はじめに
- GCPのデータエンジニアリング系サービスを勉強したときのメモです
- AIチームのためのデータエンジニアリング入門で一度まとめましたが、Professional Data Engineer取得に向けてサービス別に勉強し直したときのメモです
データ基盤全体像
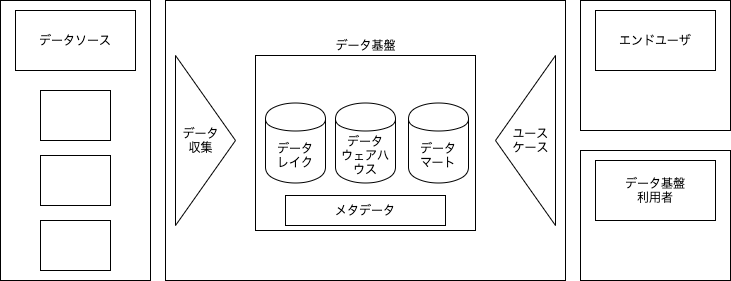
①データソース
- 業務システムのデータベースなど
②データ収集(処理)
- キュー、トリガファイルなどを利用する
- データベースからの収集
- ①SQL利用
- SQL、レプリカからSQL→たいていの場合、これが良い?
- データ全量ではなくカーソルだけを返すことも検討する
- ②ファイル経由
- エクスポート、データベースダンプ
- ③更新ログ収集
- 更新ログからDB復元、CDCツール
- ①SQL利用
- ログからの収集
- ログエージェントにはバッファを持たせる
- 分散メッセージキュー
- 順序性保証、メッセージの重複、可視性タイムアウトなどに気をつける
③データレイク層
- rawデータをそのまま集めること
- 構造化データも非構造化データも保存する
④データウェアハウス層
- 共通指標となるデータの置き場
- ここでデータクレンジングをする
- 先にデータマートを整理して、共通化できそうだったらここを作っていく(先に両端から詰めていく)
- 更新が苦手なので、一時テーブルを作成して差し替える
⑤データマート層
- 特定用途向けのデータの置き場
- ユースケースと1対1の対応
- データウェアハウス製品がデータウェアハウス層だけでなくデータマート層も扱えたりする
⑥ユースケース
- 毎週のジャンル別の売り上げのモニタリング、など
- データの利用状況を5W1Hで整理すること
サービス別ポイント
GCS(Cloud Storage)
概要
- Google Cloudのオブジェクトストレージ
構成図
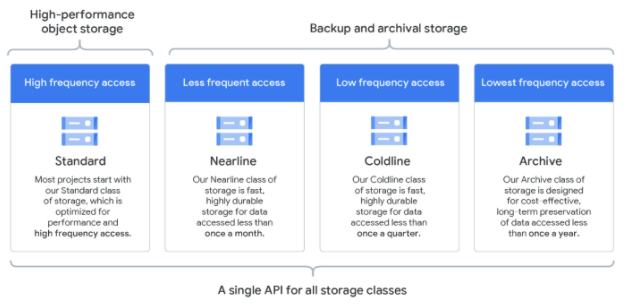
ポイント
- Hadoopのクラスタの寿命より長くデータを保持したい → Cloud Storageコネクタを使用する
- ストレージクラスを正しく使い分ける
- ライフサイクル
- 大量アップロードはgsutilを並列実行、TARファイルを送信して分解
- データ移行
- Storage Transfer Service
- オンライン
- スケジューリング可能
- Transfer Appliance
- オフライン
- 大量データ。データセンターで
- Storage Transfer Service
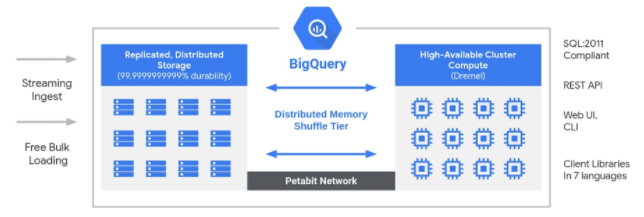
BigQuery
概要
-
Google BigQueryは、ビジネスのアジリティを高めるように設計された、Google Cloudのエンタープライズデータウェアハウスです。
-
そのサーバーレス アーキテクチャは、大規模かつ高速な動作を可能にし、大量のデータセットに対して驚くべき速度でSQL解析を実行できます。
- Analytics Platform as a Service
構成図
ポイント
- BQでは、クエリの結果は全てテーブルとして結果が書き込まれる
- 一時的なキャッシュテーブル(デフォルト)
- 最大24時間保管
- キャッシュが効かない例
- CURRENT_TIMESTAMP()を利用している
- キャッシュを利用しないオプションを指定している
- クエリ対象テーブルが変更されている
- 宛先テーブル
- CREATE TABLE AS SELECT と同じ
- 一時的なキャッシュテーブル(デフォルト)
- JSONのデータが貯まっている。SQLを実行したい→BQにインポートする。スキーマはAutomatically detectにしておく(スキーマの変更を検出する)
