はじめに
- GCPのサービスを活用してエンドツーエンドなMLOps基盤を構築してみたときのメモです。
- 【ToDo】の部分は今後追記予定です
アーキテクチャ構成
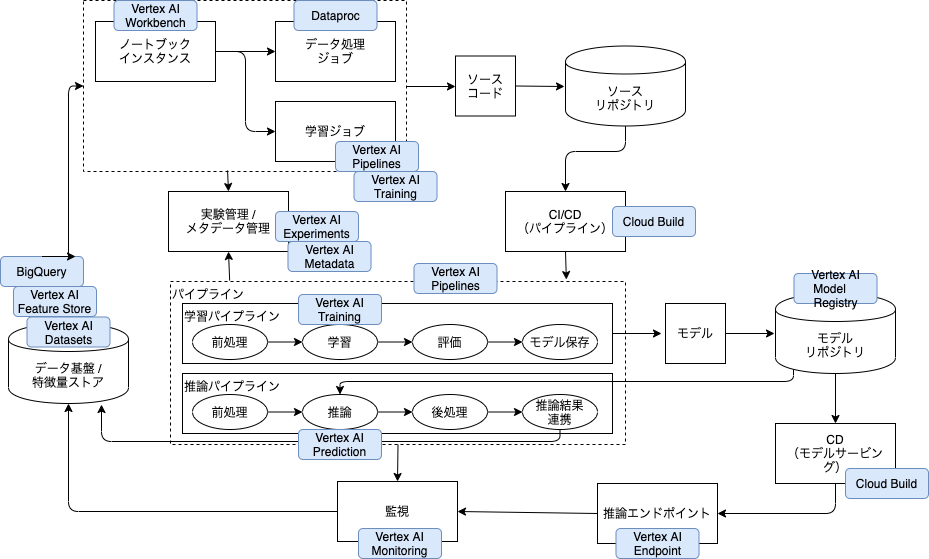
GCP実装例
1. データ基盤構築
概要
- データを格納する環境を構築する
- テーブルデータの場合: 生データをBigQueryに格納→Vertex AI Feature StoreやVertex AI Datasetsに加工したデータを格納するなど
- 画像データの場合: GCSに格納するなど
- Why BigQuery
- カラム指向データ構造(一般的なRDBはレコード指向)→列を抜き出して操作する集計処理などが得意追加更新削除のようなオンライントランザクション処理が得意(苦手)
- ANSI準拠の標準SQLを使用できる
- サーバーレスでスケーラビリティと費用対効果に優れている: ストレージとクエリーリソースが自動的にスケールする。サーバーレスで運用コストが低い。ツリーアーキテクチャによる処理の分散や並列処理が可能になっている。類似サービスと比較して安価であり、オンデマンド料金モデルなどによりコスト削減を実現可能。
- GCPの他サービスとの連携しやすい(最近はGCPサービスに限らない)
- Why Vertex AI Feature Store
- 「共有と再利用が難しい」を解決
- 冗長さの低減。各チームは特徴量エンジニアリングのためのパイプラインをそれぞれ独自に開発して運用する必要がなくなる
- 企業全体で共有される特徴量のリポジトリとして機能し、既存の特徴量を検索するための分かりやすい UI と API を備えます。また、特徴量のグループに対して適切な権限を設定し、特徴量へのアクセス制御も可能
- 「本番環境で求められる高信頼・低遅延の特徴量サービングの実装が難しい」を解決
- 特徴量のオンラインサービングをスケーラブルかつ低レイテンシで行うための、使いやすいフルマネージド ソリューションを提供する
- オンラインとオフラインという性質の異なる2つのシステムにデータを供給
- オンラインはNoSQLで高頻度の読み書きに耐えられるように。オフラインは長期的な保存のためオブジェクトストレージ、など
- Batch Import APIとStreaming Import API
- 「トレーニング時とサービング時で特徴量に意図しないスキュー(ずれ)が生じる」を解決
- 特徴量が Vertex Feature Store に一度取り込まれると、トレーニングとサービングの両方に再利用される
- 取り込まれた特徴量の分布を常に監視する
- データリークを防ぐ Point-in-time 検索
- 「共有と再利用が難しい」を解決
手順
ポイント
- BigQueryのポイント
- 権限管理
- メンバ×対象レイヤ×権限 で設定する
- 対象レイヤ
- 組織レベルおよびプロジェクトに対してアクセス権を付与する際に
Cloud IAM - データセットに対してアクセス権を付与する際に
共有データセット - テーブルに対してアクセス権を付与する際に
table access controls - テーブルやビュー以下の単位に対してアクセス権を付与する際に
承認済みビュー - テーブルの列の単位に対してアクセス権を付与する際に
列レベルのセキュリティ - 実行時の条件に対してアクセス権を付与する際に
Cloud IAM Conditions
- 組織レベルおよびプロジェクトに対してアクセス権を付与する際に
- 対象レイヤ
- データサイエンティストによるアクセスを特に検討する
- DEV環境(データサイエンティストが自由に実験できる環境)として、権限設定を考慮した上でデータ基盤を直接参照できるようにする?
