オブジェクト指向
1. オブジェクト指向の起源
2003年チューリング賞の受賞者アラン・ケイさんはよくオブジェクト指向プログラミングの父と称されます。ご本人も憚ることなく、幾度、公の場で発明権を宣言しています。しかし、ケイさんは「C++」や「Java」などの現代のオブジェクト指向言語を蔑ろにしています。これらの言語は「Simula 67」という言語を受け継いだもので、私が作った「Smalltalk」と関係ないのだとケイさんは考えています。
オブジェクト指向という名称は確かにアラン・ケイさんに由来するものです。しかし、C++とJavaで使われている現代のオブジェクト指向は当初のと結構違います。ケイさん自身もこれらの言語を後継者として認めないです。では、ケイさん曰くC++とJavaの親であるSimula 67という言語はどんな言語でしょうか。ここで、簡単なサンプルコードを見てみましょう。
Class Rectangle (Width, Height); Real Width, Height;
! Class with two parameters;
Begin
Real Area, Perimeter; ! Attributes;
Procedure Update; ! Methods (Can be Virtual);
Begin
Area := Width * Height;
Perimeter := 2*(Width + Height)
End of Update;
Boolean Procedure IsSquare;
IsSquare := Width=Height;
Update; ! Life of rectangle started at creation;
OutText("Rectangle created: "); OutFix(Width,2,6);
OutFix(Height,2,6); OutImage
End of Rectangle;
2つの変数を持つclassですね。文法は分からないですが、コメントを見てどういうものかは大体見当がつくでしょう。Simula 67は名前の通り、1967年に発表され、1973年にリリースされたプログラミング言語です。それに対して、Smalltalkは1975年に最初のバージョン(Smalltalk-72)が発表され、1980年代にリリースされた言語です。
classがあればオブジェクト指向プログラミングだというわけではないですが、Simula 67のclassは「インスタンス」、「継承」、「メソッド」 や「late binding」までサポートしています。Simula 67は間違いなくオブジェクト指向系統の言語です。
しかし、Simula 67のオブジェクト指向の設計もオリジナルなものではないです。1965年、アントニー・ホーアさん(1980年チューリング賞受賞者)はある論文を発表しました。その論文に、record classという概念が提出されました。ホーアさんは、ALGOLという言語でサンプルを書きました。
record class person;
begin integer date of birth;
Boolean male;
reference father, mother, youngest offspring, elder sbling (person)
end;
複合的なデータ型で、C言語の構造体と似ていますね。
そして1966年に、あるサマースクールで、ホーアさんはクリステン・ニガードさんとオルヨハン・ダールさんと出会いました。後ほどSimula 67を作ったのはこの2人なのです。ホーアさんはrecord classのアイデアを2人に共有しました。ダールさんの話によると、その時ホーアさんはすでに「継承」の概念も思いつき、2人に教えました。そして、2001年に、クリステン・ニガードさんとオルヨハン・ダールさんはオブジェクト指向への貢献によりチューリング賞を受賞しました。アラン・ケイさんよりも2年早かったですね。
Simula 67について紹介しました。Simula 67は世界初のオブジェクト指向系統の言語ということも理解していただけたと思います。では、ケイさんが作ったSmalltalkは偽物ですか?結論から言うと、そうでもないです。Lisp言語の「Everything is a list」に対して、Smalltalkは初めて「Everything is an object(全てがオブジェクト)」という概念を作りました。更に、Smalltalkは演算子も含め式はすべてオブジェクトに対する「メッセージ」と解釈しています。Smalltalkこそが、オブジェクト指向に追い風を吹かせたプログラミング言語です。1980年代、Smalltalkのおかげで、オブジェクト指向プログラミング言語が輩出していました。その中に、今でもまだ健在しているC++などもあります。更に関数型プログラミング言語の元祖であるLisp陣営も「Common Lisp Object System」を手に持ち加勢していました。
最後に、1996年に現代のオブジェクト指向プログラミングパラダイムの最高峰であるJavaが発表されました。これが、オブジェクト指向史上の大きなマイルストーンとなる事件です。Java自体はオブジェクト指向において何も発明していないですが、今までの優秀な概念を吸収し、更にJVMの優れたマルチプラットフォーム性能とGCを備え合わせ、今でも世界TOP3にランクインするプログラミング言語となっています。
2. オブジェクト指向の特徴
オブジェクト指向の起源について紹介しました。しかし、そもそもオブジェクト指向とは何でしょうか?本題に入る前に、まず簡単な例を使って説明したいと思います。
オブジェクト指向はよくプロセス指向(手続き型プログラミングとも言う)と比較されます。下のコードはプロセス指向とオブジェクト指向の形式を表したものになります。
a = 0
# a+3の機能を実現したい
# プロセス指向
sum(a, 3)
# オブジェクト指向
a.sum(3)
ただ書き方が違うだけじゃんと思うかもしれません。実は、オブジェクト指向プログラミングはコードのロジックを明瞭化することができます。そして、その威力はプログラムが大きければ大きいほど発揮されるものです。続いて、上記のコードの違いを詳しく見ていきましょう。
1. 構文
関数呼び出しの構文を語順の考え方で解釈することができます。
- プロセス指向は通常、
動詞(主語, 目的語)という構造になっています。動詞がメインで、主語と目的語は引数として渡されます。 - オブジェクト指向は、SVO型、いわゆる
主語, 動詞, 目的語の構造になっています。つまり、主語がメインになります。そして、主語がある動詞を呼び出して、目的語を引数として渡しています。日本語ですと、動詞が後に来るので、SVO型はしっくり来ないかもしれませんが、英語、ヨーロッパの多くの言語、中国語などはSVO型に準ずる言語なので、オブジェクト指向の方式は意味合い的には自然になります。
2. 定義方式
- プロセス指向は、
sumという2つの引数を受け取り、その和をreturnする関数を定義します。 - オブジェクト指向は、やや複雑で、まず
classを定義します。そのclassの中に、様々なメソッド(関数と理解しても良い)を定義します。そして、classのインスタンスを作成し、そのインスタンスからメソッドを呼び出します。 - 上の例では、
aは整数で、intというclassのインスタンスになります。整数のインスタンスは足し算や引き算のようなintのメソッドが使えます。 - オブジェクト指向は変数を自動的に分類します。全ての変数はオブジェクトであり、ある
classに属し、使えるメソッドも決まっています。例えば、文字列が来たら、どういうメソッドが使えるかはclass strを見れば分かります。
3. 呼び出し方式
実践では、複数のオブジェクトに同じ処理をしたい時:
- プロセス指向は、1個または複数の関数を作って、全てのオブジェクトに対して関数を適用すれば実現できます。
- オブジェクト指向は、
classとそのclassのメソッドを定義し、全てのオブジェクトに対して、classのインスタンスを作り、そのインスタンスからメソッドを呼び出します。
このような処理が多くなると
- プロセス指向は、たくさんの関数が定義され、関数の中に関数呼び出ししている可能性もあり、構造がどんどん不明瞭になります。そして、あるオブジェクトが来たら、関数で処理できるかどうかは中身を見ないと分からない場合もあります。
- オブジェクト指向は、
class単位でメソッドをまとめて管理し、オブジェクトの使えるメソッドは自明です。
次に、オブジェクト指向のメリットをPythonのコード例を通して、少し詳しく見ていきます。
2-1. インターフェースの統一と管理
鳥、犬、魚の3つのclassを定義します。
class Bird:
def __init__(self, name):
self.name = name
def move(self):
print("The bird named {} is flying".format(self.name))
class Dog:
def __init__(self, name):
self.name = name
def move(self):
print("The dog named {} is running".format(self.name))
class Fish:
def __init__(self, name):
self.name = name
def move(self):
print("The fish named {} is swimming".format(self.name))
インスタンスを作ります。
bob = Bird("Bob")
john = Bird("John")
david = Dog("David")
fabian = Fish("Fabian")
次に、全てのインスタンスのmoveメソッドを呼び出します。
bob.move()
john.move()
david.move()
fabian.move()
実行結果:
The bird named Bob is flying
The bird named John is flying
The dog named David is running
The fish named Fabian is swimming
インスタンスを作成する時、パラメータを渡す必要があります。このパラメータはオブジェクトが他のオブジェクトと区別するためのデータとなります。例えば、bobというオブジェクトのnameはBobで、johnのnameはJohnなので、同じclassから作成されたインスタンスにもかかわらず、違うオブジェクトになり、同じメソッドを実行しても結果が異なります。
また、違うclassのmoveメソッドは、違う結果を出力しています。例えば、BirdのmoveはThe bird named...を出力し、DogはThe dog named...を出力します。moveメソッドは「移動」という意味で、各動物classは移動できるので、同じmoveとして実装することで、インターフェースが統一していて記憶しやすくなります。
プロセス指向で実装すると、以下のような感じになるかもしれません。
def move_bird(name):
print("The bird named {} is flying".format(name))
def move_dog(name):
print("The dog named {} is runing".format(name))
def move_fish(name):
print("The fish named {} is swimming".format(name))
bob = "Bob"
john = "John"
david = "David"
fabian = "Fabian"
move_bird(bob)
move_bird(john)
move_dog(david)
move_fish(fabian)
bobというオブジェクトが来たら、それが「鳥」なのか「犬」なのかをまず明確にしないと、move_birdとmove_dogのどれにするかが決められません。実際のプログラムではmoveだけではなく、数十種類の処理関数を実装するのが普通です。関数が多くなると、変数との対応関係を明確にするのが極めて難しくなります。また、これらの関数は内部で他の関数を呼び出している可能性もあり、この関数を他のプログラムで再利用する時に、内部で使われている関数も全部見つけ出して、移行する必要があります。
オブジェクト指向は変数を使って、classからインスタンスを作成し、どのメソッドが使えるかはclassを見れば分かります。そして、classとして抽象化することで、同じ文脈の関数が固まり、管理しやすくなります。
2-2. カプセル化
オブジェクト指向は関数とデータを一緒に束ねてくれるので、同じ変数(データ)をたくさんの関数で処理したい時はとても便利です。
class Person:
def __init__(self, name, age, height):
self.name = name
self.age = age
self.height = height
def describe(self):
print("name: {}; age: {}; height: {}".format(self.name, self.age, self.height))
def introduce(self):
print("My name is {}, and height is {}, and age is {}. ".format(self.name, self.height, self.age))
bob = Person("Bob", 24, 170)
mary = Person("Mary", 10, 160)
bob.describe()
bob.introduce()
mary.describe()
mary.introduce()
実行結果:
name: Bob; age: 24; height: 170
My name is Bob, and height is 170, and age is 24.
name: Mary; age: 10; height: 160
My name is Mary, and height is 160, and age is 10.
上記の処理をプロセス指向で実装すると、以下の2通りの方法があります。1つはそのまま引数として渡す方法です。
def describe(name, age, height):
print("name is {}, age is {}, height is {}".format(name, age, height))
def introduce(name, age, height):
print("My name is {}, and height is {}, and age is {}. ".format(name, height, age))
describe("Bob", 24, 170)
describe("Mary", 20, 160)
introduce("Bob", 24, 170)
introduce("Mary", 20, 160)
上記の方法は毎回同じ引数を渡す必要があり、引数が多くなると、非常に面倒です。もう1つは毎回引数を渡す必要のない方法です。
bob = dict(name='Bob', age=24, height=170)
mary = dict(name='Mary', age=20, height=160)
def introduce(**kwargs):
print("My name is {name}, and height is {age}, and age is {height}. ".format(**kwargs))
def describe(**kwargs):
print("Description: name is {name}, age is {age}, height is {height}".format(**kwargs))
introduce(**bob)
describe(**bob)
introduce(**mary)
describe(**mary)
この方法は引数を辞書で格納して、引数として辞書をアンパックして渡すようにしています。しかし、もし辞書の中にname, age, heightの3つのキーが存在しないと、エラーを起こしてしまいます。
このように、プロセス指向と比べて、オブジェクト指向は処理とデータをまとめてカプセル化してくれるので、コードのロジックが綺麗になりがちです。
2-3. オブジェクトの動的操作
オブジェクトの動的な一連の動作の実現は、プロセス指向には不向きです。
class Individual:
def __init__(self, energy=10):
self.energy = energy
def eat_fruit(self):
self.energy += 1
return self
def eat_meat(self):
self.energy += 2
return self
def run(self):
self.energy -= 3
return self
anyone = Individual()
print("energy: {}".format(anyone.energy))
anyone.eat_meat()
print("energy after eat_meat: {}".format(anyone.energy))
anyone.eat_fruit()
print("energy after eat_fruit: {}".format(anyone.energy))
anyone.run()
print("energy after run: {}".format(anyone.energy))
anyone.eat_meat().run()
print("energy after eat_meat and run: {}".format(anyone.energy))
実行結果:
energy: 10
energy after eat_meat: 12
energy after eat_fruit: 13
energy after run: 10
energy after eat_meat and run: 9
上記の「個体」のclassは「エネルギー」という内部状態パラメータと「果物を食べる」、「肉を食べる」、「走る」の3つメソッドを持ちます。次に、さらに細分化した「男の子」と「女の子」の2つのclassを定義します。
class Boy(Individual):
def daily_activity(self):
self.eat_meat().eat_meat().run().eat_meat().eat_fruit().run().eat_meat()
print("boy's daily energy: {}".format(self.energy))
class Girl(Individual):
def daily_activity(self):
self.eat_meat().eat_fruit()
print("girl's daily energy: {}".format(self.energy))
bob = Boy()
bob.daily_activity()
mary = Girl()
mary.daily_activity()
実行結果:
boy's daily energy: 13
girl's daily energy: 13
上記の処理をプロセス指向で実装すると、オブジェクトごとに、専用のenergyという変数と、それぞれのenergyを処理する関数を定義する必要があり、冗長になるのが避けられないです。
また、主語, 動詞, 目的語の構造は比較的に理解しやすいです。上記の例では、まずeat_meat()、次にrun()という一連の動作が永遠に続いても理解できます。プロセス指向で実現するとboy_energy = eat_meat(boy_energy); boy_energy = run(boy_energy);...のような長文になるか、eat_meat(run(boy_energy))のような階層構造になるので、理解しにくくなるでしょう。
3. オブジェクト指向に関する概念
オブジェクト指向の特徴について簡単に紹介しました。ここからは少し高度な内容に入ります。オブジェクト指向には様々な概念がありまして、これらを説明しようと思います。
3-1. クラス
クラスは、同じ属性(変数、データ)と処理(メソッド、関数)を持つオブジェクトの設計図です。クラスは自身から生成されるオブジェクトの共通の属性と処理を定義します。プロセス指向言語では、変数は型によって分類されるのに対して、オブジェクト指向言語では、変数はクラスによって分類されます。そして、オブジェクト指向言語の型自体もクラスになっています。
ちなみに、Python 2には古いクラスと新しいクラスがあり、それぞれは以下のようになります。
class oldStyleClass: # inherits from 'type'
pass
class newStyleClass(object): # explicitly inherits from 'object'
pass
Python 3になると、全てのクラスはデフォルトで新しいクラスになるため、明示的にobject継承する必要もなくなりました。
3-2. インスタンス
インスタンスは、単にオブジェクトと呼ぶこともありますが、クラスのコンストラクタとイニシャライザによって、属性に具体的な値が付与された実体のことを指します。
3-3. インスタンス化
インスタンス化は設計図であるクラスからインスタンスを生成する行為を指します。
3-4. インスタンス変数
インスタンス変数は、インスタンスごとに割り当てられた変数のことを指します。
3-5. クラス変数
クラス変数は、クラスとそのインスタンスが共有する変数のことを指します。
3-6. メソッド
メソッドはクラスまたはインスタンスに所属する関数のことを指します。
3-7. 静的メソッド
静的メソッドはインスタンス化しなくても、呼び出せるメソッドのことを指します。
3-8. クラスメソッド
クラスメソッドはクラスをオブジェクトとして操作するメソッドのことを指します。
3-9. メンバ
メンバはクラスまたはインスタンスの持つ名前空間に格納する要素です。名前空間には、通常メンバ変数(クラス変数またはインスタンス変数)とメンバ関数(各種メソッド)などが含まれます。
3-10. オーバーライド
オーバーライドは、子クラス(サブクラス・派生クラス)が親クラス(スーパークラス・基底クラス)から継承したメソッドを上書きする行為を指します。
3-11. カプセル化
カプセル化は、データと処理をオブジェクトとしてまとめて、境界線を作る行為を指します。
3-12. 継承
継承は、既存クラスの構造を受け継いだ子クラスを設計することを指します。is-aまたはhas-aの関係性を持たせるアーキテクチャです。
3-13. ポリモーフィズム
ポリモーフィズム(多態性)は、主にオーバーライドによって実現された子クラスの多様性を指します。例として以下のようなものが挙げられます。
class Animal:
def run(self):
print('Animal is running...')
class Dog(Animal):
def run(self):
print('Dog is running...')
class Cat(Animal):
def run(self):
print('Cat is running...')
def run_twice(animal):
animal.run()
animal.run()
run_twice(Animal())
run_twice(Dog())
run_twice(Cat())
実行結果:
Animal is running...
Animal is running...
Dog is running...
Dog is running...
Cat is running...
Cat is running...
