
にゃーん。 趣味でポスグレをやってる者だ。
ぬこは激怒した。かのアドベントカレンダー(あどべんとかれんだー)の記事を締切までに書かねばなければならぬと決意した。
ぬこにはポスグレがわからぬ。ぬこは、ハマのサラリマンである。麺を食べ、象と遊んで暮して来た。けれども締切に対しては、人一倍に敏感であった。
はじめに
これはPostgreSQL Advent Calender 2021の14日目の記事です。
前日は@kasa_zipさんの「PostgreSQLの拡張機能を作ってpgxnで公開する」という記事でした。つよつよな人の後の記事でちょい緊張しますね(そしてさりげなく一部ネタかぶりしてる)。
さて今回は、珍しくラーメン&PostgreSQLネタから離れて、フツーにPostgreSQLの話をします。


今日のお題は・・・PostgreSQL使いにはお馴染み、みんな大好きpgbenchについて書いてみました。
ちょい長いです。お暇なら読んでね!
pgbench is 何?
今更だけど一応説明すると、pgbenchは、PostgreSQLコミュニティが提供している簡易ベンチマークツール。
PostgreSQL 13文書 - pgbench
公式文書を見ると、
おおよそTPC-Bに基いたシナリオを試験します。
とのこと。
きちんとしたベンチマーク試験として、OLTP系ならTPC-W/DBT-1/DBT-2, OLAP系ならTPC-H/TPC-DS/DBT-3、NewSQL系との比較にはYCSBとかを使うだろうけど、とりあえず簡易的に実行環境のおおよその性能を知りたいときに、このpgbenchという簡易なベンチマークを使うこともあるかと思う。
なんといってもPostgreSQLをインストールするだけで使えるのが一番の魅力。
しかし、自分でも今回調べてみてわかったけど、意外とpgbenchの機能をほとんど使っていないことに気づいた。
ぜんぜんわからない。
俺たちは雰囲気でpgbenchをやっていた。
pgbenchの基本
PostgreSQL 14.1のpgbenchを動かすとこんな感じになる。
pgbenchを動かす場合、まず最初に初期化を行う。この例はスケールファクタ=10(だいたい150MB程度のサイズのデータ)でpgbench用のテーブルを作成し、初期データを登録している。
$ pgbench -i -s 10 -q bench
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
1000000 of 1000000 tuples (100%) done (elapsed 2.25 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done in 3.59 s (drop tables 0.00 s, create tables 0.01 s, client-side generate 2.37 s, vacuum 0.32 s, primary keys 0.90 s).
$
初期化した後に、-iをつけずにpgbenchを実行するとベンチマーク用に負荷をかけ、負荷実行後に、ベンチマーク結果を表示する。
下の例では、2つのクライアントから負荷を60秒かける、というものになる。
$ pgbench -c 2 -T 60 bench
pgbench (14.1)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10
query mode: simple
number of clients: 2
number of threads: 1
duration: 60 s
number of transactions actually processed: 68121
latency average = 1.762 ms
initial connection time = 4.060 ms
tps = 1135.350795 (without initial connection time)
$
ベンチマーク結果は下のほうにあるlatency averageやtpsの数値で評価する。上記の例だと、
- 68121トランザクションが実行され
- その平均レイテンシは1.722ms
- スループット(秒間あたりの処理数)は1135.350795
という結果になる。結果を評価するときにはスループットと平均レイテンシをまず見ることになる。
pgbenchの変遷
pgbench自体は非常に古くから存在するツールだ。自分の覚えている限りでも、PostgreSQL 7.4の時代からあったはず。
とはいえ、さすがにそこまで古いバージョンを今更使う人もいないとは思うので、ここではPostgreSQL 10以降のpgbenchの変遷について簡単にまとめたいと思う。
コマンドパラメータ
登場したてのころのpgbenchのコマンドパラメータは非常にシンプルものだったが、PostgreSQL 10時点では多くのパラメータが追加されている。
PostgreSQL 10~PostgreSQL 14版でのパラメータの変遷を以下にまとめた。
初期化用パラメータ
初期化用パラメータについては、PostgreSQL 13でパーティションテーブルに対応したオプションが2つ追加されたのみ。意外と変更は少ない。
| パラメータ名 | 概要 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|
| -i --initialize |
初期化モード指定用 | ● | ● | ● | ● | ● |
| -I init_steps --init-steps=init_steps |
初期化ステップの詳細指定 | - | ● | ● | ● | ● |
| -F fillfactor --fillfactor=fillfactor |
フィルファクタ指定 デフフォルトは100 |
● | ● | ● | ● | ● |
| -n --no-vacuum |
指定すると初期化後にVACUUMをしない | ● | ● | ● | ● | ● |
| -q --quiet |
メッセージを抑止するモードで実行する | ● | ● | ● | ● | ● |
| -s scale_factor --scale=scale_factor |
初期生成するデータ量を指定する | ● | ● | ● | ● | ● |
| --foreign-keys | テーブル間に外部キーを設定する | ● | ● | ● | ● | ● |
| --index-tablespace=index_tablespace | インデックスを配置するテーブル空間を指定する | ● | ● | ● | ● | ● |
| --partition-method=NAME | パーティション分割方式を指定する hash or range |
- | - | - | ● | ● |
| --partitions=NUM | パーティション数を指定する | - | - | - | ● | ● |
| --tablespace=tablespace | テーブルを配置するテーブル空間を指定する | ● | ● | ● | ● | ● |
| --unlogged-tables | テーブルをUNLOGGED TABLEで作成する | ● | ● | ● | ● | ● |
--init-steps補足
-Iオプションの後には初期化ステップを示す文字を指定することで、任意の初期化ステップのみを実行することができる。
|ステップ名|概要|11|12|13|14|
|:--|:--|:-:|:-:|:-:|:-:|:-:|
|d|pgbenchのテーブルの削除|●|●|●|●|
|t|pgbenchテーブルの作成|●|●|●|●|
|g|クライアント側データ生成|●|●|●|●|
|G|サーバ側データ生成|-|-|●|●|
|v|VACUUM実行|●|●|●|●|
|p|プライマリキーインデックスの作成|●|●|●|●|
|f|外部キー制約の作成|●|●|●|●|
-
G(サーバ側データ生成)ステップはPostgreSQL 13以降でないと使用できないので注意すること。 -
gステップを設定した場合、データの生成とCOPYが行われるが、PostgreSQL 15以降では、パーティション構成でない、かつサーババージョンがPostgreSQL 14以降の場合、COPYをFREEZEオプションつきで実行する。これにより後続のVACUUMを高速化するらしい。1 -
fステップはデフォルトの初期化動作では対象外になっているので、--init-stepsでfを明示的に指定する(--foreign-keys指定でも良い)。 - 上記以外のステップ名文字列を指定した場合には、pgbenchはパラメータエラーとして何も処理せず終了する。
--init-steps指定の例を示す。以下の例では、d(テーブル削除)→t(テーブル作成)→p(PK作成。普通はデータ生成&ロード後に指定する)→G(サーバ側でデータ生成&ロード)を行っている。VACUUMは実施していない。
$ pgbench -i --init-steps=dtpG -s 10 bench
dropping old tables...
creating tables...
creating primary keys...
generating data (server-side)...
done in 2.84 s (drop tables 0.03 s, create tables 0.01 s, primary keys 0.01 s, server-side generate 2.80 s).
--init-steps時の注意点
なお、--init-stepsに指定したステップは重複していても何もチェックされない。なので下記のような意味のない指定もできてしまう。
$ psql bench -c "\d"
Did not find any relations.
なにもテーブルがない状態からpgbenchの初期化をinit-steps=dtgGvpdに従って行う。たとえ最後にdの文字があっても・・・。
$ pgbench -i --init-steps=dtgGvpd -s 10 bench
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
1000000 of 1000000 tuples (100%) done (elapsed 1.09 s, remaining 0.00 s)
generating data (server-side)...
vacuuming...
creating primary keys...
dropping old tables...
done in 8.46 s (drop tables 0.00 s, create tables 0.01 s, client-side generate 1.13 s, server-side generate 6.57 s, vacuum 0.23 s, primary keys 0.49 s, drop tables 0.03 s).
テーブルを削除→CREATE TABLE→クライアント側でデータ生成→サーバ側でデータ生成→VACUUM→PK作成→テーブル削除 を行う。
$ psql bench -c "\d"
Did not find any relations.
