はじめに
にゃーん。
日々のラーメン代を稼ぐために、社畜やってるぬこ@横浜1です。
これはPostgreSQL Advent Calendar 2018の22日目の記事です。
昨日の記事は @tom-sato さんのPostgreSQL のマイナーな contrib モジュールについてでした。
さて今日は週末。ということでゆるい話をしたいと思います。
仕事でもPostgreSQLを使うことが多い身の上なのですが、家でもより良いラーメンライフを送るためにPostgreSQLを使っていたりします。それにしても、こんな便利なものが無料で使えるとはありがたい世の中ですね。
ということで、今日は人様のために役に立つ情報ではなく、普段自分のQON(クオリティ・オブ・ヌードル)を上げるために、PostgreSQLをどう使っているかを紹介します。たまにはこういうのもいいよね?
注意
無駄に長いです。すみません。あとラーメンに興味ない人もごめんなさい。
PostgreSQLとラーメンデータベース
皆さんは日本全国にラーメンが食べられるお店が何軒あるか、ご存知ですか?私も知りませんが(笑)
とにかくたくさんあるのは事実です。人生は短い。食事の機会も僅かしかない。できれば美味しい麺を食べたい。そんな状況なので、ラーメンに関する情報を求めるのは仕方がないことです。なので、レビューサイトのようなものに頼ることもあるでしょう。
自分の場合、10年くらい前からラーメンデータベースというサイトを少々利用しています。ラーメンに特化したレビューサイトなので検索などは使いやすいのですが、統計的な情報を得る機能はサイトにはありません。ただ、ラーメンレビューに関するデータの量・内容は十分にある。なので、定期的に闇の技術2を使って自分の使いやすい情報を、自分の手元に収集し、それをPostgreSQLに突っ込んでいます。
なぜPostgreSQL?
個人的な理由でしかないけど。
- 無料
- Window関数などの機能が使える
- ついでに新バージョンの新機能を試すこともできる
- psql最高
テーブル設計
ラーメンデータベースには大きく4つの情報があります。
- 店舗(shops)
- ユーザ(users)
- レビュー(reviews)
- レビューへのコメント(comments)
なので、PostgreSQL上でもそれをテーブルとして素直にマッピングします。図にするとこんな感じですね。
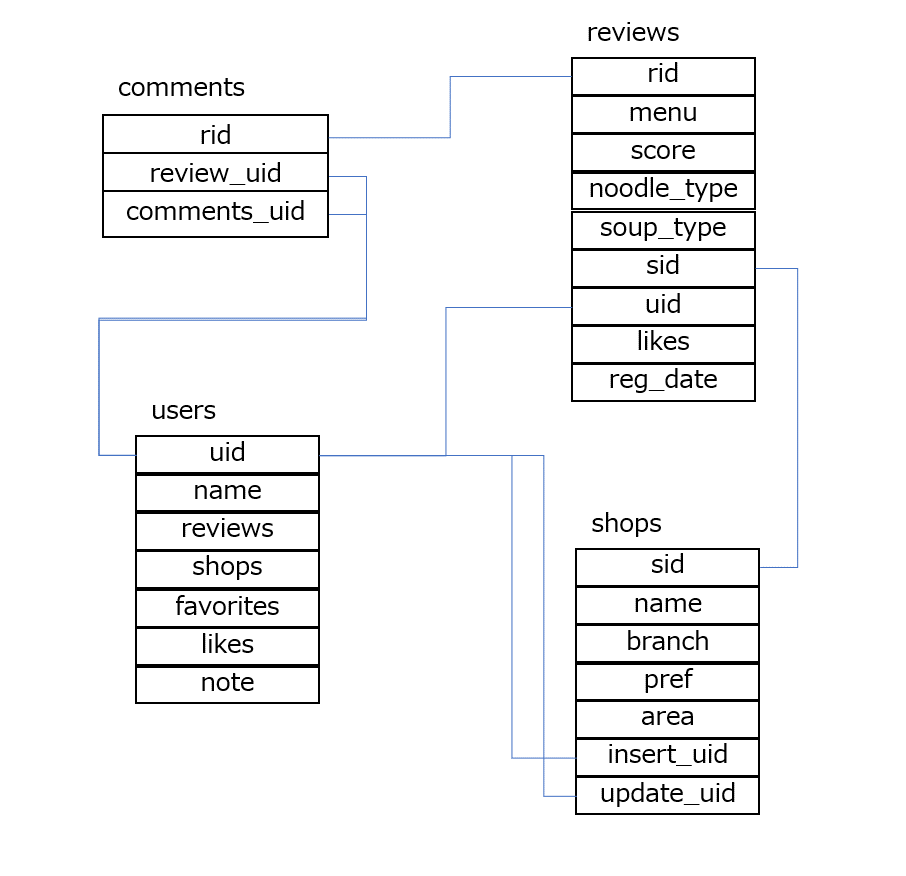
で、ここにスクレイピングしたデータを放り込んでおきます。
いろいろやってみる
サンマーメン?生碼麺?さんまー麺?
