はじめに
コチラの記事でDCGANとFastGAN(LightweightGAN)を使ってポケモンを生成してみたの続きです。
今回はCGAN(conditional GAN)モデルを構築して、推しメンの画像を生成するようにしてみました。
きっかけ

推しメンが公式ブログで新しい自撮りを載せてくれると嬉しいですよね。生きるモチベがガンガン上がります。
そこで新しい推しメン画像を自分で生成できれば、無限にモチベーション上げられて勉強がより進むのではないかという不純な動機です()
ただ結論から述べると、生成画像の質としては満足できるものではなくて、失敗してます。
一人の櫻坂ファンが奮闘する姿を見ていただければ幸いです。
CGANとは
自分のGANについてまとめた記事に簡単ですがどういうイメージなのかはまとめております。
詳しい説明は論文を参考にして頂くのがいいかと思います。
ざっくりと言うと、通常のGANの入力はノイズベクトルだけですが、ここにさらにラベル情報も入力して学習させることで、生成する画像をコントロールできるようにしたGANモデルです。
いざ、実装
実装にあたってはコチラのサイトを参考にしました。正直いろんな実装方法があって迷いましたが(コチラやコチラなど)面白そうなモデル構造なので、今回採用させて頂きました。
環境としてはGoogle Colaboratoryを使用しています。
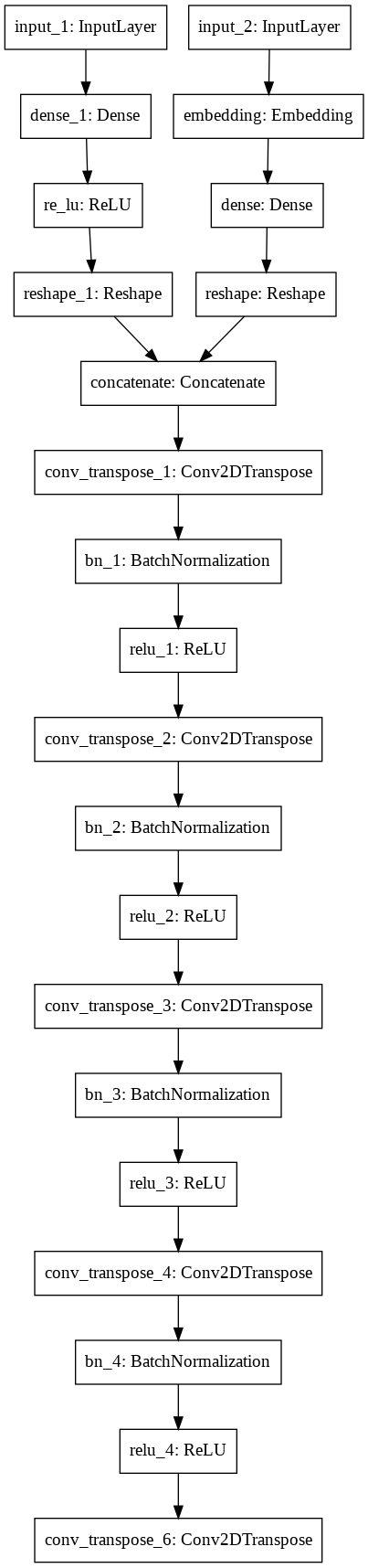
1. モデル概要図
Generator
Discriminator

個人的に面白いなと思ったのは、Generatorの方でラベル情報を埋め込んだ後に全結合層につなげている所です。
東大松尾研で無償公開されているDL4USの中のCGANモデルの章では、ラベル情報をone-hotエンコーディングしてノイズ情報と重ね合わせたものを入力とする形式を取っていたりするので、合わせ方も複数あるなぁと興味深かったです。
2. importとデータの準備
# 必要なものimport
import numpy as np
import time
import os
import glob
import cv2
import matplotlib.pyplot as plt
import datetime as dt
import tensorflow as tf
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import *
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import plot_model
# 画像データとラベルデータに分けて保存したnpzファイルからデータをロード
data = np.load('/content/drive/MyDrive/sakurazaka_make_face/sakurazaka_face.npz')
# 画像データとラベルデータの取得
Images = data['x']
labels = data['y']
コチラの記事で紹介させて頂いた櫻坂メンバーの顔分類アプリを作成する際に用意した顔画像セットをnpzファイルにして保存してたので、そちらからデータをダウンロードしてます。
この後でミニバッチデータ化します。
# 前処理
train_images = Images.astype('float32')
train_images = (train_images - 127.5) / 127.5
# データセット化
dataset = tf.data.Dataset.from_tensor_slices((train_images, labels))
dataset = dataset.shuffle(train_images.shape[0])
dataset = dataset.batch(128, drop_remainder=True)
例によってまず[-1,1]スケールに正規化しています。その後でTensorFlowのfrom_tensor_slicesを使ってデータセット化、シャッフル・バッチしてバッチサイズ128のミニバッチデータセットを作成しています。
ちなみに画像枚数は計11331枚なのでバッチサイズ128だと割り切れません。そのため
dataset = dataset.batch(128, drop_remainder=True)
drop_remainder = Trueにすることで割り切れないものは切り捨てしてバッチサイズ128に統一しています。
最初この処理を忘れていて、学習の時に**「データの次元がちゃうから損失計算できひんぞ!」**ってエラー吐かれたので要注意です。
3. Generator
# ノイズの次元数
z_size = 100
# クラスの数
n_classes = 25
# ノイズの入力層を定義
z_in = Input(shape=(z_size, ))
# ラベルの入力層を定義
label_in = Input(shape=(1, ), dtype="int32")
# モデル概要図の右側の処理を行う関数
# ラベル情報の層を作成
def make_gen_label_input(n_classes=25, embedding_dim=100):
# ラベルを埋め込む
label_embedding = Embedding(n_classes, embedding_dim)(label_in)
# 全結合層に接続
label_dense = Dense(16)(label_embedding)
# 変形[4,4,1]
label_reshape_layer = Reshape((4, 4, 1))(label_dense)
return label_reshape_layer
# モデル概要図の左側の処理を行う関数
def make_z_input(z_size=100):
z_dense = Dense(512 * 4 * 4)(z_in)
z_dense = ReLU()(z_dense)
z_reshape = Reshape((4, 4, 512))(z_dense)
return z_reshape
ノイズベクトルとラベル情報の入力をまとめるわけですが、まとめる前の処理をする関数を定義しています。
ラベルの埋め込み出力は[4,4,1]の形に
ノイズベクトルの出力は[4,4,512]の形になるようにしています。
def build_cgan_generator():
# ラベルの埋め込み出力を取得
label_output = make_gen_label_input() # 4 × 4 × 1
