はじめに
そういえば自然言語を畳み込んだことなかったなぁと思い、いつ必要になるかわからんので、どんなもんなのか雰囲気を確かめるために実装のお勉強をしてみました。
自分みたいに普段は自然言語処理ばかりしていて、CNNに不慣れな人向けに実装重視で解説してみます。
検証するタスクは、livedoorニュースコーパスの本文をカテゴリに分類する問題とします。
実装環境はGoogle Colabを使っています。
以下の文献を参考にしました!
-
https://arxiv.org/pdf/1510.03820.pdf
CNNで文章分類をしている論文で、今回の実装もこの論文で紹介されているアーキテクチャーを参考にしています。 -
https://tkengo.github.io/blog/2016/03/11/understanding-convolutional-neural-networks-for-nlp/
私みたいにCNNで自然言語処理をしたことがない人はまず一度読んでほしい大変参考になる記事です。
実装
データなどを準備
事前にlivedoorニュースコーパスを以下のようにカテゴリと本文で分けたデータを用意しておきます。
# Google Driveをcolabにマウント
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
import numpy as np
import pickle
# colab上のデータ格納先を指定
drive_dir = "drive/My Drive/Colab Notebooks/livedoor_data/"
with open(drive_dir + "livedoor_data.pickle", 'rb') as r:
livedoor_df = pickle.load(r)
# こんな感じで、categoryと本文(body)に分けたlivedoorニュースデータを事前に用意しておきます。
livedoor_df.sample(n=5).head()
# body category
# 「Ultrabook」の専門コンテンツ「Ultrabooker.jp」(ウルトラブッカージェ... it-life-hack
# GALAPAGOSが大幅値下げ!UQコミュニケーションズは15日、同社のオンラインショップに... smax
# アジア最大の映画の祭典「第24回東京国際映画祭(TIFF)」の開催日程が迫る中、学生応援団の... movie-enter
# 「家電芸人」「雛壇芸人」など、毎回様々なテーマで芸人たちがトークを繰り広げる「アメトーーク!... topic-news
# リニューアルしたPeachy iPhoneアプリの、便利な機能をご紹介します!メニューボタン... peachy
形態素解析の準備
形態素解析はpipで簡単にインストールできるmecabのラッパーであるfugashiを使います。
下記のように辞書も一緒にpipでインストールできます。
!pip install fugashi
!pip install unidic-lite
形態素解析をする関数は以下のように特に前処理などは施さないシンプルなものにしました。
fugashiは以下のように、mecabと同様の使い方ができます。
import fugashi
tagger = fugashi.Tagger("-Owakati")
def make_wakati(text):
text = tagger.parse(text)
wakati = text.split(" ")
wakati = list(filter(("").__ne__, wakati))
return wakati
# 形態素解析テスト
text = livedoor_df.sample(n=1)['body'].item()