- PROD/STG→DEVにコピーする?(インプットデータに加え、中間データ、推論結果なども同様)
- 個人情報を持つ場合は、加工してコピーする?
- メンバ×対象レイヤ×権限 で設定する
- 課金管理
- チーム、ユーザごとに課金管理する必要がある場合、方法を検討する(ラベル付与など)
- 権限管理
- 【ToDo】Vertex AI Feature Storeのポイント
2. モデル開発
概要
- モデル開発のためのセキュアでスケーラブルなモデル開発環境をVertex AI Workbench(マネージドなノートブック環境)で構築する
- 必要に応じて、計算量が不足する場合に学習処理ジョブ実行をする(ノートブックインスタンスからCustom Jobを投げる)
- 必要に応じて、計算量が不足する場合にデータ処理ジョブ実行をする(ノートブックインスタンスからDataproc Jobを投げる)
- Why Vertex AI Workbench
- フルマネージドでノートブック環境を提供
- セキュリティ管理やユーザー管理の機能が搭載
- アイドルタイムアウトと自動シャットダウン機能が搭載
- インタラクティブなデータとML体験。BigQuery、データレイク、Dataproc、Spark などのデータ資産全体とシームレスに接続
- WorkbenchのUIからGCSのファイルパスの確認ができる
- WorkbenchのUI から BQテーブルのメタ情報とプレビューにアクセス可能、クエリエディタが起動、出力結果をDataFrameに落とすためのコードが取得可能
- 最小限の移行でVertex AIにAIソリューションを開発してデプロイ
- Vertex AIサービスとの緊密な統合により、コードや新しいワークフローを書き換えることなく、MLOpsをノートブックに組み込むことができる
- ノートブックのセルをジョブとしてスケジューリング実行可能
- ジョブはVertex TrainingのCustom Jobsとして実行される
- フルマネージドでノートブック環境を提供
手順
- 【ToDo】Vertex AI Workbenchを利用してセキュアでスケーラブルなモデル開発環境を構築する参照
- GCPVertexAI(Workbench,Pipelines)で始めるKaggle参照
- Custom Job作成コマンド例
gcloud ai custom-jobs create \
--region=LOCATION \
--display-name=JOB_NAME \
--worker-pool-spec=machine-type=MACHINE_TYPE,replica-count=REPLICA_COUNT,container-image-uri=CUSTOM_CONTAINER_IMAGE_URI
ポイント
- Vertex AI Workbenchのポイント
- ネットワーク
- VPC内に作成できる(サブネット選択可)
- マネージドノートブック or ユーザー管理のノートブックの使い分け
- 家族アルバム みてねにおけるMLOps事例紹介参照
- マネージドノートブック(Vertex AIで新規に提供された機能)
- リージョンはus-central1(Iowa)のみ(現時点)
- ユーザのアカウントで管理。シングルユーザーモードのみ
- TensorFlow、PyTorch、汎用ハイパフォーマンス コンピューティングなどのよく使用されるフレームワークが含まれているマネージド環境のみ指定可能
- カスタムDockerイメージを使うことができる(Artifact Registoryのイメージを指定可能)
- アイドル状態でのシャットダウン設定が可能
- ノートブックをジョブ実行が可能(スケジューリング実行も可能)
- ユーザー管理のノートブック(従来のNotebook)
- ユーザのアカウント or サービスアカウントで管理
- 様々な環境を指定可能(Python3, PyTorch1.9, Dataproc Hub, etc)
- 品質管理
- データサイエンティストにテンプレートを渡しておくのが良い
- ディレクトリ構成を決めておく
- Jupyterと.pyの役割分担を決めておく
- ノートブックからスクリプトへの移植の流れと役割分担は確立しておくこと(相互)。ノートブックからVertex AI Pipelineを呼び出している場合は、componentファイルなどを出力できるのでそれをベースにできる。(現状完全互換ではない)
- ディレクトリ構成を決めておく
- レビューフローを決めておく
- データ管理方針を決めておく
- 生のデータセットと変換されたデータセットの両方のバージョンを管理する
- 人ごとにどこにおくか
- ローカルと本番の環境差異が発生しないようにする
- データサイエンティストにテンプレートを渡しておくのが良い
- 課金管理
- データサイエンティストごとに用意すると意外とコストが嵩むので注意する。定期起動や起動しっぱなしの検知を検討しておく。tagで管理する
- 自動バックアップの仕組みがある(特定ディレクトリ)
- ネットワーク
3. パイプライン開発・デプロイ
概要
- Vertex AI Workbenchで開発したコードをVertex AI Pipelinesのパイプライン化する
- Why Vertex AI Pipelines
- Pythonでパイプラインの記述が可能
- OSSであるKubeflow Pipelinesベース
- サーバーレスで、インフラの管理を意識することなくサービスを利用できる
- 各コンポーネントの実行時のみインスタンスが立ち上がる
- マシンスペックを柔軟に指定できる
- パイプラインを管理し、生成物を可視化するためのWeb UIがある
- コードと生成物の管理が容易
- ワークフローのアーティファクトのリネージを分析可能
- GCSマウント可能(ローカルと同じように)
- キャッシュ可能
- コンポーネントの実装はPython関数・Docker image・Google Cloudパイプラインコンポーネント
