1. 参考
- 元論文
- nishiba様のConvMF実装例(Chainerをお使いになってました!)
- 自然言語処理におけるEmbeddingの方法一覧とサンプルコード
- けんごのお屋敷 様の記事
- PyTorchを使ってCNNで文章分類を実装してみた
- A Complete Guide to CNN for Sentence Classification with PyTorch
2. はじめに
KaggleのPersonalized Recommendationコンペに参加して以降、推薦システムが自分の中で熱くなっております。以前、Implicit Feedbackに対するモデルベースの協調フィルタリング(Matrix Factorization)の論文を読んで実装してみて、今度は更に実用的(?)で発展的な手法を触ってみたいと思い、「Convolutional Matrix Factorization for Document Context-Aware Recommendation」を読みました。この論文では、Matrix Factorizationによるモデルベース協調フィルタリングに、CNNを用いてアイテムの説明文書の情報を組み合わせる ConvMF(Convolutional Matrix Factorization)を提案しています。
今実装中ですが、なかなかPytorchと仲良くなれず、苦戦しております...。(ちなみに元論文はKerasで実装しておりました!)
パート3とした本記事では、ConvMFにおけるCNNパートの実装についてまとめています。**アイテムjの説明文書$X_j$を受け取って、document latent vector $s_j$を出力する$CNN(W, X_j)$**の事ですね:)
本記事以前のパートは、以下のリンクを御覧ください。
- 評価行列とアイテムの説明文書を活用した推薦システム「ConvMF」を何とか実装していきたい!①MFパートの実装
- 評価行列とアイテムの説明文書を活用した推薦システム「ConvMF」を何とか実装していきたい!②MFパートの実装
3. 前回のリマインド
3.1. ConvMF(畳み込み行列分解)とは?
Convolutional Matrix Factorization(通称ConvMF)は、モデルベース協調フィルタリングにおいて評価行列のスパース性の上昇問題やコールドスタート問題に対応する為に提案された、Explicit FeedbackやImplicit Feedbackの評価情報に加えてアイテムの説明文書(ex. ニュース記事の中身、動画のタイトル、etc.)の情報を考慮した推薦手法の一つです。
その為に、ConvMFではモデルベース協調フィルタリングであるPMF(Probabilistic Matrix Factorization)にCNN(convolutional neural network)を統合しています。
その結果、ConvMFは最終的に協調情報と文脈情報の両方を効果的に利用することができ、評価データが極めて疎な場合でも、ConvMFは未知の評価を正確に予測することができる、らしいです...。
3.2. ConvMFの確率モデル
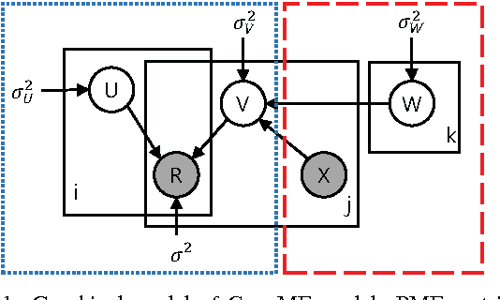
以下の図は、NLPに対するCNNモデルをPMF(確率的行列分解)モデルに統合した、ConvMFの確率モデルの概要を示したモノになります。
 )
)
ちなみに上図において、各記号の意味合いは以下です。(順次まとめていきます)
- $U$: user latent model
- $V$: item latent model
- $R$: Rating Matrix
- $X$: アイテムのDescription(説明文)
- $W$: CNNのパラメータ達。
- $i, j$: それぞれ、各ユーザと各アイテムを表す添字。
- $k$:CNN内の各パラメータを表す添字(kに関しては、潜在ファクターの次元数の記号と混在してるかもしれません...?)
また問題設定として、N人のユーザとM個のアイテムがあり、観測された評価行列は$R\in \mathbb{R}^{N\times M}$行列で表現されるとします。
そして、その積($U^T \cdot V$)が評価行列 $R$を再構成するような、ユーザとアイテムの潜在モデル($U\in \mathbb{R}^{k\times N}$ と $V \in \mathbb{R}^{k\times M}$)を見つけることが目的になります。
特にConvMFでは、アイテムjの説明文書ベクトル$X_j$を考慮して$V_j$をを推定する点が大きな特徴になります。
3.3. ConvMFにおけるパラメータ推定法
ConvMFでは、パラメータ($U, V, W$)を最適化する為に、MAP推定(maximum a posteriori estimation)を行います。
事後分布の式を対数化してマイナスを掛け、いい感じに変形($\sigma^2$で割る!)と、以下のようになりますね(前パート参照)。
L(U,V,W|R, X, \lambda_U, \lambda_V, \lambda_W)
= \frac{1}{2} \sum_{i}^N \sum_{j}^M I_{ij}(r_{ij} - u_{i}^T v_j)^2 \\
+ \frac{\lambda_U}{2} \sum_{i}^N||u_i||^2 \\
+ \frac{\lambda_V}{2} \sum_{j}^M ||v_j - cnn(W,X_j)||^2 \\
+ \frac{\lambda_W}{2} \sum_{k}^{|W_k|}||w_k||^2
\\
(
\lambda_U = \frac{\sigma^2}{\sigma_U^2},
\lambda_V = \frac{\sigma^2}{\sigma_V^2},
\lambda_W = \frac{\sigma}{\sigma_W^2}
)
この式を最小化するような$U, V, W$を求めるわけです。
ConvMFの学習では、UとVとWの内2つを固定して、一つずつ最適化していく、Alternating Least Square(ALS)的なアプローチを取っていきます。
user latent matrix $U$とitem latent matrix $V$ の推定方法に関しては、ALS同様に、閉形式(closed-form, 要するに解析的に解ける式?)で解析的に計算することができます。
u_i \leftarrow (V I_i V^T + \lambda_U I_K)^{-1}VR_i \tag{7}
v_j \leftarrow (U I_j U^T + \lambda_V I_K)^{-1}(UR_j + \lambda_V \cdot cnn(W, X_j)) \tag{8}
$V$に関しては、$\lambda_V \cdot cnn(W, X_j)$が含まれているのが、通常のMFとの大きな違いであり、ConvMFの特徴ですね。
ここで
- ユーザiについて
- $I_i$ は$I_{ij} , (j=1, \cdots, M)$を対角要素とする対角行列。
- $R_i$ はユーザiについて$(r_{ij})_{j=1}^M$とするベクトル。
- つまり、ユーザiの各アイテムjに対する評価値が入ったベクトル!