print(make_wakati(text)[:30])
# ['小腹', 'の', '空い', 'た', 'とき', 'に', 'つまみ', 'たく', 'なる', '人気', 'の', 'スナック', '菓子', 'と', 'いえ', 'ば', '「', 'ポテト', 'チップス', '」', '。', 'ついつい', '食べ', 'て', 'しまう', 'けれど', '、', '一', '袋', '空け']
torchtextでDataLoaderを作成
livedoorニュースコーパスを学習データ、検証データ、テストデータの3つに分割しています。
CNNの実装を確かめることがメインなので、単語ベクトルも今回はとりあえず学習データからvocabularyを生成して、ランダムなベクトルを扱うことにします。また、文章の最大長を指定するmax_lengthなどは特に指定していません。
from sklearn.model_selection import train_test_split
from torchtext.legacy import data
# カテゴリーをidに変換します。
categories = livedoor_df['category'].unique().tolist()
livedoor_df['category_id'] = livedoor_df['category'].map(lambda x: categories.index(x))
# 元データを学習、検証、テストの3つに分割します。
train_val_df, test_df = train_test_split(livedoor_df[['body', 'category_id']], train_size=0.8)
train_df, val_df = train_test_split(train_val_df, train_size=0.75)
print('train size', train_df.shape)
print('validation size', val_df.shape)
print('test size', test_df.shape)
# train size (4425, 2)
# validation size (1475, 2)
# test size (1476, 2)
# torchtext用にtsvファイルで保存します。
train_df.to_csv(drive_dir + 'train.tsv', sep='\t', index=False, header=None)
val_df.to_csv(drive_dir + 'val.tsv', sep='\t', index=False, header=None)
test_df.to_csv(drive_dir + 'test.tsv', sep='\t', index=False, header=None)
TEXT = data.Field(sequential=True, tokenize=make_wakati, lower=False, batch_first=True, pad_token='<pad>')
LABEL = data.Field(sequential=False, use_vocab=False)
train_data, val_data, test_data = data.TabularDataset.splits(
path=drive_dir, train='train.tsv', validation='val.tsv', test='test.tsv', format='tsv', fields=[('Text', TEXT), ('Label', LABEL)])