つまり、あるクラスを入力とする処理は、その子クラスに対して何も修正する必要がなく、正常に動作できるという「リスコフの置換原則」による性質です。
3-14. 演算子オーバーロード
演算子オーバーロードは演算子の機能をユーザーが定義する行為を指します。Pythonでは全てのクラスはobjectクラスの子クラスで、それぞれの演算子オーバーロードは特殊メソッドにより実現されているので、性質としてはポリモーフィズムの1種になります。演算子オーバーロードに関する特殊メソッドは以下のようになります。
class MyNum:
def __init__(self,x):
self.__x = x
def __lt__(self, other):
print("__lt__")
return self.__x < other
def __le__(self, other):
print("__le__")
return self.__x <= other
def __eq__(self, other):
print("__eq__")
return self.__x == other
def __ne__(self, other):
print("__ne__")
return self.__x != other
def __gt__(self, other):
print("__gt__")
return self.__x > other
def __ge__(self, other):
print("__ge__")
return self.__x >= other
x = MyNum(100)
x < 10
x <= 10
x == 10
x != 10
x > 10
x >= 10
実行結果:
__lt__
__le__
__eq__
__ne__
__gt__
__ge__
上記は、演算処理にprint処理を追加したものです。PythonにはNumpyという数値計算ライブラリがあります。そして、a * bという形で行列のアダマール積の計算ができるのはPythonが演算子オーバーロードをサポートしているからです。
3-15. 抽象化
抽象化は、カプセル化で、強い関連性のあるデータと処理だけをオブジェクトとしてまとめて、概念を形成することを指します。例えば、動物をAnimalというクラスとして設計し、動物の状態を変数にし、動物の動作をメソッドにすることで抽象化できます。
3-16. ダック・タイピングとモンキーパッチ
この2つの概念はRubyコミュニティ由来のもので、動的言語の性質を表します。
モンキーパッチはランタイムでコードを拡張や変更する方法です。Pythonのオブジェクト指向プログラミングでは、クラスを動的に変更する場合に用語として使われます。
ダック・タイピングは動的型付けオブジェクト指向プログラミング言語の性質で、例えばrun_twice(animal)というような関数を実行するとします。静的型付け言語は、引数の型を評価して、Animalクラスまたはその派生でないと、実行自体が許されません。複数の型に対応させるために、ジェネリックスやオーバーロードなどの仕組みがが必要になります。それに対して、動的型付け言語は型の評価をせずに、run()というメソッドを持ってれば正常に実行できます。「もしもそれがアヒルのように歩き、アヒルのように鳴くのなら、それはアヒルに違いない」。
3-17. SOLID
SOLIDはオブジェクト指向プログラミングの分野において、ソフトウェア設計の5つの原則を記憶するための頭字語である。その5つの原則というのは、単一責任の原則、開放閉鎖の原則、リスコフの置換原則、インターフェース分離の原則と依存性逆転の原則です。
3-17-1. 単一責任の原則
単一責任の原則は1つのクラスに1つだけの責任を持たせるべきという原則です。「1つの責任」というのは少し曖昧ですので、実践では、あるクラスを変更する時の動機が2つ以上ある時は、単一責任と言えなくなります。例として、矩形を表すクラスRectangleがあるとして、GUIの描画機能と矩形の幾何学計算の2つのモジュールに使われています。ここのRectangleクラスは単一責任の原則に違反しています。
3-17-2. 開放閉鎖の原則
開放閉鎖の原則は新しい要件に対して、コードを修正するのではなく、できるだけ拡張を行うべきという原則です。実践では、抽象化を用いてこの原則を実現することが多いです。Pythonのデコレーターは開放閉鎖の原則に則る機能で、既存メソッド、関数またはクラスを変更せずに新しい機能を実装できます。
3-17-3. リスコフの置換原則
リスコフの置換原則は親クラスが使われている箇所に、子クラスでも置換できるようにすべきという原則です。実践では、継承と多態性を用いてこの原則を実現しています。実例として、矩形を表すクラスRectangleの子クラスとして、縦と幅が一致しないとエラーを起こすSquareクラスがあります。そして、ある関数またはメソッドはRectangleクラスを入力とし、内部で縦と幅に違い値を与えた場合、Squareクラスで置換できなくなるため、リスコフの置換原則に違反することになります。
3-17-4. インターフェース分離の原則
インターフェース分離の原則はクライアントに使わないメソッドへの依存関係を持たせるべきではないという原則です。言葉では理解しづらいが、下の例を見てください。
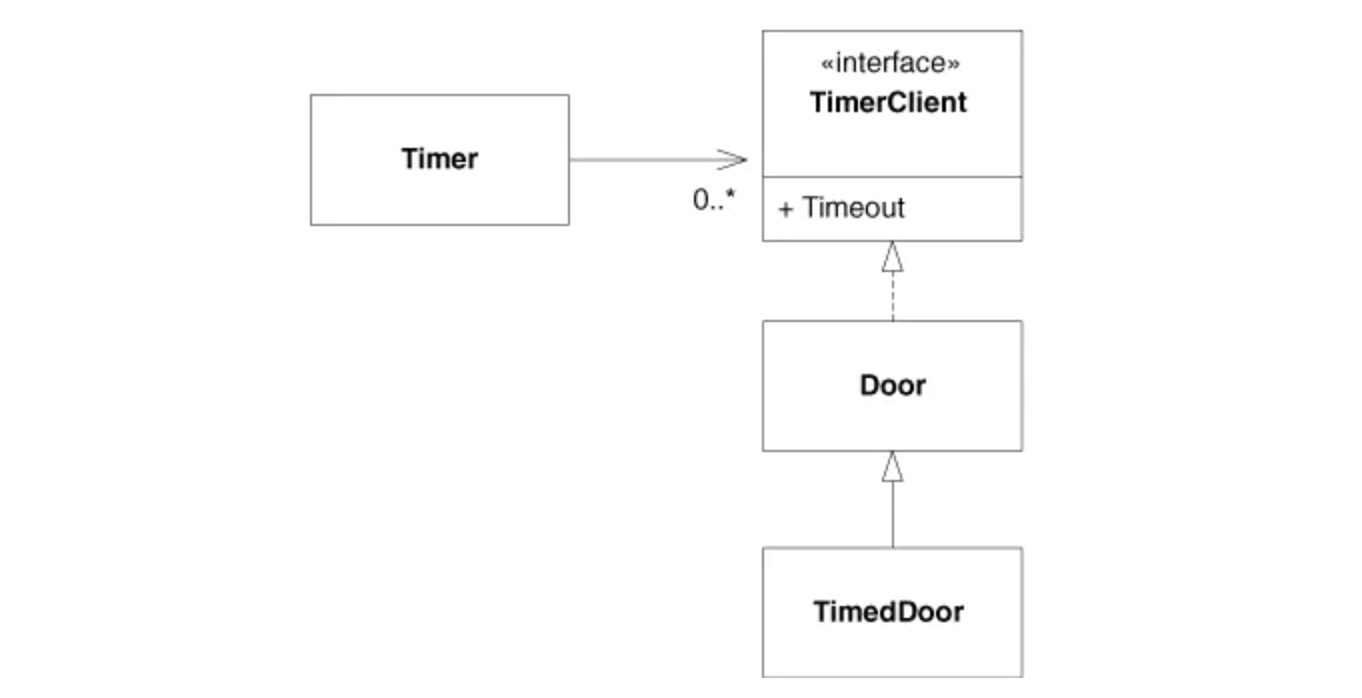
(出典:Agile Principles, Patterns, and Practices in C#)
この図はいくつかのクラスの関係を表しています。Doorクラスは、lock()、un_lock()やis_open()のような扉と関連するメソッドを持っています。今度は、扉が一定時間開いていると、自動的に閉じるTimedDoorを作ります。ここで、時間計測機能をTimerClientというクラスに持たせ、Doorは直接TimerClientを継承し、その機能を獲得します。そうすると、Doorを継承したTimedDoorも時間計測機能を獲得できます。しかし、Doorは普通の扉で、時間計測機能は要らないので、インターフェース分離の原則に違反することになります。
解決策としては、以下のようなTimedDoorの内部で、TimerClientと接続するアダプターメソッドまたは変数を作成する方法とMixin継承の2種類の方法があります。
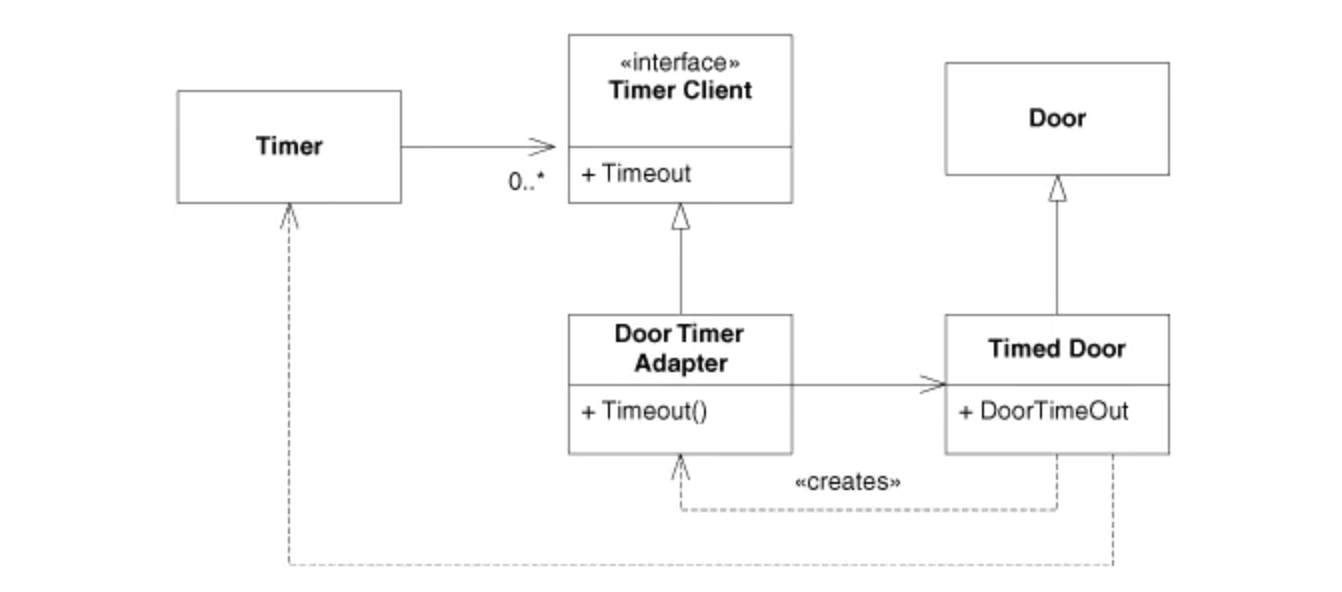
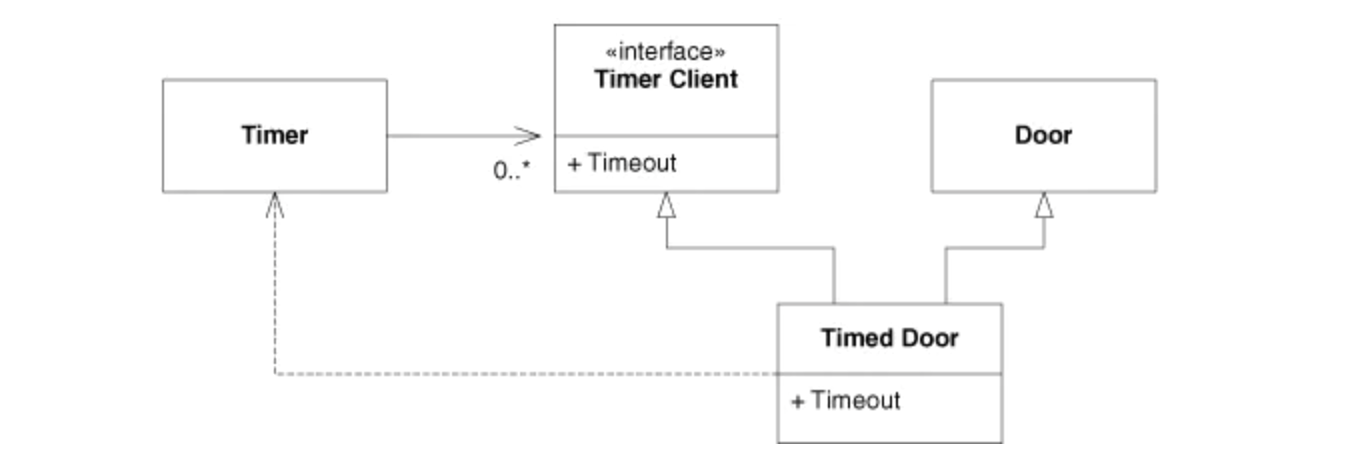
(出典:Agile Principles, Patterns, and Practices in C#)
3-17-5. 依存性逆転の原則
依存性逆転の原則は2つのルールを含みます。
- 上位モジュールは下位モジュールに依存してはならず、両方とも抽象に依存すべきです。
- 抽象は具体(実際の機能実現)に依存してはならず、具体は抽象に依存すべきです。
この原則はモジュール間のデカップリングのためのものです。例として以下のようなものがあります。
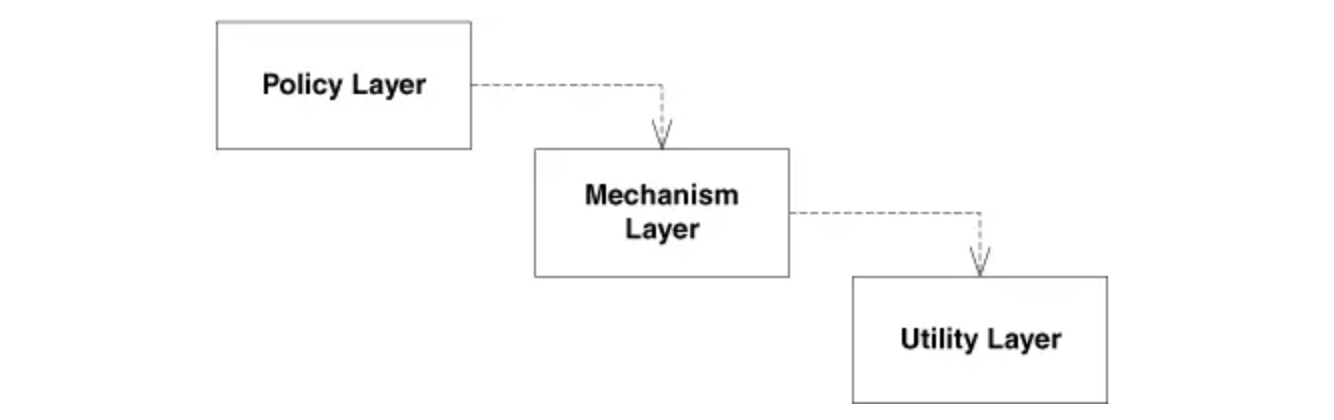
(出典:Agile Principles, Patterns, and Practices in C#)
ここの上位モジュールのPolicyLayerは、下位モジュールのMechanismLayerに依存し、下位モジュールのMechanismLayerは実際の機能を実現するモジュールUtilityLayerに依存しています。これは、依存性逆転の原則に違反するパターンです。
解決策として、以下のようなデザインができます。

(出典:Agile Principles, Patterns, and Practices in C#)
これで、PolicyLayerは下位モジュールではなく、抽象インターフェースのPolicyServiceInterfaceに依存するようになります。PolicyServiceInterfaceと互換できるよう、MechanismLayerは実装されます。
PolicyServiceInterfaceが介在することで、PolicyLayerとMechanismLayerはお互い依存することなく、互換性を実現しました。MechanismServiceInterfaceも同様です。抽象インターフェースは変更する可能性の低いもので、その介在によって各モジュールがデカップリングされます。
もう1つ例を挙げます。例えば、通常のPythonのWebアプリケーションでは、リクエスト→WSGIサーバー→WSGIアプリケーションという処理順序になります。ここのWSGIサーバーはGunicornやNginxのようなもので、WSGIアプリケーションはFlask、Djangoのようなものです。
GunicornはFlaskの実装を全く知らなくても、Flaskを呼び出すことが可能です。なぜなら、両方ともWSGIという抽象インタフェースに依存しているからです。ちなみに、ApacheはデフォルトではFlaskを呼び出すことはできません。しかし、mod_wsgiの拡張をインストールすればできるようになります。
WSGIの詳細の説明は割愛しますが、以下のコードを実行してみるのも良いでしょう。
from wsgiref.simple_server import make_server
def app(environ, start_response):
start_response('200 OK', [('Content-type', 'text/plain')])
return [b'Hello World']
if __name__ == "__main__":
with make_server('localhost', 5000, app) as httpd:
httpd.serve_forever()
3-18. GRASP
GRASPは、「General Responsibility Assignment Software Pattern」というオブジェクト指向システムの設計方針です。GRASPは、情報エキスパート、生成者、コントローラ、疎結合性、高凝集性、多態性、純粋人工物、間接化、変動から保護という9つのパターンを例として示しています。
3-18-1. 情報エキスパート
情報エキスパートパターンは、ある責務を果たすために必要な情報を全部持っているクラスがあるなら、そのクラスに任せるべきとしています。例えば、ECサイトのシステムにショッピングカートのShopCar、商品のSKUの2つのクラスあるとします。そして、「ショッピングカートに重複した商品を許容しない」という機能を実装します。同一商品がどうかを判断するための情報としてSKUIDはSKUクラスの中にあるので、情報エキスパートパターンに従い、この機能はShopCarクラスではなく、必要な情報を全部持っているSKUクラスに実装するべきです。
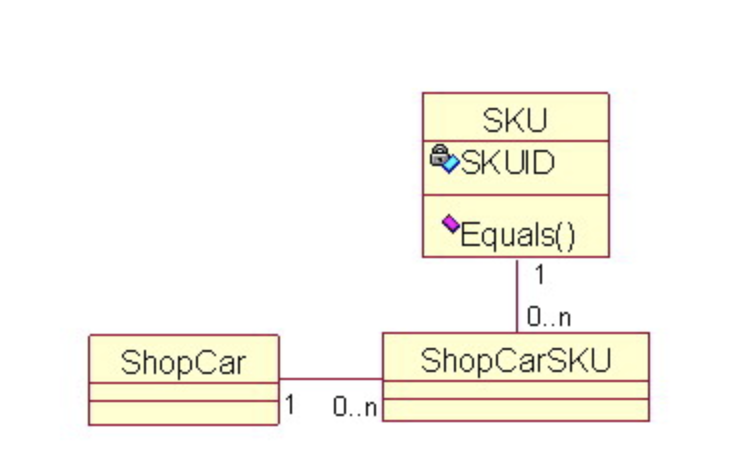
3-18-2. 生成者
生成者パターンはクラスAとクラスBがあるとして、以下の条件で1つ以上満たした時、BにAを作成させるべきとしています。この場合、BはAの生成者になります。
- BがAを含みます。
- BがAを集約しています。集約というのはhas-aの関係性です。
- BがAの初期化情報を持っています。
- BがAのインスタンスを記録します。
- Bは頻繁にAを使用します。
例えば、ECサイトのシステムで、商品SKUを管理する注文Orderというクラスがある場合、SKUの作成は、Orderの内部で行うべきです。
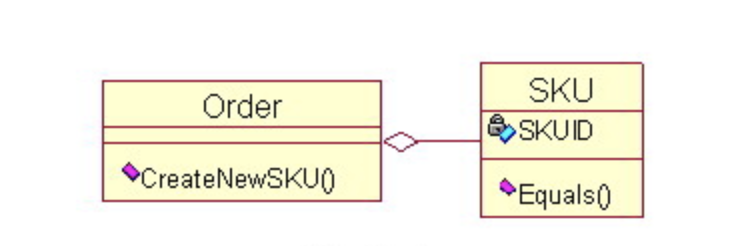
3-18-3. コントローラ
コントローラパターンは、システムイベントをコントローラというオブジェクトに制御させるべきとしています。このコントローラはクラス、システム、またはサブシステムで、UIやインターフェースとインタラクトしないものにすべきです。
例えば、Ruby on Railsに使用されるMVCというアーキテクチャの「C」はコントローラの略です。
3-18-4. 疎結合性
結合性はシステムの各コンポーネント間の依存関係の強弱を表す尺度です。疎結合性パターンは各コンポーネント間の依存関係を弱くするようにシステムを設計すべきとしています。依存関係を弱くするために、importなどを最小限にしたり、クラスメンバのアクセス権限を厳しくしたり、クラスをイミュータブルオブジェクトにしたりするような手法があります。
ECサイトのシステムを例とすると、例えば、商品のトータル価格を計算する機能を追加する時、新しいクラスなどを作成して、SKUをimportして、その金額を集計するメソッドを作るより、すでにSKUと依存関係を持っているOrderに追加したほうが、不必要な依存関係を作ることがなくなります。
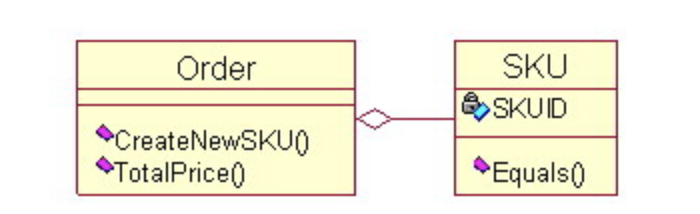
3-18-5. 高凝集性
凝集性はあるオブジェクト(モジュール)の持っている責務(機能)間の関連性の強弱を表す尺度です。高凝集性パターンはオブジェクトに適切に責務を集中すべきとしています。
