この記事はNuco Advent Calendar 2023の14日目の記事です。
弊社Nucoでは、他にも様々なお役立ち記事を公開しています。よかったら、Organizationのページも覗いてみてください。
また、Nucoでは一緒に働く仲間も募集しています!興味をお持ちいただける方は、こちらまで。
目次
1.はじめに
2.VSCodeの拡張機能紹介
3.コーディングのポイント
4.よく使われる英単語一覧
5.エラーとの向き合い方
6.テストで動作確認
7.検索の極意
8.公式ドキュメントに慣れる
9.リファクタリングでさらに読みやすく
10.資料作成で気をつけること
11.Gitで管理
12.よく使うLinuxコマンド一覧
13.仕事の進め方
14.プログラム以外で意識するところ
15.初心者こそ読んで欲しい本
16.まとめ
1. はじめに
プログラミングは現代のデジタル社会において重要なスキルです。
AIがコードを書いてくれる時代ですが、それでも人の手によるプログラミングはいまだに必要です。それはAIが完璧なコードを書いてくれるわけではないからです。
この記事では、プログラミングの世界に新たに足を踏み入れた皆さんを全力でサポートします。
VSCodeの便利な拡張機能から始まり、コーディングの基本、エラーへの対処法、効率的な検索技術、重要なリファクタリングのコツ、仕事の進め方に至るまで、初心者が即戦力となるための知識を網羅的に提供します。
このガイドを通じてプログラミングの基本を固め、日々の開発作業に自信を持って臨めるようになることを目指します。
プログラミングの世界へ足を踏み入れる皆さん、この即戦力ガイドで一緒に学んでいきましょう。
1-1. 本記事のターゲット
この記事の対象となる人たちは以下を想定しています。
- プログラミングを学び始めの人
- 仕事でプログラミングに触れ始めた人
- 自分のコードに自信がない人
- 読みやすいコードを書きたい人
- 初心を忘れてしまった人
1-2. 本記事の前提
この記事ではインストール方法や環境の設定については説明をしません。
またサンプルコードはPythonで記述をします。
わかりやすさ重視のため、一部あえて細かい説明を省いている部分もございますが、何卒ご容赦ください。
1-3. 参考著書
この記事を書くにあたり、主に以下の著書を参考にさせていただきました。
-
リーダブルコード

-
きれいなPythonプログラミング

その他の記事も大いに参考にさせていただいております。各項目で、説明しきれないところはリンクを貼っておりますので、読み進めながらリンク先で詳細を確認してもらえたらと思います。
2. VSCodeの拡張機能紹介
2-1. VSCodeとは
まずVSCodeについて簡単に説明します。
VSCodeとは正式には「Visual Studio Code」と呼ばれる、ソースコードエディター(プログラムを書くためのソフトウェア)です。
ソースコードエディターはVSCodeの他にAtom、TeraPad、サクラエディタなどいくつか種類があり、これらはコードの自動整形やエラーやデバッグのサポートなど、プログラムを書く際のサポート機能を備えています。
VSCodeは任意で拡張機能を追加することが可能なソースコードエディターで、エンジニアに非常に人気があります。
2-2. おすすめ拡張機能 6選
開発状況で入れた方が良い拡張機能は異なってくるのですが、ここではどんな状況でも役に立つであろう拡張機能を6個紹介したいと思います。
-
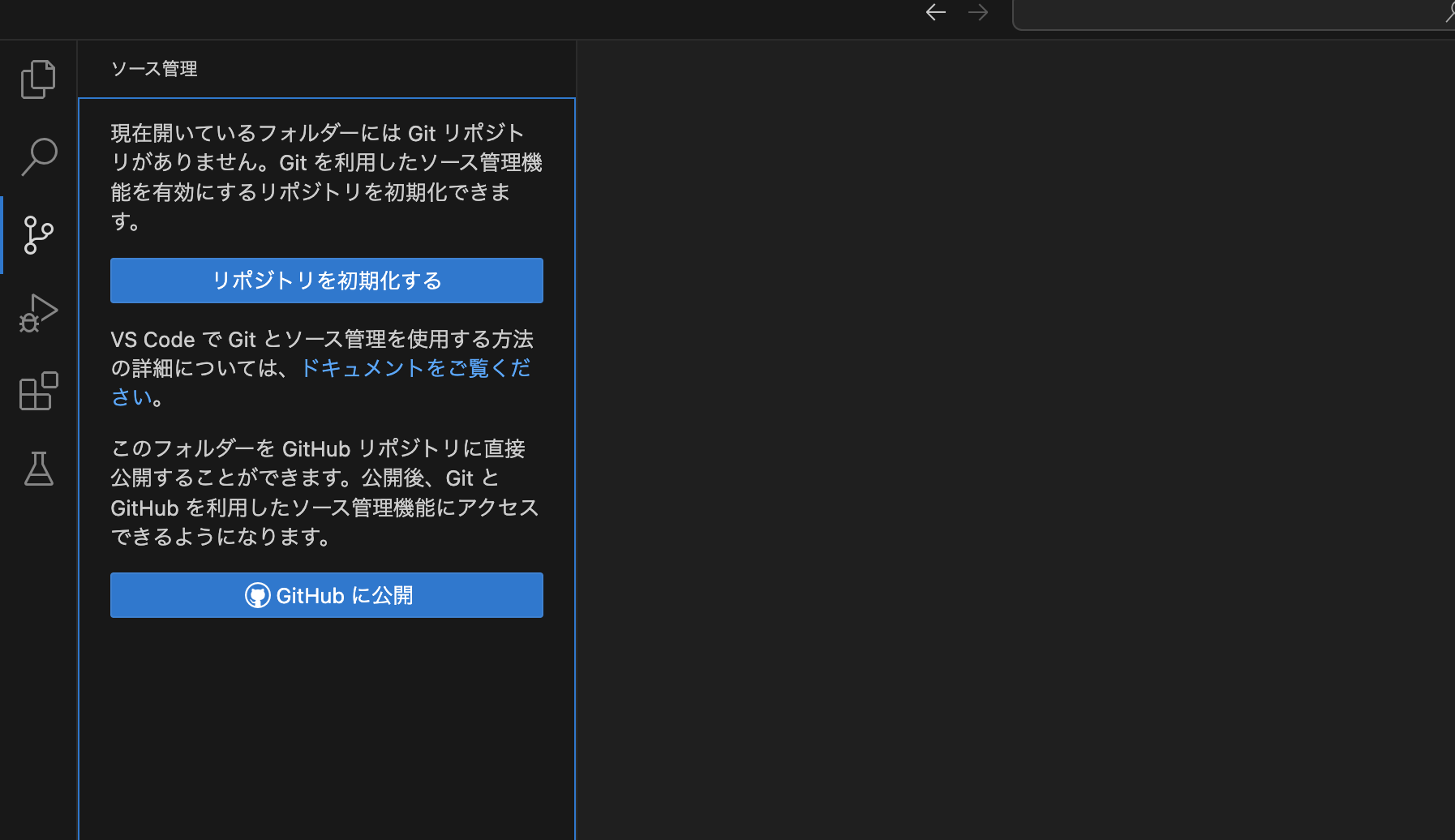
Japanese Language Pack for Visual Studio Code
VSCodeはデフォルトで英語表記です。この拡張機能はVSCode内の表記を日本語にしてくれます。英語に慣れていない方は入れたほうが良いでしょう。
インストール前
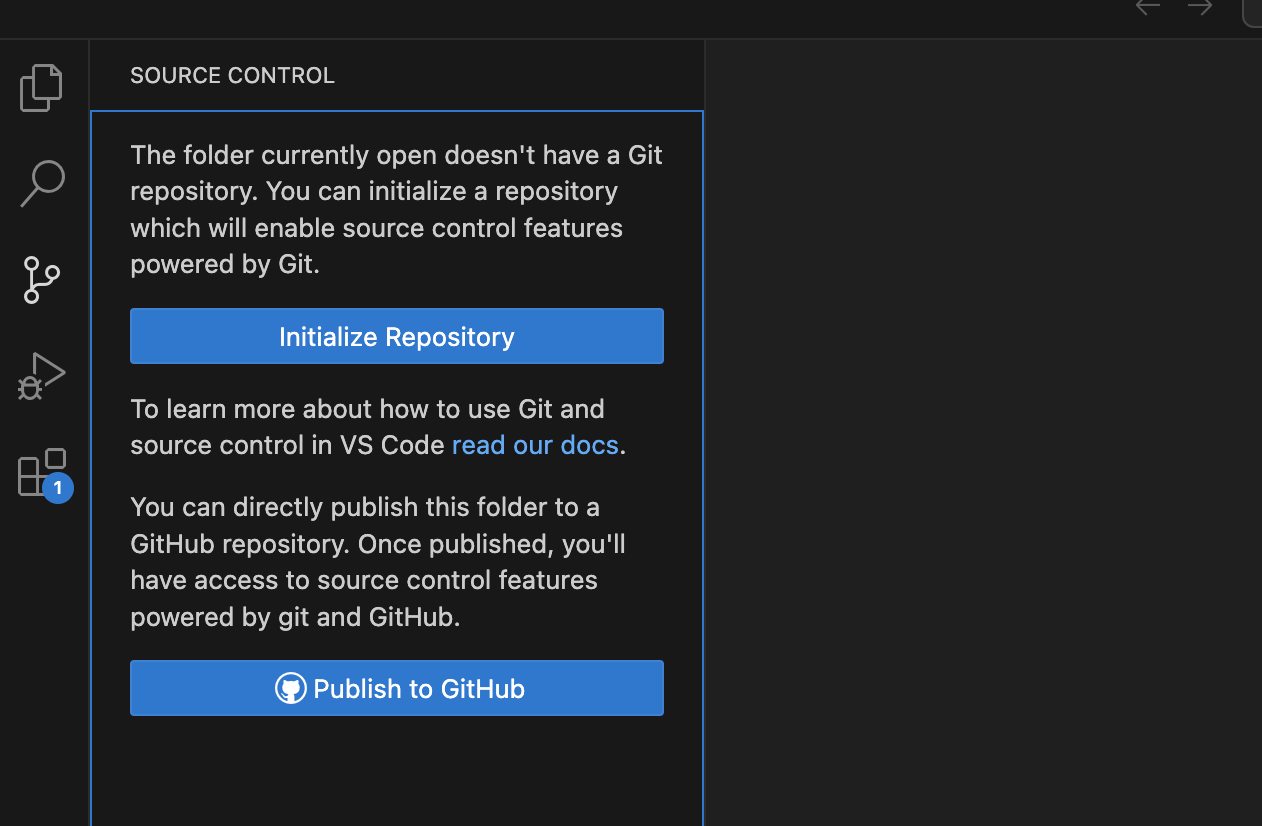
インストール後
-
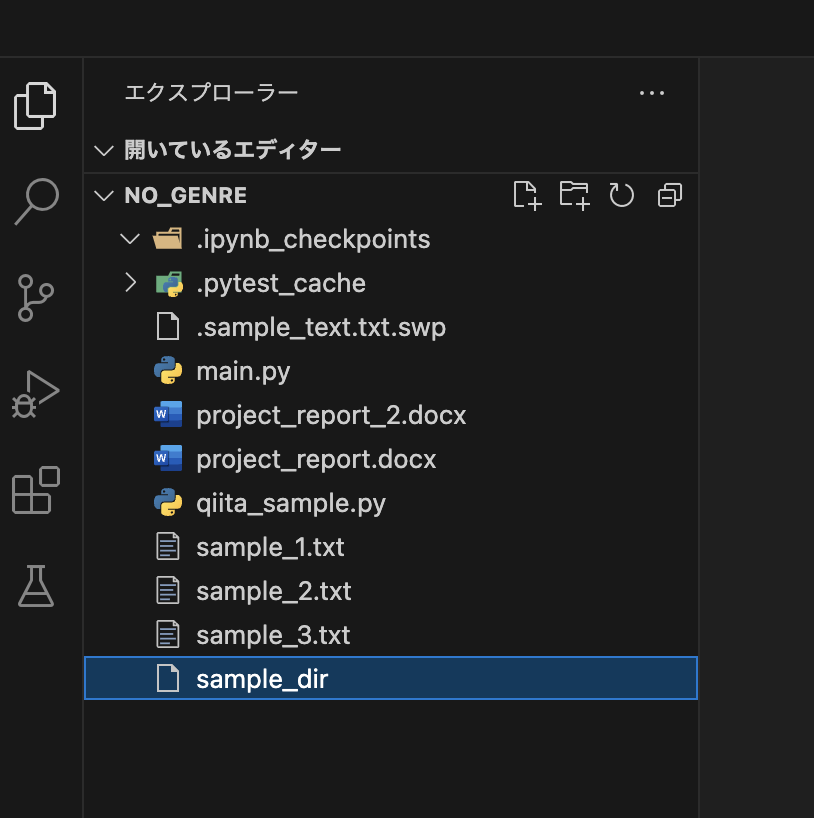
vscode-icons
この拡張機能はファイルやディレクトリのアイコンをわかりやすいように表示してくれます。視認性が高まるため開発スピードが爆上がりすること間違いなしです。
インストール前
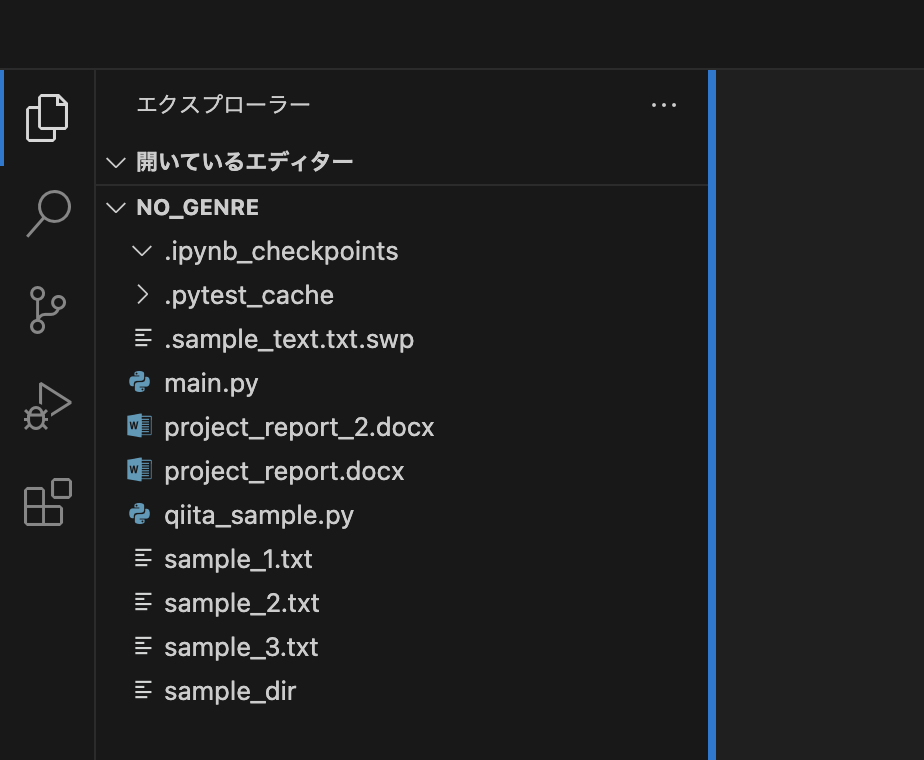
インストール後
-
Code Spell Checker
英単語のタイプミスを教えてくれるとても優れた拡張機能です。寿司打でいくら高得点をただき出す猛者でもタイプミスは無くせないはず。そんな我々のミスを見逃さずに教えてくれます。
インストール前
インストール後
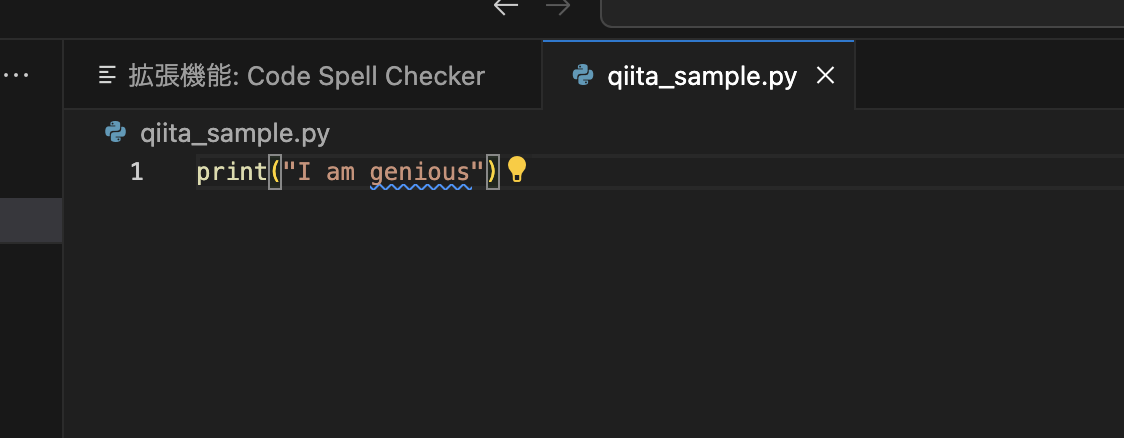
「天才」の英語「genius」のスペルミスを教えてくれていますね。
-
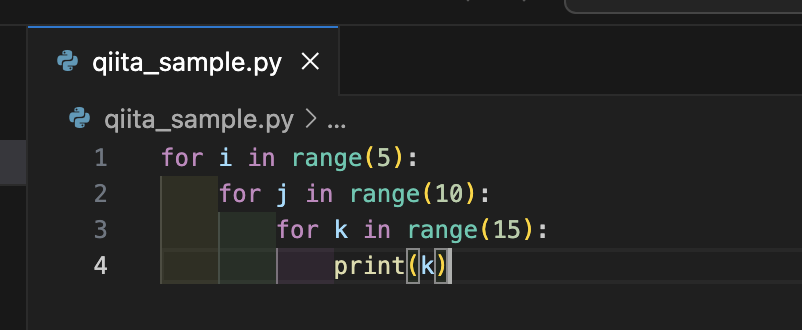
indent-rainbow
インデント(段落)を見やすいように色付けしてくれます。Pythonを利用しているならば入れたほうが良いでしょう。なぜならばPythonはインデントでコードを理解してくれる言語なので、この機能でインデントによるエラーを未然に防ぐことができるからです。
インストール前
インストール後
-
Atom One Dark Theme
VSCodeで表示される色を落ち着いた色にしてくれます。長時間画面と向き合うことを考えるとぜひ入れておきたい機能です。
インストール前
インストール後
-
Trailing Spaces
コードの終わりにある無駄なスペースを教えてくれます。余分なものが無い方がエラーを引き起こしにくいのですが、終わりのスペースほど見つけにくいものはありません。そんな無駄スペースを教えてくれます。
インストール前
インストール後
以上が私のオススメするVSCodeの拡張機能となります。これらがあると無いとでは作業効率が大きく異なってくるはずです。
なお機能紹介は Visual Studio Codeを使うなら絶対に入れておきたい拡張機能Top20【2022最新版】 を参照させていただいております。こちらの記事では今回紹介しきれなかった拡張機能についても書かれていますので、ぜひ読んで見てください。
【追記】
2023年最新版の記事が出ていましたので、こちらも合わせて確認してみてください。
どんな場面でも言えることですが、むやみやたらにインストールすると重くなったりバグが発生したりするので、自分の開発状況に合わせてインストールするようにしてください。
このトピックのまとめ
作業効率を上げるためにVSCodeの以下の拡張機能を入れよう
- Japanese Language Pack for Visual Studio Code(日本語サポート)
- vscode-icons(見やすいアイコンを表示)
- Code Spell Checker(スペルミスチェック)
- indent-rainbow(インデントをわかりやすく表示)
- Atom One Dark Theme(目に優しい色を提供)
- Trailing Spaces(コード文末の見えないスペース検知)
3. コーディングのポイント
3-1. 読みやすいコードを意識しよう
皆さんが思う優れたコードとは何でしょうか?
プログラミングを学び始めたころの私は、短く処理内容が凝縮されたコードが優れていると考えていました。
特に競技プログラミングでは効率性を追求した短いコードが多く見られ、その印象が強かったのです。
しかし、実際の開発現場での経験を通じて 短いコードが優れたコードとは限らない ことを学びました。
エンジニアの業務では、コードを書く時間よりも読む時間の方が遥かに多くなります。特に、チームでのプロジェクトにおいては自分で書いたコードは自分だけのものではなく、他の開発者にも読まれることになります。
自分のコードが他の人にとって読みにくければ、プロジェクト全体の作業効率を下げることになりかねません。
場合によっては、数ヶ月後の自分自身でさえ書いたコードを理解するのに苦労することもあります。
また読みにくいコードが原因でエラーを引き起こしてしまう可能性も多いにあります。
いくらコードを短く書いたからといって、それが他の人にとって読みにくいならば上記のようなことが起きてしまい、結果としてそれは優れたコードとは言えなくなってしまいます。
優れたコードの前提は読みやすいことです。
読みやすいコードとは他の人々にとって理解しやすい、メンテナンスしやすい、そして拡張性があるコードを意味します。
これを達成するためには、変数名や関数名を明確にし、コードに適切なコメントを付けることが重要となってきます。また、複雑なロジックを避け、必要に応じてリファクタリングを行い、コードをシンプルで分かりやすい形に保つことが求められます。
プログラミングは単にコードを書く技術だけではなく、チームでの共同作業も含まれます。
読みやすいコードを書くことは、コミュニケーションの一形態であり、効果的なチームワークの基盤を築きます。
より良いコードを目指して、私たちは常に学び、成長していく必要があります。
このトピックのまとめ
読みやすいコードのポイント
- 優れたコードは読みやすいことが前提にある
- 読みやすいコードは他の人も理解しやすいコードである
- 読みやすいコードはメンテナンスがしやすい、拡張性があるなどのメリットをもたらす
3-2. 名前の付け方
先ほどは読みやすいコードとはどういうコードなのかお伝えしました。
読みやすいコードを書くための第一歩として名前の付け方があります。名前には変数名や関数名、クラス名などがあります。
プログラミング初心者の大多数は名前の重要さを軽んじているのでは無いでしょうか。実際は名前をつける段階が非常に重要で、はじめのうちはここのステップに力を入れるべきです。
では、名前が適切に付けられなかった場合に起こり得ることをいくつかあげてみましょう。
不適切な名前が引き起こす事象
- 可読性が下がりコードの意図を理解しにくくなる
- 上記に伴い保守性や拡張性が低下する
- エラーの特定に時間がかかる
- コードの再利用性を下げる
- チームメンバーのコードに対する認識に差が出る
具体的にサンプルコードで具体的にみていきましょう。
calc(5, 3)
# 出力
8
上記はcalcという関数に5と3を与えたら8が出力された状況を表しています。
calcという関数名から何か計算していることが想像できますが、具体的な処理内容を理解できない関数名となっています。
このcalcの中身は以下のようになっています。
❌ NG
def calc(a, b):
sum = a + b
return sum
2つの引数を合計していますが、関数名から処理内容を把握することができていません。また、この関数にはもう一つ問題があります。
それは引数のa, bがどのような変数を受け取るのかわかりません。
これらの問題を2つまとめて解決して、適切な名前にしてみましょう。
⭕ GOOD
def add(first_integer, second_integer):
total = first_integer + second_integer
return total
関数名から合計を出す処理を行なっていることが把握しやすくなりました。
また引数も数値であることが明確になりました。この状態で関数呼び出し箇所を見てましょう。
num = add(5, 3)
print(num)
# 出力
8
関数名から、2つの引数を受け取って合計した数値を返していることが直感的にわかるようになっていませんか?
このように名前を見ただけで、どのような値が入っているのか、どのような処理が行われているのかがわかるようになれば可読性が高まります。
名前をつけるときは具体的な名前をつけるように心がけてください。
次に命名規則の一部を紹介します。
いざ名前をつけようとしてもルールが無ければ無秩序の名前がコード内に存在することになります。これを防ぐために、一定のルールがあります。
キャメルケース
キャメルケースは最初の単語を除く各単語の最初の文字を大文字にし、残りの文字は小文字で記述します。例えば、camelCaseVariableのようになります。このスタイルは多くのプログラミング言語で変数や関数名に用いられます。ラクダのコブのイメージですね。
camelCaseVariable = "thisIsCamelCase"
スネークケース
スネークケースは各単語をアンダースコア(_)で区切り、全ての文字を小文字で記述します。例えば、snake_case_variableのようになります。このスタイルはPythonなどで変数や関数名によく用いられます。これは蛇のイメージです。
snake_case_variable = "this_is_snake_case"
アッパースネークケース(コンスタントケース)
全ての文字を大文字で記述したスネークケースです。定数に用いられることからコンスタントケースとも呼ばれます。例えば、 SNAKE_CASE_VARIABLEのようになります。このスタイルはPythonなどで定数に用いられます。
SNAKE_CASE_VARIABLE = "THIS_IS_UPPER_SNAKE_CASE"
パスカルケース
パスカルケースは、各単語の最初の文字を大文字にし、残りの文字を小文字で記述します。例えば、PascalCaseVariableのようになります。このスタイルは多くの場合クラス名に用いられます。
PascalCaseVariable = "ThisIsPascalCase"
これらのルールに則って名前を決めるメリットはなんでしょうか。
それは名前から変数、関数、クラスなどのカテゴリーが瞬時にわかることです。名前の命名規則を徹底することで可読性を上げることに繋がります。
次は変数と関数の名前の付け方についてお伝えします。
結論をいうと 変数は名詞/名詞句、関数は動詞 を意識すると良いです。
理由は簡単で、変数は何かしらの数値や文字などのデータを入れる容器みたいなもので、処理(計算する、文字を出力する等)を行わないからです。
一方、関数は動作や振る舞い(計算する、文字を出力する等)をするからです。
それでは変数名の付け方をサンプルコードで見ていきましょう。
❌ NG
send_message = "You are genius."
これはsend_messageという変数名に文字列を格納しているだけで、何かしらの処理をしていません。
変数名が中身と一致していないため、このコードを見た人はsend_messageが「メッセージを送る」処理をする関数だと一瞬思ってしまうかもしれません。
それでは、変数名を修正してみます。
⭕ GOOD
message = "You are genius."
変数名を動詞から名詞にしました。
これにより、読む人はmessageに何かしらの文字列が格納されているということを推測することができるでしょう。
次は関数名について見てみましょう。
❌ NG
def fruits(fruits_name):
print(fruits_name)
これは関数名がフルーツという名詞になっています。フルーツ自体はただの物体であり、何かしらの処理をする訳ではありません。
コードを読んだ人はfruitsの関数名を見た時に何かしらのフルーツの名前が入った変数だと誤解する可能性が高いです。
ここで関数の中身を見ると、引数のフルーツ名を受け取って出力していることがわかります。そこで、この関数名を動詞を用いて以下のように修正してみます。
⭕ GOOD
def print_fruits(fruits_name):
print(fruits_name)
この関数名なら「フルーツの名前を出力する」と認識することができ、可読性が高くなります。
最後に英文法を意識した名前の付け方についてお伝えします。
名前をつける時、具体的な名前をつけようとすると複数の英単語を組み合わせることになります。
例えば「フィルターされたユーザー名」という変数名をつける時を考えてみましょう。
英文法に則るとfiltered_usernameとなりますね。
これを意識しないでfilter_usernameやfiltering_usernameなどとつけてしまうと、変数名から直感的に理解することが難しくなり可読性が低くなります。
このトピックのまとめ
変数名や関数名をつけるときのポイント
- 何の値か、どのような処理なのか名前から見てわかるように具体的な名前をつける
- キャメルケース、スネークケース、アッパースネークケース、パスカルケースを使い分ける
- 変数は名詞、関数は動詞を意識する
- 英文法に則った名前をつける
3-3. 型とは?