# vocabulary生成
# 学習データだけでvocabを作成します。
TEXT.build_vocab(train_data, min_freq=1)
BATCH_SIZE = 64
train_loader = data.Iterator(train_data, batch_size=BATCH_SIZE, train=True)
val_loader = data.Iterator(val_data, batch_size=BATCH_SIZE, train=False, sort=False)
test_loader = data.Iterator(test_data, batch_size=BATCH_SIZE, train=False, sort=False)
CNNによるモデルの定義
自然言語処理におけるCNNの実装解説
自然言語処理では文章を行列(単語ベクトルの集まり)として扱うことが多いですが、その行列を(チャネル1の)画像とみなせば、自然言語に対してCNNを適用することができます。
適用するフィルター(カーネル)は画像処理であれば、以下のアニメーションのように画像の区間を右に下にスライドして畳み込み演算を行いますが
(http://deeplearning.stanford.edu/tutorial/supervised/FeatureExtractionUsingConvolution/ から引用)
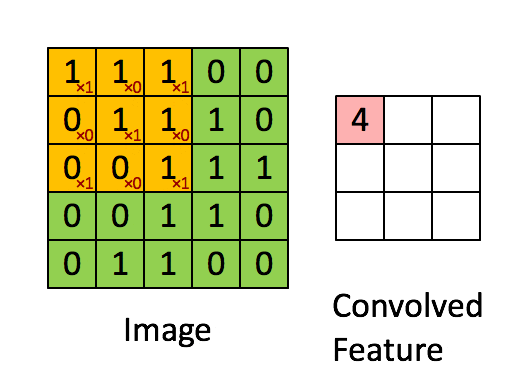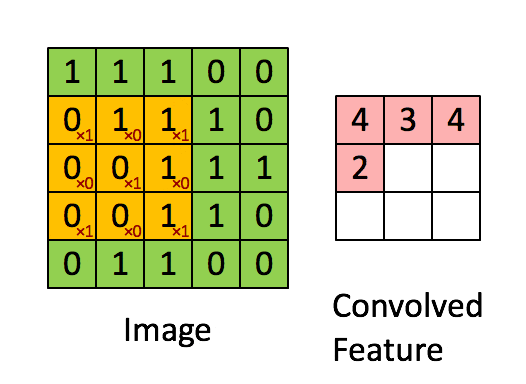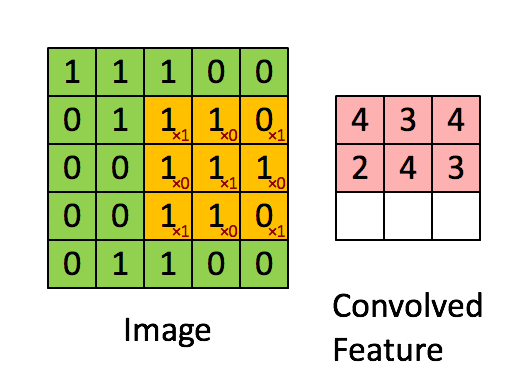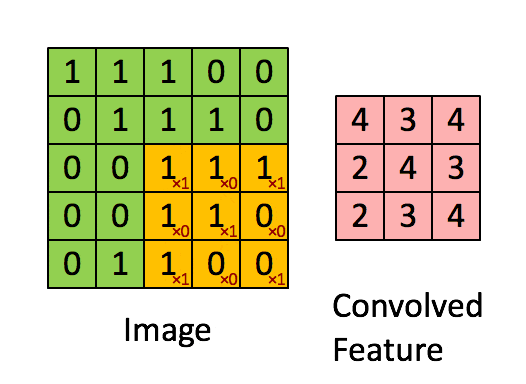
自然言語では、以下のように単語ベクトル方向(行方向)全体に対して、隣接する単語ベクトルをひとまとまりにして畳み込むようです。(以下のgifは自作しました。)
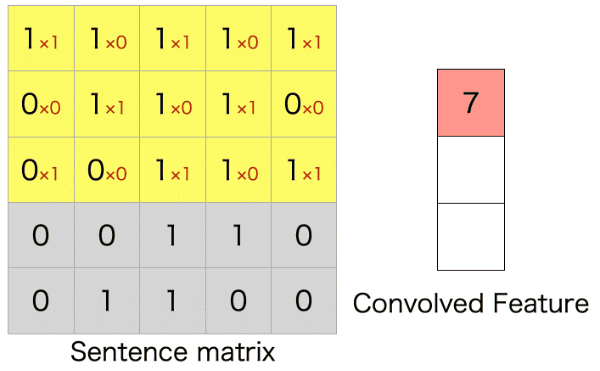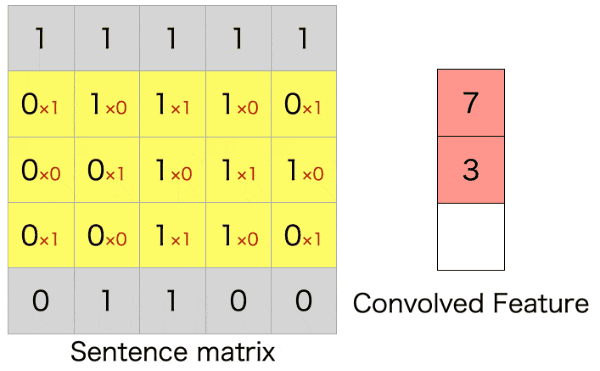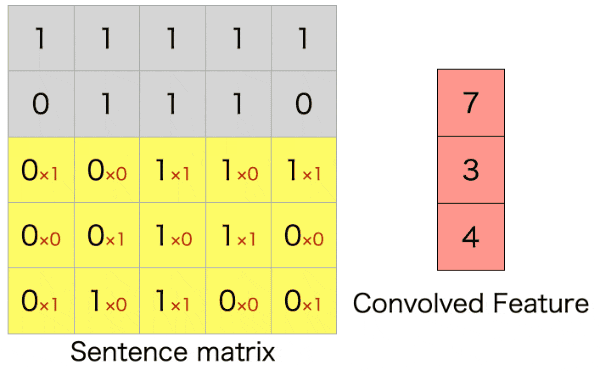
上のアニメーションは5$\times$5の文章の行列に対して、3$\times$5のフィルターをストライド1で畳み込んだ例になります。行方向全体に対して畳み込んでいるので、特徴マップ(Convolved Feature)はベクトルとして出力されます。
CNNで文章分類といっても、参考文献2.のように手法は色々あるようですが、今回参考にしたネットワークは参考文献1.の論文に記載されている以下のものです。
(説明しやすくするために、論文の図に番号と青い網掛けを施しています。)
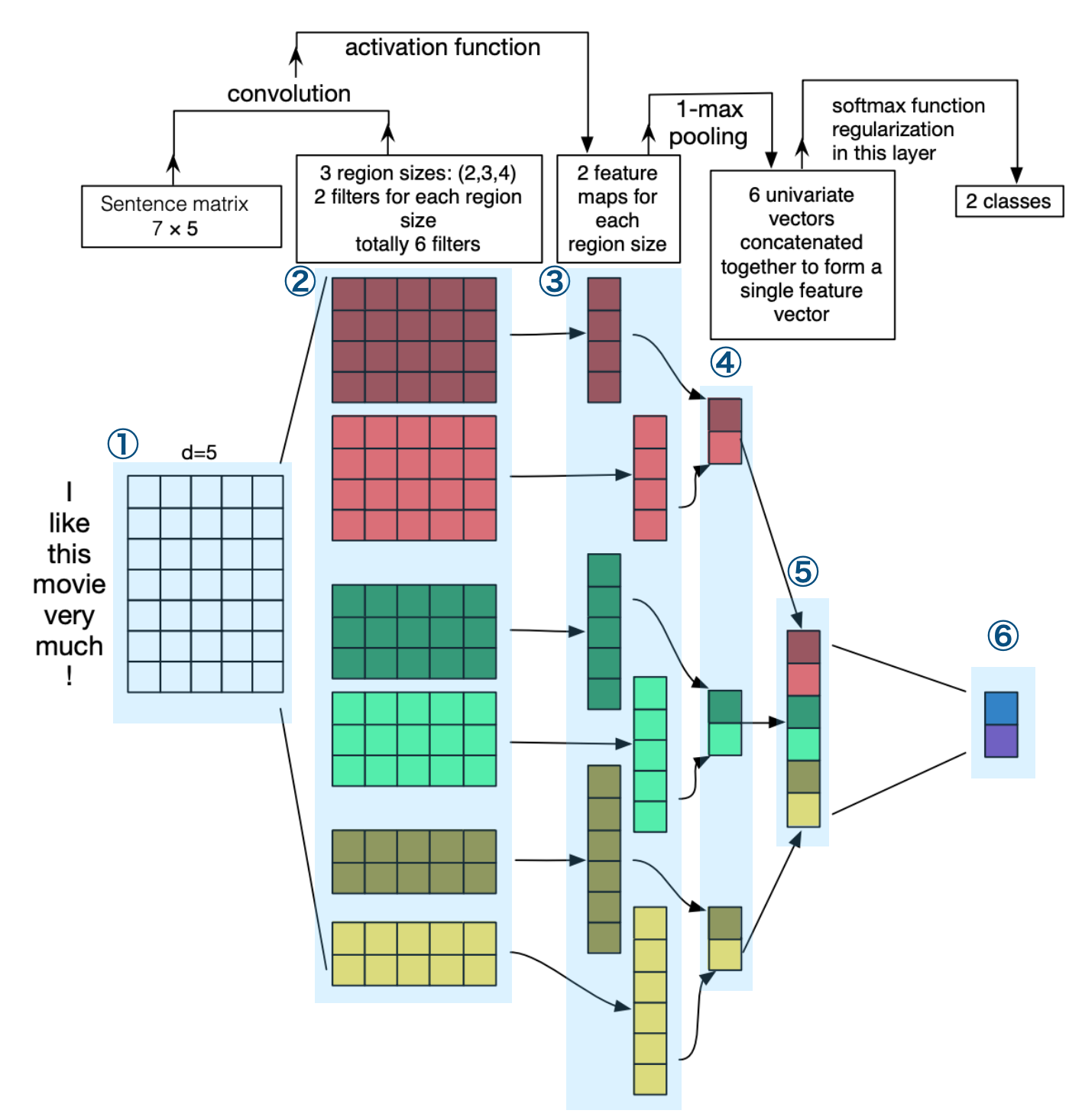
(↓論文に記載されている上図の説明文のDeepLによる翻訳)
文章分類のためのCNNアーキテクチャの説明図。3つのフィルタ領域サイズを描いている。
2、3、4の3種類のフィルター領域があり、それぞれに2つのフィルターがある。フィルターは文の行列に畳み込みをかけ、(可変長の)特徴マップを生成する。 各マップに対して1-maxプーリングを行い、各特徴マップから最大の数を記録する。 つまり、各特徴マップからの最大数が記録されます。このようにして、6つのマップすべてから一変量の特徴ベクトルが生成され、これらの 6つの特徴が連結され、最後の層の特徴ベクトルが形成されます。最後のソフトマックス層は は、この特徴ベクトルを入力として受け取り、それを使って文を分類します。ここでは2値分類を想定しているため、2つの出力状態が考えられます。