またECサイトのシステムを例としますが、注文データのDAOクラスOrderDAOを作成し、データ保存用のメソッドSaveOrder()を実装します。Excelに保存する機能とDBに保存する機能を実現したい時は、まとめてOrderDAOに実装するより、それぞれ、違うクラスを実装し、OrderDAOを継承して、仮想メソッド(Pythonでは抽象メソッドとして実装されているため以降抽象メソッドと記載する)のSaveOrder()をオーバーライドしたほうがいいが凝集性が高くなります。

3-18-6. 多態性
多態性は3-13. ポリモーフィズムで紹介した概念で、ここではそれをパターン化して、システム設計のルールとしています。多態性パターンはクラスの変動しがちな部分を抽象的なメソッドなどとして実装し、ポリモーフィズムを持たせて、その具体的な実現は子クラスで実装すべきとしています。
例えば、Shapeという抽象クラスを作り、Draw()という描画用の抽象メソッドを実装します。Shapeを継承して、矩形Rectangle、円Roundをそれぞれ作り、内部でDraw()をオーバーライドし、各自の描画機能を実現するのは多態性パターンに則った設計になります。こうすることで、次に菱形Diamondを追加したい時は、システム構造を変えずに同じやり方で作成できます。
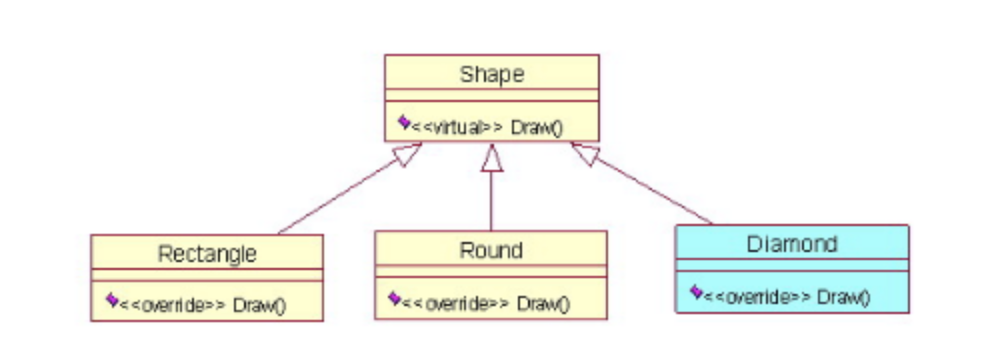
3-18-7. 純粋人工物
システムを設計する時、高凝集性と疎結合性は矛盾します。高凝集性はクラスを細分化して、責務をそれぞれに集中させるようにするが、それぞれのクラスは協力し合わないと、正常に動作しないので、どうしても結合性を高くしてしまいます。
純粋人工物は人工的なクラス、すなわち抽象クラスを作成し、凝集性と結合性をバランスを調整します。例えば、図形の描画機能の例ですが、今度はWindowsとLinux両方対応する機能を追加します。それぞれのOSのシステムコールや構造自体は違うので、描画機能Draw()も違う形で実装しなければなりません。ここで、抽象基底クラスのAbstractShapeを追加することで、凝集性を下げず、結合性もそれほど上げないままシステムを実現できます。
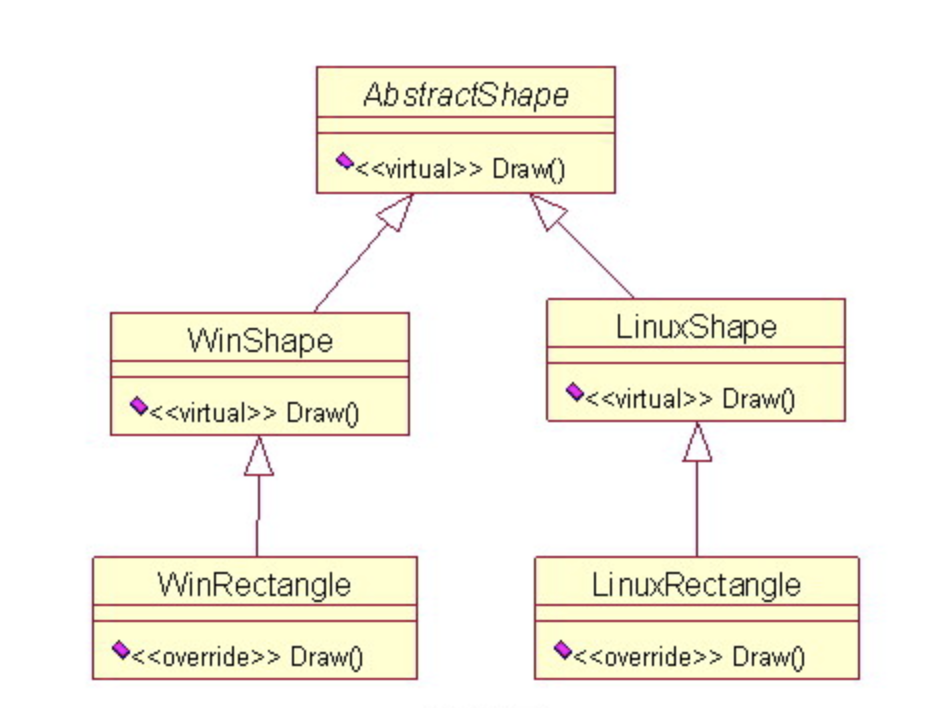
3-18-8. 間接化
間接化パターンは、2つのクラスの間に仲介としたオブジェクトを設けることで、クラス間の結合性の軽減を促進する設計方法です。MVCアーキテクチャーでは、Modelに直接Viewとやりとりさせず、間にContorollerを置くのは間接化パターンに則った設計です。3-17-4. インターフェース分離の原則で紹介した中間にあるインターフェース抽象クラスも同じ思想の設計です。
3-18-9. 変動から保護
変動から保護パターンは3-17-2. 開放閉鎖の原則と類似しています。変動から保護するために、不安定な部分を統一したインターフェースでカプセル化します。そして、変化が生じた場合はインターフェースを変更するのではなく、追加をします。古いコードを変えなくても機能を拡張できるのが目的です。3-17-2. 開放閉鎖の原則で例として出したPythonのデコレーターの他に、ORMは典型的な変動から保護パターンで、DBを変更してもクライアント側に影響を与えることはないです
3-19. デザインパターン
デザインパターンは、オブジェクト指向プログラミングにおいての設計ノウハウです。前述のSOLIDとGRASPのような設計方針(Design Principle)と違って、デザインパターンは過去の開発者が案出した経験則のようなものです。
4. Pythonのオブジェクト指向の基本
オブジェクト指向に関する概念を説明しました。これから、4つのクラスを作って、Pythonのオブジェクト指向プログラミングの基本構造について見てみます。
- Animal:各種クラス変数、メソッドについて
-
Dog:プロパティを定義する
propertyについて - Cat:プライベート変数とメソッドの継承・オーバーライドについて
-
Tiger:クラスメンバの継承用の
superについて
4-1. クラスの変数とメソッド
Pythonのクラスには変数とメソッドがあります。そして、それぞれ色々な種類があります。
- 変数はクラス変数とインスタンス変数があります。
- メソッドはいクラスメソッド、インスタンスメソッド、静的メソッドがあります。
下のコードで、各種変数とメソッドの定義について、コメントで説明します。
from types import MethodType
class Animal:
# ここはクラス変数を定義する場所
the_name = "animal" # クラス変数
def __init__(self, name, age): # イニシャライザ
self.name = name # インスタンス変数
self.age = age
# ここはメソッドを定義する場所
def sleep(self): # インスタンスメソッド
print("{} is sleeping".format(self.name))
def eat(self, food): # 引数付きのインスタンスメソッド
print("{} is eating {}".format(self.name, food))
@classmethod
def speak(cls, adjective): # クラスメソッド
print("I am a {} {}".format(adjective, cls.the_name))
@staticmethod
def happening(person, do): # 静的メソッド
print("{} is {}ing".format(person, do))
def drink_water(self):
print("{} is drinking water".format(self.name))
検証:
adam = Animal(name="Adam", age=2) # インスタンス化
print('adam.the_name: {}'.format(adam.the_name)) # インスタンスからクラス変数を呼び出す
# 実行結果:adam.the_name: animal
print('Animal.the_name: {}'.format(Animal.the_name)) # クラスからクラス変数を呼び出す
# 実行結果:adam.name: Adam
print('adam.name: {}'.format(adam.name)) # インスタンス変数を呼び出す
# 実行結果:Animal.the_name: animal
adam.sleep() # インスタンスメソッドを呼び出す
# 実行結果:Adam is sleeping
adam.eat("meat") # 引数付きのインスタンスメソッドを呼び出す
# 実行結果:Adam is eating meat
adam.speak("happy") # インスタンスからクラスメソッドを呼び出す
# 実行結果:I am a happy animal
Animal.speak("sad") # クラスからクラスメソッドを呼び出す
# 実行結果:I am a sad animal
adam.happening("Tim", "play") # インスタンスから静的メソッドを呼び出す
# 実行結果:Tim is playing
Animal.happening("Mary", "watch") # クラスから静的メソッドを呼び出す
# 実行結果:Mary is watching
Animal.the_name = "Animal" # クラス変数を修正
print('adam.the_name: {}'.format(adam.the_name))
# 実行結果:adam.the_name: Animal
adam.the_name = "animal" # インスタンスから修正
print('Animal.the_name: {}'.format(Animal.the_name))
# 実行結果:Animal.the_name: Animal
adam.age = 3 # インスタンス変数を修正
# メソッドのバインディング(モンキーパッチ)
adam.drink_water = MethodType(drink_water, adam) # インスタンスにバインディングする
adam.drink_water()
# 実行結果:Adam is drinking water
print(adam.drink_water)
# 実行結果:<bound method drink_water of <__main__.Animal object at 0x7ffd68064310>>
try:
Animal.drink_water
except AttributeError as e:
print(e)
# 実行結果:type object 'Animal' has no attribute 'drink_water'
Animal.drink_water = MethodType(drink_water, Animal) # クラスにバインディングする
adam.drink_water()
# 実行結果:Adam is drinking water
Animal.drink_water = drink_water # 直接代入でメソッドをバインディングする
adam.drink_water()
# 実行結果:Adam is drinking water
- クラス変数はクラスが持つ変数で、クラスとインスタンス両方で使えます。
- インスタンス変数は各インスタンスに所属するもので、そのインスタンスのみ使用できます。
- インスタンスメソッドはインスタンスが使うメソッドで、
selfというインスタンス自身を指す引数を定義する必要があります。 - クラスメソッドはクラスとインスタンス両方が使えるメソッドで、
clsというクラスを指す引数を定義する必要があります。 - 静的メソッドはクラス内部で管理する普通の関数で、クラスとインスタンス両方が使えます。
- クラスからクラス変数を修正すると、インスタンスから呼び出す時に変更されます。
- インスタンスからクラス変数を修正すると、他のクラスやインスタンスに影響を与えません。
- メソッドのモンキーパッチは
MethodTypeか直接代入で実現できます。 - インスタンスにメソッドをバインディングすると、元のクラスや他のインスタンスはバインディングされたメソッドが使えません。クラスににバインディングすると、全てのインスタンス(バインディングする前に作成したインスタンスも含む)に伝播します。
4-2. プロパティ
Animalを継承したDogクラスを作成し、propertyやそれに関連するデコレーターを見てみます。これらのデコレーターはメソッドをプロパティ(変数)に変換するもので、以下の2つのメリットがあります。
- インスタンス変数のように
()なしで呼び出せます。 - 変数の評価機能などの動的な処理を追加でき、合法性を保証できます。
デコレーター以外に、property関数で上記の処理を実現できる方法もあります。
from functools import cached_property
class Dog(Animal): # クラスの継承
def eating(self):
print("{} is eating".format(self.name))
@property
def running(self):
if self.age >= 3 and self.age < 130:
print("{} is running".format(self.name))
elif self.age > 0 and self.age < 3:
print("{} can't run".format(self.name))
else:
print("please input true age")
@property # プライベートな変数を取得する
def country(self):
return self._country
@country.setter # メソッド名.setter
def country(self, value): # プライベートな変数に値を代入する
self._country = value
@country.deleter # メソッド名.deleter
def country(self): # プライベートな変数に値を削除する
del self._country
print("The attr country is deleted")
# property関数で上記のデコレーターと同じ機能を実現
def get_city(self):
return self._city
def set_city(self, value):
self._city = value
def del_city(self, value):
del self._city
city = property(get_city, set_city, del_city, "I'm the 'city' property.")