$
なので、結局は何も生成されていない。にゃーん。
ベンチマーク用
ベンチマーク用パラメータについては、PostgreSQL 12以降は変更はなし。
PostgreSQL 11で--random-seed=seedが、PostgreSQL 12で--show-script=scriptnameが追加されたのみ。
| パラメータ名 | 概要 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|
| -b scriptname[@weight] --builtin=scriptname[@weight] |
組み込み処理比率を指定する | ● | ● | ● | ● | ● |
| 同時実行セッション数を指定する | -c clients --client=clients |
● | ● | ● | ● | ● |
| -C --connect |
トランザクション毎に接続する | ● | ● | ● | ● | ● |
| -d --debug |
デバッグ用出力を表示 | ● | ● | ● | ● | ● |
| -D varname=value --define=varname=value |
独自スクリプト用の変数を定義する | ● | ● | ● | ● | ● |
| -f filename[@weight] --file=filename[@weight] |
独自スクリプトと比率を指定する | ● | ● | ● | ● | ● |
| -j threads --jobs=threads |
pgbench内のワーカスレッド数を指定する | ● | ● | ● | ● | ● |
| -l --log |
各トランザクションに関する情報をログファイルに書き出す | ● | ● | ● | ● | ● |
| -L limit --latency-limit=limit |
指定レイテンシを超えたトランザクションを遅延として別レポートする | ● | ● | ● | ● | ● |
| -M querymode --protocol=querymode |
クエリ送信プロトコルを指定する。 | ● | ● | ● | ● | ● |
| -n --no-vacuum |
テスト実行前にvacuumを実施しない 独自スクリプト実行時に必要なオプション |
● | ● | ● | ● | ● |
| -N --skip-some-updates |
内蔵のsimple-updateスクリプトを実行します | ● | ● | ● | ● | ● |
| -P sec --progress=sec |
指定秒ごとにレポートを出力 | ● | ● | ● | ● | ● |
| -r --report-latencies |
ステートメントごとの平均レイテンシを出力する | ● | ● | ● | ● | ● |
| -R rate --rate=rate |
指定されたレートでトランザクションを実行する | ● | ● | ● | ● | ● |
| -s scale_factor --scale=scale_factor |
pgbenchの出力時に指定したスケールファクターを報告する | ● | ● | ● | ● | ● |
| -S --select-only |
組み込みのSELECT専用スクリプトを実行する | ● | ● | ● | ● | ● |
| -t transactions --transactions=transactions |
ベンチマークを指定したトランザクション数実行する | ● | ● | ● | ● | ● |
| -T seconds --time=seconds |
ベンチマークを指定した秒数を実行する | ● | ● | ● | ● | ● |
| -v --vacuum-all |
テストを実行前に、標準テーブルをすべてバキュームする | ● | ● | ● | ● | ● |
| --aggregate-interval=seconds | インターバルごとのサマリーデータを出力する。 | ● | ● | ● | ● | ● |
| --log-prefix=prefix | --logで作成されるログファイルのファイル名のプレフィックスを設定する | ● | ● | ● | ● | ● |
| --random-seed=seed | ランダムジェネレーターのシードを設定する | - | ● | ● | ● | ● |
| --sampling-rate=rate | ログにデータを書き込む際に使用されるサンプリングレート | ● | ● | ● | ● | ● |
| --show-script=scriptname | スクリプトscriptnameの実際のコードをstderrに表示し、直ちに終了する | - | - | ● | ● | ● |
共通オプション
共通オプションについては、PostgreSQL 10~PostgreSQL 14の間での変更はなし。
| パラメータ名 | 概要 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|
| -h hostname --host=hostname |
接続先ホスト名を指定する | ● | ● | ● | ● | ● |
| -p port --port=port |
接続先ポート番号を指定する | ● | ● | ● | ● | ● |
| -U login --username=login |
接続ユーザ名を指定する | ● | ● | ● | ● | ● |
| -V --version |
バージョン番号を表示して終了する | ● | ● | ● | ● | ● |
| -? --help |
引数の説明を表示して終了する | ● | ● | ● | ● | ● |
独自スクリプトの機能
pgbenchには独自スクリプトという機能があり、これによってpgbench規定のトランザクションに指定されたDMLでない、任意のDMLを発行することができる。
この独自スクリプトは、最初の頃は実行するSQL文や、最小限の制御用の変数をもったシンプルなものだったが、今は簡単な制御文や各種関数が実行できたりと、かなり高度な機能をもつようになっている。
(逆に言うとあまりにも高度・マニアック過ぎてあまり使われていないんじゃないか疑惑も)
自動変数
独自スクリプトでは任意の変数を使うことができる。
以下の変数はpgbenchによって自動的に値が設定される。
これも、PostgreSQL 10~PostgreSQL 14の間でいくつか追加されてる。
| 自動変数名 | 概要 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|
| client_id | クライアントセッションを識別する一意の数値 | ● | ● | ● | ● | ● |
| default_seed | ハッシュ関数で使われるデフォルトのシード | - | ● | ● | ● | ● |
| random_seed | ランダムジェネレータのシード | - | ● | ● | ● | ● |
| scale | 現在のスケールファクタ | ● | ● | ● | ● | ● |
メタコマンド
pgbenchの独自スクリプトには、psqlに良く似たコマンド体系をもつ、メタコマンドを記述することができる。
PostgreSQL 10~PostgreSQL 14までのメタコマンドの対応状況を以下に示す。
| メタコマンド名 | 概要 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|
| \gset | 単一行の検索結果の列名にあった名前の変数に格納する | - | - | ● | ● | ● |
| \aset | 複数の問い合わせの検索結果の列名にあった名前の変数に格納する | - | - | - | ● | ● |
| \if expression \elif expression \else \endif |
条件ブロック | - | ● | ● | ● | ● |
| \set varname expression | varname変数をexpressionから計算された値に設定する | ● | ● | ● | ● | ● |
| \sleep number | スクリプトの実行を停止する | ● | ● | ● | ● | ● |
| \setshell varname command | シェルコマンドの結果を変数に設定する | ● | ● | ● | ● | ● |
| \shell command | シェルコマンドを実行する | ● | ● | ● | ● | ● |
| \startpipeline \endpipeline |
SQL文のパイプラインの開始と終了を区切る | - | - | - | - | ● |
このメタコマンド、使いこなすといろいろ面白いことができそうだ。
組み込み演算子
pgbenchでは独自スクリプト内で使用できる組み込み演算子をもっている。
この演算子はメタコマンド内で使用することができる。
組み込み演算子はPostgreSQL 11から実装されている。そしてPostgreSQL 11~14の間では演算子の追加はない。PostgreSQL 11時点で完成されているということか。
また、組み込み演算子はbool/numberに限定されているため、文字型/日付・時刻型への対応はしていない。
| 演算子 | 概要 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|
| boolean OR boolean → boolean | 論理OR | - | ● | ● | ● | ● |
| boolean AND boolean → boolean | 論理AND | - | ● | ● | ● | ● |
| NOT boolean → boolean | 論理NOT | - | ● | ● | ● | ● |
| boolean IS [NOT] (NULL|TRUE|FALSE) → boolean | 値テスト | - | ● | ● | ● | ● |
| value ISNULL|NOTNULL → boolean | NULLテスト | - | ● | ● | ● | ● |
| number = number → boolean | 等価 | - | ● | ● | ● | ● |
| number <> number → boolean | 不等 | - | ● | ● | ● | ● |
| number != number → boolean | 不等 | - | ● | ● | ● | ● |
| number < number → boolean | より小さい | - | ● | ● | ● | ● |
| number <= number → boolean | 以下 | - | ● | ● | ● | ● |
| number > number → boolean | より大きい | - | ● | ● | ● | ● |
| number >= number → boolean | 以上 | - | ● | ● | ● | ● |
| integer | integer → integer | ビット毎のOR (|は実際には半角) |
- | ● | ● | ● | ● |
