Increments × cyma (Ateam Inc.) Advent Calendar 2020の22日目は,株式会社エイチーム EC事業本部の@o93が担当します.
はじめに
Qiita初投稿です,,はじめまして!
元々はWebじゃないほうのフロントエンドエンジニアとして,アプリ開発などやっていました.最近は機械学習を使った分析や自動化に取り組んでいます.今回は,以前から興味があったGANについて色々と試してみたことをまとめました.
これ,いい感じに作って
みたいなざっくりとした依頼を,機械に理解できるようなコードにして自動化する,というのもエンジニアの仕事の1つです.しかし,画面デザインや施策の立案など,複雑で自動化が難しい依頼は人間がやるしかありません.GANが発展することで,そういった難しい依頼の自動化が進むんじゃないか?という想いから,今回この題材を選ぶことにしました.(単純に面白そうというのもあります,,)
理論とか難しいことはあまり説明せず,簡単に実装して学習にトライすることを重視しました.
似たような実装はWeb上に沢山落ちています.が,エラーになったり学習が上手く進んでくれない実装もあったので,参考にさせて頂きつつもコードに手を加えています.
GANとは?
敵対的生成ネットワーク(Generative adversarial networks 略称: GAN,GANs)
一言で説明すると,「Generator」,「Discriminator」という2つの深層学習モデルを競わせることで,人間を騙せるほどのデータを生成できるネットワークです.
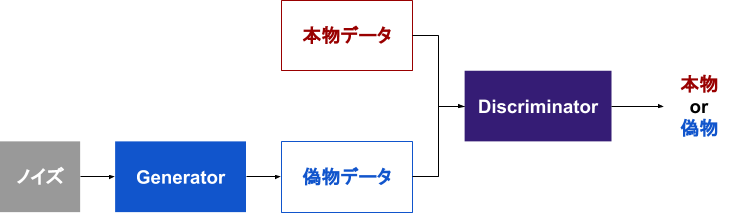
上の図を参考に仕組みを簡単に説明します.
Generator,Discriminatorを組み合わせた図のようなプログラムを作ります.Generatorはノイズを入力したら本物に似せた偽物のデータを出力するモデル,Discriminatorはデータが本物か偽物かを判定するモデルです.
最初にDiscriminatorにバッチサイズ分の本物データと偽物データの両方を入力して学習させます.次にDiscriminator側の学習をオフにした状態で,Generatorに対して偽物データだけを使った学習を実行します.このときDiscriminatorが偽物データを本物と見間違えることが,Generator側にとっての正解になります.この2つのモデルの学習を交互に繰り返し実行していくことで,モデルが競い合って成長していきます.最終的には,適当に生成したノイズを入力するだけで本物に似たオリジナルの偽物データが量産できるGeneratorが出来上がります!
個人的には,「2つのモデルをあえて敵対させることで,これまで出来なかった創造的な仕事ができるようになる」という斬新なアプローチに惹かれたんですが,画像系の深層学習に取り組む機会が今まで無かったため,なかなか手が出せず..これを機に画像認識関連を攻めていきたい..!またこれも個人の解釈でしかないのですが,人が夢を見ているときや何か想像しているとき,脳内のノイズに近いような信号から壮大な映像や音声が形作られて脳内に広がっていく..学習済みの生成モデルはそんなイメージに近い気がしました.
GANの詳細については以下を参考にしてください.
開発環境
- Windows 10 Home
- GeForce GTX 1080
- CUDA 10.1
- JupyterLab 2.2.8
- Anaconda 1.9.12
- Tensorflow 2.3.1(Keras)
- PyTorch 1.7.1(Lightweight GAN使うためだけ)
GPUがひと昔前のものなので,最後のLightweight GANの実行に3日くらいかかりました..
GANを簡単に実装してみる
深層学習経験が浅いので,とりあえず以下の書籍やWeb上のコードを参考にしながら実装してみます.