- アイテムjについて
- $I_j$と$R_j$の定義は、$I_i$と$R_i$のものと同様。
- 式(8)はアイテム潜在ベクトル$v_j$を生成する際のCNNのDocument潜在ベクトル$s_j = cnn(W, X_j)$の効果を示している。
- $\lambda_V$はバランシングパラメータ(要は重み付け平均みたいな?, 意味合いとしては正則化項のハイパラ?)になる。
CNN内のパラメータWの推定方法に関しても、UとVを定数と仮定してWを推定する方針は同じです。以下の損失関数を最小化するようなパラメータ$W$を求めていきます。CNNに関しては次回のパートで実装をまとめていきます。
\varepsilon(W) = \frac{\lambda_V}{2} \sum_{j}^M ||v_j - cnn(W,X_j)||^2 \\
+ \frac{\lambda_W}{2} \sum_{k}^{|W_k|}||w_k||^2 + constant \tag{9}
最終的には、最適化された$U, V, W$により、「アイテム$j$に対するユーザ$i$の未知の評価 $r_{ij}$」を推定する事ができます。
r_{ij} \approx E[r_{ij}|u_i^T v_j, \sigma^2] \\
= u_i^T v_j = u_i^T \cdot (cnn(W, X_j) + \epsilon_j)
\tag{10}
ここまでで、簡単なConvMFの理論の復習は完了です。
4. $s_j = CNN(W, X_j)$についてまとめる前に...NLPのCNNについて確認
$s_j = CNN(W, X_j)$の実装の前に、自然言語処理における畳み込みニューラルネットワークを理解していきます。
4.1. 畳み込みとは?
- 畳み込みについては、行列に適用されるスライド窓関数 (sliding window function) として考えるとわかりやすいらしい...。
- (けんごのお屋敷 様のgifを貼り付けさせていただきました)

- スライド窓は**カーネル(kernel)やフィルタ(filter)または特徴検出器(Feature Detector)**等と呼ばれる。
-
- 上の例では3×3のスライド窓関数を使っており、そのスライド窓関数の値と行列の値を要素毎にかけ合わせ、それらの値を合計したものを、Convoloved Featureの一つの要素とする。
- =>つまり、「スライド窓関数 & 畳み込み対象の行列の、ウィンドウサイズと合致する一部分」のアダマール積の和が、Convolved Featureの要素の一つになる。
- この操作を、行列全体をカバーするように、スライド窓関数をスライドさせながら行い、全体の畳み込み特徴(Covolved Feature)を取得する。
4.2. 畳み込みニューラルネットワークとは?
-
CNN は、ReLU や tanh のような非線形な活性化関数を通した、いくつかの畳み込みの層のこと
-
伝統的な順伝搬型ニューラルネットワークでは、それぞれの入力ニューロンは次の層のニューロンにそれぞれ接続されており、これは全結合層やアフィン層とも呼ばれる。
-
しかし CNN ではそのようなことはせずに、ニューロンの出力を計算するのに畳み込みを使う。これによって、入力となるニューロンのある領域が、それぞれ対応する出力のニューロンに接続されているような、局所的な接続ができることになる。
-
各層は別々の異なるフィルタを適用し、(これは一般的には 100 〜 1000 程度の数になるが) それらを結合する。(この結合する層を**プーリング層(subsampling)**と呼ぶ。)
-
CNNの学習フェーズでは、解決したいタスクに適応できるように、フィルタの値(=スライド窓行列=カーネルの各要素!)を自動的に学習していく。
-
例えば画像分類の話でいうと、
- CNNは最初の層で生のピクセルデータからエッジを検出する為の学習を進め、
- そのエッジを使って今度は次の層で単純な形状を検出し、
- 更により深い層ではその形状を使ってより高レベルな特徴、つまり顔の形状等の特徴を検出するようになる。
- そして最後の層は、高レベルな特徴を使った(=入力とした)分類器になる。
4.3. これをどうやってNLPへ適用するのか?
- 画像分類では入力は画像のピクセル行列になるが、ほとんどの NLP タスクではピクセル行列の代わりに、行列で表現された文章または文書が入力となる。
- 行列の各行は 1 つのトークンに対応しており、一般的には単語がトークンになることが多いが、文字がトークンのケースもある。
- =>すなわち、各行は単語を表現するベクトル。
- 普通、これらのベクトルは word2vec や GloVe のような低次元な単語埋め込み表現 (word embeddings) を使う。one-hot ベクトルのケースもある。
- 例えば、100 次元の単語埋め込みを使った 10 単語の文章があった場合、10x100 の行列となる。これがNLPにおける"画像"になる。
- コンピュータビジョンでは、フィルタは画像のある区画上をスライドしていくが、NLP では一般的に行列の行全体 (つまり単語毎) をスライドするフィルタを使う。
- つまり、フィルタの幅(横幅)は入力となる行列の幅と同じになる!
- つまり、NLPの場合のフィルタ(スライド窓, カーネル, 特徴検出器)は横方向にはスライドせず、縦方向にのみスライドしていく!
- フィルタの高さ(縦幅)は様々だが、一般的には2~5くらい?
これらのことを加味すると NLP の畳み込みニューラルネットワークはこんな感じになる。(けんごのお屋敷 様のgifを使用させていただきました!)

上図の解釈
- 文章分類のための畳み込みニューラルネットワーク (CNN) のアーキテクチャを説明した図.
- 畳み込み層
- この図には 2、3、4 の高さをもったフィルタが、それぞれ 2 つずつ(計6)ある。
- 各フィルタは文章の行列上で畳み込みを行い、特徴マップ(〇行1列のやつ!)を生成する。
- プーリング層
- 各特徴マップに対して最大プーリングをかけていき、各特徴マップの中で一番大きい値を記録していく。(=Max pooling)
- そして、全6つの特徴マップから単変量な特徴 (univariate feature) が生成され、それら 6 つの特徴は結合されて、それが最後から 2 番目の層になる。
- 全結合層(アフィン層)(一層?出力層?)
