1. はじめに
この記事はNuco Advent Calendar 2022の12日目の記事です。
1-1. 対象者
この記事は
・正規表現に触れたことがあるけど、結局なんだったのかわかっていない
・正規表現の考え方にイマイチ慣れない
・正規表現って美味しいんですか?
というような正規表現初心者の方に向けて書いています。
1-2. この記事を読むメリット
大きなメリットとしては「正規表現の考え方」を身につけることができるはずです。
また記事の最後では正規表現のサンプル集、参考記事および練習サイトを紹介しています。
足りない知識をカバーし実際に手を動かすことで身についていくので、この記事と合わせて参考記事を読んだり練習問題にチャレンジしてみてください。
2. 導入知識
2-1. 正規表現のメリット
具体的な話に入る前に、正規表現を使えばどのようなことができるのか紹介します。
正規表現を用いればVSCodeなどで共通のパターンに一致するテキストを検索、置換することが可能です。
例えば下記のような電話番号の集合があったとします。
111-1234-56789
222-4649-98712
000(5252)78787
444(1111)12345
000(1234)99999
632-7777-00000
このように真ん中4桁の数字が--で囲まれている番号と()で囲まれている番号がありますね。
正規表現を使えば、この電話番号の集合から先頭が000かつ()が使われている番号を一括で検索することができます。
この例では電話番号の数が少ないのであまりメリットを感じられないかもしれませんが、これがもっと多かったときに正規表現の威力を感じることができます。
もう一つ例を挙げてみましょう。
以下は渋谷区役所、新宿区役所、世田谷区役所の住所になります。
〒150-8010 東京都渋谷区宇田川町1-1
〒160-8484 東京都新宿区歌舞伎町1丁目1-1
〒154-8504 東京都世田谷区世田谷4丁目21-27
正規表現を使えばこれらの郵便番号や「東京都」、「〜〜区」の箇所を一気に置換することが可能です。
実際にVSCodeで郵便番号を正規表現で検索し、一気に置換する様子を確認してみましょう。
下図の右側に上記の住所があります。
それぞれの郵便番号を117-4649にまとめて置換していることが確認できますね。

2-2. 正規表現とは
正規表現(せいきひょうげん、英: regular expression)は、文字列の集合を一つの文字列で表現する方法の一つである。
(wikipediaより)
こんなことを言われてもパッと理解することは難しいですよね。
順を追って少しずつ説明していきます。
まずは正規表現を理解するために、集合について簡単におさらいしていきます。
2-2-1. 集合とは
「集合」とは、「要素」の集まりのことで、「要素」とは、それ以上分割できない個別のものを指します。
これについて、偶数の集合を具体例として見ていきましょう。
偶数の集合は正負の整数(要素)を含めた下記のイメージとなります。
(集合内の「...」は要素が無限個あることを示しています。)
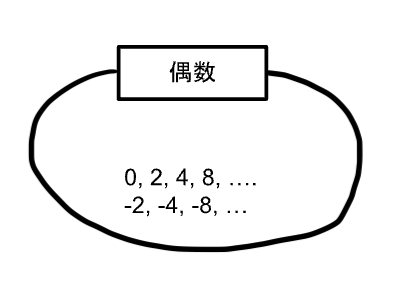
上記の「2」「4」「-4」などが要素であり、これら要素が集まった手書きの◯が集合を表しております。
要素は集合の中で一意(○の中で重複がない)となっております。
ここで、偶数の集合のイメージを利用しながら別の集合である3の倍数でさらに見ていきましょう。
先程の図の右側に水色で囲まれた集合が追加されていますね。
これが3の倍数の集合のイメージになります。
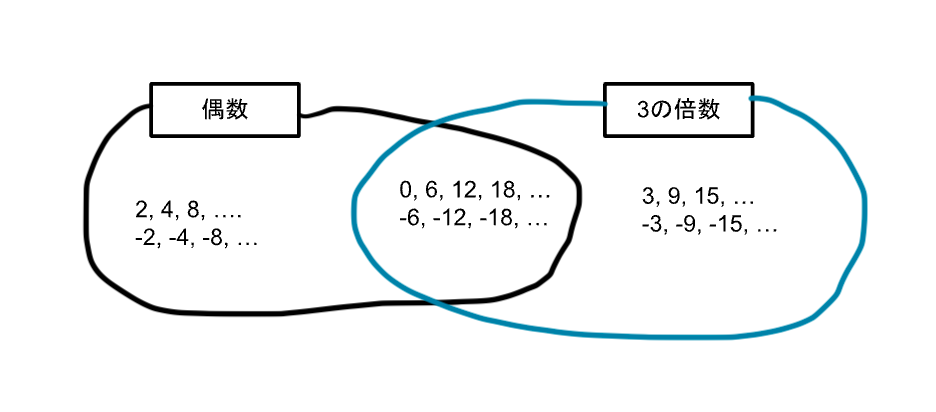
3の倍数の要素は正負を含め「3」「6」「-18」などがあります。
ここで、下記イメージの二つの集合に含まれている赤線の集合は「偶数」かつ「3の倍数」の要素の集合となります。
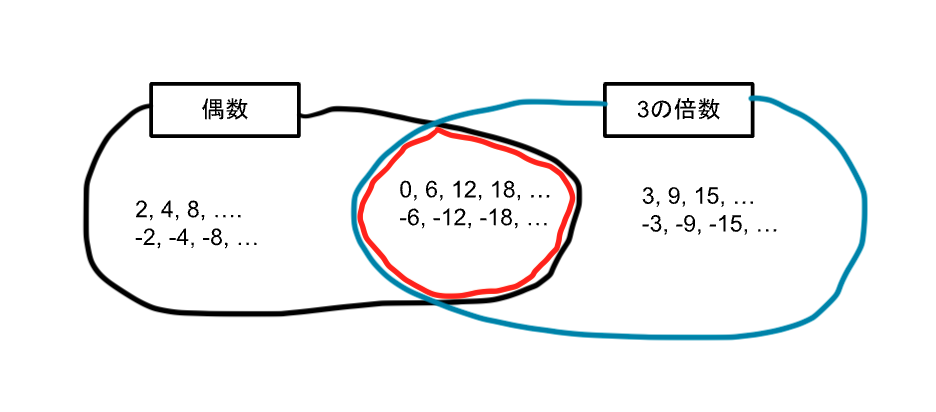
この赤線の集合のことを「積集合」と言います。
また下記のイメージのオレンジ線の集合は「偶数」または「3の倍数」の要素の集合となります。
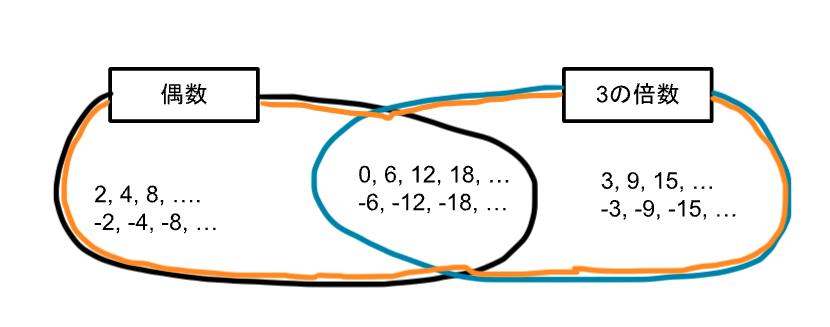
ここのオレンジ線の集合のことを「和集合」と言います。
以上が集合の基礎的な説明になります。
以降の正規表現の説明では、この集合の考え方が肝となってきます。
(集合の詳細についてはこの記事で説明しないので、気になる方はご自身で調べていただきますようお願いします。)
2-2-2. リテラルとメタ文字
正規表現の具体的な話に入っていきたいと思います。
正規表現はリテラル・メタ文字の組み合わせによるパターンで表現されます。
リテラル
文字列そのものことを言います。
「空」「東京」「バナナ」などといった通常の文字列のことを指します。
メタ文字
特別な働きをする文字列のことを言います。
例えば「.」「*」「^」「$」などの文字列は正規表現の中で特殊な働きをします。
正規表現とはリテラルとメタ文字を用いパターンを指定することを意味しています。
噛み砕いて理解するために、ちょっとした具体例で確認していきましょう。
いきなりですが 僕はチェンソーマンのマキマちゃんが大好物です。 とテキストがあったとします。
ここのマキマの箇所をパワーやヒメノのように他のキャラクターでも表せるようにしたい場合、下記のように正規表現で表すことで可能となります。
僕はチェンソーマンの...ちゃんが大好物です。
「マキマ」を「...」に置き換えていますね。
この「.」をメタ文字と言い、「僕はチェンソーマンの」と「ちゃんが大好物です。」がリテラルになります。
「.」自体は「任意の1文字」という特別な意味を持っていますが、これについては次の章で説明します。
2-3. 基本的なメタ文字
ここまでで正規表現と集合の基礎的な知識を身につけられたと思われます。
次からは基本的なメタ文字についてお伝えします。
先程の例では「.」が「任意の1文字」という意味を持つと述べました。
正規表現にはこのような特殊な意味や働きを持つメタ文字がたくさんあります。
ここで基本的なメタ文字とその意味・働きを紹介しますが、留意していただきたいことがあります。
