はじめに
MLプロジェクトのPoCフェーズにて、MLOpsエンジニアとして取り組んだことをまとめてみました。
「MLモデリング以外のことを全部やる」、位のくくりで取り組んだので、厳密には「それMLOpsか...?」ということもまぁまぁある気がしますが、ご容赦下さい。
前提となるMLOpsの概要についてはこちらに記載しています。
意識していたこと
以下、MLプロジェクトのPoCフェーズにおける大小様々な課題とそれを解決するためにやったことを書いていますが、
・PoCフェーズでの成果が後続フェーズできちんと利用できるにすること、が最低限達成すべきことであり、一方で
・データサイエンティストのコストは極力最小化する(トレードオフな部分はある)、ということは意識していました。
前提
- フェーズ
- MLプロジェクトがPoCフェーズ→構築フェーズ→運用フェーズから構成されるとした場合の、PoCフェーズについて記載しています。
- 案件の種類
- 受託案件での取り組みについて記載しています。受託案件と自社開発案件との差分は大きくはないと思っていますが、強いて言うなら「顧客ごとの要件に合わせて環境や仕組みを個別にクイックに作ることになりがち」「PoCフェーズは自社環境で実施するが、構築フェーズ以降は顧客環境で実施する場合がある」あたりが違いかなと思っています。(ケースバイケースですが)
- ロールの定義(便宜上)
- データサイエンティスト: MLモデリングを担当する人
- MLOpsエンジニア: MLモデリング以外のエンジニアリングを担当する人(以下のタスクを実施する人)
取り組んだこと
0. 導入提案
概要
- MLOps導入の提案
目的
- プロジェクトリーダー・データサイエンティストに対して、プロジェクト開始前or直後に、MLOps導入の目的(必要性)やスコープを明確に伝えておくことで、スムーズに連携することが目的でした。
- データサイエンティストvsソフトウェアエンジニアの対立、とかはあるあるとしてよく聞くので、事前に必要性とスコープを明確に伝えておきました。
内容