型はプログラミングで非常に大切な概念です。プログラムを読むのはコンピュータですが、彼らは書かれたコード内容をそのまま理解することができません。
なのでコードを書く際にコンピュータに対して「これは整数、これは文字列」といった具合に教えてあげなければなりません。
この時の「数値、文字列」が型になります。型には他にも種類があるのですが、代表的なものについて後ほど紹介します。
それではなぜ型が大切なのか確認していきましょう。まずはサンプルコードを見てみましょう。
❌ NG
def add(number, text):
return number + text
result = add(5, "apples") # 5は整数(int)型、"apples"は文字列(str)型
print(result)
# エラーメッセージ
TypeError: unsupported operand type(s) for +: 'int' and 'str'
これは5が整数(int)型、applesが文字列(str)型であり、型が異なるもの同士を足そうとしてエラーになっています。
では同じ型同士は計算できるのか見てみましょう。
⭕ GOOD
def add(number_1, number_2):
return number_1 + number_2
result = add(5, 10) # 5,10ともに整数(int)型
print(result)
# 出力結果
15
これはnumber_1とnumber_2が同じ整数(int)型であるため足し算ができています。
もう一つ見てみましょう。
⭕ GOOD
def add(text_1, text_2):
return text_1 + text_2
result = add("私は", "猫が好きです") # "私は"と"猫が好きです"はどちらも文字列型
print(result)
# 出力結果
私は猫が好きです
これはtext_1とtext_2が同じ文字列型であるため足し算ができています。
もう一歩踏み込んでみましょう。次は関数の出力の型を意識できなかったパターンです。
❌ NG
def add(int_1, int_2):
return int_1 + int_2
def print_num(int):
print("This num is " + int)
num = add(5, 10)
print_num(num)
# 出力
TypeError: can only concatenate str (not "int") to str
これはaddが2つの整数を合計する関数で、print_numが「This num is {引数の数値}」を出力する関数です。
addに5と10を与え、その返り値を変数numに代入しています。そのnumをprint_numに渡しています。
その結果はTypeErrorになっています。これもprint_numで文字列型と整数型を足そうとしていることが原因です。
初めのうちは慣れないかもしれませんが、関数の返り値の型が何であるかを意識することで上記のようなエラーを防ぐことができます。
ちなみに上記のコードを修正すると以下のようになります。
⭕ GOOD
def add(int_1, int_2):
return int_1 + int_2
def print_num(int):
print(f"This num is {int}")
num = add(5, 10)
print_num(num)
# 出力
This num is 15
print_numの処理内容を修正しています。ここのfはフォーマット済み文字リテラルと言います。詳しくはこちらの記事を見てみてください。
型が同じで無ければ演算ができないわけではありません。
上記は説明のための例にすぎず、ここで言いたいことは処理内容と型を意識することが大事だということです。
続いては代表的な型を紹介します。
| 表記 | 型名 | 意味 | 例 |
|---|---|---|---|
| int | 整数型 | 整数を表す | 10 |
| float | 浮動小数点型 | 小数点を含む数値を表す | 10.23 |
| string | 文字列型 | 文字の並びを表す | apple |
| boolean | ブーリアン型 | TrueまたはFalseを表す | True |
| list | リスト型 | 順序付けられた要素のコレクションを表す | ["Tom", "Alice", "Bob"] |
| dict | 辞書型 | キーと値のペアのコレクションを表す | {"name": "Alice", "age": 30} |
| tuple | タプル型 | 順序付けられた変更不可な要素のコレクションを表す | (1, 2) |
| set | セット型 | 重複しない要素のコレクションを表す | {"apple", "banana", "cherry"} |
変数に代入されているデータの型は何か、関数の引数および返り値の型は何かを常に意識してください。
続いては動的型付け言語における型についてお伝えします。
Python、Ruby、JavaScriptなどは動的型付け言語と呼ばれ、プログラムを書くときに型を明示しなくても実行時に勝手に型を理解してくれる言語になります。
以下のサンプルで確認してみましょう。
def add(int_1, int_2):
return int_1 + int_2
num = add(5, 10)
print(num)
print(type(num))
# 出力
15
<class 'int'>
addで引数に5と10の整数を与え、その返り値と型を確認しています。(print(type(num))でnumの型を確認しています。)
numの型はint(整数)型ですね。
続いては引数を5.0と10.0にしてみましょう。
def add(int_1, int_2):
return int_1 + int_2
num = add(5.0, 10.0)
print(num)
print(type(num))
# 出力
15.0
<class 'float'>
numが15.0のfloat(浮動小数点)型に変わっていますね。
このように型を勝手に理解してプログラムを実行してくれるのが動的型付け言語になります。
プログラムは基本的に変数や定数などに型を指定し、その型が格納されないとそもそも実行できないのですが、動的型付け言語は型を明示しなくても都合よく型を理解してくれます。
その結果エンジニアのコードを書くときの手間を省いてくれます。
それでも可読性を高めるためには型を明示した方が良いです。
それはコードを読む人がその変数や定数ががどのような型なのか把握できるからです。
先ほどの2つの関数のサンプルコードについて、型を明示して修正してみましょう。
def add(int_1: int, int_2: int) -> int:
return int_1 + int_2
def print_num(int: int) -> str:
print(f"This num is {int}")
num: int = add(5, 10)
print_num(num)
# 出力
This num is 15
まずaddから見てみましょう。
修正されている点としては引数部分に :intが追記されていますね。また、関数名の列の最後に-> int:も追加されていますね。
引数の追加した箇所は、引数の型がint(整数)型であると明示しています。また-> int:については、この関数の返り値の型がint(整数)型であると明示しています。
関数print_numと変数numについても同様に型を明示しています。
このメリットはコードを追わないでも型がわかることにあります。
プロジェクトのコードはお互いの関係が複雑になり、プロジェクト参加し始めたときのキャッチアップやエラーの原因特定の時は、ひたすらコードを追うことになります。
この時に型が明示されていないと、コードを追う量が一気に増えてしまいますが、型を明示しているとコードを追う量が少なくなります。
今回のサンプルコードでは型を明示することのメリットを中々感じられないですが、普段から型を明示する癖をつけましょう。
また動的型付け言語についてはこちらの記事に詳細が書かれていますので、気になった方は確認してみてください。
このトピックのまとめ
型に関するポイント
- 型はプログラミングで大切な考えである
- 変数や関数の引数、返り値の型を常に意識する
- 動的型付け言語でも型を明示して可読性を上げる
3-4. ミュータブルとイミュータブル
変数には数値や文字列、リストやタプルなどが代入されます。
同じ変数に違う値などを代入し内容を変更できる場合をミュータブルと言い、変更できない場合をイミュータブルと言います。
サンプルコードで確認してみましょう。まずは変更可能なミュータブルについてです。
# ミュータブル
⭕ GOOD
mutable_list = [1, 2, 3]
print("Original Mutable List:", mutable_list)
print(type(mutable_list))
print(mutable_list[0])
mutable_list[0] = 10 # インデックス0の数値「1」を「10」に変更
print("Modified Mutable List:", mutable_list)
# 出力
Original Mutable List: [1, 2, 3]
<class list>
1
Modified Mutable List: [10, 2, 3]
mutable_listに[1, 2, 3]のリストを代入しています。mutable_listのインデックス0の数値が1であることを確認し、その値を10に変更しています。
この時のmutable_listの型はlist型であることも確認できます。
次はイミュータブルのサンプルコードを見てみましょう。
# イミュータブル
❌ NG
immutable_tuple = (1, 2, 3)
print("Original Immutable Tuple:", immutable_tuple)
print(type(immutable_tuple))
print(immutable_tuple[0])
immutable_tuple[0] = 10 # インデックス0の数値「1」を「10」に変更
print("ModifiedImmutable Tuple:", immutable_tuple)
# 出力
File "/Users/qiita/sample.py", line 6, in <module>
immutable_tuple[0] = 10 # インデックス0の数値「1」を「10」に変更
~~~~~~~~~~~~~~~^^^
TypeError: 'tuple' object does not support item assignment
処理内容は先ほどとほとんど同じです。異なる点はimutable_tupleの型がtuple型ということです。(ここではエラーとなり型の確認まではできおりませんが。)
エラー箇所はimmutable_tuple[0] = 10になります。immutable_tupleの内容を変更しようとしてエラーになったのです。
このように、内容の変更ができる場合はミュータブルといい、変更ができない場合はイミュータブルと言います。
なぜこのようにミュータブルとイミュータブルがあるのでしょうか。
先ほどのリストの例のように、ミュータブルなオブジェクトはデータの動的な操作を可能にし、プログラムが実行される間に内容を変更したり拡張したりすることができます。
これによりアルゴリズムやデータ処理が柔軟になります。
またミュータブルなオブジェクトはメモリ効率が良く、新しいオブジェクトを何度も作成する必要がないため、実行速度の向上にも寄与します。
しかしミュータブルなオブジェクトは、予期しない変更によるバグや、並行処理の際のデータ競合を引き起こすリスクがあります。
一方、イミュータブルなオブジェクトは、一度作成されるとその状態が変更されないことが特徴です。
イミュータブルなオブジェクトのこの特徴により、プログラムの安全性と予測可能性を高めることが可能になります。
またデータが変わらないため、予期しない変更や並列処理時の競合が発生しません。
しかし必要に応じて新しいオブジェクトの作成が必要になるため、メモリ使用量が増加する可能性があります。
このようにミュータブルとイミュータブルにはそれぞれメリット・デメリットが存在します。
これらはプログラミングにおける柔軟性、効率性、安全性、予測可能性などのバランスを取るためのものであり、特定のアプリケーションや要件に応じて適切なタイプが選択する必要があります。
このトピックのまとめ
ミュータブルとイミュータブルのポイント
- ミュータブルオブジェクトは内容の変更が可能
- イミュータブルオブジェクトは内容の変更が不可能
- 必要に応じてミュータブルオブジェクトとイミュータブルオブジェクトを使いわける
3-5. 関数の内容はコンパクトに
次は関数の書き方についてです。
3-2.名前の付け方で、関数は処理や振る舞いを行うので、関数名をつけるときは動詞で考えると良いことをお伝えしました。
このとき、1つの関数が色々な振る舞いや処理を行なっていればどうなるでしょうか。
名前をつける時に具体的な名前をつけることができなくります。
その他のデメリットとして、エラーが起きた時や予期しない動作(エラーではないが期待通りの挙動ではない)を起こしたときに、原因特定が困難になってしまいます。
例えば以下のような関数があったとします。
# 多くの処理を持つ関数の例
❌ NG
def process_data(data: list) -> int:
# 入力リストの要素を2倍
processed_data = [x * 2 for x in data]
# データ集計
total = sum(processed_data)
# データ表示
print(f"Processed Data: {processed_data}")
print(f"Total: {total}")
# データ保存
with open("output.txt", "w") as file:
file.write(str(processed_data))
return total
process_data([1, 2, 3, 4])
# 出力
Processed Data: [2, 4, 6, 8]
Total: 20
process_dataの中には「データ前処理」「データ集計」「データ表示」「データ保存」の処理があります。そして「データ集計」処理で行われた合計値(total)を返しています。
このように処理が複数あると、そもそもprocess_dataという関数名が適切でないことがわかります。
しかし、処理全てを反映した関数名、例えばprocessed_print_save_dataも明かにわかりにくですよね。
1つの関数に複数の処理を持たせると可読性が低くなります。
それでは修正した場合のサンプルコードを見てみましょう。
⭕ GOOD
# 入力リストの要素を2倍する関数
def two_times_data(data: list) -> list:
return [x * 2 for x in data]
# データ集計を行う関数
def sum_data(data: list) -> int:
return sum(data)
# データ表示を行う関数
def print_data(data: list, total: int) -> str:
print(f"Processed Data: {data}")
print(f"Total: {total}")
# データ保存を行う関数
def save_data(data: list, filename="output.txt"):
with open(filename, "w") as file:
file.write(str(data))
# 関数を組み合わせて全体のプロセスを実行
original_data = [1, 2, 3, 4]
processed_data = two_times_data(original_data)
total = sum_data(processed_data)
print_data(processed_data, total)
save_data(processed_data)
# 出力
Processed Data: [2, 4, 6, 8]
Total: 20
先ほどのprocess_dataに含まれていた4つの処理を4つの関数に分けています。
出力結果は同じですが、 関数の責任(関数が行う処理)がより明確になりました。また関数名も処理内容を反映したものになっています。
関数の数自体は増えていますが、可読性の向上とエラー特定も簡単になることから分割する方が良いです。
定義した関数の処理内容が多いなと感じたら、その関数の処理の「動詞」を考えてみてください。
サンプルコードでもわかるように、動詞にすることで関数の分割するポイントが見えてくるはずです。
このトピックのまとめ
関数の処理内容をコンパクトにするポイント
- 関数に複数の処理をなるべくさせない
- 関数の処理が複数あると具体的な関数名をつけにくくなる
- 処理内容が複数ある場合、処理の「動詞」を考えてみる
3-6. 説明変数とは
説明変数とは式を表す変数のことです。
と言われてもよくわからないと思うので早速サンプルコードでみてみましょう。
❌ NG
if line.split(":")[0].strip() == "root":
print("This is root")
処理内容は置いておいて、このコードを読んだ時if文を直感的に理解しにくくありませんか。
このサンプルコードにおける式はline.split(":")[0].strip() == "root"になります。
これを以下のように修正してみましょう。
⭕ GOOD
username = line.split(":")[0].strip()
if username == "root":
print("This is root")
usenameという変数を宣言して、先ほどの式の左辺(line.split(":")[0].strip())を入れています。
その後、usernameを条件文で利用しています。
つまり変数を準備して、式を分割していることになります。
修正前のコードだと「何」が「root」ならば「This is root」が出力されるのかが、わかりにくいです。
しかし修正後だと「username」が「root」ならば「This is root」が出力されることが、すぐにわかるのではないでしょうか。
このように式を利用する場面において、そのままコードを書くとわかりにくい場合は、わかりやすい名前の変数を準備して式を代入することで可読性が高くなります。
このトピックのまとめ
説明変数のポイント
- 式を用いた時に読みにくいのであれば、変数を準備して式を分割する
3-7. 変数への書き込みは1度だけ
変数には何かしらのデータを代入しますが、同じ変数に他のデータを何度も代入することは避けましょう。
再代入を行うことでさまざまなデメリットが生じます。
まず、同じ変数に異なる値や異なる型のデータを繰り返し代入すると、コードの読み手がその変数の現在の値や、変数の意味を理解するのが難しくなります。
また変数の値が頻繁に変更されると、プログラムの特定の部分で期待される値が保持されなくなる可能性があり、これがバグの原因になることがあります。
他にも変数が頻繁に変更されると、デバッグ中にその変数の値がどの時点でどのように変化したかを追跡するのが難しくなったり、同じ変数が異なる箇所で使用されたことによりコードの修正や拡張が難しくなります。
それではサンプルコードで確認してみましょう
❌ NG
def process_data(data: list) -> int:
result = sum(data) # 合計を計算
result = result / len(data) # 平均を計算
result = round(result, 2) # 結果を丸める
return result
average = process_data([1, 2, 3, 4, 5])
print("Average:", average)
# 出力
Average: 3.0
process_dataの中でresultに何度か値が代入され返されていますが、このresultには何の値が入っているのかわかりにくくなっています。(そもそもresult自体も具体的な変数名ではないですね)
次に修正したサンプルコードを見てみましょう。
⭕ GOOD
def process_data(data: list) -> int:
total = sum(data) # 合計を計算
average = total / len(data) # 平均を計算
rounded_average = round(average, 2) # 結果を丸める
return rounded_average
average = process_data([1, 2, 3, 4, 5])
print("Average:", average)
# 出力
Average: 3.0
resultに何度も代入していた時よりも具体性が増しています。またこのようにすることで、関数の中身が複雑になっても同じ変数を利用することを避けられるので、バグを生み出す可能性を下げてくれます。
ただし処理によっては再代入を必要とするところも出てくると思うので極力、再代入をしないことを心がけてください。
次に参照透過性について少しお伝えします。参照透過性には以下2つのポイントがあります。
- 関数は同じ変数を引数として与えられれば同じ値を返す
- 変数の値は最初に定義した値と常に同じとする
後者については先述のとおりです。
前者についてをサンプルコードで見てみましょう。
❌ NG
total = 0
def add_to_total(value: int) -> int:
global total
total += value
return total
result1 = add_to_total(5)
print("結果1:", result1)
result2 = add_to_total(5)
print("結果2:", result2)
# 出力
結果1: 5
結果2: 10
これは参照透過性を守れていないサンプルコードです。
参照透過性では、関数は同じ引数なら同じ出力結果を出すことがルールですが、上記のサンプルコードでは引数5を与えられたときに1回目と2回目で出力結果が異なっています。
出力結果が、1回目は5なのですが、2回目では10となっていますね。
これは関数の中でグローバル変数のtotalが呼ばれていること原因です。(グローバルについては後述)
totalの初期値は0で、1回目の関数で呼ばれ 0 + 5 = 5となり、5が代入され返されています。
2回目の関数で呼ばれたときはtotalに5が入った状態なので5 + 5 = 10となり、10が代入され返されています。
この結果から、関数の処理が関数の外にあるグローバル変数に依存していることがわかります。
このように、引数が同じなのに出力が異なると処理が複雑になってきた時にエラーやバクの原因となるだけでなく、その原因の特定が難しくなってしまいます。
関数の処理が外部の要素に依存しないようにすることが大切です。
それではサンプルコードを修正してみましょう。
⭕ GOOD
def add_values(value1: int, value2: int) -> int:
return value1 + value2
result1 = add_values(5, 10)
print("結果1:", result1)
result2 = add_values(5, 10)
print("結果2:", result2)
# 出力
結果1: 15
結果2: 15
若干処理内容が変わっていますが、同じ引数を与えたときに同じ出力となることが確認できます。
このように参照透過性を守ることはプログラミングにおいて重要です。
このトピックのまとめ
説明変数への代入は1度だけのポイント
- 変数への再代入は原則しない
- 同じ引数を与えたら同じ出力を返す関数を作る
3-8. if文を読みやすく
続いてはif文を読みやすくするポイントをお伝えしようと思います。
if文の条件文を考える時、自然な日本語で考えていませんか?
例えば「年齢が10歳以上なら」や「色が赤なら」といった具合です。
この日本語をそのままコードに落とし込めば、それだけでも可読性は上がります。サンプルコードで見てみましょう。
❌ NG
age = 10
if 10 <= age:
print("age is over 10")
# 出力
age is over 10
この条件文は先ほどの「年齢が10歳以上なら」の語順に則っていませんよね。
読み手からすると不自然であり、理解に時間を要します。
これを修正すると以下のようになります。
⭕ GOOD
age = 10
if age >= 10:
print("age is over 10")
# 出力
age is over 10
語順が文法に則っているためこちらの方が読みやすくなります。
それでは修正後のサンプルコードを少し変更してみます。
❌ NG
age = 10
if not age < 10:
print("age is over 10")
# 出力
age is over 10
条件文が否定系になっています。出力自体はこれまでと同じなのですが否定系にすると読みにくくなっていませんか?
余程のことがない限りコードは普通肯定で書かれるので否定系が出てくるとコードの可読性が下がってしまいます。
可読性を落とさないためにも条件文で否定系を使用することは極力避けましょう。
続いては三項演算子についてです。まずは以下のサンプルコードを確認してみましょう。
age = 9
if age >= 10:
print("age is over 10")
else:
print("age is under 10")
# 出力
age is under 10
これでも直感的に意味はわかるのですが、少し冗長な気がします。これを1文にまとめることが可能なので、サンプルコードで見てみましょう。
age = 9
print("age is over 10") if age >= 10 else print("age is under 10")
# 出力
age is under 10
このように 条件が成立したとき if 条件 else 条件が成立しなかったときのように記載することを三項演算子と言います。
先ほどの elseブロックがある時よりも冗長性が無くなりスッキリしていますね。
このように三項演算子を用いることで可読性を上げることができます。
しかし、場合によっては三項演算子が読みにくくなることもあります。
サンプルコードで確認してみましょう。
❌ NG
a = 5
b = 10
c = 15
result = a * 2 if b > 5 else c if a < 10 else b
print("Result:", result)
# 出力
Result: 10
サンプルコードでは三項演算子を使っていますが、直感的に分かりにくいですよね。その結果、可読性を低くさせています。
この場合は無理に三項演算子を使わないで、elseブロックを使用した方が良いです。
以下修正したサンプルコードです。
⭕ GOOD
a = 5
b = 10
c = 15
if b > 5:
result = a * 2
elif a < 10:
result = c
else:
result = b
print("Result:", result)
# 出力
Result: 10
先ほどの三項演算子を使った場合よりも、直感的にわかりやすくなっていませんか。
このように、コードを短くしても他の人が読みにくくなるくらいならば、少し冗長になっても読みやすい方が可読性が高くなります。
このトピックのまとめ
if分を読みやすくするポイント
- if文の条件文は日本語の文法の語順で書く
- 条件文にはなるべく否定系を使用しない
- 状況に応じて三項演算子を使用する
3-9. ネストは浅く
プログラムの内容が複雑になると、ネストが深くなってしまうことがあります。
しかし、ネストを深くすることは可読性の低下につながります。
ネストが深い場合のサンプルコードを見てみましょう。
❌ NG
def check_conditions(num_1: int, num_2: int, num_3: int):
if num_1 > 0:
if num_2 > 0:
if num_3 > 0:
print("All variables are positive")
else:
print("c is not positive")
else:
print("b is not positive")
else:
print("a is not positive")
check_conditions(1, 2, -3)
# 出力
c is not positive
サンプルコードではif文が3つ使用されています。このコードを読むとき「aが0より大きいならば」 → 「bが0より大きいならば」 → 「cが0より大きいならば」と条件文を追っていく必要があります。
これがさらにネストが深くなり、また条件文も複雑になると非常に読みにくくなることが考えられますね。
それではネストを深くしないように修正したサンプルコードを確認してみましょう。
⭕ GOOD
def check_conditions(num_1: int, num_2: int, num_3: int):
if num_1 > 0 and num_2 > 0 and num_3 > 0:
print("All variables are positive")
elif num_1 <= 0:
print("a is not positive")
elif num_2 <= 0:
print("b is not positive")
else:
print("c is not positive")
check_conditions(1, 2, -3)
# 出力
c is not positive
3つの条件文を組み合わせ、かつ条件文を追加することでネストが浅くなり、読みやすくなりました。
別のパターンも見てみましょう。
⭕ GOOD
def check_conditions(num_1: int, num_2: int, num_3: int):
if num_1 <= 0:
print("a is not positive")
return
if num_2 <= 0:
print("b is not positive")
return
if num_3 <= 0:
print("c is not positive")
return
print("All variables are positive")
check_conditions(1, 2, -3)
# 出力
c is not positive
こちらもネストが浅くなり読みやすくなっています。先ほどのパターンと違うところは、各if文にreturnが設定されている点です。
これは早期リターン(アーリーリターン)またはガード節といい、条件に当てはまったら関数を終えることができます。
早期リターンによって無駄な処理を走らせることがなくなる(条件に当てはまったif文のreturn以降の処理が走らない)ので、バグやエラーの発生を少なくさせることができます。
今回はif文を例にしましたが、他にもfor文などでもネストが深くなる場合があるので、その時は一度処理自体を見直すようにし、ネストが浅くなるようにしましょう。
このトピックのまとめ
ネストを浅くするポイント
- ネストが深いと可読性が下がる
- if文でネストが深いなら、条件文を考え直しネストを浅くするようにする
- アーリーリターンでネストを浅くすると、エラーやバグの原因が少なくなる
3-10. スコープ(範囲)を意識する
プログラミングにおけるスコープとは、変数や関数などの名前(識別子)が有効である範囲のことを指します。
スコープがあることでプログラムの異なる部分(ブロック等)で名前の衝突を避けることができるので、重要な役割となっています。
ここではグローバルスコープとローカルスコープについてお伝えします。
グローバルスコープとは、プログラム全体にわたる範囲(スコープ)のことを指します。
グローバルスコープで宣言された値や変数(グローバル変数という)や関数はどこからでもアクセス可能になりますが、グローバル変数を多用すると、プログラムの理解や保守が難しくなる可能性があります。
ローカルスコープとは、関数やブロック内など特定の範囲(スコープ)のことを指します。
ローカルスコープで宣言された値や変数は、その関数やブロック内でのみ有効です。これにより、同じ名前の変数が他の場所で使われていても、それらが衝突することなく独立して機能します。
それではサンプルコードで確認してみましょう。
global_variable = "グローバル" # グローバル変数
def print_scope() -> str:
local_variable = "ローカル" # ローカル変数
print("関数内:", local_variable)
print("関数内:", global_variable)
print_scope()
# 出力
関数内: ローカル
関数内: グローバル
サンプルコードでglobal_variableがグルーバル変数になります。これは特定の範囲内で宣言されていないグローバル変数になります。
一方local_variableは関数print_scopeで宣言されたローカル変数になります。
サンプルコードではグローバル変数をprint_scopeのローカルスコープでも呼び出すことが可能ということが確認できます。
次のサンプルコードでグローバル変数とローカル変数の違いを確認してみましょう。
⭕ GOOD
# グローバル変数を出力
global_variable = "グローバル" # グローバル変数
def print_scope() -> str:
local_variable = "ローカル" # ローカル変数
print("関数内:", local_variable)
print("関数内:", global_variable)
print(global_variable)
# 出力
グローバル
❌ NG
# ローカル変数を出力
global_variable = "グローバル" # グローバル変数
def print_scope() -> str:
local_variable = "ローカル" # ローカル変数
print("関数内:", local_variable)
print("関数内:", global_variable)
print(local_variable)
# 出力
NameError: name 'local_variable' is not defined. Did you mean: 'global_variable'?
