はじめに
- GCPのVertexAI(Workbench,Pipelines)を使ってKaggleをやってみました
- PythonではじめるKaggleスタートブックを参考にしながら、Titanicコンペにsubmitすることを目指してみました
- GCSにデータを配置してWorkbenchで開発→Pipelinesで実行、をしてみました
- とりあえず動くコードは書けましたが、「課題・ToDo」の章に記載した内容は今後修正していきたいです
- コードはこちら
前提
- Kaggleのアカウントが開設されていること
- GCPアカウントが開設されていること
- GCPプロジェクトが作成されていること
ゴールイメージ
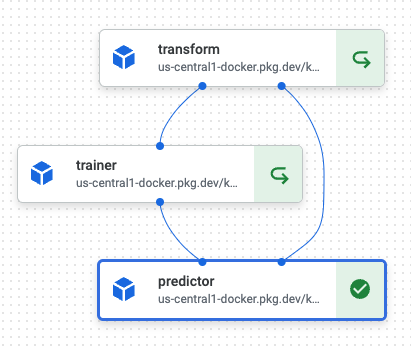
- transform
- KaggleからダウンロードしてGCSにアップロードしておいたinputデータを前処理
- trainer
- sklearnでロジスティック回帰モデルを作成
- predictor
- 推論実行+Kaggleにsubmit
手順
ノートブックを立ち上げる(Workbench)
- Vertex AI → Workbench
- Notebooks API 有効化
- New Notebook
- MANAGED NOTEBOOKS
- 事前にArtifact Registoryに配置したコンテナイメージも指定可能
- OPEN JUPYTERLAB
inputデータをバケットに配置する(GCS)
- バケットを作成する
- Cloud Storage
- リージョンを合わせること
- ディレクトリ構成は、kaggleノートブックに合わせて
input/titanicにする
- Kaggleからダウンロードする
$ pip install kaggle
$ vim .kaggle/kaggle.json
$ chmod 600 kaggle.json
$ kaggle competitions download -c titanic
$ unzip titanic.zip
->
# input/titanic/train.csv
# input/titanic/test.csv
# input/titanic/gender_submission.csv
- バケットへアップロードする
$ gsutil cp -r input gs://${BUCKET_NAME}/
開発・実行用コンテナを用意する(Artifact Registory)
- Artifact Registry API 有効化
- Repository作成
- Docker
- イメージアップロード
# ユーザアカウント認証
$ gcloud auth login
$ gcloud config set project ${PROJECT_NAME}
# 利用するゾーンに対する docker コンフィグ生成を実施する
$ gcloud auth configure-docker us-central1-docker.pkg.dev
# DockerHubからkaggleコンテナのプル→Artifact Registoryへのプッシュ
# ※コンポーネントごとにコンテナを分ける場合は、それぞれビルドしてプッシュしておく
$ docker pull kaggle/python
$ docker tag kaggle/python:latest us-central1-docker.pkg.dev/${PROJECT_NAME}/kaggle/python:latest
$ docker push us-central1-docker.pkg.dev/${PROJECT_NAME}/kaggle/python:latest
ノートブックで開発→パイプライン実行する(Workbench→Pipelines)
ローカルで動作確認後(@componentなどをコメントアウトして実行)、パイプライン実行する
1. 定数を定義する
- 中間データやモデルは、TIMESTAMPごとにGCSにディレクトリを作成してそこに格納することでバージョン管理するようにしました
- イメージも同様に、バージョン管理のためにタグを指定するようにしています(コミットハッシュ値)
- PIPELINE_ROOTに指定すると、
/gcs/<GCS_BUCKET_NAME>として各コンテナにマウントされます。パイプライン実行ごとのメタデータなども格納されます(BUCKET_NAME/XXXXXX/titanic-20220313120000/predictor_-XXXXXX/executor_output.jsonなど)
# Define constants
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
# -> '20220305052457'
PROJECT_ID = ""
REGION = "us-central1"
BUCKET_NAME = ""
PIPELINE_ROOT = "gs://{}".format(BUCKET_NAME)
API_ENDPOINT = "{}-aiplatform.googleapis.com".format(REGION)
# -> 'us-central1-aiplatform.googleapis.com'
DISPLAY_NAME = "titanic_" + TIMESTAMP
KAGGLE_COMMIT_MESSAGE = "update at " + TIMESTAMP
RAW_DATA_PATH = "/gcs/" + BUCKET_NAME + "/input/titanic"
TRANSFORMED_DATA_PATH = "/gcs/" + BUCKET_NAME + "/output/titanic/" + TIMESTAMP
TRAINED_MODEL_PATH = "/gcs/" + BUCKET_NAME + "/output/titanic/" + TIMESTAMP
PREDICTED_DATA_PATH = "/gcs/" + BUCKET_NAME + "/output/titanic/" + TIMESTAMP
PIPELINE_SPEC_NAME = "pipeline_titanic_" + TIMESTAMP + ".json"
BASE_IMAGE_TRANSFORM = REGION + "-docker.pkg.dev/" + PROJECT_ID + "/kaggle/transform:XXX"
BASE_IMAGE_TRAINER = REGION + "-docker.pkg.dev/" + PROJECT_ID + "/kaggle/trainer:XXX"