# ノイズベクトルの出力を取得
z_output = make_z_input() # 4 × 4 × 512
# 上記2つを連結
merge = Concatenate()([z_output, label_output]) # 4 × 4 × 513
# 重みを初期化するinitializerを定義
# 論文より平均0,標準偏差0.02の正規分布から初期化する(より早く収束するらしい)
initializer = tf.keras.initializers.RandomNormal(mean=0.0, stddev=0.02)
x = Conv2DTranspose(64 * 8, kernel_size=4, strides= 2, padding='same',
kernel_initializer=initializer, use_bias=False, name='conv_transpose_1')(merge)
x = BatchNormalization(momentum=0.1, epsilon=0.8, center=1.0, scale=0.02, name='bn_1')(x)
x = ReLU(name='relu_1')(x)
x = Conv2DTranspose(64 * 4, kernel_size=4, strides= 2, padding='same',
kernel_initializer=initializer,use_bias=False, name='conv_transpose_2')(x)
x = BatchNormalization(momentum=0.1, epsilon=0.8, center=1.0, scale=0.02, name='bn_2')(x)
x = ReLU(name='relu_2')(x)
x = Conv2DTranspose(64 * 2, kernel_size=4, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False, name='conv_transpose_3')(x)
x = BatchNormalization(momentum=0.1, epsilon=0.8, center=1.0, scale=0.02, name='bn_3')(x)
x = ReLU(name='relu_3')(x)
x = Conv2DTranspose(64 * 1, kernel_size=4, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False, name='conv_transpose_4')(x)
x = BatchNormalization(momentum=0.1, epsilon=0.8, center=1.0, scale=0.02, name='bn_4')(x)
x = ReLU(name='relu_4')(x)
out_layer = Conv2DTranspose(3, kernel_size=4, strides=2,padding='same',
kernel_initializer=initializer, use_bias=False, activation='tanh', name='conv_transpose_6')(x)
# 今までの入力層と出力層を結合
model = Model(inputs=[z_in, label_in], outputs=out_layer)
return model
# Generatorインスタンスを作成、モデル概要、モデル図も作成
generator = build_cgan_generator()
generator.summary()
plot_model(generator, to_file='generator.png')
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 100)] 0
__________________________________________________________________________________________________
input_2 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
dense_1 (Dense) (None, 8192) 827392 input_1[0][0]
__________________________________________________________________________________________________
embedding (Embedding) (None, 1, 100) 2500 input_2[0][0]
__________________________________________________________________________________________________
re_lu (ReLU) (None, 8192) 0 dense_1[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 1, 16) 1616 embedding[0][0]
__________________________________________________________________________________________________
reshape_1 (Reshape) (None, 4, 4, 512) 0 re_lu[0][0]
__________________________________________________________________________________________________
reshape (Reshape) (None, 4, 4, 1) 0 dense[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 4, 4, 513) 0 reshape_1[0][0]
reshape[0][0]
__________________________________________________________________________________________________
conv_transpose_1 (Conv2DTranspo (None, 8, 8, 512) 4202496 concatenate[0][0]