- 参考にした書籍
- 使用したデータセット
-
作成したすべてのコードはここ!
- https://github.com/o93/try-gan
- githubでipynbファイルが閲覧できないことがあるようです
- 以下にアクセスしてipynbファイルのURLを貼れば見れます
元祖GAN
書籍にあったサンプルコードを参考に元祖GANを実装してみます.MNIST(手書き数字データベース)を使用して,GANに数字を手書きして貰いましょう.
まずはImport
import numpy as np
import time
import os
import matplotlib.pyplot as plt
import datetime as dt
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, Activation,Flatten,Reshape
from tensorflow.keras.optimizers import Adam
devices = tf.config.list_physical_devices('GPU')
tf.config.list_physical_devices('GPU')
tf.config.set_visible_devices(devices[0], 'GPU')
何故かGPUを使ってくれなかったので手動で指定しています.最後の3行は不要であれば削除しても問題無いです.
Generatorの構成
def build_generator():
noise_shape = (z_dim, )
model = Sequential(name='Generator')
model.add(Dense(256, input_shape=noise_shape, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Dense(1024, activation='relu'))
model.add(Dense(np.prod(img_shape), activation='tanh'))
model.add(Reshape(img_shape))
model.summary()
return model
畳み込みニューラルネットワークではなく,ただのニューラルネットワークで構成されています.
Discriminatorの構成
def build_discriminator():
img_shape = (img_rows, img_cols, channels)
model = Sequential(name='Discriminator')
model.add(Flatten(input_shape=img_shape))
model.add(Dense(512, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
return model
2つのモデルを繋げます.
def build_combined():
discriminator.trainable = False
model = Sequential([generator, discriminator], name='Combined')
model.summary()
return model
ここでdiscriminator.trainable = Falseとしていることに注意してください.
2つをくっつけたモデルはGeneratorの学習に使うので,内部に入れるdiscriminatorの学習をオフにしています.
# 入力画像のサイズ
img_rows = 28
img_cols = 28
channels = 1
img_shape = (img_rows, img_cols, channels)
# ノイズの次元数
z_dim = 20
# 最適化関数
optimizer = Adam(lr=0.0001, beta_1=0.5)
# Discriminator
discriminator = build_discriminator()
discriminator.compile(loss="binary_crossentropy", optimizer=optimizer, metrics=["accuracy"])
# Generator
generator = build_generator()
# ネットワーク作成
combined_model = build_combined()
combined_model.compile(loss="binary_crossentropy", optimizer=optimizer)
実行するとモデルのサマリーが表示されます.
Model: "Discriminator"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 784) 0
_________________________________________________________________
dense_7 (Dense) (None, 512) 401920
_________________________________________________________________
dense_8 (Dense) (None, 256) 131328
_________________________________________________________________
dense_9 (Dense) (None, 1) 257
=================================================================
Total params: 533,505
Trainable params: 533,505
Non-trainable params: 0
_________________________________________________________________
Model: "Generator"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_10 (Dense) (None, 256) 5376
_________________________________________________________________
dense_11 (Dense) (None, 512) 131584
_________________________________________________________________
dense_12 (Dense) (None, 1024) 525312
_________________________________________________________________
dense_13 (Dense) (None, 784) 803600
_________________________________________________________________
reshape_1 (Reshape) (None, 28, 28, 1) 0
=================================================================
Total params: 1,465,872
Trainable params: 1,465,872
Non-trainable params: 0
_________________________________________________________________
Model: "Combined"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
Generator (Sequential) (None, 28, 28, 1) 1465872
_________________________________________________________________
Discriminator (Sequential) (None, 1) 533505
=================================================================
Total params: 1,999,377
Trainable params: 1,465,872
Non-trainable params: 533,505
_________________________________________________________________
生成された画像の表示と保存を行うメソッドを定義します.