サンマーメンというのは横浜発祥と言われる地ラーメンの一種です。要するにもやしなどの食材を餡かけで炒めて、スープの上に乗せたラーメンです。3
さて、ラーメンデータベースを集計していて困ったのが、お店によってサンマーメンの表記がいろいろ揺れていること。以下はその一例。
- すべてカタカナで「サンマーメン」
- 麺だけ漢字の「サンマー麺」
- 漢字のみの「生碼麺」
- 「麺」が「面」になっている「生碼面」
- 「碼」が「馬」になっている「生馬麺」
上記以外の表記も結構あります。
「サンマーメン」を食べたい!と思ったときに、どの店にサンマーメンがあるのかを探すのは大変です。この表記の組み合わせを一々OR接続の条件を書くのはとても面倒。
でも、幸いPostgreSQLにはPOSIX正規表現マッチ演算子が用意されています。過去のレビューからサンマーメンの表記を分析したところ、だいたい以下のような規則になっているぽい。
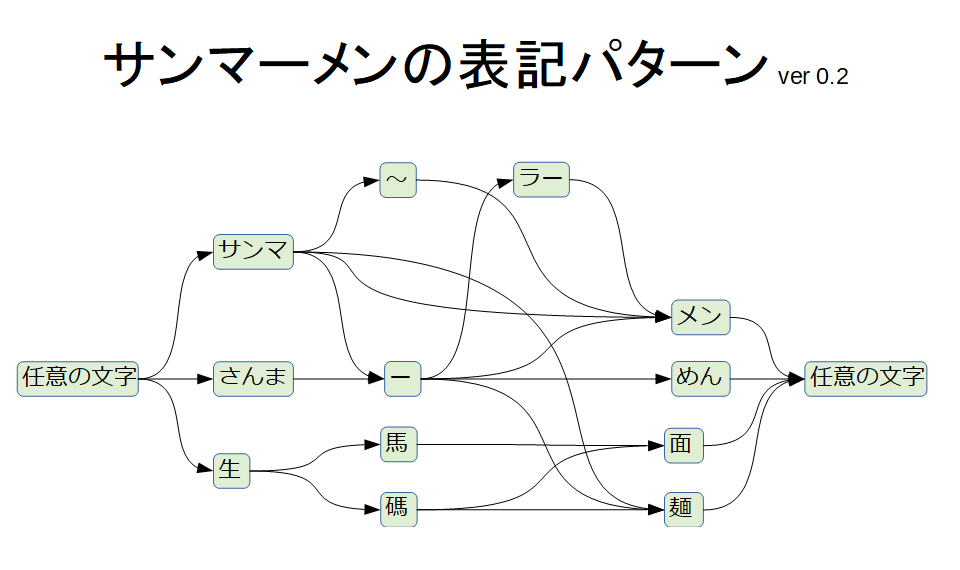
これに対応する正規表現を書けば、一撃でサンマーメンのレビューが登録された店舗が探せます。正規表現は例えばこんな感じになります。
((サンマ(ー|~)*|さんま)(ー)*|生(馬|碼))(ラーメン|メン|めん|麺|面)
実際にこの正規表現演算子で検索してみましょう。
rdb=# SELECT r.rid, r.menu
FROM reviews r
WHERE menu ~ '((サンマ(ー|~)*|さんま)(ー)*|生(馬|碼))(ラーメン|メン|めん|麺|面)';
rid | menu
---------+------------------------------------------------------------------
(中略)
75567 | サンマーメン
76540 | サンマーメン 麺カタメ、胡椒スクナメ
80077 | 生馬麺(五目うまにそば)730円
81941 | さんまーめん
82654 | サンマーメン(850円)
86414 | サンマーメン・タンメン
87872 | サンマーメン
91213 | サンマーメン
92032 | サンマメン
92107 | サンマー麺
100289 | 三生碼麺
104765 | サンマーメン 750円
107044 | サンマーメン 5番
111165 | サンマーメン
112097 | サンマー麺
(後略)
いろんなパターンのサンマーメンが検索できてますね。
おまけ:サンマーメンの分布
サンマーメンは横浜発祥ということもあって、基本的には横浜・川崎周辺で提供されているのですが、隣県の東京都や静岡県にも伝播しているようです。個人的には埼玉県・茨城県・群馬県の北関東エリアに分布しているのが面白いなと。
rdb=# SELECT s.pref, COUNT(pref)
FROM reviews r JOIN shops s ON (r.sid = s.sid)
WHERE menu ~ '((サンマ(ー|~)*|さんま)(ー)*|生(馬|碼))(ラーメン|メン|めん|麺|面)' GROUP BY pref ORDER BY COUNT(pref) DESC;
pref | count
----------+-------
神奈川県 | 866
東京都 | 147
埼玉県 | 21
静岡県 | 17
茨城県 | 14
群馬県 | 11
千葉県 | 7
福島県 | 5
広島県 | 4
宮城県 | 4
山梨県 | 4
栃木県 | 3
愛知県 | 3
富山県 | 3
岩手県 | 2
北海道 | 2
大阪府 | 2
新潟県 | 1
大分県 | 1
岐阜県 | 1
(20 rows)
過去のラーメン旅を振り返る
PostgreSQL 9.6からpsqlのメタコマンドとして\crosstabviewという素敵機能が追加されました。