__________________________________________________________________________________________________
bn_1 (BatchNormalization) (None, 8, 8, 512) 2048 conv_transpose_1[0][0]
__________________________________________________________________________________________________
relu_1 (ReLU) (None, 8, 8, 512) 0 bn_1[0][0]
__________________________________________________________________________________________________
conv_transpose_2 (Conv2DTranspo (None, 16, 16, 256) 2097152 relu_1[0][0]
__________________________________________________________________________________________________
bn_2 (BatchNormalization) (None, 16, 16, 256) 1024 conv_transpose_2[0][0]
__________________________________________________________________________________________________
relu_2 (ReLU) (None, 16, 16, 256) 0 bn_2[0][0]
__________________________________________________________________________________________________
conv_transpose_3 (Conv2DTranspo (None, 32, 32, 128) 524288 relu_2[0][0]
__________________________________________________________________________________________________
bn_3 (BatchNormalization) (None, 32, 32, 128) 512 conv_transpose_3[0][0]
__________________________________________________________________________________________________
relu_3 (ReLU) (None, 32, 32, 128) 0 bn_3[0][0]
__________________________________________________________________________________________________
conv_transpose_4 (Conv2DTranspo (None, 64, 64, 64) 131072 relu_3[0][0]
__________________________________________________________________________________________________
bn_4 (BatchNormalization) (None, 64, 64, 64) 256 conv_transpose_4[0][0]
__________________________________________________________________________________________________
relu_4 (ReLU) (None, 64, 64, 64) 0 bn_4[0][0]
__________________________________________________________________________________________________
conv_transpose_6 (Conv2DTranspo (None, 128, 128, 3) 3072 relu_4[0][0]
==================================================================================================
Total params: 7,793,428
Trainable params: 7,791,508
Non-trainable params: 1,920
__________________________________________________________________________________________________
モデル構造は参考記事とほぼ一緒です。モデル概要図になるように結合させています。
個人的にはモデルを書くときはmodel.addで上から順番にどんどん層を積んでいく書き方が分かりやすくて好きなのですが、コチラの書き方の方が後でmodel.summary()した時に、どの層と層が繋がってるかが分かりやすいので、この書き方も練習していこうと思います。
4. Discriminator
# 画像の入力をそのまま出力として返す関数
def make_image_input(input_shape=(128,128,3)):
input_image = Input(shape=input_shape)
return input_image
# モデル図の左側の処理を行う関数
def make_disc_label_input(input_shape=(128,128,3), n_classes=25, embedding_dim=100):
# ラベルの入力
label_in = Input(shape=(1, ))
# ラベルの埋め込み
label_embedding = Embedding(n_classes, embedding_dim)(label_in)
# 全結合層につなぐ
label_dense = Dense(128 * 128 * 3)(label_embedding)
# 128 × 128 × 3に変形
label_reshape_layer = Reshape((input_shape[0], input_shape[1], 3))(label_dense)