※ 事前に認識合わせをした内容
-
機械学習プロジェクトで発生し得る課題とMLOpsの概要
- 【MLOps入門】MLOps概要参照
- → 特にPoCフェーズで意識すべき課題
- 「MLプロジェクトを円滑に進めることを阻害する課題がある。特に、PoCフェーズを経て、構築運用フェーズ(プロダクション化)に進むに連れ、問題が顕在化しがちである。」
- 「PoCにて、報告資料に乗せる良い数字がローカル環境で取れた」 ≠ 「MLモデルがプロダクション環境にデプロイされ、サービス(価値)を安定的に提供していく」
- 「厄介なのは、前フェーズ(PoC担当者など)で対策をしなかった結果、困るのは後フェーズ(構築運用担当者)、となる課題も多いこと。」
-
スケジュール概要
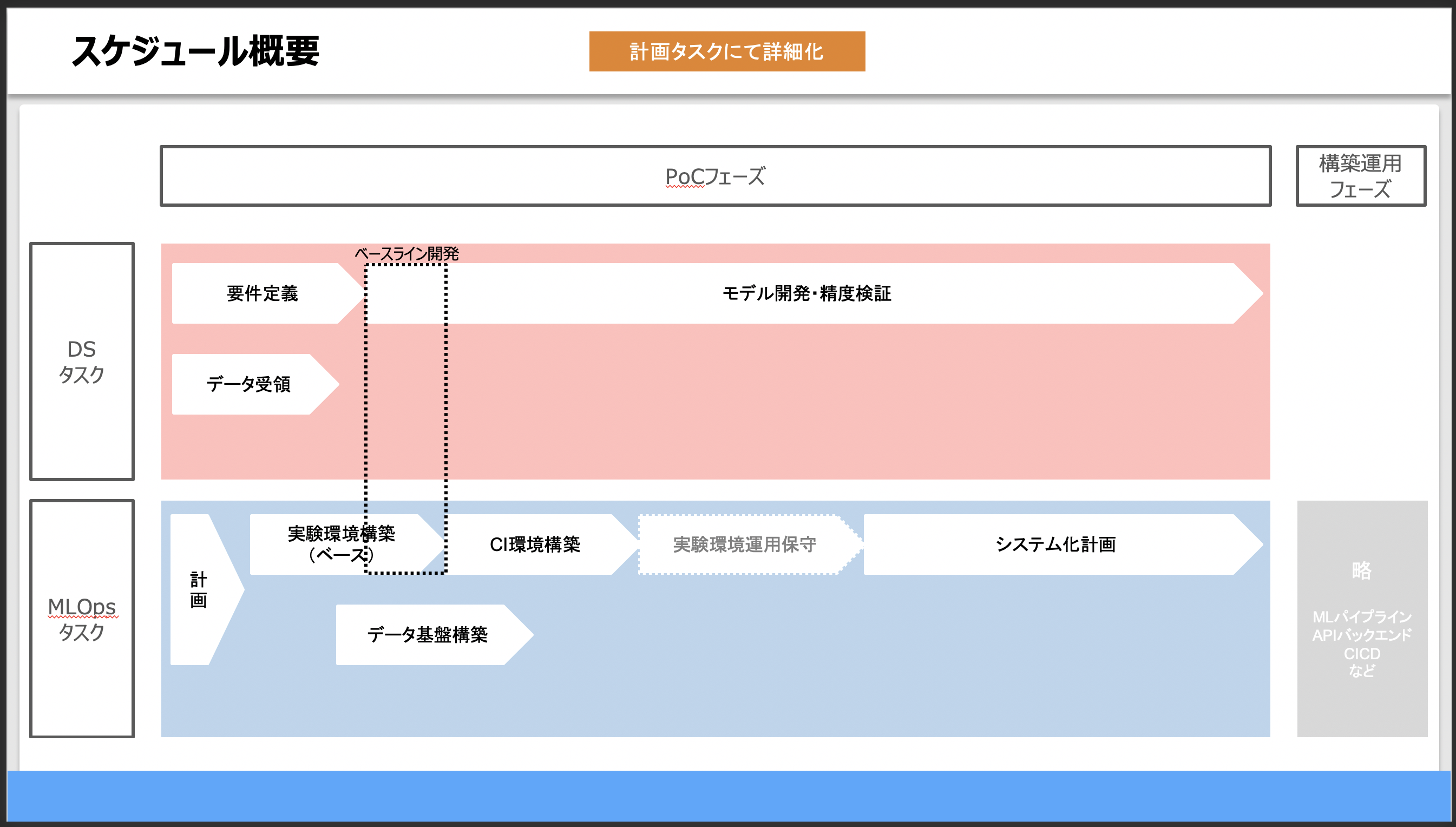
ポイント
- できるだけ具体的なケースを踏まえつつ、導入の必要性を正しく伝えるようにしました。
- また、実施内容(→改善内容)の認識にズレが起きないようにしました。
- 合わせて、MLOpsエンジニア側と、特にデータサイエンティスト側の追加工数について、工数感をざっくり伝えておきました。
1. 計画
概要
- ヒアリング実施
- WBS作成
目的
- 案件の進め方を認識合わせし、実施する作業内容を詳細化し、WBSを作成して合意を取りました。
内容
-
ヒアリング事項
(補足)PoCからシステム化フェーズに進むためのヒアリング
- 案件基本情報(PoCフェーズ時点)
- 背景・課題(プロジェクト発足の経緯)
- 目的とゴール(「【目的】のために【解き方】する」)
- 現在の作業フロー(セットアップ、データ取得〜推論結果取得まで)
- 作業フロー(手動部分、プログラム部分)
- 実行頻度
- 処理時間
- データ(In/Out)
- 種別(CSV, etc)
- 格納先
- データ量
- 実行環境
- プログラム実行環境(ローカル, 開発サーバ, etc)
- 言語・ライブラリ(Python?ノートブック?Pythonパッケージのみで環境再現できる?)
