何したの?
櫻坂46のメンバー25人全員の顔画像をCNNモデルで分類するWebアプリケーションを作りました。画像分類のテーマはたくさんありますが、好きなもので取り組む方がモチベ出るでしょってことで櫻坂46を。(乃木坂・日向坂に比べるとそんな流行ってない...?)
作ったもの
櫻坂46メンバー顔分類アプリ
※10/22 Azureのキー期限切れでエラーが出ます。修正する予定は無いので、ソースコードを見てもらえれば幸いです。
はじめに
「[第3版]Python機械学習プログラミング 達人データサイエンティストによる理論と実践」を元に機械学習の学習を進めており、ちょうど16章のRNNモデルの部分まで読み進められたので、主にCNNモデルのアウトプットとして作成したものになります。
機械学習を学び始めて2ヶ月行くか行かないかくらいの初学者ですので、同じくらいのレベルの方に、機械学習のモデル構築・学習からアプリとして公開するまでの流れの参考になれば幸いです。
また顔分類に関しては、たくさんの先駆者様がコードや記事を公開して頂いているため、調べに調べて参考にさせて頂きました。本当にありがとうございます。
環境構成
画像データを扱うため、GPUが必須になってきます。
メインマシンとしてMacBook Air M1を使っているのですが、どうもGPUの設定がうまくいかなかったため、クラウドの力を借りることにしました。GCPのAI Platformが環境構築が簡単かつ楽で助かりました。
Google CloudのAI Platform Notebooksで楽々コンペ環境の構築が非常にわかりやすかったです。ありがとうございます。
以下、立ち上げたノートブックインスタンスの詳細です。
| 環境 | TensorFlow: 2.5 |
| マシンタイプ | 8 vCPUs, 30GB RAM |
| GPU | NVIDIA Tesla K80 ×1 |
ただこの後の画像集め、切り出し、振り分けはローカルの方がやりやすいため、Anacondaの仮想環境上のJupyter Labで動かしています。
アプリ構成
コチラを参考にStreamlitで作成しました。めちゃ簡単で感動しました。
最終的なアプリのディレクトリ図が以下。
app/
├─ main.py (Streamlitで実行するメインのpythonファイル)
├─ my_model.h5 (学習済みモデル)
├─ requirements.txt (必要なライブラリを記載したテキストファイル)
├─ SourceHanSans-VF.ttf (アプリケーションで用いるフォントファイル)
├─ secret.json (APIキー格納)※本当は良くない
一応、この他APIキーを書いたファイルや.gitignoreもあります。
作成までの流れ
大まかに以下のようになります。
- 画像収集
- 顔の切り出し
- 画像の振り分け
- データセットの用意
- 画像の前処理
- データ分割・モデル構築
- モデルの学習・評価・保存
- アプリケーション化
- アプリのデプロイ
1つずつ説明していきます。
1. 画像収集
本当はメンバーの公式ブログからスクレイピングで集めてきたかったんですが、実装コードの理解に時間がかかりすぎて先に進まなそうだったので、簡単に使えるiclawlerを使いました。
from icrawler.builtin import BingImageCrawler
# 画像フォルダの名前はローマ字の方が都合がいいのでローマ字でのメンバーリスト
names_eng = ['uemura_rina', 'ozeki_rika', 'koike_minami', 'kobayashi_yui', 'saito_fuyuka',
'sugai_yuka', 'habu_miduho', 'harada_aoi', 'moriya_akane', 'watanabe_rika', 'watanabe_risa',
'inoue_rina', 'endo_hikari', 'oozono_rei', 'oonuma_akiho', 'kousaka_marino', 'seki_yumiko',
'takemoto_yui', 'tamura_hono', 'fuziyoshi_karin', 'masumoto_kira', 'matuda_rina','morita_hikaru',
'moriya_rena', 'yamasaki_ten']
# 検索は日本語でするので日本語リストも
names_jap = ['上村莉菜', '尾関梨香', '小池美波', '小林由依', '齋藤冬優花', '菅井友香', '土生瑞穂',
'原田葵', '守屋茜', '渡辺梨加', '渡邉理佐', '井上梨名', '遠藤光莉', '大園玲', '大沼晶保',
'幸阪茉里乃', '関有美子', '武元唯衣', '田村保乃', '藤吉夏鈴', '増本綺良',
'松田里奈', '森田ひかる', '守屋麗奈', '山﨑天']
# 繰り返し処理でBingから各メンバーにつき900枚集める
# 集めた画像ファイルは data/<メンバーの名前>/ のフォルダに保存
for name_eng, name_jap in zip(names_eng, names_jap):
crawler = BingImageCrawler(storage={"root_dir": "data/" + name_eng})
crawler.crawl(keyword=name_jap, max_num=900)
max_num=900としてますが、実際には500枚ちょっとしか保存されてません。
全メンバーそれぞれ500枚ずつくらいは集められました。
2. 顔の切り出し
画像は集まりましたが、このまま訓練データに...とはできません。
顔以外の余計な部分まで学習させるのはナンセンス。顔だけを切り出す必要があります。
主な流れは
識別器で顔部分を特定→その部分だけを切り出して、カラー画像として保存
ここは色々と試行錯誤したポイントです。
最初はコチラの記事を参考に、識別器はTensorflow Face Detectorを使おうと思いましたが、何度やっても顔を認識してくれず断念。
dlibライブラリも使ってみて、試しに何枚かテストでやってみたところ、比較的精度が良かったのでそのまま進めていましたが、どうやらWebアプリ化してHerokuなどにデプロイするのがめんどくさくなりそうということでコチラも不採用に。
結局、色々な方が使っている定番のOpenCVを使うことに。
ただOpenCVのカスケード分類器は斜めの画像になると検出力が落ちるという弱点があるため、TensorFlowによるももクロメンバー顔認識(前編)様を参考に(ほぼ一緒ですが)検出器を少し改造しました。
ただ先にネタバレをすると、この検出器は本番環境で使いません()
さてこの検出器の大まかな流れは
- -40度から40度まで10度刻みで画像を回転させて顔認識
- 両目の認識
- 口の認識
- 重複は省き、もっとも良さげな1枚を別のフォルダに128×128のサイズでカラー保存していく
となってます。正直参考コードを自分のフォルダ構成で動くように変えただけなので、仕組みの部分は理解してません。時間の関係もあったので、とにかく学習データを用意することが最優先でした。
import os
import glob
import cv2
import numpy as np
import math
# カスケード分類器
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_alt2.xml')
eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml')
mouth_cascade = cv2.CascadeClassifier('haarcascade_mcs_mouth.xml')
# base_dirはどのフォルダに切り出した顔画像を保存するか
base_dir = './face'
# ここを変更することで1人1人確認しながら顔画像切り出ししてました
# もちろんfor文で25人まとめてやるのもいいと思います。
member_name = 'tamura_hono'
# 指定したメンバーの画像を全て取得して保存先のファイルを作る
file_list = glob.glob('./data/' + member_name + '/*')
os.makedirs('./face/' + member_name, exist_ok=True)
# それぞれのファイルをcv2で読み込み、グレースケール化
for image_file in file_list:
file_number = image_file.split('/')[-1].split('.')[0]
input_img = cv2.imread(image_file)
height, width, colors = input_img.shape
img_gray = cv2.cvtColor(input_img, cv2.COLOR_BGR2GRAY)
#画像データの斜辺を1辺とする枠組みを作る
hypot = int(math.hypot(height, width))
frame = np.zeros((hypot, hypot), np.uint8)
frame[int((hypot - height) * 0.5):int((hypot + height) * 0.5),
int((hypot - width) * 0.5):int((hypot + width) * 0.5)] = img_gray
results = []
face_id_seed = 0
for degree in range(-40, 41, 10):
print('degree: %s' % degree)
M = cv2.getRotationMatrix2D((hypot * 0.5, hypot * 0.5), -degree, 1.0)
rotated = cv2.warpAffine(frame, M, (hypot, hypot))
faces = face_cascade.detectMultiScale(rotated, scaleFactor = 1.11, minNeighbors = 3, minSize = (128, 128))
for (x, y, w, h) in faces:
face_position = rotated[y:y+h, x:x+w]
center = (int(x + w * 0.5), int(y + h * 0.5))
origin = (int(hypot * 0.5), int(hypot * 0.5))
r_degree = -degree
center_org = rotate_coord(center, origin, r_degree)
print('face:', (x,y,w,h), center_org)
resized = face_position
if w < 128:
print('resizing...')
