はじめに
pandasでデータ分析を行うとき、分析したいデータが欠損している場合があります。データの欠損を放置したまま分析を行うと、おかしな分析結果が導かれてしまう可能性があります。そこで、この記事ではデータの欠損に対処する方法について、まだまだ不慣れなので備忘録として書いておきます。
Pandasについて
pandasは、DataFrameとSeriesの2種類のデータ構造、およびデータ解析ツールを提供してくれるPythonライブラリです。
欠損値の有無を確認する方法
欠損値の有無を確認する方法はいくつかあります。
- isnull():データが欠損しているか否かを返す
- info():データの要約を表示
動作例を見てみましょう。動作環境は、Python 3.7.3, pandas 0.24.2 です。
まず、pandasをインポートし、データをDataFrameとして読み込みます。ここでは、kaggleのチュートリアルで使用されているタイタニックの乗船者のデータ(https://www.kaggle.com/c/titanic/data )を使います。
import pandas as pd
data = pd.read_csv("train.csv")
isnull()
isnull()は、データの欠損を検出するためのメソッドです。DataFrameの要素で、値が欠損していればTrue、欠損していなければFalseを返します。
data.isnull()
これを実行すると、列Cabinにデータの欠損があることがわかります。(結果の表示は一部)

sum()メソッドと組み合わせることで、欠損している要素数を列ごとに調べることができます。
data.isnull().sum()
今回のデータの場合、列Age, Cabin, Embarkedにそれぞれ177個、687個、2個の欠損があることがわかります。
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
info()
データの要約を表示するinfo()メソッドでも、欠損値の有無を確認できます。
data.info()
info()メソッドは、DataFrameの行数、列数、各列の列名、各列に格納されるデータの型、メモリ使用量を表示します。各列の欠損していない要素数も表示するため、欠損値の有無の確認にも利用できます。今回のデータの場合、列Age, Cabin, Embarkedの欠損でない要素数が714, 204, 889と、行数(=891)に一致せず、欠損値があることが確認できます。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
ただし、上記のメソッドは万能ではありません。その理由は、上記のメソッドはPython側で認識できる欠損値(NaN, None, NaT)のみを検出するためです。例えば、データが欠損している場合には現実的でない値を格納しておく(例:年齢のデータが欠損している場合には-1を格納する、職業のデータが欠損している場合には"?"を格納する、など)という方針でデータが管理されていた場合、上記のメソッドでは欠損値を検出できません。したがって、データを説明した文書を確認したり、それがなければhead()メソッドなどでデータを眺めたりすることで、データの欠損がどのように扱われているか確認することが必要です。
欠損値を処理する方法
欠損値を処理するアプローチとしては、1. 欠損値を含む行や列を削除する、2. 欠損した要素に別のデータを格納する、があります。
どのアプローチを採用すべきかは、状況に応じて変更する必要があると思います。どう処理すべきか判断するには、「データ分析の目的は何か?」を明確にすることが重要です。例えば、目的変数を精度よく予測するモデルを構築することが目的であれば、欠損値を含む行を削除することでデータ数を減らすより、適切に穴埋めを行うことでデータ数を維持することが得策かもしれません。特に、データに依存した欠損が発生している(例:温度が一定以上になるとセンサーが不調になり、温度のデータが取得できなくなる)場合に、欠損のある行や列を削除すると、特定の傾向を持つデータを削除することになり、データの全体的な傾向を見誤ることになります。また、データの理解(どの説明変数の変化が目的変数の変化に大きく影響するか、などを明らかにする)が目的であれば、穴埋めをしてデータに手を加えすぎるのはデータの誤った理解につながってしまうかもしれません。さらに、ある説明変数が重要でないため利用しないという判断を下した場合は、そもそもその変数の欠損値の処理は行わない、という選択肢もあり得ます。何が最善かは、データ分析の目的を明確にした上でデータをいろいろと操作することで見えてくるものだと思います。
欠損値を処理するメソッドとしては、
- dropna():データが欠損している行や列を削除する(アプローチ1)
- fillna():データが欠損している要素を別の値で穴埋めする(アプローチ2)
があります。
dropna()
欠損値を含む行や列を削除するためのメソッドがdropna()です。
data.dropna()
デフォルトでは、dropna()はいずれかの要素が欠損している行を削除します。削除後のDataFrameを見ると、欠損値(NaN)を含む行が削除されていることが確認できます。