@cached_property # キャッシュされるproperty
def official_name(self):
return 'Mr.{} - the Dog'.format(self.name)
検証:
david = Dog("David", 2)
david.eating()
# 実行結果:David is eating
david.running # ()なしで呼び出す
# 実行結果:David can't run
dean = Dog("Dean", 4)
dean.running
# 実行結果:Dean is running
# デコレーターによる方法
david.country = "America"
print(david.country)
# 実行結果:America
del david.country
# 実行結果:The attr country is deleted
# property関数による方法
david.city = "NewYork"
print(david.city)
# 実行結果:NewYork
# キャッシュされるproperty
print(david.official_name)
# 実行結果:Mr.David - the Dog
-
@propertyデコレーターはメソッドを変数に変換します。 -
property関数でも同じ処理を実現できます。4番目の引数"I'm the 'city' property."という文字列はドキュメントで、Dog.city.__doc__で確認できます。 -
@cached_propertyはPython 3.8で実装された値がキャッシュされるpropertyです。計算量の高い変数処理をする時、キャッシュされると再計算が必要なくなるので性能向上に繋がります。
4-3. プライベート変数とメソッドの継承・オーバーライド
Catクラスとその子クラスBlackCatを定義し、プライベート変数とメソッドの継承・オーバーライドについて見ていきます。
- プライベートな変数は外部から使うことが制限される変数です。
- 子クラスは親クラスを継承する時、親クラスのメソッドを全部継承しますが、子クラスの中で同じ名前のメソッドを定義すると、継承されたメソッドがオーバーライドされます。イニシャライザメソッドの
__init__も同様です。
class Cat(Animal):
def __init__(self, weight): # 親クラスの__init__をオーバーライド
self.__weight = weight
self._weight = weight + 1
self.weight = self._weight + 1
def get_weight(self):
print("My _weight is {}kg".format(self._weight))
def get_real_weight(self):
print("Actually my __weight is {}kg".format(self.__weight))
class BlackCat(Cat):
def get_weight(self): # 親クラスのメソッドをオーバーライド
print("My weight is {}kg".format(self.weight))
def get_real_weight(self):
print("Actually my _weight is {}kg".format(self._weight))
def get_actual_weight(self):
print("My __weight is exactly {}kg".format(self.__weight))
検証:
cole = Cat(5)
print("Cole's weight: {}kg".format(cole.weight))
# 実行結果:Cole's weight: 7kg
# _xは外部からの利用を推奨しないプライベート変数で、利用すること自体は制限されない
print("Cole's _weight: {}kg".format(cole._weight))
# 実行結果:Cole's _weight: 6kg
# __xは外部からの利用をを禁止するプライベート変数で、利用することは制限され、_<class>__xの形で強制的に呼び出せる
print("Cole's __weight: {}kg".format(cole._Cat__weight))
# 実行結果:Cole's __weight: 5kg
cole.get_real_weight() # メソッドで内部から__xを利用できる
# 実行結果:Actually my __weight is 5kg
cain = BlackCat(5)
cain.get_weight()
# 実行結果:My weight is 7kg
# _xは制限されないため、子クラスからでも呼び出せる
cain.get_real_weight()
# 実行結果:Actually my _weight is 6kg
# 親クラスのプライベート変数の__xを子クラスの内部から素直な方法では利用できない
try:
cain.get_actual_weight()
except AttributeError as e:
print(e)
# 実行結果:'Blackcat' object has no attribute '_Blackcat__weight'
-
weightは普通の変数で、外部から利用できます。 -
_weightのような1つのアンダースコアが付いてる変数は外部からの利用を推奨しないプライベート変数で、利用すること自体は制限されません。ただし、オブジェクト名(クラス名、関数名、モジュールスコープの変数名など)にする場合、from module import *ではimportされません。 -
__weightのような2つのアンダースコアが付いてる変数は外部からの利用を禁止するプライベート変数です。ただし、<class>._<class>__xの形で強制的に呼び出せます。継承による属性の衝突を避けたい場合に使用するべきです。 - 変数名のパターンによる違う動作の実現は「名前修飾(Name Mangling)」と言います。
- 子クラスの中で親クラスが持っているメソッドと同じ名前のメソッドを定義すると、オーバーライドすることができます。
4-4. クラスメンバの継承
TigerとWhiteTigerを定義し、superの使い方について見ていきます。superは子クラスの中で親クラスの変数やメソッドを呼び出すための関数です。
class Tiger(Animal):
def speak(self):
return "I'm a tiger not Lulu's song"
def eat(self):
return "{} is eating".format(self.name)
class WhiteTiger(Tiger):
def __init__(self, name, age, height):
super().__init__(name, age)
self.height = height
def speak(self):
return super().speak().replace("tiger", 'white tiger')
def eat(self):
return super().eat()
検証:
tony = WhiteTiger("Tony", 10, 100)
print(tony.eat())
# 実行結果:Tony is eating
print(tony.speak())
# 実行結果:I'm a white tiger not Lulu's song
-
return super().eat()は親クラスのeatメソッドを返しているだけで、子クラスの中でeatメソッドを定義しなければsuperを使う必要がありません。 -
super().__init__(name, age)は、親クラスのイニシャライザ__init__を実行します。これがないと、self.nameとself.ageを呼び出せません。super().__init__(name, age)と同等な書き方は以下のようにいくつかあります。
1. 親クラスの変数を再定義します。
def __init__(self, name, age, height):
self.name = name
self.age = age
self.height = height
2. 親クラスの__init__を明示的に呼び出します。親クラスの名前を変えると、呼び出された箇所を全部修正しなければなりません。
def __init__(self, name, age, height):
Tiger.__init__(self, name, age)
self.height = height
5. Pythonのオブジェクト指向の発展
Pythonのオブジェクト指向プログラミングの基本的な形式を見てきました。実務においても、4. pythonのオブジェクト指向の基本の内容でほぼ事足ります。しかし、高度な機能の実現、モジュールの自作またはデザインパターンに則った綺麗なシステムを作成したいなら、もう少し発展した内容を知る必要があります。
5-1. 特殊メソッド
3-14. 演算子オーバーロードで少し触れましたが、Pythonのクラスには__init__のような、前後に2つのアンダースコアの付いた「特殊メソッド」、「マジックメソッド」または「__dunder__(ダンダー:ダブルアンダースコア)」と呼ばれるメソッドや変数がたくさん存在します。これらのメソッドや変数は一部または全てのオブジェクト共通のもので、様々な機能を実現できます。
import collections
import copy
import math
import operator
import pickle
import sys
import asyncio
class Dunder:
def __abs__(self):
# abs(Dunder()); 絶対値を計算する時に呼び出される
return self.x
def __add__(self, other):
# Dunder() + 123; 加算をする時に呼び出される
return self.x + other
async def __aenter__(self):
# `__aenter__`と`__aexit__`は一緒に実装しなければならない
# async with Dunder() as coro; awaitable object限定
await asyncio.sleep(1)
async def __aexit__(self, exc_type, exc_val, exc_tb):
# `__aenter__`と`__aexit__`は一緒に実装しなければならない
# async with Dunder() as coro; awaitable object限定
await asyncio.sleep(1)
def __aiter__(self):
# `__aiter__`と`__anext__`は一緒に実装しなければならない
# async for _ in Dunder()
return self
def __and__(self, other):
# Dunder() & 123; 論理積演算をする時に呼び出される
return self.x & other
async def __anext__(self):
# `__aiter__`と`__anext__`は一緒に実装しなければならない
# async for _ in Dunder(); 要素がなくなったら、StopAsyncIterationを引き起こすべき
# awaitable object限定
val = await self.readline()
if val == b'':
raise StopAsyncIteration
return val
def __await__(self):
# await Dunder(); 戻り値はiterator限定
return self.z # `__next__`と`__iter__`を実装したクラス
def __call__(self, *args, **kwargs):
# Dunder()(); callable(Dunder()) == True; 関数のように呼び出せる
return self.x
def __init__(self, **kwargs):
# Dunder(y=2); イニシャライザ
self.x = 1
self.y = kwargs.get('y')
self.z = [1, 2, 3]
def __bool__(self):
# bool(Dunder()) == True; ブール演算する時に呼び出される
return True
def __bytes__(self):
# bytes(Dunder()); バイト列
return bytes('123', encoding='UTF-8')
def __ceil__(self):
# math.ceil(Dunder()); 切り上げ計算する時に呼び出される
return math.ceil(self.x)
def __class_getitem__(cls, item):
# Dunder[int] == "Dunder[int]"; このメソッドは自動的にクラスメソッドになる
return f"{cls.__name__}[{item.__name__}]"
def __complex__(self):
# complex(Dunder()); 複素数
return complex(self.x)
def __contains__(self, item):
# item not in Dunder(); item in Dunder()
return True if item in self.z else False
def __copy__(self):
# copy.copy(Dunder()); 浅いコピーをする時に呼び出される
return copy.copy(self.z)
def __deepcopy__(self, memodict={}):
# copy.deepcopy(Dunder()); 深いコピーをする時に呼び出される
return copy.deepcopy(self.z)
def __del__(self):
# dunder = Dunder(); del dunder;
# オブジェクトを削除する時に呼び出される。ガベージコレクションにも対応
del self
def __delattr__(self, item):
# del self.params; インスタンス変数を削除する時に呼び出される
del self.item
def __delete__(self, instance):
# class Owner: dunder = Dunder()
# del Owner().medusa; ディスクリプタメソッド
# 所有者クラスの属性として削除する時に呼び出される
del self.x
def __delitem__(self, key):
# del Dunder()['some_key']
self.__dict__.pop(key)
def __dir__(self):
# dir(Dunder()); オブジェクトの全ての属性を格納するiterable objectを返す
return super().__dir__()
def __divmod__(self, other):
# divmod(Dunder(), 123); 割り算の商と余りを同時に取得
return divmod(self.x, other)
def __enter__(self):
# with Dunder() as dunder: pass
return self
def __eq__(self, other):
# Dunder() == 123; 等価演算をする時に呼び出される
return self.x == other
def __exit__(self, exc_type, exc_val, exc_tb):
# with Dunder() as dunder: pass; 引数はそれぞれTypeError、ValueError、Traceback
return True
def __float__(self):
# float(Dunder()); 浮動小数にする
return float(self.x)
def __floor__(self):
# math.floor(Dunder()); 小数点を切り捨てる
return math.floor(self.x)
def __floordiv__(self, other):
# Dunder() // 123; 切り捨て除算する時に呼び出される
return self.x // other
def __format__(self, format_spec):
# '{:x}'format(Dunder()); format(Dunder(), 'x')
if format_spec == 'x':
return '{}'.format(self.x)
return '{}'.format(self.y)
def __fspath__(self):
# os.fspath(Dunder()) == '/var/www/html/mysite'; ファイルシステムパスを返す
return '/var/www/html/mysite'
def __ge__(self, other):
# Dunder() >= 123
return self.x >= other
def __get__(self, instance, owner):
# class Test: dunder = Dunder(); ディスクリプタメソッド
# `Test().dunder`または`Test.dunder`をする時にの時に呼び出される
return self.x
def __getattr__(self, item):
# Dunder().a; 未定義のメンバーにアクセスする時に呼び出される
return f'object has no attribute "{item}"'
def __getattribute__(self, item):
# Dunder().a; 未定義・定義済みにかかわらず、全てのメンバーにアクセスする時に呼び出される
# `return self.x`などすると無限ループになるのでご注意ください
return super().__getattribute__(item)
def __getitem__(self, item):
# Dunder()[item]
return self.__dict__.get(item)
def __getnewargs__(self):
# pickle.loads(pickle.dumps(Dunder())); unPickleする時に、`__new__`メソッドに渡される引数を定義できる
# Python 3.6以前にpickle protocol 2または3を利用する時に使われる
# Python 3.6以降にpickle protocol 2または3を利用する時に`__getnewargs_ex__`が使われる
# 直接呼び出されるわけではなく、`__reduce__`メソッドを構成している
return (2 * self.x, )
def __getstate__(self):
# pickle.dumps(Dunder()); Pickle処理する時に、オブジェクトの状態を取得できる
# 直接呼び出されるわけではなく、`__reduce__`メソッドを構成している
return self.__dict__.copy()
def __gt__(self, other):
# Dunder() > 123
return self.x > 123
def __hash__(self):
# hash(Dunder()); ハッシュ値を計算する時に呼び出される
return hash(self.x)
def __iadd__(self, other):
# dunder = Dunder(); dunder += 123; in-placeの加算をする時に呼び出される
self.x += other
return self
def __iand__(self, other):
# dunder = Dunder(); dunder &= 123; in-placeの論理積演算をする時に呼び出される
self.x &= other
return self
def __ifloordiv__(self, other):
# dunder = Dunder(); dunder //= 123; in-placeの切り捨て除算をする時に呼び出される
self.x //= other
return self
def __ilshift__(self, other):
# dunder = Dunder(); dunder <<= 123; in-placeのビット左シフトを計算する時に呼び出される
self.x <<= other
return self
def __imatmul__(self, other):
# dunder = Dunder(); dunder @= 123; in-placeのバイナリ演算をする時に呼び出される
# numpyではドット積として実装している
self.x @= other # 標準ライブラリでは機能未実装
return self
def __imod__(self, other):
# dunder = Dunder(); dunder %= 123; in-placeの剰余演算をする時に呼び出される
self.x %= other
return self
def __imul__(self, other):
# dunder = Dunder(); dunder *= 123; in-placeの乗算をする時に呼び出される
self.x *= 123
return self
def __index__(self):
# slice(Dunder(), Dunder() * 2); bin(Dunder()); hex(Dunder()); oct(Dunder())
# operator.index(Dunder()); 戻り値は整数限定で、`operator.index`関数から呼び出される
# また、整数を必要とする`slice`、`bin()`、`hex()`、`oct()`はこのメソッドを呼び出す
return self.x
def __init_subclass__(cls, **kwargs):
# class Test(Dunder, **kwargs): ...; 継承される時に呼び出される
super().__init_subclass__()
cls.x = kwargs.get('x', 1)
def __instancecheck__(self, instance):
# class MetaClass(type):
# def __new__(cls, name, bases, namespace):
# return super().__new__(cls, name, bases, namespace)
#
# def __instancecheck__(self, other):
# return True
#
# class Test(metaclass=MetaClass): ...
# isinstance(int, Test) == True
# このメソッドはクラスのタイプ(メタクラス)で定義しないと呼び出されない
# また、`type(other) == self`の場合は直接Trueになり、呼び出されない
pass
def __int__(self):
# int(Dunder()); 整数に変換する時に呼び出される
return int(self.x)
def __invert__(self):
# ~Dunder(); ビット反転を計算する時に呼び出される
return ~self.x
def __ior__(self, other):
# dunder = Dunder(); dunder |= 123; in-placeの論理和演算をする時に呼び出される
self.x |= other
return self
def __ipow__(self, other):
# dunder = Dunder(); dunder ** 2; in-placeの冪乗を計算する時に呼び出される
self.x ** other
return self
def __irshift__(self, other):
# dunder = Dunder(); dunder >>= 2; in-placeのビット右シフトを計算する時に呼び出される
self.x >>= other
return self
def __isub__(self, other):
# dunder = Dunder(); dunder -= 2; in-placeの減算をする時に呼び出される
return self
def __iter__(self):
# dunder = iter(Dunder()); next(dunder); iterable objectを作成するためのメソッド
# `__next__`と一緒に実装しなければならない
self._i = 0
return self.z[self._i] # self.zはリストとして定義している
def __itruediv__(self, other):
# dunder = Dunder(); dunder /= 123; in-placeの除算をする時に呼び出される
self.x /= other
return self
def __ixor__(self, other):
# dunder = Dunder(); dunder ^= 123; in-placeの排他的論理和演算をする時に呼び出される
self.x ^= other
return self
def __le__(self, other):
# dunder = Dunder(); dunder <= 123
return self.x <= other
def __len__(self):
# len(Dunder())
return len(self.z)
def __lshift__(self, other):
# Dunder() << 123; ビット左シフトを計算する時に呼び出される
return self.x << other
def __lt__(self, other):
# Dunder() < 123
return self.x < other
def __matmul__(self, other):
# Dunder() @ 123; バイナリ演算をする時に呼び出される
return self.x @ other # 標準ライブラリでは機能未実装
def __missing__(self, key):
# class Dict(dict):
# def __missing__(self, key):
# return f'__missing__({key})'
# dunder = Dict({'key': 1})
# print(dunder['unk_key'])
# 辞書内にキーが存在しない時に呼び出されるメソッド
pass
def __mod__(self, other):
# Dunder() % 123; 剰余演算をする時に呼び出される
return self.x % other
def __mro_entries__(self, bases):
# クラス定義の親リストにクラスオブ ジェクトではないものが指定された時に呼ばれる
# 型アノテーションの実装で、継承関係を正しくするためのメソッド
# https://www.python.org/dev/peps/pep-0560/#mro-entries
pass
def __mul__(self, other):
# Dunder() * 123; 乗算をする時に呼び出される
return self.x * ohter
def __ne__(self, other):
# Dunder() != 123; 不等価演算をする時に呼び出される
return self.x != other
def __neg__(self):
# -Dunder(); 反数を計算する時に呼び出される
return -self.x
def __new__(cls, *args, **kwargs):
# Dunder(); コンストラクタ
# __init__や他のインスタンスメソッドで使われるself(インスタンスそのもの)を作成する
return super().__new__(cls)
def __next__(self):
# dunder = iter(Dunder()); next(dunder); iterable objectを作成するためのメソッド
# `__iter__`と一緒に実装しなければならない
self._i += 1
return self.z[self._i]
def __or__(self, other):
# Dunder() | 132; 論理和演算をする時に呼び出される
return self.x | other
def __pos__(self):
# +Dunder(); 正数に変換する時に呼び出される
return +self.x
def __post_init__(self):
# データクラス用のメソッドで、`__init__`が定義されている場合のみ、`__init__`の後に呼び出される
pass
def __pow__(self, power, modulo=None):
# Dunder() ** 123; 冪乗を計算する時に呼び出される
if modulo:
return self.x ** power % modulo
else:
return self.x ** power
@classmethod
def __prepare__(metacls, name, bases, **kwargs):
# class MetaClass(type):
# def __new__(cls, name, bases, namespace):
# return super().__new__(cls, name, bases, namespace)
#
# @classmethod
# def __prepare__(cls, name, bases, **kwargs):
# return dict()
#
# class Test(metaclass=MetaClass): ...
# namespace = MetaClass.__prepare__(name, bases, **kwargs)
# クラス本体を評価する前に呼び出されて、クラスメンバを格納する辞書形オブジェクト(名前空間)を返す
# 通常`types.prepare_class`と一緒に使用する
# このメソッドはメタクラスでクラスメソッドとして定義しないと呼び出されない
return collections.OrderedDict()
def __radd__(self, other):
# 123 + Dunder(); 被演算子が反射した加算をする時に呼び出される
return other + self.x
def __rand__(self, other):
# 123 & Dunder(); 被演算子が反射した論理積演算をする時に呼び出される
return other & self.x
def __rdiv__(self, other):
# 123 / Dunder(); 被演算子が反射した除算をする時に呼び出される
return other / self.x
def __rdivmod__(self, other):
# divmod(123, Dunder()); 被演算子が反射した割り算の商と余りを同時に取得
return divmod(other, self.x)
def __reduce__(self):
# pickle.dumps(Dunder())
# `__getstate__`、`__setstate__`、`__getnewargs__`を利用し、Pickleの挙動をコントロールできる
# なるべく`__reduce__`を直接定義せず、上記のメソッドを定義するこること
# 後方互換の`__reduce_ex__`が定義されると優先的に使用される
return super().__reduce__() # return super().__reduce_ex__(protocol)
def __repr__(self):
# repr(Dunder()); オブジェクトの印字可能な表現を含む文字列を返す
return super().__repr__()
def __reversed__(self):
# reversed(Dunder()); 反転したiterator objectを返す
new_instance = copy.deepcopy(self)
new_instance.z = new_instance.z[::-1]
return new_instance
def __rfloordiv__(self, other):
# 123 // Dunder(); 被演算子が反射した切り捨て除算をする時に呼び出される
return other // self.x
def __rlshift__(self, other):
# 123 << Dunder(); 被演算子が反射したビット左シフトを計算する時に呼び出される
return '__rlshift__'
def __rmatmul__(self, other):
# 123 @ Dunder(); 被演算子が反射したバイナリ演算をする時に呼び出される
return other @ self.x # 標準ライブラリでは機能未実装
def __rmod__(self, other):
# 123 % Dunder(); 被演算子が反射した剰余演算をする時に呼び出される
return other % self.x
def __rmul__(self, other):
# 123 * Dunder(); 被演算子が反射した乗算をする時に呼び出される
return other * self.x
def __ror__(self, other):
# 123 | Dunder(); 被演算子が反射した論理和演算をする時に呼び出される
return other | self.x
def __round__(self, n=None):
# round(Dunder()); 四捨五入
return round(self.x)
def __rpow__(self, other):
# 123 ** Dunder(); 被演算子が反射した冪乗を計算する時に呼び出される
return other ** self.x
def __rrshift__(self, other):
# 123 >> Dunder(); 被演算子が反射したビット右シフトを計算する時に呼び出される
return other >> self.x
def __rshift__(self, other):
# Dunder() >> 123; ビット右シフトを計算する時に呼び出される
return self.x >> other
def __rsub__(self, other):
# 123 - Dunder(); 被演算子が反射した減算をする時に呼び出される
return other - self.x
def __rtruediv__(self, other):
# 123 / Dunder(); 被演算子が反射した除算をする時に呼び出される
return other / self.x
def __rxor__(self, other):
# 123 ^ Dunder(); 被演算子が反射した排他的論理和を計算する時に呼び出される
return other ^ self.x
def __set__(self, instance, value):
# class Test: dunder = Dunder(); ディスクリプタメソッド
# `Test().dunder=123`または`Test.dunder=123`をする時にの時に呼び出される
instance.x = value
def __set_name__(self, owner, name):
# ディスクリプタの変数名のアサイン
# class Test: pass; オーナークラスが作成される時に自動的に呼び出されるが、
# dunder = Dunder(); 後でバインディングする時は明示的に呼び出す必要がある
# Test.dunder = dunder
# dunder.__set_name__(Test, 'dunder')
# dunderというディスクリプタをTestクラスの命名空間の'dunder'にアサインする
owner.__dict__[name] = self
def __setattr__(self, key, value):
# dunder = Dunder(); dunder.x = 123; 属性設定する時に呼び出される
self.__dict__[key] = value
def __setitem__(self, key, value):
# dunder = Dunder(); dunder['x'] = 123; ; 添字で属性を設定する時に呼び出される
self.__dict__[key] = value
def __setstate__(self, state):
# pickle.loads(pickle.dumps(Dunder()))
# unPickleする時に、`__getstate__`で取得しといたオブジェクトの状態を利用できる
# 直接呼び出されるわけではなく、`__reduce__`メソッドを構成している
self.__dict__.update(state)
def __sizeof__(self):
# sys.getsizeof(Dunder()); オブジェクトのサイズを返す
return super().__sizeof__()
def __str__(self):
# str(Dunder())
# print(Dunder())
# オブジェクトの文字列表現を定義する
return f'{self.x}'
def __sub__(self, other):
# Dunder() - 123; 減算をする時に呼び出される
return self.x - other
def __subclasscheck__(self, subclass):
