきます。
環境
- conda 4.9.2
- python 3.7.1
- xenonpy 0.4.4
Sample data
まずはサンプルデータを取得していきます。Materials Projectから1000個の無機化合物をランダムに選び出します。Materials Projectからデータを取得するにはAPIキーが必要となります。なお、Materials Projectに関してはこちらの投稿に概要を記載しています。
from xenonpy.datatools import preset
preset.build('mp_samples', api_key='Your API')

Data access
データはDatasetオブジェクトとして容易に取り扱うことができます。(実例がないとどんな感じでデータを取り扱っていくのかいまいちイメージできませんでした…)
Dataset
set1にdata1.csv, data1.pd.xz, data1.pkl.zが存在し、set2にata2.csv, data2.pd.xz, data2.pkl.zが存在するとします。以下のコードでset1とset2の全てのファイルを含むDatasetオブジェクトが作成可能です。
from xenonpy.datatools import Dataset
dataset = Dataset('/set1', '/set2')
dataset
<Dataset> includes:
"data1": C:\set1\data1.pd.xz
"data2": C:\set2\data2.pd.xz
公式ページでは以下のコードでデータの取り扱いが可能とのことですが、エラーが出て実行できずでした。
dataset.dataframe.data1
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-10-bdc1f28a8254> in <module>
----> 1 dataset.dataframe.data1
~\AppData\Local\Continuum\anaconda3\lib\site-packages\xenonpy\datatools\dataset.py in __getattr__(self, name)
175 if name in self.__extension__:
176 return self.__class__(*self._paths, backend=name, prefix=self._prefix)
--> 177 raise AttributeError("'%s' object has no attribute '%s'" % (self.__class__.__name__, name))
AttributeError: 'Dataset' object has no attribute 'dataframe'
以下のコードでdata1を読み込むことができました。
dataset.data1
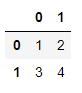
pd, csv, xlsx(xls), pklのファイル形式を読み込むことが可能であり、backendのパラメータで以下のように指定します。
dataset = Dataset('set1', 'set2', backend='csv')
dataset.data1
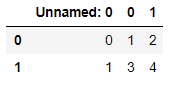
Preset
XenonPyでは"elements"と"elements_completed"の2つの特性データが使用可能です。これらのデータはmendeleev,pymatgen,CRC Hand Book,Magpieから収集されています。
- elements:118元素、74個の特徴量が含まれたデータ
- elements_completed:94元素(HからPu)、58個の特徴量が含まれたデータ
2021年5月現在、存在が確認されている元素の種類は118個であり、**"elements"は欠損値や計算値もありながら全ての元素の情報を含んでいるデータと言えます。**elementsやelements_completedの詳細やデータに含まれる特徴量についての詳細はこちらを参考にして下さい。
では、まずelementsについて見ていきます。
from xenonpy.datatools import preset
preset.elements
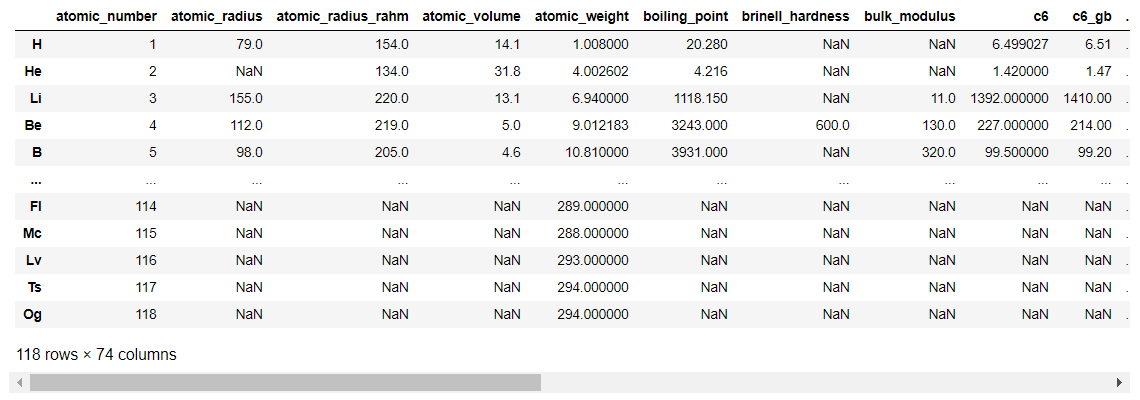
elementsデータに含まれる特徴量を確認します。
preset.elements.columns
Index(['atomic_number', 'atomic_radius', 'atomic_radius_rahm', 'atomic_volume',
'atomic_weight', 'boiling_point', 'brinell_hardness', 'bulk_modulus',
'c6', 'c6_gb', 'covalent_radius_bragg', 'covalent_radius_cordero',
'covalent_radius_pyykko', 'covalent_radius_pyykko_double',
'covalent_radius_pyykko_triple', 'covalent_radius_slater', 'density',
'dipole_polarizability', 'electron_negativity', 'electron_affinity',
'en_allen', 'en_ghosh', 'en_pauling', 'first_ion_en', 'fusion_enthalpy',
'gs_bandgap', 'gs_energy', 'gs_est_bcc_latcnt', 'gs_est_fcc_latcnt',
'gs_mag_moment', 'gs_volume_per', 'hhi_p', 'hhi_r',
'heat_capacity_mass', 'heat_capacity_molar', 'icsd_volume',
'evaporation_heat', 'gas_basicity', 'heat_of_formation',