- GCSのCSVをSparkで変換しているが、アナリストはANSI SQLを実行したい → BQを利用する。Dataprocを使用して変換を実行する
- BQにストリーミングで挿入するが、データが1回のみ送信される保証はない → 1つに絞るために、
SELECT ROW_NUMBER() OVER (PARTITION BY category ORDER BY purchases DESC) rn WHERE rn = 1--- PARTITION by "一意のID列"としている。その内の行番号=1を指定している。 - 複数のテーブルのデータに対してクエリ → バッククォート、ワイルドカード
- BQでユーザが何をしているか確認 → Cloud Audit Logを使用してデータアクセスを確認する。Activityタグ。誰がいつそのリソースを作成したのか
- SQLをサポートしている。BigTableはサポートしていない。CloudSQLも権限管理が難しいので分析用途には向いていない。(→分析でSQLを利用するならBQ)
- バッチならタダ。デイリーで更新なら問題ない。
- BIツールから参照するときなど、コスト削減のためにはキャッシュが大事
- キャッシュが効かないのは、timestampや、wildcard、destination tableを使っている
- ユーザーごとにカスタムクォータを設定する。1日あたりPJ/ユーザ
- スキーマの変更ができないケースは、INSERT SELECTなどを使って作り直す(単なるカラム追加は可能)
- カラム名変更
- カラムデータタイプ変更
- カラム削除
- GCSにデータを置いたままexternal tableとしてクエリをかけられる
- まずexternal → 処理してinternalに(レポートのためなど)
- エンコーディング注意
- 権限を正しく付与する
- engineer groupにadmin / data analystにdataEditor / dev teamにuser
- authorized viewを作る。同じデータセットに
- 元のテーブルへのアクセス権がなくても、クエリの結果を特定のユーザに共有できる
- 緊急メンテナンス時に一時的な権限付与をどうするか(権限付与の履歴は残す)
- editorでも不足する場合もある?INFORMATION_SCHEMAを見れるようにとか(アプリチームもINFORMATION_SCHEMAは見るとか)
- クエリ数と実行時間をモニタリングする
- 分析のためには、CloudSQL→Dataflow→GCS→BQ→DataStudio、など
- パーティショニングとシャーディングを正しく設計する(スキャン量を減らすためにも。シャーディングはテーブル数の上限に注意)
- TABLE_DATE_RANGE()で過去30日にクエリ
- Audit logを管理する
- 特定のテーブルの更新を確認したい → 高度なログフィルタでテーブルログのみをフィルタ
- 更新は苦手なので、新しいテーブルを作成して元とマージする。BQジョブを作成する。
- コスト分析ができるようにしておく。クエリとストレージ
- ストレージはデータセットごとにtagを打っておく、ダッシュボードを作っておく
- コストを正しく取得できているか。データ量=コストではない。logical volumeかとか。
- 不要なデータセットが増えていくもの。対策を考えておく
- データ量順に表示
- tagがついていないデータセットを検知
- メトリクス確認
- 大きくはクエリ(スロット)とストレージ
- 割り当てに対して何%か、実行時間外れ値ないか、Query Countの規則性、Stored Bytes
- タイムトラベル機能で直近1wは遡ることができる
- INFORMATION_SCHEMA でクエリごとのスロット使用量や実行時間を確認できる
- チームごとなどに集計するには、クエリに仕込んでおく?