| integer # integer → integer | ビット毎のXOR | - | ● | ● | ● | ● |
| integer & integer → integer | ビット毎のAND | - | ● | ● | ● | ● |
| ~ integer → integer | ビット毎のNOT | - | ● | ● | ● | ● |
| integer << integer → integer | ビット毎の左シフト | - | ● | ● | ● | ● |
| integer >> integer → integer | ビット毎の右シフト | - | ● | ● | ● | ● |
| number + number → number | 加算 | - | ● | ● | ● | ● |
| number - number → number | 減算 | - | ● | ● | ● | ● |
| number * number → number | 乗算 | - | ● | ● | ● | ● |
| number / number → number | 除算 | - | ● | ● | ● | ● |
| integer % integer → integer | 剰余 | - | ● | ● | ● | ● |
| - number → number | 符号反転 | - | ● | ● | ● | ● |
組み込み関数
pgbenchでは独自スクリプト内で使用できる組み込み関数をもっている。
これらの関数はメタコマンド内で使用することができる。
組み込み関数はPostgreSQL 10の時点では既に実装されている。
PostgreSQL 11で数個追加された以降、PostgreSQL 13まで組み込み関数の追加はなし。PostgreSQL 14でpermute()が追加された。
| 演算子 | 概要 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|
| abs ( number ) | 絶対値 | ● | ● | ● | ● | ● |
| debug ( number ) | 引数をstderr出力 | ● | ● | ● | ● | ● |
| double ( number ) | 型変換 | ● | ● | ● | ● | ● |
| exp ( number ) → double | 指数 | - | ● | ● | ● | ● |
| greatest ( number [, ... ] ) | 引数内の最大値 | ● | ● | ● | ● | ● |
| hash ( value [, seed ] ) | ハッシュ関数 | - | ● | ● | ● | ● |
| hash_fnv1a ( value [, seed ] ) | ハッシュ関数 | - | ● | ● | ● | ● |
| hash_murmur2 ( value [, seed ] ) | ハッシュ関数 | - | ● | ● | ● | ● |
| int ( number ) | 型変換 | ● | ● | ● | ● | ● |
| least ( number [, ... ] ) | 引数内の最小値 | ● | ● | ● | ● | ● |
| ln ( number ) | 自然対数 | - | ● | ● | ● | ● |
| mod ( integer, integer ) | 剰余 | - | ● | ● | ● | ● |
| permute ( i, size [, seed ] ) | 範囲 [0, size] における i の順列値 | - | - | - | - | ● |
| pi () | πの近似値 | ● | ● | ● | ● | ● |
| pow ( x, y ) power ( x, y ) |
xのy乗 | - | ● | ● | ● | ● |
| random ( lb, ub ) | 一様分布の整数乱数 | ● | ● | ● | ● | ● |
| random_exponential ( lb, ub, parameter ) | 指数分布の整数乱数 | ● | ● | ● | ● | ● |
| random_gaussian ( lb, ub, parameter ) | ガウス分布の整数乱数 | ● | ● | ● | ● | ● |
| sqrt ( number ) | 平方根 | ● | ● | ● | ● | ● |
いろいろな使い方
ここからは、自分の復習も兼ねてpgbenchの様々な機能を使ってみる。
--partition-method/--partitions
このオプションはPostgreSQL 13から使用可能なオプションである。
名前のとおり、pgbenchのデフォルトトランザクション用のテーブルを単一のテーブルではなく、パーティション化するオプションである。
たぶん、パーティション化したときにどのくらい性能オーバヘッドがあるのかを調べるのに使えそう。
とりあえず動かしてみた。
$ pgbench -i -s 100 --partitions=3 bench
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
creating 3 partitions...
generating data (client-side)...
10000000 of 10000000 tuples (100%) done (elapsed 34.33 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done in 68.49 s (drop tables 0.00 s, create tables 0.01 s, client-side generate 34.45 s, vacuum 18.84 s, primary keys 15.19 s).
生成途中にcreating 3 partitions...というメッセージが出力される。
作成したあとのテーブルの状態をpsqlで確認してみる。
bench=# \d
List of relations
Schema | Name | Type | Owner
--------+--------------------+-------------------+----------
public | pgbench_accounts | partitioned table | postgres
public | pgbench_accounts_1 | table | postgres
public | pgbench_accounts_2 | table | postgres
public | pgbench_accounts_3 | table | postgres
public | pgbench_branches | table | postgres
public | pgbench_history | table | postgres
public | pgbench_tellers | table | postgres
(7 rows)
bench=# \d+ pgbench_accounts
Partitioned table "public.pgbench_accounts"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
----------+---------------+-----------+----------+---------+----------+-------------+--------------+-------------
aid | integer | | not null | | plain | | |
bid | integer | | | | plain | | |
abalance | integer | | | | plain | | |
filler | character(84) | | | | extended | | |
Partition key: RANGE (aid)
Indexes:
"pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
Partitions: pgbench_accounts_1 FOR VALUES FROM (MINVALUE) TO (3333335),
pgbench_accounts_2 FOR VALUES FROM (3333335) TO (6666669),
pgbench_accounts_3 FOR VALUES FROM (6666669) TO (MAXVALUE)
bench=#
レンジ方式のパーティションテーブルが生成されていることが確認できる。
ちょっと面白いと思ったのはpgbench_accounts_1の最大値が3333333ではなく3333335であったこと。これ、何か理由あるのかな・・・?
さて、pgbenchではレンジ方式だけでなくハッシュ方式のパーティションも選択できる。ハッシュ方式の場合には、--partition-method=hashオプションを追加する。ハッシュ方式のテーブルの場合は以下のようにパーティションテーブルが生成される。
bench=# \d+ pgbench_accounts
Partitioned table "public.pgbench_accounts"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
----------+---------------+-----------+----------+---------+----------+-------------+--------------+-------------
aid | integer | | not null | | plain | | |
bid | integer | | | | plain | | |
abalance | integer | | | | plain | | |
filler | character(84) | | | | extended | | |
Partition key: HASH (aid)
Indexes:
"pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
Partitions: pgbench_accounts_1 FOR VALUES WITH (modulus 3, remainder 0),
pgbench_accounts_2 FOR VALUES WITH (modulus 3, remainder 1),
pgbench_accounts_3 FOR VALUES WITH (modulus 3, remainder 2)
bench=#
例えばパーティション数が非常に多い場合に、性能にどういった影響があるのか、などを簡単に調べられそうだ。もちろん、単純に宣言パーティション化した場合のオーバヘッドを見積もるようなケースでも使えると思う。
--rate オプション
pgbenchはデフォルトの動作では、全力で負荷をかける動作をするのだが、このオプションをつけることで、指定したtps以上の負荷をかけないような動作も可能である。