- 一番最後の softmax 層では先程の特徴を入力として受け取り、文章を分類する。
- ここでは二値分類を前提としているので、最終的には 2 つの出力がある。
4.4. CNN のハイパーパラメータ
- スライド窓関数のサイズ(畳み込み幅のサイズ)
- wide convolution か narrow convolution か
- ストライドのサイズ
- プーリング層の選択(メジャーなのがmax pooling?)
- チャンネル数
4.4.1. 畳み込み幅のサイズ
-
最初に畳み込みの説明をした時、フィルタ(スライド窓、カーネル、特徴検出器)を適用する際の詳細について説明を飛ばしたものがある。
- 行列の真ん中辺りに 3x3 のフィルタを適用するのは問題ないが、それではフチの辺りに適用する場合はどうなんだろうか??
- 行列の左側にも上側にも隣接した要素がないような、たとえば行列の最初の要素にはどうやってフィルタを適用すればよいのだろうか?
-
そういった場合には、ゼロパディングが使える!
- 行列の外側にはみ出してしまう要素は全て 0 で埋めるのである。
- こうすることで、入力となる行列の全要素にわたってフィルタを適用することができる。
- ゼロパディングを行うことは wide convolutionとも呼ばれ、逆にゼロパディングをしない場合は narrow convolutionと呼ばれる。
-
以下は1次元での例:
(Narrow Convolution と Wid Convolution。フィルタのサイズは 5 で、入力データのサイズは 7。)
(けんごのお屋敷 様の画像を使用させていただきました!) -
入力データのサイズに対してフィルタサイズが大きい時には wide convolution が有用。
- 上記の場合、narrow convolution は出力されるサイズが $(7 - 5) + 1 = 3$ になり、wide convolutin は $(7 + 2 * 4 - 5) + 1 = 11$ になる。
- 一般化すると、**wide convolutionの場合の出力サイズ(畳み込み層の出力=特徴マップの大きさ?)**は $n_{out}=(n_{in} + 2*n_{padding} - n_{filter}) + 1$

4.4.2. ストライド
- フィルタを順に適用していく際に、フィルタをどれくらいシフトするのかという値。
- これまでに示してきた例は全てストライド=1 で、フィルタは重複しながら連続的に適用されている。
- ストライドを大きくするとフィルタの適用回数は少なくなって、出力のサイズも小さくなる。
- 以下のような図が Stanford cs231 にあるが、これは 1 次元の入力に対して、ストライドのサイズが 1 または 2 のフィルタを適用している様子。
(畳み込みのストライドのサイズ。左側のストライドは 1。右側のストライドは 2) 
- 普通、文書においてはストライドのサイズは 1だが、ストライドのサイズを大きくすることで、例えばツリーのような 再帰型ニューラルネットワーク と似た挙動を示すモデルを作れるかもしれない...!
4.4.3. プーリング層
- 畳み込みニューラルネットワークの鍵は、畳み込み層の後に適用されるプーリング層
- プーリング層は、入力をサブサンプリングする。
- 最も良く使われるプーリングは、各フィルタの結果(=各畳み込み層の出力=特徴マップ)の中から最大値を得る操作。=>Max Pooling
- ただ、畳み込み結果の行列全体にわたってプーリングする必要はなく、指定サイズのウィンドウ上でプーリングすることもできる。
- たとえば、以下の図は 2x2 のサイズのウィンドウ上で最大プーリングを実行した様子。

- (NLP では一般的に出力全体にわたってプーリングを適用する。つまり各フィルタ(=>特徴マップ)からは 1 つの数値が出力されることになる。)
4.4.4. チャンネル数
- チャンネルとは、入力データを異なる視点から見たものと言える。
- 画像認識での例を挙げると、普通は画像は RGB (red, green, blue) の 3 チャンネルを持っている。
- 畳み込みはこれらのチャンネル全体に適用でき、その時のフィルタは各チャンネル毎に別々に用意してもいいし、同じものを使っても問題ない。
- NLP では、異なる単語埋め込み表現 (word2vec や GloVe など) でチャンネルを分けたり、同じ文章を異なる言語で表現してみたり、また異なるフレーズで表現してみたり、という風にして複数チャンネルを持たせることができそう...!
5. NLPタスクにおけるCNNを実装してみる(CNNによるDocumentの2クラス分類)
さてここから、CNNによるDocumentの2クラス分類をPytorchで実装していきます。
A Complete Guide to CNN for Sentence Classification with PyTorchを参考に(ほぼ写経でコメントアウトをはさみまくりながら)実装します。
ConvMFのCNNパート$s_j = CNN(W, X_j)$に関しても、出力次元数と損失関数の形以外は、この実装と変わらないので、今回実装するスクリプトを調整すれば、すぐにできるはずです...!
5.1. データの準備
今回は、パート1⃣で用意したデータセットの内、各映画の説明文descriptions.csvのみを使用します。
また、文章をtokenizeする為に、fastTextをダウンロードしておきます。
加えて、今回は練習として2クラス分類問題を解くCNNを実装するので、各映画の説明文に対して適当に0か1のラベルを割り振ります。
TEXT_FILE = r'data\descriptions.csv'
FAST_TEXT_PATH = r'fastText\crawl-300d-2M.vec'
def load_data():
texts_df = pd.read_csv(TEXT_FILE)
return texts_df
def load_word_vector():
URL = "https://dl.fbaipublicfiles.com/fasttext/vectors-english/crawl-300d-2M.vec.zip"
FILE = "fastText"
if os.path.isdir(FILE):
print("fastText exists.")
else:
print('please download fastText.')
def main():
load_word_vector()
texts_df = load_data()
print(texts_df.head())
# 文章をList[List[str]]として取得
texts = texts_df['description'].to_list()
# 今回は実装テストなので、labelを適当に作成
labels = np.array(
[0]*len(texts[:len(texts) % 2])
+ [1]*len(texts[len(texts) % 2:])
)
# データのサイズの確認
print(
f'the num of texts data is {len(texts)}, and the num of labels is {len(labels)}.')
一応、上記のコードを回した結果の出力が以下になります。
title description id
0 pirates of the caribbean: at world's end Captain Barbossa, long believed to be dead, ha... 0
1 spider-man 3 The seemingly invincible Spider-Man goes up ag... 1
2 superman returns Superman returns to discover his 5-year absenc... 2
3 quantum of solace Quantum of Solace continues the adventures of ... 3
4 pirates of the caribbean: dead man's chest Captain Jack Sparrow works his way out of a bl... 4
the num of texts data is 2243, and the num of labels is 2243.