この記事ではメタ文字を全て網羅しません。
これから紹介するメタ文字だけがその意味・働きを持つわけではない(他のメタ文字でも同じ意味・働きを持つものもある)と言う点にご注意ください。
それでは基本的なメタ文字を見ていきましょう。
| メタ文字 | 意味 |
|---|---|
| [ABC] | A,B,Cのいずれか1文字 |
| [^ABC] | A,B,C以外の1文字 |
| [A-Z] | 大文字英語の1文字 |
| [a-z] | 小文字英語の1文字 |
| [A-Za-z] | 大文字・小文字英語の1文字 |
| [0-9] | 数字の1文字 |
| | | 2項目以上のいずれか |
| . | 任意の1文字 |
| ^ | 行の先頭を指定 |
| $ | 行の末尾を指定 |
※[ABC]および[^ABC]ですが、これは具体例としてABCを挙げています。実際には[]の中は任意の文字列になります。
上記のメタ文字とリテラルを使った正規表現の1例で確認していきます。
※{}内の末尾に...がある集合は無限個の要素があることを意味しています。
# 正規表現
[ABC]D
# 意味
A,B,Cのいずれか1文字の直後にDがある2文字
# 正規表現が表す集合に含まれる文字列
{AD, BD, CD}
# 正規表現が表す集合に含まれない文字列
{DD, DA, aD, ab, ABC, ...}
# 正規表現
[^ABC]D
# 意味
A,B,Cのいずれでもない1文字の直後にDがある2文字
# 正規表現が表す集合に含まれる文字列
{DD, aD, 7D, ...}
# 正規表現が表す集合に含まれない文字列
{AD, BD, CD, DA, ab, ABC, ...}
#正規表現
[A-Z]7
# 意味
大文字英語1文字の直後に数字の7がある2文字
# 正規表現が表す集合に含まれる文字列
{A7, B7, ..., Z7}
# 正規表現が表す集合に含まれない文字列
{a7, A1, D87, ...}
# 正規表現
AB[a-z]
# 意味
ABの文字列の直後に小文字英語1文字がある3文字
# 正規表現が表す集合に含まれる文字列
{ABa, ABb, ..., ABz}
# 正規表現が表す集合に含まれない文字列
{ABD, AB1, dDa, ABfu, ...}
# 正規表現
[A-Za-z]D
# 意味
大文字または小文字英語のいずれかの1文字の直後にDがある2文字
# 正規表現が表す集合に含まれる文字列
{AD, cD, ..., Zz}
# 正規表現が表す集合に含まれない文字列
{1D, AB, U1D, ...}
# 正規表現
[0-9][0-9]
# 意味
数字の2文字
# 正規表現が表す集合に含まれる文字列
{11, 32, ..., 99}
# 正規表現が表す集合に含まれない文字列
{a1, AA, 123, ...}
# 正規表現
...
# 意味
任意の3文字
# 正規表現が表す集合に含まれる文字列
{マキマ, パワー, 東京都, ...}
# 正規表現が表す集合に含まれない文字列
{愛, 1A, 麻婆豆腐, ...}
# 正規表現
(Green|Red|Blue)
# 意味
RED,BLUE,GREENのいずれかの文字列
# 正規表現が表す集合に含まれる文字列
{RED,BLUE,GREEN}
# 正規表現が表す集合に含まれない文字列
{BLACK, YELLOW, 100, abc, ...}
# 正規表現
^a
# 意味
先頭にaがある文字列
# 正規表現が表す集合に含まれる文字列
{a, ab, a1Z, ...}
# 正規表現が表す集合に含まれない文字列
{b, ca, d8d, ...}
# 正規表現
a$
# 意味
末尾にaがある文字列
# 正規表現が表す集合に含まれる文字列
{a, ba, 12a, ...}
# 正規表現が表す集合に含まれない文字列
{ab, BB, a12, ...}
以上が基本的なメタ文字とその例になります。
2-4. 基本的な量指定子
量指定子とはメタ文字の中で直前の文字の繰り返しを表現する働きをもつ文字列です。
まず基本的な量指定子とその働きを下記に上げてみます。
| 量指定子 | 意味 |
|---|---|
| * | 直前の文字を0回以上繰り返したものに一致 |
| + | 直前の文字を1回以上繰り返したものに一致 |
| ? | 直前の文字が0又は1回表示したものに一致 |
| {n} | 直前の文字がn回繰り返したものに一致 |
次に上記の量指定子とリテラルを使った正規表現の1例で確認していきます。
# 正規表現
hog*e
# 意味
*の直前の文字のgが0回以上あり且つhoとeが前後に存在する文字列
# 正規表現が表す集合に含まれる文字列
{hoe,hoge,hogge,hoggge, ...}
# 正規表現が表す集合に含まれない文字列
{ho, oe, oge, ...}
# 正規表現
hog+e
# 意味
+の直前の文字のgが1回以上あり且つhoとeが前後に存在する文字列
# 正規表現が表す集合に含まれる文字列
{hoge,hogge,hoggge, ...}
# 正規表現が表す集合に含まれない文字列
{hoe, oge, ...}
# 正規表現
hog?e
# 意味
?の直前の文字のgが0回か1回あり且つhoとeが前後に存在する文字列
# 正規表現が表す集合に含まれる文字列
{hoe,hoge}
# 正規表現が表す集合に含まれない文字列
{hogge, hoggge, ...}
# 正規表現
hog{3}e
# 意味
gが3回あり且つhoとeが前後に存在する文字列
# 正規表現が表す集合に含まれる文字列
{hoggge}
# 正規表現が表す集合に含まれない文字列
{hoge, hogge, hogggge, ...}
引き続き、量指定子を用いて正規表現がまとめられることを確認していきましょう。
# 正規表現 (修正前)
[A-Z][A-Z]
# 意味
大文字英語2文字
# 正規表現 (修正後)
[A-Z]+
# 正規表現が表す集合に含まれる文字列
{AB, DE, ..., ZZ}
# 正規表現が表す集合に含まれない文字列
{ab, 1A, ABC, ...}
# 正規表現 (修正前)
......