def save_imgs(log_path, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, z_dim))
gen_imgs = generator.predict(noise)
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("{}/{}.png".format(log_path, epoch))
plt.show()
plt.close()
学習とか諸々行うメインのメソッドを定義します.
def train(epochs, batch_size=512, save_interval=1):
# データセットをダウンロードして読み込む
(X_train, _),(_, _) = mnist.load_data()
# -1 ~ 1の範囲にする
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
X_train = np.expand_dims(X_train, axis = 3)
half_batch = int(batch_size / 2)
num_batches = int(X_train.shape[0] / half_batch)
print("Number of Batches : ", num_batches)
log_path = 'log/{}/images'.format(dt.datetime.now().strftime("%Y-%m-%d_%H%M%S"))
os.makedirs(log_path, exist_ok=True)
for epoch in range(epochs):
for iteration in range(num_batches):
# NoiseからGeneratorで生成
noise = np.random.normal(0, 1, (half_batch, z_dim))
gen_imgs = generator.predict(noise)
# データセットから画像をピックアップ
idx = np.random.randint(0, X_train.shape[0], half_batch)
imgs = X_train[idx]
# それぞれのデータでDiscriminatorを学習
d_loss_real = discriminator.train_on_batch(imgs, np.ones((half_batch, 1)))
d_loss_fake = discriminator.train_on_batch(gen_imgs, np.zeros((half_batch, 1)))
# DiscriminatorのLossを算出
d_loss = np.add(d_loss_real, d_loss_fake) / 2
# ノイズ生成
noise = np.random.normal(0, 1, (batch_size, z_dim))
# 騙すことが正解になる目的変数
valid_y = np.array([1] * batch_size)
#Generatorを学習
g_loss = combined_model.train_on_batch(noise, valid_y)
if epoch % save_interval == 0:
# 生成画像の表示と保存
print ("epoch:%d, iter:%d, [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, iteration, d_loss[0], 100*d_loss[1], g_loss))
save_imgs(log_path, epoch)
処理の内容はコメントを参照ください.
最後に学習を実行します!
train(epochs=100)
epochごとに25枚の画像生成を100回繰り返していきます.

全部同じ画像が生成されているようです..ぼやけたブラックホールみたい

書籍には,「元祖GANを実装してみたが,うまく学習が進まなかった」と書かれていましたが,,,

20epoch辺りから変化が出始めて,40epochでこのように数字らしきものが生成されるようになってきました
最後の生成結果.

不完全でノイズのような点々が多いですが,数字だなと思える画像もいくつか生成できるようになりました.これはプログラムが手書き数字のデータセットをそのままコピーして貼り付けているわけではなく,全くランダムなノイズからニューラルネットワークを介してオリジナルの偽手書き数字を生成しているわけです!何の役にも立たないモデルではありますが,赤ちゃんの成長を見ているようで微笑ましいですね.
DCGAN(Deep Convolutional GAN)
元祖GANではニューラルネットワークを使用しました.次に実装するDCGANでは,モデルに畳み込みニューラルネットワークを使用することで,学習時間短縮やノイズ軽減を実現しています.build_generator,build_discriminatorを以下に差し替えて実行してみましょう.
参考: DCGAN (Deep Convolutional GAN):畳み込みニューラルネットワークによる敵対的生成
import numpy as np
import time
import os
import matplotlib.pyplot as plt
import datetime as dt
import tensorflow as tf
from tensorflow.keras.datasets import mnist, cifar10
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, Activation,Dropout,Flatten,Reshape
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import UpSampling2D, Conv2D
devices = tf.config.list_physical_devices('GPU')
tf.config.list_physical_devices('GPU')
tf.config.set_visible_devices(devices[0], 'GPU')
def build_generator():
noise_shape = (z_dim, )
activation = Activation("relu")
model = Sequential(name='generator')
model.add(Dense(1024, input_shape=noise_shape))
model.add(activation)
model.add(BatchNormalization())
model.add(Dense(7 * 7 * 128))
model.add(activation)
model.add(BatchNormalization())
model.add(Reshape((7, 7, 128), input_shape=(128 * 7 * 7,)))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(64, 5, padding="same"))
model.add(activation)
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(1, 5, padding="same"))
model.add(Activation("tanh"))
model.summary()
return model
アップサンプリングと畳み込み層が2回繰り返されていることが分かります.