shapeを使ってDataFrameの行数、列数を確認すると、行数が減っていることがわかります。
data.dropna().shape
(183, 12)
dropna()は、引数を指定することで削除方法を細かく設定することができます。代表的なものを以下に挙げます。
data.dropna(axis = 'columns') # 欠損値を含む列を削除する
data.dropna(how = 'all') # すべての要素が欠損している行を削除する
data.dropna(thresh = 2) # 欠損していない要素数が2以上の行のみを保持する
data.dropna(subset = ['Age', 'Cabin']) # 列Age, Cabinで欠損値を含む行を削除する
また、注意点として、dropna()を呼び出すだけでは元のデータは変更されません。DataFrameを欠損値を含む行・列を削除したものに更新したい場合は、引数にinplace=Trueを指定するか、削除後にDataFrameに再代入します。(もちろん、元のDataFrameを残したければ別の変数に代入します。)
data.dropna(inplace=True)
# あるいは
data = data.dropna()
fillna()
欠損を別のデータで埋めるためのメソッドがfillna()です。
data.fillna('FILL')
欠損した要素に格納したいデータを引数に指定することで、欠損を埋めることができます。例えば、文字列'FILL'を指定すると、列Cabinの欠損した要素に'FILL'が格納されていることがわかります。

数値データが欠損している場合には、ある定数、同じ列の平均値や中央値、最頻値で穴埋めすることが多いようです。ただし、欠損が多い場合は、指定した値のデータが極端に増え、データの分散(ばらつき)がもとのデータより小さくなってしまうなどの欠点があるため、注意が必要です。どの方法を用いるかは、データ分析の目的と照らし合わせて検討するべきです。
data['Age'].fillna(20) # 列Ageの欠損値を20で穴埋め
data['Age'].fillna(data['Age'].mean()) # 列Ageの欠損値をAgeの平均値で穴埋め
data['Age'].fillna(data['Age'].median()) # 列Ageの欠損値をAgeの中央値で穴埋め
data['Age'].fillna(data['Age'].mode()) # 列Ageの欠損値をAgeの最頻値で穴埋め
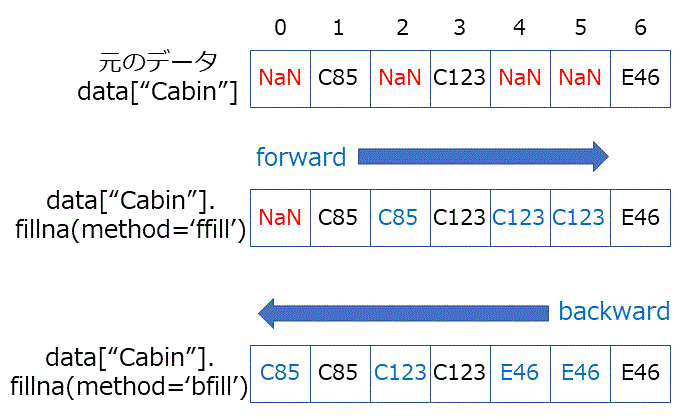
fillna()は、引数をmethod = 'ffill', method = 'bfill'と指定することで、欠損した要素に同じ列内の別の値を格納することができます。method = 'ffill'とした場合は、添え字が小さい要素に格納されていた値で、method = 'bfill'とした場合は、添え字が大きい要素に格納されていた値で欠損値を穴埋めします。'ffill'はf(orward)fillなので、値が前方(添え字が大きいほう)に伝搬する、'bfill'はb(ackward)fillなので、値が後方(添え字が小さいほう)に伝搬する、というイメージです。
data.fillna(method = 'ffill')
data.fillna(method = 'bfill')
また、fillna()もdropna()と同様に、呼び出すだけではデータの欠損の穴埋めが元のDataFrameに反映されません。
欠損値の穴埋めをする方法としては、ほかにも多重代入法(さまざまな方法で穴埋めを行った複数のデータセットを用意し、それらの解析結果を統合して穴埋めを行う方法)などがあります。
おわりに
この記事では、pandasでデータ分析を行うとき、欠損値を処理する方法について触れました。
欠損値をどのように扱うべきかは、データ分析の目的を考えて決める必要がありますが、このあたりはデータ分析の経験を積むことで見えてくるものかもしれません。手を動かして、欠損値の扱いの変化がデータの分析結果にどう影響するかを見てみるのがいいかもしれませんね。
参考文献
更新履歴
- (2019/09/29)欠損値を処理する方法の補足を追記