はじめに
この記事は、Apache Beam Documentation の内容をベースとしています。
Apache Beam Python SDK でバッチ処理が可能なプログラムを実装し、Cloud Dataflow で実行する手順や方法をまとめています。また、Apache Beam の基本概念、テストや設計などについても少し触れています。

Apache Beam SDK 入門
Apache Beam SDK は、Java, Python, Go の中から選択することができ、以下のような分散処理の仕組みを単純化する機能を提供しています。
- **Pipeline:**処理タスク全体(パイプライン)をカプセル化します。処理タスクには、入力データの読み取り、変換処理、および出力データの書き込み等が含まれます。
- **PCollection:**分散処理対象のデータセットを表すオブジェクトです。通常は、外部のデータソースからデータを読み取り、PCollection を作成しますが、インメモリから作成することも可能です。
- **Transform:**データ変換処理の機能を提供します。すべての Transform は、1つ以上の PCollection を入力として受け取り、その PCollection の要素に対して何らかの処理を実行して、0個以上の PCollection を出力します。
- **I/O Transform:**様々な外部ストレージシステム(GCS や BigQuery など)に対してデータの読み書きができる機能(Read/Write Transform)を提供しています。
Apache Beam 実行環境
Apache Beam SDK によって作成されたプログラムは、以下のような分散データ処理システム上で実行することができます。Apache Beam では、この実行環境のことをランナーと呼んでいます。
- DirectRunner: ローカルマシン上(テストを行う際などに使う)
- SparkRunner: Apache Spark
- DataflowRunner: Google Cloud Dataflow
- その他はこちらを参照
今回は、DirectRunner と DataflowRunner の2つの実行環境で動かします。
パイプラインの実装
一般的な(単純な)Apache Beam のプログラムは以下のように作成・動作します。
- Pipeline オブジェクトを作成し、実行オプションを設定します。
- Read Transform を使用して外部ストレージシステムまたはインメモリからデータを読み込み、 PCollectionを作成します。
- PCollection に Transform を適用します。Transform は、PCollection 内の要素を様々なロジックで変換処理することが可能です。
- Write Transform を適用して、Transform によって変換された PCollection を外部ソースに書き込みます。
この処理フローの場合、以下のような単純なパイプラインになります。

上記のような単純なパイプラインを実際に Python で実装してみます。動作環境は以下を想定しています。
- Python バージョン:2系で 2.7 以上 または 3系で 3.5 以上
- Apache Beam バージョン: 2.15.*
Apache Beam SDK のインストール
追加パッケージを特に必要としない場合は、次のコマンドでインストールします。
pip install apache-beam
今回は、Dataflow(GCP) 上で実行することを想定しているため、GCPの追加パッケージもインストールしておきます。
pip install apache-beam[gcp]
完成コード
こちらは完成形のコードになります。以下で各々について説明していきます。
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.options.pipeline_options import StandardOptions
class MyOptions(PipelineOptions):
"""カスタムオプション."""
@classmethod
def _add_argparse_args(cls, parser):
parser.add_argument(
'--input',
default='./input.txt',
help='Input path for the pipeline')
parser.add_argument(
'--output',
default='./output.txt',
help='Output path for the pipeline')
class ComputeWordLength(beam.DoFn):
"""文字数を求める変換処理."""
