はじめに
数ヶ月に一回、ラーメンデータベースのスクレイピングをやっているんだけど、その集計のためにPostgreSQLを使っている。
で、スクレイピング結果を使って、PostgreSQL上でヒストグラムっぽいのを作っているんだけど、毎回そのやり方を忘れちゃうので、ここに書いておくことにした。
witdh_bucket関数
ヒストグラムっぽいのを作成するのに、PostgreSQLの算術演算関数 width_bucket(operand numeric, b1 numeric, b2 numeric, count int) を使う。
PostgreSQL文書だと、あんまり親切な説明がない。この素っ気なさはPostgreSQLクオリティだよなあw
b1からb2までの範囲に広がる等幅でバケット数countのヒストグラムにおいて、operandが割り当てられるバケット番号を返す。 範囲の外側の入力値に対しては0またはcount+1を返す。
例に挙げられている関数を実行すると、
rdb=# SELECT width_bucket(5.35, 0.024, 10.06, 5);
width_bucket
--------------
3
(1 row)
こんな結果を返却するのだけど、これはどういうことかと言うと、こんな感じだと思う。このへんの優しさがPostgreSQL文書には足りないように思うのだw
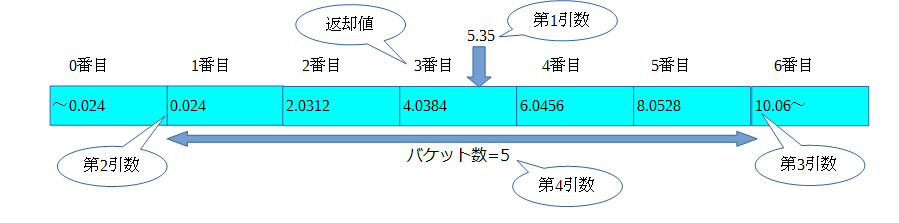
要するにこの関数は第1引数で指定した数値が、指定したバケットの何番目に存在するかを返却するものだ(と思う)。
レビュー数のヒストグラム
さて、今回はラーメンデータベースユーザのレビュー数のヒストグラムを作ってみようと思う。
今回のデータおソース
今回のデータソースは、9/24~9/25にかけてスクレイピングしたユーザページ。
ちなみに、ぬこのユーザページはこんな感じになっている。
ユーザページには、ユーザID、ユーザ名、レビューした数、レビューした店舗の数、いいね!の数などが表示されているので、それらを収集する。収集した結果を、以下のようなスキーマをもつテーブルにCOPYる。
rdb=# \d users
Table "public.users"
Column | Type | Collation | Nullable | Default
-----------+---------+-----------+----------+---------
uid | integer | | not null |
name | text | | |
reviews | integer | | |
shops | integer | | |
favorites | integer | | |
likes | integer | | |
note | text | | |
Indexes:
"users_pkey" PRIMARY KEY, btree (uid)
以降、このテーブルからヒストグラムを生成してみる。今回はreviews(レビュー件数)を題材にしてみる。
今回収集したユーザ数は171365。結構ユーザ数多いんだよな。ただ、そのうち約80%はレビューを投稿していないROMユーザだったりする。
- レビュー数が0のユーザ数:136932
- レビュー数が1以上のユーザ数:34433
rdb=# SELECT ROUND(
(SELECT COUNT(*) FROM users WHERE reviews = 0)::numeric
/
(SELECT COUNT(*) FROM users) :: numeric * 100 ,
2);
round
-------
79.91
(1 row)
なので、レビューを投稿している約20%(34433ユーザ)を対象に、with_bucket()を適用してみる。
rdb=# SELECT width_bucket(reviews, 1, 4000, 40) as wb FROM users WHERE reviews > 0;
wb
----
1
1
1
1
1
1
1
1
1
1
1
1
10
1
1
1
2
1
1
1
1
(後略)
このクエリでは、各ユーザのレビュー数が、100のレンジで分割したバケットの何番目に属するのかを返却する。
なので、これをGROUP BYでグループ化すれば、ヒストグラムの元データが取得できるというわけだ。
rdb=# SELECT wb * 100 as range, count(wb) FROM