例えばある程度案件の性能要件(要求されるスループットなど)がわかっている場合には、このオプションをつけて実行することで、要求したtpsを満たせる環境なのかを推測することができる。
例えば今自分が使っている環境で動かしているPostgreSQL 14に対して16接続でpgbenchのデフォルトトランザクションを1000回動かすと、こんな感じの結果になる。
$ ~/pgsql/pgsql-14/bin/pgbench -c 16 -t 1000 bench
pgbench (14.1)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 100
query mode: simple
number of clients: 16
number of threads: 1
number of transactions per client: 1000
number of transactions actually processed: 16000/16000
latency average = 6.323 ms
initial connection time = 31.872 ms
tps = 2530.537659 (without initial connection time)
$
--rate=1000オプションをつけることで、1000tps程度になるように負荷を調整することができる。
$ ~/pgsql/pgsql-14/bin/pgbench --rate=1000 -c 16 -t 1000 bench
pgbench (14.1)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 100
query mode: simple
number of clients: 16
number of threads: 1
number of transactions per client: 1000
number of transactions actually processed: 16000/16000
latency average = 133.847 ms
latency stddev = 346.377 ms
rate limit schedule lag: avg 128.423 (max 1563.141) ms
initial connection time = 32.175 ms
tps = 988.558303 (without initial connection time)
$
全力で動かした場合には、2530 tpsだったが--rate=1000をつけた場合には、指定したtpsに近い988 tps程度になっていることがわかる。
また、このモードで動かした場合には、
- latency stddev
- rate limit schedule lag
の行も出力される。letancy averageを見るとlagも含めたlatencyが報告される。
この--rate指定つきで実行したときのデータベースサーバのリソース使用状況などを計測して、要求されたスループットだとリソースの利用状況に余裕があるか、みたいな確認に使えそうだ。
ログファイルの利用
pgbenchの実行時にはトランザクションが実行され、その個々のトランザクションのレイテンシが記録される。最終的にそれらを計算して平均レイテンシやスループット結果として出力される。
pgbenchのベンチマーク実行時に`--log``オプションを付与すると、個々のトランザクションのレイテンシの情報がファイルとして残る。このログファイルを元に、実行内容の詳細な分析が可能になっている。
--log 形式のファイルの利用方法
ログフォーマットの詳細はPostgreSQL文書のトランザクション毎のログ処理を参照。
これを具体的にどう利用していくかを例にしてみる。
file_fdw経由でアクセス可能にする
このログファイルをExcelやLibreOfficeなどに食わせて処理してもいいのだが、ログファイルは空白セパレートのファイルとして生成してあるので、これをfile_fdwを使ってSQLで処理できるようにする。
file_fdwによる外部テーブルをおくデータベースをてきとーに作成し、そのデータベースにfile_fdwをCREATE EXTENSIONで登録しておく。その状態で、以下のようにCREATE SERVERコマンドとCREATE FOREIGN TABLEコマンドを使って外部サーバと外部テーブルを登録する。
CREATE SERVER files FOREIGN DATA WRAPPER file_fdw ;
CREATE FOREIGN TABLE pgbench_log
(client_id int, transaction_no int, time int, script_no int, time_epoch int, time_us int)
SERVER files
OPTIONS (filename '/tmp/pgbench_log', delimiter ' ')
;
そして、pgbenchを--logオプションつきで実行したときに生成されるログファイル(pgbench_log.xxxxといった名称になっているはず)を/tmp/pgbench_logにコピーする。
これで、SELECT文でpgbenchの実行ログが参照可能になった。あとはお好きに。
セッション毎のレイテンシの統計情報を取得する
例えば、セッション(client_id)毎のレイテンシのmin/max/avg/stddevなんかもクエリ一撃で取得できるようになる。
test=# SELECT client_id, max(time), min(time), ROUND(avg(time),3) avg, ROUND(stddev(time),3) stddev
FROM pgbench_log
GROUP BY client_id
;
client_id | max | min | avg | stddev
-----------+-------+------+----------+---------
0 | 11773 | 1101 | 1526.029 | 304.812
1 | 11845 | 1062 | 1529.465 | 307.595
(2 rows)
レイテンシの分布状況を精査する
今度はレイテンシの分布状況を精査するために、レイテンシのヒストグラムを算出してみる。
ヒストグラムの算出のためには、width_bucket()というSQL関数を使う。さっき、レイテンシの最小値と最大値を算出しているので、それを元にwidth_bucket()の最大値(12000あたりで良さげ)と区間数(テキトーに120くらいにしておく)を与えて実行する。で、その実行結果に対して、レイテンシ区間(0.1ms幅)でGROUP BY/ORDER BYをかけると以下のような結果が取得できる。
test=#
WITH t AS (
SELECT width_bucket(time, 0, 12000, 120) as wb
FROM pgbench_log
)
SELECT ROUND(wb::numeric / 10,1) lt, count(*)
FROM t
GROUP BY wb ORDER BY wb
;
lt | count
------+-------
1.1 | 3
1.2 | 85
1.3 | 824
1.4 | 2040
1.5 | 2475
(後略)
単にこれを表示するのも芸がないので、この検索結果をLibreOfficeでプロットしてみる。
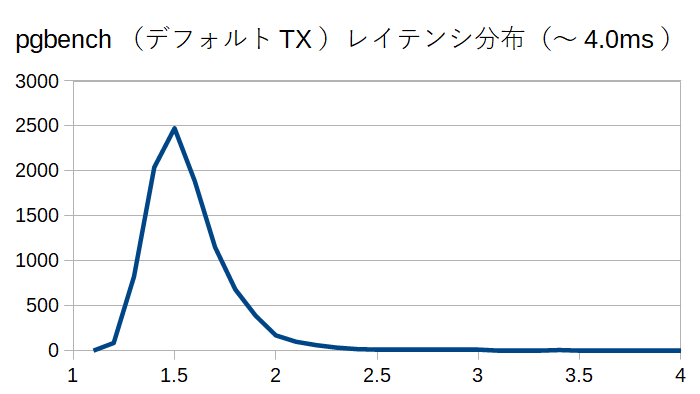
と、こんな感じで1.5ms付近を中心に多くのレイテンシが分布している、といった傾向を見ることができる。
自分は統計の専門家ではないので、これ以上はあまり詳しくは言えないけど、統計に詳しい人だと、もっと色々有益な分析ができるかもしれない。
--aggregate-interval 指定時のログファイルの利用方法
--logオプションと一緒に--aggregate-intervalを指定した場合、--logオプションにより生成されるログファイルとは別形式の集約されたログファイルが生成される。
このログファイルは--aggregate-intervalで指定した間隔で1行分のログを出力する。--aggregate-interval=10と指定すれば10秒間のトランザクションに関する集計情報を出力することになる。
ログフォーマットの詳細はPostgreSQL文書のログ処理の集約を参照。
これを具体的にどう利用していくかを例にしてみる。
集約ログフォーマットについての補足
ちょい面倒なことに、集約ログファイルはpgbenchのオプション指定によって出力される列が変わってくる。以下にオプションと出力される列の対応を整理する。
| 列番号 | 内容 | --aggregate-interval | --aggregate-interval --rate |
--aggregate-interval --rate --latency-limit |
|---|---|---|---|---|
| 1 | interval_start インターバルの開始時刻 |
○ | ○ | ○ |
| 2 | num_of_transactions インターバル内のトランザクション数 |
○ | ○ | ○ |
| 3 | latency_sum インターバル内のトランザクションレイテンシの総和(μs) |
○ | ○ | ○ |
| 4 | sum_latency_2 インターバル内のトランザクションレイテンシの2乗の総和 |
○ | ○ | ○ |
| 5 | min_latency インターバル内の最小レイテンシ(μs) |
○ | ○ | ○ |
| 6 | max_latency インターバル内の最大レイテンシ(μs) |
○ | ○ | ○ |
| 7 | sum_lag トランザクションの予定開始時刻と実際の開始時刻の差の総和 |
- | ○ | ○ |
| 8 | sum_lag_2 トランザクションの予定開始時刻と実際の開始時刻の差の2乗の総和 |
- | ○ | ○ |
| 9 | min_lag トランザクションの予定開始時刻と実際の開始時刻の差の最小値 |
- | ○ | ○ |
| 10 | max_lag トランザクションの予定開始時刻と実際の開始時刻の差の最最大値 |
- | ○ | ○ |
| 11 | skipped 開始時刻が遅くなったためにスキップされたトランザクション数 |
ー | - | ○ |
--aggregate-intervalのみ
これは--aggregate-interval=1のみを指定したときのログファイルの例
$ head -3 pgbench_log.19063
1638744607 213 350881 603333723 1161 4514
1638744608 1175 1993833 3568658223 1193 5488
1638744609 1196 1997489 3507619861 1187 6485
- 2列目はトランザクション数。1行目は1秒フルにカウントしていない可能性があるので、2行目に比べると数は小さい。
- 3列目はレイテンシの総和。なので、これを2列目の数で割るとその時間帯での平均レイテンシになるのかな。
- 4列目はレイテンシ2乗の総和。これの使い方は自分では良くわかっていない。これから分散が求められるわけでもないしなあ・・・。