def __init__(self):
pass
def process(self, element):
yield len(element)
def run():
options = MyOptions()
# options.view_as(StandardOptions).runner = 'DirectRunner'
p = beam.Pipeline(options=options)
(p
| 'ReadFromText' >> beam.io.ReadFromText(options.input) # I/O Transform を適用して、オプションで指定したパスにデータを読み込む
| 'ComputeWordLength' >> beam.ParDo(ComputeWordLength()) # Transform を適用
| 'WriteToText' >> beam.io.WriteToText(options.output)) # I/O Transformを適用して、オプションで指定したパスにデータを書き込む
p.run()
if __name__ == '__main__':
run()
Pipeline
Pipeline オブジェクトは、データ処理タスクのすべてをカプセル化します。Apache Beam のプログラムは通常、PCollection の作成と Transform の適用のために、まずは Pipeline オブジェクトを作成します。
Pipeline の作成
Apache Beam のプログラムを使用するには、最初に Apache Beam SDK の Pipeline のインスタンスを(通常 main 関数内に)作成する必要があります。そして、Pipeline を作成するときには実行オプションを設定します。
次のコードは、Pipeline のインスタンスを作成する例です。
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
options = PipelineOptions() # 実行オプション
p = beam.Pipeline(options=options)
PipelineOptions の設定
PipelineOptions を使用して、パイプラインを実行するランナーや、選択したランナーに必要な固有のオプションを設定することができます。例として、プロジェクトIDやファイルの格納場所などの情報が含まれる可能性があります。
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.options.pipeline_options import StandardOptions
options = PipelineOptions()
options.view_as(StandardOptions).runner = 'DirectRunner' # ランナーの指定
p = beam.Pipeline(options=options)
オプションは、プログラム上で設定する方法と、コマンドライン引数から渡す方法の2通りがあります。後述の Cloud Dataflow で実行 でその例を記述しています。
カスタムオプションの追加
標準の PipelineOptions に加えてカスタムオプションを追加できます。次の例では、入力先と出力先のパスを指定するオプションを追加しています。カスタムオプションでは、ユーザーがコマンドライン引数から --help を渡したときに表示される説明やデフォルト値を指定することもできます。
PipelineOptions を継承することで、カスタムオプションを作成することができます。
class MyOptions(PipelineOptions):
"""カスタムオプション."""
@classmethod
def _add_argparse_args(cls, parser):
parser.add_argument(
'--input', # オプション名
default='./input.txt', # デフォルト値
help='Input path for the pipeline') # 説明
parser.add_argument(
'--output',
default='./output.txt',
help='Output path for the pipeline')
作成したオプションは次のように渡します。
p = beam.Pipeline(options=MyOptions())
カスタムオプションにデフォルト値以外の値を設定するには、コマンドライン引数から次のように値を渡します。
--input=value --output=value
PCollection
PCollection は、分散処理対象のデータセットを表すオブジェクトです。Apache Beam のパイプラインで、Transform は入力と出力として PCollection を使用します。そのため、パイプラインでデータを処理したい場合は、PCollection を作成する必要があります。
Pipeline オブジェクトを作成したら、まず何らかの形で少なくとも1つの PCollection を作成する必要があります。
PCollection の作成
I/O Transform を使用して外部ソースからデータを読み取るか、インメモリから PCollection を作成します。後者は主にテストやデバッグする際に役立ちます。
外部ソースから PCollection を作成
外部ソースから PCollection を作成するには、I/O Transform を使用します。データを読み取るためには、各 I/O Transform が提供する Read Transform を Pipeline オブジェクトに適用します。
PCollection を作成するために Read Transform を Pipeline に適用する方法は次のとおりです。
lines = p | 'ReadFromText' >> beam.io.ReadFromText('gs://some/input-data.txt')
インメモリから PCollection を作成
インメモリから PCollection を作成するには、Create Transform を使用します。
lines = (p | 'ReadFromInMemory' >> beam.Create(['To be, or not to be: that is the question: ', 'Whether \'tis nobler in the mind to suffer ', 'The slings and arrows of outrageous fortune, ', 'Or to take arms against a sea of troubles, ']))
Transform
Transformは、一般的な処理フレームワークを提供します。Transform は、入力の PCollection の各要素に適用されます。
Apache Beam SDK は、PCollection に適用できる様々な Transform を提供しています。これには、ParDo や Combine などの汎用な Core transforms や、1つ以上の Core transforms を組み合わせた Composite transforms が含まれます。様々な Transform が提供されていますので、こちらなどを参照してみてください。