# class MetaClass(type):
# def __new__(cls, name, bases, namespace):
# return super().__new__(cls, name, bases, namespace)
#
# def __subclasscheck__(self, subclass):
# return True
#
# class Test(metaclass=MetaClass): ...
# issubclass(int, Test) == True
# このメソッドはクラスのタイプ(メタクラス)で定義しないと呼び出されない
return NotImplemented
@classmethod
def __subclasshook__(cls, subclass):
# class Test: x = 1; # クラス変数を定義
# issubclass(Test, Dunder) == True
# このメソッドは仮想基底クラスのクラスメソッドとして定義しなければならない
if cls is Dunder:
return hasattr(subclass, 'x')
def __truediv__(self, other):
# Dunder() // 123; 切り捨て除算をする時に呼び出される
return self.x // other
def __trunc__(self):
# math.trunc(Dunder()); 端数処理をする時に呼び出される
return int(self.x)
def __xor__(self, other):
# Dunder() ^ 123; 排他的論理和演算をする時に呼び出される
return self.x ^ other
上記のものは一般的な特殊メソッドです。全てを覚える必要はなく、こういうものもあったなぐらいでちょうど良いと思います。その他に、もう少し特殊な属性やメソッドも存在します。
| 属性 | 意味 |
|---|---|
| __dict__ | オブジェクトの (書き込み可能な) 属性を保存するために使われる辞書またはその他のマッピングオブジェクトです。ビルトイン関数vars()でその辞書を参照できます。 |
| __class__ | クラスインスタンスが属しているクラスです。 |
| __bases__ | クラスオブジェクトの基底クラス(親クラス)のタプルです。 |
| __name__ | クラス、関数、メソッド、デスクリプタ、ジェネレータインスタンスまたはモジュールの名前です。 |
| __qualname__ | クラス、関数、メソッド、デスクリプタ、ジェネレータインスタンスの修飾名です。 |
| __mro__ | この属性はメソッドの解決時に基底クラス(親クラス)を探索する時に考慮されるクラスのタプルです。 |
| mro() | このメソッドは、メタクラスによって、そのインスタンスのメソッド解決の順序をカスタマイズするために、上書きされるかも知れません。このメソッドはクラスのインスタンス化時に呼ばれ、その結果は__mro__に格納されます。 |
| __subclasses__ | それぞれのクラスは、それ自身の直接のサブクラスへの弱参照を保持します。このメソッドはそれらの参照のうち、生存しているもののリストを返します。 |
| __doc__ | クラスや関数のドキュメンテーション文字列で、ドキュメンテーションがない場合はNoneになります。サブクラスに継承されません。 |
| __module__ | クラスや関数が定義されているモジュールの名前です。モジュール名がない場合はNoneになります。 |
| __defaults__ | デフォルト値を持つ引数に対するデフォルト値が収められたタプルで、デフォルト値を持つ引数がない場合にはNoneになります |
| __code__ | コンパイルされた関数本体を表現するコードオブジェクトです。 |
| __globals__ | 関数のグローバル変数の入った辞書 (への参照) です --- この辞書は、関数が定義されているモジュールのグローバルな名前空間を決定します。 |
| __closure__ | Noneまたは関数の個々の自由変数 (引数以外の変数) に対して値を束縛しているセル(cell)群からなるタプルになります。セルオブジェクトは属性 cell_contents を持っています。 これはセルの値を設定するのに加えて、セルの値を得るのにも使えます。 |
| __annotations__ | 型アノテーション情報が入った辞書です。辞書のキーはパラメータ名で、返り値の注釈がある場合は、'return'がそのキーとなります。 |
| __kwdefaults__ | キーワード専用パラメータのデフォルト値を含む辞書です。 |
| __slots__ | このクラス変数には、インスタンスが用いる変数名を表す、文字列、イテラブル、または文字列のシーケンスを代入できます。slots は、各インスタンスに対して宣言された変数に必要な記憶領域を確保し、dict と weakref が自動的に生成されないようにします。 |
| __weakref__ | 主にガベージコレクションのための属性で、弱参照を格納しています。 |
| __func__ | クラスメソッドが持つ属性で、メソッドの実体である関数オブジェクトを返します。 |
| __self__ | クラスメソッドが持つ属性で、自身の所属するオブジェクトを返します。 |
| __isabstractmethod__ | 抽象基底クラスにおいて、抽象メソッドかどうかを判断するための属性です。 |
| __members__ | 列挙型クラス専用の属性で、各要素を保存するために使われる辞書です。 |
| __loader__ |
from package import *の時に、importすべきモジュール名をリストとして限定できます。 |
| __package__ | パッケージの場合は__name__に、パッケージじゃない場合はトップレベルのモジュールは空の文字列に、サブモジュールは親パッケージの__name__にすべきです。 |
| __spec__ |
python -m <module> <file>の時に、パッケージやモジュールのスペック情報を格納する属性です。 |
| __path__ | importする時にモジュールを探す場所で、リストとして定義できます。__path__を定義すると、モジュールがパッケージになります。 |
| __file__ | モジュールの絶対パスを格納する変数です。 |
| __cached__ |
.pycファイルとしたコンパイルされたパッケージのパスを格納する変数です。 |
| __all__ |
from package import *の時に、importすべきモジュール名をリストとして限定できます。 |
表で示したものの一部は関数オブジェクトが所有する属性です。Pythonは全てがオブジェクトなので、関数もオブジェクトになり、第一級関数であるプログラミング言語です。その他に、モジュールに使われる属性もありますが、__init__.pyファイルの中に定義して使うことができます。また、上記の表で示したもの以外に、特定のモジュールに使われている属性もあります。
クラスのメンバを参照したい時は、vars()とdir()が使えます。vars()はオブジェクトの__dict__属性を参照しますので、継承されたメンバは表示されません。それに対して、dir()はオブジェクトの__dir__メソッドを呼び出します。__dir__メソッドのデフォルトの実装はスコープ内にある名前を全部返すため、継承されたメンバも取得できます。そして、メンバの値も一緒に参照したい時はinspect.getmembers()が使えます。inspect.getmembers()はメンバとその値を格納したリストを返します。また、inspect.getmembers(obj, inspect.ismethod)で、メソッドだけ絞り込むこともできます。他にも、isから始まるinspectモジュールの関数がありまして、それらを使用して特定のメンバを取得できます。詳しくはドキュメントを参照してください。
5-2 タイプとオブジェクト
Pythonのtypeとobjectは「鶏が先か、卵が先か」のような関係性を持っています。つまり、どれが先かははっきり説明できないです。そして、typeとobjectは共生関係で、常に同時に出てきます。
まず、Pythonは「全てがオブジェクト」のプログラミング言語です。そして、3. オブジェクト指向に関する概念で紹介したように、オブジェクト指向の枠組みには主に以下の2種類の関係性が存在します。
- 継承関係。子クラスは親クラスを継承し、is-aの関係性を作ります。例えば、
reptileを継承したsnakeクラスがあるとして、「snake is a kind of reptile」と言えます。親クラスを参照したい時は、__base__が使用できます。 - クラス・インスタンス関係。あるタイプのクラスをインスタンス化するとこの関係が生まれます。例えば、
Squasherというsnakeのインスタンスを作ることができ、「Squasher is an instance of snake」と言えます。ここのsnakeはSquasherのタイプクラスと定義します。インスタンスのタイプクラスを参照したい時は、__class__か、type()関数が使用できます。
この2種類の関係性を図で表すと以下のようになります。
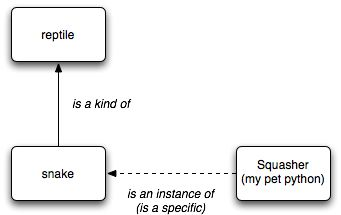
次に、typeとobjectを見てみます。
print(object)
# 実行結果:<class 'object'>
print(type)
# 実行結果:<class 'type'>
Pythonの世界では、objectは継承関係の頂点であり、全てのクラスの親クラスになります。それに対して、typeはクラス・インスタンス関係の頂点で、全てのオブジェクトのタイプクラスになります。2者の関係性を「object is an instance of type」と表現できます。
print(object.__class__)
# 実行結果:<class 'type'>
print(object.__bases__) # 継承関係の頂点なので、それ以上は存在しない
# 実行結果:()
print(type.__class__) # type自身もtypeのインスタンス
# 実行結果:<class 'type'>
print(type.__bases__)
# 実行結果:(<class 'object'>,)
続いて、list、dict、tupleなどのビルトインデータクラスについて見てみます。
print(list.__bases__)
# 実行結果:(<class 'object'>,)
print(list.__class__)
# 実行結果:<class 'type'>
print(dict.__bases__)
# 実行結果:(<class 'object'>,)
print(dict.__class__)
# 実行結果:<class 'type'>
print(tuple.__bases__)
# 実行結果:(<class 'object'>,)
print(tuple.__class__)
# 実行結果:<class 'type'>
同じく、親クラスはobjectで、typeのインスタンスになります。listをインスタンス化して検証してみましょう。
mylist = [1, 2, 3]
print(mylist.__class__)
# 実行結果:<class 'list'>
print(mylist.__bases__)
# 実行結果:
# ---------------------------------------------------------------------------
# AttributeError Traceback (most recent call last)
# <ipython-input-21-0b850541e51b> in <module>
# ----> 1 print(mylist.__bases__)
#
# AttributeError: 'list' object has no attribute '__bases__'
インスタンス化したlistには親クラスがないらしいです。次に、自分でクラスを定義して、そのインスタンスについて見てみましょう。
class C: # Python3ではクラスはデフォルトでobjectを継承する
pass
print(C.__bases__)
# 実行結果:(<class 'object'>,)
c = C()
print(c.__class__)
# 実行結果:<class '__main__.C'>
print(c.__bases__)
# 実行結果:
# ---------------------------------------------------------------------------
# AttributeError Traceback (most recent call last)
# <ipython-input-30-bf9b854689d5> in <module>
# ----> 1 print(c.__bases__)
#
# AttributeError: 'C' object has no attribute '__bases__'
ここのCクラスのインスタンスにも親クラスが存在しません。
ここまでの各種の関係性を図にすると以下のようになります。ここでは、実線は継承関係を表し、矢印は親クラスを指します。点線はクラス・インスタンス関係を表し、矢印はインスタンスのタイプクラスを指します。
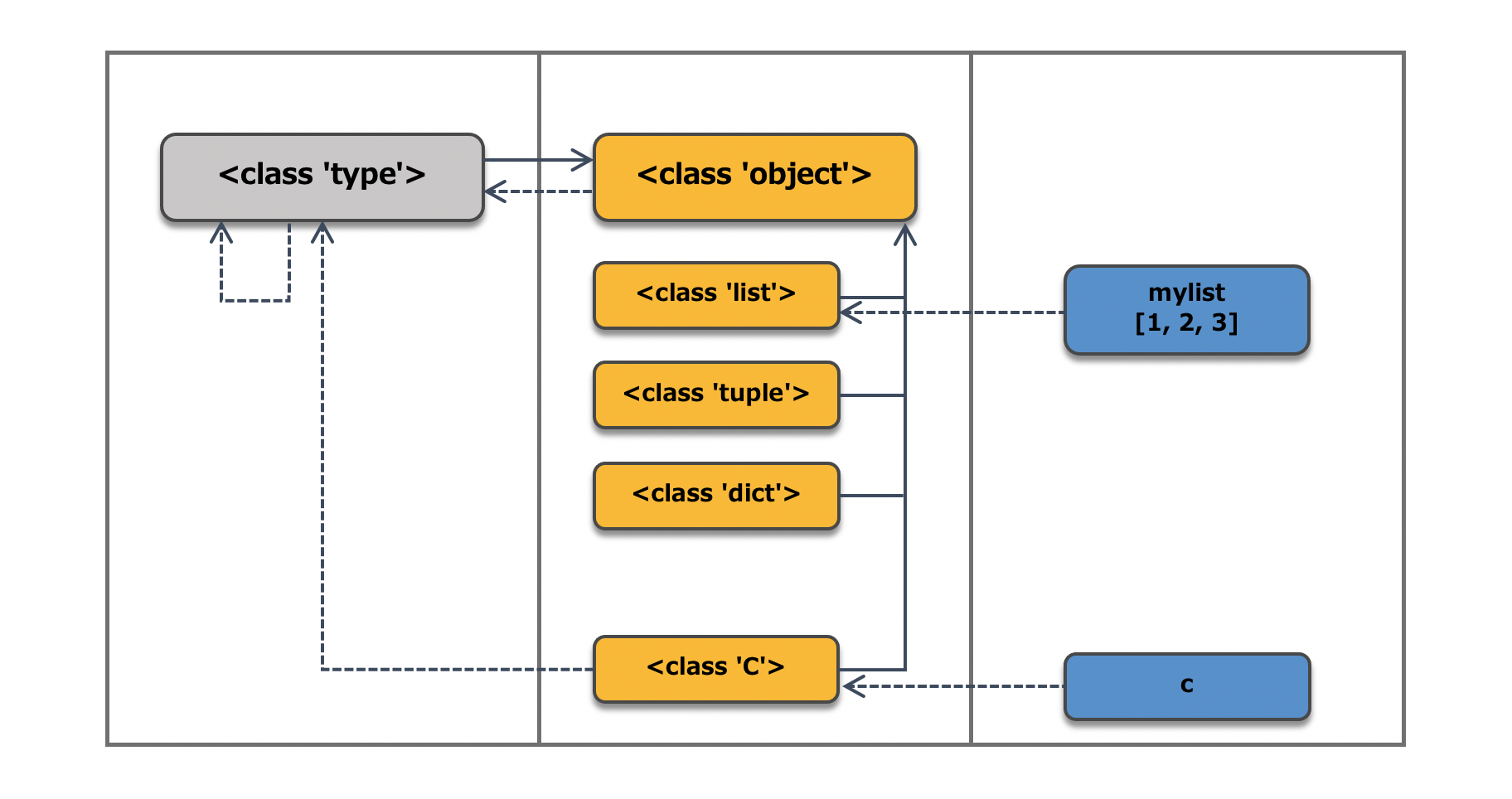
上記の検証から、以下の結果に辿り着きました。
- 全ての
objectはtypeのインスタンスです。 -
typeの直属のインスタンスはobjectやobjectを継承したクラスで、これらはPythonのオブジェクト指向においての「クラス」です。 -
typeの直属のインスタンス、つまり「クラス」の更なるインスタンスは__bases__を持たないクラスで、これらはPythonのオブジェクト指向においての「インスタンス」です。
では、typeを継承したクラスはどんなものになるでしょうか?
class M(type):
pass
print(M.__class__)
# 実行結果:<class 'type'>
print(M.__bases__)
# 実行結果:(<class 'type'>,)
ここのMクラスのタイプクラスも親クラスもtypeです。上記の図のルールでは、1列目に置くべきですね。しかし、Mのインスタンスはどこに置くべきでしょうか?
