9/15 更新
GANの数式部分
はじめに
CNN(畳み込みニューラルネットワーク)の主要な創始者の1人であるヤン・ルカン氏が
This, and the variations that are now being proposed is the most interesting idea in the last 10 years in ML, in my opinion."
「機械学習においてこの10年間で最も興味深いアイデア」
と述べた人工知能アルゴリズムであるGAN。
自分はPython機械学習プログラミング 達人データサイエンティストによる理論と実践を使って、機械学習の学習を進めており、ちょうど17章にこのGANが出てきて、今までのアルゴリズムより遥かに理解が難しく、かついろんな派生モデルもあって困惑したので、自分なりにわかる範囲でまとめてみました。
※数式や理論的な部分は自分も理解できていない部分が多いため、省いてます。
理解したらまとめて更新していこうと思います。
また主要なものだけとりあえずまとめました。
GANのモデルに関してはコチラやコチラにまとめてくれているので、少しずつ読み進めてまとめていけたらなと思います。
初学者なので、間違いが散見される可能性大です。遠慮なくご指摘頂けますと幸いです。
GANとは
GAN(Generative Adversarial Network)の略で敵対的生成ネットワークと訳されます。
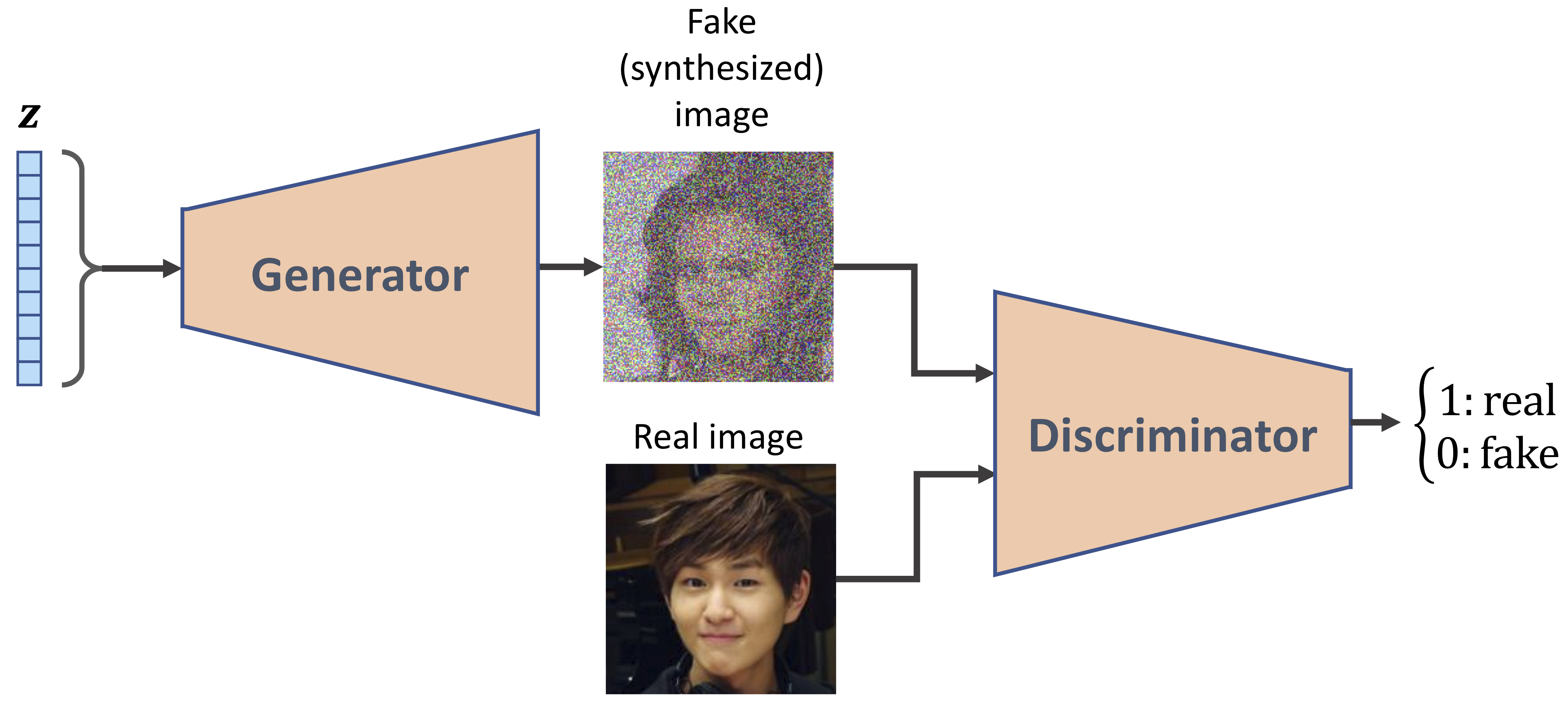
図のように**Generator(生成ネットワーク)とDiscriminator(識別ネットワーク)**の2つのネットワークで構成されているのが大きな特徴です。
Generatorは入力として、ノイズ Z を受け取り、偽物(Fake)の画像を生成します。
Discriminatorは、Generatorが生成した偽物(Fake)の画像を、本物(Real)の画像と比較して、本物なのか偽物なのかを判別します。
GeneratorはDiscriminatorに見破られないほど本物そっくりの画像を生成するように学習し、Discriminatorはそうした見破るのが難しい偽物をより正確に見破れるように学習します。