- (参考)MLパイプラインの必要性
- (参考)Python関数でコンポーネント実装パターン
手順
Vertex AI Pipelines開発
- 0_ディレクトリを作成する
ディレクトリ構成例
project
├── README.md
├── components
│ ├── data_generator
│ │ ├── src
│ │ │ └── data_generator.py
│ │ ├── Dockerfile
│ │ └── component.yaml
│ ├──transform
│ │ └── ...
│ ├── trainer
│ │ └── ...
│ └── evaluator
│ └── ...
└── pipeline.py
- 1_各Componentを作成する
- 1-1. src(.py) + Dockerfileを作成する
- 1-2. Component定義ファイル(.yaml)を作成する
components/trainer/src/trainer.py
...
def train(dataset_uri: str, learning_rate: float, max_depth: int, artifact_uri: str) -> None:
...
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Train')
parser.add_argument('--dataset-uri', type=str)
parser.add_argument('--learning-rate', type=float, default=0.1)
parser.add_argument('--max-depth', type=int, default=10)
parser.add_argument('--artifact-uri', type=str)
args = parser.parse_args()
train(**vars(args))
components/trainer/Dockerfile
...
ENTRYPOINT ["python", "src/trainer.py"]
components/trainer/component.yaml
name: trainer
description: Train on LightGBM
inputs:
- {name: dataset, type: Dataset}
- {name: learning_rate, type: Float, default: 0.1}
- {name: max_depth, type: Integer, default: 10}
outputs:
- {name: artifact, type: Model}
implementation:
container:
image: gcr.io/<container_image_path>/train:latest
command: [python, src/trainer.py]
args: [
--dataset-uri, {inputPath: dataset},
--learning-rate, {inputValue: learning_rate},
--max-depth, {inputValue: max_depth},
--artifact-uri, {outputPath: artifact}
]
- 2_Pipelineを作成する
- 2-1. Pipeline作成ファイル(.py)を作成する
- 2-2. Pipeline作成ファイル(.py)を実行し、Pipeline定義ファイル(.json)を生成する
- -> このjsonファイルがVertex Pipelineの実行時に必要となる唯一のファイル
- 2-3. コンソール or PythonクライアントからPipelineを作成する
pipeline.py
from kfp.v2 import dsl, compiler, components
...
@dsl.pipeline(name='pipeline', pipeline_root=ROOT_BUCKET)
def pipeline(learning_rate: float = 0.1, max_depth: int = 10) -> None:
# data_generator
# コンポーネントの読み込み
data_generator_op = components.load_component_from_file(
'components/data_generator/component.yaml')
# コンポーネントの実行
data_generator_task = data_generator_op(src_csv=SOURCE_CSV_URI, n_splits=3)
...
# trainer
# コンポーネントの読み込み
trainer_op = components.load_component_from_file(
'components/trainer/component.yaml')
# コンポーネントの実行
trainer_task = trainer_op(dataset=transform_task.outputs['dataset'],
learning_rate=learning_rate,
max_depth=max_depth)
# カスタムジョブの実行時設定
trainer_task.custom_job_spec = {
'displayName': train_task.name,
'jobSpec': {
'workerPoolSpecs': [{
'containerSpec': {
'imageUri': trainer_task.container.image,
'args': trainer_task.arguments,
},
'machineSpec': {
'machineType': 'c2-standard-4'
},
'replicaCount': 1
}],
}
}
...