5.2. tokenizeの処理
続いて、tokenizeの処理を実装していきます。
tokenizeとは、文章を何らかの単位に区切る事を意味します。
今回は映画の説明文に対して、「単語」をtokenとしてtokenizeします。
実装には、gensim.utilsモジュールのtokenize()関数を用いています。
以下で定義されたconduct_tokenize()関数は、文章のリストをtexts引数として受け取って、tokenizeされた文章のリストtokenized_texts、学習データに含まれる全ての単語(token)を通し番号として登録したword2idx、学習データの中の文章の最大長さmax_lenの3つを返します。
from typing import Dict, List
from tqdm import tqdm
import pandas as pd
import os
from collections import defaultdict
import numpy as np
import gensim
def conduct_tokenize(texts: List[str]):
"""文章を単語をtokenとしてtokenizeする。
全文章に使われている単語を確認しvocabularyを生成すると共に、文章の最大長さを記録する。
Tokenize texts, build vocabulary and find maximum sentence length.
Args:
texts (List[str]): List of text data
Returns:
tokenized_texts (List[List[str]]): List of list of tokens
word2idx (Dict): Vocabulary built from the corpus
max_len (int): Maximum sentence length
"""
# 結果格納用の変数をInitialize
tokenized_texts: List[List[str]] = []
word2idx: Dict[str, int] = {}
max_len = 0
# Add <pad> and <unk> tokens to the vocabulary
word2idx['<pad>'] = 0 # 長さの短いSentenceに対して、長さをmax_lenにそろえるために使う?
word2idx['<unk>'] = 1 # 未知のtokenに対する通し番号
# Building our vocab from the corpus starting from index 2
idx = 2
# 各文章に対して繰り返し処理
for text in texts:
# tokenize
# tokenized_text = nltk.tokenize.word_tokenize(text=text)
tokenized_text = gensim.utils.tokenize(text=text)
tokenized_text = list(tokenized_text)
# Add `tokenized_text` to `tokenized_texts`
tokenized_texts.append(tokenized_text)
# Add new token to `word2idx`
# text内の各tokenをチェックしていく...
for token in tokenized_text:
# word2idxに登録されていないtoken(単語?)があれば、通し番号を登録!
if token not in word2idx:
word2idx[token] = idx
idx += 1
# Update `max_len`
max_len = max(max_len, len(tokenized_text))
return tokenized_texts, word2idx, max_len
続いて、tokenizedされた文章データ(List[List[str]])を、通し番号化(List[List[int]])する為に、encode()関数を定義します。要するにtokenizeされた単語のListを、CNNに入力する形に変換する処理ですね!
encode()関数では、tokenizeされた各テキストを、the maximum sentence lengthに合わせてゼロパディングする。
その後、tokenizeされたテキスト内の各tokenを、vocabularyの通し番号にencode(符号化)しています。
# 略
def encode(tokenized_texts: List[List[str]], word2idx: Dict[str, int], max_len: int):
"""tokenizeされた各テキストを、the maximum sentence lengthに合わせてゼロパディングする。
加えて、tokenizeされたテキスト内の各tokenを、vocabularyの通し番号にencode(符号化)する.
Pad each sentence to the maximum sentence length and encode tokens to
their index in the vocabulary.
Returns:
input_ids (np.array): Array of token indexes in the vocabulary with
shape (N, max_len). It will the input of our CNN model.
"""
input_ids: List[List[int]] = []
for tokenized_text in tokenized_texts:
# tokenized_textの長さがmax_lenと一致するように、最後尾に<pad>を追加する。
# Pad sentences to max_len
tokenized_text += ['<pad>'] * (max_len - len(tokenized_text))
# tokenized_text内の各tokenを通し番号へ符号化
# Encode tokens to input_ids
input_id: List[int] = [word2idx.get(token) for token in tokenized_text]
input_ids.append(input_id)
# 最後は配列としてReturn
# (R^{n \times max_len}の行列。各要素はtokenの通し番号)
return np.array(input_ids)
上で定義した関数を、main.py内で呼び出し、学習データである映画の説明文に対して、tokenize & encodeしていきます。
# 略(文章データのload + ラベルの振り分けまで完了)
# Tokenize, build vocabulary, encode tokens
print('Tokenizing...\n')
tokenized_texts, word2idx, max_len = conduct_tokenize(texts=texts)
print(f'the num of vocabrary is {len(word2idx) - 2}')
print(f'max len of texts is {max_len}')
input_ids = encode(tokenized_texts, word2idx, max_len)
print(f'the shape of input_ids is {input_ids.shape}')
上記のコードを回した結果が以下になります。
Tokenizing...
the num of vocabrary is 15246
max len of texts is 174
the shape of input_ids is (2243, 174)
学習データに含まれるユニークな単語(token)数は15246個であり、一つの文章における最大長さ(最大token数)が174らしいです。
そして、tokenize及びencodeの処理を経て、CNNに入力する前の学習データが2243(データ数) * 174(token数)の行列として用意されました。
5.3. 学習済み単語埋め込みベクトルの読み込み
さて続いて、学習済みの単語埋め込み(Embedding)ベクトルのデータを、CNNの学習に使えるように読み込みます。
ここで読み込んだデータは、CNN内のEmbedding layerにて、前述した文章学習データ(=2243(データ数) * 174(token数)の行列)の各要素(=各単語の通し番号)を単語埋め込みベクトルに変換する際に使われます。
今回は、学習済みの単語埋め込み(Embedding)ベクトルのデータとしてfastTextをダウンロードしておきました。
以下が、学習済みの単語埋め込み(Embedding)ベクトルのデータを読み込む処理になります。
load_pretrained_vectors()は、conduct_tokenize()の返り値として得られた「単語と通し番号の対応表」(word2idx:Dict)と「学習済みの単語埋め込み(embedding)ベクトルのデータの保存先」を引数として受け取り、対応表の各単語を表現する為の単語埋め込みベクトルを返します。
実際の返り値としては、word2idxの各通し番号を行indexとして、各行に単語埋め込み(Embedding)ベクトルが格納されたnumpy.ndarrayになります。
from typing import Dict, List
from tqdm import tqdm
import pandas as pd
import os
from collections import defaultdict
import numpy as np
import gensim
def load_pretrained_vectors(word2idx: Dict[str, int], frame: str):
"""学習済みの単語埋め込み(embedding)ベクトルのデータを読み込んで、
学習データのvocabularyに登録された各tokenに対応する、単語埋め込み(embedding)ベクトルを作成する。
Load pretrained vectors and create embedding layers.