- 5列目,6列目はレイテンシの最小値,最大値。こうやって見ると結構最大値が異常値っぽく見えるよな。
--aggregate-intervalと--rateの場合。
これは--aggregate-interval=1 --rate=1000を指定したときのログファイルの例
$ head -3 pgbench_log.19111
1638744812 813 2435337 8948116769 1230 9019 1136761 3258452673 1 7593
1638744813 1080 3979466 19601370542 1199 11365 2287778 9793293540 1 9964
1638744814 1051 3045304 10801757262 1235 10029 1428528 3937561034 0 8638
項番1~6の説明は省略。項番7~項番10のlagがついた情報が出力されるのが、この形式の特徴。
- 項番7は
sum_lag。例えば2行目だと2287778になっている。これを2列目のトランザクション数1080で割ると平均のラグになるのかな。この例だと2,118.3(μs)が平均のラグってことになる。このログを生成したときのpgbench結果にもラグに関する情報が出力されており、その内容はrate limit schedule lag: avg 2.382 (max 50.224) msになっているので、まあまあ妥当な結果なのかな。このラグが処理時間とともにどう変化していくのかを確認できるってことか。 - 項番8の
sum_lag2はラグの2乗の総和。これの使い方はよくわからない。 - 項番9,項番10はラグの最小値と最大値。2行目の例だと、最小値が1(μs)、最大値が9964(μs)になる。最小値の1ってなーんかアテにならない気もするが・・・。
--aggregate-interval,--rate,--latency-limit の場合
これは--aggregate-interval=1 --rate=1000 --latency-limit=5を指定したときのログファイルの例。--latency-limitは「5msを超えた」という指定になる。
$ head -3 pgbench_log.20207
1638748074 7 14340 31317928 1474 2977 2217 1135735 83 738 0
1638748075 1028 3103225 11172881799 1293 6744 1477664 3871118176 0 4887 13
1638748076 1011 2862680 9799954002 1220 8215 1246830 3103624474 0 4987 20
右端の列(項番11)が追加された「開始時刻が遅くなったためにスキップされたトランザクション数」になる。2行目は13トランザクション、3行目は20トランザクションがスキップされた(サーバにもクエリを送らなかった)トランザクション数を示す。
2行目,3行目のskippedの列を2列目のnum_of_transactionsの列で割ると、2行目は1.26%、3行目は1.90%になるんだけど、これがスキップされたトランザクションの比率ってことになるのかな。
この指定でpgbenchを動作させた場合、全体でスキップされたトランザクション数とその比率が出力される。今回の例だと、number of transactions above the 5.0 ms latency limit: 1181/9780 (12.076 %)という出力がされていた。これはさっきのスキップされたトランザクションを除外したもので、かつ5msを超えたトランザクションの比率を出力している、ということなのだろう。
なんかわかったようなわからんような感じではあるが、-aggregate-intervalを使うことで、時間経過に伴うトランザクション処理時間のおおまかな推移はつかめるのかもしれない。デフォルトのTPC-Bだとあまり傾向の変化はないのかもしれないけど、独自スクリプトで長時間ベンチマークを実行したときに(実行計画の変動等で)大きくレイテンシの傾向が変わるようなケースで有用なのかも。
独自スクリプトファイル
独自スクリプトファイルの概要
pgbenchではpgbench規定のトランザクション3種だけでなく、ユーザ任意のクエリを実行することができる。ユーザ任意のクエリを実行するためには、独自スクリプトファイルを作って、それを-f カスタムファイル名というオプションで指定する。
独自スクリプトファイルを使うことで、pgbench規定のテーブルではなく、任意のテーブルを対象にベンチマークを実行することが可能になる。
これを巧く使えば、実案件により近い形でのベンチマークを簡単に実行できる。
ただ、慣れないうちは独自スクリプトをゼロから書くのは大変なので、PostgreSQL文書にも書かれている、TPC-Bを独自スクリプトで実装したときのサンプルを元にするのがおすすめかも。
TPC-Bのサンプルはこんな感じになる(PostgreSQL文書から引用)。
\set aid random(1, 100000 * :scale)
\set bid random(1, 1 * :scale)
\set tid random(1, 10 * :scale)
\set delta random(-5000, 5000)
BEGIN;
UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
UPDATE pgbench_tellers SET tbalance = tbalance + :delta WHERE tid = :tid;
UPDATE pgbench_branches SET bbalance = bbalance + :delta WHERE bid = :bid;
INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
END;
上記の例を見ると、前半部分で独自スクリプトで使う変数への値のセットを、後半(BEGIN;~END;の間)に実行したいトランザクションのDMLを記述しているのがわかる。
メタコマンド(\set)等は必ず先頭部分に書くというものではなく、メタコマンドによってはDMLの後でないと意味のないものもある(\gset等)。
\set とdebug()
\setメタコマンドではpgbench独自スクリプトで使用できる変数に値を設定できる。
また、\setメタコマンドにdebug()という関数を指定して、設定した変数が意図したとおりになっているかを確認するデバッグ用の関数を併用できる。
例えば以下のような(DMLを発行しないダミーの)独自スクリプトファイルを例にする。
$ cat debug-1.txt
\set port 5432
\set foo debug(:port)
$
この独自スクリプトを3トランザクション分実行する。
$ pgbench bench -n -f debug-1.txt -t 3
pgbench (14.1)
debug(script=0,command=2): int 5432
debug(script=0,command=2): int 5432
debug(script=0,command=2): int 5432
transaction type: debug-1.txt
(後略)
$
debug(スクリプト番号,スクリプト内の行数)、表示対象の型・値が標準エラー出力に出力される。
\setで与えられる値
\setには基本的には数値文字列や数値式を設定することが多いが、他にもNULL文字列、TRUE/FALSEといったboolean文字列だけでなく、SQL式のCASEも使うことができる。
CASE式を使った\setの例を示す。
$ cat set_case.txt
\set foo random(1,2)
\set port CASE WHEN :foo = 1 THEN 5432 ELSE 3306 END
\set bar debug(:port)
$
これを実行すると、4行目のdebug()で5432か3306を出力する。
$ pgbench bench -n -f set_case.txt -t 3
pgbench (14.1)
debug(script=0,command=3): int 5432
debug(script=0,command=3): int 3306
debug(script=0,command=3): int 5432
transaction type: set_case.txt
(後略)
なお、debug()に与えられる引数は数値型のみに限定される。このため、後述の\gsetメタコマンドで非数値のデータを変数に格納した後、その変数をdebug()で表示しようとすると、そんな関数はねーよ、と怒られてしまう。
pgbench: error: malformed variable "g_tdata" value: "ABC"
pgbench: error: client 0 aborted in command 3 (set) of script 0; evaluation of meta-command failed
にゃーん。
乱数関数各種
ベンチマーク用のデータを生成したり、ベンチマーク実行時の条件値を作るために、pgbenchでは乱数を発生させる関数を用意している。先程のTPC-Bを擬似した独自スクリプトでも先頭部分で乱数を発生させて値をpgbench用の変数に設定していた。
\set aid random(1, 100000 * :scale)
\set bid random(1, 1 * :scale)
\set tid random(1, 10 * :scale)
\set delta random(-5000, 5000)
上記の例では乱数を発生させるのにrandom()という関数を使用している。
pgbenchでは単純な一様分布の乱数だけでなく、他に3種類の分布を擬似する乱数用関数が用意されている。この乱数関数も使いこなすと、より現実的なベンチマークモデルを作ることができるかもしれない。
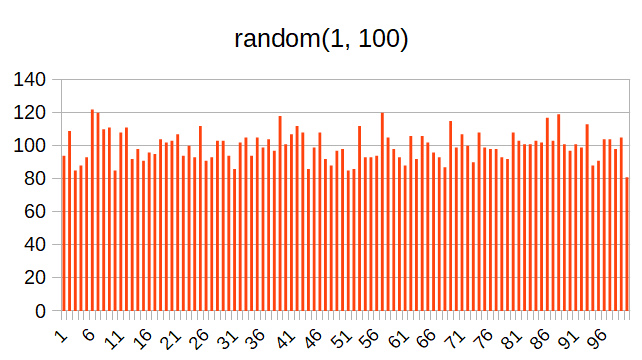
random()
最初に紹介するのは一番単純なrandom()という関数。
上のTPC-Bサンプルの例では、最初の数行の箇所でrandom()という関数が使用されている。random()の引数は2つあり、最初の引数は乱数の区間の最小値、2つ目の引数は乱数の区間の最大値となる。
このrandom()関数で生成される乱数は「一様分布」をとる。
random()で生成される値の分布を実際に動作させて調べてみる。
まず、こんな簡単なテーブルを定義しておく。
$ psql bench -c "\d test"
Unlogged table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+----------------------------------
id | integer | | not null | nextval('test_id_seq'::regclass)
data | integer | | |
このテーブル対して、random()で1~100の範囲で生成した数値データを挿入するだけの簡単な独自スクリプト作成する。