# 意味
任意の6文字
# 正規表現 (修正後)
.* または .+
# 正規表現が表す集合に含まれる文字列
{ABCDEF, 123456, acbCD56, ...}
# 正規表現が表す集合に含まれない文字列
{A, 12C, ...}
正規表現で繰り返し表しているパターンを量指定子を用いて簡潔にすることができました!
この章のまとめ
・正規表現用いると共通のパターンに一致する文字列を検索、置換することが可能
・正規表現を構成するものは「リテラル」と「メタ文字」である
・リテラルとは「空」「東京」「バナナ」などといった通常の文字列である
・メタ文字とは特別な働きをする文字列である
・量指定子とはメタ文字の中でも直前の文字の繰り返しを表現する文字列である
・量指定子を利用すると正規表現の繰り返し箇所をまとめることができる
3. 具体例で考える
3-1. 正規表現チェッカーについて
以降では正規表現チェッカーというサイトを利用して正規表現を確認していきます。
使い方は下記のイメージのとおりです。
「対象の文字列」内の文字列に対して、「チェックしたい正規表現」内に書いた正規表現が一致する箇所があれば右下に表示されます。
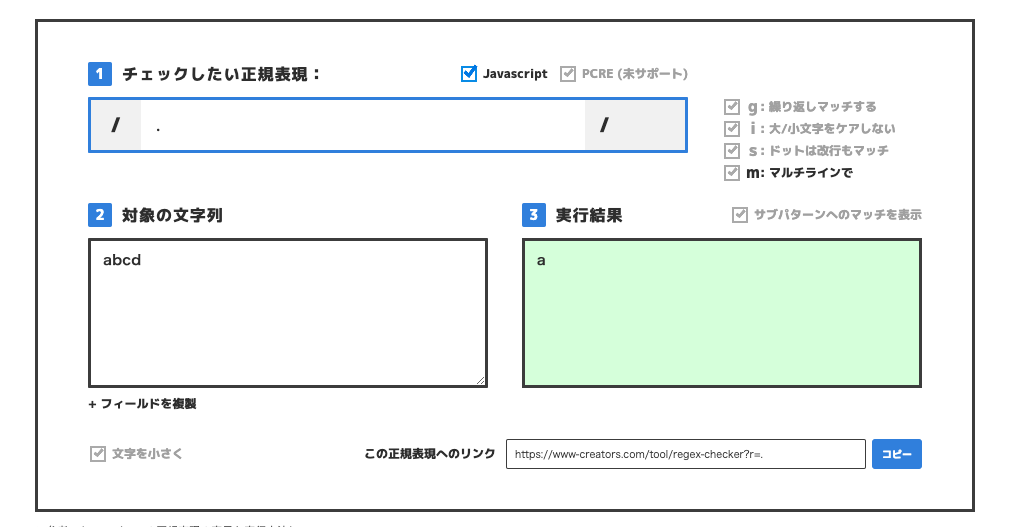
注意点
正確には正規表現で表される文字列の集合に含まれる、対象の文字列の部分文字列のうち先頭の部分文字列を表示しています。
部分文字列とは、文字列を構成する1文字以上を元の順番で並べ得られる文字列のこと言います。
上記例でいうと、文字列「abcd」の部分文字列は「a」「b」「c」「d」「ab」「bc」「cd」「abc」「bcd」「abcd」となります。
それでは部分文字列と正規表現のイメージについて、少し詳しくみていきましょう。
例として文字列「abcDE」があったとします。
文字列「abcDE」は「abcD」や「ab」の部分文字列を含んでおり、その集合は下図の左側のようになります。
これら部分文字列のうち「DE」を含むような、正規表現の1つに[A-Z][A-Z]があります。
[A-Z][A-Z]は「AB」や「ES」などの大文字英語2文字の集合を表しており、下図の右側のようになります。
(...は要素が無限個あることを意味しています。)
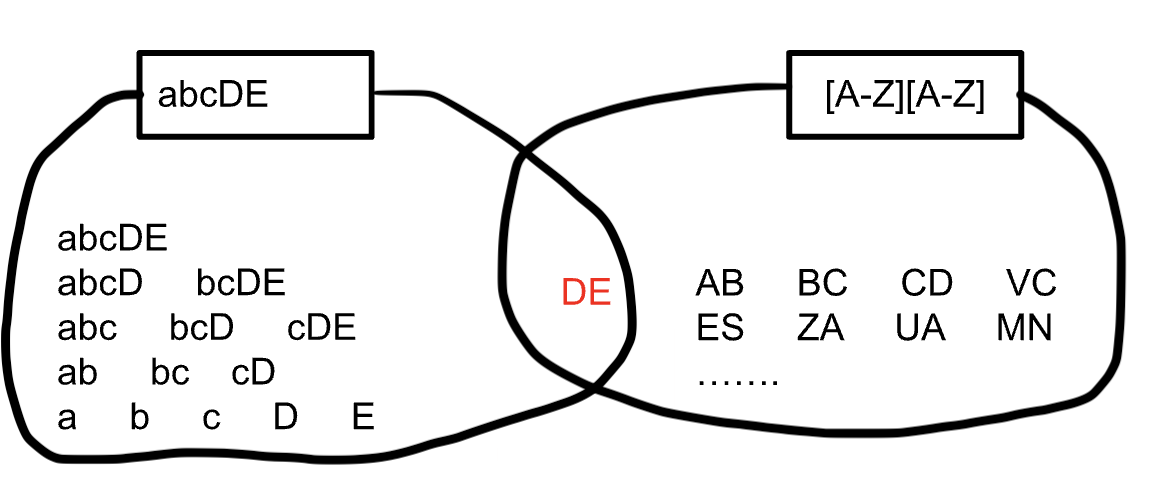
このイメージが文字列と正規表現の関係を表しています。
同様に「AbCdE7」でも確認していきましょう。
文字列「AbCdE7」は「AbCdE」や「bCd」などの部分文字列を含んでおり、下図の左側のような文字列の集合になります。
これら部分文字列のうち「AbCdE7」を含むような、正規表現の1つに......があります。
......は文字列「hogeho」や「123456」などの任意の6文字の集合を表しており、下図の右側のようになります。
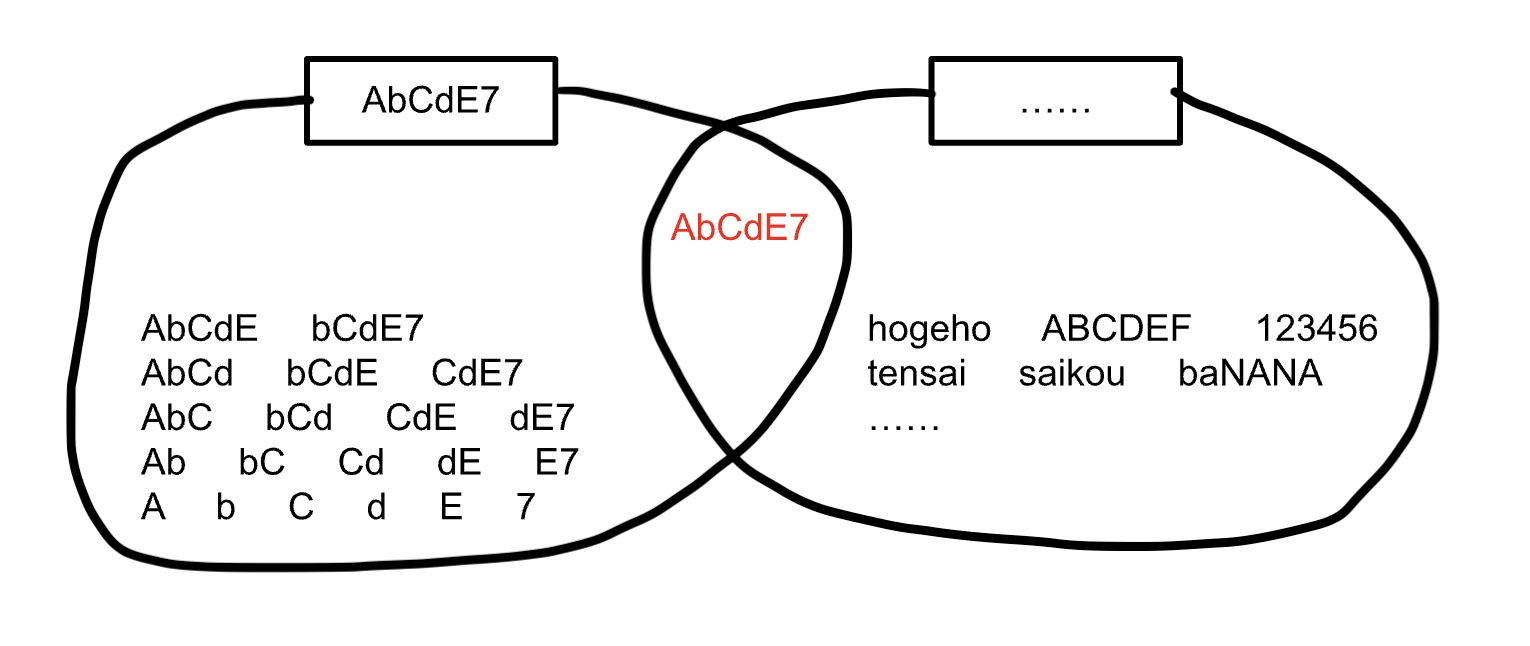
上記の正規表現は一例です。
実際には、前者の「DE」を含む正規表現は他にも[DE][DE]や[A-Z]+などがあります。