Args:
word2idx (Dict): Vocabulary built from the corpus
fname (str): Path to pretrained vector file
Returns:
embeddings (np.array): Embedding matrix with shape (N, d) where N is
the size of word2idx and d is embedding dimension
配列の行indexが、word2idxの通し番号に対応。
"""
print('Loading pretrained vectors...')
# ファイルを開いて...
fin = open(frame, encoding='utf-8', newline='\n', errors='ignore')
# intで行数とか(?)を取得
n, d = map(int, fin.readline().split()) # 登録されてる単語数, 埋め込みベクトルの次元数
# Initilize random embeddings
embeddings: np.ndarray = np.random.uniform(
low=-0.25, high=0.25,
size=(len(word2idx), d) # (Vocabularyに登録された単語数, 埋め込みベクトルの次元数)
)
# <pad>の埋め込みベクトルは0ベクトル
embeddings[word2idx['<pad>']] = np.zeros(shape=(d,))
# Load pretrained vector
count = 0
for line in tqdm(fin):
# 学習済みモデルに登録されている単語と、対応する埋め込みベクトルを取得。
tokens = line.rstrip().split(' ')
word = tokens[0]
# 今回のVocabularyにある単語の場合
if word in word2idx:
count += 1
# 配列の行index = word2idxの通し番号として、埋込ベクトルを保存
embeddings[word2idx[word]] = np.array(tokens[1:], dtype=np.float32)
print(f'There are {count} / {len(word2idx)} pretrained vector found.')
return embeddings
では、上記で実装したload_pretrained_vectors()関数をmain.pyで呼び出し、学習データ内で出現する各単語(token)に対応する単語埋め込みベクトルを取得します。
# 略(文章データ読み込み + 疑似ラベル生成)
# 略(文章データに対して、tokenize + encode)
# Load pretrained vectors
embeddings = load_pretrained_vectors(word2idx, FAST_TEXT_PATH)
embeddings = torch.tensor(embeddings) # np.ndarray => torch.Tensor
print()
上記処理の実行結果は、以下のようになります。
Loading pretrained vectors...
1999995it [01:37, 20484.44it/s]
There are 15090 / 15248 pretrained vector found.
the shape of embedding_vectors is (15248, 300)
学習データに含まれるユニークな単語(token)数=15246個の内、15090個が事前学習された単語埋め込みベクトルの中に見つかったようです。
また、返り値embeddingsのshape属性を確認したところ、単語埋め込みベクトルの次元数は300のようですね!
5.4. CNN_NLPクラスの実装
さてようやく、CNN_NLPクラスを実装していきます。
以下が、CNN_NLPクラスの実装部分になります。
まずコンストラクタ.__init__()では、Embedding layerで使用する単語埋め込みベクトルを指定しています。引数として渡された場合はそれを使用し、引数で渡されなかった場合は単語埋め込みベクトルnn.EmbeddingをInitializeしています。
その下では、CNNの各layerを定義しています。
本クラスで定義するCNNの構造は、前Chapterで述べた以下のアーキテクチャを採用しています。
from typing import List, Tuple
from torch import Tensor
import torch.optim as optim
from turtle import forward
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class CNN_NLP(nn.Module):
"""
文章分類の為の一次元CNN
An 1D Convulational Neural Network for Sentence Classification.
"""
def __init__(self, pretrained_embedding: torch.Tensor = None,
freeze_embedding=False,
vocab_size=None,
embed_dim=300,
filter_sizes=[3, 4, 5],
num_filters=[100, 100, 100],
dim_output: int = 2,
dropout: float = 0.5
) -> None:
"""
CNN_NLPクラスのコンストラクタ
The constructor for CNN_NLP class.
Args:
pretrained_embedding (torch.Tensor): Pretrained embeddings with
shape (vocab_size, embed_dim)。学習済みの単語埋め込みベクトル。
Default: None
freeze_embedding (bool): Set to False to fine-tune pretraiend
vectors. 学習済みの単語埋め込みベクトルをfine-tuningするか否か。
Default: False
vocab_size (int): Need to be specified when not pretrained word
embeddings are not used. 学習済みの単語埋め込みベクトルが渡されない場合、指定する必要がある。
Default: None
embed_dim (int): Dimension of word vectors. Need to be specified
when pretrained word embeddings are not used.
学習済みの単語埋め込みベクトルが渡されない場合、指定する必要がある。
Default: 300
filter_sizes (List[int]): List of filter sizes.
畳み込み層のスライド窓関数のwindow sizeを指定する。
Default: [3, 4, 5]
num_filters (List[int]): List of number of filters, has the same
length as `filter_sizes`. 畳み込み層のスライド窓関数(Shared weihgt)の数
Default: [100, 100, 100]
dim_output (int): Number of classes. 最終的なCNNの出力次元数。
Default: 2
dropout (float): Dropout rate. 中間層のいくつかのニューロンを一定確率でランダムに選択し非活性化する。
Default: 0.5
"""
super(CNN_NLP, self).__init__()
# Embedding layerの定義
# 学習済みの単語埋め込みベクトルの配列が渡されていれば...
if pretrained_embedding is not None:
self.vocab_size, self.embed_dim = pretrained_embedding.shape
self.embedding = nn.Embedding.from_pretrained(
pretrained_embedding,
freeze=freeze_embedding
)
# 渡されていなければ...
else:
self.embed_dim = embed_dim
# 単語埋め込みベクトルを初期化
self.embedding = nn.Embedding(
num_embeddings=vocab_size, # 語彙サイズ
embedding_dim=self.embed_dim, # 埋め込みベクトルの次元数
padding_idx=0, # 文章データ(系列データ)の長さの統一:ゼロパディング
# 単語埋め込みベクトルのnorm(長さ?)の最大値の指定。これを超える単語ベクトルはnorm=max_normとなるように正規化される?
max_norm=5.0
)
# Conv Networkの定義
modules = []
# スライド窓関数のwindow size(resign size)の種類分、繰り返し処理
for i in range(len(filter_sizes)):
# 畳み込み層の定義
conv_layer = nn.Conv1d(
# 入力チャネル数:埋め込みベクトルの次元数
in_channels=self.embed_dim,
# 出力チャネル数(pooling後、resign size毎に代表値を縦にくっつける)
out_channels=num_filters[i],
# window size(resign size)(Conv1dなので高さのみ指定)
kernel_size=filter_sizes[i],
padding=0, # ゼロパディング
stride=1 # ストライド
)
# 保存
modules.append(conv_layer)
# 一次元の畳み込み層として保存
self.conv1d_list = nn.ModuleList(modules=modules)
# 全結合層(中間層なし)とDropoutの定義
# Fully-connected layer and Dropout
self.fc = nn.Linear(
in_features=np.sum(num_filters),
out_features=dim_output
)
self.dropout = nn.Dropout(p=dropout)
def forward(self, input_ids):
"""Perform a forward pass through the network.