上記より、グローバル変数の出力は問題ないのですが、ローカル変数の出力ではエラーが発生していますね。
先ほどお伝えしたようにローカル変数は宣言された関数やブロックのみで有効となります。
エラーが起きたサンプルコードではlocal_variableは関数print_scope内で宣言されたローカル変数です。
このローカル変数を関数外(スコープ外)から呼ぼうとして(print(local_variable)の箇所)エラーが起きてしまったのです。
このようにグローバルスコープとローカルスコープで宣言された変数の扱われかれ方が異なりますが、これらがあることのメリットは何でしょうか。
グローバルスコープで値や変数を宣言することのメリットは、先ほどのサンプルコードで確認できたように、どこからでも呼ぶことが可能になることです。
アプリケーション全体で利用する値や変数をグローバルスコープで宣言すれば、スコープの違いによるエラーが防ぐことができるでしょう。
また頻繁に利用する値や変数をグローバルスコープで宣言することで一箇所にまとめることになり、再利用されることになるのでメモリの効率化へとつながります。
次に、ローカルスコープについてです。
ローカルスコープで値や変数を宣言することのメリットは、変数名の衝突を防ぐことが挙げられます。ローカルスコープで宣言された値や変数は、そのスコープでしか有効でないため、他のスコープ(関数など)で同じ変数名があってもお互いに干渉することがありません。
これについてサンプルコードで確認しましょう。
def print_student_name() -> str:
name = "Tom"
print("student name:", name)
def print_teacher_name() -> str:
name = "Alex"
print("teacher name:", name)
print_student_name()
print_teacher_name()
# 出力
student name: Tom
teacher name: Alex
print_student_nameとprint_teacher_nameそれぞれの関数内でnameというローカル変数が宣言されていますね。
これらの変数にはTomとAlexが代入されているのですが、関数を実行した時にお互いの名前を保持しています。
これが先ほどお伝えした、ローカル変数はお互いに干渉しないということです。
それではグローバル変数とローカル変数は干渉するのかも合わせて確認しましょう。
name = "Alex"
def print_student_name() -> str:
name = "Tom"
print("student name:", name)
print_student_name()
# 出力
student name: Tom
nameがグローバル変数とローカル変数として存在していますね。
グローバル変数でAlexを代入したのち、ローカル変数でTomを再代入した結果、最終的には出力がTomになっています。
このようにグローバルスコープとローカルスコープを意識しないと、エラーやバグの原因となってしまうので、注意する必要があります。
グローバルスコープとローカルスコープで何の値や変数を宣言すべきなのか、コードを書く時にはよく考えるようにしましょう。
このトピックのまとめ
グローバルスコープとローカルスコープのポイント
- スコープにはグローバルスコープとローカルスコープがある
- グローバルスコープで宣言された値や変数(グローバル変数)はどこからでもアクセスが可能
- ローカルスコープで宣言された値や変数(ローカル変数)はローカルスコープ内のみで有効
- グローバルスコープとローカルスコープで何の値や変数を宣言すべきか考慮する
3-11. 不要なコードは削除する
プログラミングでよく目にするコメントアウトなどがされている不要なコードですが、これが残っていることで様々なデメリットをもたらしてしまいます。
まずは可読性の低下です。サンプルコードで確認してみましょう。
❌ NG
def add(numbers: list) -> int:
total = 0
for number in numbers:
total += number
unused_variable = 10
return total
sample_list = [1, 2, 3]
num = add(sample_list)
print(num)
# 出力
6
この関数はnumbersというリストを受け取り、リストの中の数値を合計して返しています。
ただ、unused_variable = 10 というコードは処理の中で何もしていません。このような不要なコードがあると、何のために設定されているのか読む人が無駄に時間を要してしまう可能性があります。
この不要コードを削除したら以下のようになります。
⭕ GOOD
def add(numbers: list) -> int:
total = 0
for number in numbers:
total += number
return total
sample_list = [1, 2, 3]
num = add(sample_list)
print(num)
# 出力
6
不要コードがなくなったことで処理内容がわかりやすくなりました。
このように可読性を下げる不要コードはどんどん削除していきましょう。
続いてのデメリットは保守性の低下です。先ほどの内容と被ってしまうのですが、コードのリファクタリング(後述)において、不要なコードがあることで修正の妨げとなります。
他にも使われていないコードがあると、その分メモリを消費するのでパフォーマンスの低下にも繋がります。
最後にバグの原因にもなります。不要コードといえど、何かしらのタイミングで他の部分と干渉してしまう可能性があります。
こういったデメリットがあるので不要コードは消すようにしましょう。
何かのタイミングでまた使うかもしれないと思うかもしれませんが、不要コードはその後使われることはほぼ無いので心配する必要はありません。
このトピックのまとめ
不要コードを削除するポイント
- 可読性の低下、保守性の低下、メモリの無駄な消費、バグの原因になるので不要コードは消す
- 不要コードはその後使われることはほぼ無い
3-12. 重複コードは避ける
同じような内容の重複コードがあれば、それを排除(1つにまとめるなど)で対応しましょう。
重複コードがあることのデメリットは先ほどの不要なコードは削除するであげたものと同様になりますが、1点だけさらに追加されます。
それは機能拡張がしにくくなるです。同じようなコードを書いていると、その箇所の修正があった場合、他の同様のコードも合わせて修正しなければならなくなります。
1、2箇所であれば問題ないのですが、重複コードが全体に及んでいる場合は修正に非常に時間がかかることになります。
また修正の漏れがあった場合、そこがエラーの原因にもなります。
それではサンプルコードで確認していきましょう。
❌ NG
def print_student_details(name: str, age: int, grade: int) -> str:
print(f"Name: {name}")
print(f"Age: {age}")
print(f"Grade: {grade}")
def print_teacher_details(name: str, age: int, subject: str) -> str:
print(f"Name: {name}")
print(f"Age: {age}")
print(f"Subject: {subject}")
print_student_details("Tom", 15, 3)
# 出力
Name: Tom
Age: 15
Grade: 3
print_teacher_details("Alexander", 30, "Science")
# 出力
Name: Alexander
Age: 30
Subject: Science
1つずつ関数の中身を見てみましょう。
print_student_detailsは生徒の名前、年齢、学年を出力します。
print_teacher_detailsは先生の名前、年齢、教科を出力します。
2つを見比べると名前と年齢を出力する箇所が重複していることがわかります。
同じような内容なのに関数が2つに分かれているのも冗長に感じられるのではないでしょうか。
この冗長なコードを以下のように修正してみます。
⭕ GOOD
def print_details(name: str, age: int, third_label, third_attribute) -> str:
print(f"Name: {name}")
print(f"Age: {age}")
print(f"{third_label}: {third_attribute}")
print_details("Tom", 15, "Grade", 3)
# 出力
Name: Tom
Age: 15
Grade: 3
print_details("Alexander", 30, "Subject", "Science")
# 出力
Name: Alexander
Age: 30
Subject: Science
まず2つあった関数が1つにまとまりました。そして重複コードも無くなっています。
ここでprint_detailsについて少しみてみましょう。
引数にthird_labelとthird_attributeが新しく追加されています。
修正前のコードと比較するとthird_labelには Grade またはSubjectの文字列が入り、' third_attribute ` には学年数か教科が入ることがわかると思います。
修正後は引数が増えてしまっていますが、print_details呼び出す時の引数の渡し方も異なってしまいますが、全体としてスッキリしたと思われます。
このように重複したコードがある場合は、それを1つにまとめるようにしていきましょう。
このトピックのまとめ
重複コードを排除するのポイント
- 可読性の低下、保守性の低下、メモリの無駄な消費、バグの原因、機能拡張時のコスト増大につながるので重複コードはまとめる
- 同じようなコードを見かけたら1つにまとめるようにする
3-13. 言葉で説明できるコードを書く
あなたは自分で書いたコードを他の人に説明できるでしょうか。
アルバート・アインシュタインは以下の言葉を残しています
おばあちゃんがわかるように説明できなければ、本当に理解したとは言えない。
何度も言いますが、どんなに複雑なコードでもそれを理解してもらえなければほとんど意味がありません。
ましてや、自分で書いたコード自体も言葉で説明できないのならばそれは理解に苦しむコードと言われるでしょう。
説明できるためには処理内容を簡単なレベルに落としこむことが解決策につながるはずです。
これは文章でも同じです。以下の日本語を見てみましょう。
昨日、私が大学で研究している分野に関連する重要な講義があったのですが、その講義についての詳細な内容を友人に説明しようと思ったところ、その講義で取り扱われた複数の理論とそれらがどのように互いに関連しているのか、さらにそれらの理論が現代の社会においてどのように応用され得るのかという点について、私自身も完全には理解していない部分が多々あることに気づき、その講義の内容を再度じっくりと振り返りながら、それに関連する文献や研究報告を調べたり、さらには専門的な知識を持つ教授にもいくつか質問を投げかけてみたりするなど、多角的にその理解を深めるための努力をした結果、ある程度その内容を理解することができたものの、それを友人に簡潔に説明するということが思いの外難しく、結局長々と話してしまい、友人にはその複雑な内容を的確に伝えることができなかったという経験を昨日のうちにしてしまったのでした。
もはや何がなんだかわかりません。文章の内容自体が複雑なことに加え、1つの文章に詰め込みすぎです。
この文章をわかりやすくしてみましょう。
昨日、大学の講義で研究分野に関する重要な話がありました。しかし、その複雑な内容を友人に説明しようとしたとき、自分も完全には理解していないことに気づきました。そこで、その話題についてもっと勉強しました。文献を読んだり、教授に質問したりして、内容を理解する努力をしました。最終的にはある程度理解できましたが、それを友人に簡潔に伝えるのは難しかったです。
こちらの方が圧倒的にわかりやすく本質を逃していません。
この文章ならおばあちゃんに伝えても理解されるはずです。
これはコードでも同じです。
あなたが書いたコードを他の人に説明できるのか立ち止まってみてみましょう。
もしもできないようならば複雑な処理を行なっていないか、もっと簡単なロジックに落とし込めないかを疑うべきです。
このトピックのまとめ
他の人に説明できるコードを書くポイント
- 他の人に説明できないコードは理解されにくい
- 説明できないコードとなっている場合は、複雑な処理でないか、ロジックを簡潔にできないかを疑う
3-14. コメントの容量用法は適切に
コメントをメモ代わりとして残そうとする人がいます。
一見、他の人がコード読んだ時のサポートとなるから良いように見えますが、実際のところはそうではありません。
適切なコメントが読み手をサポートしてくれるのであり、それ以外は逆に可読性を落としてしまいます。
コメントがあると読み手はそこを読むために時間を割きます。またコメントがある分、画面を占領してしまうことになります。
コメント自体はコードに影響を与えることはないのですが、コメントを残す場合は先程のデメリットを上回る価値が必要となります。
それでは不適切なコメントとはなんでしょうか。
関数や変数に対するコメントはハッキリ言ってほとんどが意味がないでしょう。
そもそも、そのような箇所にコメントを残すということは関数名や変数名が適切につけられていない可能性があります。
またコードを読めば処理内容がわかるため、これもコメントにする必要がありません。
サンプルコードで確認しましょう。
❌ NG
# この関数は引数を受け取り合計値を返します。
def calculate(int_1: int, int_2: int) -> int:
return int_1 + int_2
num = calculate(5, 10)
print(num)
# 出力
15
これは関数名の付け方が不適切です。また処理内容もコードを見ればわかります。
関数名が適切ならばコメントをする必要がありません。
サンプルコードを修正してみましょう。
⭕ GOOD
def add(int_1: int, int_2: int) -> int:
return int_1 + int_2
num = add(5, 10)
print(num)
# 出力
15
関数名が具体的になったことでコメントの必要が無くなりました。
次の不適切なコメントについてですが、曖昧な言葉を使っているコメントも良くありません。
代名詞(あれ、それ、これ等)などがコメントにあると読み手はさらにその代名詞を読み解かなくてはなりません。
曖昧な言葉を使うことを避け、簡潔(複数行にならない)で具体的な言葉でコメントを残すようにしましょう。
次はコメントを残した方が良いパターンを考えてみます。
コメントを残した方が良い例として、定数に対するコメントや、コードから読み取れない処理実行時に対するコメントがあります。
まず定数のコメントのサンプルコートで見てみましょう。
⭕ GOOD
# ブックマークの上限は現実的に1000が妥当
max_bookmark_num = 1000
この場合max_bookmark_numに1000の値を設定しているが、なぜ1000なのか読み手はコメントがなければ、その意図が読み取れません。
しかしコメントにあるように「現実的に1000が上限ですよ」とコメントを残しておくと、その定数の背景がわかり、読み手もコードに対する理解が深まります。
次にコードから読み取れない処理に対するコメントです。
⭕ GOOD
# 関数を実行すると完了までに1時間程度要する
def archive_documents(documents: list, genres: list):
categorized_documents = {}
for document in documents:
for genre in genres:
categorized_documents[genre] = document
return categorized_documents
この場合、コードを読んだだけではわからない実際の処理の内容をコメントとして残しています。
サンプルコードではarchive_documentで二重for文が使われていますが、実際にこの関数が動いたときにどのくらい処理に時間がかかるかまではわからないです。
この処理にかかる時間を、関数前にコメントで残しておくと読み手は実際にコードが走ったときに「なんでこんなに時間がかかるんだろう」と疑問に思わなくなります。
このように、コードの背景がわからない箇所や、実際の処理に関するコメントは有効となることがあります。
コメントに対して、そのコメントが具体的に何を意味するのかを明示するコメントも存在します。
例えばTODOコメントです。TODOコメントは、その箇所で行わないといけない内容を記載するものです。
サンプルコードで確認しましょう。
def calculate_statistics(data):
# TODO: この関数の処理を実装する
pass
この場合は、calculate_statisticsの具体的な処理がまだ実装されていないので、TODOコメントで将来的に実装する旨をコメントで残しています。
このTODOのようなコメントはアノテーションコメントといい、特定の意図や注意点をマークするために使われるコメントになります。
以下に代表的なアノテーションコメントを紹介します。
| アノテーションコメント | 意味 |
|---|---|
| TODO | まだ実装されていない機能や、後で追加または改善する必要がある部分を示す |
| FIXME | 修正が必要なバグや問題点を指摘 |
| HACK | 標準的でない方法、または一般的でない解決策を使っているコード部分を示す |
| XXX | 注意を引くためのコメントで、特に注意深く見るべき危険なまたは疑わしいコードを指摘 |
| REVIEW | 他の開発者によるレビューが必要なコードを示す |
| OPTIMIZE | パフォーマンスの最適化が必要なコードを指摘 |
| CHANGED | 最近変更されたコードを示す |
| NOTE | 他の開発者にとって有益かもしれない情報、注意点、説明を提供 |
| WARNING | コードが特定の条件下で予期せぬ結果を引き起こす可能性がある場合に使用 |
このようなアノテーションコメントを利用することで、読み手にとってどのような意味があるのが簡潔に伝えることができます。
このトピックのまとめ
コメントを残すときのポイント
- コメントは読み手にとってコストとなる場合もある
- 関数や変数につけようとする場合は、関数名や変数名が適切かまず疑う
- コードを読んでわかるコメントはしない
- 定数の背景がわかるようなコメントをつける
- コードの実際の処理がわからない箇所にコメントをつける
- 適切にアノテーションコメントを利用する
3-15. コードフォーマットで綺麗に
フォーマットを意識することも大切です。
フォーマットが汚いとコードが読みにくくなるので可読性が低下します。
またバグやエラーの発見が難しくなったり、メンテナンスが困難になったりします。
フォーマットの方法には明確なルールというものがないのですが、一般的に多くの人が見やすいフォーマットというものがあります。
早速サンプルコードで確認してみましょう。
❌ NG
def calculate_area(length,width):return length*width # 計算を一行で行っている
def printArea(area):print('Area:',area) # スペースの不足
length,width=10,5# 変数宣言が不明瞭
area=calculate_area(width,length) # 宣言された変数と引数の順番が一致していない
if area>0:printArea(area)
else:print("Invalid dimensions") # if文が読みにくい
# 出力
Area: 50
一目見ただけでも嫌悪感を抱くレベルのフォーマットです。サンプルコードの問題点を以下に示します。
- 関数が1行でまとめられている
- 改行がされていない(ブロックに分けられていない)
- シングルクォーテーション(
')とダブルクォーテーション(")の混同 - 変数宣言が不明瞭
- 変数宣言と引数の順番が一致していない
- 適切なスペースがない
- if文が読みにくい
このサンプルコードだけでも、指摘するポイントがたくさんあります。
フォーマットが揃っていないと読み手にとって上記が負担になってしまいます。
それではサンプルコードを修正してみましょう。
⭕ GOOD
def calculate_area(length, width):
return length * width
def print_area(area):
print("Area:", area)
length = 10
width = 5
area = calculate_area(length, width)
if area > 0:
print_area(area)
else:
print("Invalid dimensions")
# 出力
Area: 50
修正前と比べて非常に読みやすくなっています。
適切な改行やスペースを入れる、ブロックに分けるなどのフォーマットは読み手の負担を一気に減らしてくれます。
この他にもフォーマットに関するポイントはいくつかあるのですが、フォーマットは言語によっても異なる点があります。
この記事はPythonでコードを記載しているので、その他のPythonのフォーマットに関するスタイルガイドを確認してみてください。
このトピックのまとめ
フォーマットのポイント
- フォーマットが綺麗でないと可読性が落ちる
- 改行やスペースを適切に入れる
- 無理に1行にまとめない
- 宣言された変数と関数の引数の順番を一致させる
- 記号を混同させない
3-16. マジックナンバーを避ける
まずは以下のコードを見てください。
expiration = time.time() + 604800
expirationは期限という意味です。
time.time()で現在時刻を取得するのはわかりますが、604800は何を意味しているのでしょうか。
このコードを書いた本人ならば数値の意味がわかるかもしれませんが、他の人がコードを読んだ時は理解できないと思います。
実は604800は1週間の秒数を表しています。(60秒 * 60分 * 24時間 * 7日 = 604800秒)
つまり先ほどのコードは、「期限は現在時刻から1週間後」を表しています。
しかしながら、これを直感的に理解できる人はほとんどいないと思います。
このようにソースコードに直接記載された、本人しかわからない数値のことを マジックナンバー といいます。
マジックナンバーがあることでコードの可読性を下げてしまいます。
マジックナンバーを使わないで上記コードを書く場合は定数を使います。定数は大文字で表記された、内容が変更されない変数のことを言います。
先程のコードを定数を使って書き換えてみます。
SECOND_PER_MINUTE = 60
MINUTE_PER_HOUR = 60 * SECOND_PER_MINUTE
HOUR_PER_DAY = 24 * MINUTE_PER_HOUR
SECONDS_PER _WEEK = 7 * HOUR_PER_DAY
expiration = time.time() + SECONDS_PER_WEEK
いかがでしょうか。
行数こそ増えてしまったものの、expirationが何を意味しているか定数(SECONDS_PER_WEEK)から理解しやすくなったと思います。
このように、コードの中でマジックナンバーが出てきたら定数を設けてみましょう。
マジックナンバーという名前からハードコード(コードに直接記載)された数値とイメージされると思いますが、文字列の場合も同様になります。
このトピックのまとめ
マジックナンバーのポイント
- マジックナンバーは他の人にとって読みにくい(理解されにくい)
- マジックナンバーは適切な名前の定数に代入する
3-17. オブジェクト指向プログラミング
プログラミングにおいてオブジェクト指向は非常に重要な考え方(概念)です。
これは何かの決まったルールや規則ではなく、プログラミングを効率よくするための考え方です。
オブジェクト指向については詳しい記事や本がたくさんありますので、ここでは詳細をお伝えすることはしません。
オブジェクト指向の基本的な考え方の部分を紹介したいと思います。
そもそも「オブジェクト」って何?って思う方がいらっしゃると思うので、オブジェクトについてお伝えします。
オブジェクトとは直訳すると「物体」という意味ですが、文脈(環境や状況)によってその意味は異なります。
wikipediaによると以下のような説明となっています。
コンピュータ科学の分野において、オブジェクト(英語: object)は、変数、データ構造、関数、メソッドなど、識別子によって参照されるメモリ上の値を意味することがある。
オブジェクト指向プログラミングのパラダイムでは、オブジェクトは変数、関数、データ構造を組み合わせたものを意味することがある。特に、クラスベースのオブジェクト指向プログラミングのパラダイムでは、特に、クラスのインスタンスを指す。
今回は、オブジェクト指向でのオブジェクトということなので後者の意味、
特に、クラスベースのオブジェクト指向プログラミングのパラダイムでは、特に、クラスのインスタンスを指す。
の意味になります。
そうなると、次に疑問に思うのは「クラス」と「インスタンス」とは何か、ということですね。
よく言われるのが、クラスは設計書、インスタンスはクラス(設計書)から作られる具体的な物体(オブジェクト)ということです。
上記を図にすると以下のようになります。
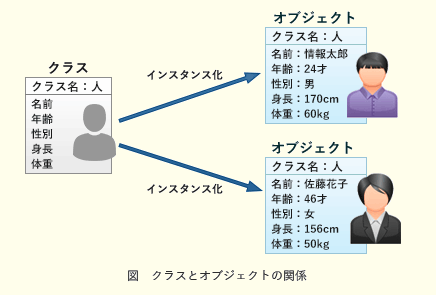
(こちらの記事より引用させていただいております。)
この図は個人をオブジェクトとしており、個人を定義するための人というカテゴリの設計書(雛形、テンプレート)をクラスとしています。
もう少し具体的にみていきましょう。
例えばゲームを開発しているとしましょう。このゲームの中で登場する生物が「ヒト」「犬」だったとします。
もちろん、それぞれの生物にはさらに個体に細分化されたキャラクターがいます。
ヒトならば「タケシ」や「ヒトミ」といった個人、犬ならば「ポチ」や「ロドリゲス」といった個体です。
ヒトのキャラクターを表すためには「名前」「性別」「年齢」「職業」「年収」「趣味」などがあると思います。
一方、犬のキャラクターを表すためには「名前」「性別」「年齢」「犬種」「好きなエサ」などが考えられます。
これらに具体的なデータ(名前ならタケシ、性別なら男等)を定義してキャラクターになりますね。
次にキャラクターのとる動作(振る舞い)についてみていきましょう。
キャラクターの取れる動作は生物ごとに決まっています。
ヒトなら「挨拶をする」や「告白する」、犬なら「鳴く」のような振る舞いをとります。
よって、タケシやヒトミは「挨拶をする」「告白する」振る舞いを持っており、ポチやロドリゲスは「鳴く」振る舞いを持っています。
このように、キャラクターを決定するための「名前」や「性別」の変数をメンバ変数といい、具体的な値のことを属性と言います。
またキャラクターの「挨拶をする」「鳴く」のような振る舞いのことを操作といいます。
そして属性や操作によってそれぞれのキャラクターが確定していきます。
それでは、それぞれのキャラクターのメンバ変数(名前や性別など)の属性(タケシや男など)と操作(挨拶するなど)を具体的に決定してみましょう。
(ヒト)
名前 : タケシ
性別 : 男
年齢 : 47
職業 : 経営者
年収 : 2,000万円
趣味 : バードウォッチング
挨拶をする
告白をする
名前 : ヒトミ
性別 : 女
年齢 : 38
職業 : 看護師
年収 : 600万円
趣味 : 料理
挨拶をする
告白をする
(犬)
名前 : ポチ
性別 : オス
年齢 : 5
犬種 : 芝犬
好きな餌 : 骨
鳴く
名前 : ロドリゲス
性別 : メス
年齢 : 3
犬種 : パグ
好きな餌 : チュール
鳴く
このように、メンバ変数に属性を設定し、それぞれに「挨拶する」や「鳴く」などの操作(振る舞い)を持たせることで個人・個体が決定しました。
この例でいうとメンバ変数や操作(振る舞い)をまとめているのがクラスであり、クラスから作られたキャラクターがインスタンス(オブジェクト)になります。
上記についてはサンプルコードで見てみましょう。(コードの__init__などの詳細については説明しません。)
class Human:
def __init__(self, name: str, sex: str, age: int, job: str, annual_income: int, hobby: str):
self.name = name
self.sex = sex
self.age = age
self.job = job
self.annual_income = annual_income
self.hobby = hobby
def greet(self):
print("Hello")
def confess(self):
print("I love you")
class Dog:
def __init__(self, name: str, sex: str, age: int, type: str, favorite_food: str):
self.name = name
self.sex = sex
self.age = age
self.type = type
self.favorite_food = favorite_food
def bark(self):
print("Bow Bow")
Takeshi = Human("タケシ", "male", 47, "executive", 2000, "bird_watching")
Hitomi = Human("ヒトミ", "female", 38, "nurse", 600, "cooking")
Pochi = Dog("Pochi", "male", 5, "Shiba", "bone")
Rodriguez = Dog("Rodriguez", "female", 3, "Pug", "Churu")
Takeshi.greet()
# 出力
Hello
Takeshi.confess()
# 出力
I love you
class Humanと class Dogがメンバ変数と操作(振る舞い)をまとめているクラス(設計書)であり、その設計書に属性(具体的なデータ)を与えて作られたタケシやポチなどのキャラクターがインスタンス(オブジェクト)になります。
またクラスの中に書かれている操作(振る舞い)の関数のことをメソッドと呼びます。
クラスとインスタンスの関係が何となく理解できたでしょうか。
そもそも、なぜクラスを定義してインスタンスを作るのでしょうか?
別にクラスが無くても今回のタケシやポチは作れると思っていませんか?
クラスがないとオブジェクトは作ることはできませんが、結果としてデータや振る舞いを実装することはできます。
クラスを用いない場合のサンプルコードを見てみましょう。
import copy
def select_dict(animal_type: str) -> dict:
if animal_type == "human":
dict = {
"animal_type": "human",
"name": "Default Taro",
"sex": "Default male",
"age": "Default 20",
"job": "Default no_job",
"annual_income": "Default 100",
"hobby": "Default no_hobby",
"greet": True,
"confess": True
}
elif animal_type == "dog":
dict = {
"animal_type": "dog",
"name": "Default Pochi",
"sex": "Default male",
"age": "Default 1",
"type": "Default hybrid",
"favorite_food": "Default dog_food",
"bark": True
}
return dict
def act(object: dict) -> str:
if object["animal_type"] == "human":
if object["greet"] == True:
print("Hello")
if object["confess"] == True:
print("I love you")
elif object["animal_type"] == "dog":
if object["bark"] == True:
print("Bow Bow")
return
human = select_dict("human")
Takeshi = human.copy()
Takeshi = {
"animal_type": "human",
"name": "Takeshi",
"sex": "male",
"age": 47,
"job": "executive",
"annual_income": 2000,
"hobby": "bird_watching",
"greet": True,
"confess": True
}
act(Takeshi)
# 出力
Hello
I love you
サンプルコードを順番にみていきましょう。
select_dictでは引数のanimal_typeで返す辞書を選択しています。返り値の辞書にはデフォルトの値が設定されています。
actではobjectという辞書型の引数を受け取り、その後条件分岐で動作(振る舞い)を決定しています。
変数humanにはselect_dictのデフォルトの値を持った辞書が代入されています。
その後Takeshiにコピーされたhumanを代入しています。
Takeshiの辞書のvalueはまだデフォルト値なので、Takeshi用に上書きしています。
そしてactの引数にTakeshiを渡して動作(振る舞い)を実行しています。
この動作(振る舞い)はTakeshiのgreetとconfessのbool値で決定されています。
これらがTrueならば動作を実行し、Falseならば実行しません。
動作(振る舞い)を制御するために、ここのbool値を都度変更する必要があります。
ここまでがクラスを使わなかった場合のサンプルコードになります。
見ていただいてわかるように、非常に読みにくいコードですよね。
一方クラスを使用した方がパッと見てわかりやすいコードになっています。
このようにクラスに属性や操作(振る舞い)をまとめて、インタンスを作成するコードは読み手にとってもわかりやすいです。
またクラスとオブジェクトに分離することで責任が明確になり、修正や変更がしやすくなります。
冒頭でも述べましたが、オブジェクト指向とは規則やルールではなくプログラミンの重要な考え方(概念)ということを覚えておいてください。
次からはオブジェクト指向の重要な三原則を紹介します。
継承
継承とは、あるクラスをもとに新しいクラスを作っていく考え方のことです。
3-12. 重複コードは避けるでもお伝えしたように同じようなコードがあると可読性が低くなり、またメンテナンスもしにくくなります。
これも具体例で確認していきましょう。
今度はRPGのゲームで見ていきます。
このゲームのキャラクターには戦士や魔法使いなどの「職業」が設定され、職業ごとの特殊スキルを発動できます。
また職業ごとに装備できるアイテムが異なります。
一方で全てのキャラクターには「名前」「level」「HP」「MP」の共通のパラメーターがあります。
ここでキャラクターとして「戦士のガッツ」、「魔法使いのシールケ」が登場するとしましょう。
先程のクラスを用いたサンプルコードを参考にすると以下のようになると思います。
class Warrior:
def __init__(self, name: str, level: int, HP: int, MP: int, sword: str, armor: str, shield: str):
self.name = name
self.level = level
self.HP = HP
self.MP = MP
self.sword = sword
self.armor = armor
self.shield = shield
def special_attack(self):
print("Enemy died")
class Wizard:
def __init__(self, name: str, level: int, HP: int, MP: int, wand: str, robe: str):
self.name = name
self.level = level
self.HP = HP
self.MP = MP
self.wand = wand
self.robe = robe
def magic(self):
print("Heal allies")
Guts = Warrior("Guts", 100, 999, 50, "Dragon Slayer", "Berserk armor", "Huge Shield")
Schierke = Wizard("Schierke", 50, 600, 999, "Wizards wand", "Wizard's robe")
print(Guts.name)
print(Guts.level)
print(Guts.sword)
Guts.special_attack()
print("--------------")
print(Schierke.name)
print(Schierke.level)
print(Schierke.wand)
Schierke.magic()
# 出力
Guts
100
Dragon Slayer
Enemy died
--------------
Schierke
50
Wizards wand
Heal allies
コードを見るとWarrior(戦士)ではsword, armor, shield のメンバ変数があります。
一方、Wizard(魔法使い)にはwand, robe のメンバ変数があります。
またそれぞれのクラスの操作(振る舞い)は戦士だとspecial_attackですが、魔法使いだとmagicになっています。
しかし、それ以外(name, level, HP, MP)は共通していることがわかります。
この共通したメンバ変数を1つにまとめることが可能そうですね。
またWarriorクラスとWizardクラスには「たたかう」操作がありません。
この操作も合わせて追加してみましょう。
class Human:
def __init__(self, name: str, level: int, HP: int, MP: int):
self.name = name
self.level = level
self.HP = HP
self.MP = MP
def attack(self):
print("Attack Enemy")
class Warrior(Human):
def __init__(self, name: str, level: int, HP: int, MP: int, sword: str, armor: str, shield: str):
super().__init__(name, level, HP, MP)
self.sword = sword
self.armor = armor