このように2つのネットワークが騙し合いを繰り返しながら、レベルアップしていく仕組みになっており、相反した目的のために学習するために敵対的と呼ばれます。
オリジナルバージョンのGANにおいて、GeneratorとDiscriminatorは、1つ以上の隠れ層を持つ2つの全結合ネットワークであり、vanila GANと呼ばれたりします。
GANの目的関数
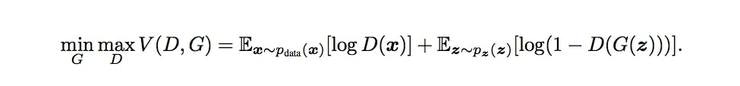
公式論文にも記載されているやつです。
この式の値をGに対しては最小化、Dに対しては最大化したい。
右辺の第一項が本物画像に対するもの、第二項が偽物画像に対するもの。
・$D(x)$は本物画像 $x$ がDに与えられた時、Dが判別した結果から得られる確率を表す(本物である確率を返す)
→$D(x)$が1に近ければ近いほど本物画像を本物だと正しく判別していることを意味する
・$D(G(z))$は ノイズ $z$からGが生成した偽物画像がDに与えられた時、Dが判別した結果から得られる確率を表す
→$D(G(z))$が0に近ければ近いほど、偽物画像を偽物だと正しく判別している事になる
ここでDにとって望ましい状態とは「本物は本物、偽物は偽物と正しく見分けること」
