第6感をAIで可視化できないか?という試みの 第2弾です。
全体のお話はこちら
人工知能(機械学習)で、第6感の可視化に挑戦
はじめに
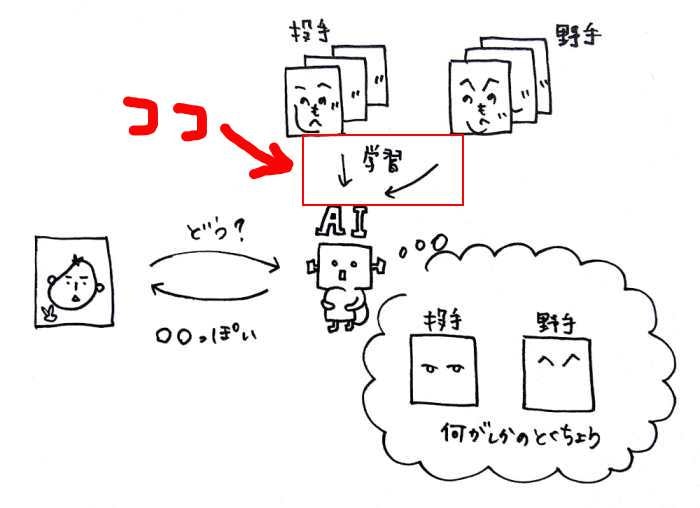
今回の範囲はこちらになります。
AIに選手の画像(投手と野手)を学習させることが今回のゴールです。
AI(機械学習)
機械学習には様々な種類がありましが、今回はDeepLearningを使います。
利用するライブラリはkeras(特に理由なし。試してみたかったから)
また、学習データが少なくて済むというFine-tuningを使ってみます。
kerasとは
公式ドキュメントによると、
Kerasは,Pythonで書かれた,TensorFlowまたはCNTK,Theano上で実行可能な高水準のニューラルネットワークライブラリです.
ということです。
下記サイトの中ほどにある記述によると、程よいバランスで人気らしいです。
Fine-tuningとは
Fine-tuningとは既存の学習モデルを流用する学習方法で、
少量のデータでニューラルネットの重みを再調整することをFine-tuningという
VGG16のFine-tuningによる犬猫認識 (1)
ということらしいです。さらに、
Deep Learningの画像応用において代表的なモデルであるVGG16
ということで、VGG16を使ってみたいと思います。
Fine-tuning、VGG16に関して、下記サイトが大変参考になりました。
- KerasでVGG16を使う
- Deep learningで画像認識⑧〜Kerasで畳み込みニューラルネットワーク vol.4〜
- Keras(Tensorflow)の学習済みモデルのFine-tuningで少ない画像からごちうさのキャラクターを分類する分類モデルを作成する
- Keras(TensorFlow)で学習済みモデルを転用して少ないデータでも画像分類を実現する[転移学習:Fine tuning]
学習モデル作成・Fine-Turning
前回のデータ収集、加工、水増しで用意した画像を、学習用、検証用、テスト用に分けます。
このうち、学習用と検証用の画像を使って、中日ドラゴンズの投手と野手の画像を学習させます。
参考サイト
こちらのサイト「KerasでVGG16を使う」に大変なお力添えを頂きました。
一部自分の環境で動かない箇所があったので、その部分は上記の他サイトを参考にさせて頂きました。
指定パラメータ
# 分類するクラス
classes = ['toushu', 'yashu']
nb_classes = len(classes)
# VGG16のデフォルト入力サイズは224x224 らしいのですが、150×150にします。
img_width, img_height = 150, 150
# トレーニング用とバリデーション用の画像格納先
train_data_dir = 'data/train'
validation_data_dir = 'data/validation'
# 今回はトレーニング用に40枚、バリデーション用に40枚の画像を用意した。
# トレーニング用、バリデーション用の割合はいろいろ適切なものがあるようですが、、よく分からないので、とりあえず半分に
nb_train_samples = 40
nb_validation_samples = 40
batch_size = 5 # 学習データの単位
nb_epoch = 20 # モデルを訓練させるエポック数(訓練の指標。与えられた反復回数分訓練をするわけではない)
# 学習結果のパラメータファイル保存先
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
学習モデル作成
VGG16は、ImageNetの大規模画像セットで学習済みのモデル
デフォルトで出力層は1000ユニットあり、1000クラスを分類するニューラルネットである。
ということで、出力層をカスタマイズして、投手・野手の2クラスに分類するニューラルネットワークに変更します。
def vgg_model_maker():
# VGG16のロード。
# デフォルトのFully-connected層(全結合層)は使わないので、include_top=Falseを指定する
input_tensor = Input(shape=(img_width, img_height, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# 全結合層作成
# Flatten 入力を平滑化する
# 公式サイトだと引数なし(https://keras.io/ja/getting-started/sequential-model-guide/#_3)
# 参考にしたサイトはいずれも引数あり。違いが何かは分からない
# Dense 通常の全結合ニューラルネットワークレイヤー
# units:正の整数,出力空間の次元数
# activation 活性化関数
# Dropout 入力にドロップアウトを適用する(訓練時の更新においてランダムに入力ユニットを0とする割合であり,過学習の防止に役立つ)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(nb_classes, activation='softmax'))
# VGG16と全結合層を結合
model = Model(input=vgg16.input, output=top_model(vgg16.output))
# 15層目まではデフォルトの層を使うので、freeze
for layer in model.layers[:15]:
layer.trainable = False
# 学習処理を指定
# (https://keras.io/ja/getting-started/sequential-model-guide/#_1)
# loss 損失関数(多クラス分類「categorical_crossentropy」を指定)
# optimizer オプティマイザ(最適化アルゴリズム)の利用方法
# metrics 訓練やテストの際にモデルを評価するための評価関数
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-3, momentum=0.9),
metrics=['accuracy'])
return model
Kerasで画像ファイルを直接ロード
機械学習では画像をNumPy array形式に変換する必要があります。