self.shield = shield
def special_attack(self):
print("Enemy died")
class Wizard(Human):
def __init__(self, name: str, level: int, HP: int, MP: int, wand: str, robe: str):
super().__init__(name, level, HP, MP)
self.wand = wand
self.robe = robe
def magic(self):
print("Heal allies")
Guts = Warrior("Guts", 100, 999, 50, "Dragon Slayer", "Berserk armor", "Huge Shield")
Schierke = Wizard("Schierke", 50, 600, 999, "Wizards wand", "Wizard's robe")
print(Guts.name)
print(Guts.level)
print(Guts.sword)
Guts.attack()
print("--------------")
print(Schierke.name)
print(Schierke.level)
print(Schierke.wand)
Schierke.attack()
# 出力
Guts
100
Dragon Slayer
Attack Enemy
--------------
Schierke
50
Wizards wand
Attack Enemy
新しくclass Humanというクラスを作成し、これにメンバ変数name, level, HP, MPとattackメソッドを持たせています。
そして、class Warriorとclass Wizardの引数にHumanクラスを渡しています。
この時Humanを親クラスといい、WarriorクラスとWizardクラスを子クラスといいます。
親クラスは基底クラスやスーパークラス、子クラスは派生クラスやサブクラスと言われることもあります。
その後super()で親クラス(Human)のメンバ変数とメソッドを子クラス(Warrior、Wizard)が引き継ぐことを定義しています。
そして装備できるアイテム(メンバ変数)と特殊スキル(メソッド)は子クラス別で異なるので、個別で定義しています。
あとは先程のサンプルコードと一緒です。
このように共通コードを1つのクラスにまとめて、そのクラスを利用して新しいクラスを作成する考え方のことを継承と言います。
継承を利用すると、親クラスから派生する子クラスを簡単に作成することができます。
例えば新しく盗賊や忍者などの職業を作ろうとしたとき、親クラスから派生して作れば、共通したメンバ変数やメソッドを職業別に定義する必要がなくなります。
また共通した箇所に修正や変更を加える時も親クラスだけに手を加えるだけで良くなります。
カプセル化
カプセル化とは、プログラムが他のプログラムの影響を受けないようにする考えのことです。具体的にはカプセル化された中身が外部から確認されない、変更できないことです。
カプセル化についてサンプルコードで見てみましょう。
先程のゲームの例から一部引用します。
最初はカプセル化がされていないパターンです。
# カプセル化がされていない
class Human:
def __init__(self, name: str, level: int, HP: int, MP: int):
self.name = name
self.level = level
self.HP = HP
self.MP = MP
def attack(self):
print("Attack Enemy")
class Warrior(Human):
def __init__(self, name: str, level: int, HP: int, MP: int, sword: str, armor: str, shield: str):
super().__init__(name, level, HP, MP)
self.sword = sword
self.armor = armor
self.shield = shield
def special_attack(self):
print("Enemy died")
Guts = Warrior("Guts", 100, 999, 50, "Dragon Slayer", "Berserk armor", "Huge Shield")
print(Guts.sword)
# 出力
Dragon Slayer
Guts.sword = "Wood stick"
print(Guts.sword)
# 出力
Wood stick
上記はHumanクラスから派生したWarriorクラスによってGutsインスタンスを最初に作っています。
この時、weaponはDragon Slayerで定義されていたのですがGuts.sword = "Wood stick"でWood stick で変更されております。
このようにインスタンスの属性が変わってしまう状態はカプセル化がされていないと言います。
カプセル化がされていないと、意図しないところでインスタンスの属性が変更され、バグやエラーの原因となってしまいます。
これを防ぐためにカプセル化をした状態のサンプルコードを見てみましょう。
# カプセル化がされている
class Human:
def __init__(self, name: str, level: int, HP: int, MP: int):
self.name = name
self.level = level
self.HP = HP
self.MP = MP
def attack(self):
print("Attack Enemy")
class Warrior(Human):
def __init__(self, name: str, level: int, HP: int, MP: int, sword: str, armor: str, shield: str):
super().__init__(name, level, HP, MP)
self.__sword = sword
self.__armor = armor
self.__shield = shield
def special_attack(self):
print("Enemy died")
Guts = Warrior("Guts", 100, 999, 50, "Dragon Slayer", "Berserk armor", "Huge Shield")
print(Guts.sword)
# 出力
AttributeError: 'Warrior' object has no attribute 'sword'
変更箇所はWarriorクラスのメンバ変数にダブルアンダースコア(__)をつけていることです。
これでprint(Guts.sword)でswordを呼び出そうとすると AttributeError(属性エラー)となってしまいました。
メッセージを見るとWarriorクラスにはswordの属性がないよと言われています。
ここでちょっと待てよと思う方がいるかもしれません。
Gutsインスタンスを作った時にswordも定義してるから、そのエラーはおかしいんじゃないかと。
それではGutsインスタンスが持っている属性とメソッドを確認してみましょう。
print(dir(Guts))
# 出力
['HP', 'MP', '_Warrior__armor', '_Warrior__shield', '_Warrior__sword', '__class__',
'__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__',
'__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__',
'__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__',
'__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__',
'__subclasshook__', '__weakref__', 'level', 'name', 'special_attack']
よく見ると_Warrior__swordが確認できますね。
今回のエラーは、正確にはWarriorクラスのswordはあるが、情報を取得できない(Getできない)ということだったのです。
完全にプライベートなものとなってしまったというわけです。
それでは、swordの中身を確認してみましょう。
class Human:
def __init__(self, name: str, level: int, HP: int, MP: int):
self.name = name
self.level = level
self.HP = HP
self.MP = MP
def attack(self):
print("Attack Enemy")
class Warrior(Human):
def __init__(self, name: str, level: int, HP: int, MP: int, sword: str, armor: str, shield: str):
super().__init__(name, level, HP, MP)
self.__sword = sword
self.__armor = armor
self.__shield = shield
@property
def sword(self):
return self.__sword
def special_attack(self):
print("Enemy died")
Guts = Warrior("Guts", 100, 999, 50, "Dragon Slayer", "Berserk armor", "Huge Shield")
print(Guts.sword)
# 出力
Dragon Slayer
今度は出力されましたね。
先程からの変更点は@propertyがついたswordメソッドを追加したことです。
@propertyはデコレーターというのですが、ここでは詳細を説明しません。
こちらの記事にカプセル化の際のデコレーターの使い方が書かれていますので、確認してみてください。
@property(デコレーター)をつけることでプライベートであったswordの中身を確認することができました。
それではswordの中身を変更することはできるのか、確認してみましょう。
class Human:
def __init__(self, name: str, level: int, HP: int, MP: int):
self.name = name
self.level = level
self.HP = HP
self.MP = MP
def attack(self):
print("Attack Enemy")
class Warrior(Human):
def __init__(self, name: str, level: int, HP: int, MP: int, sword: str, armor: str, shield: str):
super().__init__(name, level, HP, MP)
self.__sword = sword
self.__armor = armor
self.__shield = shield
@property
def sword(self):
return self.__sword
def special_attack(self):
print("Enemy died")
Guts = Warrior("Guts", 100, 999, 50, "Dragon Slayer", "Berserk armor", "Huge Shield")
print(Guts.sword)
Guts.sword = "Wood stick"
# 出力
AttributeError: property 'sword' of 'Warrior' object has no setter
今回もAttributeError(属性エラー)となってしまいました。
しかしメッセージの中身を見ると、setterが無いよと言われています。
実は最初のswordの中身を見ようとして起きたエラーはgetterというものが関係しており、@property(デコレーター)箇所がgetterの役割を果たしていました。
今回のswordの中身を変更しようとした時のエラーはsetterというものが関係しており、setterの役割を果たすコードがない状態です。
これらの役割を端的に言ってしまうとgetterは属性を取得する、setterは属性を変更するためのものです。
プライベートになった属性は、getterやsetterがないとアクセスすることができないことが確認できました。
ここでもう一度カプセル化について振り返りましょう。
カプセル化とは、プログラムが他のプログラムの影響を受けないようにする考えのことです。具体的はカプセル化された中身が外部から確認されない、変更できないことです。
今回はカプセル化の例として、Warriorクラスのメンバ変数をプライベートにしました。
ただ、中身を確認できなかったため@property(デコレーター)でメンバ変数の中身を見れるようにしました。
しかし、そもそもカプセル化とは中身が見えることも避けたいのです。
getterで情報が見えてしまうということは、インスタンスに機密情報を持たせるようにした際に、場合によっては見られるてしまうことになります。
カプセル化を徹底するためにはsetterもgetterも設定してはいけません。
(もちろん、サービスやアプリケーションの仕様によっては避けられないこともありますが)
ポリモーフィズム
ポリモーフィズムとは、同じ名前のメソッドが異なるクラスやオブジェクトで、それぞれの振る舞いを持つことを意味します。
先ほどまでのサンプルコードでは戦士と魔法使いには「たたかう」という振る舞いがありましたが、攻撃内容が同じになっていました。
ここで、戦士と魔法使いで攻撃の内容を分けたい場合のことを考えましょう。
戦士は「剣で攻撃」、魔法使いは「杖で攻撃」といった具合です。
これを実現するためのコードを見てみましょう。
class Human:
def __init__(self, name: str, level: int, HP: int, MP: int):
self.name = name
self.level = level
self.HP = HP
self.MP = MP
def attack(self):
print("Attack Enemy")
class Warrior(Human):
def __init__(self, name: str, level: int, HP: int, MP: int, sword: str, armor: str, shield: str):
super().__init__(name, level, HP, MP)
self.sword = sword
self.armor = armor
self.shield = shield
def special_attack(self):
print("Enemy died")
def attack(self):
print(f"Attack Enemy with {self.sword}")
class Wizard(Human):
def __init__(self, name: str, level: int, HP: int, MP: int, wand: str, robe: str):
super().__init__(name, level, HP, MP)
self.wand = wand
self.robe = robe
def magic(self):
print("Heal allies")
def attack(self):
print(f"Attack Enemy with {self.wand}")
Guts = Warrior("Guts", 100, 999, 50, "Dragon Slayer", "Berserk armor", "Huge Shield")
Schierke = Wizard("Schierke", 50, 600, 999, "Wizards wand", "Wizard's robe")
Guts.attack()
Schierke.attack()
# 出力
Attack Enemy with Dragon Slayer
Schierke.attack()
# 出力
Attack Enemy with Wizards wand
WarriorクラスとWizardクラスにattackメソッドを追加し、attackメソッドを呼ぶと、それぞれの武器で敵に攻撃するようになっています。
実際にはHumanクラスから継承したattackメソッドをそれぞれのクラスで処理内容を上書きしています。
このように他のクラスから継承したメソッドの内容を上書きすることをオーバーライドと言います。
ポリモーフィズムを実現するために、必ずしも継承しオーバーライドをする必要はありません。
ポリモーフィズムは、同じメソッド名が異なるクラスでそれぞれの振る舞いを持つ考え方のことです。
つまり、次のサンプルコードのように継承を用いない場合でも、ポリモーフィズムが成り立っていることになります。
class Human:
def __init__(self, name: str, level: int, HP: int, MP: int):
self.name = name
self.level = level
self.HP = HP
self.MP = MP
class Warrior(Human):
def __init__(self, name: str, level: int, HP: int, MP: int, sword: str, armor: str, shield: str):
super().__init__(name, level, HP, MP)
self.sword = sword
self.armor = armor
self.shield = shield
def special_attack(self):
print("Enemy died")
def attack(self):
print(f"Attack Enemy with {self.sword}")
class Wizard(Human):
def __init__(self, name: str, level: int, HP: int, MP: int, wand: str, robe: str):
super().__init__(name, level, HP, MP)
self.wand = wand
self.robe = robe
def magic(self):
print("Heal allies")
def attack(self):
print(f"Attack Enemy with {self.wand}")
Guts = Warrior("Guts", 100, 999, 50, "Dragon Slayer", "Berserk armor", "Huge Shield")
Schierke = Wizard("Schierke", 50, 600, 999, "Wizards wand", "Wizard's robe")
Guts.attack()
# 出力
Dragon Slayerで敵に攻撃
Schierke.attack()
# 出力
Wizards wandで敵に攻撃
Humanクラスからattackメソッドを削除しました。
これにより、子クラスへの継承はメンバ変数のみ(name, level, HP, MP)になりました。
WarriorクラスとWizardクラスそれぞれでattackメソッドを定義しています。
この場合もポリモーフィズムの考えが実現できていることになります。
他の記事では継承してオーバーライドしたり、抽象クラスというものを準備するようなことが書かれていますが、どれもポリモーフィズムを実現するための1つの手段でしかなく、必須というわけではありません。
もう一度言いますが、ポリモーフィズムとは同じ名前のメソッドが異なるクラスやオブジェクトでそれぞれの振る舞いを持つことです。
このサンプルだとポリモーフィズムのメリットがなんなのかよく理解できないと思いますので、もう一つポリモーフィズムを実現するための一例をお伝えしようと思います。
その前に抽象クラスというものを紹介します。
抽象クラスとは少なくも1つの抽象メソッドを持ったクラスのことを言います。
抽象メソッドとは具体的な処理を持たないメソッドのことを言います。
サンプルコードで確認していきましょう。
from abc import ABCMeta, abstractmethod
class Human(metaclass=ABCMeta):
def __init__(self, name: str, level: int, HP: str, MP: str):
self.name = name
self.level = level
self.HP = HP
self.MP = MP
@abstractmethod
def attack(self):
pass
class Warrior(Human):
def __init__(self, name: str, level: int, HP: int, MP: int, sword: str, armor: str, shield: str):
super().__init__(name, level, HP, MP)
self.sword = sword
self.armor = armor
self.shield = shield
def special_attack(self):
print("Enemy died")
def attack(self):
print(f"Attack Enemy with {self.sword}")
class Wizard(Human):
def __init__(self, name: str, level: int, HP: int, MP: int, wand: str, robe: str):
super().__init__(name, level, HP, MP)
self.wand = wand
self.robe = robe
def magic(self):
print("Heal allies")
def attack(self):
print(f"Attack Enemy with {self.wand}")
Guts = Warrior("Guts", 100, 999, 50, "Dragon Slayer", "Berserk armor", "Huge Shield")
Schierke = Wizard("Schierke", 50, 600, 999, "Wizards wand", "Wizard's robe")
Guts.attack()
# 出力
Dragon Slayerで敵に攻撃
Schierke.attack()
# 出力
Wizards wandで敵に攻撃
まず、from abc import ABCMeta, abstractmethodで抽象クラスのためのモジュールをインポートしています。
その後、Humanクラスの引数にABCMetaを渡してあげています。
こうすることによってHumanクラスが抽象クラスであることを定義しています。
Humanクラスの中身を見ると@abstractmethodというデコレーターがついたattackメソッドが定義されています。
attackメソッドの中身はpassによって何もしないことになっています。
このattackが抽象メソッドになります。
あとは先ほどまでと同様に`Warrior `クラスとWizardクラスがHumanクラスを継承して、attackメソッドをオーバーライドしています。
それでは、Wizardクラスでattackメソッドを宣言しなかった場合どうなるかみてみましょう。
# Wizardクラスでattackを宣言しなかった場合
from abc import ABCMeta, abstractmethod
class Human(metaclass=ABCMeta):
def __init__(self, name: str, level: int, HP: int, MP: int):
self.name = name
self.level = level
self.HP = HP
self.MP = MP
@abstractmethod
def attack(self):
pass
class Warrior(Human):
def __init__(self, name: str, level: int, HP: int, MP: int, sword: str, armor: str, shield: str):
super().__init__(name, level, HP, MP)
self.sword = sword
self.armor = armor
self.shield = shield
def special_attack(self):
print("Enemy died")
def attack(self):
print(f"Attack Enemy with {self.sword}")
class Wizard(Human):
def __init__(self, name: str, level: int, HP: int, MP: int, wand: str, robe: str):
super().__init__(name, level, HP, MP)
self.wand = wand
self.robe = robe
def magic(self):
print("Heal allies")
Guts = Warrior("Guts", 100, 999, 50, "Dragon Slayer", "Berserk armor", "Huge Shield")
Schierke = Wizard("Schierke", 50, 600, 999, "Wizards wand", "Wizard's robe")
Guts.attack()
Schierke.attack()
# 出力
AttributeError: 'Wizard' object has no attribute 'attack'
AttributeErrorでattackメソッドがないと言われています。
このように抽象クラスと抽象メソッドを設定してあげると、抽象クラスから作られる子クラスは抽象メソッドを強制的に持たなければならなくなります。
抽象クラスを定義しなくてもポリモーフィズムは実現できますが、プログラムが複雑になってくると共通な振る舞いを持つメソッドの定義漏れが発生することが考えられます。
そうなるとバグやエラーの原因につながります。
抽象クラスを定義してあげることでポリモーフィズムの実現をより堅固なものにすることができます。
以上がオブジェクト指向の3原則(継承・カプセル化・ポリモーフィズム)です。
なお、オブジェクト指向についてはこちらの記事でとても詳しく書かれていましたので、ぜひ確認してみてください。
このトピックのまとめ
オブジェクト指向のポイント
- オブジェクト指向はプログラミングを効率よく行うための考え方(概念)である
- オブジェクト試行の3原則は継承・カプセル化・ポリモーフィズム
- 継承は親クラスから子クラスへメンバ変数とメソッドを渡す
- カプセル化は外のプログラムからの情報の取得や変更をさせない
- ポリモーフィズムは異なるクラスで共通のメソッド名が異なる処理をする
3-18. デザインパターンとは
オブジェクト指向で、継承・カプセル化・ポリモーフィズムについてお伝えしました。
その際に具体的な例を用いて修正や変更を加えていましたが、より効果的なクラスの設計を教えてくれるのがデザインパターンです。
デザインパターンはthe Gang of Fourと呼ばれる4人の開発者が提案した、オブジェクト指向開発における23個の再利用性の高い設計のことを言います。
この23パターンは、過去に問題に直面した際、より効果的に解決するために生み出されたパターンでありオブジェクト指向開発の設計指針と言われています。
ただし最近では各プログラミング言語のフレームワークでの開発が主流になってきており、フレームワークがよしなに設計してくれるため、個人がデザインパターンを意識して開発する機会が少なくなってきています。
その結果、デザインパターンを知らない人も開発することが可能となってきており、このような人がいる中でデザインパターンを適用したせいで、逆に可読性が落ちるといったこともあるそうです。
このような経緯からデザインパターンを知っておけば開発が効率良くなる場合もあるといったものなので、ここでは詳細については触れないでおきたいと思います。
なおデザインパターンについてはこちらの記事に詳細が書かれていますので、気になる方は確認してみてください。
3-19. ディレクトリの構成の重要性
ディレクトリの構成もプログラミングにおいて大切です。
練習用のプロジェクトでディレクトリを作る程度なら問題ないでしょうが、実務においてディレクトリ構成を軽視するとプロジェクトの全体像を把握できなくなるだけでなく、チームの人もどこにどんなファイルがあるのかわからなくなり、迷惑をかけることになります。
例えば以下のようなデレクトリ構成があったとします。
my_project/
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── com/
│ │ │ │ ├── myapp/
│ │ │ │ │ ├── App.java
│ │ ├── resources/
│ │ │ ├── config.properties
├── test/
│ ├── java/
│ │ ├── com/
│ │ │ ├── myapp/
│ │ │ │ ├── AppTest.java
├── build.gradle
├── README.md
このディレクトリ構成が必ずしも正しいわけではないのですが、少なくともどこにどのようなファイルがあるかが把握しやすいと思いませんか?
例えばsrcディレクトリ配下にはプロジェクトの実態に関するコードが置かれていることがわかり、testディレクトリ配下ではテストに関するコードが置かれていることがわかります。
また、プロジェクトの全体像の資料であるREADME.mdがmy_project直下においてありますが、一般的にREADME.md はプロジェクト全体に関することが記載されているので、このファイルの配置の仕方も理にかなっています。
仮にtestディレクトリがcomディレクトリ配下にあった時に、testとcomの関係性がよくわからないので、ファイルを探すのに時間がかかってしまうでしょう。
このようにディレクトリ構成を不適切に設定すると、全体像を把握することが難しくなってしまいます。
プロジェクトに参加し始めは、まずディレクトリの構成を見て全体像の把握するようにしましょう。
そうすることによって、修正や変更が必要なファイルを探す時間を省くことができます。
少し本題とずれてはしまうのですが、適当なファイル名やディレクトリ名も全体の見通しを悪くさせてしまいます。
ディレクトリはどのようなファイルをまとめているのかを一目見てわかる名前にしたほうが良いです。
同様にファイル名もどのようなコードを含んでいるのかがわかる名前にしたほうが良いです。
変数名や関数名をつけるときと同様、慎適切な名前をつけるようにしましょう。
このトピックのまとめ
ディレクトリの構成のポイント
- ディレクトリ構成で全体像を把握する
- ディレクトリを作るときは適切なディレクトリ構成をつくる
- ディレクトリ名とファイル名は適切な名前をつける
3-20. 既存コードを見る(ルールを知る)
コードが全くない状態からコードを書き始めるときは気にしなくても良いかもしれませんが、すでにコードがある状態(例えば、途中からプロジェクトに参加した場合など)では既存のコードをよく見るようにしましょう。
すでに何かしらのルールに則ってコードを書いている可能性が大きいです。
既存コードのルールを知ることには以下のようなメリットがあります。
- コードの一貫性を保つ
既存コードのルールを理解することで、コード全体で一貫性のあるスタイルや規則を維持できます。これによりコードが読みやすく、他の開発者との協力が円滑になります。
- バグの早期発見
既存コードのルールを理解することで、潜在的な問題やバグを早期に発見しやすくなります。あなたがルールを徹底していても、他の開発者がルールを破っている可能性があります。このような時にルールから外れたコードを見つけることが可能になり、将来的にバグとなる可能性をなくすことができます。
- コードの効率的な変更
既存コードのルールを知ることは、コードの変更やアップデートを行う際に役立ちます。ルールに則った変更を行うことで、リスクの低い変更や、作業期間を短くすることが可能になります。
- プロジェクトへの適応
新しいプロジェクトやチームに参加する際、既存コードのルールを理解することは、プロジェクトに適応するのに役立ちます。適切なスタイルガイドやコーディング慣行を守ることで、プロジェクトへの適応がスムーズになります。
- ベストプラクティスの学習
既存コードは、ベストプラクティスや設計パターンの実例となる可能性があります。あなたが知らない、他の開発者が採用したアプローチを学び、自身のスキルを向上させるのに非常に役立ちます。
- メンテナンスの容易化
既存コードのルールに則ってコードを記述することで、将来のメンテナンスが容易になります。誰でも理解しやすいコードを書くことで、バグの修正や新機能の追加がスムーズに行えます。
このように既存コードのルールを知ることはフォーマットを揃えることにもなり、最終的には可読性を高めることにつながります。
あなたの独自ルールをコードに落とし込んでしまい、他の人にとって読みにくいコードとならないためにも既存コードをよく見るようにしましょう。
このトピックのまとめ
既存のコードを知ることのポイント
- コードの一貫性を保つ、バグを未然に防ぐ、プロジェクトへ適用する、新しい知見を得る等のために既存コードのルールを知るようにする
4. よく使われる英単語一覧(全759語)
この章ではプログラミングでよく使われる英単語を品詞別で紹介したいと思います。
敢えてこの章を設けているのには理由があります。
それはプログラミングであまり使用されていない英単語を利用すると可読性が下がるからです。
具体例で説明してみます。
あなたがコードを書いている時に「受け入れられたユーザー」という変数名をつけようとしたとしましょう。
おそらくあなたは「受け入れられた」の英語を調べると思います。
Googleで「受け入れる」で検索をすると以下のような候補がいくつか出てくるでしょう。
- accept
- admit
- welcome
- adapt
どれも「受け入れる」という意味ですが、ニュアンスが異なっています。
プログラミングにおいてよく使われているのはacceptやadmitだと思われますが、あなたがここでwelcomeを選んでwelcomedUserと変数名をつけたらどうなるでしょうか。
他の人がこの変数を見たときに直感的に「受け入れられたユーザー」と認識できるでしょうか。
恐らくそうはならず、この変数の意味を理解するためにコードを追うことになるでしょう。
もしくはwelcomeの意味を調べてしまうかもしれません。
仮にあなたが厳密にニュアンスを理解して使い分けていたとしても、他の人がそれを理解しているとは限らず、結局可読性を下げてしまうことになります。
一方、よく使われているacceptやadmitを使えば上記のようなことは避けられるはずです。
大切なことは他の人が読んでもわかりやすいコードを書くことです。
これから紹介する英単語はプログラミングでよく使われる英単語であるため、可読性を下げること防いでくれます。
4-1. 動詞
| 英単語 | 意味 |
|---|---|
| accept | 受諾する、受け入れる |
| access | アクセスする、利用する、入手する |
| allow | 可能にする、許可する |
| apply | 適用する |
| avoid | 回避する |
| activate | 有効にする、アクティブにする |
| adjust | 調整する |
| aggregate | 集約する |
| append | 追加する |
| assert | アサートする、表明する |
| assign | 割り当てる、代入する |
| associate | 関連づける |
| attach | 接続する、添付する |
| authenticate | 認証する |
| authorize | 権限を与える |
| add | 追加する |
| agree | 同意する |
| bind | バインドする |
| boot | 起動する |
| break | 中断する |
| browse | 閲覧する、参照する |
| build | 構築する |
| bump | バージョンを上げる |
| bundle | バンドルする |
| cancel | キャンセルする、取り消す |
| clear | 消去する |
| click | クリックする |
| commit | コミットする、(処理などを)確定する |
| connect | 接続する |
| contain | 含む |
| continue | 続行する |
| control | 制御する |
| customize | カスタマイズする |
| comment | コメント/コメントする |
| calculate | 計算する |
| call | 呼び出す |
| capture | 取り込む、キャプチャーする |
| cast | キャストする |
| change | 変更する |
| check | 確認する、チェックする |
| choose | 選択する |
| clean | きれいにする |
| close | 閉じる |
| collapse | 折りたたむ、非表示にする |
| compile | コンパイルする |
| compress | 圧縮する |
| compute | 計算する |
| configure | 構成する、設定する |
| confirm | 確定する、確認する |
| conflict | 競合する |
| construct | 生成する |
| contact | 連絡する |
| contribute | 貢献する |
| convert | 変換する |
| copy | コピーする |
| correct | 訂正する |
| create | 作成する |
| clarify | 明確にする |
| clone | 複製する、クローンする |
| clean | きれいな/きれいにする |
| complete | 完了する/完全な |
| correct | 正確な/訂正する |
| debug | デバッグする |
| define | 定義する |
| delete | 削除する |
| destroy | 破棄する |
| determine | 判別する、決定する |
| download | ダウンロードする |
| declare | 宣言する |
| decode | デコードする |
| deploy | 配備する、デプロイする |
| detect | 検出する |
| disable | 無効にする |
| distribute | 分散する、配布する |
| dump | 放出する、投げ捨てる |
| duplicate | 重複する/重複 |
| describe | 説明する |
| debug | デバッグする/デバッグ |