return label_in, label_reshape_layer
Generator同様、最終的にラベルデータと実際の画像データを結合させる前の処理を行う関数を定義しています。
def build_cgan_discriminator():
# ラベルの入力層と、そのラベルデータの出力層を取得(128 × 128 × 3)
label_in, label_output = make_disc_label_input()
# 画像データの出力を取得(128 × 128 × 3)
input_image_output = make_image_input()
# 上記、ラベルデータと画像データを連結(128 × 128 × 6)
merge = Concatenate()([input_image_output, label_output])
# 重みを初期化するinitializerを定義
# 論文より平均0,標準偏差0.02の正規分布から初期化する(より早く収束するらしい)
initializer = tf.keras.initializers.RandomNormal(mean=0.0, stddev=0.02)
x = Conv2D(64, kernel_size=4, strides= 2, padding='same',
kernel_initializer=initializer, use_bias=False, name='conv_1')(merge)
x = BatchNormalization(momentum=0.1, epsilon=0.8, center=1.0, scale=0.02, name='bn_1')(x)
x = LeakyReLU(0.2, name='leaky_relu_1')(x)
x = Dropout(0.3, name = 'dropout_1')(x)
x = Conv2D(64 * 2, kernel_size=4, strides= 3, padding='same',
kernel_initializer=initializer, use_bias=False, name='conv_2')(x)
x = BatchNormalization(momentum=0.1, epsilon=0.8, center=1.0, scale=0.02, name='bn_2')(x)
x = LeakyReLU(0.2, name='leaky_relu_2')(x)
x = Dropout(0.3, name = 'dropout_2')(x)
x = Conv2D(64 * 4, kernel_size=4, strides=3, padding='same',
kernel_initializer=initializer, use_bias=False, name='conv_3')(x)
x = BatchNormalization(momentum=0.1, epsilon=0.8, center=1.0, scale=0.02, name='bn_3')(x)
x = LeakyReLU(0.2, name='leaky_relu_3')(x)
x = Dropout(0.3, name = 'dropout_3')(x)
x = Conv2D(64 * 8, kernel_size=4, strides=3,padding='same',
kernel_initializer=initializer, use_bias=False, name='conv_5')(x)
x = BatchNormalization(momentum=0.1, epsilon=0.8, center=1.0, scale=0.02, name='bn_4')(x)
x = LeakyReLU(0.2, name='leaky_relu_5')(x)
flattened_out = Flatten()(x)
dropout = Dropout(0.4, name = 'dropout_4')(flattened_out)
dense_out = Dense(1, activation='sigmoid')(dropout)
# 出力と入力をまとめる
model = Model([input_image_output, label_in], dense_out)
return model
画像とラベルの出力を連結させて[128,128,6]の形で次の層に送ります。
最終的に色々な畳み込み層を通って本物か偽物かを判断します。
# Discriminatorをインスタンス化、モデル概要、モデル図も作成
discriminator = build_cgan_discriminator()
discriminator.summary()
plot_model(discriminator)
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
embedding_1 (Embedding) (None, 1, 100) 2500 input_3[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 1, 49152) 4964352 embedding_1[0][0]
__________________________________________________________________________________________________
input_4 (InputLayer) [(None, 128, 128, 3) 0
__________________________________________________________________________________________________
reshape_2 (Reshape) (None, 128, 128, 3) 0 dense_2[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 128, 128, 6) 0 input_4[0][0]
reshape_2[0][0]
__________________________________________________________________________________________________
conv_1 (Conv2D) (None, 64, 64, 64) 6144 concatenate_1[0][0]
