概要
- 近年、画像生成の分野で主流となっている技術であるGAN(敵対的生成ネットワーク)を用いて、絵画を生成
- 生成した絵画を展示するオンライン美術館を作成した(AI Art Gallery)

GANとは
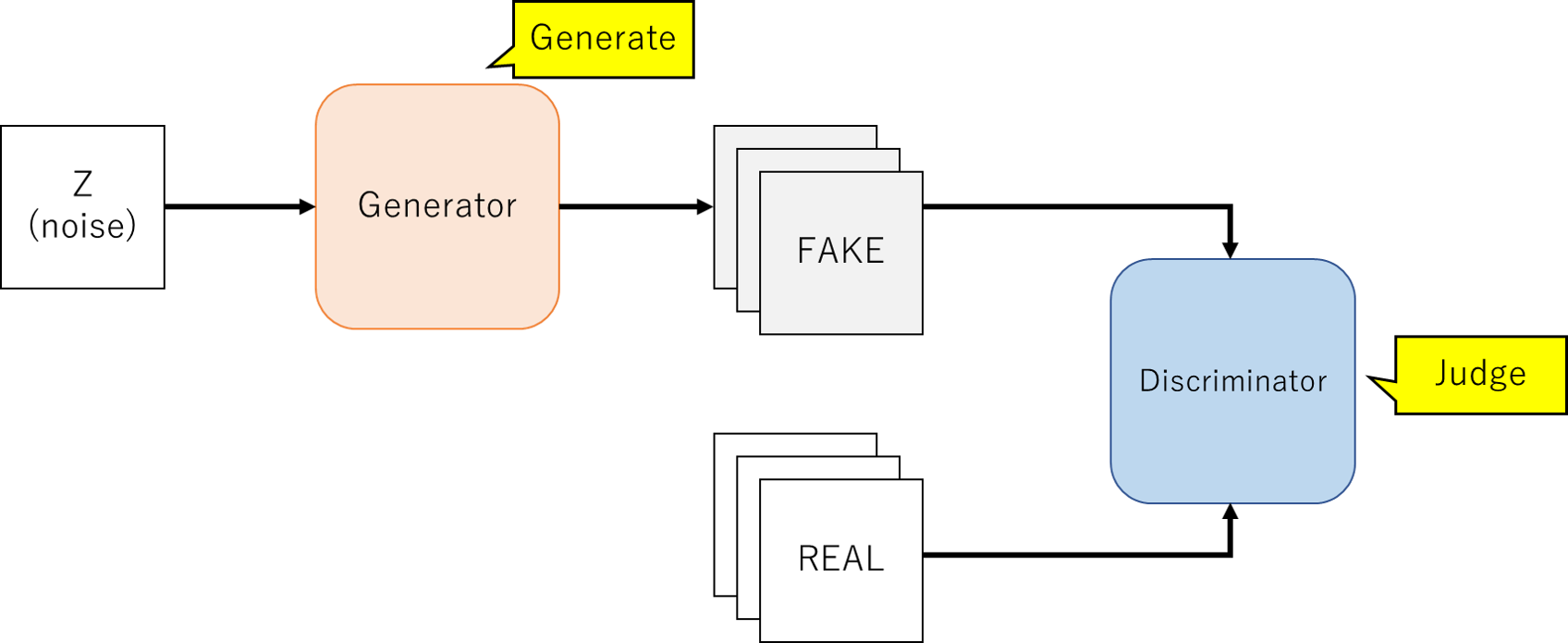
- GANとは2014年にイアン・グッドフェローらが提案した生成モデルアーキテクチャ
- GANは、Generator(生成器)とDiscriminator(判別器)の2つのニューラルネットワークから構成される
- Generatorはノイズ($z$)から偽の画像を生成し、DiscriminatorはGeneratorが生成した画像と本物の画像を判別する役割を持つ
- その上で、GeneratorはDiscriminator本物と間違える画像を生成するように学習し、Discriminatorはその間違いを小さくするように学習するといったように両者を競合させることで生成モデルを構築する
データ収集
- 肖像画、静物画(花)、風景画、都市景観画の4つの絵画データをWebスクレイピングで収集
- 多少ばらつきがあるが各データ3万枚程度集まった
- 関係のないデータも入っているので仕分けを行い、最終的に1万枚程度(少ないもので5千枚程度)の画像データを学習に使用した
学習
具体的な手法は、StyleGANを用いた。StyleGANを解説をしつつ、学習に用いたコードを追っていく。
※今回用いた実装コードはNVIDIAが公開しているものとは異なるため、論文の内容を厳密に再現したものではありません。
公式の実装を参照したい場合は、こちらをご確認ください。
StyleGANとは
- NVIDIAが2018年12月に発表した敵対的生成ネットワーク
- Progressive Growing GANで提案された手法を採用し、高解像度で精巧な画像を生成することが可能
- スタイル変換(Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization)で提案された正規化手法を導入し、生成画像の制御を可能とした
- 以下のように本物と区別がつかない画像を生成することができる