| default | デフォルトで〜になる/デフォルト |
| display | 表示する/表示 |
| edit | 編集する |
| enable | 可能にする、有効にする |
| encode | エンコードする、符号化する |
| encounter | 遭遇する |
| enter | 入力する |
| escape | エスケープする |
| execute | 実行する |
| expand | 拡大する、展開する |
| exit | 終了する |
| exclude | 除外する |
| express | 表現する |
| emit | 発する、生成する |
| ensure | 確実にする、確かめる |
| exist | 存在する |
| extend | 拡張する |
| extract | 抽出する |
| fail | 失敗する |
| fetch | 取得する、フェッチする |
| filter | 絞り込む |
| fire | 始動する、発火する |
| fix | 修正する、解決する |
| follow | 従う、フォローする |
| force | 強制する |
| format | 初期化する、書式設定する |
| find | 検索する |
| finish | 終了する、完了する |
| generate | 生成する |
| get | 獲得する、取得する |
| handle | 処理する |
| hide | 隠す、非表示にする |
| highlight | 強調表示する |
| hack | ハックする、(その場しのぎで)作る |
| ignore | 無視する |
| indicate | 示す |
| input | 入力する |
| install | インストールする |
| implement | 実装する |
| import | インポートする |
| initialize | 初期化する |
| inline | インライン化する |
| insert | 挿入する |
| inspect | 検査する |
| interact | 対話する |
| invoke | 呼び出す |
| iterate | (処理を)反復する、繰り返す |
| join | 結合する |
| improve | 改良する、改善する |
| include | 含む |
| introduce | 導入する、紹介する |
| label | ラベルを貼る |
| launch | 起動する、開始する |
| limit | 制限する |
| link | リンクする |
| load | 読み込む |
| lock | ロックする |
| log | ログを取る |
| license | ライセンス供与する |
| list | 一覧表示する |
| make | 作成する |
| manage | 管理する |
| map | 対応づける、マッピングする |
| match | 一致する |
| merge | マージする、統合する |
| modify | 修正する、変更する |
| monitor | 監視する |
| move | 移動する |
| navigate | 移動する |
| normalize | 標準化する、正規化する |
| notify | 通知する |
| note | 〜に注意する |
| occur | 発生する |
| obtain | 取得する |
| open | 開く |
| optimize | 最適化する |
| output | 出力する |
| override | オーバーライドする、優先する |
| overwrite | 上書きする |
| parse | パースする、解析する |
| pass | 渡す |
| perform | 実行する |
| permit | 許可する |
| play | 再生する |
| populate | 自動入力する |
| post | 書き込む |
| prepare | 準備する |
| preview | プレビューする |
| 印刷する、出力する | |
| process | 処理する |
| protect | 保護する |
| provide | 提供する |
| publish | 公開する |
| pull | プルする、取得する |
| push | 押す、プッシュする |
| read | 読み取る |
| receive | 受信する |
| recommend | 推奨する |
| record | 記録する |
| redirect | リダイレクトする、転送する |
| refresh | 更新する |
| register | 登録する |
| reload | 再読み込みする、リロードする |
| remove | 削除する |
| rename | 名前を変更する |
| render | 描画する、レンダリングする |
| replace | 置換する |
| report | 報告する |
| request | 要求する |
| require | 必要とする |
| reserve | 予約する、確保する |
| reset | リセットする |
| resize | サイズ変更する |
| resolve | 解決する |
| respond | 応答する、返信する |
| restart | 再起動する |
| restore | 復元する |
| return | 戻す、返す |
| revert | (以前の状態に)戻る、戻す |
| run | 実行する |
| reference | 参照、リファレンス/参照する |
| release | リリースする、公開する |
| refactor | リファクタリングする、リファクターする |
| resolve | 解決する |
| retrieve | 取得する |
| save | 保存する |
| scan | スキャンする、走査する |
| scroll | スクロールする |
| search | 検索する |
| select | 選択する |
| send | 送信する |
| set | 設定する |
| show | 表示する |
| simplify | 簡素化する |
| split | 分割する |
| start | 開始する |
| stop | 停止する |
| store | 保存する、格納する |
| submit | 提出する、送信する |
| supply | 提供する、供給する |
| support | サポートする、支援する |
| switch | 切り替える |
| scale | (大きさを)変える |
| serialize | シリアル化する |
| setup | 設定する |
| shutdown | シャットダウンする |
| simplify | 簡素化する |
| skip | スキップする、とばす |
| sort | 並び替える、ソートする |
| specify | 指定する |
| split | 分割する |
| start | 開始する |
| stop | 停止する |
| store | 保存する、格納する |
| submit | 提出する、送信する |
| suppress | 表示しない |
| synchronize | 同期する |
| schedule | 動詞 |
| support | 動詞 |
| throw | スローする、投げる |
| toggle | 切り替える |
| touch | タッチする |
| translate | 変換する、翻訳する |
| transfer | 転送する |
| transform | 変換する、変形する |
| trigger | トリガーする、発火する |
| tweak | 微調整する |
| terminate | 終了する |
| undo | 元に戻す |
| uninstall | アンインストールする |
| update | 更新する |
| upgrade | アップグレードする |
| upload | アップロードする |
| use | 使う |
| validate | (妥当性を)確認する、検証する |
| verify | (正しいことを)確認する、検証する |
| visit | 訪問する、アクセスする |
| use | 使う/使用 |
| view | 表示する/表示、ビュー |
| wait | 待機する |
| warn | 警告する |
| wrap | ラップする、(テキストを)折り返す |
| write | 書き込む |
4-2. 名詞
| 英単語 | 意味 |
|---|---|
| account | アカウント、口座 |
| algorithm | アルゴリズム |
| application | アプリケーション |
| argument | 引数、実引数 |
| array | 配列 |
| attribute | 属性 |
| audio | オーディオ、音声 |
| author | 作成者 |
| accessibility | アクセシビリティー、アクセス可能性 |
| administrator | 管理者 |
| alias | エイリアス、別名 |
| allocation | 割り当て |
| annotation | アノテーション、注釈 |
| asset | アセット、資産 |
| assignment | 割り当て、代入 |
| authentication | 認証 |
| availability | 可用性 |
| action | アクション、操作 |
| activity | アクティビティー、活動 |
| address | アドレス、住所 |
| area | 領域、エリア |
| backup | バックアップ |
| bit | ビット |
| block | ブロック |
| boolean | ブール値 |
| branch | ブランチ、分岐 |
| browser | ブラウザー |
| bug | バグ |
| byte | バイト |
| batch | バッチ |
| brace | 波かっこ |
| bracket | 角かっこ |
| breakpoint | ブレークポイント |
| buffer | バッファー、余白 |
| bundle | バンドル、束、包み |
| body | 本体、本文 |
| build | ビルド |
| button | ボタン |
| cache | キャッシュ |
| capacity | 容量 |
| case | 場合、ケース、大文字小文字の区別 |
| character | 文字 |
| checkbox | チェックボックス |
| choice | 選択 |
| client | クライアント |
| clipboard | クリップボード |
| cloud | クラウド |
| cluster | クラスター |
| code | コード |
| collection | コレクション、収集 |
| column | 列、カラム |
| command | コマンド、命令 |
| communication | 通信、コミュニケーション |
| component | コンポーネント、部品 |
| condition | 条件 |
| configuration | 構成 |
| connection | 接続 |
| console | コンソール |
| constant | 定数 |
| constructor | コンストラクター |
| container | コンテナー |
| content | 内容、コンテンツ |
| context | コンテキスト、文脈 |
| control | 制御 |
| cookie | クッキー |
| core | コア |
| count | 回数、数 |
| cursor | カーソル |
| callback | コールバック |
| capability | 機能 |
| caret | 文字入力カーソル、カレット |
| certificate | 証明書 |
| checkout | チェックアウト |
| cleanup | クリーンアップ、整理 |
| compatibility | 互換性 |
| completion | 補完、完了 |
| constraint | 制約 |
| constructor | コンストラクター |
| contact | 連絡先 |
| coordinate | 座標 |
| copyright | 著作権 |
| crash | クラッシュ |
| credential | 資格情報、認証情報 |
| child | 子 |
| class | クラス |
| damage | 損害、ダメージ |
| dashboard | ダッシュボード |
| data | データ |
| database | データベース |
| debug | デバッグ |
| default | デフォルト、既定値 |
| declaration | 宣言 |
| delay | 遅延 |
| dependency | 依存関係 |
| deployment | 配備、デプロイ |
| deprecation | 非推奨 |
| descriptor | 記述子 |
| destination | 目的地、移動先 |
| digit | 数字、桁 |
| display | 表示、画面 |
| duration | 期間 |
| debugger | デバッガー |
| description | 説明 |
| detail | 詳細 |
| developer | 開発者 |
| development | 開発 |
| device | 機器、デバイス |
| dialog | ダイアログ、対話 |
| directory | ディレクトリー |
| disk | ディスク |
| domain | ドメイン |
| documentation | ドキュメント、資料 |
| editor | エディター |
| element | 要素 |
| entry | エントリー、入力 |
| environment | 環境 |
| error | エラー |
| exception | 例外 |
| expression | 表現、式 |
| メール | |
| event | イベント、出来事 |
| example | 例 |
| export | エクスポート |
| endpoint | エンドポイント、端点 |
| entity | エンティティー、実体 |
| enumeration | 列挙 |
| executable | 実行可能ファイル |
| execution | 実行 |
| extension | 拡張、拡張子 |
| encoding | エンコーディング、符号化 |
| encryption | 暗号化 |
| feature | 機能、特徴 |
| field | フィールド |
| file | ファイル |
| filter | フィルター |
| flag | フラグ |
| folder | フォルダー |
| font | フォント |
| format | フォーマット、書式、形式 |
| function | 機能、関数 |
| failure | 失敗、故障 |
| fallback | フォールバック |
| framework | フレームワーク |
| functionality | 機能 |
| form | フォーム |
| graphic | グラフィック、画像 |
| guide | ガイド |
| group | グループ |
| generation | 生成、世代 |
| hack | ハッキング、一時回避策 |
| handle | ハンドル |
| handler | ハンドラー |
| handling | 処理 |
| hardware | ハードウェア |
| hash | ハッシュ、ハッシュ記号 |
| header | ヘッダー |
| health | ヘルス、正常性 |
| height | 高さ |
| hierarchy | 階層 |
| highlight | ハイライト |
| host | ホスト |
| icon | アイコン |
| image | 画像、イメージ |
| import | インポート |
| index | インデックス、索引、添字 |
| input | 入力 |
| installer | インストーラー |
| instance | インスタンス、実例 |
| instruction | 指示 |
| integer | 整数 |
| interface | インターフェイス |
| issue | 問題点 |
| item | 項目 |
| identifier | 識別子 |
| implementation | 実装 |
| increment | 増分、インクリメント |
| indentation | インデント |
| initialization | 初期化 |
| inspection | 検査 |
| installation | インストール |
| interval | 間隔 |
| key | キー |
| label | ラベル |
| latency | 待ち時間 |
| layer | レイヤー、層 |
| layout | レイアウト |
| length | 長さ |
| level | レベル、水準 |
| library | ライブラリー |
| license | ライセンス |
| limit | 制限 |
| link | リンク |
| listener | リスナー |
| locale | ロケール |
| location | 位置、場所 |
| log | ログ |
| login | ログイン |
| loop | ループ |
| logic | ロジック、論理 |
| lookup | 検索、探索 |
| information | 情報 |
| language | 言語 |
| line | 行、線 |
| list | リスト |
| manager | マネージャー |
| map | 地図 |
| master | マスター |
| media | メディア |
| memory | メモリ |
| menu | メニュー |
| message | メッセージ |
| metadata | メタデータ |
| method | メソッド、方法 |
| migration | 移行 |
| millisecond | ミリ秒 |
| model | モデル、型 |
| mode | モード |
| modification | 修正、変更 |
| modifier | 修飾子 |
| module | モジュール |
| manual | マニュアル |
| name | 名前 |
| namespace | 名前空間 |
| navigation | ナビゲーション、移動 |
| network | ネットワーク |
| node | ノード |
| none | 一つもなし |
| note | 注意 |
| notice | 通知、注意 |
| notification | 通知 |
| number | 数 |
| object | オブジェクト、物体、対象 |
| occurrence | 出現、発生 |
| offset | オフセット |
| operation | 操作、処理 |
| option | オプション |
| output | 出力 |
| owner | 所有者、オーナー |
| overview | 概要 |
| package | パッケージ |
| parameter | パラメーター、仮引数 |
| parent | 親 |
| parse | パース、解析 |
| password | パスワード |
| patch | パッチ、修正プログラム |
| path | パス |
| payload | ペイロード |
| performance | 性能、パフォーマンス |
| permission | 許可、パーミッション |
| persistence | 永続化 |
| placeholder | プレースホルダー |
| plugin | プラグイン |
| pool | プール |
| popup | ポップアップ |
| port | ポート |
| position | 位置 |
| post | 投稿 |
| preference | 優先 |
| prefix | 接頭辞、プレフィックス |
| preview | プレビュー |
| priority | 優先順位、優先度 |
| problem | 問題 |
| product | 製品、プロダクト |
| profile | プロファイル、プロフィール |
| progress | 進行状況 |
| project | プロジェクト |
| protocol | プロトコル |
| prototype | プロトタイプ |
| provider | プロバイダー |
| provision | プロビジョニング |
| proxy | プロキシ |
| public | 公開 |
| pull | プル |
| push | プッシュ |
| range | 範囲 |
| read | 読み取り |
| record | 記録、レコード |
| redirect | リダイレクト |
| refresh | 更新 |
| register | 登録 |
| registration | 登録 |
| registry | レジストリー |
| reload | 再読み込み、リロード |
| removal | 削除、除去 |
| rename | 名前変更 |
| render | 描画、レンダリング |
| repository | リポジトリー |
| represent | 表示 |
| representation | 表現 |
| request | 要求、リクエスト |
| response | 応答 |
| restart | 再起動 |
| restore | 復元 |
| return | 戻り値 |
| revert | 戻り、復帰 |
| revision | 改訂、リビジョン |
| right-click | 右クリック |
| role | 役割、ロール |
| root | ルート |
| route | 経路、ルート |
| row | 行 |
| rule | ルール、規則 |
| runtime | 実行時、ランタイム |
| resource | リソース、資源 |
| response | 応答 |
| result | 結果 |
| restriction | 制限 |
| schedule | 予定、スケジュール |
| screen | 画面 |
| script | スクリプト |
| search | 検索 |
| security | セキュリティー |
| server | サーバー |
| setting | 設定 |
| shape | 形状 |
| shortcut | ショートカット |
| sign | 記号 |
| source | ソース、〜元(送信元など) |
| space | スペース、空白 |
| specification | 仕様 |
| stack | スタック |
| state | 状態 |
| status | 状態、ステータス |
| step | ステップ、手順 |
| string | 文字列 |
| support | サポート |
| switch | スイッチ |
| system | システム |
| schema | スキーマ、構造 |
| scope | スコープ、範囲 |
| section | セクション、部分 |
| separator | セパレーター、区切り |
| sequence | シーケンス |
| session | セッション |
| setup | 設定、構成、セットアップ |
| shutdown | シャットダウン |
| signature | 署名、シグネチャー |
| snapshot | スナップショット |
| socket | ソケット |
| software | ソフトウェア |
| space | スペース、空白 |
| statement | ステートメント、文 |
| storage | ストレージ |
| stream | ストリーム |
| style | スタイル |
| suffix | 接尾辞、サフィックス |
| syntax | 構文、シンタックス |
| service | サービス |
| size | 大きさ |
| software | ソフトウェア |
| space | スペース、空白 |
| statement | ステートメント、文 |
| startup | 起動、スタートアップ |
| static | 静的 |
| storage | ストレージ |
| stream | ストリーム |
| successfully | 正常に |
| suffix | 接尾辞、サフィックス |
| syntax | 構文、シンタックス |
| tab | タブ |
| table | 表、テーブル |
| tag | タグ |
| target | ターゲット、対象、〜先(移動先など) |
| task | タスク |
| template | テンプレート |
| timeout | タイムアウト |
| touch | タッチ |
| type | 型、種類 |
| termination | 終了 |
| terms | 期間、条項 |
| third party | サード・パーティー、第三者 |
| thread | スレッド |
| timestamp | タイムスタンプ |
| token | トークン |
| transaction | トランザクション |
| transition | 遷移 |
| typo | 入力ミス、タイポ |
| test | テスト |
| traffic | トラフィック、通信(量) |
| tree | 木、ツリー |
| unit | 単位、ユニット |
| update | 更新 |
| upload | アップロード |
| usage | 利用、使用 |
| username | ユーザー名 |
| user | ユーザー |
| value | 値 |
| variable | 変数 |
| version | バージョン、版 |
| view | 表示、ビュー |
| validation | 検証 |
| visibility | 可視性、可視範囲 |
| warning | 警告 |
| website | ウェブサイト |
| widget | ウィジェット |
| width | 幅 |
| window | ウィンドウ |
| whitespace | 空白、スペース |
| wizard | ウィザード |
| wrapper | ラッパー |
4-3. 形容詞
| 英単語 | 意味 |
|---|---|
| alternative | 代替の |
| available | 利用可能な、入手可能な |
| abstract | 抽象的な |
| accessible | アクセス可能な、利用可能な |
| active | 有効な、アクティブな |
| additional | 追加の |
| automatic | 自動の |
| automatically | 自動で、自動的に |
| based | ベースの、〜に基づく |
| blank | 空白の |
| binary | バイナリーの、二進法の |
| constant | 一定の |
| conditional | 条件つきの |
| complete | 完全な |
| current | 現在の |
| custom | カスタムの、ユーザー設定の |
| dedicated | 専用の |
| deprecated | 非推奨の、廃止された |
| dynamic | 動的な |
| empty | 空の |
| equal | 等しい |
| existing | 既存の |
| expected | 期待された |
| external | 外部の |
| extra | 余分な、追加の |
| executable | 実行可能な |
| equal | 〜に等しい |
| false | 誤りの、偽の |
| final | 最終の |
| free | 空きの、無料の |
| following | 次の項目の |
| general | 全般の、一般の |
| global | グローバルな、大域の |
| generic | 汎用の、総称の、ジェネリックの |
| incompatible | 互換性がない |
| initial | 初期の、最初の |
| inline | インラインの |
| inner | 内部の、内側の |
| internal | 内部の |
| invalid | 無効な |
| latest | 最近の |
| local | ローカルの、局所の |
| manual | 手動の |
| matching | 一致する、マッチする |
| maximum | 最大の |
| minimum | 最小の |
| minor | マイナーな、小さな |
| missing | 見つからない、欠落している |
| mock | モックの、模造の |
| multiple | 複数の |
| native | ネイティブの |
| nested | 入れ子の、ネストされた |
| next | 次の |
| normal | 標準の |
| null | 空の、nullの |
| numeric | 数値の |
| open | 開いた |
| optional | 任意の、オプションの |
| physical | 物理的な |
| preferred | 優先の |
| previous | 前の |
| private | プライベートな、非公開の |
| public | 公開の |
| raw | 生の |
| real-time | リアルタイムの |
| redundant | 冗長な |
| remote | 遠隔の、リモートの |
| specific | 特定の |
| secure | セキュアな、安全な |
| standalone | スタンドアロンの |
| static | 静的な |
| successful | 成功した |
| temporary | 一時的な |
| true | 正しい、真の |
| unable | 不可能な |
| unused | 未使用の |
| unauthorized | 権限のない |
| unavailable | 利用できない |
| undefined | 未定義の |
| unexpected | 予期しない |
| unique | 一意の、固有の |
| unknown | 不明の |
| unnecessary | 不要な |
| unresolved | 未解決の |
| unsupported | 非対応の、サポートされない |
| useful | 便利な |
| valid | 有効な |
| verbose | 冗長な |
| virtual | 仮想の |
| visible | 可視の、表示できる |
4-4. 副詞
| 英単語 | 意味 |
|---|---|
| below | 下記に |
| correctly | 正しく、正常に |
| except | 〜を除く |
| externally | 外部で |
| including | 〜を含めて |
| manually | 手動で |
| properly | 適切に、正常に |
| successfully | 正常に |
以上がプログラミングでよく使われる単語になります。
なお、ここで紹介した単語の一覧についてはこちらの記事から引用させていただいております。
こちらの記事はより見やすくまとめられおり、また単語の省略形や予約語(プログラミング言語側ですでに設定されている単語)などもまとめられているので、ぜひ確認してみてください。
またこちらの記事は単語のニュアンス含め整理されている非常に中身の濃い内容なので、合わせて読んでみてください。
5. エラーとの向き合い方
エラーはプログラミングにおいて回避しきれないものです。
エラーの扱い方を誤るとタスクの進捗が遅れるだけではなく、さまざまな弊害をもたらしてしまいます。
以下にデメリットの例を示します。
- 時間の浪費
適切なエラーの対処法をしないと、問の解決に無駄に時間がかかってしまいます。私もそうだったのですが、なんとなくでエラーを解決しようとすると手戻りが多くなってしまいます。
- バグの拡散
エラーを見過ごしたり握りつぶす(動作に直接関係ないエラーを見逃す)など、間違った対処をすると他のコード部分に影響を与え、さらなるバグを生む可能性があります。
- セキュリティリスク
一部のエラーはセキュリティの脆弱性を引き起こすことがあり、適切に対処しないとセキュリティリスクが高まります。
- ユーザー体験の悪化
エラーは開発者だけに関係しているわけではありません。サービスを利用しているユーザーにも影響します。エラーが適切に処理されないと、頻繁にエラーを起こす可能性があります。その結果、サービスが提供されなくなり、ユーザーが不快な思いをすることになります。
- 信頼性の低下
頻繁にエラーが発生するアプリケーションやサービスは、クライアントやユーザーからの信頼を失うことにつながります。
- 学習機会の損失
エラーを無視すると、適切な対処の過程で得られる学習の機会を失うことになります。
- ストレスとフラストレーション
エラーと適切に向き合わないと、将来的に自分自身のストレスやフラストレーションが増大します。1つ1つのエラーと向き合うことで知識を身につけ、同様のエラーが起きても即座に解決することができます。
- プロジェクトの遅延
エラーによるプロジェクトの遅延は、予算超過や納期遅延の原因になります。
以上のようにエラーを適切に対処しないと多くのデメリットをもたらすことになります。
5-1. エラーの内容を読む
エラーを適切に処理するためには、まずはエラーの内容を適切に読まなければなりません。
多くの場合、エラーを読むと原因箇所が特定できるようになっています。
エラーの対応にはいくつかコツがあるので、それを紹介します。
- エラーメッセージを注意深く読む
エラーメッセージは通常、何が問題であるかを示してくれます。メッセージをよく読み、 「何が」起こっているのかを理解しましょう。エラーメッセージはプログラミング言語やフレームワークによって異なることがあるので、特定のコンテキスト(環境や状況)でのメッセージを理解することが大切です。
- エラーメッセージの行番号やファイル名を確認
エラーメッセージは通常、問題が発生したコードの行番号やファイル名を教えてくれます。これにより、どの部分のコードが問題を引き起こしているのかを特定できます。
- コードを確認
エラーメッセージが指摘している行やファイルを開き、該当のコードを確認しましょう。そして、コードのロジックや構文を注意深く調査しましょう。
- エラーメッセージのキーワードを探す
エラーメッセージにはエラーの原因に関連するキーワードが含まれていることがあります。例えば、「未定義の変数」、「構文エラー」、「型エラー」などです。これらのキーワードを探し、エラーのタイプを特定しましょう。
- エラーメッセージをググる
エラーメッセージが分からない場合、そのエラーメッセージをコピーし、オンラインで検索してみましょう。他のプログラマーが同様の問題に遭遇し、解決策を共有している可能性があります。
- ログやスタックトレースを確認
エラーメッセージには、エラーがどのように発生したかを示すスタックトレーが含まれていることがあります。スタックトレースとは、プログラムの実行中にエラーや例外が発生した際に、そのエラーがどのように発生したかを示す情報です。スタックトレースを読むことで、エラーの発生経路を理解しやすくなります。
- コードの文脈を考慮
エラーが特定の条件下でのみ発生する場合、その条件を考慮に入れましょう。エラーが特定のデータ入力や環境設定に依存しているかもしれません。
- エラーの種類に応じた対策を検討
エラーメッセージからエラーの種類を特定し、それに対する対策を検討します。例えば、構文エラーならば構文を修正し、型エラーなら型の整合性を確認しましょう。
- コミュニティや同僚に助けを求める
エラーが解決できない場合、プログラミングコミュニティや同僚に助けを求めましょう。他の人の視点やアイデアがエラー解決に役立つことが多々あります。時間をかけるよりは、すぐに聞いたほうが良い場合があります。個人的にstackoverflowというコミュニティはエラー解決の際に非常にお世話になっていると思います。
このトピックのまとめ
エラーの内容を読むポイント
- エラーメッセージを注意深く読む
- エラーメッセージの行番号やファイル名を確認する
- エラーメッセージ内のコードを確認する
- エラーメッセージのキーワードを探す
- エラーメッセージをググる
- ログやスタックトレースを確認する
- コードの文脈を考慮する
- エラーの種類に応じた対策を検討する
- コミュニティや同僚に助けを求める
5-2. エラーの種類
エラーにはさまざまな種類があります。
ここではよく発生するエラーについて紹介します。
- 構文エラー(Syntax Error)
- 原因 : コードが言語の構文規則に違反している
- 対処法 : エラーメッセージを注意深く読み、指摘された行や文字を確認し、構文を正しく修正する
❌ NG
print("Hello world"
# 出力
File "/Users/sample/qiita_sample.py", line 1
print("Hello world"
^
SyntaxError: '(' was never closed
qiita_sample.pyの1行目にエラーがあることを最初に教えてくれています。
次に構文エラーであること教えてくれ、具体的には括弧で閉じられていないことを教えてくれています。
修正後のサンプルコードは以下になります。
⭕ GOOD
print("Hello world")
# 出力
Hello world
- 型エラー(Type Error)
- 原因 : 異なるデータ型間で不適切な操作が行われた
- 対処法 : 変数の型を確認し、必要に応じて型変換を行うか、適切なデータ型を使用する。
❌ NG
a = "5"
b = 10
print(a + b)
# 出力
File "/Users/sample/qiita_sample.py", line 3, in <module>
print(a + b)
~~^~~
TypeError: can only concatenate str (not "int") to str
qiita_sample.pyの3行目のmodule(print)にエラーがあることを最初に教えてくれています。
次に型エラーであること教えてくれ、具体的にはstr(文字列)型はstr型同士でないと結合できないことを教えてくれています。
修正後のサンプルコードは以下になります。(int型に合わせています)
⭕ GOOD
a = 5
b = 10
print(a + b)
# 出力
15
- 名前エラー(Name Error):
- 原因 : 定義されていない変数や関数を参照した
- 対処法 : スペルミスがないか確認し、変数や関数が適切なスコープで定義されているかを確認する
❌ NG
print(variable)
# 出力
File "/Users/sample/qiita_sample.py", line 1, in <module>
print(variable)
^^^^^^^^
NameError: name 'variable' is not defined. Did you mean: 'callable'?