$ cat random-ins.txt
--
-- target table
-- create unlogged table test (id serial, data int)
--
\set data random(1, 100)
INSERT INTO test VALUES ( :data );
$
そして、pgbenchの独自スクリプト機能を使って、上記の独自スクリプトファイルの内容を10000回実行してみる。
$ pgbench bench -n -f random-ins.txt -t 10000
pgbench (14.1)
transaction type: random-ins.txt
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10000
number of transactions actually processed: 10000/10000
latency average = 0.094 ms
initial connection time = 1.901 ms
tps = 10646.225913 (without initial connection time)
挿入後にdataの内容を確認してみる。
bench=# SELECT data, count(data) FROM test GROUP BY data ORDER BY data;
data | count
------+-------
1 | 94
2 | 109
(中略)
99 | 105
100 | 81
(100 rows)
これをグラフにプロットしてみるとこんな感じになる。予想よりは凸凹しているけど、まあ一様分布という感じではある。
random_exponential()
この関数は指数分布の乱数を発生する関数である。第1引数と第2引数で範囲を指定するが、これに加えて第3引数で分布を制御する。雑に言うと、第3引数が大きいとより偏った分布になる。以下、第3引数を5にしたときと10にしたときの分布の例を示す。
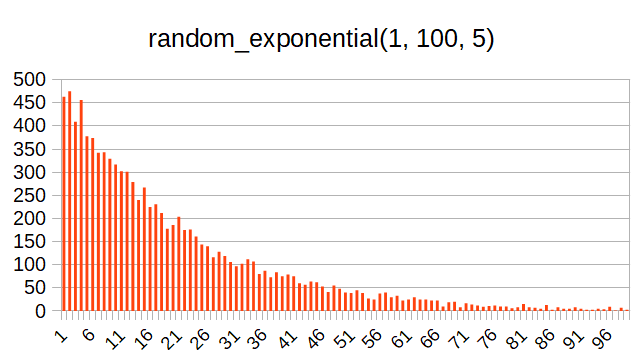
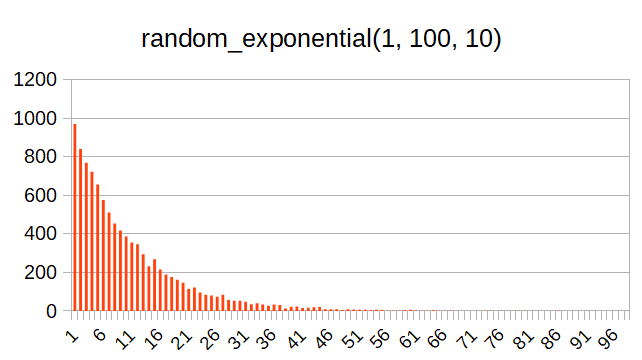
この分布は、例えばラーメンデータベースにおいて、あるユーザがレビューした件数の分布に近い(PostgreSQLでヒストグラムっぽいのを作る 参照)。
ほとんどのユーザのレビュー数は0または1に近いのだが、一部のヘビーユーザのレビュー数は非常に多いという傾向を示している。なので、それっぽい分布を擬似するときにこの関数は使えそうだ。
random_gaussian()
この関数は正規分布=ガウス分布(自分は数学の徒ではないので、専門的なことはわかっていない。Wikipediaのリンクをとりまつけておく。→正規分布)の乱数を発生する関数である。
この関数も第1引数と第2引数で乱数の範囲を指定し、第3引数で分布の調整をする。雑に言うと、この値を大きくすると、より中央の値が選ばれやすくなる。
以下、第3引数を2.0(最小値)にしたときと4.0にしたときの分布の例を示す。
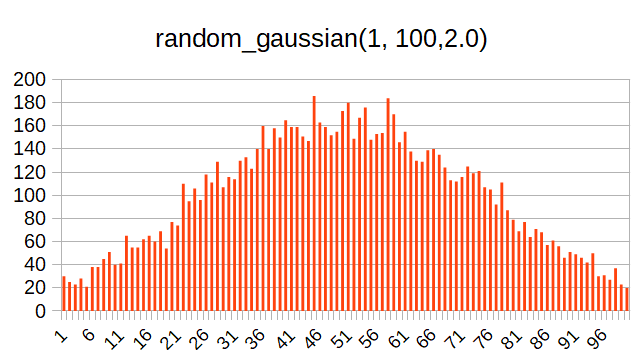
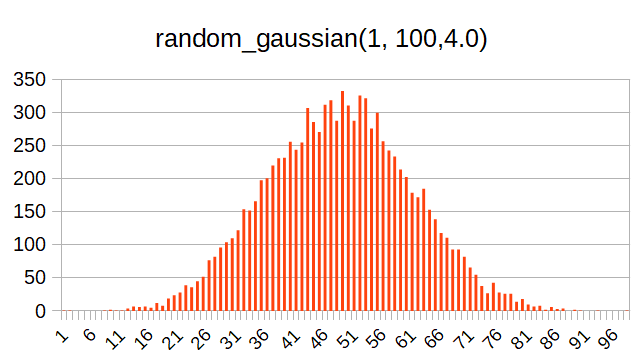
この分布は、ラーメンデータベースで例えると、全ユーザの採点の分布に似ている。
(麺とポスグレと私 「ヒストグラム」の項を参照)
random_zipfian()
この乱数関数は自分ではあまり馴染みのないもの。初めて使ってみる関数だ。
ジップの法則というものに基づいて乱数を分布を生成するものっぽい。
読むだけだとイメージが掴みづらいので、これも実際に動かして結果を見てみる。
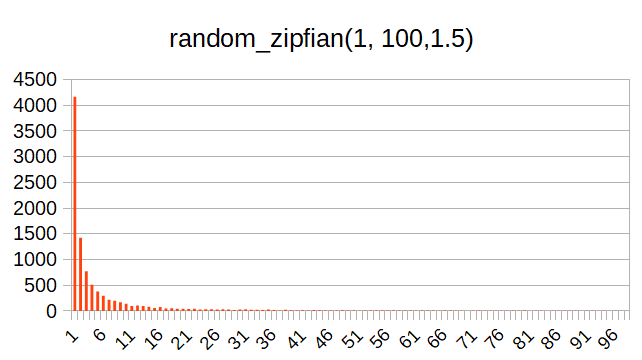
お、こっちのほうが、ラーメンデータベースにおけるレビューアごとのレビュー数分布に近いかもしれないな。
ここまで4種類の乱数発生関数について見てみたが、用途によってこれらを巧く使い分けると現実のモデルに近い乱数データを作り出せるかもしれない。
permute()
この組み込み関数はPostgreSQL 14で追加された関数である。PostgreSQL文書の説明を見ると
Permuted value of i, in the range [0, size). This is the new position of i (modulo size) in a pseudorandom permutation of the integers 0...size-1, parameterized by seed, see below.
擬似的乱数順列の中の順番(position)を返却する関数らしい・・・いったいどういう用途があるのか、これだけ読んでもピンとこない。
また引数として、レンジ最小値(必須)、レンジ最大値(必須)、シード(オプション)の3つの引数を与えるのだが、シードについての説明が書いてないので、どういう役割をするのかがよくわからない・・・。
ということで実際に動かして動作を見てみる。
今回はpermute_seed1.txtとpermute_seed2.txtという2つの独自スクリプトファイルを用意する。
$ cat permute_seed1.txt
\set p debug(permute(1, 100))
\set q debug(permute(1, 100, 125))
$ cat permute_seed2.txt
\set p debug(permute(1, 100))
\set q debug(permute(1, 100, 256))
$
- どちらのファイルも2回permute()を発行する。
- 変数
pにセットするpermute()はシードなし、変数qにセットする -
permute()にはシードの整数値を設定する。シードの値は、permute_seed1.txtとpermute_seed2.txtで別のものを設定する。
この2つ独自スクリプトファイルを同じ比率(@5)で2クライアントから、1クライアントあたり4回実行する。このpgbenchの実行では8回のpermute()が動作することになる。
$ pgbench bench -n -f permute_seed1.txt@5 -f permute_seed2.txt@5 -t 4
pgbench (14.1)
debug(script=0,command=1): int 47
debug(script=0,command=2): int 56
debug(script=1,command=1): int 47
debug(script=1,command=2): int 81
debug(script=0,command=1): int 47
debug(script=0,command=2): int 56
debug(script=1,command=1): int 47
debug(script=1,command=2): int 81
transaction type: multiple scripts
結果を見てみると・・・
- script=0, script=1 ともに最初のシード指定のない
permute()
の結果は全て同じ値(47)を返却している。 - script=0 の2回目の
permute()は4回のトランザクションで同じ値(56)を返却している。 - script=1 の2回目の
permute()は4回のトランザクションで同じ値(81)を返却している。 - シードが異なる場合には別の値を返却している。
- シードありなしに関わらず、そのpgbench実行中は
permute()は同じ値を返却し続ける。
つまり、permute()の使い所としては、1回のpgbenchの実行中でランダムかつ全トランザクションで共通の乱数を返却するケース ということなのだろう。実際の使い所については、ぱっとは思いつかないが・・・。
メタコマンド
pgbenchの独自スクリプトでは、DMLだけでなく各種メタコマンドを使うことができる。値の設定を行うものが主だが、中には条件分岐などの処理制御が可能なメタコマンドもある。
\if expression \elif expression \else \endif
みんな大好きpsqlにも同様のメタコマンドがPostgreSQL 10から実装されている。それと同様の記述方法で、独自スクリプト内で条件による処理分岐を記述できるようになった。
expressionには数値の比較演算結果を書くこともできるし、クエリから取得したboolean値をセットすることもできる。
例えば、以下のような\if expression \elif expression \else \endifを使った独自スクリプトファイルを作成する。
$ cat if-elif-else-endif.txt
--
-- target table
-- create table test (id serial, data)
--
\set class random_zipfian(1, 100, 1.2)
\set low_sal random(2, 7)
\set mid_sal random(3, 10)
\set high_sal random(1, 10)
\if :class < 70
INSERT INTO test (data) VALUES ( :low_sal * 500000);
\elif :class < 95
INSERT INTO test (data) VALUES ( :mid_sal * 10000000);
\else
INSERT INTO test (data) VALUES ( :high_sal * 100000000);
\endif
これはrandom_zipfian()で生成したclass変数を、\if(highならこの分岐に), \elif(middleならこの分岐に), \else(lowはこの分岐に)で分岐させ、class別のおちんぎんをテキトーに演算してdataにINSEETする、という簡単なスクリプトである。
これをpgbenchを使って10000回実行し、その後にdataの平均値、中間値、最頻値を取ってみると・・・
$ psql bench -e -f agg.sql
SELECT '平均値' AS 集計値, ROUND(AVG(data)) FROM test
UNION
SELECT '中央値', (PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY data) ) AS mode FROM test
UNION
SELECT '最頻値', MODE() WITHIN GROUP (ORDER BY data) FROM test
;
集計値 | round
--------+---------
平均値 | 7765750
最頻値 | 2000000
中央値 | 2500000
(3 rows)
という、まるで某国のような格差社会おちんぎんデータを作ることができる。
ちょい邪道な使い方かもしれないけど、データの生成にもpgbenchの独自スクリプトは使えそうだ。
\sleep number [ us | ms | s ]
これは名前から想像できるように、独自スクリプト内で指定時間処理を停止するというもの。この機能はDBT-2などのベンチマークにあるThining time/Keying timeを擬似するのに使えそうだ。