Gにとって望ましい状態とは「Dが本物と間違えてしまうくらいの偽物画像を作ること」
であることをふまえると
Dにとって望ましい状態の時
$D(x)$の値は1に近くなり$logD(x)$の値は大きくなる。
$D(G(z))$の値は0に近くなるので $1-D(G(z))$の値は1に近くなって、$log(1-D(G(z)))$の値は大きくなる。
すなわち目的関数の右辺の第一項、第二項ともに大きくなるので、式全体の値が大きくなる。
Gにとって望ましい状態の時
Gが関与するのは右辺の第二項だけなので、その部分だけ見る
$D(G(z))$の値は1に近くなるので、$1-D(G(z))$の値は0に近くなる。$log(1-D(G(z)))$の値は小さくなる
すなわち目的関数の第二項が小さくなるので、式全体の値が小さくなる。
以上のことから目的関数において、Dは最大化、Gは最小化したいという理由が掴めると思う。
ただ上記目的関数をそのまま損失関数として定義すると値がマイナスになってしまって意味合いが取りづらいので、実際の実装では正解ラベルを付け替えたり、そもそも損失関数に二値交差エントロピーを使うことで損失の値を正の値で考えることがほとんど。
ちなみにGANの学習がうまく進んでいる状態とは、Dが本物画像と偽物画像を半々の確率で見分けている状態(正答率が50%)のことなので、この時Dの損失はマイナスを考慮して
$$ -\bigl(log(0.5) + log(1-0.5)\bigr) ≒ 1.4$$
となって1.4付近の値を取ることが多い。
DCGANとは
DCGAN(Deep Convolutional Generative Adversarial Networks)は深層畳み込みGANと訳されます。(ディープ畳み込みGANとも)
要はvanila GAN の GeneratorとDiscriminatorに畳み込み層を組み込んだGANモデルです。
公式論文では両方ともに組み込むことを提案しています。
小さいですがネットワーク構成図が下です。
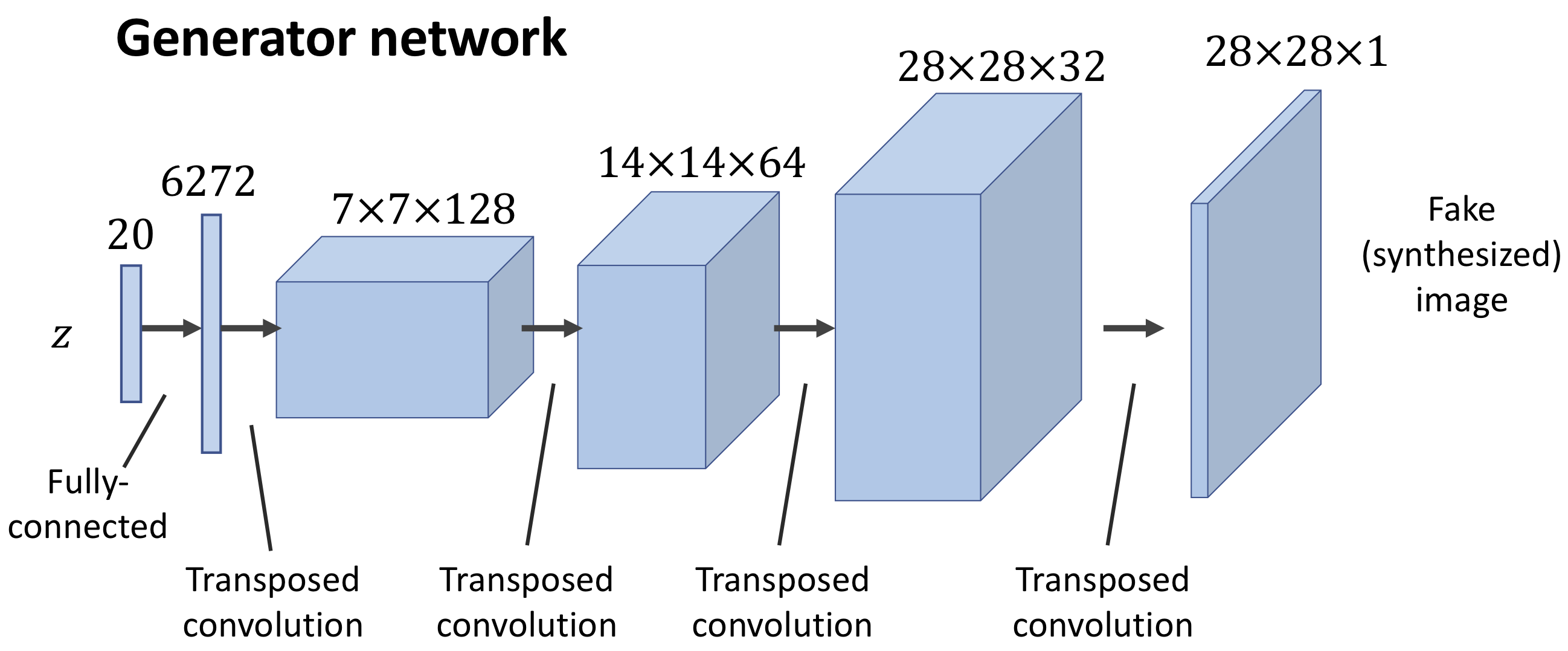
Generatorに関して見ていくと、20次元のノイズを**転置畳み込み(逆畳み込み)**によって最終的に28×28サイズの画像にアップサンプリングしています。