後者「AbCdE7」も[A-Z].[ACE].+などの正規表現で表すことができます。
部分文字列と正規表現の関係は上記のとおりとなりますが、イメージを掴めたでしょうか。
ここで文字列「abcd」の例に戻って正規表現チェッカーの機能について説明を続けていきます。
上の図の対象文字列「abcd」、正規表現「.」とした時、実行結果欄に「a」のみが表示されています。
しかし「.」は任意の1文字を意味しているので、実際には「b」「c」「d」もこの正規表現に含まれています。
イメージで確認していきましょう。
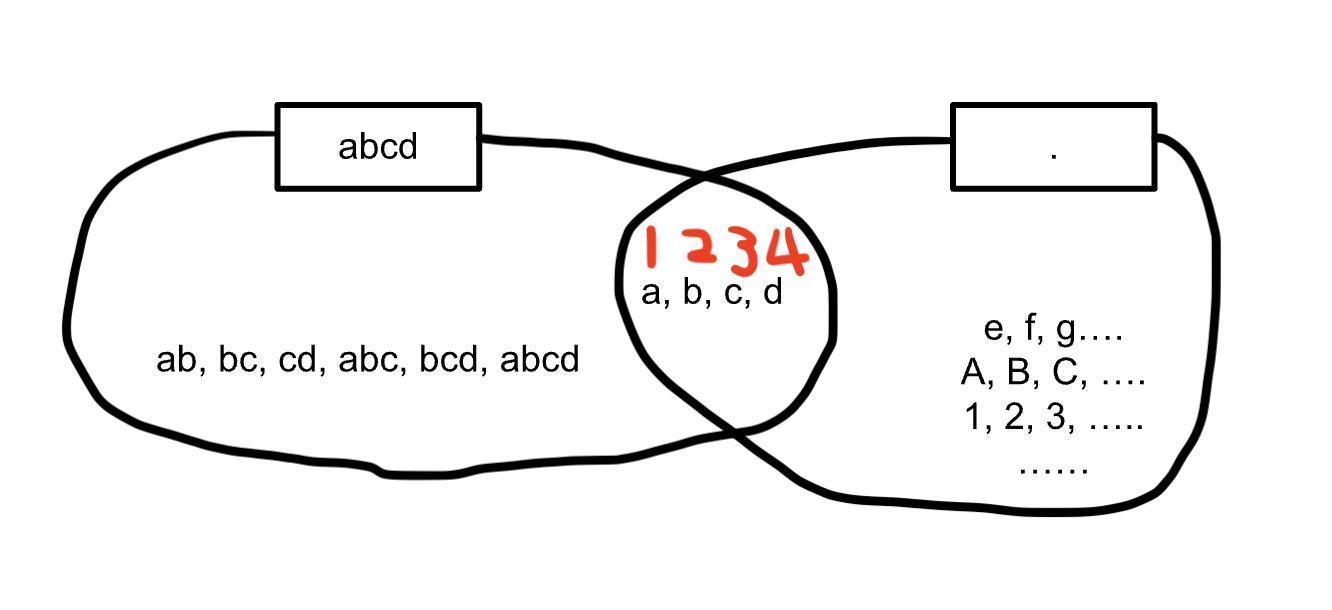
正規表現「.」には「a」「b」「c」「d」が含まれるのですが、正規表現チェッカーの機能で先頭の文字列「a」(1番目)のみを実行結果に表示しているのです。
(赤い数字が文字列の順番を示しています。)
もう一つ例を挙げてみましょう。
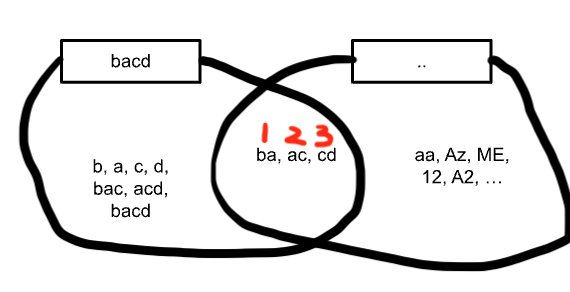
対象の文字列を「bacd」、正規表現を「..」とした時の実行結果が「ba」となっています。

これも実際には「ac」「cd」も正規表現「..」で表される文字列の集合に含まれるのですが、先頭の「ba」のみが実行結果に表示されます。
3-2. 最大量指定子と最小量指定子
次に最大量指定子と最小量指定子について説明していきたいと思います。
いきなりですが、下記の文字列と量指定子「+(または(*))」を使った正規表現があった場合、どこが正規表現に含まれるのか考えてみましょう。
# 文字列
My milk is bottled in black milk bottle
# 正規表現
m.+k(またはm.*k)
# 意味
mの後ろに任意の文字が1回以上あり、かつkで終わる
この正規表現に含まれる文字列は複数考えられるのですが、それらを下記に上げてみます。
milk
milk is bottled in black
milk is bottled in black milk
実は上記の中でmilk is bottled in black milkだけが正規表現に含まれます。
これを正規表現チェッカーで確認してみます。

このように対象の文字列の中で複数の箇所が正規表現に含まれるとき、最大数の部分文字列を指定する量指定子のことを最大量指定子と言います。(+や*のこと)
一方で「milk」だけを正規表現に含めることもできます。
それは m.+?kです。
これも正規表現チェッカーで確認してみましょう。

先程の正規表現の末尾に「?」が加わりましたが、これによりできるだけ文字数の少ない箇所を正規表現に含めることが可能になります。
このように対象の文字列の中で複数の箇所が正規表現に含まれるとき、最小数の部分文字列を指定するような量指定子のことを最小量指定子と言います。
また上記例からわかるように量指定子はデフォルトで最大量指定子になります。
複数の文字列が正規表現に含まれるときに最小文字数の文字列だけを指定したい場合は最小量指定子「?」を加える必要があります。
3-3. パターンの見つけ方のコツ
正規表現のパターンを見つけるのは、初めはとても苦労するところだと思います。