- 外部サービスの利用(ChatGPT, etc)
- システム化に向けた認識合わせ
- 懸念事項・課題感洗い出し
- リファクタリング
- スクリプト化(ノートブックのPythonファイル化)
- モジュール化
- ハードコーディングの削除、秘匿情報対応
- エラーハンドリング
- ログ出力
- 可用性
- 障害発生時の影響
- サポート体制(24/365?平日日中?)
- アラート通知
- 性能
- データ量、アクセス量
- バッチウィンドウ、レスポンスタイム
- セキュリティ対応(権限、個人情報、etc)
- 倫理上の問題(バイアス、平等性、etc)
- リファクタリング
- スケジュール・マイルストーン(今後のPoC・リリース計画、運用引き継ぎ)
- 体制と役割分担(レポートライン・PoC詳細ヒアリング先、運用フェーズも考慮する)
- 予算(金額概算、予算取得タイミング)
- 懸念事項・課題感洗い出し
- 1_PJ基本情報の確認
-
-
背景・課題
- プロジェクト発足の経緯
-
背景・課題
-
-
目的とゴール
- 「〇〇のために、××する」(目的と解き方のセット)
- 一般的なPoCフェーズの目的: フィジビリティのチェック、デプロイする価値があるかの確認
- PoCかMVPか
- ビジネス視点でのKPIと技術的視点でのKPI
- フェルミ推定で、技術的KPI(精度など)とビジネス的KPIを紐付ける
- 精度目標
- MVA(Minimum Viable Accuracy)、AVC(Accuracy Value Cureve)
- 人の精度
-
目的とゴール
-
- 作業内容と役割分担
-
-
成果物
- コード、モデルを顧客に提出するか、など
- 各成果物のアウトプットイメージ
-
成果物
-
-
スケジュールとマイルストーン
- 要件定義、モデル開発・精度検証・最終報告、システム化計画・構築フェーズ提案 → 要件定義、設計、構築、テスト、リリース、etc
-
スケジュールとマイルストーン
-
-
体制
- チーム体制、ステークホルダー
-
体制
-
-
予算
- 後続フェーズまで含めた予算額と取得タイミング
-
予算
-
- 2_MLOps導入に向けた確認
- 前提確認(現時点/これから)
-
-
プロジェクト(モデル)の種類
- 需要予測 / 類似画像検索, etc
- ブレストで洗い出し、まずはベースライン(シンプルで解釈容易なもの)から実装する
-
プロジェクト(モデル)の種類
-
-
データの種類
- データソースごとに整理する
- テーブルデータ / 画像 / テキスト, etc
- 取得元(BQ、S3、etc)
- カラム
- 個人情報有無
- ライセンス
- データサイズ
- データ受領方法
- 取得するまでにかかる時間
- 本番データとの違い
- 分布、取得条件、更新頻度、etc
- ラベリング有無
-
データの種類
-
- 利用者数(DS, SWE, SRE)
-
-
環境(オンプレ/クラウド)は何か
- オンプレのみ / AWS / GCP / Azure, etc
- GPU利用予定有無
- インフラ費用見積もり
-
環境(オンプレ/クラウド)は何か
-
-
プログラミング言語
- Python / 推論部分はGo, etc
-
プログラミング言語
-
-
フレームワーク
- Tensorflow / PyTorch, etc
-
フレームワーク
-
-
その他、ツール
- ソースリポジトリ
- 外部サービス
- バージョン(GAかβかαか)
- 制約(リミット、対応リージョンなど)
-
その他、ツール
-
-
懸念事項
- ブレストで洗い出す
- 倫理上の問題(Bias、平等性、etc)
-
懸念事項
-
- スコープ確認(現時点/これから)
- レベル0: 手動プロセス
-
-
データ基盤(収集, 蓄積, 加工)
- 前処理
- Scaling, Normalization, Standarization, Bucketing / Binning, 次元削減,,,
- Development Data(Training, Validation), Test Data
- 前処理
-
データ基盤(収集, 蓄積, 加工)
-
-
ラベリング
- 質、一貫性の担保をどうするか
-
ラベリング
-
-
データ分析環境
- 評価指標
- 定量評価と定性評価
- オンライン検証とオフライン検証
- 撤退ライン
- 許容されるエラー(優先度)
- カテゴリごとにも上記を検討(優先度)
- 評価指標
-
データ分析環境
-
- 実験管理
-
- 学習基盤
-
- モデルレジストリ
-
-
サービング
- プロダクション化する際の要件
