概要
近年ではStyleGANの登場により「写真が証拠になる時代は終わった」としばしば騒がれるようになった。
Genera tive Adversarial Networks(以下、GAN)とは教師無し学習に分類される機械学習の一手法で、学習したデータの特徴を元に実在しないデータを生成したり、データを変換することができる。
例えば以下の絵画はGANにより生成された画像である。

引用元:Edmond de Belamy - Wikipedia
この絵画は2018年10月25日に米ニューヨークで著名オークション「クリスティーズ」で43万2500ドルで落札され、GANが世間の注目を浴びる一つのきっかけとなった。
現在はDCGAN、BigGAN、StackGAN、Pix2pix、Age-cGAN、CycleGAN等、様々なGANの派生が登場しており、StyleGANもその内の一つである。
StyleGANでは、前述したように「写真が証拠になる時代は終わった」と言われるほど超高精度な画像を生成することができる。
下に示す画像は一見写真のように見えるが、実際は全て存在しない人物であり、StyleGANによって生み出された画像である。

引用:A Style-Based Generator Architecture for Generative Adversarial Networks
GAN
Generative Adversarial Networksは敵対的生成ネットワークと訳される。
"敵対的"とあるように、GANは互いに敵対し合う生成器と判別器の2つのネットワークから成り立つ。
生成器はGenerator、判別器はDiscriminatorと呼ばれる。
GeneratorはDiscriminatorを欺くようにデータを生成し、Discriminatorは生成されたデータが生成されたデータであると暴くことができるように学習を行う。
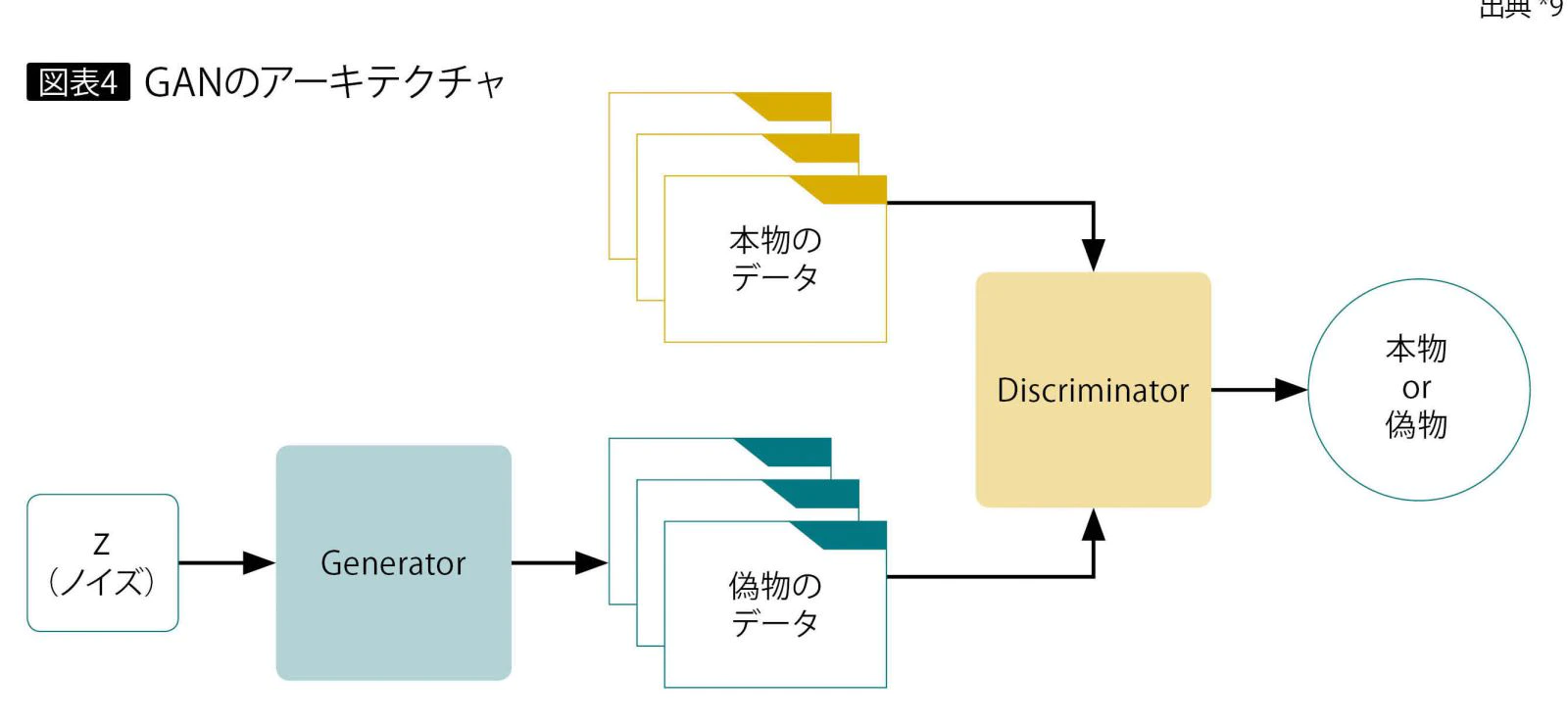
引用元:GAN:敵対的生成ネットワークとは何か ~「教師なし学習」による画像生成 - アイマガジン|i Magazine|IS magazine
