はじめに
機械学習PJにてCICDパイプラインを組むときに考えたら良いのではないかと思われることを書いていきます。
実際に組んでみる際に考えたこと、組んだことを振り返って思うことを書いていきます。
CI/CDとは
CIはContinuous Integrationの略で、CDはContinuous Deliveryの略です。
CIは、コードがセントラルリポジトリにマージされる度にビルドやテストなどが自動で実行されること、
CDは、ソフトウェアのリリースプロセス全体の自動化のことを言います。(雑に言うと)
なぜCI/CDを導入したかったのか
ビルド→テスト→デプロイといった、モデル・アプリの本番運用に必要なプロセスを自動化することで、プロダクトアップデートのためのSpeed・Reliability・Accuracyを向上したかったからです。
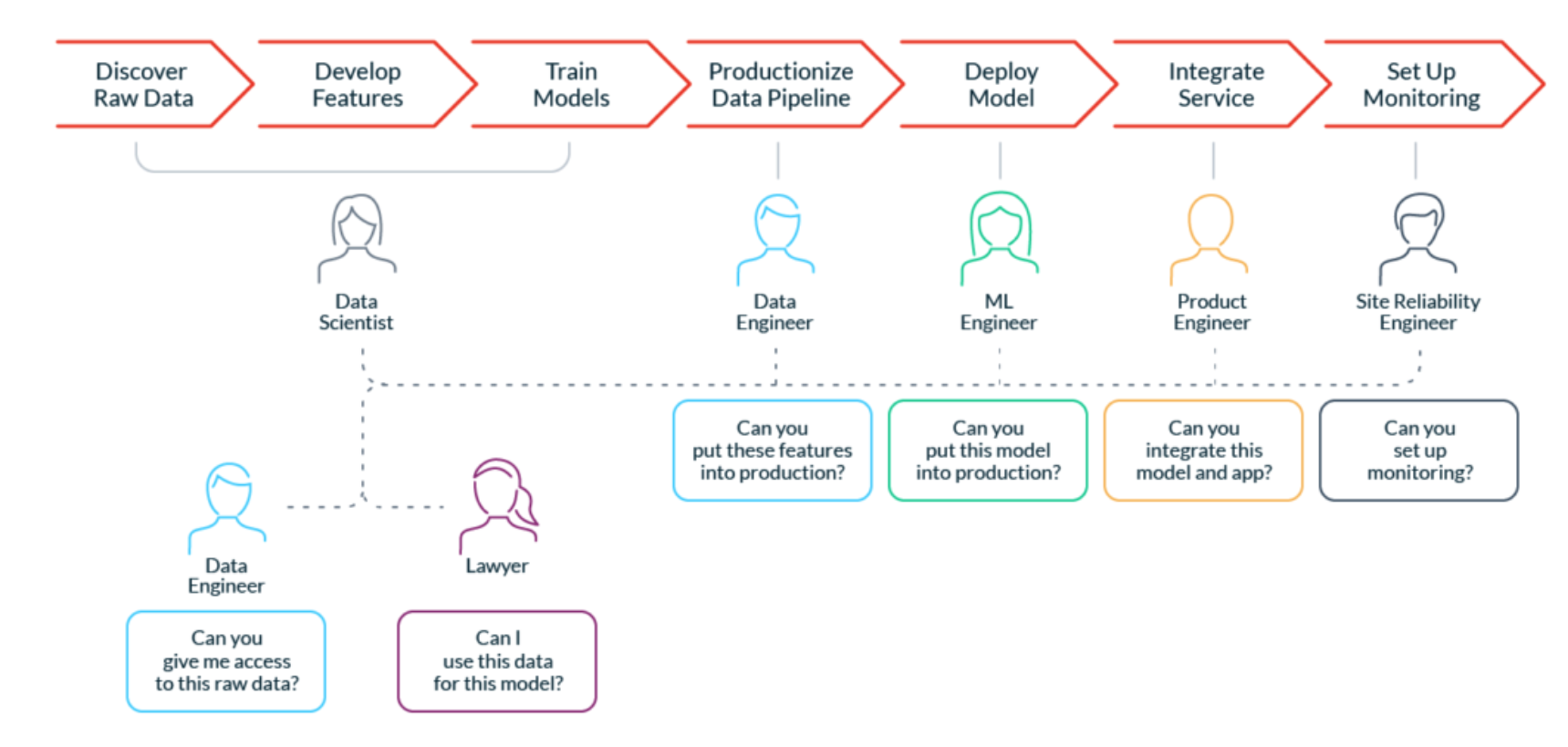
Why We Need DevOps for ML Dataから引用
- Speed
- ビルド→テスト→デプロイといった様々な作業をクイックに実行することができます。
- 並列実行などスケールもしやすくなります。また、再利用性も高いです。
- 特に、モデルの学習には、数時間~数日、数週間かかる場合もあります。
- Reliability
- ブランチの動作・精度を担保できます。
- ex. 「PoC案件に引き継ぎで入ったが、masterブランチが動作しない or 精度が聞いていたのと異なる」というようなことがありました。