これはGROUP BYなどで出力された結果をクロスセルのように表示してくれるというもので、個人的に結構気にいってる機能です。
この機能を使って、過去に自分が行ったラーメン旅を振り返ることができます。
こんな感じでSQLを実行して、\cresstabviewを実行すると、年別/都道府県別にラーメンをレビューした一覧を出力してくれます。
rdb=# SELECT pref, year, count(year) FROM
(SELECT pref, extract(year from reg_date) as year FROM reviews r JOIN shops s
ON (r.sid = s.sid)
WHERE reg_date < '2018-01-01' AND uid = 8999) t
GROUP BY pref, year ORDER BY year;
rdb=# \o
rdb=# \crosstabview pref year
pref | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017
----------+------+------+------+------+------+------+------+------+------+------+------
埼玉県 | 1 | 1 | 2 | | 3 | 2 | | | | | 2
東京都 | 38 | 31 | 29 | 13 | 20 | 17 | 28 | 32 | 21 | 22 | 23
神奈川県 | 76 | 157 | 351 | 311 | 282 | 189 | 214 | 252 | 171 | 191 | 229
千葉県 | | 4 | 4 | | | 2 | | | | |
山形県 | | 1 | 2 | 3 | | | | | | |
栃木県 | | 1 | 1 | | 2 | | 2 | | 1 | 1 | 1
福島県 | | 3 | | 2 | 2 | 5 | 4 | | 4 | 3 | 4
茨城県 | | 1 | 1 | | 1 | | 4 | | | 1 |
長崎県 | | 1 | | | | | | | 3 | |
静岡県 | | 1 | 5 | 5 | 7 | 1 | 2 | | 2 | 5 | 1
鹿児島県 | | 1 | | | | | | | | |
三重県 | | | 1 | | | | | | | |
山梨県 | | | 1 | | 2 | | | 2 | | 5 | 2
岐阜県 | | | 1 | 1 | | 1 | | | | |
島根県 | | | 1 | 2 | 1 | | 2 | 1 | 2 | 2 |
愛知県 | | | 2 | | | 1 | | | | |
新潟県 | | | 2 | | | | | | | | 1
石川県 | | | 1 | | | 1 | | | | |
群馬県 | | | 2 | | 1 | | | 1 | 4 | |
和歌山県 | | | | 1 | | | | | | |
富山県 | | | | 1 | 1 | | | | | |
長野県 | | | | 1 | 2 | 1 | | 6 | | | 3
宮城県 | | | | | 2 | | | | | |
京都府 | | | | | | 2 | | | | |
岩手県 | | | | | | | | 3 | | |
広島県 | | | | | | | | 4 | | |
北海道 | | | | | | | | | 4 | |
大阪府 | | | | | | | | | 3 | 1 | 7
岡山県 | | | | | | | | | 1 | | 2
沖縄県 | | | | | | | | | | 3 |