筆者も初めの頃は、ネットで当てはまりそうなパターンを色々と調べ、繰り返し試していました。
この章でパターンの見つけ方のコツについて、具体例を用いて説明していきます。
また正規表現チェッカーの実行結果に表示されることを「一致」という言葉を使って説明していきます。
最初にパターンの見つけ方のコツの結論を言ってしまうと、
1. 一致しそうなパターンを忠実に当てはめる
2. 簡潔にすることを考える
になります。
上記について具体的にどのように考えるのか、チェンソーマンの例で見ていきましょう。
3-3-1. 一致しそうなパターンを忠実に当てはめる
僕はチェンソーマンのマキマちゃんが大好物です。
「マキマ」が他の3文字のキャラクター名でも一致するような正規表現を順を追って考えてみましょう。
1. まずは対象となる「マキマ」に注目
2. 「マキマ」が任意の3文字なので、任意の1文字を意味するメタ文字「.」が3回続く
3. マキマの前後にあるリテラル(文字列)は「僕はチェンソーマンの」と「ちゃんが大好物です。」で共通
上記の流れで正規表現にすると 僕はチェンソーマンの...ちゃんが大好物です。 になります。
3-3-2. 簡潔にすることを考える
量指定子を用いて「...」を簡潔にしてみましょう。
「.」が任意の1文字を意味するので、この任意の3文字を簡潔に表すためには「.{3}(任意の文字列が3回ある)」であれば良いと考えます。
すると正規表現は 僕はチェンソーマンの.{3}ちゃんが大好物です。 になります。
初めは手間がかかりますが、このように正規表現を考えると後々パターンの見つけ方に慣れてきます。
パターンの見つけ方のコツがわかったので、次は具体例で考えてみましょう。
3-4. 具体例
3-4-1. メールアドレス
world_is_4649@hoge.ccc
上記のような迷惑メールアドレスからメールが届いたとします。
上記以外にも他の迷惑メールが来ていましたが、
○○○○○_is_△△△△@hoge.ccc
のような共通パターンであることがわかりました。(○は任意の小文字英語で数は1つ以上で不定、△は数字で数は4文字)
1. 一致しそうなパターンを忠実に当てはめる
2. 簡潔にすることを考える
上記のことを意識しながらメタ文字とリテラルを用いて、下記のとおりに正規表現で表してみましょう。
- ○の箇所は小文字英語が1文字以上あり、数は決まっていないので[a-z]と+で表せる
- その直後には必ず「_is_」が来ている
- △の箇所は4桁の数字が来ているので[0-9][0-9][0-9][0-9]で表せる
- [0-9]が4回繰り返されているので、{4}で簡潔にできる
- 「@」以降は「hoge.ccc」で固定
上記の考え方で順番に正規表現に変換してみます。
- [a-z]+_is_△△△△@hoge.ccc
- 上記のまま
- [a-z]+_is_[0-9][0-9][0-9][0-9]@hoge.ccc
- [a-z]+_is_[0-9]{4}@hoge.ccc
- 上記のまま(完成)
上記の正規表現で無事に迷惑メールアドレスのパターンと一致するのか正規表現チェッカーで確認して見ましょう。