### パイプライン関数をコンパイルする
compiler.Compiler().compile(pipeline_func=pipeline,
package_path='pipeline.json')
# Pipelineを作成する
import google.cloud.aiplatform as aip
if __name__ == "__main__":
job = aip.PipelineJob(
display_name="pipeline",
template_path="pipeline.json",
location="asia-northeast1"
)
job.submit()
CI/CDパイプライン開発
cloudbuild.yaml
steps:
# Build the container image
- name: 'docker'
entrypoint: 'sh'
args: [
'-c',
'docker build -f Dockerfile -t us.gcr.io/$PROJECT_ID/${_IMAGE_NAME}:$COMMIT_SHA -t us.gcr.io/$PROJECT_ID/${_IMAGE_NAME}:latest .'
]
# Push the container image
- name: gcr.io/cloud-builders/docker
args:
- push
- us.gcr.io/$PROJECT_ID/${_IMAGE_NAME}
...
ポイント
- Vertex AI Pipelines開発のポイント
- 各コンポーネントの実行結果をキャッシュしておける(リラン)
- cachingOptions
- コンテナベースのコンポーネントではModelやMetricsの型が未対応?(現時点)
- → executor_inputを利用して自前でどうにかする必要がある
- Pythonベースであれば対応している
- Metrics: UI上にパイプライン実行時の指標を表示できる
- GCSパスの指定ができる
-
dsl.pipelineの引数である、pipeline_rootにCloud Storageのバケットを指定することで、各処理で生成されるアーティファクトを保持しておくことができます。このバケットはCloud Storage FUSEによって各ジョブのインスタンスにマウントされるため、 ローカルファイルシステムとしてファイルの読み書きが可能です。
-
- 各コンポーネントの実行結果をキャッシュしておける(リラン)
- Vertex AI Pipelines実行のポイント
- Cloud FunctionsやCloud Composerでラップ・キックする (or Vertex AI Pipelineでもcron形式でスケジュール実行可能?現時点では未対応と思われる)
- 既存方針・運用の踏襲、待ち合わせ処理などDAGでシンプルな実装が可能な処理、VertexAI Pipelineの起動ラグ、などを考慮する
- ジョブごとにVertexAI Pipelineのjsonを指定し、引数を渡すイメージ
- 課金監視ができるようにしておく
- コードにバージョンを仕込んでおく
- Cloud FunctionsやCloud Composerでラップ・キックする (or Vertex AI Pipelineでもcron形式でスケジュール実行可能?現時点では未対応と思われる)
- Cloud Buildのポイント(Vertex AI Pipelines利用前提)
- 成果物: コンテナイメージとpipeline spec
- →バージョン管理する。Gitのハッシュ値ごとなど
- ブランチ: mainにマージ→ビルド→STGにデプロイ ⇨ OKなら、mainでtag打ち・PRODにコピー・PRODにデプロイ、など
- このタイミングではビルド(とテスト)まで(=STGへのデプロイ前まで)
- STG→PRODにtag打ちしつつもろもろコピーして断面を残す(再度ビルドが必要なものは再度ビルド)
- タイムアウト通知やエラー通知を仕込んでおく
- CI結果を誰がみるか。そのためにどこに飛ばすか、CIスクリプトを誰がメンテするか考えておく
- 成果物: コンテナイメージとpipeline spec
4. エンドポイント構築・デプロイ
概要
- 学習されたモデル、推論ロジックを含んだイメージをVertex AI Modelsにアップロードし、それをVertex AI Endpointsへとデプロイする
- Why Vertex AI Models / Vertex AI Endpoints
- Vertex Pipelinesパイプラインとの結合が簡単
- Python向けSDKであるgoogle-cloud-aiplatformを用いることで、パイプラインの一部として推論APIのリリースを組み込むことができる
- Cloud Runなどのサービスでリリースフローを実現するためには、そのための機能を開発する必要がある
- バッチ推論への切り替えが簡単
- Vertex Models は Vertex Endpoints にデプロイすればオンライン推論を行うことができ、同時に Vertex Batch Prediction としてバッチ推論にも利用可能
- Vertex Pipelinesパイプラインとの結合が簡単
手順
エンドポイントを作成する
$ gcloud ai endpoints create \
--region=LOCATION \
--display-name=ENDPOINT_NAME
モデルをデプロイする(カスタムトレーニング)
$ gcloud ai endpoints deploy-model ENDPOINT_ID\
--region=LOCATION \
--model=MODEL_ID \
--display-name=DEPLOYED_MODEL_NAME \
--machine-type=MACHINE_TYPE \
--min-replica-count=MIN_REPLICA_COUNT \
--max-replica-count=MAX_REPLICA_COUNT \
--traffic-split=0=100
ポイント
- Vertex AI Endpointsのポイント
- ビルド済みコンテナ or カスタムコンテナ
- ビルド済みコンテナを使うには条件あり
- カスタムコンテナによってVertex AI上で予測を提供するためには、HTTPサーバーとして一定の要件を満たすように実装を行う必要があり。FastAPIで実装するなど
- Torch Serveを使うとシンプルに実装できる?