Args:
input_ids (torch.Tensor): A tensor of token ids with shape
(batch_size, max_sent_length)
Returns:
logits (torch.Tensor): Output logits with shape (batch_size,
dim_output)
"""
# Get embeddings from `input_ids`. Output shape: (b, max_len, embed_dim)
# Embedding層にtokenizedされたテキスト(符号化済み)を渡して、文書行列を取得する
x_embed: Tensor = self.embedding(input_ids).float()
# Permute `x_embed` to match input shape requirement of `nn.Conv1d`.
# Tensorの軸の順番を入れ替える:(batch_size, max_len, embed_dim)=>(batch_size, embed_dim, max_len)
x_reshaped = x_embed.permute(0, 2, 1)
# Output shape:(batch_size, embed_dim, max_len)
# Apply CNN and ReLU.
# Output shape: (batch_size, num_filters[i], L_out(convolutionの出力数))
x_conv_list: List[Tensor] = [F.relu(conv1d(x_reshaped))
for conv1d in self.conv1d_list]
# Max pooling.
# 各convolutionの出力値にmax poolingを適用して、一つの代表値に。
# Output shape: (batch_size, num_filters[i], 1)
# kernel_size引数はx_convの次元数に!=>poolingの出力は1次元!
x_pool_list: List[Tensor] = [
F.max_pool1d(x_conv, kernel_size=x_conv.shape[2]) for x_conv in x_conv_list
]
# Concatenate x_pool_list to feed the fully connected layer(全結合層).
# x_pool_listを連結して、fully connected layerに投入する為のshapeに変換
# Output shape: (batch_size, sum(num_filters)=今回は100+100+100=300)
x_fc: Tensor = torch.cat([x_pool.squeeze(dim=2) for x_pool in x_pool_list],
dim=1)
# Compute logits. Output shape: (batch_size, dim_output)
logits = self.fc(self.dropout(x_fc))
return logits
.forward()では、CNN_NLPインスタンスが入力値(=tokenize & encodeされた文章データ)を受け取ってCNNの出力値を返す処理を実装しています。
5.5. 学習データとラベルのセットをDataLoaderに~
ここまででモデルクラスの定義まで完了したので、モデルにデータを流し込む為のDatasetオブジェクト,DataLoaderオブジェクトを作成します。
以下のdataloader.pyで、create_data_loaders()関数を定義しています。create_data_loaders()関数は、学習用inputデータ、検証用inputデータ、学習用outputデータ、検証用outputデータをそれぞれnp.ndarray型で引数として渡して、返り値として学習用DataLoaderオブジェクトと検証用DataLoaderオブジェクトを出力します。
import torch
from torch.utils.data import (
TensorDataset, DataLoader, RandomSampler, SequentialSampler)
import numpy as np
def create_data_loaders(train_inputs: np.ndarray, val_inputs: np.ndarray, train_labels: np.ndarray, val_labels: np.ndarray, batch_size: int = 50):
"""Convert train and validation sets to torch.Tensors and load them to DataLoader.
Parameters
----------
train_inputs : np.ndarray
学習用データ(tokenize & encode された文章データ)
val_inputs : np.ndarray
検証用データ(tokenize & encode された文章データ)
train_labels : np.ndarray
学習用データ(ラベル)
val_labels : np.ndarray
検証用データ(ラベル)
batch_size : int, optional
バッチサイズ, by default 50
Returns
-------
Tuple[DataLoader]
学習用と検証用のDataLoaderをそれぞれ返す。
"""
# Convert data type to torch.Tensor
train_inputs, val_inputs, train_labels, val_labels =\
tuple(torch.tensor(data) for data in
[train_inputs, val_inputs, train_labels, val_labels])
# Create DataLoader for training data
# DatasetオブジェクトのInitialize
train_data = TensorDataset(train_inputs, train_labels)
train_sampler = RandomSampler(train_data)
# DataLoaderオブジェクトのInitialize
train_dataloader = DataLoader(
train_data, sampler=train_sampler, batch_size=batch_size)
# Create DataLoader for validation data
# DatasetオブジェクトのInitialize
val_data = TensorDataset(val_inputs, val_labels)
val_sampler = SequentialSampler(val_data)
# DataLoaderオブジェクトのInitialize
val_dataloader = DataLoader(
val_data, sampler=val_sampler, batch_size=batch_size)
return train_dataloader, val_dataloader
5.6. モデルの学習&検証用の関数を作成
最後の実装部分として、ここまでで用意したモデル、Optimizer、および2つ(学習用+検証用)のDataLoaderを用いて、CNN_NLPの学習と検証の処理を実装します。
以下のtrain_nlp_cnn.py内で、train()関数を定義しています。
実装の詳細に関しては、執拗に記述されたコメントアウトや、docstringを読んでいただければおそらく理解できると思います!
ざっくり関数内の処理の内容としては、CNN_NLPオブジェクト、Optimizer、torch.device('cpu' or 'cuda')、及びepoch数を指定して、返り値として学習によりパラメータ最適化されたCNN_NLPオブジェクトを出力します。
各epochの学習後に、検証用データを用いてモデルの汎化性能を評価しており、検証用データの予測精度の評価の処理は、evaluate()関数で定義して、train()関数内で呼び出しています。
from typing import Tuple
from torch import Tensor
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
import random
import time
from torch.utils.data import (TensorDataset, DataLoader, RandomSampler,
SequentialSampler)
# Specify loss function
loss_fn = nn.CrossEntropyLoss()
def set_seed(seed_value=42):
"""Set seed for reproducibility."""
random.seed(seed_value)
np.random.seed(seed_value)
torch.manual_seed(seed_value)
torch.cuda.manual_seed_all(seed_value)
def train(model: nn.Module, optimizer: optim.Adadelta, device: torch.device,
train_dataloader: DataLoader, val_dataloader: DataLoader = None,
epochs: int = 10
) -> nn.Module:
"""Train the CNN_NLP model.