Generator
Generatorは教師データの特徴に沿ってそれっぽいデータを生成するように学習を行う。
様々なパターンの画像を生成できるように、入力には乱数によって生成された値の配列を用いる。
画像は転置畳み込み処理によって生成される。
転置畳み込み処理とはいわば畳み込み処理の逆で、1ピクセルごとにkernelとの積を求め、strideごとの和を取り、画像をアップサンプリングする処理である。
以下がそのイメージ(下の青い画像に対し転置畳み込み処理を行ってアップサンプリングしている。)。
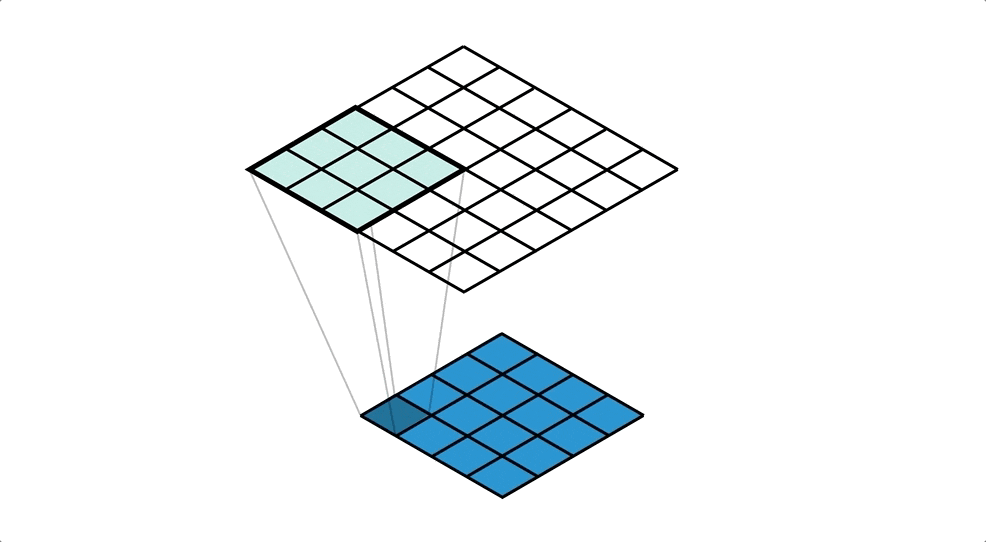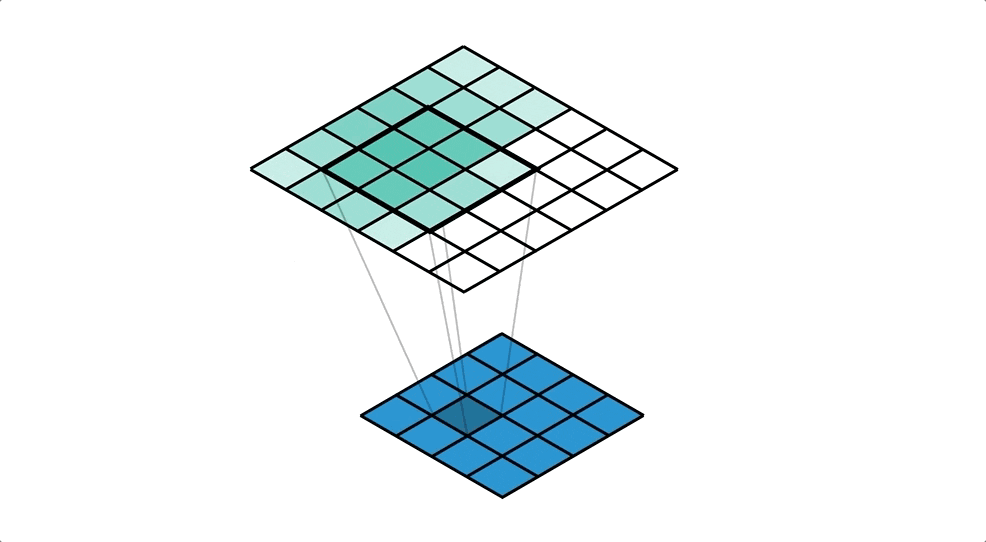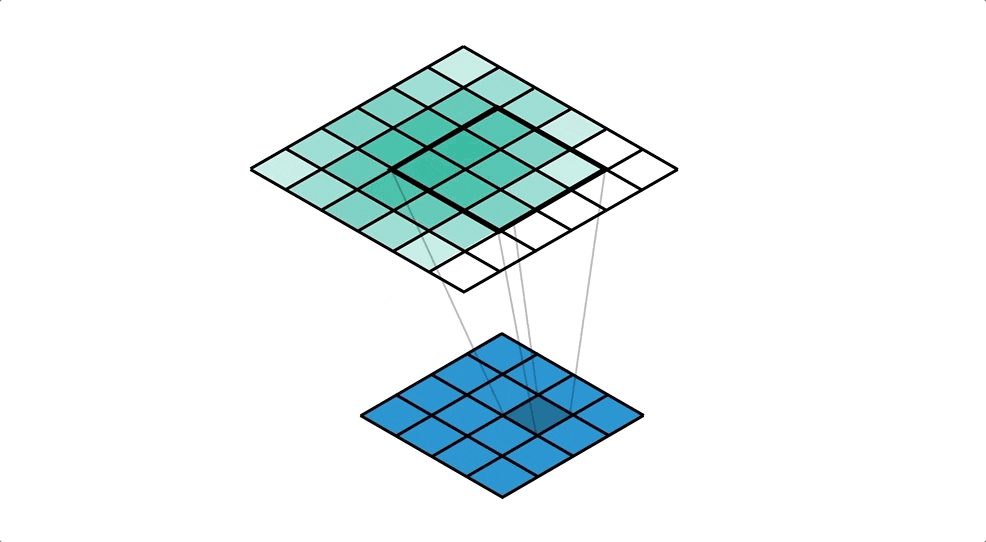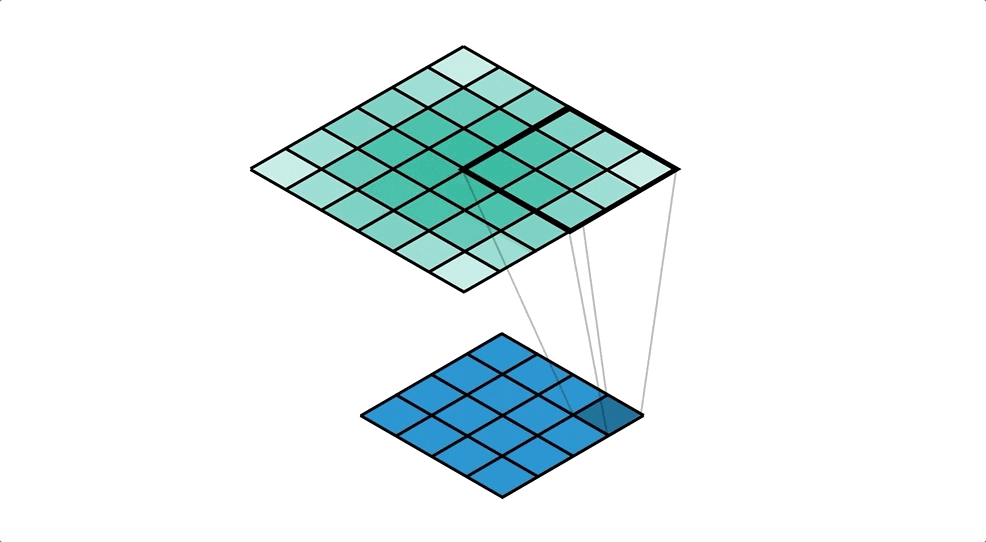
引用元:Transposed Convolutions explained with… MS Excel! - Apache MXNet - Medium
Discriminator
Discriminatorは入力画像に対して、生成された画像なのか教師データなのかを判別する。
どれだけ教師データに近いかを表す数値を0~1の範囲で出力する(1が教師データ、0が生成された画像)。
損失関数
$G$:Generator
$D$:Discriminator
$z$:ノイズベクトル
$x$:教師データ
$G(z)$:Generatorが生成したデータ
Generatorの損失関数
L_{G}=\frac{1}{M}\sum_{i=1}^{M}log(1-D(G(z)))
Generatorが生成したデータをDiscriminatorに入力し、教師データと判定されると出力の絶対値が最小になる式。
Discriminatorの損失関数
L_{D}=\frac{1}{M}\sum_{i=1}^{M}[logD(x)+log(1-D(G(z)))]
Discriminatorが教師データを教師データ(出力1)、生成画像を生成画像(出力0)と判定すると出力の絶対値が最小になる式。