図や上の説明文でネットワークについては十分説明されていると思うのですが、理解を深めるために上の図の赤色の2つのフィルターを畳み込んでいる部分について、①〜④まで処理をPyTorchで実装しながら動きを確認してみます。
まずは文章の行列を用意します。要素がランダムなミニバッチサイズ2の7$\times$5の行列を用意しています。
自然言語処理で考えると、長さが7, 単語のベクトル次元数が5の文章を2つ用意した、ということになります。
import torch
import torch.nn as nn
mat = torch.rand(2, 7, 5)
print(mat.size())
# torch.Size([2, 7, 5])
print(mat)
# tensor([[[0.7829, 0.7500, 0.0219, 0.9649, 0.7882],
# [0.3702, 0.4209, 0.4233, 0.9416, 0.2782],
# [0.0063, 0.6495, 0.6619, 0.7269, 0.4565],
# [0.3230, 0.5307, 0.4363, 0.1298, 0.6383],
# [0.4901, 0.4339, 0.0146, 0.0567, 0.2657],
# [0.0016, 0.6974, 0.0411, 0.5870, 0.9980],
# [0.5924, 0.9639, 0.8020, 0.1496, 0.8250]],
#
# [[0.3794, 0.4447, 0.9487, 0.2464, 0.9708],
# [0.9758, 0.2641, 0.1398, 0.2571, 0.4791],
# [0.6313, 0.0070, 0.8250, 0.6199, 0.3993],
# [0.6212, 0.0736, 0.5846, 0.0366, 0.3479],
# [0.2804, 0.3105, 0.4070, 0.8294, 0.7184],
# [0.2304, 0.5620, 0.6029, 0.1019, 0.1179],
# [0.2298, 0.4102, 0.8991, 0.7467, 0.3501]]])
②でこの文章を畳み込みます。畳み込みフィルターのサイズは図の通り、4$\times$5とし、ストライドは1とします。このフィルターを2枚畳み込みたいので、アウトプットのチャネルは2を指定すればOK。
自然言語処理でnn.LSTMなどを扱うとき、インプットの形式は(batch_first=Trueを指定した場合)ミニバッチサイズ×文章の長さ×単語ベクトル次元数のテンソルを扱いますが、nn.Conv2dのインプットの形式はミニバッチサイズ×チャネル数×高さ×幅である必要があります。なので、下記のようにmat.unsqueeze(1)をしてミニバッチサイズの次にチャネル1の次元を追加しています。
# 第1引数はインプットのチャネル(今回は1)を指定
# 自然言語処理で畳み込む場合、異なる単語分散表現(word2vecとfasttextみたいな)などを使って、
# 複数チャネルとみなす方法もあるようです。
# 第2引数はアウトプットのチャネル数で、今回は同じフィルターを2枚畳み込みたいので、2を指定
# カーネルサイズは高さ×幅を指定しており、幅は図で説明した通り、単語ベクトルの次元数5を指定
conv = nn.Conv2d(1, 2, kernel_size=(4, 5))
# チャネル数1を挿入
mat = mat.unsqueeze(1)
print(mat.size())
# torch.Size([2, 1, 7, 5])
# ↑ミニバッチサイズ×チャネル数×文章の長さ×単語ベクトル次元数
# 畳み込む
feature = conv(mat)