resized = cv2.resize(face_position, (128, 128))
result = {
'face_id': 'f%s' % face_id_seed,
'img_resized': resized, #顔候補bitmap(小さい場合zoom)
'img': face_position, #顔候補bitmap(元サイズ)
'degree': degree, #回転
'frame': (x, y, w, h), #回転状態における中心座標+size
'center_org': center_org, #角度0時における中心座標
}
results.append(result)
face_id_seed += 1
eyes_id_seed = 0
eyes_faces = []
for result in results:
print('#eyes:'),result['face_id']
img = np.copy(result["img_resized"])
fw,fh = img.shape
eyes = eye_cascade.detectMultiScale(img, 1.02)
left_eye = right_eye = None #左上/右上にそれぞれ目が1つずつ検出できればOK
for (x,y,w,h) in eyes:
print('## eye:',x,y,w,h,fw/8,fw/4,fh/8,fh/4)
cv2.rectangle(img,(x,y),(x+w,y+h),(64,64,0),1)
if not (fw/6 < w and w < fw/2):
print('eye width invalid')
continue
if not (fh/6 < h and h < fh/2):
print('eye height invalid')
continue
if not fh * 0.5 - (y + h * 0.5) > 0: #上半分に存在する
print('eye position invalid')
continue
if fw * 0.5 - (x + w * 0.5) > 0:
if left_eye:
print('too many left eye')
continue
else:
left_eye = (x,y,w,h)
else:
if right_eye:
print('too many right eye')
continue
else:
right_eye = (x,y,w,h)
if left_eye and right_eye:
print('>>> valid eyes detect')
result['left_eye'] = left_eye
result['right_eye'] = right_eye
eyes_faces.append(result)
candidates = []
for i, result in enumerate(eyes_faces):
print('result:',result['face_id'])
result['duplicated'] = False
for cand in candidates:
c_x, c_y = cand['center_org']
_,_,cw,ch = cand['frame']
r_x, r_y = result['center_org']
_,_,rw,rh = result['frame']
if abs(c_x - r_x) < ((cw+rw)*0.5*0.3) and abs(c_y - r_y) < ((ch+rh)*0.5*0.3): #近い場所にある顔候補
c_diff = eyes_vertical_diff(cand)
r_diff = eyes_vertical_diff(result)
print('c_diff:',cand['face_id'],c_diff)
print('r_diff:',result['face_id'],r_diff)
if c_diff < r_diff: #より左右の目の水平位置が近いほうが採用
result['duplicated'] = True
else:
cand['duplicated'] = True
candidates.append(result)
filtered = filter(lambda n: n['duplicated'] == False, candidates)
finals = []
for item in filtered:
img = np.copy(item['img_resized'])
fw,fh = img.shape
mouthes = mouth_cascade.detectMultiScale(img, 1.02) #faceの中心下部付近にあればOK
mouth_found = False
for (mx,my,mw,mh) in mouthes:
print('mouth',(mx,my,mw,mh))
cv2.rectangle(img,(mx,my),(mx+mw,my+mh),(128,128,0),2)
h_diff = fh/2 - (my+mh/2)
print(fh, h_diff)
if h_diff < 0:
mouth_found = True
break
if mouth_found:
finals.append(item)
for item in finals:
out_file = crop_color_face(item, input_img, base_dir, file_number)
# posをdegree度回転させた座標を返す関数
def rotate_coord(pos, origin, degree):
"""
posをdeg度回転させた座標を返す
pos: 対象となる座標tuple(x,y)
origin: 原点座標tuple(x,y)
degree: 回転角度
return: 回転後の座標tuple(x,y)
"""
x, y = pos
ox, oy = origin
r = np.radians(degree)
xd = ((x - ox) * np.cos(r) - (y - oy) * np.sin(r)) + ox
xy = ((x - ox) * np.sin(r) + (y - oy) * np.cos(r)) + oy
return (int(xd), int(xy))
# 目の水平位置のズレを計算する関数
def eyes_vertical_diff(face):
_,ly,_,lh = face["left_eye"]
_,ry,_,rh = face["right_eye"]
return abs((ly + lh * 0.5) - (ry + rh * 0.5))
# 最終的に取得した画像をカラーで切り出して保存する関数
def crop_color_face(item, img, base_dir, file_number):
height, width, colors = img.shape
hypot = int(math.hypot(height, width))
frame = np.zeros((hypot, hypot, 3), np.uint8)
frame[int((hypot - height) * 0.5):int((hypot + height) * 0.5), int((hypot - width) * 0.5):int((hypot + width) * 0.5)] = img
degree = item['degree']
M = cv2.getRotationMatrix2D((hypot * 0.5, hypot * 0.5), -degree, 1.0)
rotated = cv2.warpAffine(frame, M, (hypot, hypot))
x,y,w,h = item['frame']
face = rotated[y:y+h, x:x+w]
face = cv2.resize(face, (128, 128))
web_path = '%s/%s_%s_%s.jpg' % (member_name, member_name,file_number, item['face_id'])
out_file = '%s/%s' % (base_dir, web_path)
print('web_path', web_path)
print('out_file', out_file)
cv2.imwrite(out_file, face)
return web_path
変更点としてはコチラを参考に分類器のパラメータ
scaleFactor = 1.11
minNeighbors = 3で検出してます。(2でもあまり大差ありませんでした)
また顔画像ファイルの名前を(メンバーの名前+ファイルNo.jpg)となるようにしてます。
というのも、そもそもicrawlerで集めてきたファイルの名前は000001.jpgのようになってます。
この後の振り分け作業をする際に、意外と拡大されたり顔だけになったりすると目視だとどのメンバーなのか分からなくなることがあります。(ファンとして恥ずべきことです。反省してます。)
そのため、ファイルナンバーもセットにすることで、どの写真から切り出されたものかわかるようにしてます。
以下余談というか、今後の戒めになるようメモを残します。
結論、for文のインデント位置ミスったせいで、ループ位置がミスり、時間を大幅に無駄にしました...。
最初コードを実行した時、1人あたり500枚ほどある画像から、顔だけの画像が1メンバーにつき900~1100枚ほど集まり、「多いな...」と思いつつも、次の振り分け作業をしてました。
そもそも1人の切り出しに20~30分、途中画像データが存在しないデータのせいで中断され、全メンバーの切り出しに10時間ほどかかった段階で気づけよって話なんですが...。
振り分けしている時もやたら顔じゃない画像や、同じ画像が頻繁に出たりしていたり違和感はあったのに。
まず画像を集めた段階で、関係ない画像の削除や簡単な振り分けしておけば良かったと後悔しました。
再度、正しくやると1人あたり5分、計500枚ほどの顔だけの画像が集まりました。
for文のインデント位置、特に他のソースコードからコピペするとズレることがよくあるので気をつけたいです。
3. 画像の振り分け
地獄の時間でした。正直二度とやりたくないです。
ある程度は正確に切り出しできてますが、それでも変な部分の画像はいくらかあり、削除しなければいけません。またツーショット写真などもあるので、例えば**「田村保乃ちゃん」のフォルダに「森田ひかるちゃん」**の顔画像が切り出しされてたりします。そうすると顔画像を正しくフォルダに振り分け、余計なファイルを削除する作業が、25人分発生します。
一人当たり500枚×25人分 = 約12500枚を1枚1枚目視で正しいメンバーのフォルダに振り分け、削除。
ただでさえ上記のミスのせいで時間無駄にしていることもあり、この時期はイライラが半端なかったです。
MacのFinderを3つ開き、ひたすら確認・削除orドラッグ&ドロップしました。
嫌いではないですが、推しメンではないメンバーの時が精神的に辛かったですね...。
ただ、推しメンの田村保乃ちゃんの時は幸せでした。(1st写真集最高でした。3rdシングルセンター応援してます。)
一人振り分けるのに集中して20~30分はかかりました。とはいえ、集中力が続かずダラダラして25人振り分け終わるのに2日かかりました。(本当に辛かった)
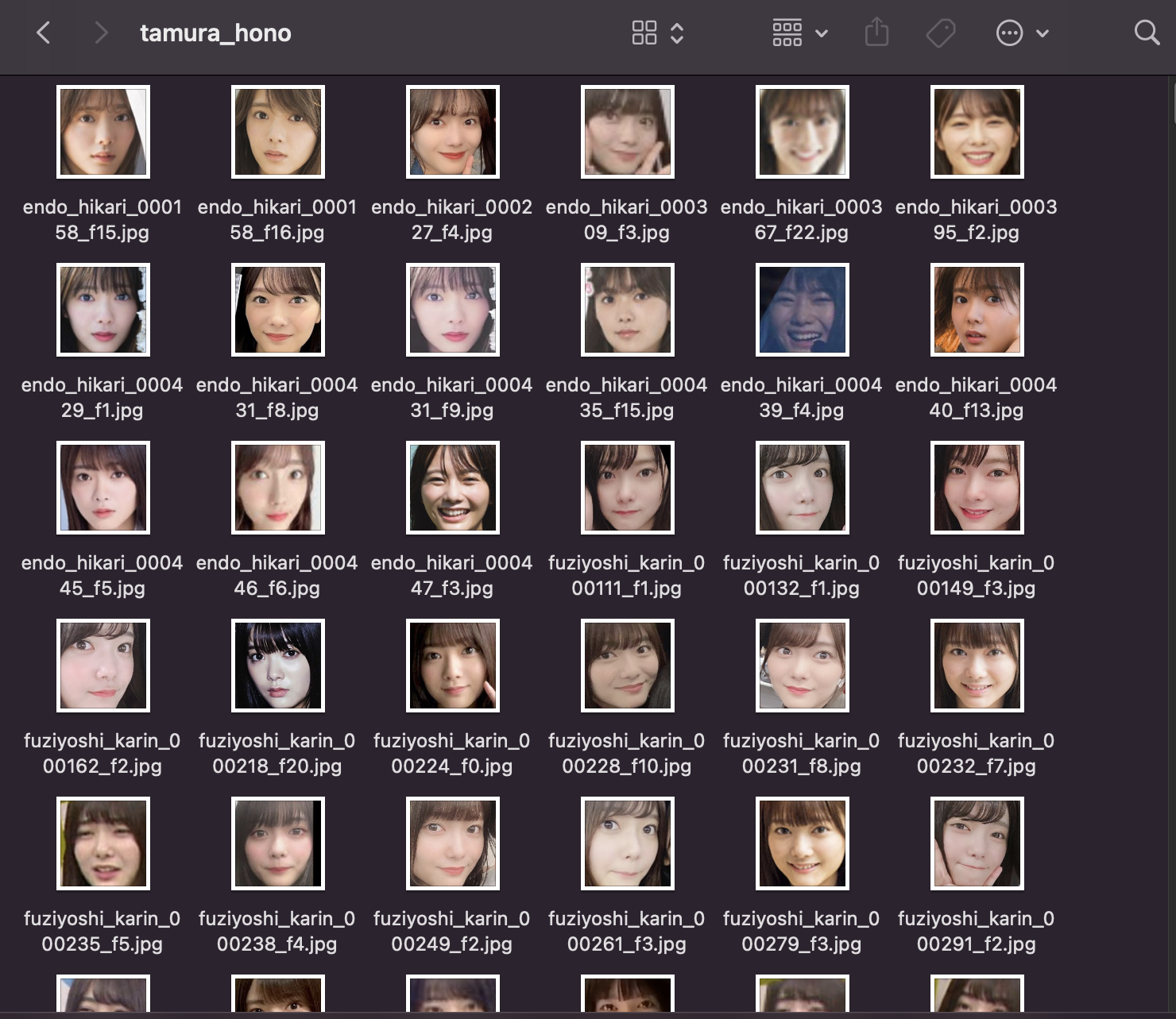
顔の部分だけちゃんと集められてますね。
それぞれのメンバーの画像枚数も調べておきます。
import os
import glob
for member_name in os.listdir('./face'):
print(member_name, ':', len(glob.glob('./face/' + member_name + '/*')), '枚')
harada_aoi : 394 枚
uemura_rina : 432 枚
ozeki_rika : 458 枚
inoue_rina : 492 枚
yamasaki_ten : 426 枚
morita_hikaru : 522 枚
endo_hikari : 361 枚
moriya_akane : 526 枚
seki_yumiko : 346 枚
moriya_rena : 389 枚
watanabe_rika : 433 枚
watanabe_risa : 606 枚
kobayashi_yui : 569 枚
fuziyoshi_karin : 521 枚
matuda_rina : 476 枚
sugai_yuka : 574 枚
koike_minami : 486 枚
saito_fuyuka : 281 枚
oozono_rei : 400 枚
takemoto_yui : 470 枚
masumoto_kira : 398 枚
tamura_hono : 686 枚
habu_miduho : 459 枚
oonuma_akiho : 263 枚
kousaka_marino : 363 枚
保乃ちゃんだけ圧倒的に多いのは何故でしょうかね()
やっぱりメンバーによって他のメンバーとよく自撮りしてたり、してなかったりというのがあるので、ばらつきはでますね。
4. データセットの用意
ここまでで画像フォルダの構成が以下。
# icawlerで集めてきた画像フォルダ
data/
├tamura_hono/
│ ├000001.jpg
│ ├000002.jpg
│ ├000003.jpg
│ │...
│
├morita_hikaru/
│...
# 顔部分を切り出し、正しく振り分けた顔画像フォルダ
face/
├tamura_hono/
│ ├tamura_hono_000001.jpg
│ ├tamura_hono_000002.jpg
│ ├tamura_hono_000003.jpg
│ │...
│
├morita_hikaru/
│...
ここからGCPのノートブックインスタンスに環境移動して実行していきます。
主にfaceフォルダの顔画像を、機械学習モデルに放り込める形にしていきます。
(まずGCP側に顔画像をアップロードするのが大変でしたが...)