__________________________________________________________________________________________________
bn_1 (BatchNormalization) (None, 64, 64, 64) 256 conv_1[0][0]
__________________________________________________________________________________________________
leaky_relu_1 (LeakyReLU) (None, 64, 64, 64) 0 bn_1[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 64, 64, 64) 0 leaky_relu_1[0][0]
__________________________________________________________________________________________________
conv_2 (Conv2D) (None, 22, 22, 128) 131072 dropout_1[0][0]
__________________________________________________________________________________________________
bn_2 (BatchNormalization) (None, 22, 22, 128) 512 conv_2[0][0]
__________________________________________________________________________________________________
leaky_relu_2 (LeakyReLU) (None, 22, 22, 128) 0 bn_2[0][0]
__________________________________________________________________________________________________
dropout_2 (Dropout) (None, 22, 22, 128) 0 leaky_relu_2[0][0]
__________________________________________________________________________________________________
conv_3 (Conv2D) (None, 8, 8, 256) 524288 dropout_2[0][0]
__________________________________________________________________________________________________
bn_3 (BatchNormalization) (None, 8, 8, 256) 1024 conv_3[0][0]
__________________________________________________________________________________________________
leaky_relu_3 (LeakyReLU) (None, 8, 8, 256) 0 bn_3[0][0]
__________________________________________________________________________________________________
dropout_3 (Dropout) (None, 8, 8, 256) 0 leaky_relu_3[0][0]
__________________________________________________________________________________________________
conv_5 (Conv2D) (None, 3, 3, 512) 2097152 dropout_3[0][0]
__________________________________________________________________________________________________
bn_4 (BatchNormalization) (None, 3, 3, 512) 2048 conv_5[0][0]
__________________________________________________________________________________________________
leaky_relu_5 (LeakyReLU) (None, 3, 3, 512) 0 bn_4[0][0]
__________________________________________________________________________________________________
flatten (Flatten) (None, 4608) 0 leaky_relu_5[0][0]
__________________________________________________________________________________________________
dropout_4 (Dropout) (None, 4608) 0 flatten[0][0]
__________________________________________________________________________________________________
dense_3 (Dense) (None, 1) 4609 dropout_4[0][0]
==================================================================================================
Total params: 7,733,957
Trainable params: 7,732,037
Non-trainable params: 1,920
__________________________________________________________________________________________________
3日くらいかけて最終的にこのモデルになったわけですが、まだまだ改善の余地ありです。このモデルでも200エポックぐらいからDiscriminatorが強くなりすぎて、D-lossが0に収束してしまいました。