def build_discriminator():
activation = LeakyReLU(alpha=0.2)
model = Sequential(name='discriminator')
model.add(Conv2D(64, 5, strides=(2, 2), padding="same", input_shape=(img_shape)))
model.add(activation)
model.add(Conv2D(128, 5, strides=(2, 2)))
model.add(activation)
model.add(Flatten())
model.add(Dense(256))
model.add(activation)
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation("sigmoid"))
model.summary()
return model
Discriminatorにも畳み込みニューラルネットワークを使用しています.
実行結果


10epochで既に数字と読み取れるまでになってきています.


元祖GANと比べて数字がちゃんと形作られていますし,細かいノイズもあまり見られませんね.
DCGAN おまけ
FFHQという顔のデータセットをDCGANに生成させてみたら以下のようになりました!MNISTはグレースケールなので,カラー画像に対応させています.

参考: Flickr-Faces-HQ Dataset (FFHQ)
CGAN(Conditional GAN)
CGANは,Generatorに入力するノイズにラベル情報を加えることで,指定したラベルの画像を効率良く生成することができます.DCGANでは完全にランダムに画像を生成していましたが,「5を10個作って」といった指示ができるようになります.DCGANまでは書籍を参考に作ってきたのですが,何故か画像がノイズのままで学習が進まなかったため,コードを大きくカスタマイズして,画像サイズ可変&カラーにも対応させています.
参考: [Keras で GANs 実装] GANs の理論解説 DCGAN vs cGAN
import numpy as np
import time
import os
import matplotlib.pyplot as plt
import datetime as dt
import tensorflow as tf
from tensorflow.keras.datasets import mnist, cifar10
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Input, Dense, Activation, Dropout, Flatten,Reshape, LeakyReLU, BatchNormalization, UpSampling2D, Conv2D, Embedding, Concatenate, Multiply, Conv2DTranspose
from tensorflow.keras.optimizers import Adam
devices = tf.config.list_physical_devices('GPU')
tf.config.list_physical_devices('GPU')
tf.config.set_visible_devices(devices[0], 'GPU')
def bulid_generator(latent_dim, class_num, img_shape):
noise = Input(shape=(latent_dim,))
label = Input(shape=(class_num,), dtype='float32')
# ラベルをくっつける
model_input = Concatenate()([noise, label])
size = img_shape[0] // 4
hid = Dense(128 * size * size, activation="relu")(model_input)
hid = Reshape((size, size, 128))(hid)
hid = UpSampling2D()(hid)
hid = Conv2D(128, kernel_size=3, padding="same")(hid)
hid = BatchNormalization(momentum=0.8)(hid)
hid = Activation("relu")(hid)
hid = UpSampling2D()(hid)
hid = Conv2D(64, kernel_size=3, padding="same")(hid)
hid = BatchNormalization(momentum=0.8)(hid)
hid = Activation("relu")(hid)
hid = Conv2D(img_shape[2], kernel_size=3, padding="same")(hid)
img = Activation("tanh")(hid)
return Model([noise, label], img)
def build_discriminator(img_shape):
img = Input(shape=img_shape)
label = Input(shape=(class_num,), dtype='float32')
hid = Conv2D(32, kernel_size=3, strides=2, padding="same")(img)
hid = LeakyReLU(alpha=0.2)(hid)
hid = Conv2D(64, kernel_size=3, strides=2, padding="same")(hid)
hid = BatchNormalization(momentum=0.8)(hid)
hid = LeakyReLU(alpha=0.2)(hid)
hid = Conv2D(128, kernel_size=3, strides=2, padding="same")(hid)
hid = BatchNormalization(momentum=0.8)(hid)
hid = LeakyReLU(alpha=0.2)(hid)
hid = Conv2D(256, kernel_size=3, strides=2, padding="same")(hid)
hid = BatchNormalization(momentum=0.8)(hid)
hid = LeakyReLU(alpha=0.2)(hid)
hid = Flatten()(hid)
# ラベルをマージ
merge = Concatenate()([hid, label])
hid = Dense(512, activation="relu")(merge)
validity = Dense(1, activation="sigmoid")(hid)
return Model([img, label], validity)
Generator, Discriminatorそれぞれのネットワークにラベルを繋げています.