- スロットを購入するときはignore_idol_slotを設定
- データセットコピーの方式はいくつかあるので、使い分ける
- BQDT(データセットごと)、snapshot、etc
- ストレージ量が増えないように設定しておく。snapshot改廃期間、longterm, TVFの利用、etc
- スロット割り当ての履歴は残しておく。後から、テストや障害分析時にスロット量がどうだったか分かるように
- どのチームがどこまで管理するか決めておく。データセットはインフラでTerraform、とか
- データセットの命名規則を予め決めておく
- クォータ制限もあるので注意
- QueryUsagePerDayとか
- データの転送方法は色々あるので適切に使い分ける
- BigQueryDataTransfer
- 差分更新
- 定期実行の場合、12時間ごと
- -> Composerなどでラップするべきか
- 途中でこけてしまった場合の検知
- データの更新をメタデータで見る場合は、0件の場合に注意
- PubSubを利用するか
- TimeTravel利用時は制約条件に注意
- DropCreate, non-partitionとか
- Sessionの管理
- Analytics Hubの活用
- 各種 BigQuery オブジェクト(テーブル、ビュー、ML モデル)を、組織間で共有できるサービス
BigTable
概要
- フルマネージドでスケーラブルな NoSQL データベース サービス
- レイテンシが安定して 10 ミリ秒未満で、毎秒何百万ものリクエストを処理
- パーソナライズ、アドテック、フィンテック、デジタル メディア、IoT などのユースケースに理想的
構成図

ポイント
- 時系列データに向いている
- write readの要件が高く、クエリ要件がない場合に向いている
- 1TB未満は向かない
- 250000台のデバイスから10sごとにjson形式のデバイスステータスイベントを生成。外れ値の時系列分析をしたい → Bigtableに入れて、cbt(command line tool)で外れ値データを表示する