Transform の適用
Apache Beam SDK の各 Transform には、パイプ演算子 | が提供されているので、そのメソッドを入力のPCollection に適用することで Transform を適用することができます。
[Output PCollection] = [Input PCollection] | [Transform]
次のように Transform を連鎖してパイプラインを作成することもできます。
[Output PCollection] = ([Initial Input PCollection]
| [First Transform]
| [Second Transform]
| [Third Transform])
このパイプラインは、今回の実装例と同じフローなので、このような形状のパイプラインになります。
Transform は、入力の PCollection には変更を加えずに、新しい PCollection を作成します。Transform によって入力の PCollection に変更が加わることはありません。 PCollection は定義上不変です。そのため、同じ PCollection に複数の Transform を適用して PCollection を分岐させることもできます。
[Output PCollection] = [Initial Input PCollection]
[Output PCollection A] = [Output PCollection] | [Transform A]
[Output PCollection B] = [Output PCollection] | [Transform B]
このパイプラインの形状は、次のようになります。
I/O Transform
パイプラインを作成するときは、多くの場合、ファイルやデータベースなどの外部ソースからデータを読み取る必要があります。同様に、パイプラインからデータを外部ストレージシステムに出力することもできます。
Apache Beam SDKは、一般的なデータストレージタイプに対して I/O Transform を提供しています。サポートされていないデータストレージの読み書きを行いたい場合は、独自の I/O Transform を実装する必要があります。
データの読み込み
Read Transform は、外部ソースからの読み取りデータを PCollection に変換します。パイプラインを構築している間はいつでも Read Transform を使用できますが、一般的には最初に実行します。
lines = pipeline | beam.io.ReadFromText('gs://some/input-data.txt')
データの書き込み
Write Transform は、PCollection 内のデータを外部データソースに書き込みます。パイプラインの結果を出力するには、ほとんどの場合、パイプラインの最後で Write Transform を使用します。
output | beam.io.WriteToText('gs://some/output-data')
複数ファイルからの読み込み
多くの Read Transform は、glob 演算子にマッチする複数の入力ファイルからの読み込みをサポートしています。 次の例では、glob 演算子 (*) を使用して、指定された場所に接頭辞「input-」と接尾辞「.csv」があるすべての一致する入力ファイルを読み取ります。
lines = p | 'ReadFromText' >> beam.io.ReadFromText('path/to/input-*.csv')
複数ファイルへの書き込み
Write Transform はデフォルトで複数のファイルに書き込みます。その際、ファイル名(第1引数のパスの最下位層)がすべての出力ファイルの接頭辞として使用され、接頭辞の後に -00000-of-00001 といった文字列が付与されます。
次の例では、複数ファイルを1つのロケーションに書き込みます。各ファイルには、接頭辞「numbers」、および接尾辞「.csv」が付与されます。
output | 'WriteToText' >> beam.io.WriteToText('/path/to/numbers', file_name_suffix='.csv')
パイプラインの実行
それでは、完成コードを使用してパイプラインを実行してみます。実行環境として、ローカルと Cloud Dataflow それぞれで実行します。
入力には次のような文字列が含まれるテキストファイルを用意します。
good morning.
good afternoon.
good evening.
ローカルで実行
ローカルでパイプラインを実行するには、PipelineOptions にランナーとして DirectRunner を設定しますが、特に細かい設定がない限りは、ランナーを明示的に指定する必要はありません。
次のコマンドをコマンドラインから実行します。入力先と出力先のパスは環境によって書き換えてください。
python pipeline.py --input=./input.txt --output=./output.txt
今回の実装例は、単語の文字数を数えるパイプラインですので、次のような結果が出力されます。
また、beam.io.WriteToText では複数のファイルに分散して書き込みを行います。1つのファイルに書き込みたい場合は、 shard_name_template 引数を空にすることで可能です。
13
15
13
Cloud Dataflow で実行
Cloud Dataflow は、GCP (Google Cloud Platfom) で提供されている、ストリームモードまたはバッチモードでデータ処理を行うフルマネージドサービスです。利用者はサーバなどインフラの運用を気にすることなく、実質無制限の容量を従量課金制で使用して、膨大な量のデータ処理を行うことができます。
Cloud Dataflow でパイプラインを実行すると、GCP プロジェクトで Compute Engine リソースと Cloud Storage リソースを使用するジョブが作成されます。Cloud Dataflow を利用するには、GCP で Dataflow API をオンにしてください。
Cloud Dataflow で 完成コード を実行するには少し修正が必要です。主に GCP の設定(プロジェクトID の指定など)やランナーの変更が必要です。次のように修正します。
import apache_beam as beam
from apache_beam.options.pipeline_options import GoogleCloudOptions
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.options.pipeline_options import StandardOptions
from apache_beam.options.pipeline_options import WorkerOptions
GCP_PROJECT_ID = 'my-project-id'
GCS_BUCKET_NAME = 'gs://my-bucket-name'
JOB_NAME = 'compute-word-length'
class MyOptions(PipelineOptions):
"""カスタムオプション."""