今回はGeneratorに指示が出せるので,生成した画像をラベル順に並べて表示します.
def label2onehot(labels, class_num):
return np.identity(class_num)[labels.reshape(labels.shape[0])]
def combine_images(log_path, gen_imgs, epoch, idx, iterations, size):
r = size
c = class_num
# 生成画像を0-1に再スケール
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
img = gen_imgs[cnt, :, :, :]
axs[i, j].imshow(img, cmap='gray' if img.shape[2] == 1 else 'viridis')
axs[i, j].axis('off')
cnt += 1
fig.savefig("{}/{}_{}.png".format(log_path, epoch, idx))
plt.show()
plt.close()
色々とカスタマイズした学習部分です.
def train(train_data, train_labels):
# -1 ~ 1に
train_data = train_data.astype(np.float32) / 127.5 - 1.0
print(train_data.shape, train_label.shape)
# モデル
generator = bulid_generator(latent_dim, class_num, train_data.shape[1:])
discriminator = build_discriminator(train_data.shape[1:])
# 最適化関数
optimizer = Adam(0.0002, 0.5)
# Discriminatorコンパイル
discriminator.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
# Generatorがノイズから画像を生成
z = Input(shape=(latent_dim,))
label = Input(shape=(class_num,))
img = generator([z, label])
discriminator.trainable = False
valid = discriminator([img, label])
# Generator学習用のモデル
combined = Model([z, label], valid)
combined.compile(loss='binary_crossentropy', optimizer=optimizer)
gif_noise = np.random.normal(0, 1, (class_num, latent_dim))
gif_labels = np.identity(class_num)
stack_gif_img = []
iterations = train_data.shape[0] / batch_size
print('iterations:', iterations)
# 画像の真偽ラベルを準備
real = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
for i in range(int(iterations)-1):
s = int(epoch * iterations) + i
np.random.seed(s)
idx = np.random.randint(0, train_data.shape[0], batch_size)
# 学習画像をランダムで選ぶ
imgs = train_data[idx]
labels = train_label[idx]
# Generatorが画像生成
np.random.seed(s)
noise = np.random.normal(0, 1, (batch_size, latent_dim))
gen_imgs = generator.predict([noise, labels])
# 本物画像と偽物画像を混ぜないと上手く学習してくれない(コードが冗長なので直したい)
d_imgs = np.concatenate([imgs, gen_imgs])
np.random.seed(s)
np.random.shuffle(d_imgs)
d_labels = np.concatenate([labels, labels])
np.random.seed(s)
np.random.shuffle(d_labels)
d_y = np.concatenate([real, fake])
np.random.seed(s)
np.random.shuffle(d_y)
# 混合データを入れてDiscriminatorを学習
d_loss = discriminator.train_on_batch([d_imgs, d_labels], d_y)
# G を訓練(D が G の生成画像を誤って real 1 と判定するように訓練される)
g_loss = combined.train_on_batch([noise, labels], real)
# 生成画像を保存
if i % 500 == 0:
print(d_loss, g_loss)
print("{}:{} [D loss: {}] [G loss: {}]".format(epoch, i, d_loss[0], g_loss))
# 4行×ラベル数の画像を生成
size = 4
noise = np.random.normal(0, 1, (size * class_num, latent_dim))
g_labels = np.tile(np.arange(class_num), size)
g_labels = label2onehot(g_labels, class_num)
gen_imgs = generator.predict([noise, g_labels])
combine_images(log_path, gen_imgs, epoch, i, iterations, size)
書籍はじめWeb上に上がっている幾つかのコードでは,本物画像と偽物画像を別々にしてdiscriminator.train_on_batchを実行させています.それだと何故かd_loss,g_loss共にすぐ0に張り付いてしまいます..