StyleGAN
StyleGANがGANと異なる点は大きく3つ。
- 各転置畳み込み処理後にstyleの調整を行う
- 細部の特徴はノイズによって生成される
- 潜在変数zを潜在空間wに非線形変換する
この変更により従来よりも高精度な画像の生成を可能としている。
以下にGeneratorのネットワーク図を示す。
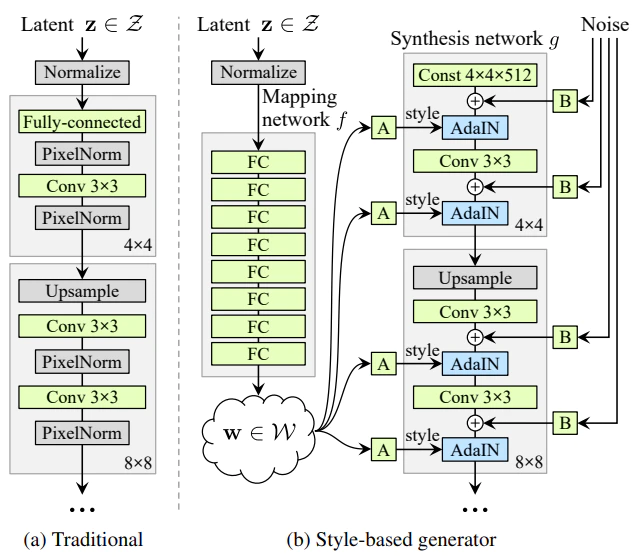
引用:A Style-Based Generator Architecture for Generative Adversarial Networks
左の図がこれまでのGAN(PG-GAN)、右の図がStyleGANである。
StyleGANはMapping networkとSynthesis networkの2つのネットワークで構成されていることが分かる。
また、GANでは潜在変数zから直接画像を生成していたのに対して、StyleGANでは4×4×512の固定のテンソルから画像を生成していることもわかる。
Mapping network
Mapping networkでは8層の全結合層によって潜在変数zを潜在空間wに非線形変換している。
これは入力時には情報的な意味を持たないただの乱数の数列(潜在変数z)を多次元的なスタイル情報(年齢、性別、表情etc)を表す空間に数値をマッピングし、スタイルの特徴を表すものに変換するという処理である。
これが後にスタイルの情報としてSynthesis networkで用いられる。
Synthesis network
Synthesis networkは画像のアップサンプリング、スタイル及びノイズ情報のマージを行う。
アップサンプリングを何度にも分け、その都度スタイル情報を挿入することにはとても大きな意味がある。
それは画像のサイズによって持つ情報が異なるためである。
極論、7680×4320(8K)の画像では画像の特徴は非常に分散しており1ピクセルから得られる情報は極めて少なく、細かいものである。対して1×1の画像が表す1ピクセルの情報は画像最大の特徴(全体の色味)を表し、一番アバウトな情報である。