- 「システム化計画タスクの内容」参照
- プロダクション化する際の要件
-
サービング
-
- レベル1: ML パイプラインの自動化
-
- MLパイプライン
-
- メタデータ管理
-
- CD(MLパイプライン, サービング)
-
- 特徴量ストア
-
- レベル2: CI / CD パイプラインの自動化
-
- CI
-
- モニタリング(精度含む)
-
- レベル0: 手動プロセス
- 前提確認(現時点/これから)
- 案件基本情報(PoCフェーズ時点)
ポイント
- WBS作成では、作業内容・優先度を明細レベルで確定させ、作業ごとの完成イメージを共有し、完了条件を合意しました。
- 予定外タスクを拾いにいくことも多いので、タスクの組み替えを相談しやすいように、優先度を明確にしておきました。
- 計画から漏れがちなタスク
- 整備したルール・ツール定着のためのタスク
- メンバ追加・実験数増加(並列化)に伴うリソース拡張
2. 実験環境構築
概要
- 実験規約作成(サンプルコード開発含む)
- 学習環境構築(サンプルコード開発、利用ルール整備含む)
- 実験管理環境構築(サンプルコード開発、利用ルール整備含む)
- ベースライン開発フォロー
目的
- データサイエンティストが実験に着手できるよう、ルールを整備・共有した上で、環境を構築・提供します。
- 各種自動化については、「4. CI環境構築」で対応しました。
- 下記のようなことが起こらないようにしました。(想定される課題)
- ディレクトリ構成が直感的でない/PJ間で異なり、新規参画・引き継ぎのキャッチアップコストがかかった
- 急遽実験回数を増やす/メンバーをアサインすることになったが、学習リソースが足りない(、既存メンバと同じ環境が作れない)
- 後になって実験の詳細を聞かれたが、条件を辿ることができない。ノートブックを漁って探すしかない。(検索性が低い)
- スクリプト/ノートブックが量産されるが、実行方法が不明
- 実験の経緯や考察が残されておらず、後から説明ができない
- 実験結果の検索が比較検討がし辛い。他メンバーと実験結果や利用したリソースを共有し、コラボレーションすることが難しい。
内容
-
実験規約(wiki)の目次例
- 0_プロジェクト概要
- 計画タスクの内容を転記しておく(新規参画者のためにも)
- 1_受領データの取り扱い
- 中間成果物含め、どのデータをどこに置いてどう権限管理するか
- 案件終了後の削除のためにも、置き場所を管理しておく
- 2_ドキュメント管理方針
- 3_チケット運用ルール
- タスク指示者がIssueを起票する
- 完了条件を明記する
- Issueごとにブランチを作成する
- 中間報告などの顧客報告断面でIssueにマイルストーン、ブランチにタグを打つ
- タスク指示者がIssueを起票する
- 4_ブランチ運用ルール
- 5_ディレクトリ構成
- Coockie Cutter など
- 6_コーディング規約
- コミットルール、READMEアジェンダ(実行手順を書くようにする)、Python開発環境、実験管理ルールなど
- 7_会議運営、コミュニケーション
- 定例で、Issueとコードベースで各担当者から進捗報告する
- 0_プロジェクト概要
-
学習環境構築
- 環境を揃えるため、Dockerで構築しました。
- READMEに、環境構築手順だけでなく、実験の再現に必要な手順をきちんと載せるようにしました。
- メンバ追加・実験数増加(並列化)に伴うリソース拡張に備えておくようにしました。
- スタート時点のディレクトリ構成・Dockerファイルは、下記を参考にすることが多いです。
-
実験管理シート作成
- 最初はスプレッドシートなどで管理して、固まってきたらMLflowなどに移行するようにしました。
- 詳細はこちら
- 管理項目
- 1_データセット(raw)管理
- データセット正式名称,①データセット名(raw),ライセンス,ライセンス証跡URL,データ数,取得日,取得方法,保存先,担当者,備考
- 2_データセット(加工後)管理
- ②データセット名(前処理後),保存先,データ数,①データセット名(raw),前処理スクリプト,担当者,備考
- 3_実験結果管理
- モデル名,モデル保存先,②Inputデータ,学習スクリプト,変更点サマリ,評価スクリプト,評価サマリ,顧客報告,関連IssueNo,担当者,備考
- 1_データセット(raw)管理
-
ベースライン開発フォロー
- パイプラインのガワを予め作成してからデータサイエンティストに渡しました。
- Input→スクリプト→Output→...