数日悩んだ末,ラベルと目的変数を揃えて学習したからリークしてしまっている,という仮説を考えて対策してみました.データをくっつけてシャッフルした上で学習させたら上手くいったのですが,原因は今も不明なので分かるかたいらっしゃいましたら教えて頂けると嬉しいです,,,
最後に実行します.
class_num = 10
(train_data, train_label), (_, _) = mnist.load_data()
train_data = train_data.reshape((train_data.shape[0], train_data.shape[1], train_data.shape[2], 1))
train_label = label2onehot(train_label, class_num)
latent_dim = 100
batch_size = 1000
epochs = 100
log_path = 'log/{}/images'.format(dt.datetime.now().strftime("%Y-%m-%d_%H%M%S"))
os.makedirs(log_path, exist_ok=True)
train(train_data, train_label)


綺麗に手書き数字が順番に生成されていますね!
以下のようなラベルリストとノイズから手書き数字が生成されています.
np.tile(np.arange(10), 4)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
他のラベル付きデータセットでも学習を試してみました.
CIFAR10
データセットを差し替えます.
(train_x, train_y), (test_x, test_y) = cifar10.load_data()
train_data = np.concatenate([train_x, test_x])
train_label = np.concatenate([train_y, test_y])
# カラー画像なのでこの処理は不要
# train_data = itrain_data.reshape((train_data.shape[0], train_data.shape[1], train_data.shape[2], 1))

生成されている画像もラベルも法則が見えそうで見えない..上手く学習できなかったようです.
Fashion-MNIST
(train_x, train_y), (test_x, test_y) = fashion_mnist.load_data()
train_data = np.concatenate([train_x, test_x])
train_label = np.concatenate([train_y, test_y])

こちらは上手くラベル分けして生成させることができました.
CGANはランダムにデータを生成するのではなく,こういうデータをいい感じに生成して!とGeneratorに対して指示が出せるところがDCGANと異なる部分です.ノイズと何らかのデータを結合するというアイデアは,画像の合成・拡大にも応用され研究・実用化が進んでいるようです.
- その他のGAN
Lightweight GANを試す
今回実装した元祖GAN・CGANのMNISTの画像サイズは28x28,FFHQも32x32で,低解像度画像にしか対応できていません.せっかくなので高解像度な画像も生成してみたい!と思ったのですが,↑で紹介しているStyleGANは学習にかなり時間がかかるとのこと,,,そこで最近目に留まったLightweight GANを試してみることにしました.
参考: GPU1枚、1日未満で学習!超高速学習GAN、「Lightweight GAN」
- 以下のPyTorchで実装されたパッケージを使用(上手くpip installできなかったのでgit cloneして直接叩きました)
- データセットはFFHQの256x256(以下を256x256に縮小して使っています)
- https://www.kaggle.com/arnaud58/flickrfaceshq-dataset-ffhq/version/1
- Google Driveに置いてあるやつは1024x1024,Kaggleのほうは512x512で,それでも19GBあります..