Parameters
----------
model : nn.Module
CNN_NLPオブジェクト。
optimizer : optim.Adadelta
Optimizer
device : torch.device
'cuda' or 'cpu'
train_dataloader : DataLoader
学習用のDataLoader
val_dataloader : DataLoader, optional
検証用のDataLoader, by default None
epochs : int, optional
epoch数, by default 10
Returns
-------
学習を終えたCNN_NLPオブジェクト
nn.Module
"""
# Tracking best validation accuracy
best_accuracy = 0
print("Start training...\n")
print("-"*60)
# エポック毎に繰り返し
for epoch_i in range(epochs):
# =======================================
# Training
# =======================================
# Tracking time and loss
t0_epoch = time.time()
total_loss = 0
# Put the model into the training mode
model.train()
# バッチ学習
for step, batch in enumerate(train_dataloader):
# inputデータとoutputデータを分割
b_input_ids, b_labels = tuple(t for t in batch)
# ラベル側をキャストする(そのままだと何故かエラーが出るから)
b_labels: Tensor = b_labels.type(torch.LongTensor)
# データをGPUにわたす。
b_input_ids: Tensor = b_input_ids.to(device)
b_labels: Tensor = b_labels.to(device)
# Zero out any previously calculated gradients
# 1バッチ毎に勾配の値を初期化(累積してく仕組みだから...)
model.zero_grad()
# Perform a forward pass. This will return logits.
# モデルにinputデータを入力して、出力値を得る。
output_pred = model(b_input_ids)
# Compute loss and accumulate the loss values
# 損失関数の値を計算
loss = loss_fn(input=output_pred, target=b_labels)
# 1 epoch全体の損失関数の値を評価する為に、1 batch毎の値を累積していく.
total_loss += loss.item()
# Update parameters(パラメータを更新)
loss.backward() # 誤差逆伝播で勾配を取得
optimizer.step() # 勾配を使ってパラメータ更新
# Calculate the average loss over the entire training data
# 1 epoch全体の損失関数の平均値を計算
avg_train_loss = total_loss / len(train_dataloader)
# =======================================
# Evaluation
# =======================================
# 1 epochの学習が終わる毎に、検証用データを使って汎化性能評価。
if val_dataloader is not None:
# After the completion of each training epoch, measure the model's
# performance on our validation set.
val_loss, val_accuracy = evaluate(
model=model,
val_dataloader=val_dataloader,
device=device
)
# Track the best accuracy
if val_accuracy > best_accuracy:
best_accuracy = val_accuracy
# Print performance over the entire training data
time_elapsed = time.time() - t0_epoch
print(f"the validation result of epoch {epoch_i + 1:^7} is below.")
print(
f'the values of loss function : train(average)={avg_train_loss:.6f}, valid={val_loss:.6f}')
print(
f'accuracy of valid data: {val_accuracy:.2f}, time: {time_elapsed:.2f}')
print('-'*20)
print("\n")
print(f"Training complete! Best accuracy: {best_accuracy:.2f}%.")
# 学習済みのモデルを返す
return model
def evaluate(model: nn.Module, val_dataloader: DataLoader, device: torch.device) -> Tuple[np.ndarray]:
"""各epochの学習が完了した後、検証用データを使ってモデルの汎化性能を評価する。
After the completion of each training epoch, measure the model's
performance on our validation set.
Parameters
----------
model : nn.Module
CNN_NLPオブジェクト。
val_dataloader : DataLoader
検証用のDataLoader
device : torch.device
'cuda' or 'cpu'
Returns
-------
Tuple[np.ndarray]
検証用データセットに対する、モデルの損失関数とAccuracyの値。
"""
# Put the model into the evaluation mode. The dropout layers are disabled
# during the test time.
model.eval()
# Tracking variables
val_accuracy = []
val_loss = []
# For each batch in our validation set...
for batch in val_dataloader:
b_input_ids, b_labels = tuple(t for t in batch)
# ラベル側をキャストする(そのままだと何故かエラーが出るから)
b_labels: Tensor = b_labels.type(torch.LongTensor)
# Load batch to GPU
b_input_ids: Tensor = b_input_ids.to(device)
b_labels: Tensor = b_labels.to(device)
# モデルにinputデータを入力して、出力値を得る。
with torch.no_grad():
output_pred = model(b_input_ids)
# Compute loss
# 損失関数の値を計算
loss: Tensor = loss_fn(output_pred, b_labels)
# 得られたbacth毎の損失関数の値を保存
val_loss.append(loss.item())
# Get the predictions
# 分類問題の予測結果を取得
preds = torch.argmax(output_pred, dim=1).flatten()
# Calculate the accuracy rate(正解率)
preds: Tensor
b_labels: Tensor
accuracy = (preds == b_labels).cpu().numpy().mean() * 100
val_accuracy.append(accuracy)
# Compute the average accuracy and loss over the validation set.
val_loss = np.mean(val_loss)
val_accuracy = np.mean(val_accuracy)
return val_loss, val_accuracy
最後に実行チェック!