福井県 | | | | | | | | | | 4 |
青森県 | | | | | | | | | | | 3
(32 rows)
この結果を見ながら
- 2009年に原付で新潟へ行って燕三条ラーメンを食べたなあ(2日は一日中雨の中だったなあ)
- 2009年に原付でお伊勢参りしてラーメン食べたなあ(2日目は雨に降られながらの旅だったなあ)
- 2010年に原付で天童まで行ってラーメン食べたなあ(福島市から米沢市への山越えで死にそうになったなあ)
- 2011年に原付で仙台まで行ってラーメン食べたなあ(ニュータンタンメン美味かったなあ)
- 2012年に原付で京都まで行ってラーメン食べたなあ(しんぷくウマー)
- 福島県にしょっちゅう原付で行ってラーメン食べてるなあ
とか思いを馳せるわけです。そして、最近、そういう無茶な遠出をしなくなったなと反省もするわけです(福島県とか長野県は遠出のうちに入りません)。
都道府県とレビューされたスープ種別
今度は2018年までのレビューデータを使って、どんなスープ種別のレビューがどの都道府県に多いのかを集計してみよう。
ラーメンデータベースでは、現状スープの種別として、「醤油、塩、味噌、豚骨、塩豚骨、豚骨醤油、豚骨魚介、鶏白湯、担々麺、カレー、煮干し、その他」の分類がある。もちろんラーメンの中にはどれに分類か迷うもスープもあったりするが、そのへんは目をつぶる。
こんな感じのクエリを実行して、この結果も\crosstabviewで見やすくする。
rdb=# SELECT t.pref, t.soup_type AS soup_type, COUNT(t.soup_type)
rdb-# FROM
rdb-# (
rdb(# SELECT s.pref, r.soup_type
rdb(# FROM reviews r JOIN shops s ON (r.sid = s.sid)
rdb(# WHERE r.reg_date < '2018-01-01'
rdb(# AND s.pref IN ('東京都','神奈川県','北海道','福岡県')
rdb(# UNION ALL
rdb(# SELECT '全国' AS pref, r.soup_type
rdb(# FROM reviews r
rdb(# WHERE r.reg_date < '2018-01-01'
rdb(# ) t
rdb-# GROUP BY t.pref, t.soup_type
rdb-# ORDER BY t.soup_type ASC
rdb-# ;
pref | soup_type | count
----------+-----------+--------
神奈川県 | その他 | 4535
北海道 | その他 | 259
東京都 | その他 | 24446
全国 | その他 | 51691
福岡県 | その他 | 218
東京都 | カレー | 4473
神奈川県 | カレー | 915
北海道 | カレー | 125
福岡県 | カレー | 26
全国 | カレー | 11173
東京都 | 味噌 | 28195
神奈川県 | 味噌 | 6410
北海道 | 味噌 | 2453
福岡県 | 味噌 | 185
全国 | 味噌 | 64398
全国 | 塩 | 69016
北海道 | 塩 | 998
福岡県 | 塩 | 113
神奈川県 | 塩 | 7576
東京都 | 塩 | 30403
神奈川県 | 塩豚骨 | 970
rdb=# \crosstabview soup_type pref
soup_type | 神奈川県 | 北海道 | 東京都 | 全国 | 福岡県
-----------+----------+--------+--------+--------+--------
その他 | 4535 | 259 | 24446 | 51691 | 218