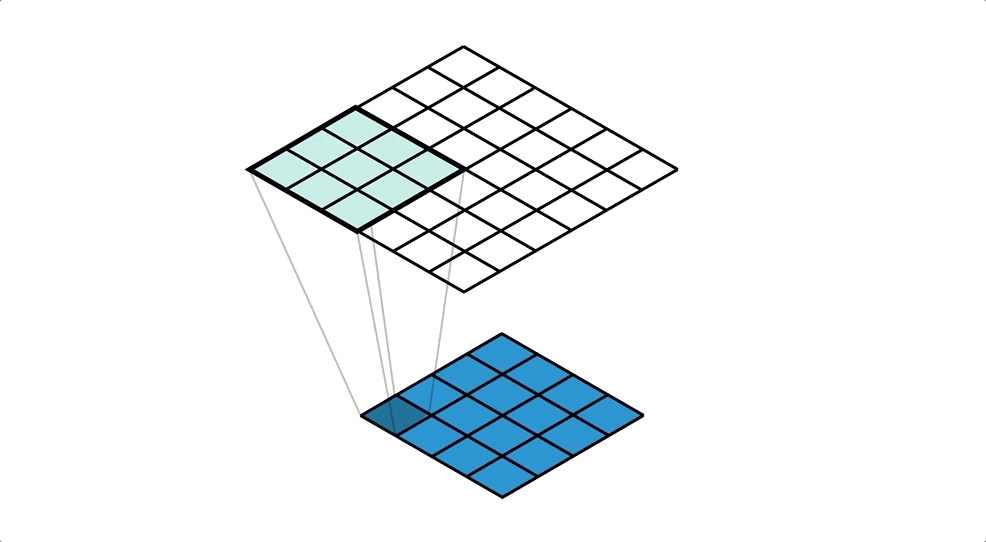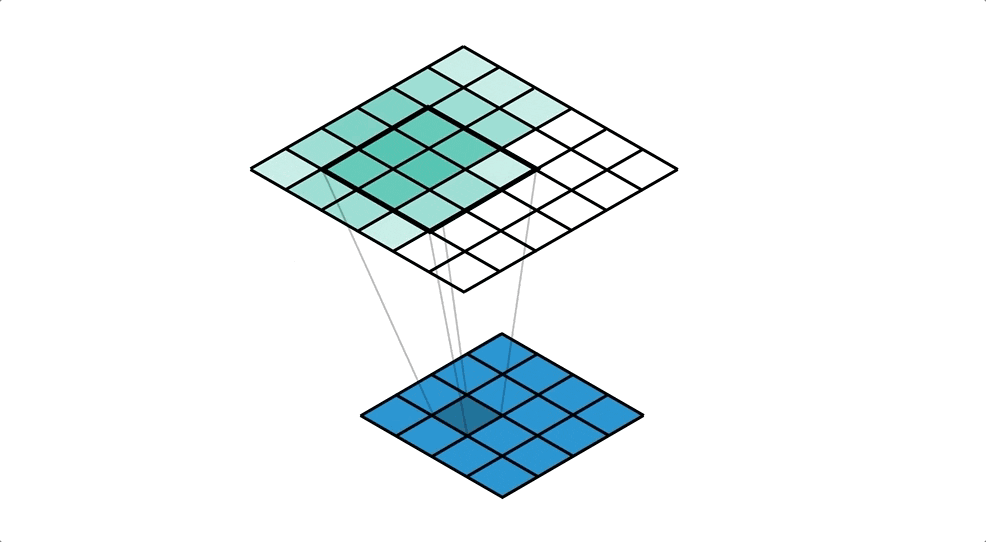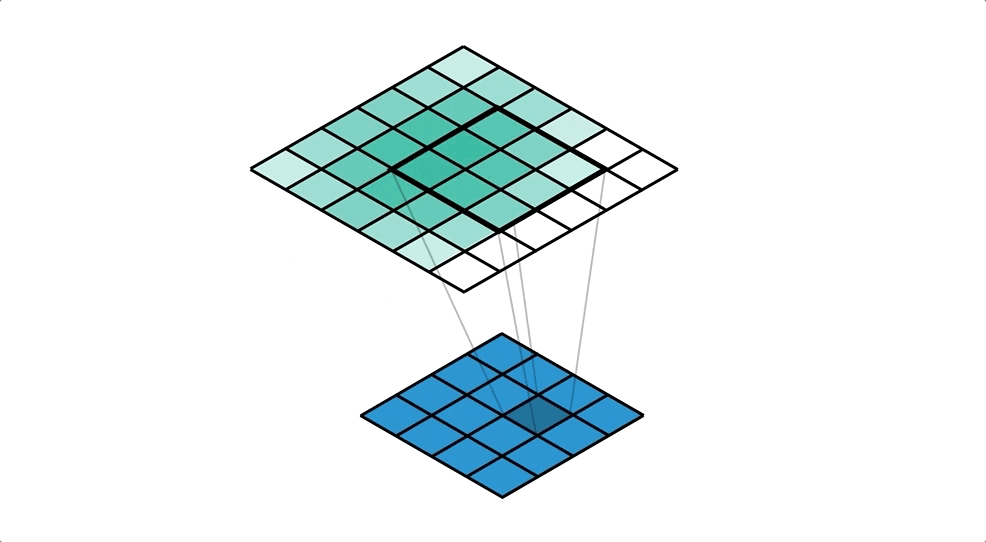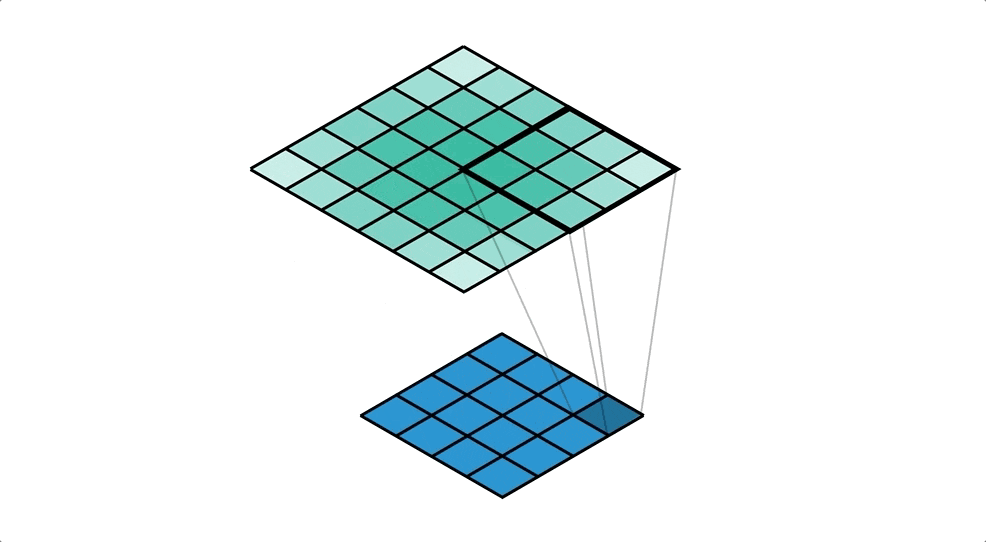
転置畳み込みのイメージgifがありました。⇩
4×4の画像から,カーネルサイズ3×3, ストライド1で 6×6の画像を出力しています。
下から上にのイメージを持つとわかりやすいかもです。
また途中で**バッチ正規化(Batch Normarization)**も行います。
層の入力をミニバッチごとに正規化して、分布を固定することで、過学習を抑えつつ、より高速な学習の収束を目的としています。
最後活性化関数に関してですが、公式論文では最後の出力層だけTanh(双曲線正接)、それ以外はReLUを使っています。
Discriminatorに関してはいわゆるCNNモデルとほとんど一緒の構造です。
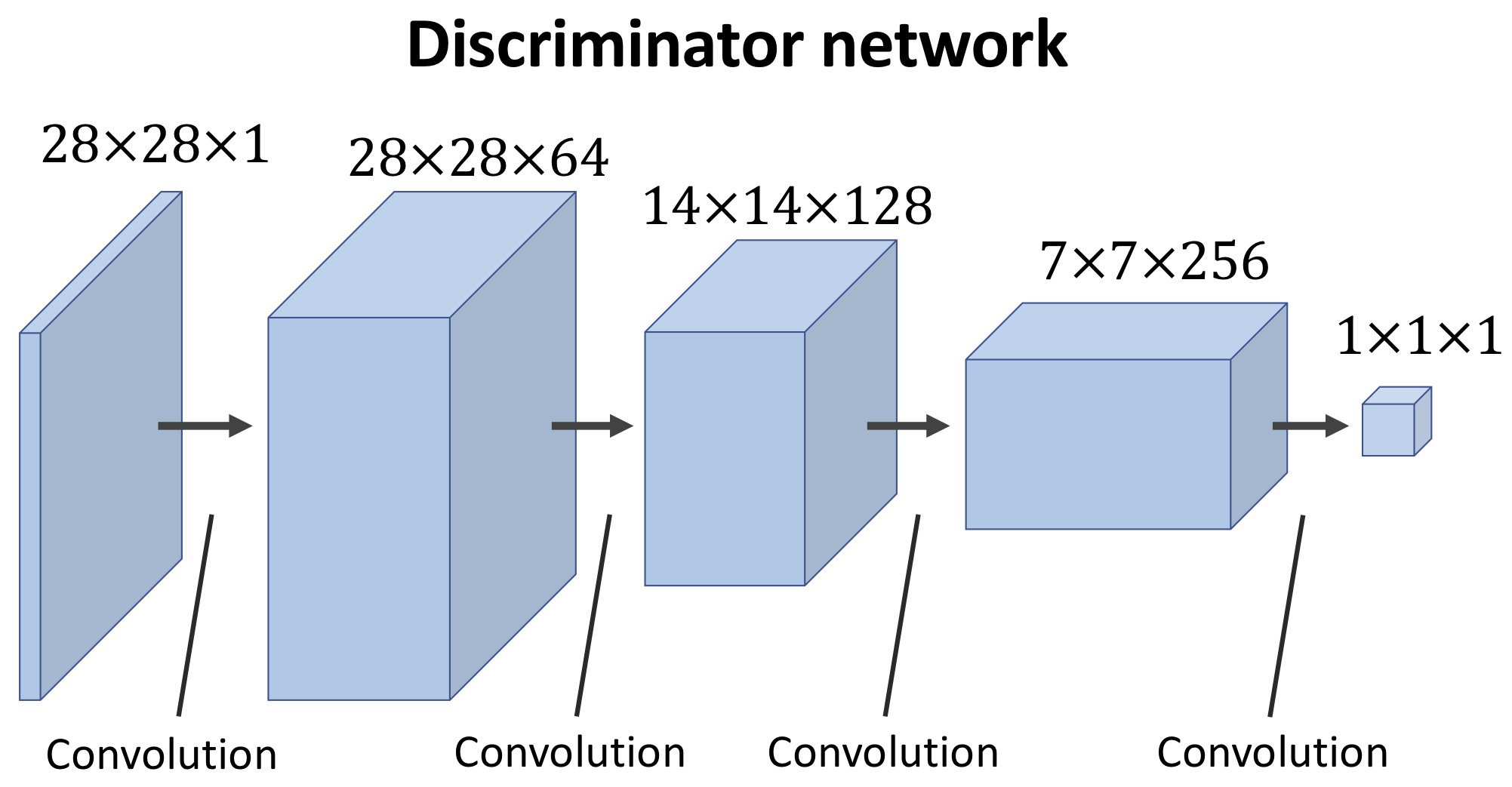