画像の読み込みは色々なやり方があって、迷いました。
kaggleの画像コンペの上位スコア者のノートや調べた記事だけでも
・ImageDataGeneratorのジェネレータを使う方法
・画像データとラベルデータをnumpy配列で対応させる方法
・TFRecord形式で保存、読み込みする方法
などなど。
TensorFlowが推奨しているのはTFRecordですが、難しそうだったので今回は2番目の方法で行きました。
import os
import cv2
from sklearn.utils import shuffle
members = ['uemura_rina', 'ozeki_rika', 'koike_minami', 'kobayashi_yui', 'saito_fuyuka',
'sugai_yuka', 'habu_miduho', 'harada_aoi', 'moriya_akane', 'watanabe_rika', 'watanabe_risa',
'inoue_rina', 'endo_hikari', 'oozono_rei', 'oonuma_akiho', 'kousaka_marino', 'seki_yumiko',
'takemoto_yui', 'tamura_hono', 'fuziyoshi_karin', 'masumoto_kira', 'matuda_rina','morita_hikaru',
'moriya_rena', 'yamasaki_ten']
# メンバーの名前と番号の辞書を作るのは内包表記が便利
members_label = {member_name:i for i, member_name in enumerate(members)}
# このディレクトリ以下にある画像フォルダの画像が対象
base_dir = './face'
# 画像ファイルがあるフォルダから画像を取得、画像とラベルに分ける関数
def make_image_dataset(base_dir):
Images = []
Labels = []
label = 0
for label_name in os.listdir(base_dir):
label = members_label[label_name]
for image_file in os.listdir(base_dir + label_name):
image = cv2.imread(base_dir + label_name + '/' + image_file)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
Images.append(image_rgb)
Labels.append(label)
return shuffle(Images, Labels, random_state=397209)
Images, Labels = make_image_dataset(base_dir)
make_image_dataset関数で指定したディレクトリの画像を、画像とラベルのリストに分けます。
やっていることは、
①ImagesとLabelsの空のリストを定義
②それぞれのメンバーの名前を取得してそれと対応するラベル番号をlabelに代入
③そのメンバーの画像を取得して、カラー画像としてImagesリストに格納
④Labelsリストにlabelを格納
⑤最後にシャッフル
これで画像データとそれと対応したラベルデータに分けることができました。
5.画像の前処理
そのまま訓練データと検証データに分けてもいいですが、正規化して扱いやすい形にします。
import numpy as np
# 画像データとラベルデータをそれぞれndarray型に
Images = np.array(Images)
Labels = np.array(Labels)
# 画像データはここまでの段階だとuint8型なのでfloat32型にして255で割って正規化
Images = Images.astype("float32")
Images /= 255
# 構造の確認
Images.shape, Labels.shape
# ((11331, 128, 128, 3), (11331,))
uint8型の値の範囲が0~255の整数なので255で割ることで最小値0,最大値1とできる。
がuint8型のまま割ってしまうと整数値しか取らないので0か1か(白か黒でしか表現できない)の画像になるため、float32型にしてから255で割っています。
0~255の尺度を維持したまま0~1に直しているイメージ(で説明あっておりますかね...)
ちゃんとカラー画像として表示されるか確認してみましょう
import matplotlib.pyplot as plt
from random import randint
f,ax = plt.subplots(5,5)
f.subplots_adjust(0,0,3,3)
for i in range(0,5,1):
for j in range(0,5,1):
rnd_number = randint(0,len(Images))
ax[i,j].imshow(Images[rnd_number])
ax[i,j].set_title(get_class_label(Labels[rnd_number]))
ax[i,j].axis('off')

ちゃんとカラー画像でかつ、ラベル対応もしっかりしていますね。
6. データ分割・モデル構築
データ分割
学習データを訓練データと検証データに分けておきます。交差検証もやりたかったのですが、時間がかかりそうだったので、ホールドアウト法でいきました。
from sklearn.model_selection import train_test_split
from keras.utils.np_utils import to_categorical
n_categories = len(members) # メンバー数25人、25個のクラスに分ける
X_train, X_valid, y_train, y_valid = train_test_split(
Images, Labels, test_size=0.30, random_state=239995, stratify=Labels)
y_train = to_categorical(y_train, n_categories)
y_valid = to_categorical(y_valid, n_categories)
# データ数の確認
X_train.shape, X_valid.shape
# ((7931, 128, 128, 3), (3400, 128, 128, 3))
# 訓練データ 7931枚
# 検証データ 3400枚
今回は直感で訓練データと検証データの割合を7:3にしました。
stratify = Labelsでラベルの割合が均等になるようにしています。
最後にモデルの損失関数にcategorical_crossentropyを使うため、to_categoricalでラベルデータをone-hotエンコーディングして訓練できるように変形しています。
モデル構築
画像分析の醍醐味、モデル構築に入っていきます。
自分で1からモデル構築するとまぁ正答率が0.2000とか酷い有様だったのでコチラを参考に既存のモデルのファインチューニングで精度を出しに行きます。
記事にもあるようにVGG16で最初ファインチューニングをしてみたんですが、正答率がなかなか上がらず、0.6000ほどだったので今度はコチラを参考にResNet50モデルを使うことにしました。
とモデルの構築に行くわけですが、偉大な先人の方々からすれば「画像の水増ししないの?」とツッコミが入るかと思います。
実は3の画像の振り分けの段階で、やたら同じ画像(アー写など)があり、ちょっとだけ切り抜くエリアが違ってたりして「すでに水増し効果があるのでは?」と思ってやらなかっただけです。決してめんどくさかったわけじゃないですよ()
from tensorflow.keras.layers import *
from tensorflow.keras.models import Model, Sequential, load_model
from keras.applications.resnet50 import ResNet50
IMAGE_SIZE = 128
# 入力画像が(128, 128, 3)なのでこれをinput_tensorとして指定
input_tensor = Input(shape = (IMAGE_SIZE, IMAGE_SIZE, 3))
# 元々のResNet50の出力層が1000個の多クラス分類なので出力層が使えない
# include_top = Falseにすることで既存モデルの出力層を消せる
# weights = 'imagenet'にすることでimagenetの重みを使える。
ResNet50 = ResNet50(include_top=False, weights='imagenet', input_tensor=input_tensor)
次にこのResNet50モデルにつなぐ全結合層を構築していきます。
top_model = Sequential()
# Resnet50.output_shape = (None, 4, 4, 2048)なのでスライス指定
top_model.add(Flatten(input_shape = ResNet50.output_shape[1:]))
top_model.add(Dense(1024, activation = 'relu'))
top_model.add(Dense(256, activation = 'relu'))
top_model.add(Dense(128, activation = 'relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(n_categories, activation = 'softmax'))
# Resnet50モデルと全結合層を結合させる
# top_model(ResNet50.output)で全結合層にResnet50の出力を当てた時の全結合層の出力が返ってくる
full_model = Model(inputs = ResNet50.input, outputs = top_model(ResNet50.output))
# モデル要約
full_model.summary()
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 128, 128, 3) 0
__________________________________________________________________________________________________
conv1_pad (ZeroPadding2D) (None, 134, 134, 3) 0 input_1[0][0]
__________________________________________________________________________________________________
conv1_conv (Conv2D) (None, 64, 64, 64) 9472 conv1_pad[0][0]
__________________________________________________________________________________________________
conv1_bn (BatchNormalization) (None, 64, 64, 64) 256 conv1_conv[0][0]
__________________________________________________________________________________________________
conv1_relu (Activation) (None, 64, 64, 64) 0 conv1_bn[0][0]
__________________________________________________________________________________________________
pool1_pad (ZeroPadding2D) (None, 66, 66, 64) 0 conv1_relu[0][0]
__________________________________________________________________________________________________
pool1_pool (MaxPooling2D) (None, 32, 32, 64) 0 pool1_pad[0][0]
__________________________________________________________________________________________________
conv2_block1_1_conv (Conv2D) (None, 32, 32, 64) 4160 pool1_pool[0][0]
__________________________________________________________________________________________________
conv2_block1_1_bn (BatchNormali (None, 32, 32, 64) 256 conv2_block1_1_conv[0][0]
__________________________________________________________________________________________________
conv2_block1_1_relu (Activation (None, 32, 32, 64) 0 conv2_block1_1_bn[0][0]
__________________________________________________________________________________________________
conv2_block1_2_conv (Conv2D) (None, 32, 32, 64) 36928 conv2_block1_1_relu[0][0]
__________________________________________________________________________________________________
conv2_block1_2_bn (BatchNormali (None, 32, 32, 64) 256 conv2_block1_2_conv[0][0]
__________________________________________________________________________________________________
conv2_block1_2_relu (Activation (None, 32, 32, 64) 0 conv2_block1_2_bn[0][0]
__________________________________________________________________________________________________
conv2_block1_0_conv (Conv2D) (None, 32, 32, 256) 16640 pool1_pool[0][0]
__________________________________________________________________________________________________
conv2_block1_3_conv (Conv2D) (None, 32, 32, 256) 16640 conv2_block1_2_relu[0][0]
__________________________________________________________________________________________________
conv2_block1_0_bn (BatchNormali (None, 32, 32, 256) 1024 conv2_block1_0_conv[0][0]
__________________________________________________________________________________________________
conv2_block1_3_bn (BatchNormali (None, 32, 32, 256) 1024 conv2_block1_3_conv[0][0]
__________________________________________________________________________________________________
conv2_block1_add (Add) (None, 32, 32, 256) 0 conv2_block1_0_bn[0][0]
conv2_block1_3_bn[0][0]
__________________________________________________________________________________________________
conv2_block1_out (Activation) (None, 32, 32, 256) 0 conv2_block1_add[0][0]
__________________________________________________________________________________________________
conv2_block2_1_conv (Conv2D) (None, 32, 32, 64) 16448 conv2_block1_out[0][0]
__________________________________________________________________________________________________
conv2_block2_1_bn (BatchNormali (None, 32, 32, 64) 256 conv2_block2_1_conv[0][0]
__________________________________________________________________________________________________
conv2_block2_1_relu (Activation (None, 32, 32, 64) 0 conv2_block2_1_bn[0][0]
__________________________________________________________________________________________________
conv2_block2_2_conv (Conv2D) (None, 32, 32, 64) 36928 conv2_block2_1_relu[0][0]
__________________________________________________________________________________________________
conv2_block2_2_bn (BatchNormali (None, 32, 32, 64) 256 conv2_block2_2_conv[0][0]
__________________________________________________________________________________________________
conv2_block2_2_relu (Activation (None, 32, 32, 64) 0 conv2_block2_2_bn[0][0]
__________________________________________________________________________________________________
conv2_block2_3_conv (Conv2D) (None, 32, 32, 256) 16640 conv2_block2_2_relu[0][0]