(SELECT width_bucket(reviews, 1, 4000, 40) as wb FROM users WHERE reviews > 0) as t
GROUP BY wb;
range | count
-------+-------
100 | 33358
200 | 450
300 | 189
400 | 105
500 | 56
600 | 53
700 | 30
800 | 29
900 | 13
1000 | 23
1100 | 21
1200 | 22
1300 | 13
1400 | 15
1500 | 6
1600 | 4
1700 | 3
1800 | 4
1900 | 6
2000 | 4
2100 | 6
2200 | 1
2300 | 3
2400 | 2
2500 | 2
2600 | 1
2700 | 3
2800 | 3
2900 | 2
3100 | 2
3200 | 1
3400 | 1
3700 | 1
3900 | 1
(34 rows)
range はその区域の最大値を示す。100であれば、レビュー件数が1~100の範囲を示す。
こうやってみると、殆どのユーザのレビュー件数は100件未満なんだよなあと。
(ぬこのレビュー数は収集時点では2840件あたりだと思うので、上の結果だと2900のところに合致する)
あとは、この結果をExcelなりLibre Calcなりに貼り付けて、グラフ化すればOK。
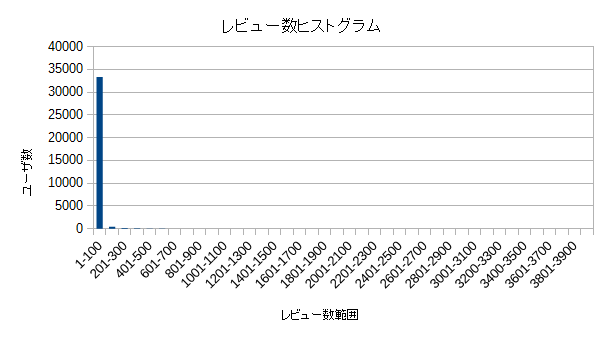
うーん、ほとんどのユーザのレビュー数が100件未満なので、それ以上のレビュー数がグラフからはよくわからんなあ・・・。
なので、100件以上のレビュー数のユーザのみを対象としてグラフを作り直す。
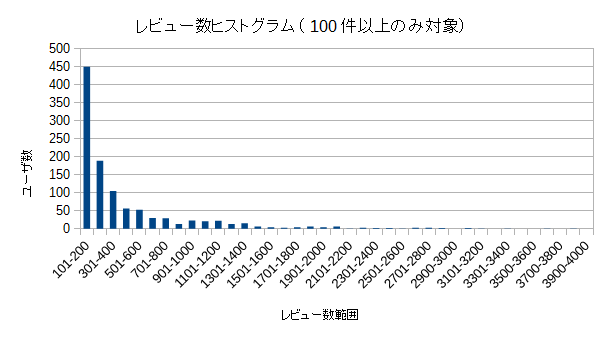
まあ、こうやって見ると、ラーメンデータベースのユーザのほとんどは、レビュー数200件以下のユーザなんだなあということが分かってくる。分かったからといって、何がどうするというものではないけれどw
おまけ:psql上でそれっぽいグラフをテキストベースで作ってみる。
repeat関数を使うと、それっぽいグラフが作れたりする。別に役には立たないけど。
rdb=# SELECT
(wb * 100 -99)::text || '-' || (wb * 100)::text AS range,
count(wb) as count, repeat('*',
ROUND(count(wb)::numeric / 1075 * 100)::int)
FROM
(SELECT width_bucket(reviews, 1, 4000, 40) as wb
FROM users WHERE reviews > 100) as t
GROUP BY wb ORDER BY wb ASC;
range | count | repeat
-----------+-------+--------------------------------------------
101-200 | 450 | ******************************************
201-300 | 189 | ******************
301-400 | 105 | **********
401-500 | 56 | *****
501-600 | 53 | *****
601-700 | 30 | ***
701-800 | 29 | ***
801-900 | 13 | *
901-1000 | 23 | **
1001-1100 | 21 | **
1101-1200 | 22 | **
1201-1300 | 13 | *
1301-1400 | 15 | *
1401-1500 | 6 | *
1501-1600 | 4 |
1601-1700 | 3 |
1701-1800 | 4 |
1801-1900 | 6 | *
1901-2000 | 4 |
2001-2100 | 6 | *
2101-2200 | 1 |
2201-2300 | 3 |
2301-2400 | 2 |
2401-2500 | 2 |
2501-2600 | 1 |
2601-2700 | 3 |
2701-2800 | 3 |
2801-2900 | 2 |
3001-3100 | 2 |
3101-3200 | 1 |
3301-3400 | 1 |
3601-3700 | 1 |
3801-3900 | 1 |
(33 rows)