が活性化関数はLeaky ReLUというものを使っており(下のグラフ)
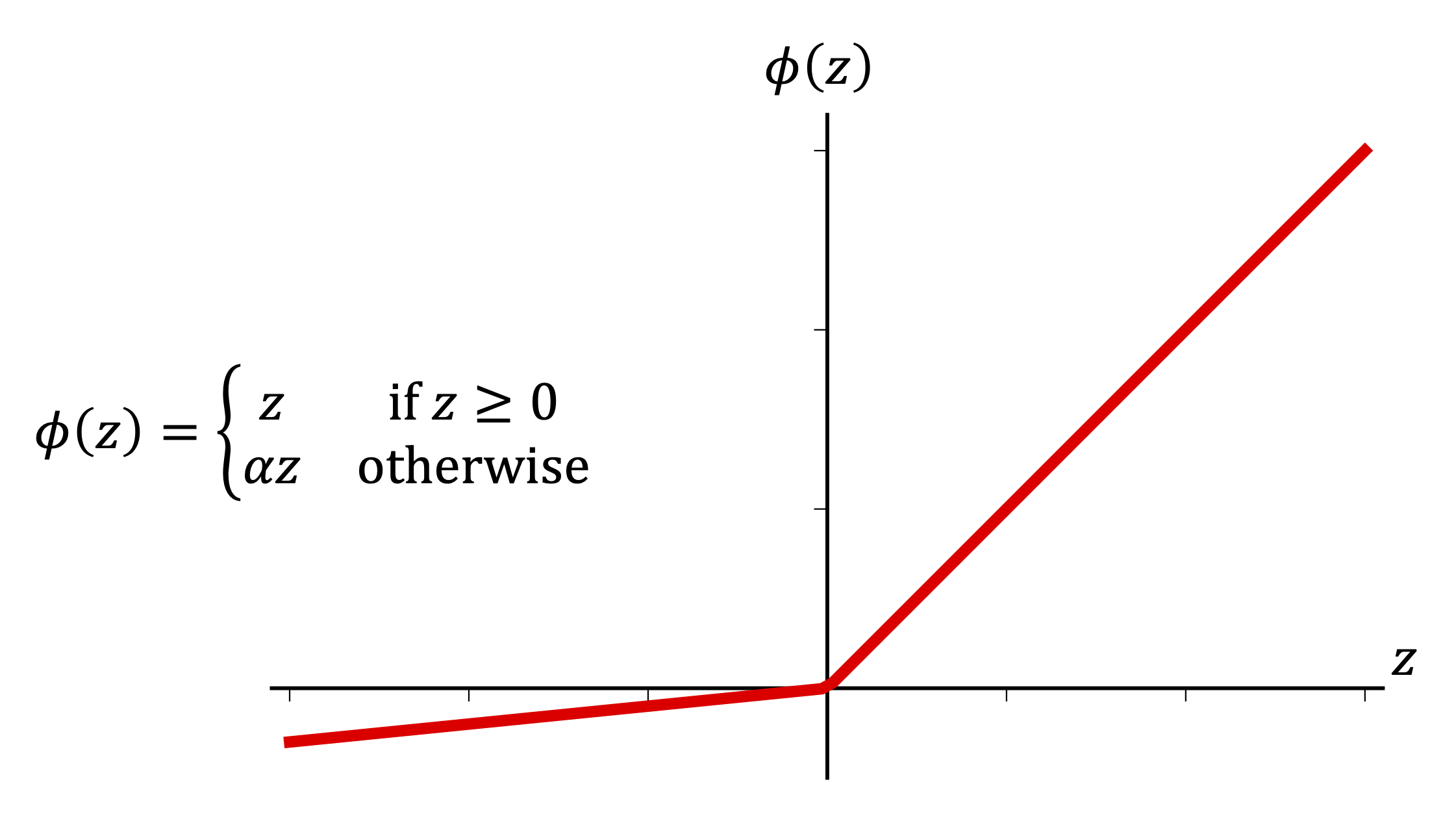
Reluと比べてzが負になった時に勾配が0ではなくなります。通常のReluだとzが負になった時勾配が0となってしまって、学習が進まなくなる問題が発生します。そうした問題を回避するために採用されています。
他にもDCGANの実装において重要なポイントはあるのですが、目立ったところだけ。
CGANとは
Conditional GANの略で、ラベル情報も考慮したモデルになっています。
MNISTの例で説明すると上記2つのモデルはランダムに0~9までの数字を生成しますが、このGANモデルでは任意の数字を生成できるようになっています。
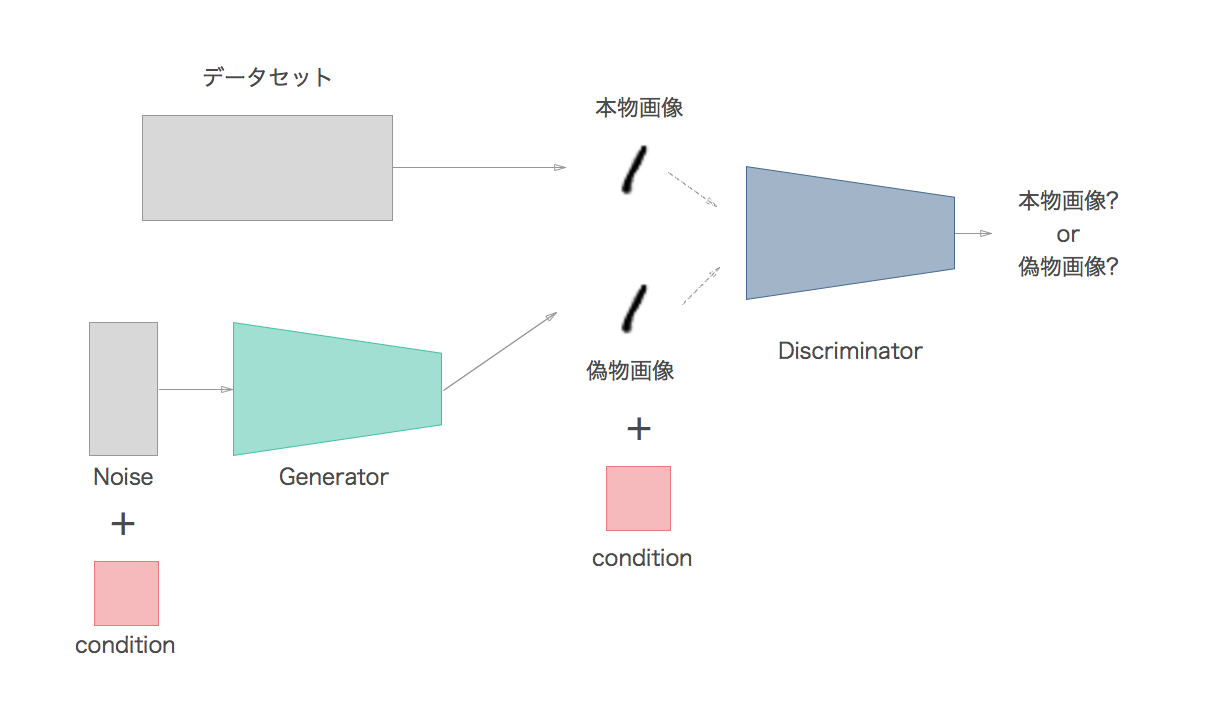
イメージ図のようにGeneratorの入力ノイズと一緒にラベル情報も
Discriminatorにも画像データと一緒にラベル情報を入力として与えています。
ただDiscriminatorの役割は、画像が**「本物か偽物かを判断すること」**から変わりません。