'lattice_constant', 'linear_expansion_coefficient', 'mendeleev_number',
'melting_point', 'metallic_radius', 'metallic_radius_c12',
'molar_volume', 'num_unfilled', 'num_valance', 'num_d_unfilled',
'num_d_valence', 'num_f_unfilled', 'num_f_valence', 'num_p_unfilled',
'num_p_valence', 'num_s_unfilled', 'num_s_valence', 'period',
'poissons_ratio', 'proton_affinity', 'specific_heat',
'thermal_conductivity', 'vdw_radius', 'vdw_radius_alvarez',
'vdw_radius_batsanov', 'vdw_radius_bondi', 'vdw_radius_dreiding',
'vdw_radius_mm3', 'vdw_radius_rt', 'vdw_radius_truhlar',
'vdw_radius_uff', 'sound_velocity', 'vickers_hardness',
'Polarizability', 'youngs_modulus'],
dtype='object')
次に、elements_completedについて見ていきます。
preset.elements_completed
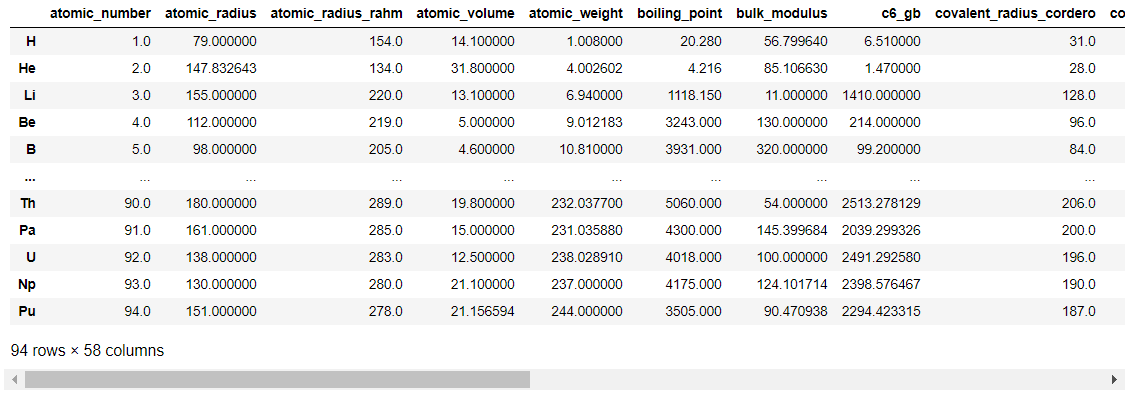
elements_completedデータに含まれる元素を確認します。95番目のAm(アメリシウム)~118番目のOg(オガネソン)が含まれていないことが分かります。
preset.elements_completed.index
Index(['H', 'He', 'Li', 'Be', 'B', 'C', 'N', 'O', 'F', 'Ne', 'Na', 'Mg', 'Al',
'Si', 'P', 'S', 'Cl', 'Ar', 'K', 'Ca', 'Sc', 'Ti', 'V', 'Cr', 'Mn',
'Fe', 'Co', 'Ni', 'Cu', 'Zn', 'Ga', 'Ge', 'As', 'Se', 'Br', 'Kr', 'Rb',
'Sr', 'Y', 'Zr', 'Nb', 'Mo', 'Tc', 'Ru', 'Rh', 'Pd', 'Ag', 'Cd', 'In',
'Sn', 'Sb', 'Te', 'I', 'Xe', 'Cs', 'Ba', 'La', 'Ce', 'Pr', 'Nd', 'Pm',
'Sm', 'Eu', 'Gd', 'Tb', 'Dy', 'Ho', 'Er', 'Tm', 'Yb', 'Lu', 'Hf', 'Ta',
'W', 'Re', 'Os', 'Ir', 'Pt', 'Au', 'Hg', 'Tl', 'Pb', 'Bi', 'Po', 'At',
'Rn', 'Fr', 'Ra', 'Ac', 'Th', 'Pa', 'U', 'Np', 'Pu'],
dtype='object')
elements_completedデータに含まれる元素を確認します。'brinell_hardness'や'covalent_radius_bragg'などのelementsには含まれていた特徴量がないことが分かります。
preset.elements_completed.columns
Index(['atomic_number', 'atomic_radius', 'atomic_radius_rahm', 'atomic_volume',
'atomic_weight', 'boiling_point', 'bulk_modulus', 'c6_gb',
'covalent_radius_cordero', 'covalent_radius_pyykko',
'covalent_radius_pyykko_double', 'covalent_radius_pyykko_triple',
'covalent_radius_slater', 'density', 'dipole_polarizability',
'electron_negativity', 'electron_affinity', 'en_allen', 'en_ghosh',
'en_pauling', 'first_ion_en', 'fusion_enthalpy', 'gs_bandgap',
'gs_energy', 'gs_est_bcc_latcnt', 'gs_est_fcc_latcnt', 'gs_mag_moment',
'gs_volume_per', 'hhi_p', 'hhi_r', 'heat_capacity_mass',
'heat_capacity_molar', 'icsd_volume', 'evaporation_heat',
'heat_of_formation', 'lattice_constant', 'mendeleev_number',
'melting_point', 'molar_volume', 'num_unfilled', 'num_valance',
'num_d_unfilled', 'num_d_valence', 'num_f_unfilled', 'num_f_valence',
'num_p_unfilled', 'num_p_valence', 'num_s_unfilled', 'num_s_valence',
'period', 'specific_heat', 'thermal_conductivity', 'vdw_radius',
'vdw_radius_alvarez', 'vdw_radius_mm3', 'vdw_radius_uff',
'sound_velocity', 'Polarizability'],
dtype='object')
このように各元素に対する様々な特徴量を取得できることが分かりました。この特徴量をインプット情報として材料探索に活用できそうですね。
まとめ
**XenonPyの概要とチュートリアルの一部(Sample dataとData access)について解説しました。**続編はこちらです。