無事に正規表現とworld_is_4649@hoge.cccが一致していますね。
他の迷惑メールアドレスがmakimalover_is_3150@hoge.cccの時、このアドレスが先程の正規表現に一致するか見てみましょう。
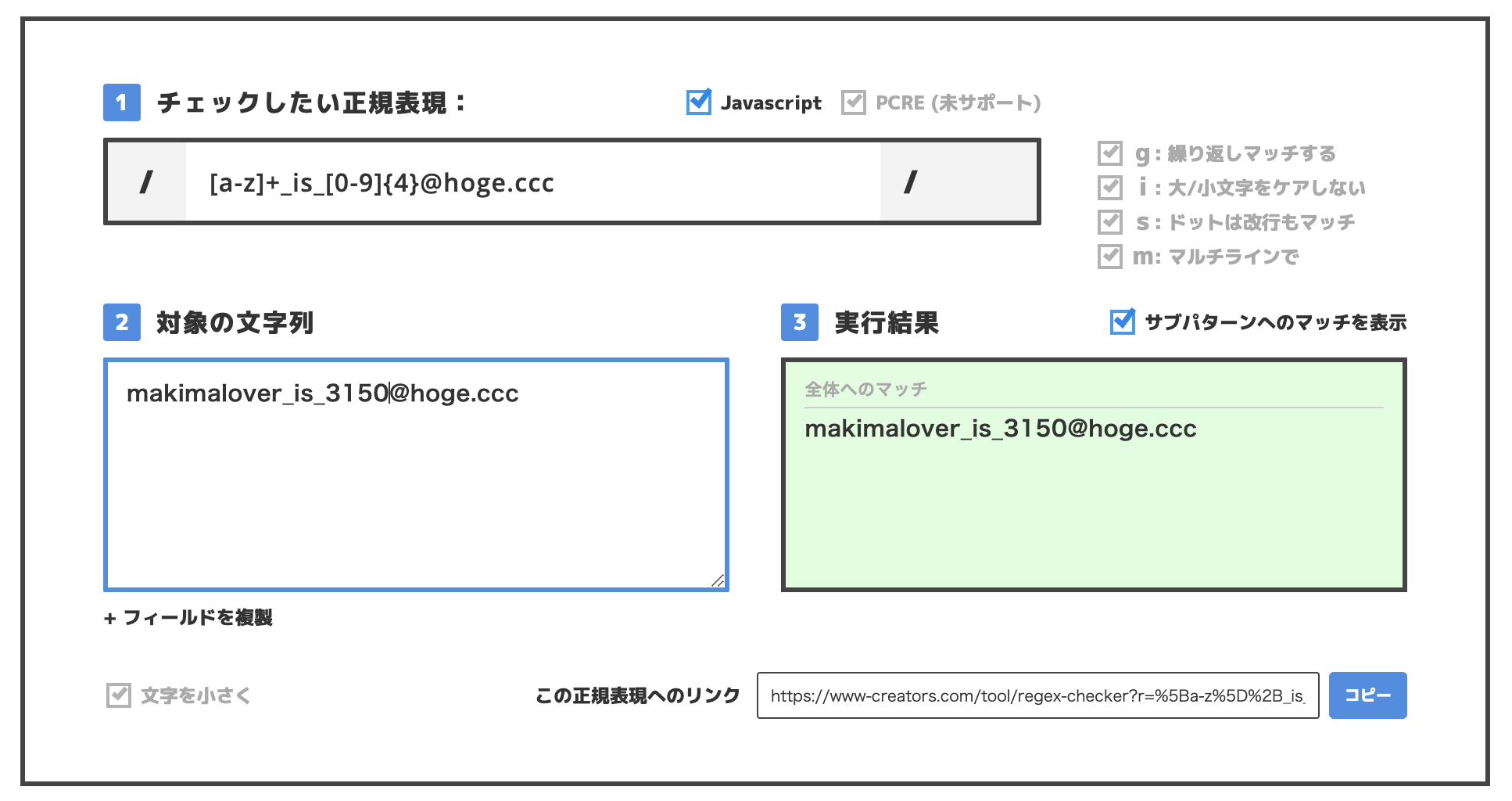
このアドレスも先程の正規表現に一致していますね。
3-4-2. 電話番号
03-103100-117117
ある地域では電話番号の表記が上記のように◯○-◯◯◯◯◯◯-◯◯◯◯◯◯の数値2桁-6桁-6桁であるそうです。
これを先程と同様に細かく考えて、この電話番号を正規表現で表して見ましょう。
- 数値2桁、6桁、6桁が「-」で繋がれているので[0-9][0-9]-[0-9][0-9][0-9][0-9][0-9][0-9]-[0-9][0-9][0-9][0-9][0-9][0-9]で表すことができる
- 桁数を{2}, {6}, {6}で表すことができる
上記の考え方で順番に正規表現に変換してみます。
- [0-9][0-9]-[0-9][0-9][0-9][0-9][0-9][0-9]-[0-9][0-9][0-9][0-9][0-9][0-9]
- [0-9]{2}-[0-9]{6}-[0-9]{6}(完成)
上記の正規表現で一致するか確認して見ましょう。
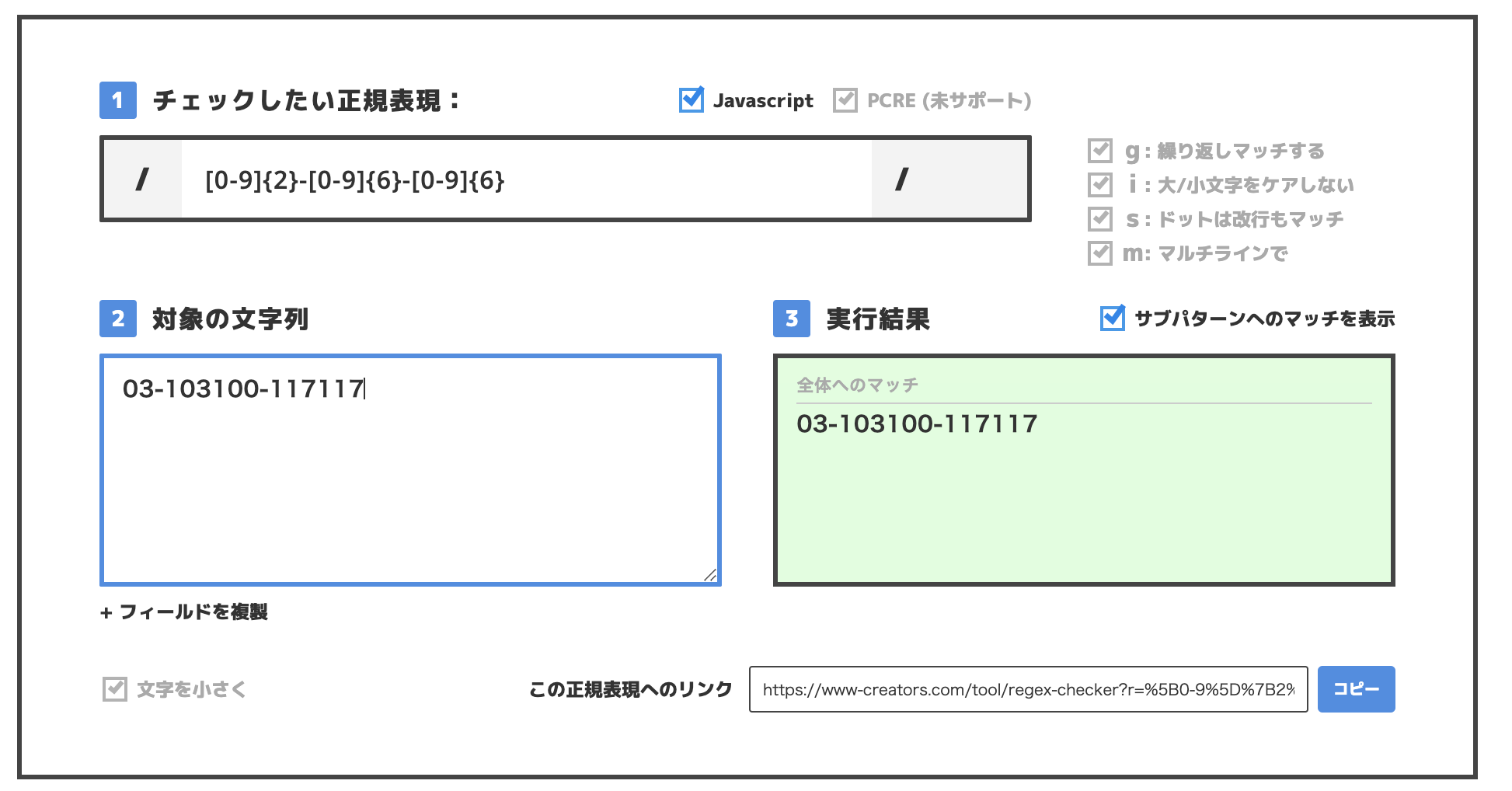
無事に一致しています。
3-4-3. 迷惑メールの文章
下のような迷惑メールが届くようになったとします。
迷惑メールの内容をよく見るとアンダーラインが引かれている名前、年齢、好きな食べ物、趣味の箇所のみが変わっているようでした。

これまでの例同様に考えて、この迷惑メールの文章を正規表現を使って表してみましょう。
- 全ての文章は任意の文字列である
- 相手の名前は任意の文字列で文字数は1文字以上、直後は必ず「さん」のリテラル(文字列)が入っている
- 年齢は2桁の数字で、直後に必ず「歳で、」のリテラル(文字列)が入っている
- 好きな食べ物は任意の文字列で文字数は1文字以上、「好きな食べ物は」と「です。」のリテラル(文字列)の間に入っている
- 2回目の名前があるが、これも任意の文字列で文字数は1文字以上、直前は「です。」のリテラルがあり、直後は必ず「さん」のリテラル(文字列)が入っている
- 趣味は任意の文字列で文字数は1文字以上、「趣味は」と「なので」のリテラル(文字列)の間、「一緒に」と「をしましょう。」のリテラル(文字列)の間にそれぞれ入っている
上記の考え方で順番に正規表現に変換してみます。
- .*
- .+さん.*
- .+さん.*[0-9]{2}歳で、.*
- .+さん.*[0-9]{2}歳で、.*好きな食べ物は.+です。.*
- .+さん.*[0-9]{2}歳で、.*好きな食べ物は.+です。.+さん.*
- .+さん.*[0-9]{2}歳で、.*好きな食べ物は.+です。.+さん.*趣味は.+なので.*一緒に.+をしましょう。(完成)
この正規表現が迷惑メールの文章と一致するのか確認して見ましょう。

無事に一致していますね!