- = ローカルでは動いていたようだが、綺麗な環境にcloneしてエンドツーエンドで実行して見ると、動かない or 精度が聞いていたのと異なることがありました。
- ローカルにのみあるデータに依存していたり
- 暗黙的にノートブックの実行順序が決まっていたり
- また、レビュー時に、ソースだけでなく、データとハイパーパラメータ、推論結果についても断面を揃え(バージョンコントロール)、再現性を担保した上で確認する必要があります。
- ブランチの動作・精度を担保できます。
- Accuracy
- 自動化することで、一連の作業を正確に実施することができます。
前提
スコープの前提
機械学習PJにおいて必要なパイプラインの全体像としては下記が分かりやすいですが、今回のスコープとしてはその内CI/CDとして、ビルド→テスト→デプロイの一部にフォーカスします。
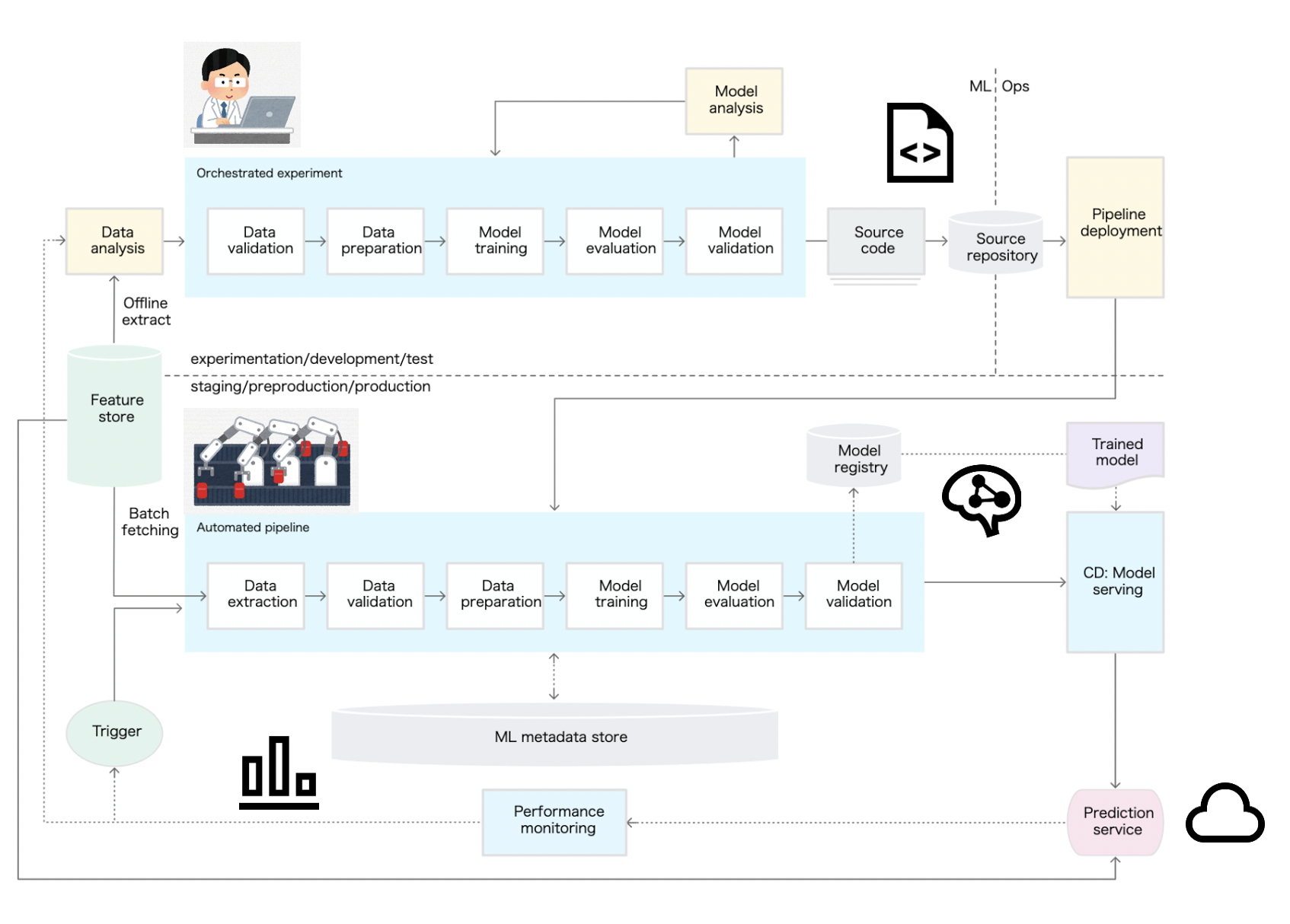
MLOps: 機械学習における継続的デリバリーと自動化のパイプラインから引用して追記
システムの前提
- 今回の対象としては、機械学習モデル開発に対するCIと、API開発に対するCI/CDとしています。
- どちらも、Python・Dockerで開発しています。
- モデル学習はGPUを利用します。
- 推論はGPUを利用しない + モデルはAPIコンテナに同梱しています。(意外と多い?)