つまり、画像サイズが大きくなるに従って、物体の色→物体の位置→物体の輪郭→物体の細かな模様と順番にアバウトな情報から細かい情報を表す物へと変化していくわけである。
よって、小さいサイズの画像にスタイル情報を挿入すれば全体の色味等が操作でき、大きいサイズの画像にスタイル情報を挿入すれば表情や服の模様などを操作することが出来るというわけである。
AdaIN
AdaINは、Mapping networkから得られた潜在空間wを各解像度ごとにスタイル情報としてマージする部分である。
マージの計算式は以下。
{AdaIN(x_i, y) = y_{s,i}\frac{x_i-μ(x_i)}{σ(x_i)}+y_{b,i}
}
$x_i$は特徴マップ、$y_{s,i}$,$y_{b,i}$は潜在変数$w$をアフィン変換したものである。
以下に示す画像は一つの潜在変数で生成されたスタイル(ソースA)の各解像度に対して、同じく一つの潜在変数で生成されたスタイル(ソースB)のスタイル情報をマージした際の変化を可視化したものである。
Coarse stylesは低解像度、Middle stylesは中解像度、 Fineは高解像度のスタイル情報。

引用:A Style-Based Generator Architecture for Generative Adversarial Networks
このように2つの潜在空間を組み合わせることをMixing Regularizationと表現される。
Noise
ノイズとは正しい法則に沿って生成すれば、ランダムに生成しても画像の見た目に大きな影響を与えない特徴である。
具体的には細かな見た目の特徴である髪の流れやヒゲ、そばかすなどに確率的な変動を与える。
逆にノイズを取り除けば、特徴のない絵画のような見た目になる。
以下に示す画像からノイズの影響を確認することが出来る(白が濃い部分ほどノイズの影響が強い)。

引用:A Style-Based Generator Architecture for Generative Adversarial Networks
また、ノイズにおいてもマージする画像サイズによって影響の細かさをコントロールすることが出来る。