カレー | 915 | 125 | 4473 | 11173 | 26
味噌 | 6410 | 2453 | 28195 | 64398 | 185
塩 | 7576 | 998 | 30403 | 69016 | 113
塩豚骨 | 970 | 134 | 2575 | 6476 | 40
担々麺 | 2078 | 57 | 8196 | 17149 | 92
煮干し | 315 | 25 | 1539 | 3872 | 6
豚骨 | 4906 | 227 | 20768 | 48735 | 3564
豚骨醤油 | 19470 | 383 | 54683 | 118173 | 325
豚骨魚介 | 5484 | 250 | 48776 | 90532 | 166
醤油 | 18159 | 1803 | 91601 | 202986 | 304
鶏白湯 | 1229 | 176 | 10164 | 24159 | 78
(12 rows)
で、この結果の比率をグラフ化すると、結構面白い結果がでてくる。

全国の傾向と東京都の傾向がほぼ同じなのは、東京都の店舗のレビュー数が非常に多くを占めているため。
今回は特徴が強くでている都道府県をチョイスしてみた。
- 神奈川県:神奈川県は家系ラーメン発祥の地、ということもあってか豚骨醤油ラーメンのレビューが比較的多い。
- 北海道:北海道にはいわゆる三大ラーメン(札幌味噌、旭川醤油、函館塩)があるのだが、やはり札幌味噌はその中でも別格ということか。全国平均の味噌ラーメンレビュー比率の数倍を占めている。まあ、自分も札幌では味噌ばっかり食べていた気がする。
- 福岡県:さすがは九州、豚骨王国としか言いようがない。なんと7割のレビューが豚骨なのだ。福岡県では家系ラーメンは流行りそうにないな・・・。
レビュースコアの統計
ラーメンレビューの総数は2018年上期時点で約73万件あります。結構な数ですね。レビューには食べたラーメンの点数を100点満点でつけるのですが、みんなどんな感じの点数をつけているのか、ちょっと気になったので、レビュースコアの統計をとってみた。
平均値
平均値。これは標準SQLとして使えるAVG関数一撃でOK。
rdb=# SELECT AVG(score) FROM reviews;
avg
---------------------
77.9435001268486323
(1 row)
中央値
これが意外と面倒くさい。中央値を取るためには、その値をソートして中央に位置する値をとってこなくてはいけない。さらに対象の要素数が奇数と偶数の場合で取得方法が違うのが面倒くさい。plpgsqlあたりを使えば実装できるだろうけど、なんとかSQLで実行したいところ。で、SQLでいろいろ頑張ってみた。
rdb=# WITH
t1 AS
(SELECT COUNT(score) c FROM reviews_test),
t2 AS
(SELECT
CASE t1.c % 2 WHEN 0 THEN t1.c / 2 ELSE t1.c / 2 + 1 END offset_num,
CASE t1.c % 2 WHEN 0 THEN 2 ELSE 1 END limit_num
FROM t1)
SELECT t2.offset_num, t2.limit_num FROM t2,reviews_test ORDER BY score OFFSET t2.offset_num LIMIT t2.limit_num
;
ERROR: argument of OFFSET must not contain variables
LINE 9: ...it_num FROM t2,reviews_test ORDER BY score OFFSET t2.offset_...