openCVや、Scikit-image等画像処理ライブラリもありますが、kerasには、「ImageDataGenerator」というクラスが用意されているようです。
「ImageDataGenerator」は、元画像に移動、回転、拡大・縮小、反転などの人為的な操作を加えることによって、画像数を増やすことができます
らしく、前回、openCVで画像を水増ししましたが、「ImageDataGenerator」でもできたかも。
def image_generator():
""" ディレクトリ内の画像を読み込んでトレーニングデータとバリデーションデータの作成 """
# ほぼ公式ドキュメントとおり
# https://keras.io/ja/preprocessing/image/
train_datagen = ImageDataGenerator(
rescale=1.0 / 255,
zoom_range=0.2,
horizontal_flip=True)
validation_datagen = ImageDataGenerator(rescale=1.0 / 255)
# flow_from_directory(directory): ディレクトリへのパスを受け取り,拡張/正規化したデータのバッチを生成する.
# directory 画像データがあるディレクトリへのパス
# class_mode categorical 2次元のone-hotにエンコード化されたラベル
# classes クラスサブディレクトリのリスト(最初に定義したclasses = ['toushu', 'yashu'])
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
color_mode='rgb',
classes=classes,
class_mode='categorical',
batch_size=batch_size,
shuffle=True)
validation_generator = validation_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
color_mode='rgb',
classes=classes,
class_mode='categorical',
batch_size=batch_size,
shuffle=True)
return (train_generator, validation_generator)
学習
if __name__ == '__main__':
start = time.time()
# モデル作成
vgg_model = vgg_model_maker()
# 画像のジェネレータ生成
train_generator, validation_generator = image_generator()
# Fine-tuning
# fit_generator Pythonジェネレータによりバッチ毎に生成されたデータでモデルを訓練します
history = vgg_model.fit_generator(
train_generator,
samples_per_epoch=nb_train_samples,
nb_epoch=nb_epoch,
validation_data=validation_generator,
nb_val_samples=nb_validation_samples)
# 学習済パラメータを保存
vgg_model.save_weights(os.path.join(result_dir, 'finetuning.h5'))
process_time = (time.time() - start) / 60
print(u'学習終了。かかった時間は', process_time, u'分です。')
実行結果
学習した結果が「finetuning.h5」に保存されています。
最初、batch_size = 16だったのですが、CPUだからか1日経っても学習が終わらず、、、たまらずbatch_sizeを小さくしました。
今回は、batch_size = 5で、30分くらいで学習が終わりました。
Epoch 1/20
8/8 [==============================] - 110s 14s/step - loss: 1.1884 - acc: 0.4500 - val_loss: 1.2809 - val_acc: 0.4150
Epoch 2/20
8/8 [==============================] - 107s 13s/step - loss: 0.9468 - acc: 0.5933 - val_loss: 0.6858 - val_acc: 0.5550
~途中略~
Epoch 20/20
8/8 [==============================] - 108s 13s/step - loss: 0.6915 - acc: 0.6250 - val_loss: 0.6989 - val_acc: 0.4050
学習終了。かかった時間は 36.11136643091837 分です。
fine-tuningしたパラメータをテスト
さきほど学習用、検証用、テスト用に分けた画像のうち、今度はテスト用を使います。
ちゃんと中日ドラゴンズの投手と野手を判定できるのかテストします。
指定パラメータ
classes = ['toushu', 'yashu']
nb_classes = len(classes)
img_width, img_height = 150, 150
# 学習済パラメータファイル(finetuning.h5)保存先
result_dir = 'results'
# このディレクトリにテストしたい画像を格納しておく
test_data_dir = 'test'
学習モデル作成
再び、テスト用にモデルを再作成します。
def model_load():
# VGG16をロード
input_tensor = Input(shape=(img_width, img_height, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# FC層の作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(nb_classes, activation='softmax'))
# VGG16とFC層を結合してモデルを作成
model = Model(input=vgg16.input, output=top_model(vgg16.output))
# 学習済みの重みをロード
model.load_weights(os.path.join(result_dir, 'finetuning.h5'))