- 命名規則、ディレクトリ構成を伝える意味もありました。
- パイプラインのガワを予め作成してからデータサイエンティストに渡しました。
ポイント
- 後から修正するのが大変なやつは、ここで最初決めておくようにしました。一方で、データサイエンティストの手が止まらないように注意しました。
- 上記に記載したことが定着するまでしっかりフォローしました。
- PoCとはいえ、Issue/ブランチは0レビューだと際限なく品質が低下し、まずいことになることがあるので、どこかでチェックポイントを設ける仕組みを作りを意識しました。
3. データ基盤構築
概要
- データ基盤構築、利用ルール整備
- ※データ基盤構築と書いていますが、ここでは広く、PoCで使うデータの置き場の整備、という意味で書いています。
目的
- 普通のシステム開発との違いとして、コードだけでなくデータもバージョン管理する必要があります。
- 学習データが違えば、出来上がるモデルが変わってくるので、再現のためにはデータの管理も必須です。
- 下記のようなことが起こらないようにしました。(想定される課題)
- このモデルはどのデータで作ったかが分からないので(ローカルにしかなかったデータで今は消えてしまったので)、もう再現ができない
内容
- 今回は画像系の案件だったのですが、とにかくS3にあげるようにしました。
- 画像データは、追加で受領したり収集したりする度に、(一応ディレクトリを分けて)S3にどんどん追加しつつ、学習やテストに利用したデータが記載されているCSVは、ファイルを分けてバージョン管理するようにしていました。
- AWSを使う場合は、下記を参考にストレージ系のサービスを使い分けています。(EBS, EFS, S3)
ポイント
- 一連の処理の中で出てくるInput/Outputを(中間生成物含めて)どこにどう管理するか考えました。(権限回り含めて)
- データの実体とメタデータ
- データレイク、特徴量ストア、モデルレジストリ、など
- データ種、データ量、アクセス元、アクセス頻度、許容処理時間、インフラ費用、拡張性、可用性、などなどから考えました。
4. CI環境構築
概要
- CI+実験管理パイプラインの構築(Automated pipeline)
目的
- データサイエンティストのpushのタイミングで、CI+実験管理パイプラインが自動で動くようにしました。
- 下記のようなことが起こらないようにしました。(想定される課題)
- 後続フェーズになってから、PoC時の特定のモデルが再現できない
- Masterブランチのスクリプトが動かない
- 最終的に使ってなさそうなスクリプトも大量にあり、どのスクリプトをどの順序で実行すれば良いか分からない