class TM(metaclass=M):
pass
print(TM.__class__)
# 実行結果:<class '__main__.M'>
print(TM.__bases__)
# 実行結果:(<class 'object'>,)
実はこのMはメタクラスというクラスのクラスです。メタクラスMから作成したTMは上記の図の2列目の「クラス」に所属するでしょう。メタクラスの使い方に関しては後でまた紹介します。
-
typeは全てのメタクラスの親で、typeを継承してメタクラスを作成できます。 -
objectは全ての「クラス」の親で、ほとんどのビルトインデータクラスはこの「クラス」です。 - 「クラス」をインスタンス化して作られたのは「インスタンス」で、継承やインスタンス化に使用できません。
なぜPythonにはtypeとobject両方必要だろうと思うかもしれません。例えば、typeがないと、上の図は2列になり、1列目が「タイプクラス」、2列目が「インスタンス」になります。静的オブジェクト指向プログラミング言語は大体この2列の構造です。Pythonが3列構造になったのは、ランタイムでクラスを動的に作成するためです。2列目のobjectはただtypeのインスタンスなので、ランタイムでメソッドや属性を変更できるわけです。この性質を実現するために、3列構造が必要になります。
5-3. メタクラス
5-3-1. クラスはオブジェクト
Pythonのクラスはsmalltalkから拝借したものです。殆どのオブジェクト指向プログラミング言語では、クラスというのは「オブジェクトをどう生成するか」を記述したコードになります。
class ObjectCreater:
pass
my_object = ObjectCreater()
print(my_object)
# 実行結果:<__main__.ObjectCreater object at 0x7fbc76f9a970>
しかし、繰り返しにはなりますが、Pythonのクラスはクラスであると同時に、オブジェクトでもあります。class予約語を実行する時に、Pythonはメモリ上オブジェクトを作成します。上記のコードでは、ObjectCreaterというオブジェクトが作成されました。この「クラス」オブジェクトは「インスタンス」オブジェクトを作成することができます。これが「クラス」の役割です。そして、オブジェクトであるため、ObjectCreaterに対して以下の操作が可能です。
- 他の変数に代入する
- コピーする
- 属性を増やす
- 引数として関数に渡す
class ObjectCreator:
pass
def echo(obj):
print(obj)
echo(ObjectCreator) # 引数として渡す
ObjectCreator.new_attr = 'foo' # 属性を増やす
assert hasattr(ObjectCreator, 'new_attr') == True
ObjectCreatorMirror = ObjectCreator # 他の変数に代入する
5-3-2. クラスの動的作成
クラスもオブジェクトなので、ランタイムでの作成は他のオブジェクトと同じくできるはずです。まず、class予約語を使って、クラスを作成する関数を作ってみます。
def choose_class(name):
if name == 'foo':
class Foo:
pass
return Foo
else:
class Bar:
pass
return Bar
MyClass = choose_class('foo')
print(MyClass)
print(MyClass())
実行結果:
<class '__main__.choose_class.<locals>.Foo'>
<__main__.choose_class.<locals>.Foo object at 0x7fad2abc8340>
クラスを条件分岐で作成できました。しかし、この方法はそれほど「動的」とは言えないですね。クラスもオブジェクトなら、クラスを作る何かがあるはずです。実は、その「何か」が5.2 タイプとオブジェクトで紹介したtypeです。
殆どの人は使ったことがあると思いますが、Pythonにはtypeという関数があります。
print(type(1))
# 実行結果:<class 'int'>
print(type('1'))
# 実行結果:<class 'str'>
print(type(ObjectCreatorMirror))
# 実行結果:<class 'type'>
しかし、typeにはもう1つの機能があります。それは、ランタイムでクラスを作成するという機能です。なぜ1つの関数に2つの機能があるかというと、3-1. クラスで紹介したようにPython 2には、typeを継承した古いクラスが存在します。その後方互換のために、typeに2つの機能を持たせました。
MyShinyClass = type("MyShinyClass", (), {})
print(MyShinyClass)
print(MyShinyClass())
実行結果:
<class '__main__.MyShinyClass'>
<__main__.MyShinyClass object at 0x7f9cd02bddc0>
typeでクラスを作る時に、3つの引数が必要です。
- クラス名
- クラスが継承するクラスのタプル
- クラスの属性を格納する辞書型オブジェクト(名前空間)
次に、typeの使い方をもう少し見ていきます。
class Foo:
bar = True
def echo_bar(self):
print(self.bar)
上記と同じ構造のクラスをtypeで作ると以下のようになります。
def echo_bar(self):
print(self.bar)
Foo = type('Foo', (), {'bar': True, 'echo_bar': echo_bar})
継承関係のあるクラスを作成します。
class FooChild(Foo):
pass
typeで作ると以下のようになります。
FooChild = type('FooChild', (Foo, ), {})
5-3-3. メタクラスの定義
前述のように、メタクラスはクラスのクラスで、クラスを作るクラスになります。「typeは全てのメタクラスの親で、typeを継承してメタクラスを作成できます。」というのを説明しましたが、実はtype自身もメタクラスです。メタクラス、クラス、インスタンスの関係性は以下の図のようになります。
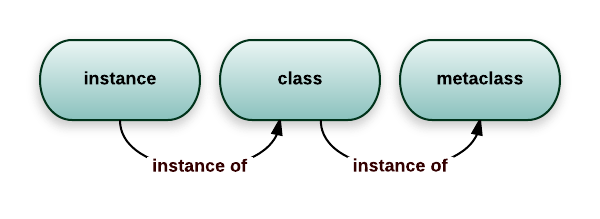
type関数は特殊なメタクラスです。実はclassを使ってクラスを作成する時に、Pythonは裏でtypeを使っています。そのため、全てのobjectはtypeのインスタンスになるわけです。
x = 30
print(x.__class__)
# 実行結果:<class 'int'>
print(x.__class__.__class__)
# 実行結果:<class 'type'>
typeはビルトインのメタクラスです。メタクラスの自作については5-2. タイプとオブジェクトでも説明しましたが、以下のようになります。
class Meta(type):
pass
class Foo(metaclass=Meta):
pass
5-3-4. メタクラスの使い方
メタクラスを使う目的は、クラスの作成時に、自動的に何らかのカスタマイズをすることです。例えば、あるモジュールにおいて、全てのクラスの属性名を大文字にしたい時に、このようなメタクラスが作れます。
class UpperAttrMetaClass(type):
# __new__はインスタンスselfを作成するコンストラクタ
# __init__は作成されたインスタンスselfを初期化するイニシャライザ
def __new__(cls, new_class_name,
new_class_parents, new_class_attr):
uppercase_attr = {}
for name, val in new_class_attr.items():
# 特殊メソッドを除く
if not name.startswith('__'):
uppercase_attr[name.upper()] = val
else:
uppercase_attr[name] = val
return type.__new__(cls, new_class_name, new_class_parents, new_class_attr)
# 下の書き方と同様
# return super().__new__(cls, new_class_name, new_class_parents, new_class_attr)
メタクラスはデータ型のチェックや継承のコントロールなどに使うことができます。メタクラスを導入すると、コードがやや複雑になるかもしれませんが、メタクラスの役割自体はシンプルです。クラスのデフォルトの作成過程に割り込み、修正を加え、修正後のクラスを返すだけです。
また、Pythonの標準ライブラリにはtypesというモジュールがあり、メタクラスやクラス生成に関する関数が提供されています。
types.prepare_class(name, bases=(), kwds=None)はこれから作る新しいクラスの適切なメタクラスを選ぶ関数です。関数の戻り値はmetaclass, namespace, kwdsのタプルになります。types.new_class(name, bases=(), kwds=None, exec_body=None)は新しいクラスを作成する関数で、exec_bodyは新しいクラスの名前空間を構築するためのコールバック関数を受け取ります。例えば、exec_body=lambda ns: collections.OrderedDict()で順序付き辞書を使って名前空間を構築できます(Python 3.6以降は不要)。
import types
class A(type):
expected_ns = {}
def __new__(cls, name, bases, namespace):
return type.__new__(cls, name, bases, namespace)
@classmethod
def __prepare__(cls, name, bases, **kwargs):
expected_ns.update(kwargs)
return expected_ns
B = types.new_class("B", (object,))
C = types.new_class("C", (object,), {"metaclass": A})
# メタクラスの継承チェーンの1番下はtypeではなく、Aになる
meta, ns, kwds = types.prepare_class("D", (B, C), {"metaclass": type, 'x': 1})
assert meta is A # 継承チェーンの1番下にあるメタクラスAが選択されたのが確認できる
assert ns is expected_ns # Aの__prepare__が使用されているのが確認できる
print(kwds) # metaclassキーワード引数が削除されたのが確認できる(適切なメタクラスを戻り値として返したため)
# 実行結果:{'x': 1}
メタクラスの実用例として、ORMが挙げられます。ここでは、DjangoのORMを例として見てみましょう。
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=30)
age = models.IntegerField()
guy = Person.objects.get(name='bob')
print(guy.age) # output is 35
DjangoのORMは上記のように非常に簡単に使えます。Djangoはメタクラスを使用して、データベースの複雑なクエリなどを実現しています。後でORMの実装例も紹介しますので、Django ORMの詳細はdjango.db.models.base.ModelBaseを参照してください。
5-4. ディスクリプタ
5-4-1. ディスクリプタの基本
4-2. プロパティのところで、propertyデコレーターについて見てきました。propertyはメソッドをインスタンス変数のようにするだけではなく、値の代入などに対してチェックを行うこともできます。
class Student:
def __init__(self, name, score):
self.name = name
self._score = score
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if not isinstance(value, int):
print('Please input an int')
return
self._score = value
propertyデコレーターでの値チェックには2つの問題点があります。
- 変数に対して、
propertyとx.setterデコレーターをそれぞれ適用する必要があり、変数が多いととコードが冗長になります。 - 初期化の時点でのチェックができません。
ディスクリプタ(Descriptor)はこの問題を解決するためのソリューションです。ディスクリプタはオブジェクトの属性の参照、保存と削除をカスタマイズするためのものです。クラスの中に、__get__、__set__、__delete__のどれか1つを実装すればそれがディスクリプタになります。使用する時はがディスクリプタを所有クラスのクラス変数として定義しなければなりません。
ディスクリプタは以下の2種類があります。
-
__get__のみ実装したクラスはノンデータディスクリプタ(non-data descriptor)と言います。 -
__get__と__set__を実装したクラスはデータディスクリプタ(data descriptor)と言います。
5-4-2. ノンデータディスクリプタとデータディスクリプタ
ディレクトリーのファイル数を取得する簡単なディスクリプタを作ってみまょう。
import os
class DirectorySize:
def __get__(self, instance, owner):
return len(os.listdir(instance.dirname))
class Directory:
size = DirectorySize() # ディスクリプタ
def __init__(self, dirname):
self.dirname = dirname
debug = Directory('debug')
print(debug.size)
ディスクリプタメソッド__get__はself以外に、自身を所有するクラスownerとそのインスタンスinstanceの2つの引数を受け取ります。Directoryクラスの中でディスクリプタDirectorySizeをインスタンス化し、クラス変数sizeに入れます。そして、sizeを呼び出すと、DirectorySizeの__get__メソッドが呼び出されます。
print(vars(debug))
# 実行結果:{'dirname': 'debug'}
上記のコードを見れば分かりますが、ノンデータディスクリプタはインスタンスの名前空間には存在しません。
次に、__get__と__set__を実装したデータディスクリプタを実装してみます。
import logging
logging.basicConfig(level=logging.INFO)
class LoggedAgeAccess:
def __get__(self, instance, owner):
value = instance._age
logging.info('Accessing %r giving %r', 'age', value)
return value
def __set__(self, instance, value):
logging.info('Updating %r to %r', 'age', value)
instance._age = value
class Person:
age = LoggedAgeAccess() # ディスクリプタ
def __init__(self, name, age):
self.name = name # 普通のインスタンス変数
self.age = age # ディスクリプタを呼び出す
def birthday(self):
self.age += 1 # __get__と__set__両方が呼び出される
mary = Person('Mary M', 30)
mary.age
mary.birthday()
実行結果:
INFO:root:Updating 'age' to 30
INFO:root:Accessing 'age' giving 30
INFO:root:Accessing 'age' giving 30
INFO:root:Updating 'age' to 31
ディスクリプタメソッド__set__は、所有クラスのインスタンスinstanceとディスクリプタに代入する値valueを受け取ります。ディスクリプタに値を代入すると__set__メソッドが呼び出されます。そして、__init__の初期化の時も同じです。
print(vars(mary))
# 実行結果:{'name': 'Mary M', '_age': 31}
データディスクリプタで、インスタンス変数に値を代入すると、名前空間に現れます。
ディスクリプタには、__set_name__というメソッドがあります。ディスクリプタにアサインされた変数名(上の例ではage)を取得でき、修正を加えることもできます。下記の例はメタクラスと__set_name__を使用したデータディスクリプタで実装したシンプルなORMです。
import sqlite3
conn = sqlite3.connect('entertainment.db')
class MetaModel(type):
def __new__(cls, clsname, bases, attrs):
table = attrs.get('table')
if table:
col_names = [k for k, v in attrs.items() if type(v) == Field]
# ダミーのデータ型を付与
col_names_with_type = [f'{c} {attrs[c].datatype} PRIMARY KEY' if attrs[c].is_primary_key
else f'{c} {attrs[c].datatype}'
for c in col_names]
# テーブルの作成
create_table = f"CREATE TABLE IF NOT EXISTS {table} ({', '.join(col_names_with_type)});"
conn.execute(create_table)
conn.commit()
attrs['_columns_'] = col_names # 各モデルのカラム名を格納
return super().__new__(cls, clsname, bases, attrs)
class Model(metaclass=MetaModel):
def __init__(self, *col_vals):
self.col_vals = col_vals # レコードの各カラムの値を格納
cols = self._columns_
table = self.table
pk = self.primary_key
pk_val = self.primary_key_value = col_vals[cols.index(pk)]
record = conn.execute(f'SELECT * FROM {table} WHERE {pk}=?;',
(pk_val,)).fetchone()
if not record:
params = ', '.join(f':{c}' for c in cols)
conn.execute(f"INSERT INTO {table} VALUES ({params});", col_vals)
conn.commit()
else:
params = ', '.join(f"{c}=?" for c in cols)
update_col_vals = col_vals + (pk_val,)
conn.execute(f"UPDATE {table} SET {params} WHERE {pk}=?;", update_col_vals)
class Field:
def __init__(self, datatype, primary_key=False):
self.datatype = datatype
self.is_primary_key = primary_key
def __set_name__(self, owner, name):
if self.is_primary_key:
owner.primary_key = name
self.fetch = f'SELECT {name} FROM {owner.table} WHERE {owner.primary_key}=?;'
self.store = f'UPDATE {owner.table} SET {name}=? WHERE {owner.primary_key}=?;'
def __get__(self, instance, owner):
return conn.execute(self.fetch, [instance.primary_key_value]).fetchone()[0]
def __set__(self, instance, value):
conn.execute(self.store, [value, instance.primary_key_value])
conn.commit()
if self.is_primary_key:
instance.primary_key_value = value
class MovieModel(Model):
table = 'Movie'
title = Field(datatype='TEXT', primary_key=True)
director = Field(datatype='TEXT')
year = Field(datatype='INTEGER')
class MusicModel(Model):
table = 'Music'
title = Field(datatype='TEXT', primary_key=True)
artist = Field(datatype='TEXT')
year = Field(datatype='INTEGER')
genre = Field(datatype='TEXT')
star_wars = MovieModel('Star Wars', 'George Lucas', 1977)
print(f'{star_wars.title} released in {star_wars.year} by {star_wars.director}')
star_wars.director = 'J.J. Abrams'
print(star_wars.director)
country_roads = MusicModel('Country Roads', 'John Denver', 1973, 'country')
print(f'{country_roads.title} is a {country_roads.genre} song of {country_roads.artist}')
実行結果:
Star Wars released in 1977 by George Lucas
J.J. Abrams
Country Roads is a country song of John Denver
このように、メタクラスとデータディスクリプタを組み合わせればORMも簡単に実装できます。もちろん両方とも使わなければならないという制約はなく、例えばDjangoのFieldはディスクリプタを使用していません。実際のORMはできる限りDBとの通信回数を減らすように、アプリケーション層での型評価やキャッシュなどもっと複雑な機能が実装されています。
5-4-3. ディスクリプタの仕組み
5-1. 特殊メソッドで、__getattribute__について触れました。__getattribute__は「未定義・定義済みにかかわらず、全てのクラスメンバーにアクセスする時に呼び出される」の機能を持っているメソッドで、ディスクリプタを使用したクラスに対して、b.xのような呼び出しをtype(b).__dict__['x'].__get__(b, type(b))のような処理に置き換えています。
class Descriptor:
def __get__(self, instance, owner):
return self._x
def __set__(self, instance, value):
self._x = value
class B:
x = Descriptor()
def __init__(self, x):
self.x = x
def __getattribute__(self, key):
attr = type(self).__dict__[key]
if hasattr(attr, '__get__'):
return attr.__get__(self, type(self))
else:
return attr
そのため、__getattribute__をカスタマイズすると、ディスクリプタが使えなくなります。そして、当たり前かもしれませんが、__get__と__set__を実装したデータディスクリプタは、変数の代入にチェックを入れるので、常にインスタンス変数を上書きします。上記の例では、b = B(1); b.x = 2にしても、b.xはディスクリプタのままです。それに対して、__get__だけ実装したノンデータディスクリプタは変数の代入をチェックしないので、クラス変数を直接更新すれば、ディスクリプタが上書きされます。
5-4-4. ディスクリプタの使い方
実はディスクリプタを使って、4. pythonのオブジェクト指向の基本で紹介したproperty、classmethod、staticmethodデコレーターと同じ機能を実現できます。
5-4-4-1. property
propertyは以下のように実装できます。
class Property:
def __init__(self, fget=None, fset=None, fdel=None, doc=None):
self.fget = fget
self.fset = fset
self.fdel = fdel
if doc is None and fget is not None:
doc = fget.__doc__
self.__doc__ = doc
def __get__(self, obj, objtype=None):
if obj is None:
return self
if self.fget is None:
raise AttributeError("unreadable attribute")
return self.fget(obj)
def __set__(self, obj, value):
if self.fset is None:
raise AttributeError("can't set attribute")
self.fset(obj, value)
def __delete__(self, obj):
if self.fdel is None:
raise AttributeError("can't delete attribute")
self.fdel(obj)
def getter(self, fget):
return type(self)(fget, self.fset, self.fdel, self.__doc__)
def setter(self, fset):
return type(self)(self.fget, fset, self.fdel, self.__doc__)
def deleter(self, fdel):
return type(self)(self.fget, self.fset, fdel, self.__doc__)
上記のディスクリプタをデコレーター@Propertyの形でsomemethodに使う時は、実はsomemethod = Property(somemethod)の処理になります。そして、Propertyのself.fgetに第一引数のfgetを代入し、インスタンスを作ります。次に、@somemethod.setterで作成済みのPropertyインスタンスのsetterメソッドで、fsetをインスタンス引数に代入します。続いて、 @somemethod.deleterで同じく、fdelをインスタンスに代入できます。この流れは4-2. プロパティと同じですね。
5-4-4-2. methodとfunction
4-1. クラスの変数とメソッドでMethodTypeを簡単に紹介しました。同じ機能をPythonコードで実装すると、以下のようになります。
class MethodType:
def __init__(self, func, obj):
self.__func__ = func
self.__self__ = obj
def __call__(self, *args, **kwargs):
func = self.__func__
obj = self.__self__
return func(obj, *args, **kwargs)
そして、クラスの内部で関数をメソッドに変えるディスクリプタはこんな感じで作成できます。
class Function:
def __get__(self, obj, objtype=None):
if obj is None:
return self
return MethodType(self, obj)
5-1. 特殊メソッドで、「instance.method.__func__はメソッドの実体である関数オブジェクトを返す」を説明しました。しかし、instance.methodでアクセスすると、メソッドオブジェクトが返ってきます。この挙動は上記のディスクリプタでシミュレートできます。
5-4-4-3. classmethodとstaticmethod
この2つのデコレーターは上記のMethodTypeを使って、非常に簡単に実現できます。まず、classmethodは以下のように実装できます。
class ClassMethod:
def __init__(self, f):
self.f = f
def __get__(self, obj, cls=None):
if cls is None:
cls = type(obj)
if hasattr(obj, '__get__'):
return self.f.__get__(cls)
return MethodType(self.f, cls)
@ClassMethodの形で使用すると、somemethod = ClassMethod(somemethod)になり、somemethodをインスタンスではなく、クラスにバインディングできます。
次に、staticmethodについて見ていきます。
class StaticMethod:
def __init__(self, f):
self.f = f
def __get__(self, obj, objtype=None):
return self.f
Pythonの静的メソッドstaticmethodの実体は普通の関数です。上記のStaticMethodを@StaticMethodの形で使用すると、同じくsomemethod = StaticMethod(somemethod)になり、単純にディスクリプタのインスタンス変数self.fに関数somemethodを保存し、クラスやインスタンスにバインディングされるのを阻止します。そして、呼び出された時はself.fをそのまま返します。
5-4-4-5. types.DynamicClassAttribute
あまり知られてないですが、Pythonの標準ライブラリにはtypes.DynamicClassAttributeというディスクリプタがあります。使い方は、propertyと同じです。このディスクリプタはインスタンスからアクセス時は普通のpropertyと全く一緒で、クラスからアクセスする時のみ機能が変わります。クラスからアクセスすると、クラスの__getattr__メソッドに、__getattr__が定義されてない時は、メタクラスの__getattr__に振り替えられます。
from types import DynamicClassAttribute
class EnumMeta(type):
def __new__(cls, name, bases, namespace):
reserved_names = ('name', 'value', 'values')
enum_namespace = namespace.copy()
enum_namespace['_member_map_'] = {}
enum_namespace['_member_map_']['values'] = []
for k, v in namespace.items():
if not (k in reserved_names or k.startswith('_')):
member_namespace = namespace.copy()
member_namespace.update({"_name_": k, "_value_": v})
member_cls = super().__new__(cls, name, bases, member_namespace)
enum_namespace['_member_map_']['values'].append(v)
enum_namespace['_member_map_'][k] = member_cls()
enum_namespace[k] = enum_namespace['_member_map_'][k]
return super().__new__(cls, name, bases, enum_namespace)
def __getattr__(self, item):
return self._member_map_[item]
class Enum(metaclass=EnumMeta):
@DynamicClassAttribute
def name(self):
return self._name_
@DynamicClassAttribute
def value(self):
return self._value_
@DynamicClassAttribute
def values(self):
return self._values_
class Color(Enum):
red = 1
blue = 2
green = 3
print(Color.red.value)
# 実行結果:1
Color.red._values_ = [1]
print(Color.red.values) # インスタンスのvalues
# 実行結果:[1]
print(Color.values) # クラスのvalues
# 実行結果:[1, 2, 3]
上記は自作の簡易版列挙型です。列挙型については後で詳しく紹介します。ここのEnumクラスの各クラス変数はメタクラスEnumMetaによってEnumのインスタンスに変換されました。そして、types.DynamicClassAttributeによって、クラスのvaluesとインスタンスのvaluesはお互い干渉せずに共存できました。このように、クラスとインスタンスに違う動作を実現させたい時はtypes.DynamicClassAttributeを使用すると楽です。
5-4-4-5. __slots__
Pythonには特殊な属性__slots__が存在し、既存クラスに対して、モンキーパッチでの新しい属性の追加を阻止できます。使い方としては以下のようになります。
class Student:
__slots__ = ('name', 'age')
student = Student()
student.name = 'Mike'
student.age = 20
student.grade = 'A'
# 実行結果:
# Traceback (most recent call last):
# File "oop.py", line 10, in <module>
# student.grade = 'A'
# AttributeError: 'Student' object has no attribute 'grade'
公式ドキュメントによると、この機能も実はディスクリプタによって実現されたのです。ここでは実装しませんが、メタクラスとディスクリプタを組み合わせることでこのような機能も実現できます。
5-5. 抽象基底クラス
3-18-7. 純粋人工物で少し触れた概念ではあるが、抽象基底クラスはオブジェクト指向プログラミングにおいて非常に強力な武器です。抽象基底クラスを使って、クラスがある特定のインターフェースを提供しているかを判定することができます。Pythonの標準ライブラリにはabcという抽象基底クラスに必要なツールを提供するモジュールがあり、それを使えば抽象基底クラス、抽象メソッドなどを作成できます。
5-5-1. インターフェース
3. オブジェクト指向に関する概念で「インターフェース」という用語を何度も繰り返しました。インターフェースはソフトウェア工学分野において非常に重要な概念です。よく知られているインターフェースとして、API (Application Programming Interface)が挙げられます。他に、最近「マイクロサービス」で多用されている「gRPC」は本質で言うと、インタフェースを「Protocol Buffers」という「インターフェース定義言語」で定義し、サーバー側とクライアント側はそれぞれそのインタフェースを実装することで、相互通信を実現したものです。また、オブジェクト指向においてのインターフェースはオブジェクトレベルのものを指します。
しかし、JavaやC++と違って、Pythonにはビルトインのインターフェースクラスは存在しません。Pythonでインターフェースと同じ機能を実現するためにはいくつかの方法があります。
5-5-2. 仮想基底クラスによるインターフェース
仮想基底クラスは明示的な継承関係がないにも関わらず、インターフェースに制約をかけられるクラスです。Pythonではメタクラスを利用して、仮想基底クラスを実現できます。
class RESTAPIMeta(type):
def __instancecheck__(cls, instance):
return cls.__subclasscheck__(type(instance))
def __subclasscheck__(cls, subclass):
return (hasattr(subclass, 'get') and
callable(subclass.get) and
hasattr(subclass, 'post') and
callable(subclass.post))
class RESTAPIInterface(metaclass=RESTAPIMeta):
...