__________________________________________________________________________________________________
conv2_block2_3_bn (BatchNormali (None, 32, 32, 256) 1024 conv2_block2_3_conv[0][0]
__________________________________________________________________________________________________
conv2_block2_add (Add) (None, 32, 32, 256) 0 conv2_block1_out[0][0]
conv2_block2_3_bn[0][0]
__________________________________________________________________________________________________
conv2_block2_out (Activation) (None, 32, 32, 256) 0 conv2_block2_add[0][0]
__________________________________________________________________________________________________
conv2_block3_1_conv (Conv2D) (None, 32, 32, 64) 16448 conv2_block2_out[0][0]
__________________________________________________________________________________________________
conv2_block3_1_bn (BatchNormali (None, 32, 32, 64) 256 conv2_block3_1_conv[0][0]
__________________________________________________________________________________________________
conv2_block3_1_relu (Activation (None, 32, 32, 64) 0 conv2_block3_1_bn[0][0]
__________________________________________________________________________________________________
conv2_block3_2_conv (Conv2D) (None, 32, 32, 64) 36928 conv2_block3_1_relu[0][0]
__________________________________________________________________________________________________
conv2_block3_2_bn (BatchNormali (None, 32, 32, 64) 256 conv2_block3_2_conv[0][0]
__________________________________________________________________________________________________
conv2_block3_2_relu (Activation (None, 32, 32, 64) 0 conv2_block3_2_bn[0][0]
__________________________________________________________________________________________________
conv2_block3_3_conv (Conv2D) (None, 32, 32, 256) 16640 conv2_block3_2_relu[0][0]
__________________________________________________________________________________________________
conv2_block3_3_bn (BatchNormali (None, 32, 32, 256) 1024 conv2_block3_3_conv[0][0]
__________________________________________________________________________________________________
conv2_block3_add (Add) (None, 32, 32, 256) 0 conv2_block2_out[0][0]
conv2_block3_3_bn[0][0]
__________________________________________________________________________________________________
conv2_block3_out (Activation) (None, 32, 32, 256) 0 conv2_block3_add[0][0]
__________________________________________________________________________________________________
conv3_block1_1_conv (Conv2D) (None, 16, 16, 128) 32896 conv2_block3_out[0][0]
__________________________________________________________________________________________________
conv3_block1_1_bn (BatchNormali (None, 16, 16, 128) 512 conv3_block1_1_conv[0][0]
__________________________________________________________________________________________________
conv3_block1_1_relu (Activation (None, 16, 16, 128) 0 conv3_block1_1_bn[0][0]
__________________________________________________________________________________________________
conv3_block1_2_conv (Conv2D) (None, 16, 16, 128) 147584 conv3_block1_1_relu[0][0]
__________________________________________________________________________________________________
conv3_block1_2_bn (BatchNormali (None, 16, 16, 128) 512 conv3_block1_2_conv[0][0]
__________________________________________________________________________________________________
conv3_block1_2_relu (Activation (None, 16, 16, 128) 0 conv3_block1_2_bn[0][0]
__________________________________________________________________________________________________
conv3_block1_0_conv (Conv2D) (None, 16, 16, 512) 131584 conv2_block3_out[0][0]
__________________________________________________________________________________________________
conv3_block1_3_conv (Conv2D) (None, 16, 16, 512) 66048 conv3_block1_2_relu[0][0]
__________________________________________________________________________________________________
conv3_block1_0_bn (BatchNormali (None, 16, 16, 512) 2048 conv3_block1_0_conv[0][0]
__________________________________________________________________________________________________
conv3_block1_3_bn (BatchNormali (None, 16, 16, 512) 2048 conv3_block1_3_conv[0][0]
__________________________________________________________________________________________________
conv3_block1_add (Add) (None, 16, 16, 512) 0 conv3_block1_0_bn[0][0]
conv3_block1_3_bn[0][0]
__________________________________________________________________________________________________
conv3_block1_out (Activation) (None, 16, 16, 512) 0 conv3_block1_add[0][0]
__________________________________________________________________________________________________
conv3_block2_1_conv (Conv2D) (None, 16, 16, 128) 65664 conv3_block1_out[0][0]
__________________________________________________________________________________________________
conv3_block2_1_bn (BatchNormali (None, 16, 16, 128) 512 conv3_block2_1_conv[0][0]
__________________________________________________________________________________________________
conv3_block2_1_relu (Activation (None, 16, 16, 128) 0 conv3_block2_1_bn[0][0]
__________________________________________________________________________________________________
conv3_block2_2_conv (Conv2D) (None, 16, 16, 128) 147584 conv3_block2_1_relu[0][0]
__________________________________________________________________________________________________
conv3_block2_2_bn (BatchNormali (None, 16, 16, 128) 512 conv3_block2_2_conv[0][0]
__________________________________________________________________________________________________
conv3_block2_2_relu (Activation (None, 16, 16, 128) 0 conv3_block2_2_bn[0][0]
__________________________________________________________________________________________________
conv3_block2_3_conv (Conv2D) (None, 16, 16, 512) 66048 conv3_block2_2_relu[0][0]
__________________________________________________________________________________________________
conv3_block2_3_bn (BatchNormali (None, 16, 16, 512) 2048 conv3_block2_3_conv[0][0]
__________________________________________________________________________________________________
conv3_block2_add (Add) (None, 16, 16, 512) 0 conv3_block1_out[0][0]
conv3_block2_3_bn[0][0]
__________________________________________________________________________________________________
conv3_block2_out (Activation) (None, 16, 16, 512) 0 conv3_block2_add[0][0]
__________________________________________________________________________________________________
conv3_block3_1_conv (Conv2D) (None, 16, 16, 128) 65664 conv3_block2_out[0][0]
__________________________________________________________________________________________________
conv3_block3_1_bn (BatchNormali (None, 16, 16, 128) 512 conv3_block3_1_conv[0][0]
__________________________________________________________________________________________________
conv3_block3_1_relu (Activation (None, 16, 16, 128) 0 conv3_block3_1_bn[0][0]
__________________________________________________________________________________________________
conv3_block3_2_conv (Conv2D) (None, 16, 16, 128) 147584 conv3_block3_1_relu[0][0]
__________________________________________________________________________________________________
conv3_block3_2_bn (BatchNormali (None, 16, 16, 128) 512 conv3_block3_2_conv[0][0]
__________________________________________________________________________________________________
conv3_block3_2_relu (Activation (None, 16, 16, 128) 0 conv3_block3_2_bn[0][0]
__________________________________________________________________________________________________
conv3_block3_3_conv (Conv2D) (None, 16, 16, 512) 66048 conv3_block3_2_relu[0][0]
__________________________________________________________________________________________________
conv3_block3_3_bn (BatchNormali (None, 16, 16, 512) 2048 conv3_block3_3_conv[0][0]
__________________________________________________________________________________________________
conv3_block3_add (Add) (None, 16, 16, 512) 0 conv3_block2_out[0][0]
conv3_block3_3_bn[0][0]
__________________________________________________________________________________________________
conv3_block3_out (Activation) (None, 16, 16, 512) 0 conv3_block3_add[0][0]
__________________________________________________________________________________________________
conv3_block4_1_conv (Conv2D) (None, 16, 16, 128) 65664 conv3_block3_out[0][0]
__________________________________________________________________________________________________
conv3_block4_1_bn (BatchNormali (None, 16, 16, 128) 512 conv3_block4_1_conv[0][0]
__________________________________________________________________________________________________
conv3_block4_1_relu (Activation (None, 16, 16, 128) 0 conv3_block4_1_bn[0][0]
__________________________________________________________________________________________________
conv3_block4_2_conv (Conv2D) (None, 16, 16, 128) 147584 conv3_block4_1_relu[0][0]
__________________________________________________________________________________________________
conv3_block4_2_bn (BatchNormali (None, 16, 16, 128) 512 conv3_block4_2_conv[0][0]