@classmethod
def _add_argparse_args(cls, parser):
parser.add_argument(
'--input',
default='{}/input.txt'.format(GCS_BUCKET_NAME), # GCS に input.txt を置く
help='Input for the pipeline')
parser.add_argument(
'--output',
default='{}/output.txt'.format(GCS_BUCKET_NAME), # GCS に出力する
help='Output for the pipeline')
class ComputeWordLength(beam.DoFn):
"""文字数を求める変換処理."""
def __init__(self):
pass
def process(self, element):
yield len(element)
def run():
options = MyOptions()
# GCP オプション
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = GCP_PROJECT_ID # プロジェクトID
google_cloud_options.job_name = JOB_NAME # 任意のジョブ名
google_cloud_options.staging_location = '{}/binaries'.format(GCS_BUCKET_NAME) # ファイルをステージングするための GCS パス
google_cloud_options.temp_location = '{}/temp'.format(GCS_BUCKET_NAME) # 一時ファイルの GCS パス
# ワーカーオプション
options.view_as(WorkerOptions).autoscaling_algorithm = 'THROUGHPUT_BASED' # 自動スケーリングを有効化する
# 標準オプション
options.view_as(StandardOptions).runner = 'DataflowRunner' # Dataflow ランナーを指定
p = beam.Pipeline(options=options)
(p
| 'ReadFromText' >> beam.io.ReadFromText(options.input)
| 'ComputeWordLength' >> beam.ParDo(ComputeWordLength())
| 'WriteToText' >> beam.io.WriteToText(options.output, shard_name_template=""))
p.run()
# p.run().wait_until_finish() # パイプラインの完了までブロックする
if __name__ == '__main__':
run()
そのほかの Dataflow のオプションについてはこちらを参照してください。
ストリーミング実行するには、 streaming オプションを true にする必要があります。
こちらも、同様のコマンドで実行できます。
python pipeline.py --input=gs://my-project-id/input.txt --output=gs://my-project-id/output.txt
プログラム上で設定してあるオプションは、このようにコマンドライン引数から渡すことも可能です。
python pipeline.py \
--input=gs://my-project-id/input.txt \
--output=gs://my-project-id/output.txt \
--runner=DataflowRunner \
--project=my-project-id \
--temp_location=gs://my-project-id/tmp/
...
GCP から Dataflow サービスにアクセスするとパイプラインをモニタリングできます。UI はこのようになり、指定したパスに結果が出力されます。

こうした Dataflow のバッチ処理を定期実行したい場合などは、Dataflow テンプレートを利用すると便利です。詳しくは、こちらを参照してみてください。
パイプラインのテスト
パイプラインをテストする際、多くの場合では、Dataflow などのリモート実行をデバッグするよりも、ローカルで単体テストする方がデバッグにかかる時間と労力を大幅に節約できます。
依存関係の解決のために以下をインストールする必要があります。
pip install nose
実装例
パイプラインをテストするには、 TestPipeline オブジェクトを用います。入力は外部ソースから読み取る代わりに、apache_beam.Create を用いてインメモリから PCollection を作成します。出力結果を assert_that で比較します。
from unittest import TestCase
import apache_beam as beam
from apache_beam.testing.test_pipeline import TestPipeline
from apache_beam.testing.util import assert_that, equal_to
from src.pipeline import ComputeWordLength
class PipelineTest(TestCase):
def test_pipeline(self):
expected = [
13,
15,
13
]
inputs = [
'good morning.',
'good afternoon.',
'good evening.'
]
with TestPipeline() as p:
actual = (p
| beam.Create(inputs)
| beam.ParDo(ComputeWordLength()))
assert_that(actual, equal_to(expected))
パイプラインの設計
上記で、既にシンプルなパイプラインと、分岐するパイプラインを作成する場合の設計(処理フロー)について簡単に説明しました。ここでは、その他の一般的なパイプラインの設計について紹介します。
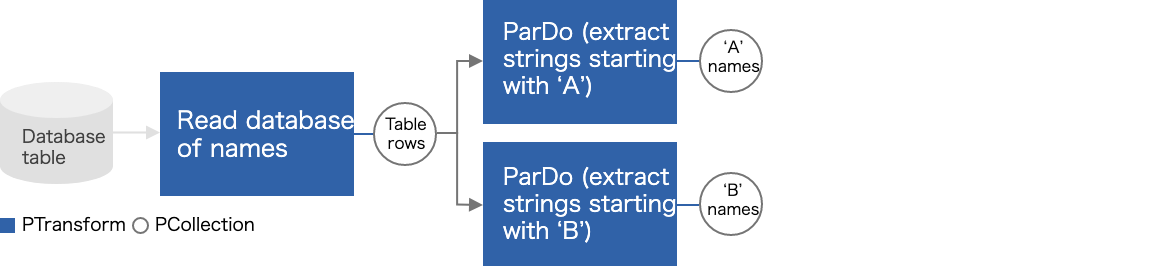
複数の PCollection を生成する Transform を持つパイプライン

Apache Beam の Additional outputs という機能を使って実現できます。
class ExtractWord(beam.DoFn):
def process(element):
if element.startswith('A'):
yield pvalue.TaggedOutput('a', element) # タグ名をつける(先頭が'A'の要素だったら'a')
elif element.startswith('B'):
yield pvalue.TaggedOutput('b', element) # タグ名をつける(先頭が'B'の要素だったら'b')
mixed_col = db_row_col | beam.ParDo(ExtractWord()).with_outputs()
mixed_col.a | beam.ParDo(...) # .タグ名でアクセスできる
mixed_col.b | beam.ParDo(...)