class ItemList:
def get(self, id):
pass
def post(self, id):
pass
class UserList:
def get(self, id):
pass
print(issubclass(ItemList, RestAPIInterface))
# 実行結果:True
print(ItemList.__mro__)
# 実行結果:(<class '__main__.ItemList'>, <class 'object'>)
print(issubclass(UserList, RestAPIInterface))
# 実行結果:False
上記はRESTAPIを定義する仮想基底クラスの例です。メタクラスRESTAPIMetaの__subclasscheck__で、getとpostメソッドを持つクラスを子クラスとして判定するよう実装しました。これで、明示的な継承をせずに、クラスのインターフェースに対してある程度の制約をかけることができます。
5-5-3. 抽象基底クラスによるインターフェース
abcモジュールを使って、上記の仮想基底クラスを実装してみましょう。抽象基底クラスはclass MyClass(abc.ABC)またはclass MyClass(metaclass=abc.ABCMeta)の形式で作成できます。
import abc
class RestAPIInterface(metaclass=abc.ABCMeta):
@classmethod
def __subclasshook__(cls, subclass):
return (hasattr(subclass, 'get') and
callable(subclass.get) and
hasattr(subclass, 'post') and
callable(subclass.post))
class ItemList:
def get(self, id):
pass
def post(self, id):
pass
class UserList:
def get(self, id):
pass
print(issubclass(ItemList, RestAPIInterface))
# 実行結果:True
print(ItemList.__mro__)
# 実行結果:(<class '__main__.ItemList'>, <class 'object'>)
print(issubclass(UserList, RestAPIInterface))
# 実行結果:False
__subclasshook__メソッドはabc.ABCMetaから作られたインスタンスクラスのクラスメソッドとして実装することで、issubclassを呼び出すとhookとして機能します。
それから、ABCMeta.registerを使うと、仮想サブクラスを登録することもできます。
import abc
class RestAPIInterface(metaclass=abc.ABCMeta):
...
class UserList:
def get(self, id):
pass
RestAPIInterface.register(UserList)
print(issubclass(UserList, RestAPIInterface))
# 実行結果:True
デコレーターとして使うこともできます。
import abc
class RestAPIInterface(metaclass=abc.ABCMeta):
...
@RestAPIInterface.register
class UserList:
def get(self, id):
pass
print(issubclass(UserList, RestAPIInterface))
# 実行結果:True
また、abc.get_cache_token()で現在の抽象基底クラスのキャッシュトークンを取得できます。このトークンはABCMeta.registerが実行される度に変更されるので、等価性検証に使えます。
import abc
class RestAPIInterface(metaclass=abc.ABCMeta):
...
class UserList:
def get(self, id):
pass
token_old = abc.get_cache_token()
RestAPIInterface.register(UserList)
token_new = abc.get_cache_token()
print(f'{token_old} >>> {token_new}')
# 実行結果:36 >>> 37
5-5-4. 抽象メソッド
これまでのインターフェイスはあくまでも仮想基底クラスなので、継承関係がなく、子クラスに対しての制限も弱いです。特定のインターフェースを実装しないと、エラーを起こす機能を実現したい時は仮想基底クラスではなく、抽象基底クラスと抽象メソッドを合わせて使う必要があります。
import abc
class RestAPIInterface(metaclass=abc.ABCMeta):
@abc.abstractmethod
def get(self, id):
raise NotImplementedError
@abc.abstractmethod
def post(self, id):
raise NotImplementedError
class ItemList(RestAPIInterface):
def get(self, id):
pass
def post(self, id):
pass
class UserList(RestAPIInterface):
def get(self, id):
pass
item_list = ItemList()
user_list = UserList()
実行結果:
Traceback (most recent call last):
File "resource.py", line 29, in <module>
user_list = UserList()
TypeError: Can't instantiate abstract class UserList with abstract methods post
また、abc.abstractmethodはclassmethod、staticmethod、propertyなどと併用することができます。
import abc
class Model(abc.ABC):
@classmethod
@abc.abstractmethod
def select_all(cls):
...
@staticmethod
@abc.abstractmethod
def show_db_name(age):
...
@property
@abc.abstractmethod
def row_id(self):
...
5-4-4. ディスクリプタの使い方で紹介したようなデコレーターの形で使うディスクリプタと一緒に使う時に、ディスクリプタの__isabstractmethod__を実装することで、abc.abstractmethodと併用できるようになります。
import abc
class StaticMethod:
def __init__(self, f):
self.f = f
def __get__(self, obj, objtype=None):
return self.f
@property
def __isabstractmethod__(self):
return getattr(self.f, '__isabstractmethod__', False)
class Model(abc.ABC):
@StaticMethod
@abc.abstractmethod
def show_db_name():
...
class ItemModel(Model):
pass
item_model = ItemModel()
# 実行結果:
# Traceback (most recent call last):
# File "oop.py", line 27, in <module>
# item_model = ItemModel()
# TypeError: Can't instantiate abstract class ItemModel with abstract methods show_db_name
そして、Pythonの抽象メソッドはただのインターフェースではなく、superで継承して、メソッドの中身を獲得できます。
5-5-5. コンテナの抽象基底クラス
標準ライブラリのcollections.abcにはPythonビルトインデータ構造(コンテナ)の抽象基底クラスを提供しています。
| ABC | 継承しているクラス | 抽象メソッド | mixinメソッド |
|---|---|---|---|
| Container | __contains__ | ||
| Hashable | __hash__ | ||
| Iterable | __iter__ | ||
| Iterator | Iterable | __next__ | __iter__ |
| Reversible | Iterable | __reversed__ | |
| Generator | Iterator | send、throw | close、__iter__ 、__next__ |
| Sized | __len__ | ||
| Callable | __call__ | ||
| Collection | Sized、Iterable、 Container |
__contains__、 __iter__ 、__len__ |
|
| Sequence | Reversible、 Collection |
__getitem__、 __len__ |
__contains__、__iter__、__reversed__、 index、count |
| MutableSequence | Sequence | __getitem__、 __setitem__、 __delitem__、 __len__、insert |
Sequenceから継承したメソッドと、 append、reverse、extend、pop、remove、 __iadd__ |
| ByteString | Sequence | __getitem__、 __len__ |
Sequenceから継承したメソッド |
| Set | Collection | __contains__、 __iter__、__len__ |
__le__、__lt__、__eq__、__ne__、__gt__、 __ge__、__and__、__or__、__sub__、__xor__、 isdisjoint |
| MutableSet | Set | __contains__、 __iter__、__len__、 add、discard |
Setから継承したメソッドと、clear、pop、 remove、__ior__、__iand__、__ixor__、 __isub__ |
| Mapping | Collection | __getitem__、 __iter__、__len__ |
__contains__、keys、items、values、get、 __eq__、__ne__ |
| MutableMapping | Mapping | __getitem__、 __setitem__、 __delitem__、 __iter__、__len__ |
Mappingから継承したメソッドと、pop、 popitem、clear、update、setdefault |
| MappingView | Sized | __len__ | |
| ItemView | MappingView、Set | __contains__、__iter__ | |
| KeysView | MappingView、Set | __contains__、__iter__ | |
| ValuesView | MappingView、 Collection |
__contains__、__iter__ | |
| Awaitable | __await__ | ||
| Coroutine | Awaitable | send、throw | close |
| AsyncIterable | __aiter__ | ||
| AsyncIterator | AsyncIterable | __anext__ | __aiter__ |
| AsyncGenerator | AsyncIterator | asend、athrow | aclose、__aiter__、__anext__ |
| (参照:collections.abc — Abstract Base Classes for Containers) |
使い方は通常の抽象基底クラスと同じです。
from collections.abc import Set
class ListBasedSet(Set):
def __init__(self, iterable):
self.elements = []
for value in iterable:
if value not in self.elements:
self.elements.append(value)
def __str__(self):
return repr(self.elements)
def __iter__(self):
return iter(self.elements)
def __contains__(self, value):
return value in self.elements
def __len__(self):
return len(self.elements)
s1 = ListBasedSet('abcdef')
s2 = ListBasedSet('defghi')
overlap = s1 & s2 # __and__は継承されたので、そのまま積集合を計算できる
print(overlap)
# 実行結果:['d', 'e', 'f']
上記はリストベースの集合の実装です。Pythonの通常の集合は辞書と同じくハッシュテーブルを利用して実装されたので、時間計算量的にはリストより速いですが、空間計算量は少し多いので、この実装はメモリ消費量を節約したい時に使用できます。
5-6. 列挙型
列挙型は、変数(正式に言うと識別子)などを有限集合として束ねる抽象データ構造です。本来はオブジェクト指向プログラミングとは無関係のものです。例えば、プロセス指向プログラミング言語のCも列挙型をサポートしています。しかし、JavaやPythonのようなオブジェクト指向プログラミング言語では、列挙型はクラスオブジェクトの形で実現されています。
なぜ列挙型が必要かというと、現実世界ではある有限の範囲内に限定されているデータは結構多いからです。例えば、曜日というのは、週単位に限定された7種類の有限のデータになります。同じく、月も年単位で12種類のデータです。ソフトウェアの中でいうと、CSSのカラーネーム、HTTPコード、真偽値、ファイル記述子など有限な状態の集合は無数にあります。これらを訳のわからない数字ではなく、列挙型で表現すると、コードの可読性が向上し、ロジックも綺麗に見えます。
Pythonの標準ライブラリには、enumという列挙型を作成するモジュールが提供されています。まず、基本的な使い方を見てみましょう。
import enum
class Color(enum.Enum):
red = 1
green = 2
blue = 3
print(Color.red)
# 実行結果:Color.red
print(Color['red'])
# 実行結果:Color.red
print(Color(1))
# 実行結果:Color.red
print(Color.red.value)
# 実行結果:1
print(Color.red.name)
# 実行結果:red
for color in Color:
print(color)