- システムメトリックを収集したい。スケールを考慮 → Pub/Sub → Dataproc or Dataflow → BigTable
- センサー情報が貯まっている。クエリパフォーマンスを改善するには? → ホットスポット化(特定のSpannerノードにリクエストが集中してしまう現象)に注意する。値が単調に増加する列を最初のキー部分に選択すると、キー空間の最後にすべての挿入が実行される。本来はUUID v4 を推奨。#。だけだと古いデータを上書きしてしまう。
- ストレージタイプを変更するなら作り直し。Dataflowでexport
- tall and narrowテーブルになるように。1行を長くではなく、縦に増やしていく
- 性能テストをするなら
- 300GB以上入れてスペックを上げておく
- スケールアップは事前にしておく
- pre-testを事前にしておく
- パフォーマンスを出すために
- ノードを追加
- 行ごとのcellが大きくならないようにする
- development type と Production type
- HDDとSSD
- クラスタのサイズを増やすのは、書き込みレイテンシとストレージ使用率を確認する
- 分析用とクラスタを分ける。プロファイル
- スロット使用量を監視。slot/allocated-for-project
- プロジェクトの優先順位を階層的に設定
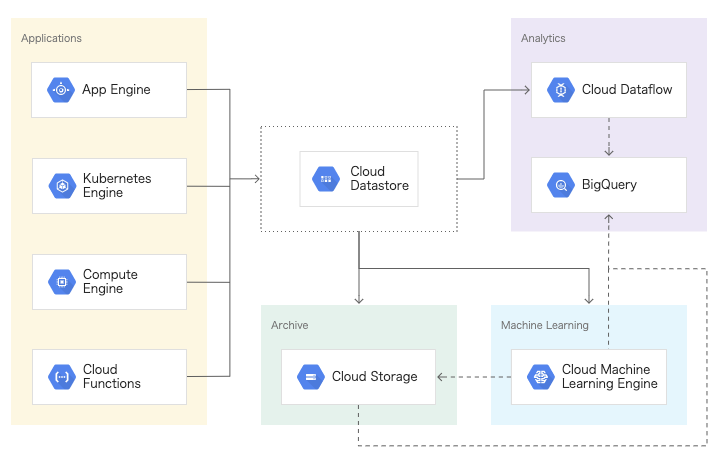
DataStore
概要
- スケーラビリティの高い NoSQL データベース
-
Datastore はシャーディングとレプリケーションを自動的に処理し、アプリケーションの負荷に合わせて自動的にスケールする、可用性と耐久性を兼ね備えたデータベースを提供します。Datastore は ACID トランザクション、SQL ライクなクエリ、インデックスなどの多くの機能を備えています。
構成図
ポイント
- SQL-like language
- fully managed
- semi-structured
Cloud SQL
概要
- MySQL、PostgreSQL、SQL Server 向けのフルマネージド リレーショナル データベース サービス