__________________________________________________________________________________________________
conv3_block4_2_relu (Activation (None, 16, 16, 128) 0 conv3_block4_2_bn[0][0]
__________________________________________________________________________________________________
conv3_block4_3_conv (Conv2D) (None, 16, 16, 512) 66048 conv3_block4_2_relu[0][0]
__________________________________________________________________________________________________
conv3_block4_3_bn (BatchNormali (None, 16, 16, 512) 2048 conv3_block4_3_conv[0][0]
__________________________________________________________________________________________________
conv3_block4_add (Add) (None, 16, 16, 512) 0 conv3_block3_out[0][0]
conv3_block4_3_bn[0][0]
__________________________________________________________________________________________________
conv3_block4_out (Activation) (None, 16, 16, 512) 0 conv3_block4_add[0][0]
__________________________________________________________________________________________________
conv4_block1_1_conv (Conv2D) (None, 8, 8, 256) 131328 conv3_block4_out[0][0]
__________________________________________________________________________________________________
conv4_block1_1_bn (BatchNormali (None, 8, 8, 256) 1024 conv4_block1_1_conv[0][0]
__________________________________________________________________________________________________
conv4_block1_1_relu (Activation (None, 8, 8, 256) 0 conv4_block1_1_bn[0][0]
__________________________________________________________________________________________________
conv4_block1_2_conv (Conv2D) (None, 8, 8, 256) 590080 conv4_block1_1_relu[0][0]
__________________________________________________________________________________________________
conv4_block1_2_bn (BatchNormali (None, 8, 8, 256) 1024 conv4_block1_2_conv[0][0]
__________________________________________________________________________________________________
conv4_block1_2_relu (Activation (None, 8, 8, 256) 0 conv4_block1_2_bn[0][0]
__________________________________________________________________________________________________
conv4_block1_0_conv (Conv2D) (None, 8, 8, 1024) 525312 conv3_block4_out[0][0]
__________________________________________________________________________________________________
conv4_block1_3_conv (Conv2D) (None, 8, 8, 1024) 263168 conv4_block1_2_relu[0][0]
__________________________________________________________________________________________________
conv4_block1_0_bn (BatchNormali (None, 8, 8, 1024) 4096 conv4_block1_0_conv[0][0]
__________________________________________________________________________________________________
conv4_block1_3_bn (BatchNormali (None, 8, 8, 1024) 4096 conv4_block1_3_conv[0][0]
__________________________________________________________________________________________________
conv4_block1_add (Add) (None, 8, 8, 1024) 0 conv4_block1_0_bn[0][0]
conv4_block1_3_bn[0][0]
__________________________________________________________________________________________________
conv4_block1_out (Activation) (None, 8, 8, 1024) 0 conv4_block1_add[0][0]
__________________________________________________________________________________________________
conv4_block2_1_conv (Conv2D) (None, 8, 8, 256) 262400 conv4_block1_out[0][0]
__________________________________________________________________________________________________
conv4_block2_1_bn (BatchNormali (None, 8, 8, 256) 1024 conv4_block2_1_conv[0][0]
__________________________________________________________________________________________________
conv4_block2_1_relu (Activation (None, 8, 8, 256) 0 conv4_block2_1_bn[0][0]
__________________________________________________________________________________________________
conv4_block2_2_conv (Conv2D) (None, 8, 8, 256) 590080 conv4_block2_1_relu[0][0]
__________________________________________________________________________________________________
conv4_block2_2_bn (BatchNormali (None, 8, 8, 256) 1024 conv4_block2_2_conv[0][0]
__________________________________________________________________________________________________
conv4_block2_2_relu (Activation (None, 8, 8, 256) 0 conv4_block2_2_bn[0][0]
__________________________________________________________________________________________________
conv4_block2_3_conv (Conv2D) (None, 8, 8, 1024) 263168 conv4_block2_2_relu[0][0]
__________________________________________________________________________________________________
conv4_block2_3_bn (BatchNormali (None, 8, 8, 1024) 4096 conv4_block2_3_conv[0][0]
__________________________________________________________________________________________________
conv4_block2_add (Add) (None, 8, 8, 1024) 0 conv4_block1_out[0][0]
conv4_block2_3_bn[0][0]
__________________________________________________________________________________________________
conv4_block2_out (Activation) (None, 8, 8, 1024) 0 conv4_block2_add[0][0]
__________________________________________________________________________________________________
conv4_block3_1_conv (Conv2D) (None, 8, 8, 256) 262400 conv4_block2_out[0][0]
__________________________________________________________________________________________________
conv4_block3_1_bn (BatchNormali (None, 8, 8, 256) 1024 conv4_block3_1_conv[0][0]
__________________________________________________________________________________________________
conv4_block3_1_relu (Activation (None, 8, 8, 256) 0 conv4_block3_1_bn[0][0]
__________________________________________________________________________________________________
conv4_block3_2_conv (Conv2D) (None, 8, 8, 256) 590080 conv4_block3_1_relu[0][0]
__________________________________________________________________________________________________
conv4_block3_2_bn (BatchNormali (None, 8, 8, 256) 1024 conv4_block3_2_conv[0][0]
__________________________________________________________________________________________________
conv4_block3_2_relu (Activation (None, 8, 8, 256) 0 conv4_block3_2_bn[0][0]
__________________________________________________________________________________________________
conv4_block3_3_conv (Conv2D) (None, 8, 8, 1024) 263168 conv4_block3_2_relu[0][0]
__________________________________________________________________________________________________
conv4_block3_3_bn (BatchNormali (None, 8, 8, 1024) 4096 conv4_block3_3_conv[0][0]
__________________________________________________________________________________________________
conv4_block3_add (Add) (None, 8, 8, 1024) 0 conv4_block2_out[0][0]
conv4_block3_3_bn[0][0]
__________________________________________________________________________________________________
conv4_block3_out (Activation) (None, 8, 8, 1024) 0 conv4_block3_add[0][0]
__________________________________________________________________________________________________
conv4_block4_1_conv (Conv2D) (None, 8, 8, 256) 262400 conv4_block3_out[0][0]
__________________________________________________________________________________________________
conv4_block4_1_bn (BatchNormali (None, 8, 8, 256) 1024 conv4_block4_1_conv[0][0]
__________________________________________________________________________________________________
conv4_block4_1_relu (Activation (None, 8, 8, 256) 0 conv4_block4_1_bn[0][0]
__________________________________________________________________________________________________
conv4_block4_2_conv (Conv2D) (None, 8, 8, 256) 590080 conv4_block4_1_relu[0][0]
__________________________________________________________________________________________________
conv4_block4_2_bn (BatchNormali (None, 8, 8, 256) 1024 conv4_block4_2_conv[0][0]
__________________________________________________________________________________________________
conv4_block4_2_relu (Activation (None, 8, 8, 256) 0 conv4_block4_2_bn[0][0]
__________________________________________________________________________________________________
conv4_block4_3_conv (Conv2D) (None, 8, 8, 1024) 263168 conv4_block4_2_relu[0][0]
__________________________________________________________________________________________________
conv4_block4_3_bn (BatchNormali (None, 8, 8, 1024) 4096 conv4_block4_3_conv[0][0]
__________________________________________________________________________________________________
conv4_block4_add (Add) (None, 8, 8, 1024) 0 conv4_block3_out[0][0]
conv4_block4_3_bn[0][0]
__________________________________________________________________________________________________
conv4_block4_out (Activation) (None, 8, 8, 1024) 0 conv4_block4_add[0][0]
__________________________________________________________________________________________________
conv4_block5_1_conv (Conv2D) (None, 8, 8, 256) 262400 conv4_block4_out[0][0]
__________________________________________________________________________________________________
conv4_block5_1_bn (BatchNormali (None, 8, 8, 256) 1024 conv4_block5_1_conv[0][0]
__________________________________________________________________________________________________
conv4_block5_1_relu (Activation (None, 8, 8, 256) 0 conv4_block5_1_bn[0][0]
__________________________________________________________________________________________________
conv4_block5_2_conv (Conv2D) (None, 8, 8, 256) 590080 conv4_block5_1_relu[0][0]