- GPU指定可能
- インスタンスの状態を0にはできない
- ビルド済みコンテナ or カスタムコンテナ
5. 監視
概要
- Cloud Monitoring / Cloud Logging / Vertex AI Monitoringを活用して死活監視・リソース監視・ログ監視・精度監視(データ分布の監視)をする
- 機械学習システムの監視入門参照
手順
- Model Monitoring ジョブの作成
- モニタリング ジョブの構成は、エンドポイントにデプロイされたすべてのモデルに適用されます。
- → 特徴に設定されたしきい値を超えると、Model Monitoring が異常を検出します。Model Monitoring は、検出された異常をメールで自動的に通知しますが、Cloud Logging でアラートを設定することもできます。
gcloud ai model-monitoring-jobs create \
--project=PROJECT_ID \
--region=REGION \
--display-name=MONITORING_JOB_NAME \
--emails=EMAIL_ADDRESS_1,EMAIL_ADDRESS_2 \
--endpoint=ENDPOINT_ID \
--feature-thresholds=FEATURE_1=THRESHOLD_1,FEATURE_2=THRESHOLD_2 \
--prediction-sampling-rate=SAMPLING_RATE \
--monitoring-frequency=MONITORING_FREQUENCY \
--target-field=TARGET_FIELD \
--bigquery-uri=BIGQUERY_URI
ポイント
- Vertex AI Monitoringのポイント
- VertexAIのEndpointを利用する場合に使うことができる。本番で受けたリクエストをサンプリングして監視する
- 検出できる項目には「スキュー」と「ドリフト」の2種類が存在する。「スキュー」の場合のベースラインは、Training時のデータとなり、現在の本番データがトレーニングとどれだけ乖離しているかを検出する。それに対して「ドリフト」は直近に本番で確認されたデータが比較対象となる。時刻nとn+1を比較して時間で差異が発生してないかを検出する。
- 数値の場合はジェンセン・シャノンダイバージェンスを、カテゴリの場合はチェビシェフ距離を使って分布感の距離を計算し、設定した閾値以上の場合はAlertが来る仕組みとなっている。
- 仕組みと運用をどう組み合わせて継続的な精度監視を実現するか
その他
- 共通して、スケール設計・権限管理・課金管理・バックアップリストア改廃あたりは検討する
- 各種サービスのクォータ・対応リージョン・GAかどうかに注意する
- クォータ制限対応のためにはプロジェクトごとのスケールアウトなども検討する
- 各種サービスのクォータ・対応リージョン・GAかどうかに注意する
- マルチテナントの設計ポイント
- 共通チームと個別チームの役割分担を明確にしておく
- 必要になった人が開発する?旗振りは共通チーム?
- マイルストーンは合意しておく
- 変更があるので、矢羽ではなく日付で
- チームごとのステータス管理ができるようにしておく
- logをsinkして共通に寄せる
- 共通チームと個別チームの役割分担を明確にしておく
参考
- BigQuery アクセス権設定まとめ & グループ設計例
- Vertex AI Workbench
- 【Vertex AI】Workbench は革命児
- Vertex Feature Storeの機械学習システムへの導入
- Vertex Feature Store で特徴量管理の MLOps はこう変わる
- MLflowで実験管理入門
- Vertex Pipelines で動く Kubeflow Pipelines のサンプルを公開しました
- Vertex Pipelinesによる機械学習パイプラインの実行
- VertexAIで構築したMLOps基盤の取り組み
- Cloud BuildでDockerfileからimageを作成してGCRにpushする
- MLOps: 機械学習における継続的デリバリーと自動化のパイプライン
- Vertex AIでカスタムモデルをサービングする
- 機械学習導入初期フェーズにおける Vertex AI Models / Endpoints を用いたオンライン推論