もう少しDropout層の率を上げたりとかすれば良くなるのかな。
Google Colaboratoryが学習のしすぎで悲鳴あげてそうだったので、ここで妥協しました()
余力できたら、改善したい。
5. Optimizer
# optimizerの定義
generator_optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002, beta_1 = 0.5, beta_2 = 0.999 )
discriminator_optimizer = tf.keras.optimizers.Adam(learning_rate=0.0001, beta_1 = 0.1, beta_2 = 0.999 )
Generator,Discriminator共にAdamで。
ただDiscriminatorが強くなりがちなので調整をしています。
6. 損失関数
# 損失関数の定義
loss_fn = tf.keras.losses.BinaryCrossentropy()
def generator_loss(label, fake_output):
gen_loss = loss_fn(label, fake_output)
return gen_loss
def discriminator_loss(label, output):
disc_loss = loss_fn(label, output)
return disc_loss
7. 学習ステップの定義
# 学習効率化のためtf.function
@tf.function
def train_step(images,label):
# ランダムにノイズを取得
noise = tf.random.normal([label.shape[0], z_size])
# discriminatorを本物の画像で学習
with tf.GradientTape() as disc_tape1:
generated_images = generator([noise,label], training=True)
real_output = discriminator([images,label], training=True)
real_labels = tf.ones_like(real_output)
disc_loss1 = discriminator_loss(real_labels, real_output)
# 本物のラベルで勾配を計算
gradients_of_disc1 = disc_tape1.gradient(disc_loss1, discriminator.trainable_variables)
# 本物のラベルでdiscriminatorのパラメータ更新
discriminator_optimizer.apply_gradients(zip(gradients_of_disc1,\
discriminator.trainable_variables))
# disctiminatorを偽物の画像で学習
with tf.GradientTape() as disc_tape2:
fake_output = discriminator([generated_images,label], training=True)
fake_labels = tf.zeros_like(fake_output)
disc_loss2 = discriminator_loss(fake_labels, fake_output)
# 偽物のラベルで勾配を計算
gradients_of_disc2 = disc_tape2.gradient(disc_loss2, discriminator.trainable_variables)
# 偽物のラベルでdiscriminatorのパラメータ更新
discriminator_optimizer.apply_gradients(zip(gradients_of_disc2,\
discriminator.trainable_variables))
# Generatorを本物のラベルで学習
with tf.GradientTape() as gen_tape:
generated_images = generator([noise,label], training=True)
fake_output = discriminator([generated_images,label], training=True)
real_labels = tf.ones_like(fake_output)
gen_loss = generator_loss(real_labels, fake_output)
# generatorの勾配を計算
gradients_of_gen = gen_tape.gradient(gen_loss, generator.trainable_variables)
# 本物のラベルでgeneratorのパラメータ更新
generator_optimizer.apply_gradients(zip(gradients_of_gen,\
generator.trainable_variables))
d_loss = disc_loss1 + disc_loss2
return d_loss, gen_loss
ほぼ参考通りです。
tf.GradientTapeを使って、GeneratorとDiscriminatorのパラメータを更新しています。
正直なところを言うと損失の計算や勾配、パラメータ更新の流れはまだ正確には理解できていないので、勉強します。
8. 学習前に必要な関数を定義
# ランダムにラベルベクトルを生成する関数
def label_gen(n_classes):
lab = tf.random.uniform((1,), minval=0, maxval=n_classes, dtype=tf.dtypes.int32, seed=None, name=None)
return tf.repeat(lab, [25], axis=None, name=None)
# 学習結果を表示・保存する関数
def save_imgs(log_path, epoch):
# 何枚画像を生成するか
num_example_gen = 25
# ノイズの生成
seed = tf.random.normal([num_example_gen, z_size])
# ラベルの生成
labels = label_gen(num_example_gen)