PCollection を結合する Transform を持つパイプライン
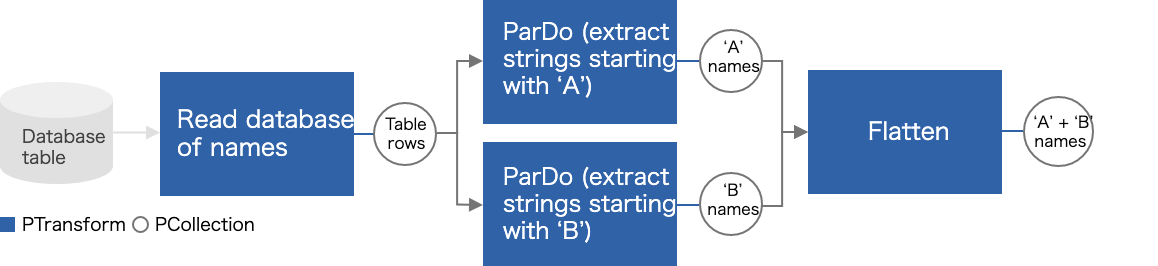
Flatten を用いることで実現できます。
col_list = (a_col, b_col) | beam.Flatten()
複数の入力ソースを持つパイプライン
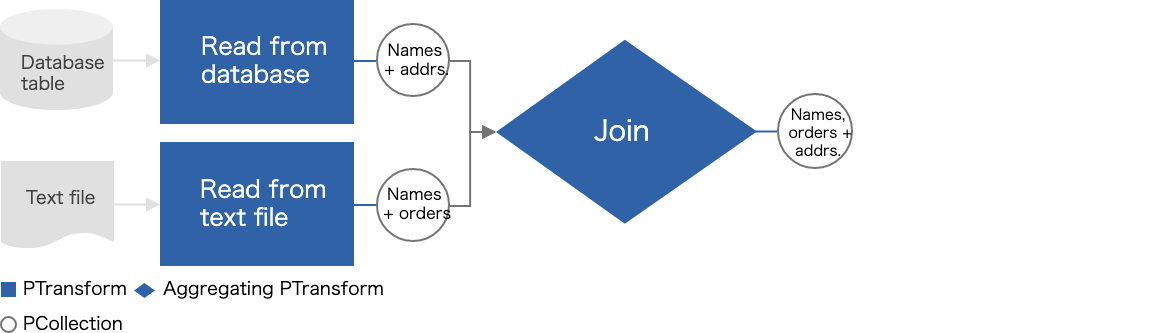
それぞれの入力ソースから PCollection を作成し、 CoGroupByKey などで共通のキーを使って Join することができます。
user_address = p | beam.io.ReadFromText(...)
user_order = p | beam.io.ReadFromText(...)
joined_col = (user_address, user_order) | beam.CoGroupByKey()
joined_col | beam.ParDo(...)
その他の便利機能
様々なユースケースに対応できるように、次のような機能も知っておくと良いかもしれません。
Composite transforms
Composite transforms は、複数の Transform (ParDo, Combine, GroupByKey...) を組み合わせたものです。複数の Transform を入れ子構造にすることで、コードがよりモジュール化されて理解しやすくなります。
実装例
Composite transforms を実装するには、Transform クラスを継承し、expand メソッドをオーバーライドする必要があります。
"""文章の単語数を数えるパイプライン."""