構成図
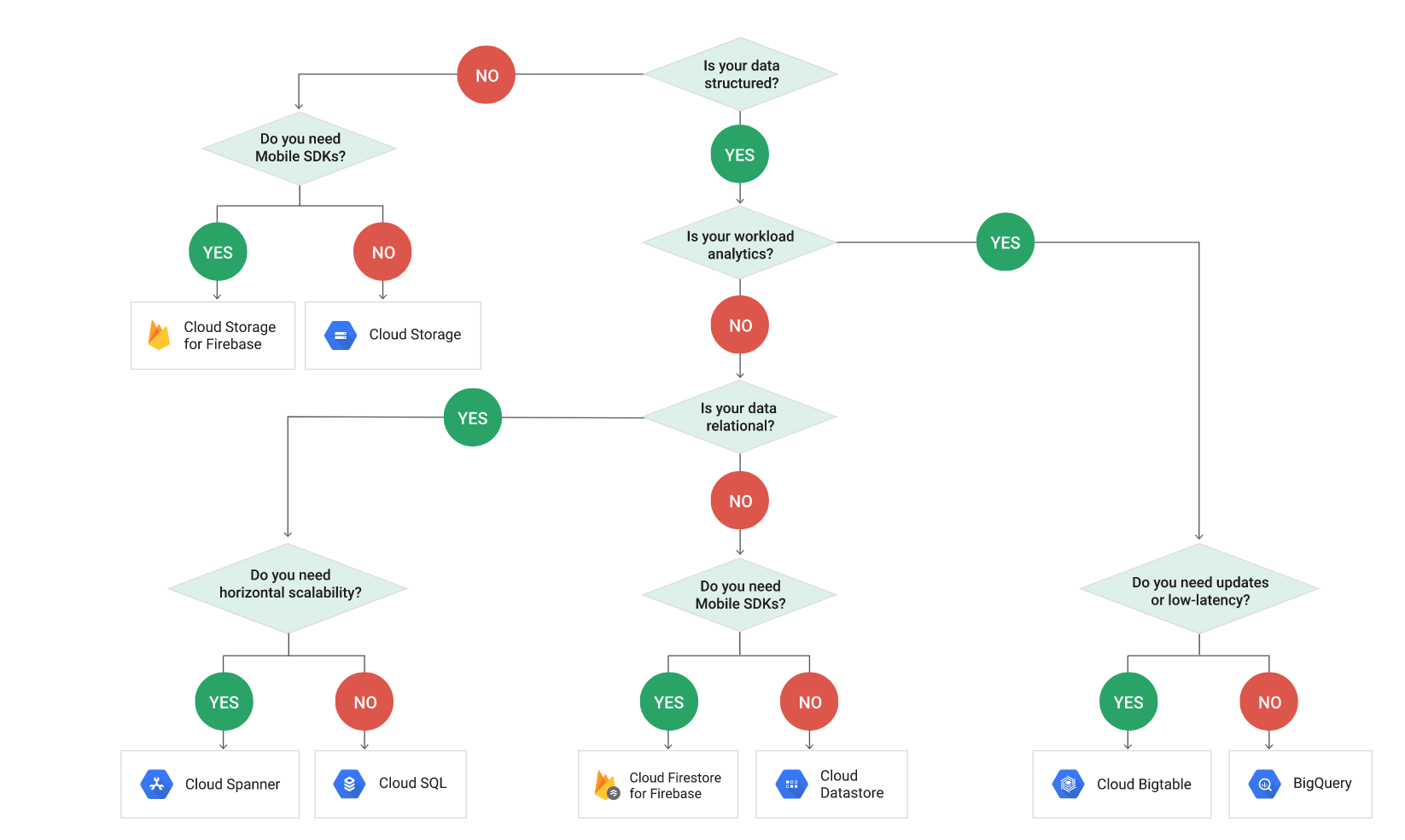
- GCPのストレージサービスの使い分け
ポイント
- fail-over replica
- 分析のためにread replicas
- privateアクセスにするときは、GCP側のVPCが作成されてpeeringされる。VPCまたぐときはAuth proxyを立てる
- proxyサーバをたてて、そこでproxyプロセスを起動(proxy-CloudSQL間セッション起動)。クライアントはproxyサーバのIP・ポートに接続
- メンテナンスの経路は考えておくこと
- パスワードはSecretで管理
- メンテナンス通知設定、優先時間設定
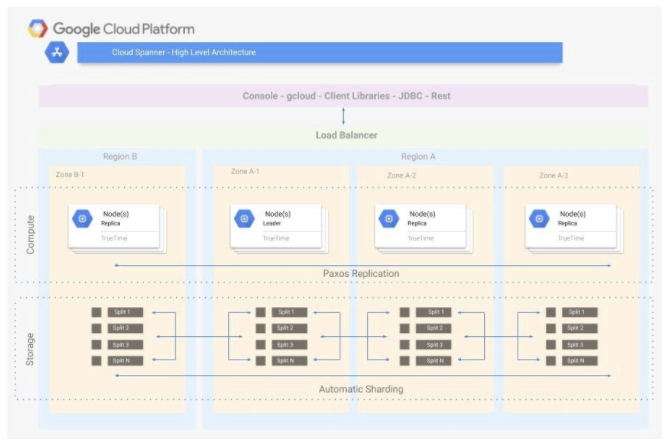
Cloud Spanner
概要
- 無制限のスケーリング、強整合性、最大 99.999% の可用性を備えたフルマネージド リレーショナル データベース
- グローバル水平スケールが求められたり、大量データ(64TB以上)を扱う場合に利用する
- 特定のレコードを主キー以外の列で見つけたいとき → セカンダリインデックス
- 元のテーブル(ベーステーブル)よりも遥かに小さいサイズのインデックステーブルから効率的に目的のレコードを取得する
構成図
ポイント
- 必要に応じて拡張するリレーショナルデータレポジトリ、入力トラフィックに合わせてノード数を調整する → Spannerを利用。CPU使用率をモニタリングし、使用率が70%を超えたらノード数を増やす
- ファイルの修正を検知
- 手動でre-run
- セカンダリインデックスの活用
- 性能を出すために
- 主キーが単調に増加しないようにする
- timestampをPKにしないようにする
Pub/Sub
概要
- 信頼性とスケーラビリティに優れた非同期メッセージサービス
構成図
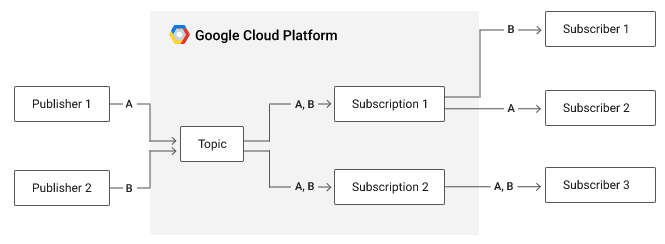
ポイント
- ログメッセージのメッセージングサービス。現在のステータスにクエリ → パブリッシャーの全てのメッセージにタイムスタンプをつける