BASE_IMAGE_PREDICTOR = REGION + "-docker.pkg.dev/" + PROJECT_ID + "/kaggle/predictor:XXX"
NOTEBOOK_NAME = "pipeline_titanic.ipynb"
NOTEBOOK_NAME_SAVED = "pipeline_titanic_" + TIMESTAMP + ".ipynb"
2. コンポーネントとパイプラインを定義する
- 型ヒントをつける必要がある(コンパイルする時にエラーになる)
Must be one of str, int, float, a subclass of Artifact, or a NamedTuple collection of these types.
- 前のコンポーネントの出力を使うかどうかで、DAGの構成は決まる(
transform_task.outputなど)
# Define components and a pipeline
# Set up your Google Cloud project
!gcloud config set project $PROJECT_ID
import google.cloud.aiplatform as aip
from kfp import dsl
from kfp.v2 import compiler
from kfp.v2.dsl import (Artifact, Dataset, Input, InputPath, Model, Output,
OutputPath, ClassificationMetrics, Metrics, component)
from typing import NamedTuple
# Set up your Google Cloud project
aip.init(project=PROJECT_ID, staging_bucket=BUCKET_NAME)
@component(base_image=BASE_IMAGE_TRANSFORM)
def transform(raw_data_path: str, transformed_data_path: str) -> NamedTuple("outputs", [("transformed_data_path", str)]):
import os
from io import BytesIO
import numpy as np
import pandas as pd
# input
train = pd.read_csv(raw_data_path + '/train.csv')
test = pd.read_csv(raw_data_path + '/test.csv')
gender_submission = pd.read_csv(raw_data_path + '/gender_submission.csv')
# run
data = pd.concat([train, test], sort=False)
data['Sex'].replace(['male', 'female'], [0, 1], inplace=True)
data['Embarked'].fillna(('S'), inplace=True)
data['Embarked'] = data['Embarked'].map({'S': 0, 'C': 1, 'Q': 2}).astype(int)
data['Fare'].fillna(np.mean(data['Fare']), inplace=True)
age_avg = data['Age'].mean()
age_std = data['Age'].std()
data['Age'].fillna(np.random.randint(age_avg - age_std, age_avg + age_std), inplace=True)
delete_columns = ['Name', 'PassengerId', 'SibSp', 'Parch', 'Ticket', 'Cabin']
data.drop(delete_columns, axis=1, inplace=True)
train = data[:len(train)]
test = data[len(train):]
y_train = train['Survived']
X_train = train.drop('Survived', axis=1)
X_test = test.drop('Survived', axis=1)
# output
if not os.path.exists(transformed_data_path):
os.mkdir(transformed_data_path)
y_train.to_csv(transformed_data_path + "/y_train.csv")
X_train.to_csv(transformed_data_path + "/X_train.csv")
X_test.to_csv(transformed_data_path + "/X_test.csv")
return (transformed_data_path,)
# debug local
transform(RAW_DATA_PATH, TRANSFORMED_DATA_PATH)
@component(base_image=BASE_IMAGE_TRAINER)
def trainer(transformed_data_path: str, trained_model_path: str) -> NamedTuple("outputs", [("trained_model_path", str)]):
import argparse
import os
from io import BytesIO
import pickle
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
# input
y_train = pd.read_csv(transformed_data_path + "/y_train.csv", index_col=0)
X_train = pd.read_csv(transformed_data_path + "/X_train.csv", index_col=0)
# run
model = LogisticRegression(penalty='l2', solver='sag', random_state=0)
model.fit(X_train, y_train)
# output
if not os.path.exists(trained_model_path):
os.mkdir(trained_model_path)