- モデルを再現するためにはソースだけでなくデータも必要だが、どこのどの断面のデータを使ったかが分からない
- 後続フェーズになってから、PoC時の特定のモデルが再現できない
内容
- CI部分は過去にここにまとめています。追加で、MLflowとも連携させるようにしました。
- (参考)構成例
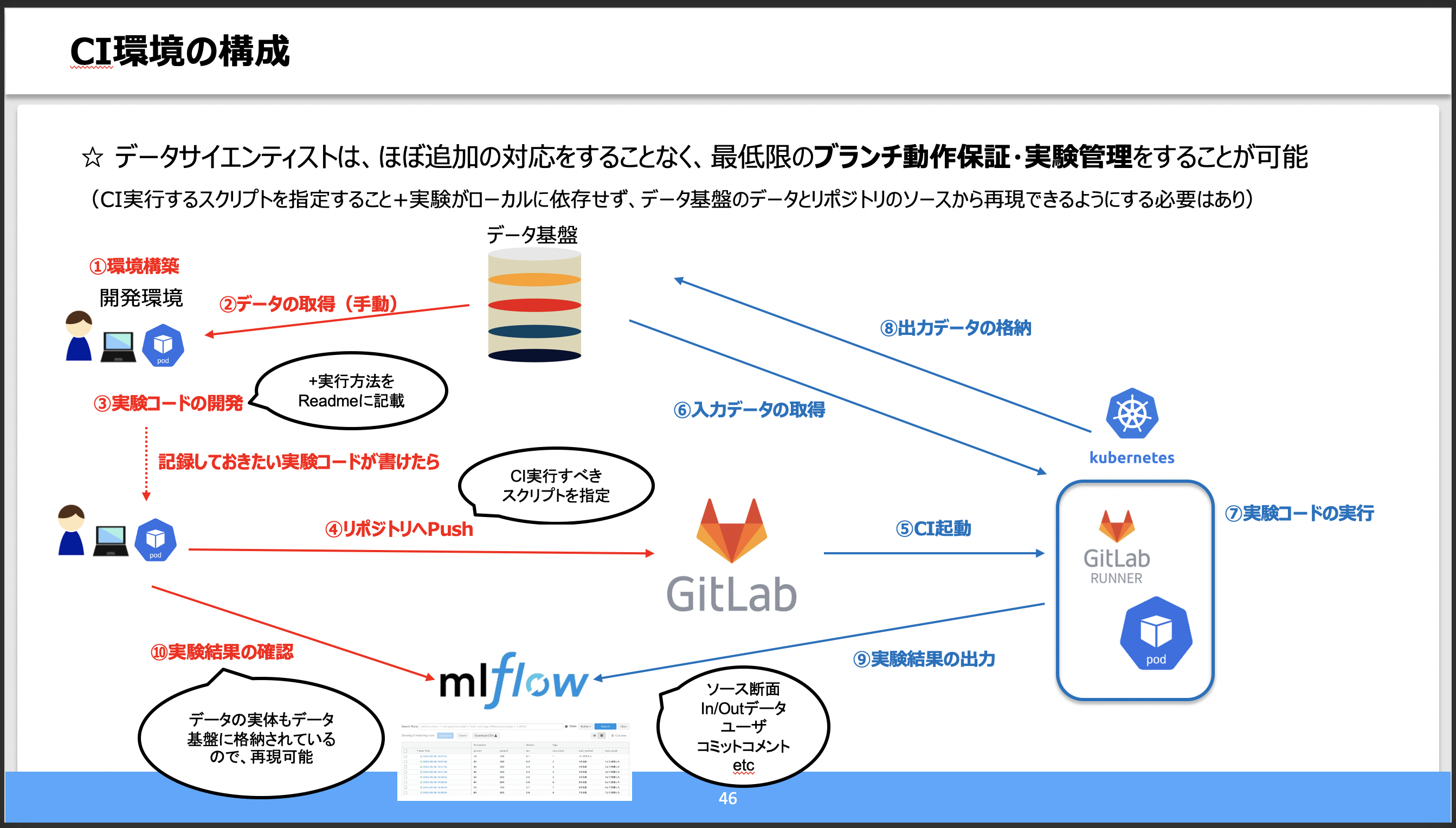
ポイント
- 通常の開発におけるCIと比べて、前処理や学習で処理時間が長くなりがちです。
- データのキャッシュ、途中実行
- データサイエンティスト側のタスクを減らす工夫
- pushすればいいだけで、裏側の仕組みは意識しなくて良い、を目指しました。
- どうしても修正してもらいたい箇所も、寄せて分かりやすくしました。
5. システム化計画
概要
- プロダクション化する際の要件確認
- 簡易性能テスト(処理時間、インフラコスト見積もりのため)
目的
- 構築フェーズが始まる前に、フィジビリティを確認しました。
- 下記のようなことが起こらないようにしました。(想定される課題)
- いざ構築フェーズに入ってから、ランニングコストが想定より高いことが発覚した。逆にマシンスペックを下げれば、サービスの許容処理時間を上回ってしまう
- クラウドサービスのAPIを内部で一部利用しているが、スループット上限があり、性能要件を満たさなかった
内容
- 一般的なシステム開発で気をつけること(下記など)に加えて、下記などを確認しました。
- チェックリスト
- 要件概要
- User, User Need, User Actions, ML System Iutput, ML System Learning
- データソース
- 処理フロー、DFD
-
処理ごとに想定データ量と処理時間、処理頻度を整理
- レイテンシ、バッチウィンドウ
-
処理ごとに想定データ量と処理時間、処理頻度を整理
- アーキテクチャ構成
- オンプレ/クラウド(AWS、GCP、etc)
- 本番で利用しているクラウドサービス確認
- 連携先システム、インターフェイス、調整先。分析用用途でTableauがつつきにくるとか
- 検証のためにstubバケットは不要か
- 再学習は自動か手動か
- オンライン/バッチ(全量・差分) × 学習/推論
- バッチ学習+オンライン推論
- Webアプリケーションで直接算出
- API
- バッチ学習+バッチ推論
- DB参照
- オンライン学習+オンライン推論
- バッチ学習+オンライン推論
- メタデータ管理(データ、モデル)
- オンプレ/クラウド(AWS、GCP、etc)
- 機能一覧
- コスト見積もり
- 性能(レイテンシ、バッチウィンドウ)とのトレードオフも考えて整理する