A Style-Based Generator Architecture for Generative Adversarial Networks
ネットワーク構造
- 次の図は、従来のGANとStyleGANにおけるGeneratorのアーキテクチャを示す
- 従来のGANは潜在変数$z$を入力レイヤーにだけ用い、CNNで徐々にアップサンプリングすることにより画像を生成する
- 一方、StyleGANは、大きく分けてMapping networkとSynthesis networkから構成されており、従来のモデルよりも複雑になっている
- Synthesis networkでは、畳み込み層の間にStyleやNoiseいった情報を組みアップサンプリングを行う
- StyleGANの各要素については、以降で詳しく説明する
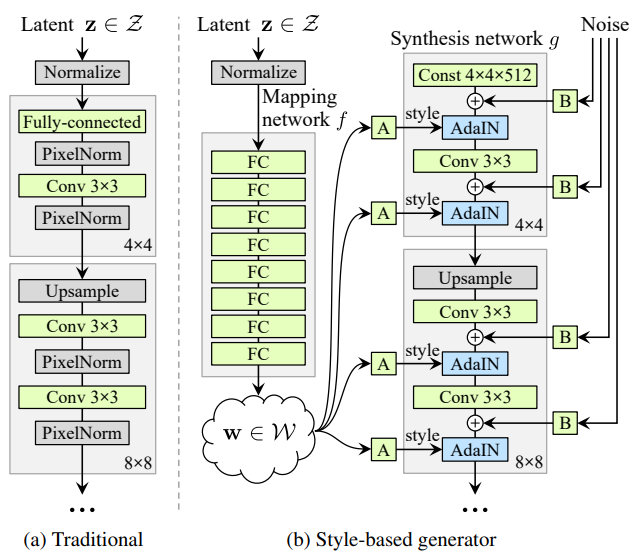
A Style-Based Generator Architecture for Generative Adversarial Networks
Mapping Network
- 従来のGANでは、画像の生成に用いる潜在変数$z$を入力でしか使用しないが、StyleGANでは潜在変数$z$をMapping networkを通して、潜在空間$w$に変換する
- この潜在空間$w$はのちに、スタイル情報としてSynthesis networkに組み込まれる
- Mapping networkは8つの層から構成されており、各層は512次元の全結合層である
stylegan.py
def generator(self):
if self.G:
return self.G
# === Style Mapping ===
self.S = Sequential()
self.S.add(Dense(512, input_shape = [latent_size]))
self.S.add(LeakyReLU(0.2))
self.S.add(Dense(512))
self.S.add(LeakyReLU(0.2))
self.S.add(Dense(512))
self.S.add(LeakyReLU(0.2))
self.S.add(Dense(512))
self.S.add(LeakyReLU(0.2))
AdaIN
- AdaINは、Mapping networkから得られた潜在変数$w$をスタイル情報として空間データに適用する役割を持ち、姿勢、髪型、輪郭など大局的な特徴を変化させることができる
- 数式は以下の通り
AdaIN(x_i, y) = y_{s,i}\frac{x_i-μ(x_i)}{σ(x_i)}+y_{b,i}
- $x_i$は特徴マップ、$y_{s,i}$, $y_{b,i}$は潜在変数$w$をアフィン変換したものであり、これは特徴マップを正規化した後にスタイルを適用していることを意味する
stylegan.py
def AdaIN(x):
#Normalize x[0]
mean = K.mean(x[0], axis = [1, 2], keepdims = True)
std = K.std(x[0], axis = [1, 2], keepdims = True) + 1e-7
y = (x[0] - mean) / std
#Reshape gamma and beta
pool_shape = [-1, 1, 1, y.shape[-1]]
g = tf.reshape(x[1], pool_shape) + 1.0
b = tf.reshape(x[2], pool_shape)
#Multiply by x[1] (GAMMA) and add x[2] (BETA)
return y * g + b
Noise Input
- 確率的な変動を作るために、データ空間にノイズを導入する
- こうしたノイズは、髪の毛やしわ、そばかすなど細かい特徴に変化をもたらすことが実験的にわかっている