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
class ComputeWordCount(beam.PTransform):
"""単語数を数える Composite transforms."""
def __init__(self):
pass
def expand(self, pcoll):
return (pcoll
| 'SplitWithHalfSpace' >> beam.Map(lambda element: element.split(' '))
| 'ComputeArraySize' >> beam.Map(lambda element: len(element)))
def run():
p = beam.Pipeline(options=PipelineOptions())
inputs = ['There is no time like the present.', 'Time is money.']
(p
| 'CreateWord' >> beam.Create(inputs)
| 'ComputeWordCount' >> ComputeWordCount()
| 'WriteToText' >> beam.io.WriteToText('出力先のパス'))
p.run()
if __name__ == '__main__':
run()
7
3
Side inputs
Side inputs は、通常の入力(主入力)の PCollection に加えて、追加の入力(副入力)を Transform に渡すことができる機能です。
実装例
"""平均以上の文字数を持つ文字列のみを出力するパイプライン."""
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam import pvalue
class FilterMeanLengthFn(beam.DoFn):
"""平均以上の文字数を持つ文字列をフィルタリングする."""
def __init__(self):
pass
# mean_word_length は副入力
def process(self, element, mean_word_length):
if len(element) >= mean_word_length:
yield element
def run():
p = beam.Pipeline(options=PipelineOptions())
inputs = ['good morning.', 'good afternoon.', 'good evening.']
# 副入力
mean_word_length = (p
| 'CreateWordLength' >> beam.Create([len(s) for s in inputs])
| 'ComputeMeanWordLength' >> beam.CombineGlobally(beam.combiners.MeanCombineFn()))
# 主入力
output = (p
| 'CreateWord' >> beam.Create(inputs)
| 'FilterMeanLength' >> beam.ParDo(FilterMeanLengthFn(), pvalue.AsSingleton(mean_word_length)) # ParDo の第2引数に副入力を挿入する
| 'WriteToText' >> beam.io.WriteToText('出力先のパス'))
p.run().wait_until_finish()
if __name__ == '__main__':
run()
「good morning.」, 「good afternoon.」, 「good evening.」の文字数はそれぞれ「13」, 「15」, 「13」で、その平均は13.67ほどなので、次のような出力になります。
good afternoon.
パイプラインの中で何が起きているか?
「パイプラインの中で何が起きているか」について少し記述しています。
シリアライズと通信
パイプラインの分散処理において最もコストの高い操作の1つは、マシン間で要素をシリアライズして通信を行うことです。Apache Beam のランナーは、マシン間で通信を行うなどの理由で PCollection の要素をシリアライズします。次のような手法を用いて、Transform と次のステップの Transform との間で要素の通信を行います。
- 要素をシリアライズしてワーカーにルーティングする
- 要素をシリアライズして複数のワーカーに再分配する
- Side inputs を使用する場合は、 要素をシリアライズしてすべてのワーカーにブロードキャストする必要がある