^
CASEでOFFSETやLIMITを奇数時/偶数時にわけて、その結果のAVGとればいけるかな?と思ったが、残念ながらOFFSET(たぶんLIMITも?)変数は指定しちゃダメっぽい。困ったな・・・と思ったら、なんと
rdb=# SELECT (PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY score) ) AS mode FROM reviews;
mode
------
80
(1 row)
順序集合集約関数のPERCENTILE_CONTに中央の値(0.5)を指定することで中央値を得ることができるようだ。WITH IN GROUPを使う方法はもっと勉強しないとなあ。
最頻値
これはwidth_bucket関数でヒストグラムを作って、その最大値をとればOK。wbが最頻値(mode)の値となる。
rdb=# WITH t2 AS (SELECT t.wb, COUNT(t.wb)
FROM (SELECT width_bucket(score, 1, 100, 99) wb FROM reviews) t
GROUP BY t.wb ORDER BY t.wb)
SELECT * FROM t2 ORDER BY count DESC LIMIT 1
;
wb | count
----+-------
80 | 72093
(1 row)
やったね♪
しかし、その後に、PostgreSQL文書を見たら、なんと順序集合集約関数のmode関数一撃で最頻値を取得できることがわかった。アバーッ!
rdb=# SELECT MODE() WITHIN GROUP (ORDER BY score) FROM reviews;
mode
------
80
(1 row)
教訓:きちんとPostgreSQL文書を調べましょう。
ヒストグラム
とはいえwidth_bucketを使った方法を検討したは無意味ではない。この関数を使うことで、ヒストグラムが作ることはできるのだ。
rdb=# SELECT t.wb score, COUNT(t.wb)
FROM (SELECT width_bucket(score, 1, 100, 99) wb FROM reviews) t
GROUP BY t.wb ORDER BY t.wb;
score | count
-------+-------
30 | 8666
31 | 223
32 | 139
(中略)
99 | 3572
100 | 12087
(71 rows)
このように採点(score)が何件あったかを求めることができる。4
で、この結果をグラフにプロットするとこんな感じになります。
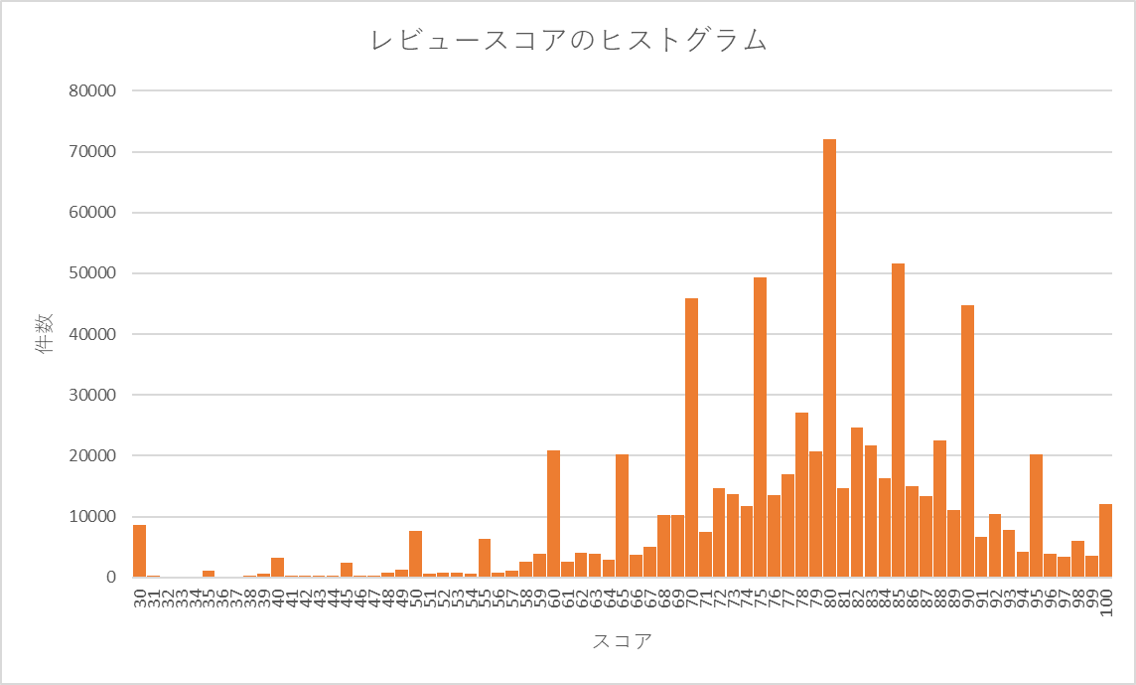
ざっくり見ると、80点を中心にscoreが分布していることがわかる。5点ごろに採点数が多くなっているのは、おそらく(自分も同様だが)5点単位で採点をする人が多いからではないかと推測している。最頻値、中央値ともに80点になっていることも80点を中心に分布していることからも納得できる結果になってます。
コメントのやりとり
ラーメンデータベースでは、自分が投稿したレビューに対して、他のユーザからコメントを書くことができます。
最近のラーメンデータベースでは、他人の採点を貶すようなコメントはほとんどない(そういうコメントを書くと運営から注意をくらう)ので、コメントのやりとりを集計することで、ユーザ間の比較的ポジティブなネットワークを推測することができます。
以下のクエリは、「2017年に神奈川の店舗にレビューした件数が多い20名のユーザに対してコメントしたユーザとコメント数」を集計したものです。(なお、神奈川県の店舗に一番レビューしているのは自分かもしれない)
rdb=# SELECT review_uid, comment_uid, COUNT(review_uid)
FROM (SELECT c.* FROM comments c JOIN reviews r ON (c.rid = r.rid)