Pix2pix
Pix2pixは広い意味で考えると、上のCGANの1つ。
Pix to pix と言うことで画像から画像に変換することができる。
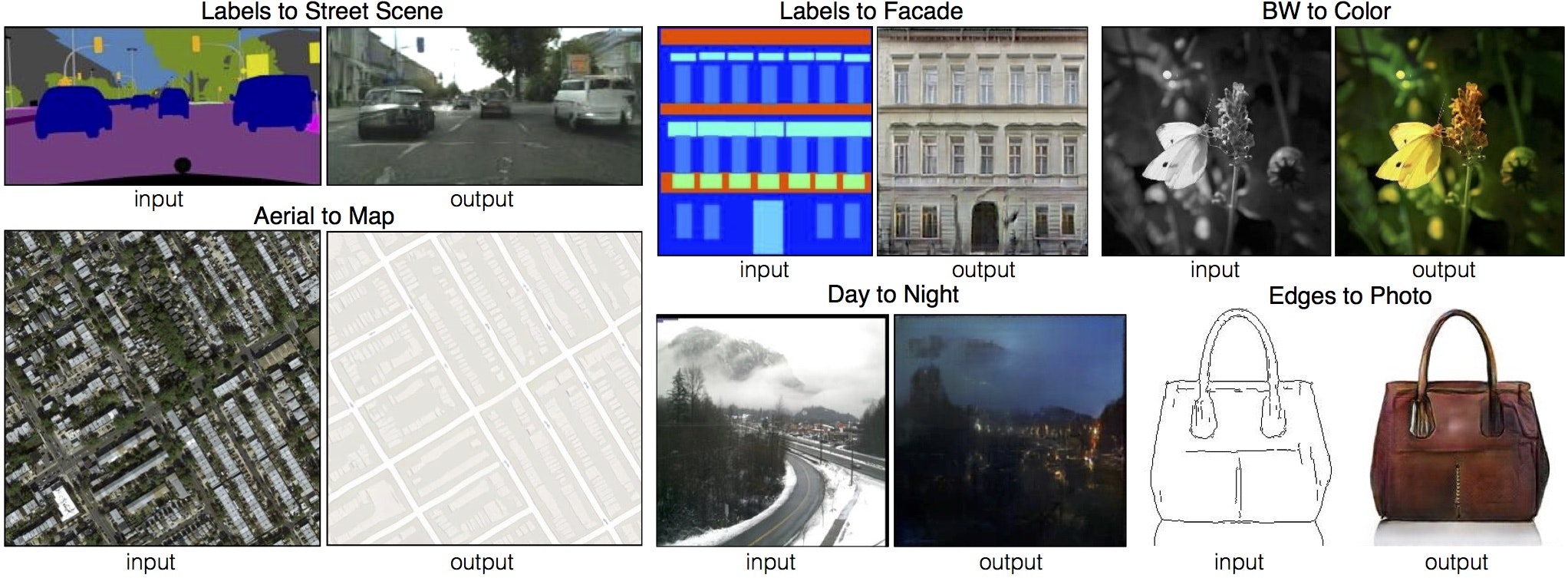
CGANは、ラベルベクトルと画像のペアを学習していたが、Pix2pixは画像と画像のペアを学習する。
CycleGAN
まとめ
一旦ここまで。
随時まとめていきます。
数学的な部分も、このポンコツ脳みその理解が追いついたらまとめていきたい。
参考
https://elix-tech.github.io/ja/2017/02/06/gan.html
https://github.com/zhangqianhui/AdversarialNetsPapers
https://github.com/hindupuravinash/the-gan-zoo
https://trainz.jp/media/learningtoai/175/
https://ledge.ai/gan/
https://weblab.t.u-tokyo.ac.jp/dl4us/