pickle.dump(model, open(trained_model_path + '/model_titanic.sav', 'wb'))
return (trained_model_path,)
# debug local
trainer(TRANSFORMED_DATA_PATH, TRAINED_MODEL_PATH)
@component(base_image=BASE_IMAGE_PREDICTOR)
def predictor(raw_data_path: str, transformed_data_path: str, trained_model_path: str, predicted_data_path: str, kaggle_commit_message: str) -> NamedTuple("outputs", [("predicted_data_path", str)]):
import os
from io import BytesIO
import pickle
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from kaggle.api.kaggle_api_extended import KaggleApi
# input
gender_submission = pd.read_csv(raw_data_path + '/gender_submission.csv')
X_test = pd.read_csv(transformed_data_path + "/X_test.csv", index_col=0)
loaded_model = pickle.load(open(trained_model_path + "/model_titanic.sav", "rb"))
# run
y_pred = loaded_model.predict(X_test)
# submit
gender_submission["Survived"] = list(map(int, y_pred))
if not os.path.exists(predicted_data_path):
os.mkdir(predicted_data_path)
gender_submission.to_csv(predicted_data_path + "/submission.csv", index=False)
api = KaggleApi()
api.authenticate()
api.competition_submit(predicted_data_path + "/submission.csv", message=kaggle_commit_message, competition="titanic")
return (predicted_data_path,)
# debug local
predictor(RAW_DATA_PATH, TRANSFORMED_DATA_PATH, TRAINED_MODEL_PATH, PREDICTED_DATA_PATH, KAGGLE_COMMIT_MESSAGE)
@dsl.pipeline(
name="titanic",
description="pipeline for titanic",
pipeline_root=PIPELINE_ROOT,
)
def pipeline(
raw_data_path: str = RAW_DATA_PATH,
transformed_data_path: str = TRANSFORMED_DATA_PATH,
trained_model_path: str = TRAINED_MODEL_PATH,
predicted_data_path: str = PREDICTED_DATA_PATH,
kaggle_commit_message: str = KAGGLE_COMMIT_MESSAGE
):
transform_task = transform(raw_data_path, transformed_data_path)
# 実行するコンテナのスペックを変更する場合に記述する
transform_task.set_cpu_limit("4").set_memory_limit("16")
trainer_task = trainer(transform_task.outputs["transformed_data_path"], trained_model_path)
predictor_task = predictor(raw_data_path, transform_task.outputs["transformed_data_path"], trainer_task.outputs["trained_model_path"], predicted_data_path, kaggle_commit_message)
- 補足: ベースイメージを指定+必要なパッケージをインストールする場合
@dsl.component(
base_image='python:3.8', # 関数を実行するベースイメージを指定
packages_to_install=["pandas>=1.3.1", "scikit-learn>=0.24.2"] # 必要なパッケージをここで指定
)
3. パイプラインをコンパイルする
# Compile the pipeline
from kfp.v2 import compiler # noqa: F811
compiler.Compiler().compile(
pipeline_func=pipeline, package_path=PIPELINE_SPEC_NAME
)
4. パイプラインを実行する
# Run the pipeline
job = aip.PipelineJob(
display_name=DISPLAY_NAME,
template_path=PIPELINE_SPEC_NAME,
pipeline_root=PIPELINE_ROOT,
)
job.run()
# save notebook
!cp $NOTEBOOK_NAME $NOTEBOOK_NAME_SAVED
課題・ToDo
- データやモデルのGCSパスをジョブ間で渡しているが、Artifactの利用もできるはず
- ノートブックにもGCSをマウントする
- 複数人開発を見据えたルール整備する
- 実験管理周りを充実させる
- スクリプト化する
- WorkBenchインスタンスへVSCodeでリモート接続する
- GitHub Actionsと連携させてCI/CDパイプラインを組む
- BigQuery・可視化ツールと連携する
- Dataprocと連携する