# 多クラス分類を指定
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-3, momentum=0.9),
metrics=['accuracy'])
return model
テスト実行
テスト用の画像読込には、「load_img」を使います。
if __name__ == '__main__':
# モデルのロード
model = model_load()
# テスト用画像取得
test_imagelist = os.listdir(test_data_dir)
# テスト用画像保存フォルダにある画像分実行
for test_image in test_imagelist:
# ファイルパスを取得
filename = os.path.join(test_data_dir, test_image)
# 画像読込
img = image.load_img(filename, target_size=(img_width, img_height))
# 画像をarrayに変換する
x = image.img_to_array(img)
# 軸を指定して次元を増やす
# print(x.shape) => (150, 150, 3)
x = np.expand_dims(x, axis=0)
# print(x.shape) => (1, 150, 150, 3)
# 学習時に正規化してるので、ここでも正規化(ImageDataGenerator(rescale=1.0 / 255,…の部分)
x = x / 255
pred = model.predict(x)[0]
# 予測確率が高いトップを出力(上位n個を表示させることも可能)
# 今回は2クラス分類なので、top=2だけ
top = 2
top_indices = pred.argsort()[-top:][::-1]
result = [(classes[i], pred[i]) for i in top_indices]
print('file name is', test_image)
print(result)
print('=======================================')
実行結果
テストとしては数が少なすぎますが、、、
川上選手(元中日ドラゴンズ投手)、山本選手(元中日ドラゴンズ投手)、松坂選手(現中日ドラゴンズ投手)の画像を判定します。
判定結果(野手と投手である確率)が返ってきます。
file name is kenshin_san.jpg
[('yashu', 0.54815245), ('toushu', 0.45184755)]
=======================================
file name is masa_san.jpg
[('yashu', 0.599152), ('toushu', 0.400848)]
=======================================
file name is matsuzaka_san.jpg
[('yashu', 0.6319344), ('toushu', 0.36806566)]
=======================================
おまけ(学習とテスト時の違い)
学習時
- モデルのメソッド:fit_generator バッチ毎に生成されたデータでモデルを訓練
- 単位:バッチ単位でまとめて学習
- 使用データ: タプル(ImageDataGeneratorで生成)
# 画像のジェネレータ生成
train_generator, validation_generator = image_generator()
# varsでオブジェクトの中身を出力可能
print(vars(train_generator))
---------------------------------------------
{
'class_mode': 'categorical', 'interpolation': 'nearest', 'batch_index': 0, 'shuffle': True, 'color_mode': 'rgb',
'directory': 'data_face/train', 'save_to_dir': None, 'target_size': (150, 150),
'classes': array([・・・]),
'seed': None, 'index_array': None, 'filenames': [・・・・],
'save_format': 'png', 'samples': 84, 'lock': <unlocked _thread.lock object at 0x000001F44E93AD28>,
'image_data_generator': <keras.preprocessing.image.ImageDataGenerator object at 0x000001F4564D32B0>,
'image_shape': (150, 150, 3),
'n': 84, 'num_classes': 2, 'data_format': 'channels_last', 'save_prefix': '',
'total_batches_seen': 0, 'class_indices': {'toushu': 0, 'yashu': 1},
'index_generator': <generator object Iterator._flow_index at 0x000001F456494DB0>, 'batch_size': 5
}
テスト時
- モデルのメソッド:predict入力サンプルに対する予測値の出力を生成
- 単位:1ファイルずつテスト
- 使用データ: Numpy 配列(load_imgで読込)
img = image.load_img(filename, target_size=(img_width, img_height))
x = image.img_to_array(img)
print(x.shape)
---------------------------------------------
(150, 150, 3)
まとめ
検証データでの正解率が上がっていない、テスト用の画像に投手しかないのでテストになっていない、等々はありますが、
kerasを使ってひととおりFine-Turningを実行することができました。
実行ソースはこちらにアップしております。github