A Style-Based Generator Architecture for Generative Adversarial Networks
stylegan.py
# === Generator ===
#Inputs
inp_style = []
for i in range(n_layers):
inp_style.append(Input([512]))
inp_noise = Input([im_size, im_size, 1])
#Latent
x = Lambda(lambda x: x[:, :128])(inp_style[0])
#Actual Model
x = Dense(4*4*4*cha, activation = 'relu', kernel_initializer = 'he_normal')(x)
x = Reshape([4, 4, 4*cha])(x)
x = g_block(x, inp_style[0], inp_noise, 16 * cha, u = False) #4
x = g_block(x, inp_style[1], inp_noise, 8 * cha) #8
x = g_block(x, inp_style[2], inp_noise, 6 * cha) #16
x = g_block(x, inp_style[3], inp_noise, 4 * cha) #32
x = g_block(x, inp_style[4], inp_noise, 3 * cha) #64
x = g_block(x, inp_style[5], inp_noise, 2 * cha) #128
x = g_block(x, inp_style[6], inp_noise, 1 * cha) #256
x = Conv2D(filters = 3, kernel_size = 1, padding = 'same', kernel_initializer = 'he_normal')(x)
self.G = Model(inputs = inp_style + [inp_noise], outputs = x)
Style Mixing & Mixing regularization
- StyleGANはアップサンプリングを行うことによって、徐々に生成画像の解像度が上がっていくが、各レベルにおいて異なる潜在空間$w$(スタイル)を適用させることで生成画像のスタイルを制御できる
stylegan.py
#Mixing Regularities
nn = noise(8)
n1 = np.tile(nn, (8, 1))
n2 = np.repeat(nn, 8, axis = 0)
tt = int(n_layers / 2)
p1 = [n1] * tt
p2 = [n2] * (n_layers - tt)
latent = p1 + [] + p2
generated_images = self.GAN.GMA.predict(latent + [nImage(64), trunc], batch_size = BATCH_SIZE)
- 次に示す画像は、Source BのスタイルをSource Aに適応した例
- Coarse stylesは低解像度(4×4~8×8), Middle stylesは中解像度(16×16~32×32), Fineは高解像度(64×64~1024×1024)の時のスタイルをSource Aに適用した画像を表す
- 低解像度のスタイルを適用すると、顔の輪郭や向きなどの大まかな特徴が適用され、高解像度のスタイルを適用すると髪や肌の色など細かい特徴が適用されていることがわかる

A Style-Based Generator Architecture for Generative Adversarial Networks
結果
-
10,000 steps

-
20,000 steps

-
30,000 steps

-
40,000 steps

-
50,000 steps