__________________________________________________________________________________________________
conv4_block5_2_bn (BatchNormali (None, 8, 8, 256) 1024 conv4_block5_2_conv[0][0]
__________________________________________________________________________________________________
conv4_block5_2_relu (Activation (None, 8, 8, 256) 0 conv4_block5_2_bn[0][0]
__________________________________________________________________________________________________
conv4_block5_3_conv (Conv2D) (None, 8, 8, 1024) 263168 conv4_block5_2_relu[0][0]
__________________________________________________________________________________________________
conv4_block5_3_bn (BatchNormali (None, 8, 8, 1024) 4096 conv4_block5_3_conv[0][0]
__________________________________________________________________________________________________
conv4_block5_add (Add) (None, 8, 8, 1024) 0 conv4_block4_out[0][0]
conv4_block5_3_bn[0][0]
__________________________________________________________________________________________________
conv4_block5_out (Activation) (None, 8, 8, 1024) 0 conv4_block5_add[0][0]
__________________________________________________________________________________________________
conv4_block6_1_conv (Conv2D) (None, 8, 8, 256) 262400 conv4_block5_out[0][0]
__________________________________________________________________________________________________
conv4_block6_1_bn (BatchNormali (None, 8, 8, 256) 1024 conv4_block6_1_conv[0][0]
__________________________________________________________________________________________________
conv4_block6_1_relu (Activation (None, 8, 8, 256) 0 conv4_block6_1_bn[0][0]
__________________________________________________________________________________________________
conv4_block6_2_conv (Conv2D) (None, 8, 8, 256) 590080 conv4_block6_1_relu[0][0]
__________________________________________________________________________________________________
conv4_block6_2_bn (BatchNormali (None, 8, 8, 256) 1024 conv4_block6_2_conv[0][0]
__________________________________________________________________________________________________
conv4_block6_2_relu (Activation (None, 8, 8, 256) 0 conv4_block6_2_bn[0][0]
__________________________________________________________________________________________________
conv4_block6_3_conv (Conv2D) (None, 8, 8, 1024) 263168 conv4_block6_2_relu[0][0]
__________________________________________________________________________________________________
conv4_block6_3_bn (BatchNormali (None, 8, 8, 1024) 4096 conv4_block6_3_conv[0][0]
__________________________________________________________________________________________________
conv4_block6_add (Add) (None, 8, 8, 1024) 0 conv4_block5_out[0][0]
conv4_block6_3_bn[0][0]
__________________________________________________________________________________________________
conv4_block6_out (Activation) (None, 8, 8, 1024) 0 conv4_block6_add[0][0]
__________________________________________________________________________________________________
conv5_block1_1_conv (Conv2D) (None, 4, 4, 512) 524800 conv4_block6_out[0][0]
__________________________________________________________________________________________________
conv5_block1_1_bn (BatchNormali (None, 4, 4, 512) 2048 conv5_block1_1_conv[0][0]
__________________________________________________________________________________________________
conv5_block1_1_relu (Activation (None, 4, 4, 512) 0 conv5_block1_1_bn[0][0]
__________________________________________________________________________________________________
conv5_block1_2_conv (Conv2D) (None, 4, 4, 512) 2359808 conv5_block1_1_relu[0][0]
__________________________________________________________________________________________________
conv5_block1_2_bn (BatchNormali (None, 4, 4, 512) 2048 conv5_block1_2_conv[0][0]
__________________________________________________________________________________________________
conv5_block1_2_relu (Activation (None, 4, 4, 512) 0 conv5_block1_2_bn[0][0]
__________________________________________________________________________________________________
conv5_block1_0_conv (Conv2D) (None, 4, 4, 2048) 2099200 conv4_block6_out[0][0]
__________________________________________________________________________________________________
conv5_block1_3_conv (Conv2D) (None, 4, 4, 2048) 1050624 conv5_block1_2_relu[0][0]
__________________________________________________________________________________________________
conv5_block1_0_bn (BatchNormali (None, 4, 4, 2048) 8192 conv5_block1_0_conv[0][0]
__________________________________________________________________________________________________
conv5_block1_3_bn (BatchNormali (None, 4, 4, 2048) 8192 conv5_block1_3_conv[0][0]
__________________________________________________________________________________________________
conv5_block1_add (Add) (None, 4, 4, 2048) 0 conv5_block1_0_bn[0][0]
conv5_block1_3_bn[0][0]
__________________________________________________________________________________________________
conv5_block1_out (Activation) (None, 4, 4, 2048) 0 conv5_block1_add[0][0]
__________________________________________________________________________________________________
conv5_block2_1_conv (Conv2D) (None, 4, 4, 512) 1049088 conv5_block1_out[0][0]
__________________________________________________________________________________________________
conv5_block2_1_bn (BatchNormali (None, 4, 4, 512) 2048 conv5_block2_1_conv[0][0]
__________________________________________________________________________________________________
conv5_block2_1_relu (Activation (None, 4, 4, 512) 0 conv5_block2_1_bn[0][0]
__________________________________________________________________________________________________
conv5_block2_2_conv (Conv2D) (None, 4, 4, 512) 2359808 conv5_block2_1_relu[0][0]
__________________________________________________________________________________________________
conv5_block2_2_bn (BatchNormali (None, 4, 4, 512) 2048 conv5_block2_2_conv[0][0]
__________________________________________________________________________________________________
conv5_block2_2_relu (Activation (None, 4, 4, 512) 0 conv5_block2_2_bn[0][0]
__________________________________________________________________________________________________
conv5_block2_3_conv (Conv2D) (None, 4, 4, 2048) 1050624 conv5_block2_2_relu[0][0]
__________________________________________________________________________________________________
conv5_block2_3_bn (BatchNormali (None, 4, 4, 2048) 8192 conv5_block2_3_conv[0][0]
__________________________________________________________________________________________________
conv5_block2_add (Add) (None, 4, 4, 2048) 0 conv5_block1_out[0][0]
conv5_block2_3_bn[0][0]
__________________________________________________________________________________________________
conv5_block2_out (Activation) (None, 4, 4, 2048) 0 conv5_block2_add[0][0]
__________________________________________________________________________________________________
conv5_block3_1_conv (Conv2D) (None, 4, 4, 512) 1049088 conv5_block2_out[0][0]
__________________________________________________________________________________________________
conv5_block3_1_bn (BatchNormali (None, 4, 4, 512) 2048 conv5_block3_1_conv[0][0]
__________________________________________________________________________________________________
conv5_block3_1_relu (Activation (None, 4, 4, 512) 0 conv5_block3_1_bn[0][0]
__________________________________________________________________________________________________
conv5_block3_2_conv (Conv2D) (None, 4, 4, 512) 2359808 conv5_block3_1_relu[0][0]
__________________________________________________________________________________________________
conv5_block3_2_bn (BatchNormali (None, 4, 4, 512) 2048 conv5_block3_2_conv[0][0]
__________________________________________________________________________________________________
conv5_block3_2_relu (Activation (None, 4, 4, 512) 0 conv5_block3_2_bn[0][0]
__________________________________________________________________________________________________
conv5_block3_3_conv (Conv2D) (None, 4, 4, 2048) 1050624 conv5_block3_2_relu[0][0]
__________________________________________________________________________________________________
conv5_block3_3_bn (BatchNormali (None, 4, 4, 2048) 8192 conv5_block3_3_conv[0][0]
__________________________________________________________________________________________________
conv5_block3_add (Add) (None, 4, 4, 2048) 0 conv5_block2_out[0][0]
conv5_block3_3_bn[0][0]
__________________________________________________________________________________________________
conv5_block3_out (Activation) (None, 4, 4, 2048) 0 conv5_block3_add[0][0]
__________________________________________________________________________________________________
sequential (Sequential) (None, 25) 33853977 conv5_block3_out[0][0]
==================================================================================================
Total params: 57,441,689
Trainable params: 57,388,569
Non-trainable params: 53,120
