前提など
対象:
・Python初学者が対象
・過去記事「Pythonプログラムの基本(はじめの一歩)」を履修済であること。
開発環境: Windows、Visual Studio Code、Python3系
前々回構築した開発環境で学習を進めます。
※Windows10での使用を前提とするが、他OSでも大きく変わらないはずです。
前提: 初学者は公式ドキュメントを元に学習すべきであるが、
社内勉強会を前提としているため、基本を掻い摘んで駆け足で説明します。
※pipのupdateを促すメッセージなど表示されていますが今回は無視します。
今回のテーマ
今回ライブラリの使用を勉強するために、WEBからの情報取得を行います。WEBから情報取得について
WEBページから情報を取得する技術のことをWEBスクレイピングと言います。そもそも、WEBページはHTMLなどの文字列を受信してブラウザで表示していますので、受信した文字列の欲しいところだけ抜き出せば良いだけです。 注意: WEBスクレイピングを禁止しているサービスも有りますのでPG組む前に目的サイトの注意事項を要確認です。 X(Twitter) 、 AMAZON などは明確に禁止されている。
ライブラリの使用
WEBからの情報取得は色々な方法が有りますが、今回は、 requestsとBeautifulSoupと言うライブラリを使用します。
前回と同様にVSを使用してpythonファイルを作成して進めます。
以下の様に test_py.py ファイルを作成します。
VS下部ウィンドのターミナルからpipコマンドではrequestsをインストールします。
pip install requests
インストール成功すると以下のように成ります。

WEBページ情報を取得する
Requestsライブラリを使用して、目的のWEBサイトのURLを指定してHTMLテキストを取得します。RequestsはPythonでのHTTPリクエストを簡単で使い易くした物です。
以下のソースをtest_py.pyに打ち込んでください。
import requests
get_data = requests.get('https://www.chancelab.jp/')
print(get_data.text)
1行目の
import requests
の記述により、requestsを利用できるようになります。
2行目の
get_data = requests.get('https://www.chancelab.jp/')
の記述は、指定のURLへリクエストしタグ情報(HTML)を取得します。
実行結果は下部ウィンドのターミナルに出力されます。

特定の情報を取得する-1
BeautifulSoupライブラリを使用して特定の情報だけを取得します。BeautifulSoupはいわゆるXMLパーサを使い易くした物です。
以下の様にpipコマンドでインストールしてください。
pip install beautifulsoup4
↓ 実行後の表示

test_py.pyを以下のように書き換えてください。
import requests
from bs4 import BeautifulSoup
get_data = requests.get('https://www.chancelab.jp/')
soup_data = BeautifulSoup(get_data.text, 'html.parser')
print(soup_data.p) # pタグの文字列を取得する ※最初の行しか取れない
2行目の
from bs4 import BeautifulSoup
の記述は、bs4モジュール内のBeautifulSoupだけをimportしています。
4行目の
soup_data = BeautifulSoup(get_data.text, 'html.parser')
の記述は、3行目で取得したHTMLをタグとして扱いやすい形にパースして、soup_data 変数に保存しています。
5行目の
print(soup_data.p)
の記述は、コメントにあるように、一番最初に見つけたpタグを指定(取得)して、print出力しています。
↓ 実行後の表示
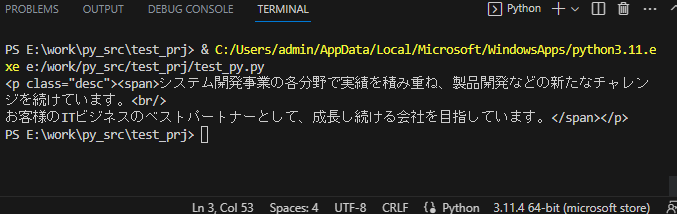
特定の情報を取得する-2
「特定の情報を取得する-2」の実装の様に、タグ指定での取得は最初に見つけたタグしか取得できません。 セレクタを使用して取得してみましょう。test_py.pyを以下のように書き換えてください。
import requests
from bs4 import BeautifulSoup
get_data = requests.get('https://www.chancelab.jp/')
soup_data = BeautifulSoup(get_data.text, 'html.parser')
p_teams = soup_data.select('p') # pタグの全行を取得する
for p_man in p_teams:
print(p_man)
5行目の
p_teams = soup_data.select('p')
の記述は、soup_datap内のpタグを全てを取得して、p_teams変数(リスト)に保存します。
6~7行目の
for p_man in p_teams:
print(p_man)
の記述は、
6行目、p_teamsリストから一件ずつp_man変数に取り込み、件数分繰り返します。最後まで読み終わったら繰り返しは終了です。
7行目、インデントされた print(p_man)は、p_man変数のprintを行いますが、前述のループで繰り返し処理されます。
↓ 実行後の表示
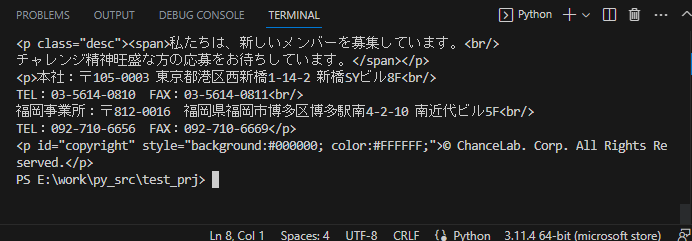
実行結果から、pタグが3箇所あったことが分かります。
ザックリですが、上記の応用でWEBスクレイピングは可能ですよね。
参考:
今日はココまで~