# 画像を生成して、[0,1]スケールにする
gen_imgs = generator([seed, labels], training=False)
gen_imgs = 0.5 * gen_imgs + 0.5
fig = plt.figure(figsize = (8, 8))
for i in range(gen_imgs.shape[0]):
plt.subplot(5,5,i+1)
plt.imshow(gen_imgs[i])
plt.axis('off')
fig.savefig("{}/{}.png".format(log_path, str(epoch+1).zfill(4)))
plt.show()
plt.close()
9. いざ学習
def train(ds, epochs, save_interval=1):
# 学習結果を保存する場所を定義
log_path = '/content/drive/MyDrive/sakurazaka_make_face/save_image5'
os.makedirs(log_path, exist_ok=True)
for epoch in range(epochs):
D_loss_list, G_loss_list = [], []
start_time = time.time()
for image, label in ds:
D_loss, G_loss = train_step(image, label)
D_loss_list.append(D_loss)
G_loss_list.append(G_loss)
if epoch % save_interval == 0:
# 生成画像の表示と保存
per_1_time = time.time() - start_time
print ("epoch:%d, Time:%.2f seconds, End: %.2f min, [D loss: %f / G loss: %f]" %
(epoch+1, per_1_time, (epochs- epoch)*per_1_time/60, np.mean(D_loss_list), np.mean(G_loss_list)))
save_imgs(log_path, epoch)
データセットをミニバッチごとに学習させます。
全部のミニバッチの学習が終わって1エポックです。
学習時間が膨大なので個人的には一回あたりの学習時間と、残り学習時間の表示は必須だと思います。
またD-loss と G-lossの表示も必須です。
うまくいっているときはD-lossの値が1.4付近になります。
$$ln(0.5)+ln(1-0.5)≒-1.4$$
なので。
まずそうなら途中で学習ストップするとかしないと時間が無駄に...。
また残り学習時間 = 1回あたりの学習時間 × 残りエポック数
で算出しています。
でとりあえず、1000エポックで学習してみたところ
1エポックあたり40秒、大体10時間ほどかかりました。
学習結果
グロいやつもあるので苦手な方はごめんなさい。
1エポック目

10エポック目

なんか顔っぽいのが生成されてます。
50エポック目

怖いですね。
100エポック目

だいぶ整ってきた?
200エポック目

うーん...。
300エポック目

よさそうなやつが生成されてますね。
500エポック目

この辺りからDiscriminatorが強くなってきました。
800エポック目

1000エポック目

微妙な感じですね、、、
ただ本番はここから。
ラベルノイズを調整して狙ったメンバーの画像を生成してもらいます。
members = ['uemura_rina', 'ozeki_rika', 'koike_minami', 'kobayashi_yui', 'saito_fuyuka',
'sugai_yuka', 'habu_miduho', 'harada_aoi', 'moriya_akane', 'watanabe_rika', 'watanabe_risa',
'inoue_rina', 'endo_hikari', 'oozono_rei', 'oonuma_akiho', 'kousaka_marino', 'seki_yumiko',
'takemoto_yui', 'tamura_hono', 'fuziyoshi_karin', 'masumoto_kira', 'matuda_rina','morita_hikaru',
'moriya_rena', 'yamasaki_ten']
def get_class_label(class_code):
class_labels = {i:member_name for i, member_name in enumerate(members)}
return class_labels[class_code]
number = 18
name = get_class_label(number)
noise = tf.random.normal([5, 100])
label = tf.ones(5) * number
gen_imgs = generator([noise, label], training=False)
gen_imgs = 0.5 * gen_imgs + 0.5
fig = plt.figure(figsize = (8, 8))
for i in range(gen_imgs.shape[0]):
plt.subplot(1,5,i+1)
plt.imshow(gen_imgs[i])
if i == 2:
plt.title(name)
plt.axis('off')
plt.show()
plt.close()
こんな感じのコードでnumberの値を変えればメンバーを変えれます。
我が推しメンは田村保乃ちゃんと森田ひかるちゃんなのでこの2人を生成してもらいましょう。
個人的にうまくいったものだけ載せます。






妥協できるラインのものを載せましたが、まだまだって感じですね。これでは僕のモチベは上がらないです()
まとめ
CGANモデルで推しメンの画像をたくさん拝めると思ったけど、ダメでした。
まだDiscriminatorが強くなりすぎるのと、学習回数重ねてないからっていうのもあるのかな。
伸び代はまだまだあるので、気が向いたら調整かけて、また紹介できればと思います。
ただ、本当にラベルを調整するだけで生成画像が変わるのは面白くて、より勉強のモチベになったのでやって良かったです。
個人的にはStyleGAN2のような高性能モデルで推しメン生成してみたいですね。
結果は失敗ですが、参考になれば幸いです。