WHERE r.reg_date >= '2017-01-01' AND reg_date < '2018-01-01'
AND review_uid IN (
SELECT uid
FROM reviews r JOIN shops s ON (r.sid = s.sid)
WHERE s.pref ='神奈川県' AND reg_date BETWEEN '2017-01-01' AND '2017-12-31'
GROUP BY uid ORDER BY count(uid) DESC LIMIT 20)
) c2017
GROUP BY review_uid, comment_uid ORDER BY comment_uid, review_uid
;
review_uid | comment_uid | count
------------+-------------+-------
6084 | 56 | 62
8999 | 56 | 124
(中略)
rdb=# \crosstabview comment_uid review_uid
comment_uid | 6084 | 8999 | 11736 | 136238 | 77743 | 24735 | 65428 | 84741 | 93238 | 110833 | 129829 | 134232 | 10796 | 22455 | 84866 | 134318 | 138361 | 161920
-------------+------+------+-------+--------+-------+-------+-------+-------+-------+--------+--------+--------+-------+-------+-------+--------+--------+--------
56 | 62 | 124 | 183 | | | | | | | | | | | | | | |
3165 | | | | 1 | | | | | | | | | | | | | |
3658 | | | | 23 | | | | | | | | | | | | | |
5817 | | | | | 1 | | | | | | | | | | | | |
6084 | | 32 | 30 | | 67 | 14 | 24 | 26 | 26 | 15 | 9 | 1 | | | | | |
6736 | | 3 | | | | | | | | | | | | | | | |
7298 | | | 1 | | | | | | 1 | | | | | | | | |
7580 | | | 27 | | | | | | | | | | | | | | |
8999 | 32 | | 65 | 13 | 170 | 6 | 1 | 32 | 89 | 35 | | | 5 | 5 | 10 | 3 | |
10089 | | | 15 | | | | | | | | | | | | | | |
10254 | 1 | 11 | | | 2 | | | | 3 | | | | | | | | |
(中略)
(118 rows)
横軸が神奈川の店舗でレビューが多かったユーザ20名のユーザIDを、縦軸がコメントしたユーザのユーザID(なお、私のユーザIDは8999です)を指します。
例えば「ユーザID=10254のユーザは私(ユーザID=8999)のレビューに対して、1年間で11回コメントしている」「ユーザID=8999のユーザは、ユーザID=11736」のユーザに65回コメントしている」みたいな結果になります。
この検索を繰り返すとユーザ間のネットワーク図が作れるのですが、正直それをPostgreSQLでやるのは面倒なので、そういうときにはNeo4jなんかのグラフデータベースを使ったりします。
それは今日の話題からちょい外れるので割愛。
町田は神奈川
店舗テーブルには、その店舗がどこの都道府県やどの市区郡にあるかという情報があります。これを条件にして、例えば神奈川県にあるラーメン店を探したい、なんてことをするのですが、ラーメンデータベースの公式サイトでは、なぜか町田市が東京都として扱われているので「神奈川県全域のラーメン店を調べたい」ときに町田市のラーメン店が対象外になってしまいます。これは困りますよね。5