例えば、こんな独自スクリプトを書いてみる。
\set data random(1, 100)
\sleep 500 ms
INSERT INTO test (data) VALUES ( :data );
2行目に500ms sleepするメタコマンドを書いておく。
これを実行すると、こんな結果になる(コマンド毎のレイテンシを表示するために、-rオプションを付与して実行する)。
$ pgbench bench -n -f sleep.txt -r -T 60
pgbench (14.1)
transaction type: sleep.txt
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
duration: 60 s
number of transactions actually processed: 120
latency average = 501.023 ms
initial connection time = 2.131 ms
tps = 1.995917 (without initial connection time)
statement latencies in milliseconds:
0.003 \set data random(1, 100)
500.606 \sleep 500 ms
0.412 INSERT INTO test (data) VALUES ( :data );
$
メタコマンド\sleepで停止した時間もレイテンシ算出時の対象になることに注目。
pg_sleep との違い
同じようなことは、PostgreSQL組み込みのSQL関数pg_sleep()でも可能である。
$ pgbench bench -n -f pg_sleep.txt -r -T 60
pgbench (14.1)
transaction type: pg_sleep.txt
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
duration: 60 s
number of transactions actually processed: 120
latency average = 501.136 ms
initial connection time = 2.123 ms
tps = 1.995467 (without initial connection time)
statement latencies in milliseconds:
0.003 \set data random(1, 100)
500.872 SELECT pg_sleep(0.5);
0.257 INSERT INTO test (data) VALUES ( :data );
$
pg_sleep()を使うのと、\sleepの違いは、データベースサーバ内でスリープするのか、クライアント側でスループするのかという違いにになる。Thinking time/Keying timeを擬似するのであれば、クライアント側でスリープする\sleepメタコマンドを使うほうが妥当そうではある。
\setshell varname command [ argument ... ]
これはpgbenchを実行している環境のシェルコマンドを実行し、その結果を変数varnameに設定するもの。
ただ、このメタコマンドで実行した結果は「整数値」の標準出力結果に限定されるので、使い所が難しい気がする・・・。
このコマンドは標準出力を通して整数値を返さなければなりません。
にゃーん。 文字列や日付時刻にも対応していれば、クライアント側でタイムスタンプを生成してINSERTする、とかの操作を疑似できるのだが・・・)
\setshellメタコマンドの使用例を以下に示す。これはLinux dateコマンドのepoch(1970/01/01 00:00:00 からの経過秒)をシェルから実行し、その結果をepoch変数に格納して、それをINSERTするというものである。
$ cat setshell.txt
\setshell epoch date '+%s'
INSERT INTO test (data) VALUES ( :epoch );
\gset
\gsetは雑に言えば、問い合わせ結果のSELECTリスト名に応じたpgbench変数に自動的に設定するという機能である。psqlユーティリティにも類似のメタコマンドが存在するが、余程のpsqlマニアでもないと使っていない機能かもしれない。
\gsetは引数としてprefixを持つこともできる。このprefixに指定した文字列+SELECT句のリストの名前(列名など)の変数を自動生成し、そこにSELECT句のリストの結果を設定する。
例えば、以下のような2つのテーブルがある。
$ psql bench -c "\d test" -c "TABLE test" -c "\d history" -c "TABLE history"
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | not null |
idata | integer | | |
tdata | text | | |
Indexes:
"test_pkey" PRIMARY KEY, btree (id)
id | idata | tdata
----+-------+-------
1 | 101 | ABC
2 | 102 | DEF
3 | 103 | GHI
(3 rows)
Table "public.history"
Column | Type | Collation | Nullable | Default
--------+-----------------------------+-----------+----------+---------
id | integer | | |
idata | integer | | |
tdata | text | | |
ts | timestamp without time zone | | |
id | idata | tdata | ts
----+-------+-------+----
(0 rows)
$
この状態で、以下の独自スクリプトを実行するケースを考える。
$ cat gset.txt
\set id random(1, 3)
BEGIN;
SELECT id, idata, tdata FROM test WHERE id = :id;
\gset g_
INSERT INTO history (id, idata, tdata, ts)
VALUES (:g_id, :g_idata, ':g_tdata', CURRENT_TIMESTAMP);
END;
この独自スクリプトの3行目でSELECT文を発行し、結果をid, idata, tdataの列に格納する。クエリからは明示的にはわからないが、1件のみ返却するクエリを前提としている。
そのSELECT文の後に\gset g_を実行すると、idの結果をg_idという変数に、idataの結果をg_idataという変数に、tdataの結果をg_tdataという変数に格納する。
これらのg_id,g_idata,g_tdataの変数の内容は、その下にあるINSERT文で使用する。
ちょっと独特なのが、単一引用符による定数の引用が必要なデータ型(文字列型や日付時刻型など)の扱い。このような型の変数を後述の処理で参照する場合には、':g_tdata'のように、単一引用符内にpgbench変数を示す:g_tdata:を記述する必要がある。残念ながらpgbench側で型を意識してpgbench変数に格納するわけではないので、参照時に引用符による引用をしないといけないのが面倒ではある。にゃーん。
上記の独自スクリプトをpgbenchで10トランザクション動かすと以下のようになる。
$ pgbench bench -n -r -f gset.txt -t 10
pgbench (14.1)
transaction type: gset.txt
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10
number of transactions actually processed: 10/10
latency average = 1.112 ms
initial connection time = 2.008 ms
tps = 899.280576 (without initial connection time)
statement latencies in milliseconds:
0.002 \set id random(1, 3)
0.058 BEGIN;
0.183 SELECT id, idata, tdata FROM test WHERE id = :id;
0.132 INSERT INTO history (id, idata, tdata, ts)
0.732 END;
このpgbench実行が終わったあとには、historyテーブルにデータが挿入されている。
bench=# TABLE history LIMIT 3;
id | idata | tdata | ts
----+-------+-------+----------------------------
1 | 101 | ABC | 2021-12-04 21:23:12.261589
1 | 101 | ABC | 2021-12-04 21:23:12.26373
3 | 103 | GHI | 2021-12-04 21:23:12.264914
(3 rows)
\aset
\asetも名前から想像できるように、\gsetと同様に複数の変数を自動セットするためのメタコマンドである。なお、\asetについてはpsqlユーティリティには実装されていない。
\asetは\;で区切られた複数のSELECT文の結果をprefixで指定した接頭辞付きの変数名に自動的に設定するメタコマンドである。
どういうときに有効に使えるのか、今ひとつわからないのだが・・・
基本的な使いかた
例えば以下のような独自スクリプトファイルを作成する。
$ cat aset.txt
SELECT 1 one\;
SELECT 2 two\;
SELECT 3 three, 4 four \aset a_
\set one debug(:a_one)
\set two debug(:a_two)
\set four debug(:a_four)
1行目~3行目にSELECT文が書かれている。これに対して\aset a_を実行すると、4~6行目でa_one,a_two,a_fourという変数にそれぞれ、1, 2, 4が格納される。
上記の独自スクリプトを実行した結果はこうなる。
$ pgbench bench -n -f aset.txt -t 1
pgbench (14.1)
debug(script=0,command=2): int 1
debug(script=0,command=3): int 2
debug(script=0,command=4): int 4
transaction type: aset.txt
(後略)
同じ列名が重複した場合
複数のSELECT文の間で列名(エイリアス名)が重複したらどうなるのか?