- 初期/ランニング × インフラ/開発工数
- 再学習の頻度
- 費用対効果の算出
- 非機能要件・基本設計
- 可用性
- 性能・拡張性
- 検討項目
- レイテンシ、バッチウィンドウ、インフラコスト
- 改善案
- GPUのシェア、マルチモデルサービング、モデルの最適化など
- NoSQLの利用(キャッシュ)
- 水平スケール
- 検討項目
- 運用・保守性
- → 運用作業一覧と役割分担
- 問い合わせ、障害対応
- 監視
- 対象
- 入力データ・推論結果
- データの長さ・大きさ、欠損値、輝度、レスポンスタイム、CTR
- 手法
- 検知
- 人を雇ってラベリングして予測結果と比較
- アラート
- 対応
- 予測誤りをどこで吸収するか
- human in the loop
- 予測誤りをどこで吸収するか
- 検知
- 対象
- 保守改修
- デプロイ
- ロールバック、シャドーモードデプロイ、カナリアデプロイ、BlueGreenデプロイ(A/B)、etc
- データ分析
- A/Bテスト
- 継続的なA/Bテスト
- 成果物
- スケジュールとマイルストーン
- 体制
- ベンダ(構築、運用・保守)と役割分担
- モジュール受け渡し方法
- 本番環境への接続方法、申請
- ベンダ(構築、運用・保守)と役割分担
- その他懸念事項
- ブレストする
- モデルの精度が下がる可能性のある要因を考える。データの傾向が変わるなど。
- 要件概要
- -> 実践例は【MLOps実践】GCPで始めるエンドツーエンドなMLOps基盤(Vertex AI,etc)、ドキュメント構成例は内製プラットフォームを開発するときに最初に準備したこと(ドキュメント・チケット管理etc)
ポイント
- フィジビリティはきっちり確認しつつ、後続の構築フェーズへスムーズに繋げられるように整理しました。
おわりに
- 感想
- 上記の通りルールやツールを整備することで、MLプロジェクトのPoCフェーズにおける品質をある程度向上・効率化させることができました。
- 改めて、特にメンバは、毎週の顧客定例への進捗出しで必死だったりするので、「後から」「他の人が」参照できる(再現できる)かとかを考える余裕がないのはある程度仕方がない面もあるのかなと感じました。
- → なので、それを前提として、基本的には仕組みで(自動化で)解決していく必要があると思いました。
- MLOpsエンジニアとしては、どこまで実験の中身に踏み込むかは毎回悩んでいます。
- 動かないノートブックがあったらこっちで直すか、とか。
- 一つの案件に工数を割きすぎるとスケールしないが、一方でルールやツールを整備しても定着までやらないと意味がない、などなど。悩ましいです。
- MLOpsシリーズ