# 実行結果:
# Color.red
# Color.green
# Color.blue
クラス変数と違って、列挙型はiterable objectになっています。
Color.red = 4
# 実行結果:
# Traceback (most recent call last):
# File "oop.py", line 26, in <module>
# Color.red = 4
# File "/Users/kaito/opt/miniconda3/lib/python3.8/enum.py", line 383, in __setattr__
# raise AttributeError('Cannot reassign members.')
# AttributeError: Cannot reassign members.
列挙型のメンバは外部から修正できません。
print(Color.red is Color.green)
# 実行結果:False
print(Color.red == Color.green)
# 実行結果:False
red = Color.red
print(Color.red == red)
# 実行結果:True
print(Color.red < Color.green)
# 実行結果:
# Traceback (most recent call last):
# File "oop.py", line 30, in <module>
# print(Color.red < Color.green)
# TypeError: '<' not supported between instances of 'Color' and 'Color'
enum.Enum列挙型はメンバ間の一致性評価と等価性評価のみサポートします。それ以外の値の比較をしたい時は、enum.IntEnumを使うことができます。
import enum
class Color(enum.IntEnum):
red = 1
green = 2
blue = 3
purple = enum.auto() # valueのオートインクリメント
print(Color.purple > Color.blue)
# 実行結果:True
また、ビッド演算でのメンバの組み合わせを実現したい時はenum.Flagが使えます。
import enum
class Color(enum.Flag):
red = enum.auto()
green = enum.auto()
blue = enum.auto()
purple = enum.auto()
print(Color.__members__)
# 実行結果:
# {'red': <Color.red: 1>, 'green': <Color.green: 2>, 'blue': <Color.blue: 4>, 'purple': <Color.purple: 8>}
print(Color.purple | Color.blue)
# 実行結果:Color.purple|blue
print(Color.purple | 2)
# 実行結果:
# Traceback (most recent call last):
# File "oop.py", line 13, in <module>
# print(Color.purple | 2)
# TypeError: unsupported operand type(s) for |: 'Color' and 'int'
enum.Flagはメンバ間のビッド演算をサポートしていますが、整数値との計算はできません。これを実現するために、enum.IntFlagを使う必要があります。
import enum
class Color(enum.IntFlag):
red = enum.auto()
green = enum.auto()
blue = enum.auto()
purple = enum.auto()
print(Color.__members__)
# 実行結果:
# {'red': <Color.red: 1>, 'green': <Color.green: 2>, 'blue': <Color.blue: 4>, 'purple': <Color.purple: 8>}
print(Color.purple | Color.blue)
# 実行結果:Color.purple|blue
print(Color.purple | 2)
# 実行結果:Color.purple|green
enum.IntFlagはメンバを整数値として扱います。
続いて、普通の列挙型enum.Enumについてもう少し見ていきます。
import enum
class MessageResult(enum.Enum):
SUCCESS = 1
INVALID_MESSAGE = 2
INVALID_PARAMETER = 3
BAD_MESSAGE = 2
print(MessageResult(2))
# 実行結果:MessageResult.INVALID_MESSAGE
class MessageResult(enum.Enum):
SUCCESS = 1
INVALID_MESSAGE = 2
INVALID_PARAMETER = 3
INVALID_MESSAGE = 4
# 実行結果:
# Traceback (most recent call last):
# File "oop.py", line 14, in <module>
# class MessageResult(enum.Enum):
# File "oop.py", line 18, in MessageResult
# INVALID_MESSAGE = 4
# File "/Users/kaito/opt/miniconda3/lib/python3.8/enum.py", line 99, in __setitem__
# raise TypeError('Attempted to reuse key: %r' % key)
# TypeError: Attempted to reuse key: 'INVALID_MESSAGE'
列挙型はメンバのnameのユニーク性を保証しますが、valueに対しては制約しません。
import enum
@enum.unique
class MessageResult(enum.Enum):
SUCCESS = 1
INVALID_MESSAGE = 2
INVALID_PARAMETER = 3
BAD_MESSAGE = 2
# 実行結果:
# Traceback (most recent call last):
# File "oop.py", line 4, in <module>
# class MessageResult(enum.Enum):
# File "/Users/kaito/opt/miniconda3/lib/python3.8/enum.py", line 865, in unique
# raise ValueError('duplicate values found in %r: %s' %
# ValueError: duplicate values found in <enum 'MessageResult'>: BAD_MESSAGE -> INVALID_MESSAGE
enum.uniqueをデコレーターとしてクラスに適用すれば、valueのユニーク性も保証できるようになります。
import enum
MessageResult = enum.Enum(
value='MessageResult',
names=('SUCCESS INVALID_MESSAGE INVALID_PARAMETER'),
)
print(MessageResult.__members__)
# 実行結果:
# {'SUCCESS': <MessageResult.SUCCESS: 1>, 'INVALID_MESSAGE': <MessageResult.INVALID_MESSAGE: 2>, 'INVALID_PARAMETER': <MessageResult.INVALID_PARAMETER: 3>}
ハードコーディングではなく、Functional APIで動的に列挙型を作成することもできます。names引数にスペース区切りの文字列を渡すと、自動採番で数字を割り振ってくれます。
import enum
MessageResult = enum.Enum(
value='MessageResult',
names=(('SUCCESS', 3),
('INVALID_MESSAGE', 2),
('INVALID_PARAMETER', 1))
)
print(MessageResult.__members__)
# 実行結果:
# {'SUCCESS': <MessageResult.SUCCESS: 3>, 'INVALID_MESSAGE': <MessageResult.INVALID_MESSAGE: 2>, 'INVALID_PARAMETER': <MessageResult.INVALID_PARAMETER: 1>}
names引数に階層化したiterable objectを渡すと、それぞれのメンバのvalueを指定できます。
import enum
class Message(enum.Enum):
DB_SAVE_SUCCESS = ('Saved successfully', 201)
INTERNEL_ERROR = ('Internal error happened', 500)
DB_DELETE_SUCCESS = ('Deleted successfully', 200)
DB_ITEM_NOT_FOUND = ('Item not found', 404)
def __init__(self, message, code):
self.message = message
self.code = code
@property
def ok(self):
if str(self.code).startswith('2'):
return True
return False
print(Message.DB_SAVE_SUCCESS)
# 実行結果:Message.DB_SAVE_SUCCESS
print(Message.DB_DELETE_SUCCESS.ok)
# 実行結果:True
print(Message.DB_ITEM_NOT_FOUND.ok)
# 実行結果:False
列挙型のメンバは整数値に限らず、あらゆるデータ型を使うことができます。また、イニシャライザの__init__を実装すると、クラスの評価時にメンバの値は__init__に渡されます。そして、タプルを使えば複数の変数を渡すことができます。
ただし、__init__はメンバの値をカスタマイズすることはできません。メンバをカスタマイズしたい時は、コンストラクタの__new__を実装する必要があります。
import enum
class Coordinate(bytes, enum.Enum):
def __new__(cls, value, label, unit):
obj = bytes.__new__(cls, [value])
obj._value_ = value
obj.label = label
obj.unit = unit
return obj
PX = (0, 'P.X', 'km')
PY = (1, 'P.Y', 'km')
VX = (2, 'V.X', 'km/s')
VY = (3, 'V.Y', 'km/s')
print(Coordinate.PY.label, Coordinate.PY.value, Coordinate.PY.unit)
# 実行結果:P.Y 1 km
print(Coordinate.PY)
# 実行結果:Coordinate.PY
上記は公式ドキュメントに載っている例で、バイナリオブジェクトでメンバの値とその他の情報をまとめて格納する列挙型になります。
列挙型はクラスなので、内部でメソッドまたはダンダーを実装することができます。しかし、列挙型は普通のクラスと違うところがたくさんあります。まず、列挙型は特殊なメタクラスで実現されていて、メンバ(クラス変数)はクラスのインスタンスになります。そのため、__new__と__init__はインスタンス化のタイミングではなく、クラス評価時に機能します。それから、列挙型はいくつか特殊な属性を持っています。
-
__members__:member_name:memberのマッピングで、読み出し専用です。 -
_name_: メンバ名 -
_value_:メンバの値、__new__で設定や変更できます。 -
_missing_:値が見つからなかった時に使われる検索関数です;オーバーライドできます。 -
_ignore_:リストまたは文字列で、その中身の要素と一致するクラス変数はメンバに変換されなくなります。 -
_order_:メンバの順番を維持するためのクラス属性です;例えば、_order_ = 'red green blue'で定義すると、この順番と違う形でメンバを定義したら、エラーを起こします。 -
_generate_next_value:Functional APIやenum.autoに使用され、あるメンバの適切な値を取得します;オーバーライドできます。
ちなみに、前後に1つのアンダースコアの付いた属性のことを_sunder_というらしいです。
5-7. データクラス
ここまで、Pythonのオブジェクト指向プログラミングのほとんどを見てきました。Pythonだけの問題ではなく、オブジェクト指向プログラミング言語全般の問題ではありますが、クラスの定義は非常に煩雑です。Pythonでは大体の場合、クラスの作成する時に、__init__の定義は最低限必要です。場合によっては他の特殊メソッドも実装しなければなりません。それに加えて、似たようなクラスを大量に作らなければならない時もあります。このようなコードの冗長性をボイラープレート・コードと呼びます。
簡単にクラスを作る1つの手として、types.SimpleNamespaceを使うことができます。
import types
bbox = types.SimpleNamespace(x=100, y=50, w=20, h=20)
print(bbox)
# 実行結果:namespace(h=20, w=20, x=100, y=50)
print(bbox==bbox)
# 実行結果:True
Pythonでtypes.SimpleNamespaceと同じ機能を実装すると以下のようになります。
class SimpleNamespace:
def __init__(self, /, **kwargs):
self.__dict__.update(kwargs)
def __repr__(self):
items = (f"{k}={v!r}" for k, v in self.__dict__.items())
return "{}({})".format(type(self).__name__, ", ".join(items))
def __eq__(self, other):
return self.__dict__ == other.__dict__
__init__、__repr__、__eq__は実装してくれましたが、__hash__や他の比較演算用特殊メソッドを実装したい時は結構面倒で、逆にコードの可読性が下がってしまう可能性があります。types.SimpleNamespaceはあくまでもシンプルなクラス(名前空間)を作るためのものです。
ボイラープレート・コードの問題に気づいたサードパーティライブラリの開発者たちがいて、クラスの定義をシンプルにするツールを開発してくれました。attrsはその1つです。基本的な使い方は以下のようになります。
from attr import attrs, attrib
@attrs
class Person:
name = attrib(type=str)
sex = attrib(type=str)
age = attrib(type=int, default=0)
mary = Person('Mary', 'F', 18)
print(mary)
# 実行結果:Person(name='Mary', sex='F', age=18)
print(mary == mary)
# 実行結果:True
attrsはクラスデコレーターの形で使用できます。ここでは、3つのインスタンス変数を定義し、ageにデフォルト引数を設定しました。attrsは、__init__と__repr__を自動的に定義してくれます。また、__eq__、__ne__、__lt__、__le__、__gt__、__ge__も定義してくれて、比較対象はインスタンス変数のタプルになります。
詳しい紹介を省きますが、attrsはtypes.SimpleNamespaceより高度なツールで、様々な機能があり、Pythonのオブジェクト指向プログラミングにとっては強力なツールになります。
ボイラープレート・コードを解消するために、公式の動きとしてPython 3.7から導入されたデータクラス(dataclasses)というモジュールがあります。このモジュールは特殊メソッドの生成など、attrsと似たような機能を提供しています。
from dataclasses import dataclass
from typing import ClassVar
from functools import cached_property
import boto3
@dataclass
class S3Image:
bucket: str
key: str
img_id: int = 1
client: ClassVar = boto3.client('s3') # クラス変数
@cached_property
def image_url(self, http_method: str) -> str:
return self.client.generate_presigned_url(...)
item_image_1 = S3Image('Image', 'ItemImage')
print(item_image_1)
# 実行結果:S3Image(bucket='Image', key='ItemImage', img_id=1)
print(item_image_1 == item_image_1)
# 実行結果:True
データクラスはPythonの型アノテーションの形式でクラスのメンバ変数を定義できます。そして、__init__、__repr__を実装してくれます。attrsと違うのは、比較演算用の特殊メソッドはデフォルトでは__eq__しか実装してくれません。そして、実装してほしいメソッドはdataclassクラスデコレーターの引数として定義できます。デフォルトでは以下のようになります。
@dataclass(init=True, repr=True, eq=True, order=False, unsafe_hash=False, frozen=False)
class C:
...
それぞれの引数の役割はほぼ自明です。
-
orderは__eq__以外の比較演算用特殊メソッドの__ne__、__lt__、__le__、__gt__、__ge__の自動追加のフラグです。Trueにするにはeq引数もTrueにしなければなりません。 -
unsafe_hashは__hash__の挙動を制御するフラグです。unsafe_hash=Trueにすると、__hash__メソッドが自動的に追加されますが、不変(immutable)オブジェクトではない時に問題が生じるかもしれません。デフォルトではeqとfrozen両方がTrueの時に、__hash__メソッドは自動的に追加されるので、フラグによる制御は不要です。eq=True、frozen=Falseの場合は親クラスの__hash__を継承し、eq=False、frozen=Trueの場合は__hash__ = Noneに設定されます。また、__hash__を定義した状態ではunsafe_hash=Trueにすることはできません。 -
frozenは、フィールド(メンバ)に対する値の代入をコントロールするフラグです。Trueの場合は、代入を阻止し、読み出し専用になります。
また、データクラスにはfieldという関数が存在し、フィールドごとのコントロールができます。
from dataclasses import dataclass, field
from typing import List
@dataclass
class C:
mylist: List[int] = field(default_factory=list)
c = C()
c.mylist += [1, 2, 3]
fieldは以下の引数を受け取り、Fieldオブジェクトを返します。
-
defaultはフィールドのデフォルト値を提供する引数です。defaultとdefault_factoryは共存できません。 -
default_factoryは引数なしで呼び出せるオブジェクトを受け取り、フィールドのデフォルトのファクトリーを提供します。例えば、上記の例ではlistが提供され、それでフィールドのデフォルトのデータ構造を作成します。 -
initは__init__にフィールドを含むかどうかのフラグです。 -
reprは__repr__にフィールドを含むかどうかのフラグです。 -
compareは__eq__や__gt__などの比較演算用特殊メソッドにフィールドを含むかどうかのフラグです。 -
hashは__hash__にフィールドを含むかどうかのフラグです。hash=Noneの場合はcompareを使ってハッシュ値を計算します。公式では、hash=Noneが推奨されています。 -
metadataはマッピングまたはNoneを受け取り、マッピングの場合は読み出し専用の辞書types.MappingProxyTypeにラップされます。主に、サードーパーティーのモジュールなどが使用するものです。
fields関数で、データクラスのフィールドオブジェクトをタプルの形で全部取得することができます。
from dataclasses import fields
print(fields(c))
# 実行結果:
# (Field(name='mylist',type=typing.List[int],default=<dataclasses._MISSING_TYPE object at 0x7f8aa098a9a0>,
# default_factory=<class 'list'>,init=True,repr=True,hash=None,compare=True,metadata=mappingproxy({}),_field_type=_FIELD),)
asdictとastupleはデータクラスのインスタンスを辞書とタプルに変換します。
@dataclass
class Point:
x: int
y: int
@dataclass
class Points:
pl: List[Point]
p = Point(10, 20)
assert asdict(p) == {'x': 10, 'y': 20}
assert astuple(p) == ((10, 20))
ps = Points([Point(0, 0), Point(10, 4)])
assert asdict(ps) == {'pl': [{'x': 0, 'y': 0}, {'x': 10, 'y': 4}]} # 再帰的に処理される
make_dataclassという動的にデータクラスを作る関数もあります。
from dataclasses import dataclass, field, make_dataclass
C = make_dataclass('C',
[('x', int),
'y',
('z', int, field(default=5))],
namespace={'add_one': lambda self: self.x + 1})
# 下の書き方と同様
@dataclass
class C:
x: int
y: 'typing.Any'
z: int = 5
def add_one(self):
return self.x + 1
データクラスのインスタンスに修正を加え、同じ型のオブジェクトを新しく作るための関数replaceも提供されています。
from dataclasses import dataclass, replace
@dataclass
class Point:
x: int
y: int
def __post_init__(self):
print('__post_init__')
p1 = Point(1, 2)
# 実行結果:__post_init__
p2 = replace(p1, x=2)
# 実行結果:__post_init__
print(p2)
# 実行結果:Point(x=2, y=2)
replaceは__init__を呼び出して新しいインスタンスを作成するのですが、 __post_init__が定義されている場合は__init__の後に呼び出します。
他に、データクラスを判別するための関数is_dataclassも提供されています。データクラスかデータクラスのインスタンスに使用する場合のみ、Trueが返ってきます。
5-8. MRO
MRO(Method Resolution Order、メソッド解決順序)は、多重継承において、継承チェーン上でメソッドを探索する時の順序です。PythonのMROアルゴリズムは、「Python 2.2の古いクラス」、「Python 2.2の新しいクラス」、「Python 2.3以降の新しいクラス」の3種類存在します。
なぜMROが必要かというと、以下の例を見てください。
class D:
def method(self):
...
class C(D):
def method(self):
...
class B(D):
pass
class A(B, C):
pass
上記のコードは「菱形継承問題」と呼ばれる現象です。クラスAはmethodをどのクラスから継承すれば良いのかを探索する必要があります。
Python 2.2の古いクラスはDFS(深さ優先探索)を採用しています。イメージとしては以下の図のようになります。
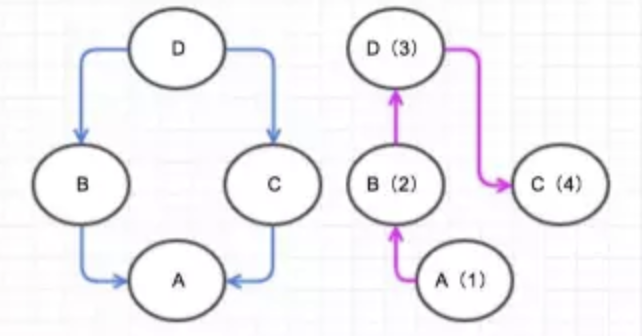
図の左は継承関係を表すもので、矢印は子クラスを指します。右はMROの探索順序です。DFSでは、クラスAはまず(B, C)の左にあるBから、Dまで辿り着き、Dはmethodを実装しているので、それを継承して探索を終えます。継承関係を見ると、CのほうがAに近いので、本来はCのmethodを継承するのが正しいであるため、DFSはうまく菱形継承問題を解決できないですね。
Python 2.2の新しいクラスはobjectを継承するクラスです。つまり、全ての新しいクラスは共通の祖先クラスobjectを持ちます。そのため、Mixin継承をする時にDFSではメソッドを正しく継承できないので、その対応としてMROアルゴリズムはDFSからBFS(幅優先探索)に変えられました。
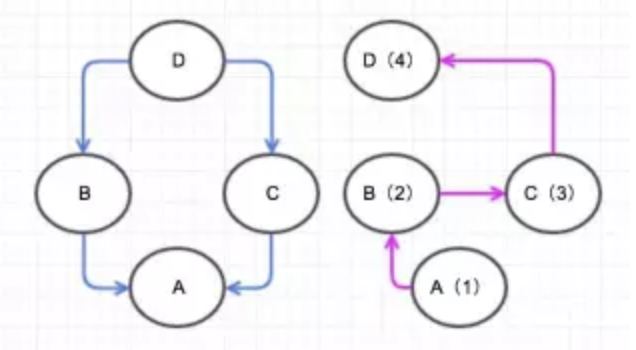
BFSでは、クラスAはBから、横にあるCを先に探索しますので、菱形継承の場合は正しくメソッドを継承できます。しかし、通常の継承パターンは少し問題があります。
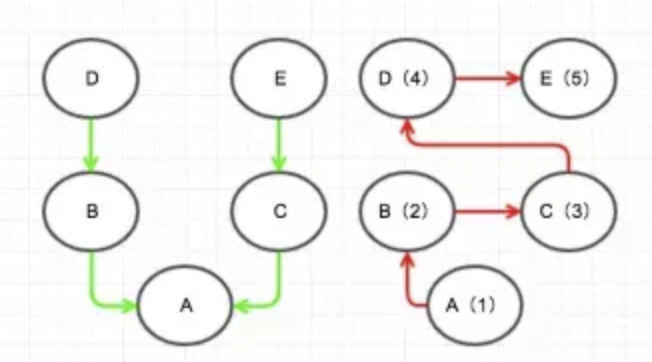
上記の図は通常のMixin継承です。右のMROは一見問題ないように見えますが、実は違いますね。
class E:
pass
class D:
def method(self):
...
class C(E):
def method(self):
...
class B(D):
pass
class A(B, C):
pass
例えば、上記のような場合、本来ならAはBからDに辿り着き、そのmethodを継承するのです。BFSになると、Cのmethodが先に探索されるため、Dまでは辿り着かなくなります。BとBの親のDから探す順序は単調写像と呼びます。
BFSは単調写像の性質を違反しているため、Python 2.3以降はC3というアルゴリズムでMROを解決するようになりました。C3は「A Monotonic Superclass Linearization for Dylan」という論文で公開されたもので、BFSとDFSの問題点を解決し、単調写像を満たした完璧なアルゴリズムになります。
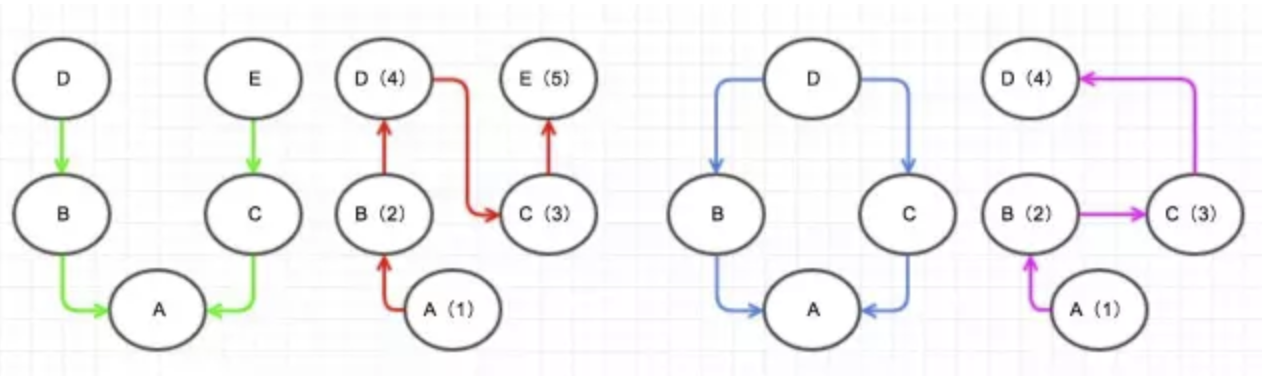
C3は以下の3つの性質を持っています。
- precedence graph(有向非巡回グラフ)
- 局所の優先順位を保持
- 単調写像
C3アルゴリズムの計算については、「The Python 2.3 Method Resolution Order」の記事に詳しく書かれています。C3は継承チェーンを有向非巡回グラフとして扱うため、循環継承だとエラーになることを注意してください。
また、クラスのMROを参照したい時は、mro()関数や__mro__属性の他に、inspect.getmro()関数を使うこともできます。
まとめ
オブジェクト指向の歴史から、OOPの関連概念、Pythonのオブジェクト指向プログラミングについて隅々まで見てきました。しかし、オブジェクト指向プログラミングは奥深いので、まだまだ学ぶことが多いです。今回はデザインパターンについて詳しく説明できませんでしたが、また別の記事で紹介したいと思います。
参考
Data Model
Built-in Functions
inspect — Inspect live objects
types — Dynamic type creation and names for built-in types
Descriptor HowTo Guide
abc — Abstract Base Classes
collections.abc — Abstract Base Classes for Containers
enum — Support for enumerations
dataclasses — Data Classes
What are metaclasses in Python?
Python Types and Objects(リンク切れ)