__________________________________________________________________________________________________
長いですね。全結合層の構築は他の記事も参考にしつつ完全に直感です。Flatten層をGlobalAveragePooling2D層にすることでパラメータ数が減り、過学習が抑えられるそうですが、そもそも学習不足気味だったので採用せず。ただ何も対策しないのもなと思って一番最後にDropout層だけ入れています。
また今回は25クラスの多クラス分類のため活性化関数をsoftmaxに。それ以外のDense層はreluです。
また
from keras.utils import plot_model
plot_model(full_model, to_file='model.png')
上記コードでモデル図を出力・保存できるので一応しておきました。
7. モデルの学習・評価・保存
いよいよGCPのGPUを使って学習をしていきます。
コールバックはearly_stoppingだけ採用しました。
コールバックに関してはコチラを参考にさせて頂きました。
import tensorflow as tf
from tensorflow.keras.callbacks import EarlyStopping
# モデルのコンパイル
full_model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.001, momentum=0.9),
loss = 'categorical_crossentropy',
metrics=['accuracy'])
# 過学習の抑制
early_stopping = EarlyStopping(monitor='val_loss',
patience=10,
verbose=1,
mode= 'auto')
optimizerはAdamと迷いましたが、調べた感じSGDの方が多かったのでSGDで。
※後でAdamで学習したところ、正答率0.0500とかで一向に正答率が伸びず。
損失関数変えるだけで結果が大きく変わるのも面白いですね。
損失関数は先ほど目的変数をto_categoricalでone-hotエンコーディングしたのでcategorical_crossentropyを使います。
sparse_categorical_crossentropyもありますが、コチラは目的変数がone-hotではなく整数ラベルの時に使うものです。間違えないように注意ですね。
# バッチ数、イテレーション回数、エポック数の定義
BATCH_SIZE = 32
steps_per_epoch = X_train.shape[0] / BATCH_SIZE
epochs = 35
history = full_model.fit(X_train, y_train, validation_data=(X_valid, y_valid),
batch_size = BATCH_SIZE, epochs = epochs, verbose = 1,
steps_per_epoch=steps_per_epoch,
callbacks = [early_stopping])
Epoch 1/35
247/247 [==============================] - 85s 313ms/step - loss: 3.1359 - accuracy: 0.1009 - val_loss: 3.8423 - val_accuracy: 0.0506
Epoch 2/35
247/247 [==============================] - 74s 299ms/step - loss: 2.4208 - accuracy: 0.2996 - val_loss: 3.5774 - val_accuracy: 0.0391
Epoch 3/35
247/247 [==============================] - 74s 300ms/step - loss: 1.5345 - accuracy: 0.5511 - val_loss: 3.1046 - val_accuracy: 0.1215
Epoch 4/35
247/247 [==============================] - 74s 300ms/step - loss: 0.8539 - accuracy: 0.7568 - val_loss: 2.3647 - val_accuracy: 0.3762
Epoch 5/35
247/247 [==============================] - 74s 300ms/step - loss: 0.4527 - accuracy: 0.8735 - val_loss: 1.0029 - val_accuracy: 0.7294
Epoch 6/35
247/247 [==============================] - 74s 300ms/step - loss: 0.2505 - accuracy: 0.9262 - val_loss: 1.5250 - val_accuracy: 0.6347
Epoch 7/35
247/247 [==============================] - 74s 300ms/step - loss: 0.1929 - accuracy: 0.9448 - val_loss: 0.9628 - val_accuracy: 0.7694
Epoch 8/35
247/247 [==============================] - 74s 300ms/step - loss: 0.1624 - accuracy: 0.9569 - val_loss: 1.0021 - val_accuracy: 0.7674
Epoch 9/35
247/247 [==============================] - 74s 299ms/step - loss: 0.1041 - accuracy: 0.9729 - val_loss: 0.9844 - val_accuracy: 0.7797
Epoch 10/35
247/247 [==============================] - 74s 299ms/step - loss: 0.0721 - accuracy: 0.9808 - val_loss: 0.7825 - val_accuracy: 0.8247
Epoch 11/35
247/247 [==============================] - 74s 299ms/step - loss: 0.0542 - accuracy: 0.9847 - val_loss: 0.9947 - val_accuracy: 0.7900
Epoch 12/35
247/247 [==============================] - 74s 299ms/step - loss: 0.0490 - accuracy: 0.9860 - val_loss: 0.7985 - val_accuracy: 0.8324
Epoch 13/35
247/247 [==============================] - 74s 299ms/step - loss: 0.0489 - accuracy: 0.9879 - val_loss: 1.6505 - val_accuracy: 0.6779
Epoch 14/35
247/247 [==============================] - 74s 299ms/step - loss: 0.0386 - accuracy: 0.9897 - val_loss: 1.3409 - val_accuracy: 0.7312
Epoch 15/35
247/247 [==============================] - 74s 299ms/step - loss: 0.0498 - accuracy: 0.9873 - val_loss: 1.3129 - val_accuracy: 0.7035
Epoch 16/35
247/247 [==============================] - 74s 300ms/step - loss: 0.0416 - accuracy: 0.9878 - val_loss: 0.9327 - val_accuracy: 0.7979
Epoch 17/35
247/247 [==============================] - 74s 300ms/step - loss: 0.0418 - accuracy: 0.9885 - val_loss: 0.8156 - val_accuracy: 0.8306
Epoch 18/35
247/247 [==============================] - 74s 300ms/step - loss: 0.0311 - accuracy: 0.9938 - val_loss: 0.8121 - val_accuracy: 0.8318
Epoch 19/35
247/247 [==============================] - 74s 300ms/step - loss: 0.0222 - accuracy: 0.9939 - val_loss: 1.2249 - val_accuracy: 0.7388
Epoch 20/35
247/247 [==============================] - 74s 300ms/step - loss: 0.0203 - accuracy: 0.9952 - val_loss: 0.6743 - val_accuracy: 0.8638
Epoch 21/35
247/247 [==============================] - 74s 300ms/step - loss: 0.0243 - accuracy: 0.9938 - val_loss: 0.7494 - val_accuracy: 0.8591
Epoch 22/35
247/247 [==============================] - 74s 300ms/step - loss: 0.0107 - accuracy: 0.9972 - val_loss: 0.7527 - val_accuracy: 0.8544
Epoch 23/35
247/247 [==============================] - 74s 299ms/step - loss: 0.0098 - accuracy: 0.9979 - val_loss: 0.6411 - val_accuracy: 0.8797
Epoch 24/35
247/247 [==============================] - 74s 301ms/step - loss: 0.0131 - accuracy: 0.9971 - val_loss: 0.6830 - val_accuracy: 0.8691
Epoch 25/35
247/247 [==============================] - 74s 300ms/step - loss: 0.0126 - accuracy: 0.9966 - val_loss: 0.6950 - val_accuracy: 0.8744
Epoch 26/35
247/247 [==============================] - 74s 300ms/step - loss: 0.0106 - accuracy: 0.9977 - val_loss: 0.7158 - val_accuracy: 0.8712
Epoch 27/35
247/247 [==============================] - 74s 299ms/step - loss: 0.0093 - accuracy: 0.9975 - val_loss: 0.8037 - val_accuracy: 0.8597
Epoch 28/35
247/247 [==============================] - 74s 299ms/step - loss: 0.0140 - accuracy: 0.9971 - val_loss: 0.7373 - val_accuracy: 0.8606
Epoch 29/35
247/247 [==============================] - 74s 299ms/step - loss: 0.0084 - accuracy: 0.9979 - val_loss: 0.6850 - val_accuracy: 0.8776
Epoch 30/35
247/247 [==============================] - 74s 300ms/step - loss: 0.0083 - accuracy: 0.9980 - val_loss: 0.7689 - val_accuracy: 0.8718
Epoch 31/35
247/247 [==============================] - 74s 300ms/step - loss: 0.0059 - accuracy: 0.9990 - val_loss: 0.8007 - val_accuracy: 0.8653
Epoch 32/35
247/247 [==============================] - 74s 299ms/step - loss: 0.0064 - accuracy: 0.9985 - val_loss: 0.6549 - val_accuracy: 0.8921
Epoch 33/35
247/247 [==============================] - 74s 299ms/step - loss: 0.0053 - accuracy: 0.9989 - val_loss: 0.6985 - val_accuracy: 0.8862
Epoch 00033: early stopping
33回目の訓練でearly stoppingとなりました。学習時間は40分ぐらい。
試しにGPUが機能してないローカル環境でやったら1epochに2時間とかで、GCP本当にありがとうとしか言えなかったです。
さて学習曲線を見てみます。
plt.plot(history.history["accuracy"], label="acc", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
結果はこんな感じ。
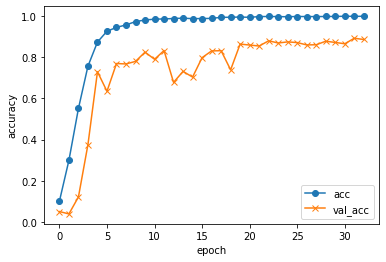
早い段階で訓練データの正答率は急激に上がり、検証データも80%後半まで伸びました。
train_score = full_model.evaluate(X_train, y_train, batch_size = BATCH_SIZE)
# 248/248 [==============================] - 19s 78ms/step - loss: 3.3646e-04 - accuracy: 0.9999
val_score = full_model.evaluate(X_valid, y_valid, batch_size = BATCH_SIZE)
# 107/107 [==============================] - 8s 77ms/step - loss: 0.6985 - accuracy: 0.8862
画像の水増ししてない状態でこのスコアなのでまだまだ改善の余地はありそう。
ただ早くアプリに落とし込みたかったので、モデルを保存します。
full_model.save("my_model.h5")
この.h5ファイルが容量460MBほどでして、後述するGitへのプッシュ時にエラーに遭遇することになります。
とりあえずGCPインスタンスを終了して、VScodeでアプリ構築に移ります。
8. アプリケーション化
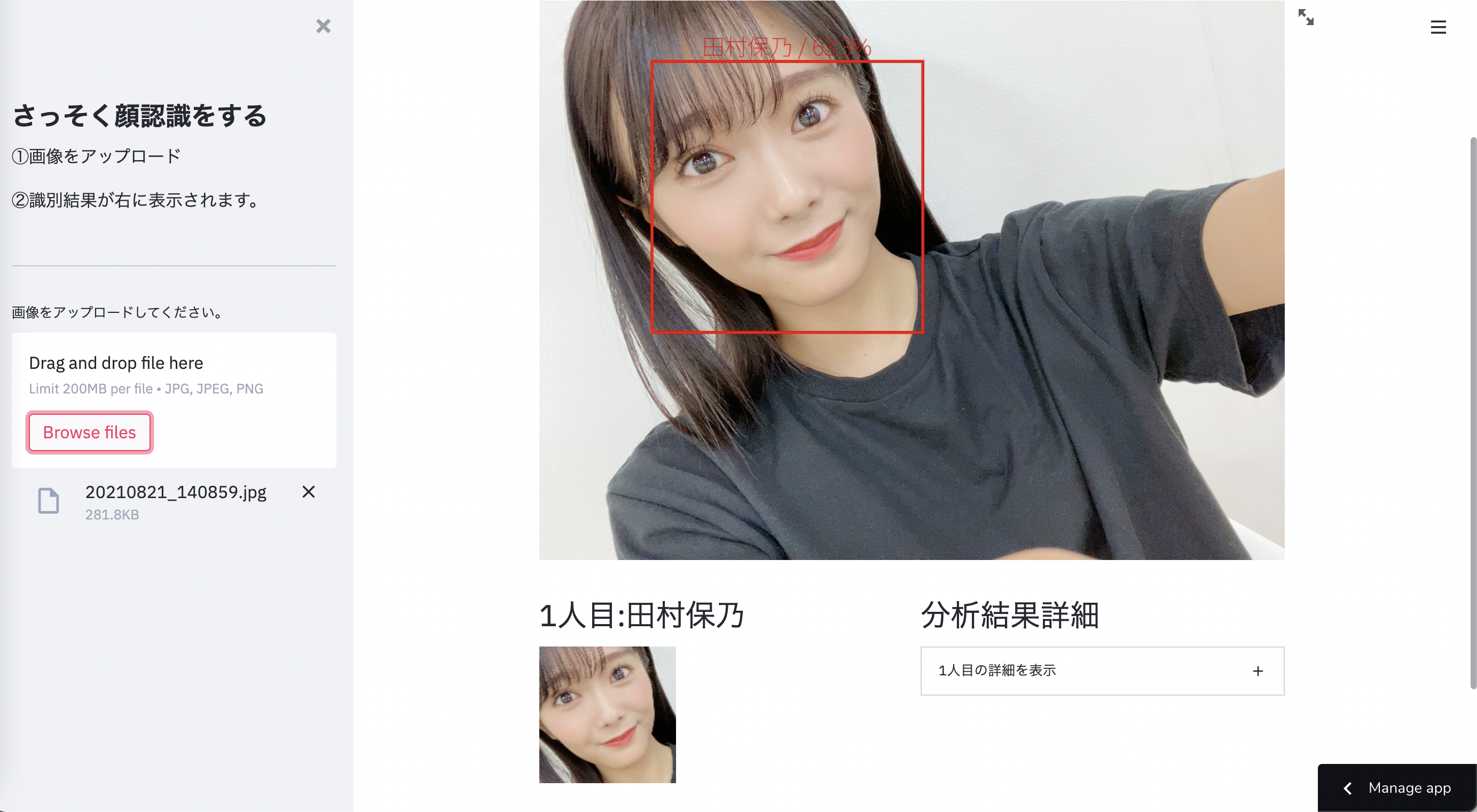
完成イメージ

こうしたアプリケーションを作っていきます。
大まかな流れ
学習したモデルをアプリケーションに落とし込んでいきます。
最初はFlaskを使う予定でしたが、前述したStreamlitが簡単かつ楽に作れそうだったので、こっちで作りました。
そもそも学習したモデルがテストデータでちゃんと予測できてるのか、この前にチェックすべきですが、Streamlitに惹かれすぎて「アプリ化してチェックすればええやろ」ということで、このままアプリ化します。
Streamlitの基本的な使い方、デプロイまでの流れはコチラやコチラの動画がわかりやすく助かりました。ありがとうございます。
このアプリケーションの大まかな流れは
①画像をアップロードしてもらう
②アップロードしてもらった画像から顔部分を認識
③顔部分をモデルで予測し、誰なのか名前を表示する
というものになっています。
①のアップロード機能に関してはStreamlitで簡単に実装できます。
問題は②なんですが、最初顔を検出する際にOpenCVのカスケード分類器を使いましたが、まぁめちゃくちゃ時間かかるし、重いです。
これをそのまま使うのは難しそうということで、別の顔認識ツールを使う必要がありました。
そこでふとyoutubeで先ほどの動画を見て、Face APIが楽そうということで、顔認識機能をこのAPIに任せることにしました。
③は学習済みモデルを読み込んでアップロードした画像を入力値として与えてあげればいけそうですね。
Face APIを使ってみる
まずFace APIをjupyterlabで試しに使ってみることにしました。
Azureへの登録、APIの取得は調べて行いました。これも先ほどの動画がわかりやすかったです。
公式ドキュメントを参考に、顔の部分を四角で囲むところまで動かしてみます。
pip install --upgrade azure-cognitiveservices-vision-face
# 必要なものをインポート
from PIL import Image, ImageDraw
from azure.cognitiveservices.vision.face import FaceClient
from msrest.authentication import CognitiveServicesCredentials
# キーとエンドポイント(URL)をそれぞれ定義
KEY = "<Face APIのAPIキー>"
ENDPOINT = "<Face APIのURL>"
最低限必要なものはこれだけです。
今回はローカルの画像を1枚読み取らせて顔認識してみます。
# 読み取る画像のパス
image_path = './test/hono_karin.jpg'
# FaceAPIの顔認識器が読み取れる形(バイナリデータ)にする。
image_data = open(image_path, 'rb')
# Pillowで読み取る(カラー画像)
img = Image.open(image_path)
# 上のカラー画像を扱いやすいように0~255のndarray型にする
img_array = np.array(img)
# バイナリデータを認識器に読み込ませる
detected_faces = face_client.face.detect_with_stream(image_data)
# 顔を囲む長方形の座標を取得する関数を定義
def get_rectangle(faceDictionary):
rect = faceDictionary.face_rectangle
left = rect.left
top = rect.top
right = left + rect.width
bottom = top + rect.height
return ((left, top), (right, bottom))
cv2で読み取ったものとはまた、拡張子や、データ型が違ってややこしかったです。
今までcv2ばかり使っていたのでPillowに慣れるまで時間がかかりそう。
# 何を背景として描くかのdrawオブジェクトを生成
draw = ImageDraw.Draw(img)
# 認識した顔の数だけ、それぞれ長方形を描いていく
for face in detected_faces:
draw.rectangle(get_rectangle(face), outline='green', width=3)