$ cat aset_dup.txt
SELECT 1 one\;
SELECT 2 two\;
SELECT 10 one, 20 two \aset a_
\set one debug(:a_one)
\set two debug(:a_two)
結論から言えば、後に書いた値が優先される(上書きされるっぽい)。
$ pgbench bench -n -f aset_dup.txt -t 1
pgbench (14.1)
debug(script=0,command=2): int 10
debug(script=0,command=3): int 20
transaction type: aset_dup.txt
(後略)
明示的にエイリアスがない場合
定数に明示的にエイリアスがない場合、PostgreSQL(というよりpsql?)はメタ情報の列名に?column?という名称を付与して結果を返却する。
$ psql bench -c "SELECT 1"
?column?
----------
1
(1 row)
では、こういう明示的な別名を付与しない場合、\asetはどういう挙動になるのか確認してみる。
$ cat aset_err1.txt
SELECT 1 \;
SELECT 2 two\;
SELECT 3 three, 4 four \aset a_
\set two debug(:a_two)
\set four debug(:a_four)
なーんと、定数値に明示的なエイリアスを含めないSELECTを含んでいると、\asetでエラーになってしまう。にゃーん。
$ pgbench bench -n -f aset_err1.txt -t 1
pgbench (14.1)
pgbench: error: aset: invalid variable name: "a_?column?"
pgbench: error: client 0 script 0 command 0 query 0: error storing into variable a_?column?
transaction type: aset_err1.txt
つまり、\aset対象のSELECT文は必ず、pgbench変数で使用可能な名称でエイリアスを設定しなくてはならない。
なので、明示的に記号を含むようなエイリアス
$ psql bench -c 'SELECT 1 "**one**"'
**one**
---------
1
(1 row)
みないなSELECTがあっても\asetで怒られてしまう。
$ cat aset_err2.txt
SELECT 1 "*one*" \;
SELECT 2 two\;
SELECT 3 three, 4 four \aset a_
\set one debug(:a_*one*)
\set two debug(:a_two)
\set four debug(:a_four)
これを実行すると、
pgbench bench -n -f aset_err2.txt -t 1
pgbench: fatal: aset_err2.txt:4: unexpected function name (one) in command "set"
\set one debug(:a_*one*)
^ error found here
変数名a_*one*は"unexpected function name"と怒られてしまう。いや、関数名じゃねーし。いずれにせよにゃーんである。
\startpipeline \endpipeline
このメタコマンドはPostgreSQL 14から実装されたものである。そもそもpipelineって何よ?って感じなのだが、実はPostgreSQL 14からlibpqの機能としてPipeline Modeという実行モードが実装されている。
このメタコマンドは、\startpipelineと\endpipelineで囲まれた範囲のクエリはPipeline Modeで実行するものらしい。
Pipeline mode is 何?
libpqのPipeline modeはPostgreSQL 14から実装されたクエリ実行方式である。
通常のlibpqの実行モードでは、先に送信したクエリの結果を読み取った後に、次のクエリの実行を行う。
libpq のパイプラインモードでは、先に送信されたクエリの結果を読み取ることなく、次のクエリを送信する。パイプラインモードを利用により、複数のクエリや結果を1つのネットワークトランザクションで送受信するため、クライアントから見たサーバに対する待ち時間が短くなる効果が期待できるようだ。
(ここでは、libpqのPipeline modeの詳細は割愛)
pgbench独自クエリでの使用方法
pgbenchでPipeline modeを使う場合には、独自スクリプトファイルを以下のように編集する。
- Pipeline modeで動作させたいクエリ群の前に
\startpipelineメタコマンドを記述する。 - Pipekine modeで動作さえたいクエリ群の後に
endpipelineメタコマンドを記述する。
実はこれだけである。
TPC-Bを擬似した独自スクリプトのDML全体をPipeline modeで動作させたい場合には、以下のように独自スクリプトを記述すればよい。
$ cat tpcb_pipeline.txt
-- TPC-B custom query
\set aid random(1, 100000 * :scale)
\set bid random(1, 1 * :scale)
\set tid random(1, 10 * :scale)
\set delta random(-5000, 5000)
BEGIN;
\startpipeline
UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
UPDATE pgbench_tellers SET tbalance = tbalance + :delta WHERE tid = :tid;
UPDATE pgbench_branches SET bbalance = bbalance + :delta WHERE bid = :bid;
INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
\endpipeline
END;```
$
- 最初のUPDATEの前に
\startpipelineの行を書く。 - 最後のINSERTの後に
\endpipelineの行を書く。
Pipeline modeで実行する。
pgbenchではクエリプロトコルを--protocol=modeで指定することができる。
modeにはsimple(単純モード。これがデフォルト)、extended(拡張モード)、prepared(準備文モード)の3種が指定可能である。
上記のようにPipeline modeの指定を記述した独自スクリプトを動作させるためには、pgbenchのクエリプロトコルを拡張モード(--protcol=extended)に指定して実行する必要がある。
拡張モード以外(例えばデフォルトのsimple)で実行すると、pgbenchは\startpipelineの実行時にモードをチェックして拡張モードでないとエラーを出力してトランザクション実行を中止する。にゃーん。
$ pgbench bench -f tpcb_pipeline.txt --protocol=simple -r -c 4 -t 2500
pgbench (14.1)
starting vacuum...end.
pgbench: error: client 0 aborted in command 5 (startpipeline) of script 0; cannot use pipeline mode with the simple query protocol
pgbench: error: client 1 aborted in command 5 (startpipeline) of script 0; cannot use pipeline mode with the simple query protocol
pgbench: error: client 3 aborted in command 5 (startpipeline) of script 0; cannot use pipeline mode with the simple query protocol
pgbench: error: client 2 aborted in command 5 (startpipeline) of script 0; cannot use pipeline mode with the simple query protocol
transaction type: tpcb_pipeline.txt
プロトコルを--protocol=extendedにして、Pipeline modeで実行した例を以下に示す。
$ pgbench bench -f tpcb_pipeline.txt --protocol=extended -r -c 4 -t 2500
pgbench (14.1)
starting vacuum...end.
transaction type: tpcb_pipeline.txt
scaling factor: 1
query mode: extended
number of clients: 4
number of threads: 1
number of transactions per client: 2500
number of transactions actually processed: 10000/10000
latency average = 3.921 ms
initial connection time = 7.759 ms
tps = 1020.191321 (without initial connection time)
statement latencies in milliseconds:
0.002 \set aid random(1, 100000 * :scale)
0.001 \set bid random(1, 1 * :scale)
0.001 \set tid random(1, 10 * :scale)
0.001 \set delta random(-5000, 5000)
0.088 BEGIN;
0.001 \startpipeline
0.000 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
0.000 SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
0.000 UPDATE pgbench_tellers SET tbalance = tbalance + :delta WHERE tid = :tid;
0.000 UPDATE pgbench_branches SET bbalance = bbalance + :delta WHERE bid = :bid;
0.000 INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
2.954 \endpipeline
0.852 END;
上記の例では、pgbench実行時に-r(レイテンシ表示)オプションも付与しているが、Pipeline modeで実行した区間のクエリはレイテンシの数値が0になっている。endpipelineの行に、それまでの全クエリ含む区間前端のレイテンシとしてレポートされるようだ。Pipeline modeで実行する区間については、個々のクエリのレイテンシ情報が取得できないことに注意が必要である。
おわりに
pgbenchは簡単に使えるベンチマークツールだけど、独自スクリプトの機能をフルに使うことで、独自のベンチマークにも対応できるようになっている。
ただ、PostgreSQL文書の説明が少し不親切な気もするので、なかなか使いづらい印象もある。
誰か、**「猫でもわかるpgbench」とか「猫でもわかるpsql」**とか作ってくれんかのう。
そういえば、明日のアドベントカレンダー担当の@tameguroさんが、PostgreSQLの技術同人誌を何冊か書いていましたよね・・・(にやり)
-
Commitfest 2021-09で"commited"になった。→Using COPY FREEZE in pgbench ↩