この章のまとめ
・正規表現を利用したサービスやツールの機能と正規表現を区別する
・最大量指定子とは最大数の文字列を指す量指定子である
・最小量指定子とは最小数の文字列を指す量指定子である
・最小量指定子を利用する場合は量指定子(+や*)の直後に「?」を加える。
正規表現のパターンを見つけるコツは下記の順番で考える
1.一致しそうなパターンを忠実に当てはめる
2.簡潔にすることを考える
4. 実務における正規表現
3つの具体例を見て見ましたが、今回は比較的簡単なパターンでした。
実際には対象となる文字列はもっと複雑である場合が多く、それらを網羅するとなると正規表現も複雑になっていきます。
メールアドレスの例を挙げてみます。
メールアドレスの公式な仕様に則ったパターンを99.99%正確に検索できる正規表現があり、下記のページで紹介されています。
Email Address Regular Expression That 99.99% Woks
その正規表現は下記のとおりとなっております。
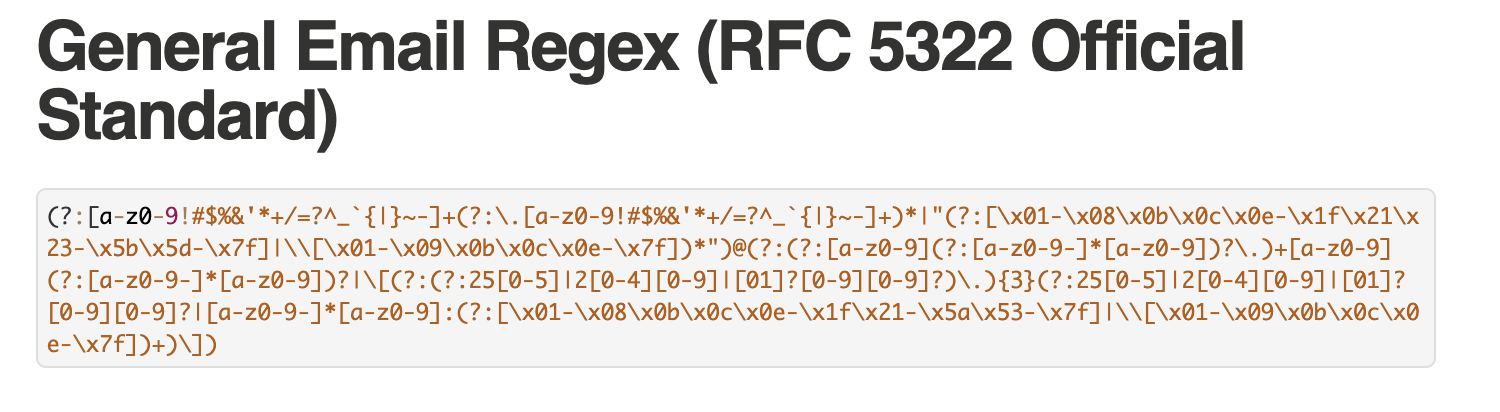
実務において、メールアドレスのほぼ全パターンに一致するような検索を行うことはまずないと思います。
実際にはどこまでの対象が正規表現で拾えれば良いか(どの程度イレギュラーな対象を含んで良いか)を考えることになります。
電話番号の例も見てみましょう。
先程は下の図の正規表現で対象の電話番号が一致しました。
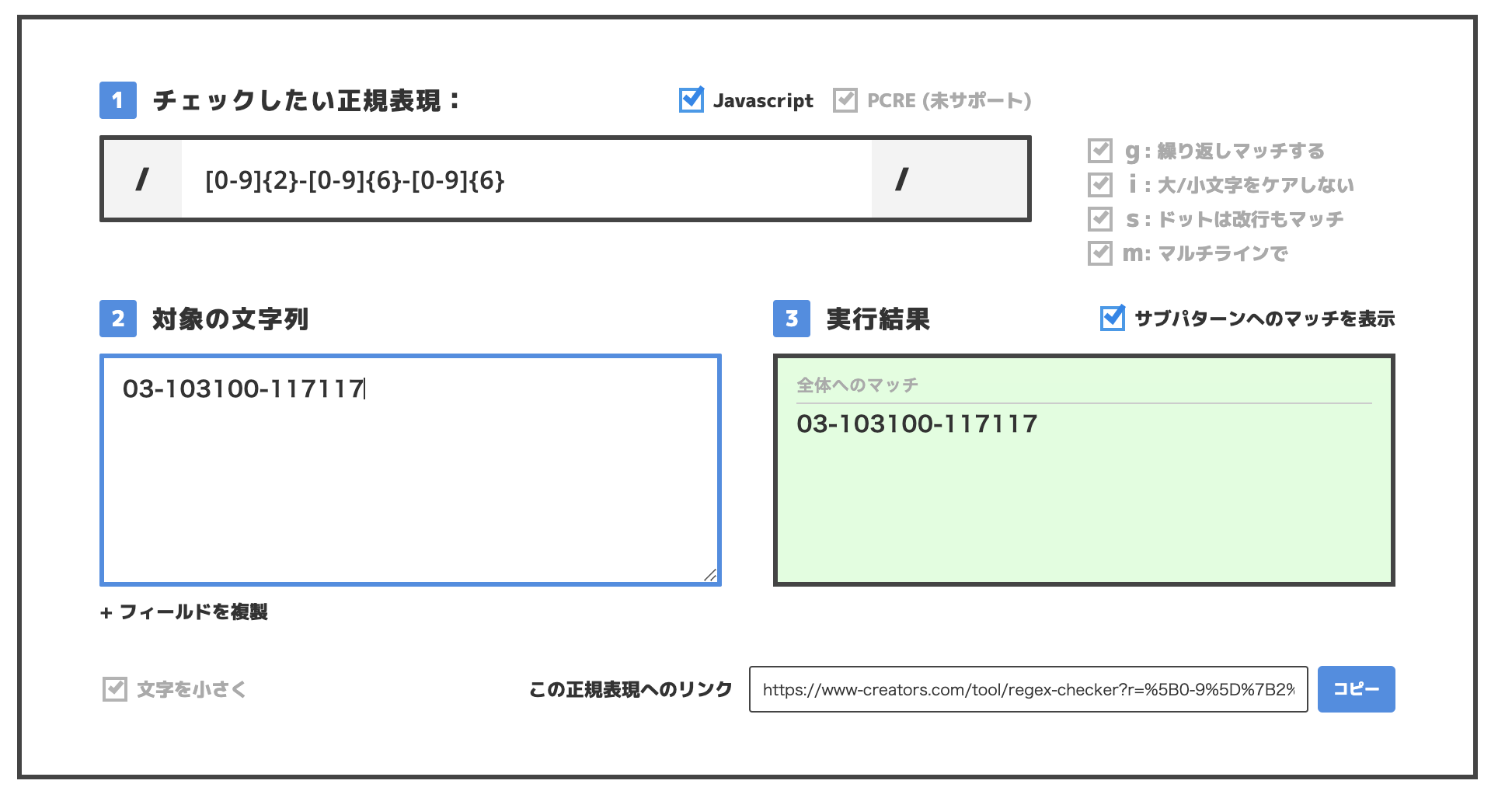
この表記の後ろに
-◯○-◯○◯○◯○ (-数値2桁-数値6桁)
が付与された場合はどうでしょうか。
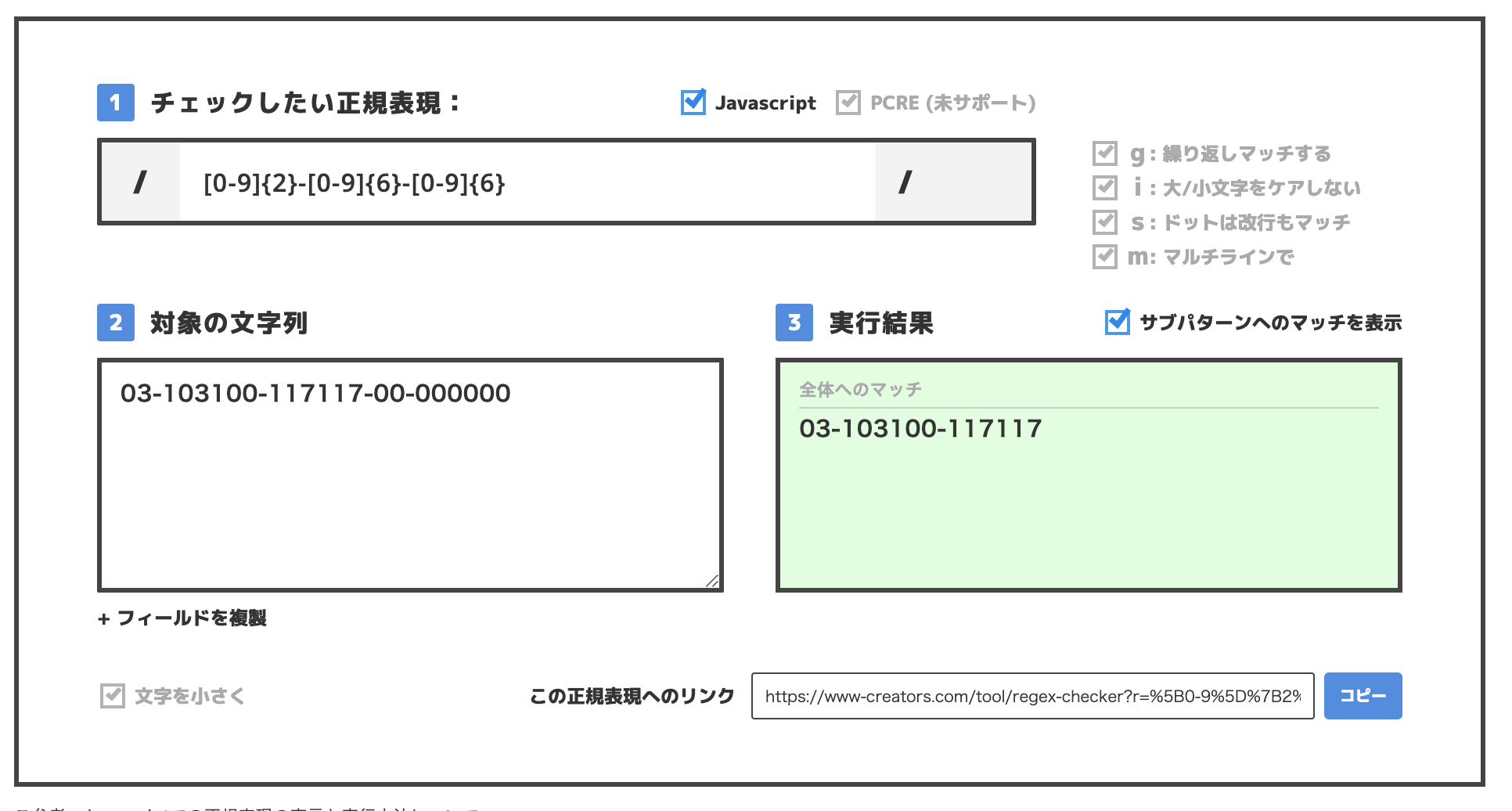
正規表現は変えていませんがこの場合も一致しています。
このような想定していないパターンのケースを許容するかどうかを実務において判断することになります。
仮に ◯○-◯◯◯◯◯◯-◯◯◯◯◯◯ の数値2桁-6桁-6桁の電話番号だけを一致させたいのであれば、正規表現は以下のようになります。

基本的なメタ文字でも紹介した「$」を末尾に付け加えていますね。
このように、正確に文字列を検索したいなどの場合は正規表現も伴い複雑になっていきます。