自分は神奈川住みなので、やっぱり神奈川のラーメンを探すことが多いです。なので、こんな感じでビューを作っておきます。
CREATE VIEW shops_kanagawa AS
SELECT * FROM shops
WHERE pref='神奈川県' OR pref='東京都' AND area='町田市';
shop_kanagawa ビューを検索すると、
rdb=# SELECT name, pref, area FROM shops_kanagawa LIMIT 5;
name | pref | area
---------------------+----------+--------------
雷文 | 東京都 | 町田市
壱八家 | 神奈川県 | 横浜市戸塚区
中村屋 | 神奈川県 | 海老名市
なんつッ亭 | 神奈川県 | 秦野市
横浜ラーメン 町田家 | 東京都 | 町田市
(5 rows)
当たり前ですが、こんな感じで町田市の店舗データも拾ってくれます。
東京都から町田市を除外したビューも作っておかないと町田市内の店舗が重複しちゃうので、shops_tokyoビューを作っておきます。
CREATE VIEW shops_tokyo AS
SELECT * FROM shops
WHERE pref='東京都' AND area <> '町田市';
shops_tokyoを検索してみます。
rdb=# SELECT name, pref, area FROM shops_tokyo WHERE area = '町田市';
name | pref | area
------+------+------
(0 rows)
これで、東京都の店舗を検索したときに、町田市の店舗がひっかからなくなりました。やっぱり町田は神奈川ですよね。
検索結果に東京都が表示されるのが気に喰わない
何?そういう人はmachidaラッパ関数を作りましょう
CREATE OR REPLACE FUNCTION machida(pref text, area text)
RETURNS text
LANGUAGE SQL
IMMUTABLE
AS $function$
SELECT CASE pref || area WHEN '東京都町田市' THEN '神奈川県' ELSE pref END as pref
$function$
;
これでshops_kanagwaビューを検索します。
rdb=# SELECT name, machida(pref, area), area FROM shops_kanagawa;
name | machida | area
---------------------+----------+--------------
雷文 | 神奈川県 | 町田市
壱八家 | 神奈川県 | 横浜市戸塚区
中村屋 | 神奈川県 | 海老名市
なんつッ亭 | 神奈川県 | 秦野市
横浜ラーメン 町田家 | 神奈川県 | 町田市
(後略)
これで違和感がなくなりましたね。やっぱり町田は神奈川ですし。
おわりに
- PostgreSQLの機能を使うといろいろ楽しい分析ぽいことができる。
- ラーメンは食べて美味しい、分析して二度美味しい。
- 町田は神奈川
-
詳しくは「PostgreSQL ラーメン」でググってください。 ↩
-
別に闇でも何でもなく、単にPyrhonでスクレイピングしているだけですが。 ↩
-
サンマー麺の定義ははっきりしていないが、「肉ともやしや白菜を使用し、野菜はシャキッと手早く炒め、必ずとろみを付けてコクのある具に仕上げる事」が共通しているらしい。出典「かながわサンマー麺の会」 ↩
-
ラーメンデータベースの表示上、30点以下の採点はすべて30と表示される。これをスクレイピングしているので、0点から30点までの採点はすべて30と扱われる。 ↩
-
某横浜ウ●ーカーのラーメン特集なんかでは、フツーに町田市が対象に入っていることが多いです。 ↩