- Pub/Subを利用してPOSからBQにストリーミングで連携しているが、ネットワークの停止中にメッセージの重複送信があった。在庫の更新を正確にしたい → クライアントアプリケーション側で一意のID(GUIDとか)をつける。Pub/Subは重複を許容する
- スケーラブルなのが長所
- Dataflowが直接ストリームを取り込めるわけではない。Pub/Subをかます。
- ユーザが自分のログをダウンロードしたい → Pub/Subで非同期に。リンクだけ返して、処理が終わったらメールアドレスに送る
- timestampを自動で付与してくれる
- スケールさせるかの判断は、CPU使用率を監視する
- メッセージの順序指定が可能
- 30日間のデータ保持が可能
- debug用のを作っておくか
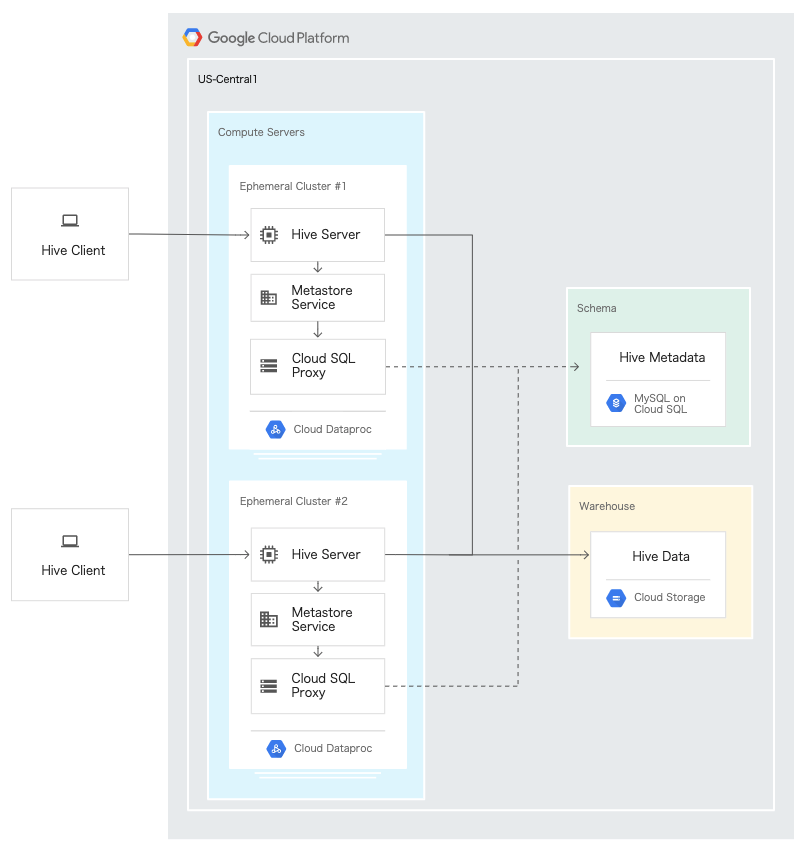
Dataproc
概要
- マネージドHadoop/Spark
構成図
$ gcloud dataproc jobs submit pyspark --cluster=my_cluster my_script.py -- --custom-flag
ポイント
- ストレージ費用を抑えるなら、ストレージをGCSに(HDFSの代わりに)。Pipeline間のデータの共有のためにも。
- プリエンプティブVMを活用する
- データが大きいなら、high memory machineを選択する
- ジョブが失敗したら自分でtempファイルは削除する
- セキュリティのためにSSH tunnel
- 停止時はdrainオプションを活用する
- I/Oに問題があるならローカルのHDFSストレージを使う
- parquetファイルが小さすぎると性能が出ない。1GB以上にする
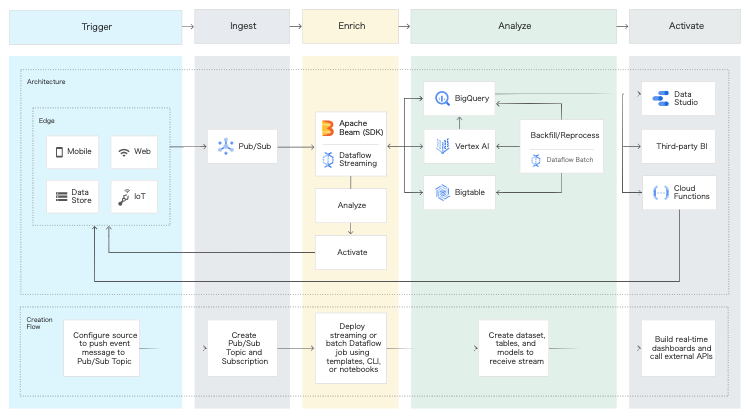
Dataflow
概要
- マネージドApache Beam
- サーバーレスかつ高速で、費用対効果の高い、統合されたストリーム データ処理とバッチデータ処理
構成図
wordcount.py
import apache_beam as beam
...