- 自チームの既存の環境は積極的に採用します。
- GitLab, オンプレKubernetesGPUクラスタ(学習基盤), AWS
- 構成検討における観点としては、下記3点とします。
- 「課題・ポイント(下記参照)に対応できていること」
- 「構築後の運用作業の手間がかからないこと」
- 「インフラランニングコストが低いこと」
構成検討
MLシステム独自の検討事項
従来のWebアプリケーションでの検討ポイントに加え、MLシステムでは下記を考慮する必要があります。
- Data
- コードだけでなくデータ(とハイパーパラメータ)がインプットになっていくことが、最大の違いです。
- データオーケストレーション、クリーニング、バージョン管理などが必要になってきます。
- データをどう取得・加工して来たかを、後から問われることになります。
- Accelerators
- CPUだけでなく、GPUや、エッジなどでは特殊なアクセラレータを利用することになります。
- Training Step
- 何時間、何日とかかる場合もあるので、分散処理が大事になってきます。
- Refitting / Online
- ドリフトの検知、モデルの再学習が必要になる場合があります。
- =従来のWebアプリケーションと違い、パイプラインが一方向とは限りません。
- (今回は検討の対象外としています)
- 再学習は、コストと鮮度のトレードオフを考慮する必要があります。
今回の整理

構成図
今回は、GitLab + GitLabRunner on Kubernetes + ECSで構築しました。
データはS3に、コンテナイメージはECRに配置し、ECSへのデプロイにはecspressoを利用しました。
構築手順については、別記事にまとめ中です。
・GitLabRunnerのKubernetesExecutorを試してみた
・ecspressoによるECSデプロイを試してみた

ポイント
上記の構成を組んでみる際に考えたこと、および、組んで見た結果を振り返って思うことを書いていきます。
(もちろんケースバイケース)
Code
- ブランチフローを早めに検討しましょう。
- ブランチごとに、何のテストをするか、キャッシュはどうするか、どこにデプロイするか。
- GitLab flowなどをベースに。
- ノートブックだとdiff確認、lintなどが辛いので、極力スクリプトにしましょう。
- 現実的な落とし所(DSとDEの)として、ノートブックの併用もいいが、最終的には(レビュー、他者への共有、CIにかける時には)、ロジックはスクリプトに書いてノートブックからは呼び出すだけにする、など。
- 画像を出力したいなどでノートブックを使う場合、papermillやcommuterを上手く使うと良いです。
- コードだけでなく、データ・モデルのバージョン管理も検討しましょう。
- DVC等のデータバージョン管理サービスもありますが、フローが複雑になりやすいので、S3のディレクトリ分け+メタデータ(ディレクトリパス)だけで管理していくのも場合によっては選択肢に挙がるかと思います。
Build
- コンテナイメージのキャッシュを考慮しましょう。
- イメージのlatest運用はしないようにしましょう。
- モデル・データのサイズを考慮しましょう。
- EFS、EBSを併用するなど
- または、Feature Storeを併用するなど
Test
- 精度確認のためのテストデータは固定しましょう。
- 変更した場合はきちんと管理しましょう。
- 実験管理のためにMLflow等のツールと連携させましょう。
- テスト済みイメージを使い回すフローにしましょう。(stg→prod)
- Dockerfileもlintをかけましょう。
Deploy
- デプロイフローの中で承認や保留、手動実行(手動でキック)した方が良い箇所がないか事前に検討しましょう。
- 過去分含めた結果確認、過去断面への切り戻し方法を事前に検討しましょう。
- A/Bテストが必要になりがちなので検討しましょう。
Monitor
- 従来の監視項目に加え、モデルの監視もしましょう。
- レイテンシや精度、INput/Outputのデータ分布など。
- ドリフトの検知ができるようにしましょう。
その他
- MLパイプライン
- 開発と本番のパイプラインのコードは同じにしましょう。
- →それには、それなりの工数がかかることを覚悟しましょう。
- Pythonのスクリプトを単にシェルでラップするのではなく、Kedroなどのツールを用いましょう。
- 開発と本番のパイプラインのコードは同じにしましょう。
- 人
- パイプラインを組むことで、データサイエンティストが全体を意識しやすくなる、という副次的メリットもあります。
- エンドツーエンドの処理フロー、パフォーマンスや信頼性など
- 本番運用開始後の精度に誰が責任を持つか、は予めきちんと決めておきましょう。
- パイプラインを組むことで、データサイエンティストが全体を意識しやすくなる、という副次的メリットもあります。
感想
今回のように最低限のCI/CDを組むだけでも、プロダクトアップデートがSpeed・Reliability・Accuracyの観点でかなり改善されました。
次は、MLパイプライン(Kedroなど)や実験管理(MLflow)を有機的に組み合わせていきたいです。