qiita_sample.pyの1行目のmodule(print)にエラーがあることを最初に教えてくれています。
次に名前エラーであること教えてくれ、具体的にはvariableが定義されていないことを教えてくれています。
親切なことにcallableの間違いではないかを指摘しれくれています。(今回のサンプルコードでは関係ないですが)
修正後のサンプルコードは以下になります。
⭕ GOOD
variable = "variable"
print(variable)
# 出力
variable
- インデックスエラー(Index Error):
- 原因 : リストや配列の範囲外のインデックスにアクセスした
- 対処法 : インデックスが配列やリストのサイズ内に収まっていることを確認し、必要に応じて条件文を追加する
❌ NG
my_list = [1, 2, 3]
print(my_list[3])
# 出力
File "/Users/sample/qiita_sample.py", line 2, in <module>
print(my_list[3])
~~~~~~~^^^
IndexError: list index out of range
qiita_sample.pyの2行目のmodule(print)にエラーがあることを最初に教えてくれています。
次にインデックスエラーであること教えてくれ、具体的にはリストのインデックスが範囲をオーバーしていることを教えてくれています。
今回のサンプルコードでリストのインデックスは2までなのに3を指定していますね。
修正後のサンプルコードは以下になります。
⭕ GOOD
my_list = [1, 2, 3]
print(my_list[2])
# 出力
3
- キーエラー(Key Error):
- 原因 : 辞書型で存在しないキーにアクセスした
- 対処法 : キーが辞書に存在するかを確認し、存在しない場合は適切な処理を行う
❌ NG
my_dict = {"a": 1, "b": 2}
print(my_dict["c"])
# 出力
File "/Users/sample/qiita_sample.py", line 2, in <module>
print(my_dict["c"])
~~~~~~~^^^^^
KeyError: 'c'
qiita_sample.pyの2行目のmodule(print)にエラーがあることを最初に教えてくれています。
次にキーエラーであること教えてくれ、具体的にはmy_dictの辞書のキーにcがないことを教えてくれています。
修正後のサンプルコードは以下になります。
⭕ GOOD
my_dict = {"a": 1, "b": 2}
print(my_dict["a"])
# 出力
1
- 属性エラー(Attribute Error):
- 原因 : 存在しない属性やメソッドをオブジェクトに対して使用した
- 対処法 : オブジェクトの型を確認し、正しい属性やメソッドを使用する
❌ NG
my_list = [1, 2, 3]
my_list.push(4)
# 出力
File "/Users/sample/qiita_sample.py", line 2, in <module>
my_list.push(4)
^^^^^^^^^^^^
AttributeError: 'list' object has no attribute 'push'
qiita_sample.pyの2行目のmodule(print)にエラーがあることを最初に教えてくれています。
次に属性エラーであること教えてくれ、具体的にはmy_listにはpushの属性(メソッド)がないことを教えてくれいてます。
ここで属性エラーの場合は、以下のサンプルコードのようにprint(dir({オブジェクト}))で、そのオブジェクトに何の属性とメソッドがあるかを調べることができます。
my_list = [1, 2, 3]
print(dir(my_list))
# 出力
['__add__', '__class__', '__class_getitem__', '__contains__', '__delattr__',
'__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__',
'__getattribute__', '__getitem__', '__getstate__', '__gt__', '__hash__', '__iadd__',
'__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__',
'__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__',
'__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__',
'__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert',
'pop', 'remove', 'reverse', 'sort']
出力結果から、my_listオブジェクトにはpushメソッドがないことがわかりますね。
修正後のサンプルコードは以下になります。
ここではオブジェクトが持っているpopメソッドを使ってみます。
⭕ GOOD
my_list = [1, 2, 3]
print(my_list.pop(2))
# 出力
3
- ゼロ除算エラー(ZeroDivision Error):
- 原因 : 数値をゼロで割った
- 対処法 : 除算前に分母がゼロでないことを確認する
❌ NG
a = 1 / 0
print(a)
# 出力
File "/Users/sample/qiita_sample.py", line 1, in <module>
a = 1 / 0 # ゼロで割っている
~~^~~
ZeroDivisionError: division by zero
qiita_sample.pyの1行目にエラーがあることを最初に教えてくれています。
次にゼロ除算エラーであること教えてくれ、具体的には0で割っていることを教えてくれてます。
修正後のサンプルコードは以下になります。
ここではオブジェクトが持っているpopメソッドを使ってみます。
⭕ GOOD
a = 1 / 2
print(a)
# 出力
0.5
- ファイルノットファウンドエラー(FileNotFoundError):
- 原因 : 存在しないファイルを読み込もうとした
- 対処法 : ファイルパスが正しいか確認し、ファイルが存在するかを確認する
with open("non_existent_file.txt") as f:
content = f.read()
# 出力
File "/Users/sample/qiita_sample.py", line 1, in <module>
with open("non_existent_file.txt") as f:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
FileNotFoundError: [Errno 2] No such file or directory: 'non_existent_file.txt'
qiita_sample.pyの1行目にエラーがあることを最初に教えてくれています。
次にファイルノットファウンドエラーであること教えてくれ、具体的にはnon_existent_file.txtが無いことを教えてくれいてます。
以上がよく出るエラーの例になります。
ここで確認できたようにエラーメッセージを読むと対処法がわかるので、焦らずにエラーを解決する癖を身につけていきましょう。
このトピックのまとめ
頻繁に起こるエラーの種類
- 構文エラー(Syntax Error): 文法の誤りが原因
- 型エラー(Type Error): 異なるデータ型間の操作が原因
- 名前エラー(Name Error): 定義されていない変数や関数を参照したことが原因
- インデックスエラー(Index Error): リストなどの範囲外のインデックスへのアクセスが原因
- キーエラー(Key Error): 辞書型の存在しないキーへのアクセスが原因
- 属性エラー(Attribute Error): オブジェクトが持っていない属性やメソッド呼んだことが原因
- ゼロ除算エラー(ZeroDivision Error): 数値をゼロでわったことが原因
- ファイルノットファウンドエラー(FileNotFoundError): 存在しないファイルを読み込もうとしたことが原因
5-3. ログを入れてみる
エラーが発生しても、場合によっては細かいところまで原因を教えてくれないことがあります。
そういった場合にログをコードの中に仕込んでおくことで、エラー特定の助けになることが多々あります。
そもそもログとは一体何なのかというと、コンピュータプログラムやシステムの動作や出来事の記録のことを指します。
ログを仕込んでおくことで具体的に以下のようなメリットがあります。
- デバッグ支援:
ログはプログラムの実行中に何が起こっているかを記録するため、バグの特定とデバッグに役立ちます。ログに情報を出力することで、特定のコードブロックや条件分岐が実行されているかどうかを確認でき、問題の特定が容易になります。
- エラー追跡:
ログにエラーメッセージやスタックトレースを出力すると、エラーが発生した際にその原因を正確に特定できます。エラーメッセージやエラーコードが分かることで、迅速に対応ができます。
- 性能評価:
ログにはプログラムの実行時間やリソース使用量などの情報を記録できます。これにより、プログラムの性能を評価し、ボトルネックを特定できます。
- 監視と分析:
ログはプログラムの動作を監視し、パフォーマンスを分析するために活用できます。ログデータを集約・解析するツールを使用することで、システムのパフォーマンスを継続的に監視できます。
- セキュリティ監査:
セキュリティイベントやアクセスログを記録することで、不正アクセスやセキュリティ侵害の検出と監査が可能になります。
次にサンプルコードで確認してみましょう。
なおログの設定方法については詳しく説明しません。ここではログを設定することが何ができるのかを具体的にお伝えしようと思います。
import logging
# ログの設定
logging.basicConfig(filename='error.log', level=logging.ERROR, format='%(asctime)s - %(levelname)s - %(message)s')
def divide_numbers(num_1: int, num_2: int):
try:
result = num_1 / num_2
return result
except ZeroDivisionError as e:
# ゼロ除算のエラーが発生した場合、エラーメッセージをログに出力
logging.error(f'ZeroDivisionError: {e}, num_1={num_1}, nm_2={num_2}')
return None
result = divide_numbers(10, 2)
print(result)
# 出力
5.0
まずはサンプルコードが正常に動くことを確認しています。divide_numbersが引数を2つ受け取り除算をする関数になっています。
次にゼロ除算エラーをわざと起こすサンプルコードで確認しましょう。
import logging
# ログの設定
logging.basicConfig(filename='error.log', level=logging.ERROR, format='%(asctime)s - %(levelname)s - %(message)s')
def divide_numbers(num_1: int, num_2: int):
try:
result = num_1 / num_2
return result
except ZeroDivisionError as e:
# ゼロ除算のエラーが発生した場合、エラーメッセージをログに出力
logging.error(f'ZeroDivisionError: {e}, num_1={num_1}, nm_2={num_2}')
return None
result = divide_numbers(10, 0)
print(result)
# 出力
None
出力はNoneとなっています。この時にerror.logファイルが同じディレクトリの階層に作られるのですが、ファイルの中身が以下のようになっています。
2023-11-29 15:07:27,962 - ERROR - ZeroDivisionError: division by zero, num_1=10, num_2=0
どのタイミング、何のエラーが起きているのか、原因となっている箇所はどこかがわかると思います。
今回は簡単なログの設定をしていますが、より詳細にログを設定することができます。
またログにはレベルがあり、任意でレベルを設定できます。以下に基本的なログレベルを紹介します。
- DEBUG(デバッグ):
最も詳細なログレベルで、デバッグの目的で使用されます。
プログラム内の特定のステップや変数の値など、詳細な情報を記録します。
通常、デバッグ中にのみ有効にし、本番環境では無効にします。
- TRACE(トレース):
プログラム内のさまざまなステップや関数呼び出しを追跡します。
通常、DEBUGよりもさらに詳細な情報を提供しますが、本番環境では無効にされることが一般的です。
- INFO(情報):
情報メッセージを記録するためのログレベルです。
通常の実行状態やプログラムの重要なイベントに関する情報を記録します。
プログラムの正常な動作を示すために使用されます。
- NOTICE(通知):
INFOとWARNINGの中間的なログレベルで、通常は重要なイベントや通知を示すために使用されます。
プログラムが期待どおりに動作しているが、特別な情報を示す必要がある場合に利用します。
通知が必要な場合に使用します。
- WARNING(警告):
警告メッセージを記録するためのログレベルです。
プログラムが予期しない動作をしている可能性がある場合や、潜在的な問題がある場合に使用されます。
警告が表示されても、プログラムは継続して動作しますが、警告の内容は修正されるべき対象となります。
- ERROR(エラー):
エラーメッセージを記録するためのログレベルです。
実行時のエラーや例外が発生した場合に使用されます。
- CRITICAL(クリティカル):
システムの致命的なエラーや重大な問題を示すための最も高いログレベルです。
プログラムが続行できないほど重大な問題が発生した場合に使用されます。
通常、非常にまれなケースにのみ使用されます。
- EMERGENCY(緊急):
システムの緊急事態を示すための最も高いログレベルで、非常にまれに使用されます。
システムが停止し、即座の対応が必要な状況を示すために使用されます。
通常、プログラムが動作不能状態にあることを示すために利用します。
なお、ログの設定の詳細についてはこちらの記事に書かれていますので、ぜひ確認してみてください。
このトピックのまとめ
ログのポイント
- ログはエラー特定のサポートとなる
- ログを仕込むことでエラーの他にプログラムのパフォーマンスを見たり、分析や性能評価をすることができる
- ログレベルなど、ログは柔軟に設計することができる
6. テストで動作確認
コードを書いたら、コードが正しく動作するのかテストを行わないといけません。
ここでは単体テストと結合テストの概要をお伝えします。
6-1. 単体テストとは
単体テスト(ユニットテスト)とは、ソフトウェア開発において重要な要素の1つで、個々の機能やユニットを分離してテストするプログラムテストの一種です。
主な目的は、各ユニットが期待通りに動作し、要件(期待通りの挙動)を満たしていることを確認することになります。(ここでいうユニットとは関数やメソッドのように最小単位の機能だと思ってください。)
通常はテストを実行するためのスクリプトやテストフレームワークを使用して自動的に実行します。
これによってテスト実行時の労力を小さくするとともに、バグの早期発見と修正を可能にしてくれます。
プロジェクトにもよるのですが、一般的にユニットは膨大にあり、ユニット毎に人力でテストを行うとかなりの時間を要してしまいます。
その結果バグの発見が遅くなってしまうことになります。
よって自動的にテストを実行することはバグの早期発見に繋がり、後の開発段階での問題を減少させてくれます。
また、単体テストは再利用性と保守性を向上させ、変更やアップデートの影響を把握しやすくさせてくれます。
再利用性の向上とは、単体テストでそのユニット(関数やクラスなど)が正しく動作することが確認できれば、そのユニットを他のユニットへ利用可能ということを意味しています。
保守性の向上についてですが、プロジェクトが進んでいくと変更やアップデートがされていきます。ユニット毎に正しい挙動がされていることが確認できれば、変更やアップデートに対応できていることを証明できます。
このように、単体テストはプロジェクトの土台となる部分のテストなので非常に需要な要素となります。
また単体テストは他のユニットに依存しないように行わなければなりません。
仮にユニットが他のユニットに依存した状態でテストを実行した場合を考えてみましょう。
もしもバグが見つかった場合、その原因がどのユニットにあるのかがわからなくなってしまいます。
ユニット毎の動作を確認するためにも、他のユニットに依存しない状態でテストをする必要があります。
それでは具体的にどのように単体テストを行うのか、一例を紹介します。
大きくは以下の流れでテストを実行します。
- テストケースの設計
- テストデータの準備
- テストの実行
- 結果の評価
- バグがあれば修正
初めのテストケースの設計がかなり重要で、ユニットが求められる挙動のテストを網羅する必要があります。
例えば以下の関数のテストを考えてみましょう。
def calculate_div(number_1: int, number_2: int) -> float:
return number_1 / number_2
calculate_divは2つの引数を除算して返す関数です。
この関数が求められる正しい挙動は適切な値を返す他に0で除算した時にエラーを出す、str(文字列)型などで計算を行なってエラーを出すも考えられます。
もちろんこれらもテスト対象となります。
ちなみに正しい挙動のテストを「正常系」といい、期待しない挙動のテストを「異常系」といいます。
このようにテストケースの設計段階では「正常系」と「異常系」パターンを網羅する必要があります。
単体テストについてはこちらの記事に詳細が書かれていますので、ぜひ確認してみてください。
このトピックのまとめ
単体テストのポイント
- 単体テストはユニット(関数やメソッドなど)単位で行われる
- 単体テストは基本的に自動で行うようにする
- 単体テストはユニット同士が依存しないように実行する
- テストケースの設計では正常系と異常系のパターンを網羅する
6-2. 結合テストとは
結合テストとは、単体テストで動作の確認が完了したユニットを利用して、システム全体が機能するかを確認するテストになります。
単体テストではユニット同士が依存しない状態でテストを行いましたが、結合テストではユニットが依存しあった状態でテストをします。
これによって、アプリケーションやサービスの本番に近い挙動を確認します。
具体的なテストについていくつか紹介したいと思います。
- インターフェーステスト
インターフェーステストとは個別のプログラムやモジュール間でデータの受け渡しが正常にできているかの確認になります。
モジュールについてですが、簡単に言ってしまえば1つのファイルのことを指します。
例えばですが、sample.pyというファイルがあった場合、これが1つのモジュールということになります。
インターフェースのテストは言い換えると、ファイル間でデータの受け渡しが正しく行われているかを確認するテストになります。
- ブラックボックステスト
これは利用者側の目線に立ったテストになります。テストする人がコードの中身を把握することなく、何かしらのデータを入れたときに、期待されるれる出力(実際のアプリ画面に表示される内容など)をしてくれるか確認するテストです。
具体的にはアプリのユーザー登録画面でユーザー情報を入力したら、登録内容とともにユーザー登録メッセージが表示されることを確認するといった具合です。
つまりは、サービスやアプリの仕様を確認するテストになります。
- 負荷テスト
システム全体に限界までの負荷をかけて、システムがダウンしないかを確認するテストになります。リリース直後などはアクセスが集中しシステムが落ちることが考えられるので、事前に負荷テストで確認する必要があります。許容できる負荷を把握しておけば、今後の指標にもなります。
ここで紹介しきれなかったテストについてはこちらの記事に記載されていますので、ぜひ確認してみてください。
このトピックのまとめ
結合テストのポイント
- 結合テストはシステム全体の挙動の確認をするテスト
- 個別のプログラムやモジュール間で正しい動きをするか確認する
7. 検索の極意
プログラミングをしていると検索を頻繁に行うことになるでしょう。
検索の仕方が悪いと辿り着きたい答えに辿り着けないことになります。
ここでは検索するときのコツを紹介します。
7-1. エラーを解決したい
エラーの検索は非常に多いです。
特にプログラミング初心者は作業時間のほとんどをエラー解決に費やしているのではないでしょうか。
ほとんどの人が行なっていると思うのですが、エラーメッセージをコピーして検索する方法は非常に有効です。
この方法がエラー解決の1番の近道とっても過言ではありません。
経験的に、ほとんどのエラーは世界の誰かがすでに直面しており、その解決策も提示されている場合が多いです。
特にプログラムを学習し初めの頃のエラーは基本的なエラーが多いので、解決策はネットの世界に溢れかえっています。
よって、エラーメッセージをコピーして検索をし、ヒットした先人の経験をそのまま利用させてもらえれば良いのです。
ただし、注意しなければならない点があります。
エラーメッセージにはファイル名やディクトリ名などの固有名詞が含まれていることがあります。
固有名詞を含めての検索は具体的すぎるので、検索結果の精度も落ちてしまいます。
エラーメッセージをコピーした後は固有名詞を含まないようにしてから、検索するようにしましょう。
このトピックのまとめ
エラーを解決したい時のポイント
- エラーメッセージをコピーして検索すると、大体解決策が見つかる
7-2. 検索は文脈に合わせて
これは結構大切なことなのですが、検索するときは検索ワードを文脈に合わせる必要があります。
文脈という言葉はこれまでも何度か登場しましたが、言い換えると「環境」や「状況」という意味になります。
私が失敗した例を用いて、文脈を意識することの大切さを伝えたいと思います。
以前、業務でGitHub ActionsというGithubが提供している機能を利用する場面がありました。
このとき初めてこの機能に触れたのですが、コードの書き方がよくわかっておらず、実装したいことがなかなかできない状況でした。
やりたいことを実装するためにはusesというキーワードを利用する必要がありました。
簡単に言えば他のファイルを利用するために必要なキーワードです。
このとき私は「他のファイルを呼んでいるんだな」という認識から「git actions ファイル 呼ぶ」や「git actions ファイル 参照」のように検索していました。
しかし結果として、具体的な解決方法がなかなか見つかりませんでした。
実は uses はGitHub Actionsでは「利用(再利用)」という意味合いが強かったのです。
なので検索時は「呼ぶ」や「参照」ではなく「利用」や「再利用」の方がより正しい検索ワードだったということになります。
これは公式ドキュメントで該当箇所をみたのちに、検索ワードを変えた結果わかったことでした。
このように、調べようとしている対象の検索ワードが文脈(環境や状況)によって異なるということを理解しておかなければ、時間を無駄に使ってしまうことになってしまいます。
このトピックのまとめ
検索の文脈を意識するポイント
- 文脈(環境や状況)に合わせて検索ワードを変えてみる
7-3. 2次ソースの信頼性
調べものをしていると、参考にする情報が2次ソースの場合が結構あると思います。
もちろん私もそうです。
公式ドキュメントやサービス開発者が発信している1次ソースはわかりにくいものが結構あります。
特にプログラミング初心者の人にとってはとっつきにくい内容がほとんどだと思います。
そこで理解がしやすい2次ソースを見ようとするのですが、2次ソースを参考にするときは注意が必要です。
言ってしまえば2次ソースは正確な情報をわかりやすい表現に噛み砕いています。
その過程で1次元ソースの正しい情報が抜け落ちていることも考えられます。
本質を押さえ、不必要な情報を省いている2次ソースもあります。
つまり参考にしている2次ソースが正しいかどうかの判断が難しいということになります。
ここの見極めには少なくとも以下の2点があります。
- 複数の2次ソースを比較する
- (指標があれば)指標を見る
まず前者についてです。
複数の2次ソースを比較することで共通部分を見つけることができるはずです。
ソースによらず同じことが書かれている箇所は多くの人にとっての共通認識であり、本質(正しい内容)である可能性が高いです。
次に後者です。
Qiitaの記事のように、いいね数などの指標がある場合は、その指標が高いほど正しい内容を伝えている可能性が高いです。
ただ、これは本当に本質を押さえているからいいねを押しているかはわからないです。
記事の質がある程度悪くても、記事が読みやすい、または面白いといった別の要素でいいねを押している場合もあるからです。
ただし経験的にですが、いいねなどの指標が高い記事は、正しい内容のものが多いと思うので、複数のソースの比較をしつつ参考にしてみると良いでしょう。
最後に、情報には鮮度があります。
1次ソースは最新の情報をアップデートしてくれますが、2次ソースではそれが担保されていません。
2次ソースの内容が古いもので、最新の状況では推奨されていない内容の可能性もあります。
2次ソースをみるときは最新の内容が反映されているかのチェックも必要になります。
この記事も2次、3次、、、、(n次)ソースなので、内容を全て鵜呑みにせず、他のソースと比較または1次ソースを確認するようにしてください。
このトピックのまとめ
2次ソースの信頼性のポイント
- 2次ソースは正確な内容を押さえているかはわからない
- 複数の2次ソースを比較して、信憑性を確かる
- (指標があれば)高い指標の2次ソースは正しい内容の可能性が高い
- 2次ソースの内容は古い可能性もある
7-4. ChatGPTに聞くのもあり
ChatGPTに聞いてしまうのも1つの手です。
場合にもよりますがにChatGPTに聞いてみると、かなり的を射た回答を出してくれるような気がします。
聞く時には、プロンプト(ChatGPTへの命令)も工夫すると精度の良い回答を出してくれます。
例えば、「前提」「聞きたい本文」「条件1」「条件2」のように細かく項目を分けて指示を出すといった感じです。
「前提」について補足ですが、ここではChatGPTの立場を明示してあげます。例えば「あなたは凄腕のプログラマーです」といった具合です。
ChatGPTは漠然とした聞き方はでなく、具体を徐々に狭めるように命令してあげると聞きたい内容の回答を得やすくなります。
またChatGPTの回答は文脈を意識した内容で返ってくる可能性が高いです。
先程お伝えした「検索は文脈に合わせて」で使えるような単語を提示してくれる場合があります。
ピンポイントの回答が得られなくても、検索で使えるような単語を知るという意味でもChatGPTは有効だと思います。
ただしChatGPTも正しい内容を答えてくれるわけではありません。
2次ソースの時と同様、別のソースと比較することで信憑性を高めることが必要でしょう。
このトピックのまとめ
ChatGPTに聞く時のポイント
- プロンプトは項目を分けて細かく指示
- 文脈にあった回答をしてくれる可能性がある
- 普通に嘘をつくことがある
8. 公式ドキュメントに慣れる
公式ドキュメントを読むのは正直大変です。
日本語で読むのでさえ辛いことが多いのに、日本語がない公式ドキュメントもあります。
最初は2次ソースだけに頼るのも良いですが、将来的には公式ドキュメント読んで理解できるようになりましょう。
そもそもなぜ公式ドキュメントは読みにくいのでしょうか。
個人的的に思うことは、公式ドキュメントを読むときにそのサービスやアプリケーション、言語の全体像および周辺知識が足りないことが原因なのかなと思っています。
例えばですが、Pythonの公式ドキュメントでfor文の使い方や内容について調べようとして、ドキュメントを見てみると冒頭で以下のような文章が書かれています。(該当記事はこちら)
for 文は、シーケンス (文字列、タプルまたはリスト) や、その他の反復可能なオブジェクト (iterable object) 内の
要素に渡って反復処理を行うために使われます:
冒頭から文字列やタプル、リストについて記載されていますが、これらの型についてわかっていないと、そもそもここで説明していること自体がわからないですよね。
ちなみに型については公式ドキュメントのこちらに詳細が書かれています。
このように何かを調べようとして、公式ドキュメントを読んだときにさらにわからないことが出てくるから読みにくいのではないでしょうか。
AWSの公式ドキュメントなんかはその典型だと思います。
それではどのようにして公式ドキュメントに慣れていけば良いのでしょうか。
明確な答えではないかもしれませんが、公式ドキュメントで読みながら周辺の知識も身につけていくことが良いと思います。
Pythonの公式ドキュメントでも関連しているキーワードのリンクが設定されているので、深掘りしながら読み進めると、少なくとも読んでいる箇所の理解はできるようになるはずです。
この作業を行うと調べているドキュメントの文脈(環境や状況)も理解できるようになり、検索能力も高くなるはずです。
このトピックのまとめ
公式ドキュメントに慣れるポイント
- 公式ドキュメントを読みながら周辺の知識も合わせて身につけていく
9. リファクタリングでさらに読みやすく
9-1. リファクタリングとは
リファクタリングとは既存のコードを改善する一連のプロセスを指します。
目的はコードを改善することであり、振る舞い自体は変更しないことにあります。
リファクタリングの主な目標は、コードの可読性と保守性を高めることです。
整理され、きれいに書かれたコードは、他の開発者が理解しやすく、将来のエラーの特定や新機能の追加を容易にしてくれます。
また、リファクタリングはソフトウェアのパフォーマンスを向上させる可能性もあります。
不要なコードの削除や効率的なアルゴリズムの導入によって、アプリケーションの速度やリソースの使用効率を改善することができます。
9-2. 具体的な修正内容
実際にリファクタリングでどのようなこと行うのか。
実はすでに皆さんはリファクタリングの手法を知っています。
3.コーディングのポイントでお伝えしたことを既存コードに対して実践すれば良いのです。
リファクタリングだからと言って特別なことをする必要はありません。
読みやすいコードを書くことを意識するだけでOKです。
それでは、リファクタリングに関するトピックをお伝えします。
- 読みやすいコードを意識しよう
- 名前の付け方
- 型とは?
- 関数の内容はコンパクトに
- 説明変数とは
- 変数への書き込みは1度だけ
- if文を読みやすく
- ネストは浅く
- スコープ(範囲)を意識する
- 不要なコードは削除する
- 重複コードは避ける
- コメントの容量用法は適切に
- コードフォーマットで綺麗に
- マジックナンバーを避ける
9-3. リファクタリングのコツ
続いてリファクタリングをするときの注意点を3つお伝えします。
一気に修正を行わない
リファクタリングを小さな変更に分割することで、影響範囲が把握しやすくなり、管理も容易になります。
大規模な変更は予期しないバグや問題を起こすリスクが高く、それらを特定し、修正するのが難しくなります。
小さなステップで進めることにより、エラーが発生した場合、どの変更が原因であるかを特定しやすくなり、修正も容易になります。
また、小さな変更はテストしやすく、コードの品質を維持しながら進めることが可能です。
各ステップ後にコードをテストすることで、そのステップの変更が全体的な振る舞いに悪影響を及ぼしていないことを確認することができます。
リファクタリングを細かく行うことで、プロセス全体がより安全になります。
テスト結果が変わらないようにする
冒頭でも述べましたが、リファクタリングの目的はコードの構造を改善することであり、外部から見たときの振る舞いを変更しないことにあります。
既存のテストがリファクタリング前後で同じ結果を示すことにより、バグや問題が新しく発生していないことを確信できます。
これにより、品質を維持しながらコードの改善を進めることができます。
またテスト結果が変わらないことは、リファクタリングの進捗を確認するための基準となります。
各リファクタリングのステップ後にテストを実行し、期待通りの結果が得られることを確認することで、リファクタリングが正しく進行しているかどうかを判断できます。
したがって、リファクタリングにおいてテスト結果が変わらないことを保証することは、機能の安定性の維持、プロセスの安全性の確保、進捗のモニタリングといった複数の重要な側面があります。
性能の向上を目指さない
性能向上もリファクタリングの目的から外れてしまいます。
何度も書きますがリファクタリンはコードを改善し、それをより理解しやすく、保守しやすいものにすることです。
リファクタリングの目的は、コードの可読性、再利用性、および拡張性を高めることで達成されます。
性能の向上はこの目的から外れることが多く、リファクタリングの焦点をずらす可能性があります。
これらのリファクタリングのコツを抑えながら、より読みやすいコードへ改善するようにしていきましょう。
このトピックのまとめ
リファクタリングのポイント
- 以下の具体的な作業を行う
- 適切な名前をつける
- (動的型付け言語の場合)型を明示する
- 関数の処理を簡潔にする
- 説明変数を適用する
- if文を読みやすくする
- ネストは浅くする
- 不要なコードは削除する
- 重複コードは避ける
- コメントの容量用法は適切に
- コードフォーマットで綺麗に
- 一気に修正を行わない
- テスト結果が変わらないようにする
- 性能向上を目指さない
10. 資料作成で気をつけること
資料(以後、ドキュメント)作成もエンジニアにとっては大切な仕事です。
ここではドキュメントの役割と作成時のポイントをお伝えします。
10-1. ドキュメントの役割
ドキュメントはプロジェクトの全体像を把握したり、サービスの仕様について記載された資料になります。
すでに動いているプロジェクトに途中から参加した場合、まずはじめにドキュメントから目を通すことになります。
ドキュメントがわかりにくいと、プロジェクト全体に対する認識を間違う可能性があります。
もしくは既に参加している人に改めてドキュメントの内容について伺ってしまうといったコミュニケーションコストが発生してしまう可能性があります。
ドキュメントはプロジェクトの透明性を高める役割も果たします。
プロジェクトの目的、機能、制約、および設計の意図が記録されていると、全ての関係者が一貫した共通認識を持つことができます。
長期的な観点から見ると、ドキュメントはメンテナンスとサポートの役割もはたします。
プロジェクトのライフサイクルは長期にわたることが多く、時間の経過とともに初期の設計意図や実装の詳細が忘れられがちです。
ドキュメントは、将来のメンテナンス作業や機能の拡張を容易にするための重要なリソースとなります。
これらがドキュメントの大きな役割となります。
しかし、コードと同様でドキュメントも読みやすいものでなければいけません。
次のトピックではドキュメント作成時の具体的なポイントを紹介します。
10-2. ドキュメント作成のポイント
- 目的と対象読者を明確にする
ドキュメントの目的を明確にし、対象読者を特定することで、内容を特定のニーズに合わせて調整できます。例えば、この記事のように初心者向けの内容ならば基本的な概念から説明する必要があり、経験豊富な技術者向けにはより高度な内容を扱う必要があります。
- 全体と詳細を準備する
全体に関する資料と、詳細に関する資料を準備することで読み手の理解度が補強されます。全体に関する資料だけだと、漠然とした理解にとどまり、詳細だけの資料だと個々の関係性を見ることが難しくなります。
- 明確さと簡潔さを保つ
エンジニアが作成する技術的なドキュメントでは、複雑な情報を簡潔に伝えることが重要です。長い文や専門用語の使いすぎは読者を混乱させる可能性があります。要点を押さえて、そして簡単に説明することで、内容の理解が容易になり、記憶に残りやすくなります。
- 一貫性のあるフォーマットを使用する
ドキュメント内で一貫したフォーマット(見出しのスタイル、フォント、色使いなど)を使用することで、読者は文書全体を通して情報を追いやすくなります。これにより、必要な情報に素早くアクセスしやすくなります。また、そもそも汚いフォーマットの文章はコードと同様で読みたいとは思われません。
- 専門用語の適切な使用
専門用語は特定の技術分野の正確なコミュニケーションに不可欠ですが、読者が専門家でない場合は、これらの用語を簡単に説明するか、要点を漏らさないで噛み砕いて説明する必要があります。
- 画像や図を効果的に使用する
画像や図表は、テキストだけでは伝えにくい情報やプロセスを視覚的に示すのに有効です。これにより理解しやすくなり、読者の関心が保たれます。また、複雑な情報を簡略化し、より直感的に伝えることが可能になります。ちなみにですが、人には「認知特性」というものあります。これは目・耳・鼻などの主に五感を中心とした感覚器から入ってきたさまざまな情報を記憶したり、脳内で理解して表現したりする能力のことを言うそうです。テキストだけのドキュメントを避けた方が良いヒントになるので、気になったかたはこちらの記事を確認してみてください。
- レビューとフィードバックのプロセスを設ける
一旦完成したドキュメントは他の人のレビューをもらうようにしましょう。他人のレビューにより、作成者が見落としているかもしれない誤りや曖昧な点を指摘できます。さらに、異なる視点からのフィードバックは、ドキュメントの明瞭さと全体の質を上げてくれるかもしれません。
- 更新とメンテナンスの計画を立てる
ドキュメントにも鮮度があります。ドキュメント作成当時は良かった内容も、プロジェクトが進むにつれて新しい機能が追加されたり、アーキテクチャーが変更になったりし、正しい内容を伝えない可能性が出てきます。ドキュメントの内容にズレが出ないように、定期的な更新をすることで、ドキュメントが常に最新の情報を反映するように保ちます。
このトピックのまとめ
ドキュメント作成時には以下のポイントを抑えること
- 目的と対象読者を明確にする
- 全体と詳細に関する資料を準備する
- 明確さと簡潔さを保つ
- 一貫性のあるフォーマットを使用する
- 専門用語の適切な使用
- 画像や図を効果的に使用する
- レビューとフィードバックのプロセスを設ける
- 更新とメンテナンスの計画を立てる
11. Gitで管理
Gitについてお伝えしようと思いますが、Gitについてはより詳しく書かれている記事がかなりありますので、ここでは概要および簡単な説明に留めておきます。
11-1. Gitってなに?