上で定義したtrain()関数を用いて、main.py内で、実際にCNNによる文章データの2クラス分類を実行してみます。
# 略(モジュールをimport)
def main():
# 略(文章データをload、適当にlabel作成、tokenize&encode、学習済み埋め込みベクトルをload)
# hold-out法によるtrain test split
train_inputs, val_inputs, train_labels, val_labels = train_test_split(
input_ids, labels, test_size=0.1, random_state=42
)
# DataLoaderオブジェクトを生成。
train_dataloader, val_dataloader = create_data_loaders(
train_inputs=train_inputs,
val_inputs=val_inputs,
train_labels=train_labels,
val_labels=val_labels,
batch_size=50
)
# check the device ('cuda' or 'cpu')
device = torch.device(
'cuda') if torch.cuda.is_available() else torch.device('cpu')
# 乱数シードの固定
set_seed(42)
# CNN_NLPモデルのInitialize
cnn_nlp, optimizer = initilize_model(
pretrained_embedding=embeddings,
freeze_embedding=True,
learning_rate=0.25,
dropout=0.5, device=device
)
cnn_nlp = train(model=cnn_nlp,
optimizer=optimizer,
train_dataloader=train_dataloader,
val_dataloader=val_dataloader,
epochs=20,
device=device
)
# モデルの学習
cnn_static = train(model=cnn_static,
optimizer=optimizer,
train_dataloader=train_dataloader,
val_dataloader=val_dataloader,
epochs=20,
device=device
)
if __name__ == '__main__':
os.chdir('text_cnn_test')
main()
実行結果は以下のようになりました。今回は正解ラベルを適当に付与していますし、精度に関してはなんとも評価しようがありませんが、Accuracyが常に100%なのは計算式がおかしいのでしょうか...?。まあでも今回の目的はCNN_NLPの練習なので、エラーなしで回ったからヨシ!です:)
title description id
0 pirates of the caribbean: at world's end Captain Barbossa, long believed to be dead, ha... 0
1 spider-man 3 The seemingly invincible Spider-Man goes up ag... 1
2 superman returns Superman returns to discover his 5-year absenc... 2
3 quantum of solace Quantum of Solace continues the adventures of ... 3
4 pirates of the caribbean: dead man's chest Captain Jack Sparrow works his way out of a bl... 4
the num of texts data is 2243, and the num of labels is 2243.
Tokenizing...
the num of vocabrary is 15246
max len of texts is 174
the shape of input_ids is (2243, 174)
Loading pretrained vectors...
1999995it [00:30, 65626.75it/s]
There are 15090 / 15248 pretrained vector found.
the shape of embedding_vectors is (15248, 300)
Start training...
------------------------------------------------------------
the validation result of epoch 1 is below.
the values of loss function : train(average)=0.094425, valid=0.014005
accuracy of valid data: 100.00, time: 3.09
--------------------
the validation result of epoch 2 is below.
the values of loss function : train(average)=0.011253, valid=0.004894
accuracy of valid data: 100.00, time: 0.20
--------------------
the validation result of epoch 3 is below.
the values of loss function : train(average)=0.005985, valid=0.002118
accuracy of valid data: 100.00, time: 0.21
--------------------
the validation result of epoch 4 is below.
the values of loss function : train(average)=0.004276, valid=0.001074
accuracy of valid data: 100.00, time: 0.21
--------------------
the validation result of epoch 5 is below.
the values of loss function : train(average)=0.003488, valid=0.000642
accuracy of valid data: 100.00, time: 0.21
--------------------
the validation result of epoch 6 is below.
the values of loss function : train(average)=0.003932, valid=0.000465
accuracy of valid data: 100.00, time: 0.20
--------------------
the validation result of epoch 7 is below.
the values of loss function : train(average)=0.003882, valid=0.000371
accuracy of valid data: 100.00, time: 0.20
--------------------
the validation result of epoch 8 is below.
the values of loss function : train(average)=0.003062, valid=0.000304
accuracy of valid data: 100.00, time: 0.20
--------------------
the validation result of epoch 9 is below.
the values of loss function : train(average)=0.003373, valid=0.000266
accuracy of valid data: 100.00, time: 0.20
--------------------
the validation result of epoch 10 is below.
the values of loss function : train(average)=0.003520, valid=0.000238
accuracy of valid data: 100.00, time: 0.20
--------------------
the validation result of epoch 11 is below.
the values of loss function : train(average)=0.003792, valid=0.000230
accuracy of valid data: 100.00, time: 0.21
--------------------
the validation result of epoch 12 is below.
the values of loss function : train(average)=0.003693, valid=0.000220
accuracy of valid data: 100.00, time: 0.21
--------------------
the validation result of epoch 13 is below.
the values of loss function : train(average)=0.003125, valid=0.000210
accuracy of valid data: 100.00, time: 0.20
--------------------
the validation result of epoch 14 is below.
the values of loss function : train(average)=0.002920, valid=0.000198
accuracy of valid data: 100.00, time: 0.21
--------------------
the validation result of epoch 15 is below.
the values of loss function : train(average)=0.003283, valid=0.000194
accuracy of valid data: 100.00, time: 0.20
--------------------
the validation result of epoch 16 is below.
the values of loss function : train(average)=0.003044, valid=0.000188
accuracy of valid data: 100.00, time: 0.21
--------------------
the validation result of epoch 17 is below.
the values of loss function : train(average)=0.002642, valid=0.000177
accuracy of valid data: 100.00, time: 0.20
--------------------
the validation result of epoch 18 is below.
the values of loss function : train(average)=0.002978, valid=0.000172
accuracy of valid data: 100.00, time: 0.21
--------------------
the validation result of epoch 19 is below.
the values of loss function : train(average)=0.002930, valid=0.000169
accuracy of valid data: 100.00, time: 0.20
--------------------
the validation result of epoch 20 is below.
the values of loss function : train(average)=0.002845, valid=0.000167
accuracy of valid data: 100.00, time: 0.21
--------------------
Training complete! Best accuracy: 100.00%.
また、最終的なディレクトリ構成は、以下のようになっています。
text_cnn_test
│ main.py
│
├─cnn_nlp_model
│ model_cnn_nlp.py
│ predict.py
│ train_nlp_cnn.py
│
├─utils
│ dataloader.py
│ pretrained_vec.py
│ tokenizes.py
│
└─__pycache__
6. 終わりに
今回の記事では「Convolutional Matrix Factorization for Document Context-Aware Recommendation」の理解と実装のパート3として、ConvMFのCNN部分の実装をまとめました。
NLPにおけるCNNを実装するだけで長くなってしまったので、次回は今回実装したCNN_NLPクラスをConvMF用にアレンジしていきます。
おそらくアレンジすべき箇所は、主にCNNのアーキテクチャと損失関数でしょうか:)
あと、今回の実装を通しての感想ですが、以前よりも少しPytorchと仲良くなれた気がします!
最後になりますが、この一連のConvMFの実装経験を通じて、"Ratingデータ"+"アイテムの説明文書"を活用した推薦システムについて実現イメージを得ると共に、"非常に疎な評価行列問題"や"コールドスタート問題"に対応し得る"頑健"な推薦システムについて理解を深めていきたいと思っています:)
理論や実装において、間違っている点や気になる点があれば、ぜひコメントいただけますと嬉しいです:)