- ライブラリ自体は1024x1024まで対応しているようです
必要なライブラリをインストール
%pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
%pip install kornia kornia einops adabelief-pytorch gsa-pytorch fire retry
pytorch_fidというライブラリだけインストールがエラーになってしまったのですが,オプションとして使える機能なので,importを削除しました
git diff
diff --git a/lightweight_gan/lightweight_gan.py b/lightweight_gan/lightweight_gan.py
index b57c714..04d85d8 100644
--- a/lightweight_gan/lightweight_gan.py
+++ b/lightweight_gan/lightweight_gan.py
@@ -29,7 +29,6 @@ from lightweight_gan.version import __version__
from tqdm import tqdm
from einops import rearrange
-from pytorch_fid import fid_score
学習開始!
from lightweight_gan.cli import *
params = {
'data': 'D:/lightweight_gan/images256x256',
'results_dir': 'D:/lightweight_gan/log/20201212_135100/results',
'models_dir': 'D:/lightweight_gan/log/20201212_135100/models',
'name': 'ffhq256_test',
'image_size': 256,
'generate': False,
}
train_from_folder(**params)
1000ステップごとに生成されるモデルが1つ辺り187MBと重いので,出力先にはDドライブを指定しています.
autosetting augmentation probability to 14%
ffhq256_test<D:/Works/Programs/gan/data/ffhq-dataset-images/images256x256>: 0%| | 0/150000 [00:00<?, ?it/s]
G: 21.83 | D: 2.19 | GP: 3.63 | SS: 3.62
ffhq256_test<D:/Works/Programs/gan/data/ffhq-dataset-images/images256x256>: 0%| | 45/150000 [01:25<156:31:11, 3.76s/it]
G: 2.18 | D: 0.88 | GP: 0.14 | SS: 0.30
ffhq256_test<D:/Works/Programs/gan/data/ffhq-dataset-images/images256x256>: 0%| | 98/150000 [02:43<69:58:26, 1.68s/it]
G: 0.30 | D: 1.26 | GP: 0.01 | SS: 0.20
ffhq256_test<D:/Works/Programs/gan/data/ffhq-dataset-images/images256x256>: 0%| | 147/150000 [03:58<64:00:58, 1.54s/it]
G: 2.27 | D: 0.56 | GP: 0.08 | SS: 0.02
ffhq256_test<D:/Works/Programs/gan/data/ffhq-dataset-images/images256x256>: 0%| | 196/150000 [05:13<63:34:59, 1.53s/it]
.
.
.
15万ステップの学習が進みはじめます.3日間実行しっぱなしにしたのですが,13万ステップ辺りで落ちてしまいました.以下のように学習状況が1000ステップごとに保存されているので無駄にはなりませんでしたが,,,

最後のほうに生成されていた画像は以下






人の顔が細部まで再現されているように見えます!ただしこれらは比較的上手く生成された画像を選んでいます.上手く生成されなかった画像は完全にホラーでした.ちょっと怖いのでここには載せません.
学習途中で気付いたのですが,
Mixed precision
You can turn on automatic mixed precision with one flag --amp
You should expect it to be 33% faster and save up to 40% memory
このオプションを指定するのを忘れていました.他にもいくつかオプションがあったので,調整すればパフォーマンスや品質が改善されるかもしれません.
まとめ
今回は,様々なGANを実際に実装して動かしてみることで,GANの仕組みや可能性を探ることができました.人が複数人集まって大きな目的を達成するのと同じように,複数の学習モデルを組み合わせることで,機械では到底出来なかった複雑な仕事がこなせるようになるかもしれませんね!私自身も,複数の学習モデルを競わせるというアプローチを得て視野が広がった気がしました.
- できたこと
- 簡単なGANの仕組みを実装して動かすことができた
- 高解像度な画像を生成するGANについても,GPU1枚で何とか学習を進めることができた
- やり残したこと
- 高度なGANを論文から実装できる能力を身に着けたい
- 独自のGANを作って良い感じに仕事を手伝って貰いたい
「これ,いい感じに作って」をそのままAIに丸投げできる日まで,,頑張ります!!
さいごに
最後まで読んで頂きありがとうございました!
Increments × cyma (Ateam Inc.) Advent Calendar 2020の23日目は,@phigasui がお送りします.お楽しみに!