Git(ギット)は、プログラムのソースコードなどの変更履歴を記録・追跡するための分散型バージョン管理システムである。
とwikipwdiaで説明されています。
分散型というのは、「各自のパソコン上にリポジトリを作成し、任意のタイミングで任意のリポジトリに同期するタイプ」ということです。
バージョンとは日本語に言い換えれば「第xxx版」といったイメージになります。
言葉だけだとイメージしにくいですよね。
後ほどGitの用語の説明のところで図を用いて説明をしようと思いますので、そこでもう少し理解が深まるはずです。
先程の説明を簡単に言い換えると「誰がどのタイミンングで、何に対してどのような変更を加え、それが第xxx版として管理されているシステム」のようなイメージです。
なお、Gitと混同されがちなのがGitHubです。
GitHubとはGitを利用した開発者のためのWebサービスです。
要はGitはツールであり、GitHubはサービスといった具合です。
このトピックのまとめ
Gitとは何かのポイント
- Gitはソースコードの変更履歴を管理する分散型バージョン管理システム
- GitHubはGitを利用した開発者のためのWebサービス
11-2. Gitは何のためにあるのか
まず初めに、エクセルやワードのファイルを変更したときのことをイメージしてください。
ファイルの中身を変更して上書きしたとき、過去の内容を復元することはできませんよね。
なので、オリジナルのファイルをコピーして自分用の修正ファイルを作って中身を変更したりしていませんでしたか。
これが複数人で行われると、ディレクトリの中身が以下のように煩雑になってしまいます。
original.txt
original_suzuki.txt
original_tanaka.txt
original_fix.txt
original_fix_2.txt
copy_original.txt
これだとどれが最新のファイルなのか非常にわかりにくいです。
サービスやアプリケーションの開発だと、さらにファイルの数も増え、修正や変更が多くなるので、カオスな状態になってしまいます。
しかしGitを使うと、このカオスな状況を回避することができます。
先程お伝えしたように、Gitは「誰がどのタイミンングで何に対してどのような変更を加え、それが第xxx版として管理されているシステム」です。
バージョン(第xxx版)で管理されることで、そのファイルがいつ・誰によって・どのように変更されたのかがわかります。
またこの変更が履歴として残るので、変更前後の差分がわかります。
つまり、先程のエクセルやワードの例のように、ファイルを複製して修正を加える必要がなくなるということです。
またGitは変更履歴から、過去のある時点でのファイル内容を復元することも可能です。
最新のファイルの内容が誤っているなと思ったら、正しい時点の内容まで戻って復元することが可能です。
このようにGitを使うと、ディレクトリやファイルが煩雑にならないように管理することができます。
このトピックのまとめ
Gitは何のためにあるのかのポイント
- ファイルの変更の履歴が残る
- 履歴のある時点までのファイル内容を復元することが可能
- チーム開発の煩雑さを無くしてくれる
11-3. Gitの用語とコマンド
GitおよびGitHubを使う際に多くの用語が出てきます。
この用語を理解しないことにはGitを使いこなせないので、ここではいくつかの基本的な用語を紹介したいと思います。
なお、途中でサンプルコードを用いますが、前提としてはローカルのdevelopブランチにおいてコマンドを実行するものとします。(「(develop) コマンド」の表記)
repository(リポジトリ)
repositoryとはファイルやデータ、ディレクトリの状態を保存する場所です。repositoryでは変更履歴が保存されています。(単に変更後の最新の内容だけが保存されているわけではなく、これまでの変更内容の形跡が保存されている)
remote(リモート)
remoteとはオンライン上にある皆がアクセスできる共通の場所のことです。
remote repositoryはオンライン上の皆がアクセスできるrepositoryのことになります。
local(ローカル)
localとは手元のパソコンのことを言います。
local repositoryは手元のパソコンにあるrepositoryのことになります。
開発のイメージはローカルで機能の修正や変更を行い、それをリモートに反映させ、別の開発者に共有させるような感じです。
(画像はこちらのサイトから引用しています。)
branch(ブランチ)
branchのイメージを掴むために、初めに以下の図を見てください。
(画像はこちらのサイトから引用しています。)
「feature A-1」「feature A」「main」「feature B」というブランチがあり、右に進むほど新しい状況を示しています。
この図からわかることは「main」ブランチが元となり他のブランチが派生していることです。
一般的にではありますが、「main」ブランチが本番環境の変更を管理しているブランチになります。(prodまたはproductionという名前の場合もあります。)
このmainブランチから他のブランチを派生(通称、ブランチをきる)ことで、mainブランチへ影響を与えることなしに、それぞれのブランチで作業を進めることができます。
例えば、3-17. オブジェクト指向プログラミングで出したゲームの例で見てみましょう。
「ゲームが終わった後にエンディングロールを出したい」と考えた時に、mainブランチ(ゲームがすでに動いている環境)から、feature Aブランチをきります。
feature Aで機能の追加を進めているうちに、「エンディングロール後はゲーム開始画面に戻る」ようにしたいと思い、さらにfeature A-1ブランチをきります。
ここで新しく作られたブランチ(feature Aとfeature A-1)での機能追加の作業は、mainブランチへ何の影響も与えません。
機能追加が完了したらfeature Aに対してfeature A-1をmergeし、さらにmainに対してfeature Aをmergeします。(mergeについては後述)
これによりmainブランチへ何の影響を与えることもなく、機能の追加をすることができます。
ここではわかりやすく説明するためにブランチとはどういったものかをお伝えしましたので、より詳しく知りたい方はこちらの記事をぜひ読んでみてください。
fetch(フェッチ)
リモートリポジトリの最新の変更内容をローカルリポジトリに取り入れる操作です。
後ほどmergeでも説明しますが、あくまでも取り入れるだけで、ローカルリポジトリのブランチに変更を反映させるものではないです。
以下のコマンドでリモートの全ての変更を反映させます。
(develop) git fetch
# リモートリポジトリの全ての変更を取得する
特定のリモートリポジトリのみを取得したい場合は以下のように、リモートリポジトリ名を追記します。
(develop) git fetch リモートリポジトリ名
(例)
(develop) git fetch origin
# リモートのoriginというリポジトリの全ての変更を取得する
さらに特定のリモートの特定のブランチのみを取得したい場合は、以下のようにリモートリポジトリ名とブランチ名を追記します。
(develop) git fetch リモートリポジトリ名 ブランチ名
(例)
(develop) git fetch origin develop
# リモートのoriginというリポジトリ名のdevelopブランチの変更を取得する
merge(マージ)
異なるブランチで行われた変更を統合し、1つのブランチにまとめる操作です。
fetchで取り入れたリモートリポジトリの変更をローカルの特定のブランチに反映させるのはmergeで行います。
以下のコマンドでmergeを実行します。
(develop) git merge ブランチ名
(例)
(develop) git merge feature-1
# ローカルのdevelopブランチにfeature-1ブランチの変更を反映させまとめる
pull(プル)
fetchとmergeを同時に行う操作です。
以下のコマンドでpullを実行します。
(develop) git pull リモートリポジトリ名 ブランチ名
(例)
(develop) git pull origin develop
# リモートリポジトリのoriginのdevelopブランチの変更を、ローカルのdevelopブランチへ反映させる
ここでpullとfetchの使い分けについて、簡単に補足です。
pullを実行するとfetcgとmergeが行われてしまいます。
単にリモートリポジトリの中身を確認したいならば、fetchを使います。
add(アッド)
変更したファイルをステージングする操作です。
以下のコマンドで実行します。
(develop) git add ファイル名
(例)
(develop) git add template.yml
# ローカルで変更したtemplate.ymlをステージングする。
staging(ステージング)
ファイルの変更をバージョン管理の対象とするために登録することです。
先程の例だとaddで指定されたtemplate.ymlファイルの変更がバージョン管理の対象になったことになります。
ステージングを行う意味は、バージョン管理の対象を選ぶことになります。
具体的にいうと、smaple_1.pyとsample_2.pyというファイルがあり、どちらもローカルで修正を行なっていたとします。
この時にsample_1.pyの修正は終わったけど、sample_2.pyはまだ完了していない場合、addのファイル指定でバージョン管理の対象を選ぶことができます。
こうすることでリモートリポジトリに中途半端なファイルの変更履歴を残さないようにすることができます。
commit(コミット)
ステージングされた変更内容をローカルリポジトリに反映させる操作です。
ステージングされたファイルの変更内容は、その時点ではまだローカルリポジトリに反映されていません。
commitによって初めてローカルリポジトリに反映されます。
以下のコマンドでcommitを実行します。
(develop) git commit
(例)
(develop) git commit
# ステージングされている変更をローカルリポジトリへ反映
なお、このコマンドを叩くとテキストエディターが開いて、コミットメッセージを記載することを求められます。
この一手間で面倒なので、以下のようにオプションコマンドを用いてコミットメッセージを同時に残すようにした方が便利です。
(develop) git commit -m 'コミットメッセージ'
(例)
(develop) git commit -m 'エンディングロール機能の追加'
# コミットメッセージと共にステージングされている変更をローカルリポジトリへ反映
コミットメッセージ
コミットの際に残すメッセージ。どのような変更を加えたのかをメッセージに残すことで、他のメンバーにわかりやすく変更内容を共有することができる。
push(プッシュ)
ローカルリポジトリの内容をリモートリポジトリへ反映させる。
以下のコマンドでpushを実行します。
(develop) git push リモートリポジトリ名 ブランチ名
(例)
(develop) git commit origin develop
# ローカルリポジトリの変更履歴をリモートリポジトリoriginのdevelopブランチへ反映させる
conflict(コンフリクト)
異なるブランチやコミットで同じファイルの同じ箇所が編集され、Gitがそれを自動的に解決できない状態を指します。
コンフリクトが起きると以下のようなメッセージが出て修正を求められます。
<<<<<<< HEAD
ここはローカルブランチの変更です
=======
ここはリモートブランチの変更です
>>>>>>> リモート/ブランチ名
この時にどちらの変更内容が正しいのかを選ばなければなりません。
自分が加えた変更ならばわかると思うのですが、他の人が加えた変更なら、その人に確認をとり、どちらの変更を残すか選ぶようにしましょう。
このトピックのまとめ
Gitの用語
- repository(リポジトリ):ファイルやデータ、ディレクトリの状態を保存する場所
- remote(リモート):オンライン上にある皆がアクセスできる共通の場所
- local(ローカル):手元のパソコンのこと
- branch(ブランチ):分岐された作業場所
- fetch(フェッチ):リモートの最新変内容を取得
- merge(マージ):異なるブランチの内容を統合
- pull(プル):fetchとmergeを同時に実行
- add(アッド):変更履歴をステージング
- staging(ステージング):バージョン管理の対象を登録
- commit(コミット):ステージングされた内容をリポジトリに反映させる
- コミットメッセージ:commitに残すメッセージ
- push(プッシュ):ローカルリポジトリの内容をリモートリポジトリへ反映
- conflict(コンフリクト):ファイル内容の競合
11-4. Gitを使う時の注意点
Gitは開発にとって非常に便利ですが、注意しなければ開発に悪影響を及ぼすこともあります。
ここでは個人的に気をつけた方が良いと思う点をお伝えしようと思います。
ブランチの使い分けを理解する
ブランチは一般的に意味を持って使い分けがされています。
本番環境のブランチはprod(production)、テスト環境のブランチはtest、開発環境のブランチはdev(develop)、機能追加や修正用のブランチはfeature-***といった具合です。
上記はあくまでも一例であり、必ずこのようなブランチ名となっているわけではないです。
ただブランチ毎に使い分けがされていることを理解する必要があるということです。
例えば、アプリケーションやサービスの本番環境(prod)に対して、開発環境の(dev)のブランチをpushしてしまったら、動作が不安定な内容を本番環境に反映させてしまうことになります。
このような事故を防ぐためにも、それぞれのブランチの役割を意識する必要があります。
ローカルのリポジトリは最新のものにする
開発では、あるブランチから作業(feature)ブランチを切って機能修正や変更を行なっていくのですが、できるだけ最新の内容を反映するようにしておきましょう。
例えば作業ブランチを1ヶ月前に切り、元のブランチの最新の内容を反映させないで作業を進めていると、修正完了後にpushした時にconflictが発生する可能性があります。
コミットメッセージはわかりやすい要約にする
コミットメッセージはそのコミットで何が変更されたかをわかりやすく、簡潔に書かないといけません。
他のチームメンバーが変更の中身を確認しなくてもわかるように書かないと、変更点が不明でコードの中身を確認する必要が出てきます。
またコミットメッセージがどうしても長くなってしまうのも別の視点で問題です。
そもそも機能の修正や変更は1つのコミットでたくさん行うものではないです。
細かくタスクを切り分け修正や変更を行なっていくべきなので、コミットメッセージがどう頑張っても長くなってしまうのは、タスクの細分化ができていないことになります。
この場合はまずタスク細分化から見直した方が良いです。
なお、こちらの記事にはコミットメッセージの書き方の詳細が書かれていますので、ぜひ確認してみてください。
force pushをしない
間違った内容の変更をリモートにpushしてしまい、その変更を取り消そうとforce pushするのは原則しないようにしましょう。
Gitは変更履歴を管理しています。
誤った内容の変更だとしてもその履歴は残っています。
誤った変更の履歴を削除する前にブランチを切った人がいた場合、その人のブランチには削除前の履歴が残っていることになるので、履歴の統一ができなくなります。
force push の代わりにrevertを使うようにしましょう。
revertは変更の取り消しをするコマンドですが、履歴まで削除をしません。
変更を取り消したという履歴が残ります。
これで履歴の統一がされた状態で変更を取り消すことができます。
このトピックのまとめ
Gitを使う時の注意点
- ブランチの使い分けを意識する
- conflictを避けるためにも、ローカルのブランチは最新の内容を反映させておく
- コミットメッセージはわかりやすい要約にする
- コミットメッセージがどうしても長くなる場合はタスクの細分化から見直す
- 歴々の統一ができなくなるのでforce pushh
なお、Gitについてこちらの記事でわかりやすく説明がされていますので、ぜひ確認してみてください。
ここで紹介した図もこちらの記事から引用させていただいております。
12. よく使うLinuxコマンド一覧
Linuxコマンドとは、Linuxオペレーティングシステム(OSがLinux)においてターミナルやコマンドラインインターフェース(略称CLI)を通じて実行される命令です。
これらのコマンドはシステムの管理、ファイル操作、プロセス管理、ネットワーク設定など、さまざまなタスクを実行するために用いられます。
プログラミングをしているとコードを書くだけではなく、新しいファイルを作ったり、削除したりといった作業も必ず出てきます。
なのでLinuxコマンドを知ることもプログラミングでは非常に大切です。
ここではよく使われるLinuxコマンドをサンプルコードを用いて紹介していきます。
サンプルコードは絶対パスで記載しています。絶対パスと相対パスについては説明をしないので、気になる方は調べてみてください。
オプションコマンドについては網羅しないですが、必要だと思うオプションコマンドについては適宜説明を追加します。
-
pwd
「print working directory」の略で、作業しているディレクトリ(作業ディレクトリ)の絶対パスを表示するために使用されます。
% pwd
/home/username
上記はpwdコマンドで現在 /home/username ディレクトリにいることを表示しています。
-
ls
「list segments」の略で、指定した作業ディレクトリ内のファイルやサブディレクトリの一覧を表示するために使用されます。
% pwd
/home/username
% ls
resume.pdf project_report.docx photos Documents
まずpwdで現在 /home/username ディレクトリにいることを確認しています。
その後、lsで現在いるディレクトリ内にあるファイルとディレクトリを確認しています。
この場合、ファイルはresume.pdf、project_report.docxがあり、ディレクトリはphotos, Documentsがあることが確認できました。
lsは現在いるディレクトリの隠しファイルや隠しディレクトリ(名前が.から始まるファイルやディレクトリ)まで確認することができません。これらを確認するためには -aのオプションコマンドを追加する必要があります。このaは「all」の略です。
ls -a
-
touch
このコマンドは新しい空のファイルを作成する、または既存のファイルのタイムスタンプを更新するために使用されます。指定したファイルが無ければ新しいファイルを作成し、既存のファイルがある場合はファイルの中身を変更せずタイムスタンプを更新します。ほとんどの場合は新しいファイルを作成するために使用されます。
touch ファイル名で新しいファイルを作成します。
% pwd
/home/username
% ls
resume.pdf project_report.docx photos Documents
% touch notes.txt
% ls
resume.pdf project_report.docx photos Documents notes.txt
pwd、lsまでは先ほど同様の内容になります。
touchでnotest.txtという新しいファイルを作成し、その後lsでnotes.txtファイルが作成されたことを確認できました。
-
cd
「change directory」の略で、ユーザーが現在いるディレクトリから移動するために使用されます。
cd 移動したいディレクトリで指定したディレクトリへ移動します。
% pwd
/home/username
% cd /home/username/Documents
% pwd
/home/username/Documents
pwdで現在いるディレクトリを確認しています。
cdでDocumentsディレクトリへ移動し、その後pwdで現在いるディレクトリが/home/username/Documentであることを確認しています。
-
mkdir
「make directory」の略で、新しいディレクトリを作成するために使用されます。
mkdir ディレクトリ名で新しいディレクトリを作成します。
# 先ほどの続きのディレクトリ(/home/username/Documents)から
% cd ..
% pwd
/home/username
% ls
resume.pdf project_report.docx photos Documents notes.txt
% mkdir Projects
% ls
resume.pdf project_report.docx photos Documents notes.txt Projects
まず cd .. についてですが、これは現在いるディレクトリの1つの上の階層に移動するコマンドです。
その後、pwd、lsでこれまで同様の操作をしています。mkdirでProjectsディレクトリを作成、その後lsでProjectsディレクトリを確認できました。
-
mv
「move」の略で、ファイルやディレクトリを移動する、または名前を変更するために使用されます。
まずはファイルやディレクトリを移動する方から確認してみましょう。
move 移動させたいファイル名 移動先ディレクトリ名 でファイルを移動させたいディレクトリへ移動します。
# 先ほどの続きのディレクトリ(/home/username)から
% ls
resume.pdf project_report.docx photos Documents notes.txt Projects
% mv resume.pdf /home/username/Documents/
% ls
project_report.docx photos Documents notes.txt Projects
% cd /home/username/Documents/
% ls
resume.pdf
mvでresume.pdfファイルをDocumentディレクトリへ移動しています。
その後lsで現在いるディレクトリからresume.pdfが無くなっていることを確認できます。
次にcdでDocumentディレクトリへ移動し、lsでresume.pdfが移動していることが確認できます。
次はファイル名の変更についてです。
move 変更前ファイル名 変更後ファイル名 でファイル名を変更できます。
# 先ほどの続きのディレクトリ(/home/username/Documents)から
% ls
resume.pdf
% mv resume.pdf resume_user_1.pdf
% ls
resume_user_1.pdf
lsでresume.pdfファイルを確認しています。
その後mvでresume.pdfからresume_user_1.pdfへとファイル名を変更し、lsで確認をしています。
-
cp
「copy」の略で、ファイルやディレクトリの内容をコピーするために使用されます。
cp コピー元ファイル名 コピー先ディレクトリでファイルを指定したディレクトリへコピーできます。
# 先ほどの続きのディレクトリ(/home/username/Documents)から
% cd ..
% pwd
/home/username
% ls
project_report.docx photos Documents notes.txt
% cp project_report.docx /home/username/Documents/
% ls
project_report.docx photos Documents notes.txt
% cd /home/username/Documents/
% ls
resume_user_1.pdf project_report.docx
cpでproject_report.docxファイルを/home/username/Documents/ディレクトリへコピーしています。
その後lsで現在いるディレクトリのファイルおよびディレクトリを確認しています。
次にcdで/home/username/Documents/へ移動し、lsでproject_report.docxがあることが確認できています。
-
rm
「remove」の略で、ファイルやディレクトリを削除するために使用されます。このコマンドで削除したファイルやディレクトリは復元できないので注意が必要です。
rm 削除したいファイル名で指定したファイルを削除できます。
ディレクトリを削除する場合は rm -r 削除したいディレクトリ になります。
# 先ほどのディレクトリ(/home/username/Documents/)の続きから
% rm project_report.docx
% ls
resume_user_1.pdf
rmでproject_report.docxファイルを削除しています。
次にlsでproject_report.docxが削除されたことが確認できます。
-
find
指定されたディレクトリ内でファイルやディレクトリを検索するために使用されます。このコマンドは非常に強力で、ファイル名、ファイルタイプ、サイズ、パーミッション、最終更新日時など、様々な基準で検索を行うことができます。
find 検索対象ファイル名 or ディレクトリ名で検索
# 先ほどのディレクトリ(/home/username/Documents/)の続きから
touch project_report.docx
% ls
resume_user_1.pdf project_report.docx
% find project_report.docx
project_report.docx
touchで先ほど削除したproject_report.docxファイルを作成。
次にlsでproject_report.docxがあることを確認できました。
同様にfindでも確認できました。
しかしfindの効果的な使い方はファイル名の指定よりも拡張子などの指定になります。
具体例として、拡張子を指定する場合 find 検索先フォルダ -name 拡張子の指定 で実施することができます。
サンプルコードをみてみましょう。
# 先ほどのディレクトリ(/home/username/Documents/)の続きから
touch project_report_2.docx project_report_3.docx
% ls
resume_user_1.pdf project_report.docx project_report_2.docx project_report_3.docx
% find . -name \*.docx
./project_report.docx
./project_report_2.docx
./project_report_3.docx
touchで拡張子が .docxのファイルを2つ作成しています。
その後findの -name オプションコマンドで .docx を指定し、拡張子がdocxのファイルのみを検索しています。
ここで、find . についてですが、.は現在いるディレクトリを示しています。
この場合は/home/username/Documents/になります。
.の箇所を書き換えると以下になります。
% find /home/username/Documents/ -name \*.docx
/home/username/Documents/project_report.docx
/home/username/Documents/project_report_2.docx
/home/username/Documents/project_report_3.docx
上記を比較すると .を使った方が簡潔になることがわかりますね。
他のオプションコマンドについては、こちらの記事で確認してみてください。
-
cat
「concatenate」の真ん中あたりのcatからきており、ファイルの内容を表示したり、複数のファイルを連結して表示したりするために使用されます。concatenateの意味は「連結」になります。
まずは1つのファイルの内容を表示する方からみてみましょう。
cat ファイル名 でファイルの内容を表示できます。
# 先ほどのディレクトリ(/home/username/Documents/)の続きから
% cat project_report.docx
This project is over
catでproject_report.docxファイルの中身を確認できました。
このファイルには「This project is over」のテキストが記載されています。
次にファイルを連結した内容表示ついて確認してみましょう。
cat ファイル名_1 ファイル名_2 で2つのファイルを連結して内容を表示できます。
# 先ほどのディレクトリ(/home/username/Documents/)の続きから
% cat project_report.docx project_report_2.docx
This project is over
Because we reached the goal
project_report_2.docxには「Because we reached the goal」のテキストが記載されています。
連結したためproject_report.docxの内容の後ろに追加で表示されています。
なお、連結できるファイルは2以上でも大丈夫です。
またcatによって、ファイルの中身を別ファイルに書き写すこともできます。
詳しくはこちらの記事で確認してみてください。
-
diff
「difference(差分)」の略称で、2つのテキストファイルやディレクトリの間の差分を比較し、異なる箇所を特定するのに使用されます。
diff ファイル名_1 ファイル名_2で2つのファイルを確認できます。
# 先ほどのディレクトリ(/home/username/Documents/)の続きから
% cat project_report.docx
I am genius
How are you ?
% cat project_report_2.docx
I am foolish
How are you ?
% diff project_report.docx project_report_2.docx
1c1
< I am genius
---
> I am foolish
diffの動作を確認するためにproject_report.docx と project_report_2.docx `の中身を変更しています。
まずcatでproject_report.docxとproject_report_2.docxの中身を確認しています。
それぞれ2行目はHow are you ?で同じですが、1行目が異なっています。
その後、diffでファイルの差分を確認していますが、1行目のみが差分ありとして出力されています。
diffはオプションが豊富にあるので用途に合わせて見やすさを変えることができます。
詳しくはこちらの記事に書かれていますので、気になる方は確認してみてください。
-
grep
「Global Regular Expression Print」の略称で、テキストファイル内で特定のパターン(正規表現や文字列)を検索し、マッチした行を出力するために使用されます。
grep パターン ファイル名で正規表現にマッチする行を出力します。
なお、正規表現については拙著ではございますが私が昨年書いた記事を見ていただければ幸いです。
# 先ほどのディレクトリ(/home/username/Documents/)の続きから
% cat project_report_3.docx
This is a sample file for demonstrating grep.
You can search for specific patterns using grep.
It's a very useful command in Linux.
% grep "Linux" sample.txt
It's a very useful command in Linux.
まずcatでproject_report_3.docxの中身を確認しています。
その後、grepでLinuxに一致するパターンを含む行を出力しています。
-
chmod
「change mode」の略称で、ファイルやディレクトリのパーミッション(アクセス権限)を変更するために使用されます。ファイルやディレクトリのパーミッションは、所有者、所有グループ、その他のユーザーに対する読み取り、書き込み、実行の権限を制御します
chmod モード ファイル名でファイルの権限を変更します。
chmodの説明の前に、ファイルやディレクトリのパーミッションについてサンプルコードで確認しましょう。
# 先ほどのディレクトリ(/home/username/Documents/)の続きから
% mkdir Archive
% ls
Archive project_report.docx project_report_2.docx
project_report_3.docx resume_user_1.pdf
% ls -l
total 24
drwxr-xr-x 2 qiita_taro staff 64 11 29 17:36 Archive
-rw-r--r-- 1 qiita_taro staff 26 11 29 16:59 project_report.docx
-rw-r--r-- 1 qiita_taro staff 27 11 29 16:58 project_report_2.docx
-rw-r--r-- 1 qiita_taro staff 132 11 29 17:10 project_report_3.docx
-rw-r--r-- 1 qiita_taro staff 0 11 29 16:42 resume_user_1.pdf
最初に新しくArchiveディレクトリを作っています。
その後、lsで現在いるディレクトリのファイルとディレクトリを確認した後、ls -lで各ファイルとディレクトリのパーミッションを確認しています。
一番右側にファイル名やディレクトリ名があり、一番左には謎の10桁の文字列があります。
この謎の10桁が、それぞれのファイルやディレクトリのパーミッションを表しています。
10桁の文字列はそれぞれの桁に意味があります。左から順番に説明すると
- 1番目はファイルかディレクトを示す。ファイルなら
-、ディレクトリならd - 2~4番目は所有者の権限
- 5~7番目は所有グループの権限
- 8~10番目はその他のユーザーの権限
を意味しています。
もう少し具体的に project_report.docxのパーミッション-rw-r--r--を分割して、それぞれ確認しましょう。
-: project_report.docxがファイルであることを示す
rw-: 所有者の権限は「読み取り」と「書き込み」ができる
r--: 所有グループの権限は「読み取り」のみできる
r--: その他のユーザーの権限は「読み取り」のみできる
となっています。
rが「読み取り」 wが「書き込み」を意味しています。
Archive のdrwxr-xr-xでも確認しましょう。
d: Archiveがディレクトリであることを示す
rwx: 所有者の権限は「読み取り」、「書き込み」、「実行」ができる
r-x: 所有グループの権限は「読み取り」と「実行」ができる
r-x: その他のユーザーの権限は「読み取り」と「実行」ができる
となっています。
基本的にパーミッションはr、w、xのみになります。
パーミッションがどういったものか何となく分かったと思いますので、次にchomodについて確認していきましょう。
chmod モード ファイル名でファイルのパーミッションを変更します。
ここのモードには3桁の数値を指定することになります。
それぞれの桁には以下のような意味があります。
- 最初の桁: 所有者の権限
- 2番目の桁: 所有グループの権限
- 3番目の桁: その他のユーザーの権限
ここで各桁の数値は読み取り(4)、書き込み(2)、実行(1)の値を合計して指定します。
例えば、読み取りと実行の権限を持つ場合は 4 + 1 = 5 となります
それではサンプルコードで確認しましょう。
# 先ほどのディレクトリ(/home/username/Documents/)の続きから
% ls -l
total 24
drwxr-xr-x 2 qiita_taro staff 64 11 29 17:36 Archive
-rw-r--r-- 1 qiita_taro staff 26 11 29 16:59 project_report.docx
-rw-r--r-- 1 qiita_taro staff 27 11 29 16:58 project_report_2.docx
-rw-r--r-- 1 qiita_taro staff 132 11 29 17:10 project_report_3.docx
-rw-r--r-- 1 qiita_taro staff 0 11 29 16:42 resume_user_1.pdf
% chmod 500 project_report.docx
% ls -l
otal 24
drwxr-xr-x 2 babakazuhei staff 64 11 29 17:36 Archive
-r-x------ 1 babakazuhei staff 26 11 29 16:59 project_report.docx
-rw-r--r-- 1 babakazuhei staff 27 11 29 16:58 project_report_2.docx
-rw-r--r-- 1 babakazuhei staff 132 11 29 17:10 project_report_3.docx
-rw-r--r-- 1 babakazuhei staff 0 11 29 16:42 resume_user_1.pdf
まずls -lで各ファイルとディレクトリのパーミッションを確認しています。
その後chmodでproject_report.docxのパーミッションを変更しています。
元々は-rw-r--r--だったものが-r-x------に変更されています。
つまり、以下のようにパーミッションが変更されています。
| 変更前/後 | 所有者のパーミッション | 所有グループのパーミッション | その他のユーザーのパーミッション |
|---|---|---|---|
| 前 | 読み取りと書き込み | 読み取り | 読み取り |
| 後 | 読み取りと実行 | なし | なし |
もう一度コマンドを確認しましょう。
chmod 500 project_report.docxのモードが500となっています。
これは
- 所有者に読み取り(4)と実行(1)のパーミッションを付与する(一番左の桁に合計値5を指定)
- 所有グループにパーミッションを付与しない(真ん中の桁に合計値0を指定)
- その他のユーザーにパーミッションを付与しない(一番右の桁に合計値0を指定)
の変更をしていることになります。
もう一つサンプルを見てみましょう。
# 先ほどのディレクトリ(/home/username/Documents/)の続きから
% ls -l
otal 24
drwxr-xr-x 2 babakazuhei staff 64 11 29 17:36 Archive
-r-x------ 1 babakazuhei staff 26 11 29 16:59 project_report.docx
-rw-r--r-- 1 babakazuhei staff 27 11 29 16:58 project_report_2.docx
-rw-r--r-- 1 babakazuhei staff 132 11 29 17:10 project_report_3.docx
-rw-r--r-- 1 babakazuhei staff 0 11 29 16:42 resume_user_1.pdf
% chmod 655 project_report_2.docx
% ls -l
total 24
drwxr-xr-x 2 babakazuhei staff 64 11 29 17:36 Archive
-r-x------ 1 babakazuhei staff 26 11 29 16:59 project_report.docx
-rw-r-xr-x 1 babakazuhei staff 27 11 29 16:58 project_report_2.docx
-rw-r--r-- 1 babakazuhei staff 132 11 29 17:10 project_report_3.docx
-rw-r--r-- 1 babakazuhei staff 0 11 29 16:42 resume_user_1.pdf
今度はproject_report_2.docxのパーミッションを変更しています。
先ほどと同様に確認してみましょう。
| 変更前/後 | 所有者のパーミッション | 所有グループのパーミッション | その他のユーザーのパーミッション |
|---|---|---|---|
| 前 | 読み取りと書き込み | 読み取り | 読み取り |
| 後 | 読み取りと書き込み | 読み取りと実行 | 読み取りと実行 |
上記のように所有グループとその他のユーザーの権限が変わっています。
また所有者自身は権限が変更されていない点にも注意してください。
少し長くなってしまいましたが、chmodについての大まかな説明は以上となります。
なお、chmodについてはこちらの記事に詳細が書かれていますので、ぜひ確認してみてください。
-
vi
このコマンドはLinuxおよびUnix系システムで使用されるテキストエディタを起動します。起動したテキストエディタではテキストファイルの編集、コードの記述、設定ファイルの編集など、さまざまな用途で使用されます
vi ファイル名でエディタを開いて編集等を行うことができます。
viはテキストエディタなのでここでは使い方について説明しません。
詳しくはこちらの記事
-
curl
「Client URL」の略で、LinuxおよびUnix系システムで使用されるコマンドラインツールです。URLを使用してデータの送受信を行うために使用されます。curlを使用することで、Webページのダウンロード、APIリクエストの送信、ファイルのアップロードなど、さまざまなネットワーク関連の操作を実行できます。
curl URLで指定したURLにリクエストを送ることができます。
ここではGETのリクエストの例を確認してみます。
% curl http://abehiroshi.la.coocan.jp/
# 出力
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=Shift_JIS">
<meta name="GENERATOR" content="JustSystems Homepage Builder Version 20.0.6.0 for Windows">
<meta http-equiv="Content-Style-Type" content="text/css">
<title>�������̃z�[���y�[�W</title>
</head>
<frameset cols=18,82>
<frame src="menu.htm" marginheight="0" marginwidth="0" scrolling="auto" name="left">
<frame src="top.htm" marginheight="0" marginwidth="0" scrolling="auto" name="right">
<noframes>
<body></body>
</noframes>
</frameset>
</html>%
これは阿部寛さんのホームページに対してGETリクエストを送信し、ホームページの情報を取得しています。
このようにcurlコマンドを使えばコマンドラインからリクエストを送ることが可能になります。
-
source
シェルスクリプトやシェルの設定ファイルを現在のシェルセッションに読み込むために使用されます。具体的には、指定したファイルを現在のシェルセッションに実行することができます。これにより、環境変数の設定やシェル関数の定義などが適用されます。
source ファイル名で実行できます。
sourceコマンドの使い方についてはこちらの記事に詳しく書かれていますので確認してみてください。
-
history
コマンド履歴を表示するために使用されます。
% history
1215 ls -l
1216 ls
1217 ls -l
1218 mkdir Archive
1219 ls
1220 ls -l
1221 chmod 500 project_report.docx
1222 ls -l
1223 chomod 644 project_report_2.docx
1224 chmod 644 project_report_2.docx
1225 ls -l
1226 chmod 655 project_report_2.docx
1227 ls -l
1228 curl https://www.google.com/
1229 curl http://abehiroshi.la.coocan.jp/
1230 curl -X POST http://abehiroshi.la.coocan.jp/
これまでの叩いてきたコマンドが確認できますね。
-
echo
指定したテキストを標準出力に表示するために使用されます。また、シェルスクリプトやプログラム内で変数の値やメッセージを表示するのにも使われます。
% echo 'I am genius'
I am genius
これは単純にI am genius という文字列を出力しているだけです。
変数に代入した場合も確認してみましょう。
% my_status='I am foolish'
% echo $my_status
I am foolish
サンプルコードはmy_statusという変数にI am foolishという文字列を代入し、echoでmy_statusの中身を出力しています。
-
head
テキストファイルの先頭から指定した行数分の内容を表示するために使用されます。デフォルトでは、テキストファイルの先頭から最初の10行を表示します。
headで最初の10行を表示できます。
サンプルコードで確認するために、project_report_3.docxの中身を以下のように修正しました。
1. This is a sample file for demonstrating grep.
2. You can search for specific patterns using grep.
3. It's a very useful command in Linux.
4. Grep, short for "Global Regular Expression Print," is a powerful command-line utility in Linux that allows you to search for specific patterns within text files or streams.