lines = p | beam.io.ReadFromPubSub(topic=known_args.input_topic)
...
counts = (lines
| 'split' >> (beam.ParDo(WordExtractingDoFn())
.with_output_types(six.text_type))
| 'pair_with_one' >> beam.Map(lambda x: (x, 1))
# FixedWindows
| beam.WindowInto(window.FixedWindows(15, 0))
| 'group' >> beam.GroupByKey()
| 'count' >> beam.Map(count_ones))
...
output = counts | 'format' >> beam.Map(format_result)
# Write to Pub/Sub
output | beam.io.WriteStringsToPubSub(known_args.output_topic)
$ python -m apache_beam.examples.wordcount \
--region DATAFLOW_REGION \
--input gs://dataflow-samples/shakespeare/kinglear.txt \
--output gs://STORAGE_BUCKET/results/outputs \
--runner DataflowRunner \
--project PROJECT_ID \
--temp_location gs://STORAGE_BUCKET/tmp/
ポイント
- テンプレートを活用する
- Pub/Subからデータを取得してBQのテーブルにストリーミングで格納
- GCSのファイルのデータを変更検知・新規検知しBQのテーブルにストリーミングで格納
- JDBCでデータベースのテーブルからBQへバッチで格納
- ウィンドウを生成する部分以外は、バッチ処理と違いがなかったりする
- Dataflow SQLもある
- タンブリングウィンドウ、ホッピングウィンドウ、セッションウィンドウ
- ページ毎のアクセス総数をユーザごとに集計。セッションは30分タイムアウト → ギャップ期間が30分間のセッションベースのウィンドウ
- ECサイトでユーザが60分操作しないとメッセージを送る → ギャップ期間が60分間のセッションベースのウィンドウ
- 30s間にどれだけの人がログインしたか → Sliding-time window
- ゲームでユーザごとのインタラクションを集計。最大15分の遅延 → セッションウィンドウ、最小15分のギャップ時間、プレイヤーIDをキー、メッセージバスはPub/Sub
- 用語
- PCollection: 分散処理対象のデータセットを表すオブジェクト
- Transform: 一般的な処理フレームワークを提供する。入力のPCollectionの各要素に適用する
[Output PCollection] = [Input PCollection] | [Transform]
- ParDo: extract certain fields
- オンプレHadoop/HDFS → Dataproc/GCS → Dataflow/BQ(Google推奨)
- BQとBigTableのどちらにも書き込みたい → PCollectionでデータをグループ化してからBigQueryIOとBigTableIO変換を使用するパイプラインを作成する
- データを受け取って、必要なデータストアへ書き込むという変換処理を適切に行うことができる
- スケジューリングするならCloud Sheduler