- Transform と次のステップの Transform が同じワーカーで実行されている場合は、要素の通信をインメモリを使って行う(シリアライズしないことで通信コストを下げることができる)
同梱と永続化
Apache Beam は、Embarassingly parallel 問題に焦点を当てています。Apache Beam は、要素を並列で処理することを重要視しているので、PCollection の各要素にシーケンス番号を割り当てるなどの動作を表現するのが苦手です。このようなアルゴリズムはスケーラビリティの問題を抱える可能性がはるかに高いためです。
すべての要素を並列に処理することにもいくつかの欠点があります。例えば、要素を出力先に書き込む場合です。出力処理において、すべての要素を並列にバッチ処理することは不可能です。
そのため、Apache Beam のランナーは、すべての要素を同時に処理するのではなく、PCollection の要素を同梱して処理します。ストリーミング処理の場合は、小さな単位で同梱して処理する傾向があり、バッチ処理の場合は、より大きな単位で同梱して処理する傾向があります。
並列処理
Transform 内の並列処理
単一の ParDo を実行する場合、Apache Beam のランナーは、PCollection の要素を2つに分割・同梱(Bundle)することがあります。
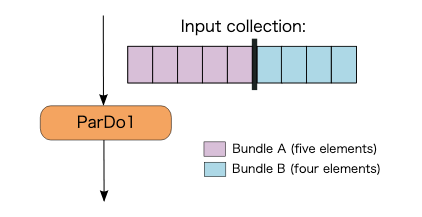
ParDoが実行されると、ワーカーは、次に示すように2つのBundleを並列で処理します。
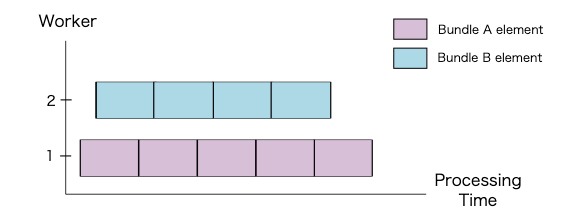
単一の要素は分割できないため、Transform の最大並列処理は PCollection の要素数によって異なります。今回の場合の最大並列処理数は図から見て 9 です。
※ 単一の要素を複数の Bundle に分割できる機能(Splittable ParDo)が開発中らしい
Transform 間の並列処理
ParDo は従属並列になることがあります。例えば、次のように ParDo1 の出力を同じワーカーで処理する必要がある場合、ParDo1 と ParDo2 は従属並列になります。
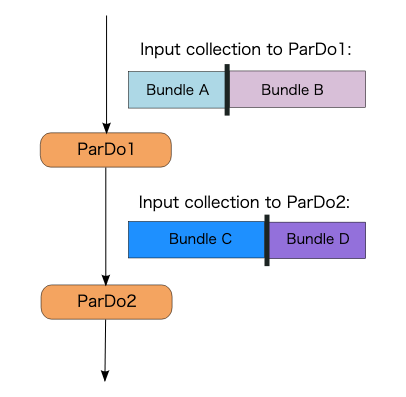
Worker1 では、Bundle A の要素に対して ParDo1 が実行され、Bundle C になります。次に、Bundle C の要素に対して ParDo2 が実行されます。同様に、Worker2 では、Bundle B の要素に対して ParDo1 が実行され、Bundle D になります。そして、Bundle D の要素に対して ParDo2 が実行されます。
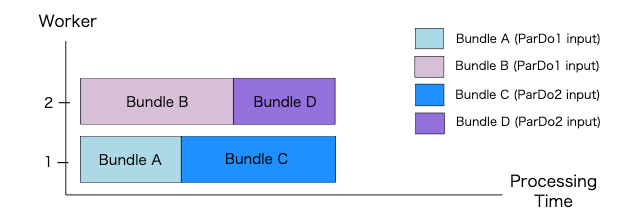
このように ParDo を実行することで、Apache Beam のランナーは、ワーカー間で要素を再配布することを回避できます。そして、これにより通信コストを節約できます。ただし、最大並列処理数は、従属並列の最初の ParDo の最大並列処理数に依存するようになります。
障害発生時の挙動
Transform 内の障害発生時の挙動
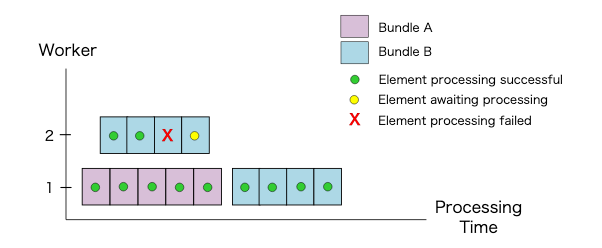
Bundle 内の要素に対する処理が失敗すると Bundle 全体が失敗してしまいます。そのため、処理を再試行する必要があります(そうしないとパイプライン全体が失敗します)。
次の例では、Worker1 が Bundle A の5つの要素すべてを正常に処理します。Worker2 は Bundle B の4つの要素を処理しますが、Bundle B の最初の2つの要素は正常に処理され、3番目の要素は処理が失敗します。
その後、Apache Beam のランナーが Bundle B のすべての要素を再試行し、2回目で処理が正常に完了しています。図のように、再試行は必ずしも元の処理の試行と同じ Worker で発生するわけではありません。
Transform 間の障害発生時の挙動
ParDo1 の処理後、ParDo2 内の要素を処理できなかった場合、これら2つの Transform は同時に失敗したことになります。
次の例では、Worker2 は Bundle B のすべての要素に対して ParDo1 を正常に実行します。しかし、Bundle D の要素を処理できないため、ParDo2 は失敗します。
その結果、Apache Beam のランナーは ParDo2 の出力を破棄して再び処理を実行する必要があります。その際には、ParDo1 の Bundle も破棄されなければならず、Bundle のすべての要素は再試行されなければいけません。

まとめ
Apache Beam Documentation の内容をもとに学習した内容をまとめてみました。
間違っている点などあればご指摘ください! ![]()