# 結果の表示
img

問題なく顔の部分を認識できてますね。
この顔を囲む長方形の座標を取得して、顔だけを切り取り、アプリに表示させたり、学習に用いたりします。
Streamlitを使う
コチラがほとんどやりたいことが一緒でしたので、参考にさせて頂きました。ありがとうございます。
コチラにStreamlitを使って作成したアプリケーションがたくさんあるのと、ソースコードも見れるので、実装の参考になりました。
まずはpip install streamlitでインストール。
次に任意のディレクトリに適当なpythonファイルを作成。
以降は作成したpythonファイル(今回はmain.py)をコーディングしていきます。
長いですが、以下ソースコード全文です。
# ライブラリのインポート
import streamlit as st
import numpy as np
from PIL import Image
from PIL import ImageDraw
from PIL import ImageFont
import cv2
import io
import os
import json
import tensorflow as tf
from azure.cognitiveservices.vision.face import FaceClient
from msrest.authentication import CognitiveServicesCredentials
# タイトル
st.title('櫻坂46メンバー顔認識アプリ')
# サイドバー
st.sidebar.title('さっそく顔認識をする')
st.sidebar.write('①画像をアップロード')
st.sidebar.write('②識別結果が右に表示されます。')
st.sidebar.write('--------------')
uploaded_file = st.sidebar.file_uploader("画像をアップロードしてください。", type=['jpg','jpeg', 'png'])
# Face APIの各種設定
# jsonファイルを読み込む
with open('secret.json') as f:
secret_json = json.load(f)
subscription_key = secret_json['AZURE_KEY'] # AzureのAPIキー
endpoint = secret_json['AZURE_URL'] # AzureのAPIエンドポイント
# キーが無ければ強制終了
assert subscription_key
# クライアントの認証
face_client = FaceClient(endpoint, CognitiveServicesCredentials(subscription_key))
# メンバーリスト
members = ['上村莉菜', '尾関梨香', '小池美波', '小林由依', '齋藤冬優花', '菅井友香', '土生瑞穂',
'原田葵', '守屋茜', '渡辺梨加', '渡邉理佐', '井上梨名', '遠藤光莉', '大園玲', '大沼晶保',
'幸阪茉里乃', '関有美子', '武元唯衣', '田村保乃', '藤吉夏鈴', '増本綺良',
'松田里奈', '森田ひかる', '守屋麗奈', '山﨑天']
# 各関数の定義
# モデルを読み込む関数
# @st.casheで再読み込みにかかる時間を減らす。
@st.cache(allow_output_mutation=True)
def model_load():
model = tf.keras.models.load_model('my_model.h5')
return model
# 顔の位置を囲む長方形の座標を取得する関数
def get_rectangle(faceDictionary):
rect = faceDictionary.face_rectangle
left = rect.left
top = rect.top
right = left + rect.width
bottom = top + rect.height
return ((left, top), (right, bottom))
# 画像に書き込むテキスト内容を取得する関数
def get_draw_text(faceDictionary):
rect = faceDictionary.face_rectangle
# メンバーの名前 / 89.2%のように表示する
text = first[0] + ' / ' + str(round(first[1]*100,1)) + '%'
# 枠に合わせてフォントサイズを調整
font_size = max(30, int(rect.width / len(text)))
font = ImageFont.truetype('SourceHanSans-VF.ttf', font_size)
return (text, font)
# テキストを描く位置を取得する関数
def get_text_rectangle(faceDictionary, text, font):
rect = faceDictionary.face_rectangle
text_width, text_height = font.getsize(text)
# ちょうど囲った長方形の上に来るように位置を取得
left = rect.left + rect.width / 2 - text_width / 2
top = rect.top - text_height - 1
return (left, top)
# 画像にテキストを描画する関数
def draw_text(faceDictionary):
text, font = get_draw_text(faceDictionary)
text_rect = get_text_rectangle(faceDictionary, text, font)
draw.text(text_rect, text, align='center', font=font, fill='red')
# 顔部分だけの画像を作る関数
def make_face_image(faceDictionary):
rect = faceDictionary.face_rectangle
left = rect.left
top = rect.top
right = left + rect.width
bottom = top + rect.height
image = np.asarray(img)
# 取得した長方形の座標を使って画像データを切り抜き
face_image = image[top:bottom, left:right]
# np.resizeだと画像が潰れちゃうのでcv2で読み取る
cv2_img = cv2.cvtColor(face_image, cv2.COLOR_BGR2RGB)
# cv2はカラー画像をBGRの順番で読み取ってしまうのでアンパックで色要素を分けて代入
b,g,r = cv2.split(cv2_img)
# RGBの順番になるようにマージ(正しいカラー画像)
face_image_color = cv2.merge([r,g,b])
# モデルの学習を(128,128,3)でやってきたので縦横のサイズを128に揃える
resized_image = cv2.resize(face_image_color, (128, 128))
return resized_image
# 顔画像が誰なのか予測値を上位3人まで返す関数
def predict_name(image):
# 四次元配列じゃないとモデルが読み取ってくれない
img = image.reshape(1, 128, 128, 3)
# テストデータも正規化を忘れない
img = img / 255
# モデルを読み込んで予測値を出す(予測値はラベルでなく確率で出力される)
model = model_load()
pred = model.predict(img)[0]
top = 3
# argsort()で確率値の小さい(可能性が低い)順に並べ、その値と対応するラベルを返す
# その[-3:]だから終わり3つ(つまり可能性が高い上位3人のラベルを取る)
# そのままだと[3位,2位,1位]となって扱いづらいので[::-1]にして逆向きにする
top_indices = pred.argsort()[-top:][::-1]
# メンバーの名前と確率をセットにしたリストを作って、上位3人分を返す
result = [(members[i], pred[i]) for i in top_indices]
return result[0], result[1], result[2]
# 以下ファイルがアップロードされた時の処理
if uploaded_file is not None:
progress_message = st.empty()
progress_message.write('顔を識別中です。お待ちください。')
# アップロードされた画像データをFaceAPIが認識できる形にする(バイナリデータ)
stream = io.BytesIO(uploaded_file.getvalue())
detected_faces = face_client.face.detect_with_stream(stream)
if not detected_faces:
raise Warning('画像から顔を検出できませんでした。')
img = Image.open(uploaded_file)
draw = ImageDraw.Draw(img)
# 各画像や、ラベル、確率を格納する空のリストを定義しておく
face_img_list = []
first_name_list = []
second_name_list = []
third_name_list = []
first_rate_list = []
second_rate_list = []
third_rate_list = []
# 認識された顔の数だけ以下の処理を行う
for face in detected_faces:
# モデルに読み込めるよう(128,128,3)の大きさの顔画像を作る
face_img = make_face_image(face)
# これも表示させたいので、一旦リストに格納
face_img_list.append(face_img)
# 予測したメンバーの名前上位3人をアンパックで代入
first, second, third = predict_name(face_img)
# 上位3人の名前とその確率をリストに格納する
first_name_list.append(first[0])
first_rate_list.append(first[1])
second_name_list.append(second[0])
second_rate_list.append(second[1])
third_name_list.append(third[0])
third_rate_list.append(third[1])
# 元の画像の顔部分を長方形で囲んで、1番可能性が高い名前とその確率を表示
draw.rectangle(get_rectangle(face), outline='red', width=5)
draw_text(face)
# 元の画像に長方形と名前が書かれているので、それを表示
st.image(img, use_column_width=True)
# カラムを2列に分ける
# ※st.beta_columns()じゃないとローカル環境では動かないです。
# ただ本番環境にデプロイするとそれじゃ古すぎる、新しいのに変更しましょうといったアラートが
# 出てきたので完成版のコードはst.columns()とこの後のst.expander()にしている
col1, col2 = st.columns(2)
# カラム1には検出した顔画像の切り抜きと名前を縦に並べて表示
with col1:
for i in range(0, len(face_img_list)):
st.header(f'{i+1}人目:{first_name_list[i]}')
st.image(face_img_list[i], width = 128)
# カラム2には、認識された顔の数だけ上位3人のラベルと確率を表示
# st.expanderで見たい時にクリックすれば現れるエキスパンダの中に入れる
with col2:
st.header('分析結果詳細')
for i in range(0, len(face_img_list)):
with st.expander(f'{i+1}人目の詳細を表示'):
st.write(first_name_list[i], 'の可能性:' , round(first_rate_list[i]*100,2), '%')
st.write(second_name_list[i], 'の可能性:' , round(second_rate_list[i]*100,2), '%')
st.write(third_name_list[i], 'の可能性:' , round(third_rate_list[i]*100,2), '%')
# ここまで処理が終わったら分析が終わったことを示すメッセージを表示
progress_message.write(f'{len(face_img_list)}人の顔を検出しました!')
Githubにもソースコードは上げていますが、多少変わっているところがあるかもです。
modelの読み込み、画像の切り出し、予測の流れは自分で考えて書けた部分でもあり、かなり楽しかったです。pythonコードに書いて、アプリ画面をリロードすればすぐ反映されるのが、本当に楽かつ面白かったです。
フロントサイド側をめちゃくちゃ楽に仕上げてくれるので助かりました。
もちろん凝ったレイアウトや見た目にするのは難しいので、本格的に商業用アプリケーションとして開発するには使いづらいですが、アプリのプロトタイプの作成とか、学習したことをアプリという形として残す分には便利だと思いました。
このコード書いてる時がちょうど櫻坂46の3rdシングル**「流れ弾」**の音源解禁日ということもあって、レコメンで聴いた後、テンションが上がってしまって、徹夜で仕上げてしまいました。
さてデプロイ前にちゃんと動作し、画像認識するか確認しておきましょう。
ここで初めてモデルのテストです。
main.pyがあるディレクトリでstreamlit run main.pyを叩くと
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8502
Network URL: http://192.168.0.35:8502
この後、ブラウザが勝手にLocal URLを開いてくれてアプリケーション画面が開きます。
実際に何枚か実行した結果を載せます。学習データと重複がないように、意図的に新しいデータにしてます。メンバーに偏りがあるのは気のせいです






ラベルが小さくて見づらいですが、画像6枚中顔の数が27でそのうち2つ検出できないのと、1つ天ちゃんを関有美子会長と間違えているのを除けば、他は全て正解してます。
他にも自分のGoogleフォトにある櫻坂メンバーフォルダからたくさん試して見たんですが、概ね正解できている印象です。
ただ顔に手がかかってたりとか、斜めになっている、目を閉じている、などは間違えやすい印象でした。
水増しもせず、ファインチューニングしただけのモデルにしては体感の精度は良くて、満足してます。ここからモデル構造変えたり、パラメータを調整したりすればさらに精度が上がるのかなと思いますが、一旦はこのモデルでデプロイします。
9. アプリのデプロイ
ここまで来たら後少しです。
と思っていたんですが...。
デプロイも簡単というので、期待してたんですが、思いの外ハマりました。
今後の参考になればと思い書いていきます。
デプロイはStreamlit Sharingという公式の方法が楽なのでこれでやっていきます。
コチラを参考に、リクエスト送って1日ぐらいでデプロイできる様になりました。
ただ実はというと待っている間、本番環境でも動くか早く試したいということでHerokuにデプロイしてみようとチャレンジ。ただこれがHeroku側の容量の上限値が500MBで、このアプリケーションが600MBほど(ほぼ学習済みモデルのせい)なのでデプロイできませんということで断念することに。
またデプロイするためにはリポジトリにプッシュする必要があるわけですが、これも学習モデルのデータサイズが大きすぎてプッシュできないエラーにハマりました。コチラはGit lfsを使うことで無事プッシュできました。(コチラを参考にさせて頂きました)
とエラーと格闘していると丁度いいタイミングでStreamlit Sharingの許可が下りたので、記事を参考にしながら1回目のデプロイ。結果は、どうやらrequirements.txtの記載が不十分 or 間違いな所があり、失敗しました。
Pillow
streamlit
Keras
cv2
python-dotenv
azure
azure-cognitiveservices-vision-face
凡ミスなんですがcv2ではなくてopencv-pythonでした。またtensorflowも書き忘れてました。てことでそれでやってみるもまた失敗。どうやらコチラによると新しくAptfileというものをディレクトリ内に作成し、opencv-python-headlessに変更が必要があるとのことでした。
Pillow
streamlit
Keras
opencv-python-headless
python-dotenv
tensorflow
azure
azure-cognitiveservices-vision-face
libsm6
libxrender1
libfontconfig1
libice6
その通りに、上記のファイルを作ってから進めるとデプロイできました!
が、画像をアップロードすると**「Face APIのキーがないぞ!」**というエラーが。
勘の良い方はお気づきかもしれませんが、requirements.txtにpython-dotenvが記載したままです。そもそもFace AIのAPIキーは第三者には公開するべきでない重要なものです。
そのためdotenvライブラリを使って、環境変数を設定して読み取らせる算段だったのですが、本番環境において、どうやっても読み取ってくれず。
理解するまでに時間がかかったのですが、アプリ側のコードで指定してもStreamlit Sharing側がどこに環境変数を記載したファイルがあるのかを知らないと意味がないということに気づき、「Streamlit 環境変数 追加」とかで検索してみたんですが、わからず...。
結局、次のアプリ開発に取り組んでみたかったので、渋々諦めて、jsonファイルを読み取らせる形でデプロイしました。
ただ今後、本格的にAPIを使ったアプリケーションを動かすとなった場合、必ず鍵データはGithubに上げてはいけないし、第三者に触れないように保存すべきです。今回は時間の関係上、諦めましたが、GCPやAWSのクラウドに鍵を保管できるサービスもあるみたいなので、そういうのも活用して安全なデプロイを心がけたいと思いました。
本番環境でも動かして見ましたが、正確に動作し、読み取り速度も速いです。
大体2,3秒くらいで結果を返してくれます。
まとめ
大体の実装期間は8日間ほどでした。前半4日間で画像集めから振り分けまで。後半4日でデータセットの用意・学習からアプリ構築までです。
初学者に毛が生えた程度ですが、CNNモデルの構築・学習をし、Webアプリケーションに落とし込む所まで、ハマりつつも実装しきれたのは大きな自信になりました。また寝食も惜しんで、画面と向き合えるくらいプログラミングが好きだということも再認識でき、いい経験になりました。
ちゃんと動作して、かつ正しくメンバーの名前を表示してくれた時は嬉しかったです。ただ別のテーマで初めから同じことをやろうとはしばらくは思えないです...
今後はせっかく、苦しい思いをしてメンバーの顔画像をたくさん集めたので冒頭で挙げたテキストで**「GAN」**を学んで、メンバーそっくりのアイドル画像を生成するアプリケーションとか作ろうかと思ってます。
→アプリ化はしてませんが、生成してみました。
コチラです。
コードの誤りや、ご意見、指摘など遠慮なく頂ければ幸いです。櫻坂のお話も待ってます。
拙い文章ですが、閲覧頂きありがとうございました。