- csvのチェックをしたいとき、dataflowでチェック→OKだったらBQに、NGならGCSにdead-letterとして置いておく
- 性能のために、最大ワーカー数とインスタンスタイプを調整
- fromQueryで特定のフィールドを読み取る(スキャン量削減)
- ウォーターマーク。ウィンドウの全てのデータが必要になる閾値
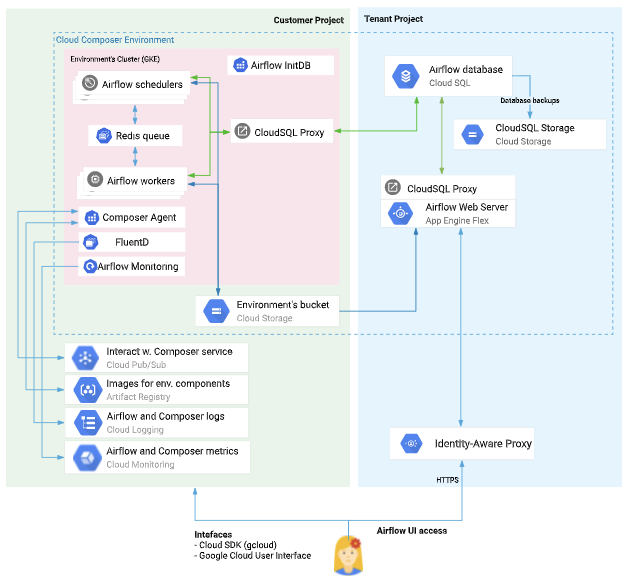
Composer
概要
- マネージドAirflow
- フルマネージドのワークフローオーケストレーションサービス
構成図
ポイント
- GCSのparquetをBQユーザが扱えるように。クエリ速度を最大化し、テーブルのパーティショニングとクラスタリングを構成したい → ComposerのOperatorである
GoogleCloudStorageToBigQueryOperatorを使用し、schema_objectにCloudStorageのschema.json、"source_format"に"PARQUET"を指定する - Airflowキュー→Celeryキュー→ワーカー。Celeryキューに入った時点でどのワーカーか決めているので、ワーカーが詰まると開始されない?
- バージョンアップの手順。Blue/Green, CIDRレンジ
- メンテナンスウィンドウが長いので注意
- 再起動(して設定反映)させるには、gcloudコマンドでなく、kubectlで環境変数を変更する?
- Cloud NATとのセカンダリIP重複に注意
- クォータに注意
- DAG数など
- -> クラスタを増やすことも検討しておく
- ローカル開発、ユーザごとに開発できるようにしておく
- poolを活用する。同時実行数の制御
- nodeあたりの同時実行数のチューニング。maxをautoで制御することも可能(worker_autoscale)
- Terraformで構築する際はnull resourceを活用
- ノードのスケール時間は要件に合うか確認しておく
- 想定通りスケールするか検証しておく
- snapshotの取得を検討する
- dbの改廃DAGを仕込む
- failer callbackで構造化ログ
- 再作成は履歴が消えるので注意する
- DAGも再配布?activateされないように注意する
- メトリクス確認
- キュー数(Airflow, celery)、アクティブワーカー数、DAGバッグサイズ(DAG数。上限あり)、合計解析時間、etc
- ワーカーごとのリソース使用率は、デフォルトのコンソールでは確認できない?
- podname airflow-worker-.*
- DAGごとのエラー監視が必要。どのDAGか分かるように。Tagは付与するようにする
- キュー詰まりはアラートを飛ばすか
- CloudLoggingに加えて、GCSにもログ出力をしている
- connectionとかをTerraformで作る場合どうするか。null resourceか
- メタデータが増え続けるので、改廃が必要。DAGを実行する
- 権限設計。ComposerとAirflowを分けて検討する
- バージョンアップ。ComposerとAirflowを分けて検討する
- メンテナンス通知の受け取り
- 待ち合わせDAGなどはTrigererを使うか
- リランをどうするか。mode=poke, reschedule
その他
ポイント
- コスト管理
- 財務チームは料金は確認できるがプロジェクトの確認ができないように → 請求アカウントの課金管理者に設定する。デベロッパーは普通にプロジェクトの閲覧者の役割に追加する
- Dataprep
- 分析と機械学習に使用するデータを視覚的に探索、クリーニング、準備できるインテリジェントなクラウドデータサービス。
- UIが提供されている
- スケジュール実行も可能