5. It uses regular expressions to define search criteria, making it a versatile tool for finding and extracting data from large sets of text.
6. One of the key features of grep is its ability to search for patterns not only in single files but also in multiple files within a directory.
7. You can use wildcards and regular expressions to refine your search, making it a flexible and efficient way to locate information.
8. In addition to its basic searching capabilities, grep also supports various options and flags that allow you to control the search process.
9. For example, you can use the -i flag to perform a case-insensitive search, or the -r flag to search recursively through directories.
10. Here's a simple example of how to use grep:
11. Let's say you have a directory full of text files, and you want to find all instances of the word "Linux" in those files.
12. You can use the following command:
それではheadのサンプルコードを見てみましょう。
# 先ほどのディレクトリ(/home/username/Documents/)の続きから
% head project_report_3.docx
1. This is a sample file for demonstrating grep.
2. You can search for specific patterns using grep.
3. It's a very useful command in Linux.
4. Grep, short for "Global Regular Expression Print," is a powerful command-line utility in Linux that allows you to search for specific patterns within text files or streams.
5. It uses regular expressions to define search criteria, making it a versatile tool for finding and extracting data from large sets of text.
6. One of the key features of grep is its ability to search for patterns not only in single files but also in multiple files within a directory.
7. You can use wildcards and regular expressions to refine your search, making it a flexible and efficient way to locate information.
8. In addition to its basic searching capabilities, grep also supports various options and flags that allow you to control the search process.
9. For example, you can use the -i flag to perform a case-insensitive search, or the -r flag to search recursively through directories.
10. Here's a simple example of how to use grep:
project_report_3.docxの初めの10行が出力されました。
出力の行数を指定する場合は-n 行数でできます。これもサンプルコードを見てみましょう。
# 先ほどのディレクトリ(/home/username/Documents/)の続きから
% head -n 5 project_report_3.docx
1. This is a sample file for demonstrating grep.
2. You can search for specific patterns using grep.
3. It's a very useful command in Linux.
4. Grep, short for "Global Regular Expression Print," is a powerful command-line utility in Linux that allows you to search for specific patterns within text files or streams.
5. It uses regular expressions to define search criteria, making it a versatile tool for finding and extracting data from large sets of text.
project_report_3.docxの最初の5行が出力されました。
-
tail
テキストファイルの末尾部分を表示するために使用されます。デフォルトでは、テキストファイルの末尾から最後の10行を表示します。
tailで末尾の10行を表示できます。
# 先ほどのディレクトリ(/home/username/Documents/)の続きから
% tail project_report_3.docx
3. It's a very useful command in Linux.
4. Grep, short for "Global Regular Expression Print," is a powerful command-line utility in Linux that allows you to search for specific patterns within text files or streams.
5. It uses regular expressions to define search criteria, making it a versatile tool for finding and extracting data from large sets of text.
6. One of the key features of grep is its ability to search for patterns not only in single files but also in multiple files within a directory.
7. You can use wildcards and regular expressions to refine your search, making it a flexible and efficient way to locate information.
8. In addition to its basic searching capabilities, grep also supports various options and flags that allow you to control the search process.
9. For example, you can use the -i flag to perform a case-insensitive search, or the -r flag to search recursively through directories.
10. Here's a simple example of how to use grep:
11. Let's say you have a directory full of text files, and you want to find all instances of the word "Linux" in those files.
12. You can use the following command:%
tailもオプションコマンドで出力する行数を指定できます。
# 先ほどのディレクトリ(/home/username/Documents/)の続きから
% tail -n 5 project_report_3.docx
8. In addition to its basic searching capabilities, grep also supports various options and flags that allow you to control the search process.
9. For example, you can use the -i flag to perform a case-insensitive search, or the -r flag to search recursively through directories.
10. Here's a simple example of how to use grep:
11. Let's say you have a directory full of text files, and you want to find all instances of the word "Linux" in those files.
12. You can use the following command:
-
which
指定したコマンドがどのディレクトリにインストールされているかを調べるために使用されます。具体的には、コマンド名を指定すると、そのコマンドの実行ファイルのパスを表示します。
which 探したいコマンドでコマンドの実態がある場所を探します。
サンプルコードで確認してみましょう。
# 先ほどのディレクトリ(/home/username/Documents/)の続きから
% which ls
/bin/ls
これはlsコマンドがどこにあるか探している例です。
whichを実行した結果/bin/lsにあることが確認できました。
-
パイプ(
|)
コマンドを組み合わせて使用するための非常に強力な機能です。パイプを使用すると、1つのコマンドの出力を別のコマンドの入力として渡すことができます。これにより、複数のコマンドを組み合わせてデータを処理したり、効率的にタスクを実行したりすることができます。
コマンド1 | コマンド2で実行できます。この場合はコマンド1の出力がコマンド2の入力として渡されます。
サンプルコードで確認してみましょう。
# 先ほどのディレクトリ(/home/username/Documents/)の続きから
% ps aux | grep System
root 161 0.0 0.1 33920872 13876 ?? Ss 月02PM 0:30.20 /System/***
root 143 0.0 0.1 33907044 10836 ?? Ss 月02PM 0:14.69 /System/***
root 139 0.0 0.1 33897840 8996 ?? Ss 月02PM 0:00.59 /System/***
root 130 0.0 0.0 33905968 4756 ?? Ss 月02PM 0:00.53 /System/***
root 126 0.0 0.0 33851296 2024 ?? Ss 月02PM 0:00.10 /System/***
root 129 0.0 0.0 33867124 3376 ?? Ss 月02PM 0:00.13 /System/***
ps auxについてですが、このコマンドを叩くと現在のプロセスの状況がわかります。
詳しくは説明しないのですが、現在パソコンでどのような処理が走っているのかを確認するものだと思っておいてください。
ps auxをそのまま叩くと膨大な量の情報が標準出力されるのですが、| grep SystemでSystemを含むものだけを抽出して出力するようにしています。
以上がよく使われるLinuxコマンドになります。
プログラミングをする上でこれらのコマンドもすぐに使えるよにしておきましょう。
このトピックのまとめ
よく使われるLinuxコマンド
- pwd: 現在いるディレクトリ表示
- ls: 現在いるディレクトリのファイルとディレクトリ一覧表示
- touch: ファイル作成
- cd: ディレクトリ移動
- mkdir: ディレクトリ作成
- mv: ファイル移動、ファイル名変更
- cp: ファイルコピー
- rm: ファイル削除
- find: ファイル、ディレクトリ検索
- cat: ファイルの中身確認
- diff: ファイルの差分確認
- grep: 正規表現で検索
- chmod: パーミッション(権限)変更
- vi: テキストエディタ起動
- curl: コマンドラインからリクエスト
- source: シェルに設定内容を読み込ませる
- history: コマンドrの履歴表示
- echo: 標準出力する
- head: ファイルの先頭10行を表示
- tail: ファイルの末尾10行を表示
- which: コマンドの場所を探す
- パイプ(
|): コマンドの出力を別のコマンドに渡す
13. 仕事の進め方
ここからは仕事の進め方について紹介をしていきます。
この章の内容はエンジニアのみならず、働く人全てに当てはまると思っているので、将来的にエンジニアから離れてしまっても応用が効くはずです。
それでは早速見ていきましょう。
13-1. タスクの優先度を決める
エンジニアは複数の仕事を同時に処理しなければならないことがあります。
その時は一度立ち止まって、何のタスクを優先すべきか考えてみましょう。
タスクの優先度を決定することは多くのメリットをもたらします。
まず、これにより効率的なプロジェクト管理が可能になります。
タスクの重要性と緊急性を識別することで最も重要な作業に集中でき、無駄を減らすことができます。
次に、時間の最適な配分が可能になります。どのタスクにどれだけの時間を割り当てるべきかを正確に把握することで、全体的な生産性を向上させることができます。
もしもマネジメントする立場になったら時間だけではなく、人員やその他リソースの割り当ても把握することができるようになります。
また、目標達成の観点からも重要です。優先度の高いタスクに焦点を当てることで、プロジェクトの主要な目標や期限を達成することが容易になり、プロジェクトの成功率が高まります。
13-2. タスクを細分化する
先ほどはタスクが複数ある場合の優先度を決めることについて説明しましたが、次に1つのタスクを細分化することのメリットをお伝えします。
優先度が高いタスクに取り組んだ際に、そのタスクの具体的な作業内容が分からなければ、なぜ優先度が高いのかを知ることができません。
もちろんプロジェクトのメインとなるタスクであることは前提なのでしょうが、タスクが振られる場合は細かい作業内容まで伝えられるとは限りません。
もしかしたら膨大なコードの修正が必要なのかもしれませんし、またはデータを取得するのに時間を要するのかもしれません。
そこで、タスクを細分化することでリスクやコストを個別に評価することができます。
またタスクを進めていく中で行き詰まることも出てくると思いますが、細分化がされていればその原因箇所が明確になり、チームの人の助けを素早く得ることができるでしょう。
その他にも、タスクを細分化して他の人に相談(壁打ち)することも可能になります。
相談した結果、あなたがこれ以上タスクを細分化できないと思っていても、他の人から見た時にさらに細分化できる要素があるかもしれません。
このようにタスクを細分化するメリットはたくさんあるので、タスクが振られたら一番初めに細分化することを心がけましょう。
13-3. 作業にかかる見積もりを出す
タスクの細分化ができたら、次は細分化された作業にかかる時間を出していきます。
それぞれの作業にかかる時間(工数)をあらかじめ求めておくと、タスク全体の見通しが良くなります。
見積もり工数がそのまま締め切りの役割も果たすことにもなるので、ダラダラと作業をすることもなくなるはずです。
自分への枷、チームメンバーへの安心感のために作業に入る前は各作業の工数の見積もりを出すようにしましょう。
13-4. 迷ったら聞いてみる
作業を進めていると必ずといっていいほど、わからないことにぶつかります。
ここで重要なことはずっと悩み続けないことです。
主観になってしまうのですが、15分くらい調べみても答えがわからない場合は周りの人に助けを求めた方が良いです。
仕事で重要なことは予定どおりに仕事をこなしていくことであり、あなたが自己解決に至った過程ではありません。
あなたが悩み抜いた結果、エラーを無事に解決できたとしても、それがタスクの進行を遅らせてしまってはいけないのです。
まずは仕事を予定通り進めること。
あなたが出会ったエラーなどは仕事が終わった後に
振り返りをし、次に同じ状況になっても対応できるようにしましょう。
13-5. テキストで聞く? 口頭で聞く?
これはどっちが良いかは明確に断言できないです。
まず両方のメリット・デメリットを整理してましょう。
テキストは紙媒体の書類だけではなく、slackなども含みます。
また口頭とはオフィス内でお互いに面と向かい合うことのほかに、Zoomなどでのオンラインミーティングも含みます。
-
テキスト
- メリット
- 明確なコミュニケーション : 口頭でのやり取りよりも具体性と明確さが増します。テキストで情報をやり取りすることで、正確な情報伝達が可能になります。
- 記録として残る : 基本的に記録が残ります。後から参照したり、何が話されたかを確認したりする際に役立ちます。
- 時間と場所の柔軟性 : 時間や場所を選ばず、相手も自分も都合の良い時に応答できます。
- デメリット
- 即時性の欠如 : 口頭でのやりとりに比べて、テキストベースのコミュニケーションは即時性に欠けることがあります。返答に時間がかかる場合があり、緊急の事項には不向きな場合があります。
- 誤解のリスク : 文脈が失われたり、誤った解釈がされたりするリスクがあります。特に複雑な内容の場合、テキストでのコミュニケーションは誤解を招く可能性が大きいです。
- メリット
-
口頭
- メリット
- 即時性の提供 : 口頭でのコミュニケーションは迅速なやり取りを可能にし、即時のフィードバックを与える、またはもらえます。
- デメリット
- 記録の欠如 : 口頭でのコミュニケーションは基本的に記録が残らないため、後で内容を確認するのが難しくなります。記録に残すためにはボイスレコーダーやオンラインミーティングの録画の作業が必要になります。
- 聞き逃しや忘れるリスク : 相手の言ったことを正確に覚えておくのが難しく、重要な情報が聞き逃されたり、時間が経つと忘れられたりするリスクがあります。
- メリット
2つのメリット・デメリットを見ると結局は使い分けした方が良いということがわかりますね。
これは主観になってしまうのですが、基本はテキストベースでコミュニケーションをとり、緊急時に口頭での確認が良いのかなと思います。
理由としてはテキストで伝えるためには、一度頭の中で整理するステップが入るため、質問するときや報告するときに相手の負担となるようなコミュニケーションになる可能性が低くなるからです。
また相手のスケジュールを抑える必要もないので、無駄な作業がなくなります。
一方、口頭(オンラインミーティング)の場合、相手の都合を考えないといけなくなります。
スケジュールが押さえられないと、スケジュールの確保作業で時間を要することになってしまいます。
また相手が何かしらの作業をしている場合は、その作業を中断させてしまうことになります。
中断された場合、元の作業に集中するためには結構な時間を要するので、相手のためにならないと思っています。(この辺りは「プログラマー脳」に書かれていますので、興味のある方は一読してみてください。)

テキストか口頭かの使い分けは、周りの環境と自分の仕事の進め方を踏まえて、どちらが良いのか探ってみてください。
13-6. 質問する時は内容を整理してから
相手に質問をする時は注意しなければなりません。
「これがわかりません」のように相手に全てを投げる質問はとても失礼であり、質問された側の負担になってしまいます。
それではどのように質問をすれば良いのか。
具体的に最低でも以下の4項目を押さえておけば相手の負担を減らせると思います。
- 質問か相談か報告かをはじめにかく
- 現状に至った経緯
- 何を調べたか
具体例で見てみましょう。
コードを修正をしていたのですが、エラーが発生したので相談させてください。
リファクタリングを行なっていて、isUser関数のif文の条件式の一部をint型からstr型に修正をしたところ、Typeエラーが発生しました。
エラーの内容を見ると、sample.pyの10行目でisUser関数が呼ばれているようなのですが、そこから先のエラー原因の特定ができておりません。
参考になる記事も見てみましたが、解決できておりません。
(https:******.com)
まずこのテキストが質問なのか、報告なのか相談なのかをはっきりとさせています。これによって回答者は何を求められているのかがわかります。
その後、具体的な作業と作業を行なって何が起きたのかを詳しく伝えています。ここが本題(一番聞きたい内容や伝えたい内容)になります。
そして質問者が何を調べたのかを伝えています。ここがないと、回答者はどこまでの解決策を提示すれば良いのかわからなくなります。
すでに質問者が調べた内容を、回答者が知らずに同じ内容を返してしまう可能性があります。
参考とした記事を添付するのも効果的です。回答者は質問者よりも知識があることが考えられます。
よって回答者は問題の切り分けができるはずなので、参考記事をみた時に質問者が問題の切り分けをできているか判断できます。
このように、回答者が回答しやすくするために「質問か相談か報告か」「現状に至った経緯」「何を調べたか」 を伝えるようにしましょう。
また他のポイントとして「What」で聞かないで「Is/Do」で質問することもあります。これは回答の範囲を狭めることになります。
具体例で見てみましょう。
What系の質問
顧客情報のデータが記載されているファイルはどこにありますか?
Is/Do系の質問
顧客情報のデータが記載されているファイルはcustomerディレクトリにある認識なのですが、あっていますか?
What系だと回答者は具体的な回答を求められてしまいます。
一方Is/Do系だと回答者はYes or Noで答えることになります。
前者は後者よりも回答に労力がかかっています。このように回答者の回答の手間を省いてあげるような質問の仕方も大切です。
このように、質問する時は相手の立場に立って質問することを心がけましょう。
なお、こちらの記事で、質問の方法をより詳細に書いているので、気になる方は確認してみましょう。
13-7. 進捗を伝える/聞く
自分の仕事の状況を伝えることは非常に大切です。
仕事はチームで行うことがほとんどなので、お互いの進捗を把握していないと、タスク全体の進み具合がわからなくなります。
タスクの細分化で作業工数の見積もりを出しましたが、この見積もりがスケジュールになります。
はじめのうちは作業ごとに進捗を報告することが無難でしょう。進捗を伝えすぎて悪いことはほとんどありません。
逆に進捗を伝えなさすぎる方がタスク管理ができなくなるので避けた方が良いです。
またあなたが誰かに仕事をお願いした場合も進捗を聞くようにしましょう。
もしもあなたがお願いした仕事が忘れられたりしていたら、その分タスクが後ろ倒しになってしまいます。
お願いしている立場だとなかなか相手のお尻を叩くようなことはしたくないとは思いますが、タスクを進めることが一番大事なので、勇気を出して進捗を聞くようにしましょう。
ただ、闇雲に進捗を聞くと相手に嫌な気持ちを与えることになるので、仕事をお願いするタイミングで「いつまでに対応してもらえると助かる」旨を一言添えてあげえると良いでしょう。
この章のまとめ
- タスクの優先度を決めてタスクの全体の進め方を把握する
- タスクを細分化して個別の作業を洗い出す
- 作業にかかる見積もりを出してスケジュールを明確にする
- 一人で延々と悩まないで、詰まったら他の人に聞く
- テキストで聞くか口頭で聞くかは状況に合わせる
- 相手の負担とならないような質問をする
- 進捗を伝えすぎて悪いことはない
- 相手に仕事をお願いしたら適度に進捗を聞くようにする
14. プログラム以外で意識するところ
ここまでプログラミング、仕事のことをお伝えしてきました。
内容をしっかり読んだあなたはすでに現場で活躍できるエンジニアになっているはずです。
この章では成長し続けるためのポイントをお伝えします。
14-1. 業務時間外で勉強する
エンジニアは勉強し続け、スキルと知識の向上を求められます。
技術の進歩は速く、常に最新の技術やトレンドを学ぶことが重要となってきます。
勉強することで、エンジニアは更なる競争力を身につけ、市場価値の高い存在になることができます。
また、新しい技術や手法を学ぶことは、創造性や問題解決能力を高めることにも繋がります。
最近で言えばChatGPTが良い例でしょう。
ChatGPTの裏側で行われている処理までを知る必要はないですが、このサービスの効率的な使い方(効果的な命令の出し方や便利なプラグインの使い方)を知ることで業務の効率を上げることができます。
このような最新の技術を学ぶことは個人のキャリアの発展にも有益で、将来的により良い職位や高い給与を得るチャンスにつながることでしょう。
加えて、勉強してスキルを身につけることは自分に自信を与え、仕事に対する満足度を高めることもあります。
ただし注意しなければならない点もあります。
プライベートでの勉強は、場合によって個人の時間や家庭生活とのバランスを取ることが難しい時があります。
特に、仕事が忙しい時期には心と体の健康を壊してしまうリスクがあります。
また、効率的な学習方法を見つけるまでに時間がかかることもあり、時には勉強の進展が思うようにいかないこともあります。
その結果、学習に対するモチベーションの維持が困難になることもあります。
エンジニアがプライベートで勉強することは、キャリアと個人的な成長のために非常に価値がありますが、それを継続するためには、生活のバランスを取り、ストレス管理に注意することが重要です。
14-2. 技術書以外の読書も大事
エンジニアが勉強するときは、技術書をひたすら読むイメージを持っていませんか。
少なくとも私はそうでした。
プログラミングを学び初めの頃はそれで大丈夫だと思うのですが、ある程度プログラミングの知識が身についたなと思ったら技術書以外の本を読むことをオススメします。
エンジニアが技術書以外の本を読むことには多くのメリットがあります。
まず文学、歴史、ビジネスなど技術書以外の本を読むことは、新しい視点や思考方法を教えてくれるはずです。
これらは問題解決やサービスの開発において、新しいアイデアを生むのに非常に役立つはずです。
また異なる分野の知識は、より広い視野を持つことに繋がり、チームの協力において新しい視点を与えてくれます。
次に、コミュニケーションスキルが向上する可能性もあります。
小説やエッセイなど人の気持ちを描写している本を読むことは、言語能力を高め、より効果的なコミュニケーション能力の向上につながります。
これは、チームメンバーやクライアントとのコミュニケーションにおいて重要です。
相手が何を求めているのか、相手の立場を想像できるスキルはエンジニア以外でも非常に重要なスキルです。
一般的に読書はリラックスを与え、ストレス解消となる言われています。
エンジニアリングはときおり要求の高いことを求められる職業なので、仕事からの一時的に解放される読書はメンタルの健康を維持するのにとても大きな役割を果たしてくれます。
ちなみに私が最近読んだオススメの本は「スマホ脳」と「食欲人」です。
この本を読んで実際にこれまでのスマホとの付き合い方を変えたり、食欲の根源を知り食事を変えることにつながりました。
上記の理由より、技術書以外の本を読むことはエンジニアスキルだけでなく、人間的な成長や幸せにもつながっていきます。


14-3. アウトプットをゴールとしてのインプット
勉強や読書でインプットした後、アウトプットすることは知識の定着に非常に良いことです。
アウトプットすることで思考が整理され、理解がより深まります。
しかしアウトプットを意識しないインプットは、必ずアウトプットするかはわかりません。
どういうことかというと、本やネットで調べてもそれを何かしらの形にするかどうかわからないということです。
例えば、この記事でプログラムの型について知ったとしても、それを実際にコードに書いて確認しないかもしれないということです。
これではせっかく得た知識を定着させることができないかもしれません。
一方、アウトプットを意識したインプットについてはどうでしょうか?
結論としては 非常に効果の高い勉強方法 だと言えます。
アウトプットの方法、例えばインプットした内容でアプリを作ってみるやQiitaの記事で発信するなど、事前にアウトプットを決めておけば、インプットする時の解像度が高まります。
この記事も同じ考えで作成しています。
記事のテーマと構成案を先に決めてから、章ごとに内容を書いています。
もちろん、記事書き始めの時点でおぼつかない知識もありました。
その点については、アウトプットの形(Qiitaの記事にすること、想定される対象者は誰か)を事前に決めていたので、知識の補完も問題なく行うことができました。
もちろん自分が理解していないと説明もできないので、意識を高く保ち続けながら記事を書いていました。
他のパターンもあげてみます。
PythonにはDjangoというフレームワークがあります。
フレームワークとは簡単に言うと、アプリケーション開発をより簡単にしてくれるプログラムの雛形みたいなものです。
Djangoには公式のチュートリアルがあるのですが、学習する前にDjangoを使って 「技術系の情報を発信するブログを作る」 といった具体的な目標を掲げていると、チュートリアルの内容の吸収も高まるし、実際にインプットした後で手を
動かすので理解が深まります。
このように、漠然とインプットするのではなく、アウトプットを意識としてインプットすることを強くおすすめします。
14-4. やる気は起きない、やったら起きる
勉強や読書をすること、アウトプットすることの大切さをお伝えしました。
しかしこれらを実践する前に立ちはだかる敵が 「やる気」 です。
「やる気が起きない」、「私のやる気スイッチはどこ?」など、モチベーションが上がらない時によく出てくる言葉ですね。
正直なところ、これは順序が逆です。
やる気が起きるから行動を起こすのではなく、行動を起こすからやる気が起きるが正しい認識です。
そもそも「やる気」は存在せず、「やる気みたいなもの」が正しいようです。
2ch創設者のひろゆき氏も「「やる気スイッチ」なんて存在しません。」と言っています。
また脳科学者の茂木健一郎氏も同様のことを言っています。
先ほどのアウトプットの件とも関係するのですが、行動を起こしたその結果が良いものだったら、脳はドーパミン(成功報酬)を出し、その行動を続けようとします。
学んだことをアウトプットし、自分の期待を超える結果(例えば、Qiitaの記事で想像以上のいいねがつく等)が得られれば脳は学習を続けようとし、インプットとアウトプットのセットが習慣化します。
このように「やる気」という言葉に惑わされず、まずは何も考えずに行動を起こしましょう。
いずれはそれが習慣化し、いつの間にか知識もスキルもたくさん身につくことになるはずです。
この章のまとめ
活躍し続けるエンジニアでいるためのポイント
- プライベートの時間でも勉強して、スキルアップを図る
- 専門書以外の本を読んで人間的成長を目指す
- アウトプットを前提としたインプットで知識の定着を図る
- 「やる気」に惑わされないこと。まずは行動を起こすことが習慣化につながるチャンス
15. 初心者こそ読んで欲しい本
プログラミングを学びはじめのころはどの本を読んだら良いのか正直迷います。
巷ではどんどん新しい書籍が発売されていくので、選択肢だけが増えていきますね。
ここでは個人的にプログラミング初心者におすすめしたい書籍を紹介します。
なるべくプログラミング言語によらない共通した内容の書籍をピックアップします。
- リーダブルコード
この記事を書く際に大いに参考にさせていただいた本です。読みやすいコードを書くためのノウハウが1冊に詰め込まれています。
- webを支える技術
webの歴史から始まり、webの仕組みをわかりやすく教えてれる本です。コードに関する本ではないですが、webに関する基礎知識取得のために読むことをオススメします。

- オブジェクト指向でなぜつくるのか
この記事でも紹介したオブジェクトについての考え方を詳しく書いています。アプリケーション開発の時に大いに役立つ知識が満載です。

- 良いコード/悪いコードで学ぶ設計入門 ―保守しやすい 成長し続けるコードの書き方
コードの設計のノウハウが詰め込まれた1冊。命名規則からより良い構造の設計までかゆい所に手が届く内容になっています。

- きれいなPythonプログラミング
Pythonでのリファクタリンングに関する本になります。リファクタリングの内容ですが、この本の内容を抑えつつコードを書けば、初めから読みやすいコードとなること間違いなしです。
- いちばんやさしいGit&GitHubの教本
わかりやすい説明とイメージしやすい図でGitおよびGitHubについて教えてくれています。

その他にも読んで欲しい本はたくさんあるのですが、ここでは紹介しきれないので、こちらの記事で気になる本を見つけてみてください。
16. まとめ
この記事で一貫して伝えたかったことは読みやすいコードを書こうということです。
優れたコードは読みやすいコードであることが前提にあり、読みやすいコードを書くためには「相手の立場」を考えることが重要になってきます。
そして、これはプログラミングだけではなく仕事全般でも言えることです。
この記事を読んだ皆さんが即戦力としてプログラミングの世界で戦えるようになれば本望です。
ここまで長々と本記事にお付き合いしていただきありがとうございました。
最後に気になる文字数ですが、こちらのサイトで数えてみました。
カウント対象は「目次」から「ここまで長々と本記事にお付き合いしていただきありがとうございました。」までです。
結果は、114,880文字(スペース除く)でした。原稿用紙309枚分らしいです。
この数値が示すとおり、正直めちゃくちゃ大変だったことは内緒です。
弊社Nucoでは、他にも様々なお役立ち記事を公開しています。よかったら、Organizationのページも覗いてみてください。
また、Nucoでは一緒に働く仲間も募集しています!興味をお持ちいただける方は、こちらまで。