自分たちが正規表現で何をしたいのか、どこまで一致するパターンを許容するかを考えることが実務では求められます。
この章のまとめ
正規表現に含まれる文字列を正確絞りたいしたいほど、正規表現は複雑になりうる
正規表現を扱うときに、どこまでのイレギュラーを許容するかを考える
5. サンプル集
ここまではごく簡単なメタ文字を利用した正規表現についてお伝えしましたが、まだ多くのメタ文字が存在しています。
他のメタ文字について整理されているサンプル集を下記にまとめてみましたので、ぜひ色々なメタ文字とその働きを確認してみてください。
基本的な正規表現一覧
正規表現サンプル集
正規表現の意味・サンプル一覧
正規表現とは?メタ文字とサンプル一覧
正規表現:メタ文字(特殊文字)の一覧
6. 参考記事
この記事は正規表現の入門レベルの内容を書いておりますが、他にも正規表現に関する有益な記事はたくさんあります。
多くの記事を読んで、知識を身につけていきましょう!
ということで筆者も読んでいてわかりやすいと思った記事をいくつか紹介させていただきます。
初心者歓迎!手と目で覚える正規表現入門・その1「さまざまな形式の電話番号を検索しよう」
ワイの正規表現入門
サルにもわかる正規表現入門
正規表現とは
「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典
7. 正規表現練習サイト
知識はインプットとアウトプットを行って初めて身につきます。
ここまでで、先程紹介した正規表現サンプル集や参考記事を含め十分な知識をインプットはできたはずです。
何よりも正規表現の考え方を身につけられたことと思われます。
さぁ、次はアウトプット(練習)あるのみ!!
ということで、正規表現を練習できるサイトを2つほど紹介させていただきます。
Regex Hunting(開発者のQiita記事はこちら)
正規表現 オンライン教材
終わりに
この記事では具体例を用いて正規表現の考え方をお伝えしました。
この記事で皆さんの正規表現に対する理解が少しでも深まり、また闇雲に調べることによる時間の浪費が軽減されれば幸いです。
弊社では経験の有無を問わず、社員やインターン生の採用を行っています。
興味のある方はこちらをご覧ください。