print(feature.size())
# torch.Size([2, 2, 4, 1])
# ↑ミニバッチサイズ×特徴マップの数×(特徴マップの形式4×1)
print(feature)
# tensor([[[[ 0.0485],
# [ 0.2434],
# [-0.3744],
# [-0.0895]],
#
# [[-0.2727],
# [ 0.1079],
# [-0.0427],
# [ 0.1704]]],
#
#
# [[[ 0.0854],
# [ 0.0208],
# [ 0.0618],
# [ 0.1806]],
#
# [[ 0.0054],
# [-0.2124],
# [-0.0473],
# [-0.0413]]]], grad_fn=<MkldnnConvolutionBackward>)
上で得られた2つの特徴マップを活性化関数に通して③が出来上がります。
import torch.nn.functional as F
feature = F.relu(feature)
print(feature.size())
# ↑ミニバッチサイズ×特徴マップの数×(特徴マップの形式4×1)
print(feature)
# reluに通したので負の要素は0になりますね。
# torch.Size([2, 2, 4, 1])
# tensor([[[[0.0485],
# [0.2434],
# [0.0000],
# [0.0000]],
#
# [[0.0000],
# [0.1079],
# [0.0000],
# [0.1704]]],
#
#
# [[[0.0854],
# [0.0208],
# [0.0618],
# [0.1806]],
#
# [[0.0054],
# [0.0000],
# [0.0000],
# [0.0000]]]], grad_fn=<ReluBackward0>)
最後に④を得るために、1-max poolingを行います。ここですることは要は各特徴マップの最大要素を抽出することになります。つまりnn.MaxPool2dを使って、
# nn.MaxPool1dでも良いですが、そのときは上のfeatureに対して
# feauture.unsqueeze(-1)をして最後の次元の1を除去しましょう。
pool = nn.MaxPool2d(kernel_size=(4, 1))
print(pool(feature))
# tensor([[[[0.2434]],
#
# [[0.1704]]],
#
#
# [[[0.1806]],
#
# [[0.0054]]]], grad_fn=<MaxPool2DWithIndicesBackward>)
としたくなりますが、上のpoolingのカーネルサイズ(上の4のところ)はインプットとなる特徴マップのサイズに依存するんですよね。図にもあるように特徴マップのサイズは元の文章の長さ(最初の行列の行方向)と畳み込みフィルターのサイズに依存するので、上のようにnn.MaxPool2dでpoolingするレイヤーのインスタンスを宣言しちゃうと、poolingのカーネルサイズを可変にできないので、F.max_pool2dを使って以下のようにpoolingする際、インプットとなる特徴マップのサイズを指定するようにします。
# feature.size()[2]で特徴マップの高さを取得しています。
feature = F.max_pool2d(feature, kernel_size=(feature.size()[2], 1))
print(feature.size())
# torch.Size([2, 2, 1, 1])
print(feature)
# tensor([[[[0.2434]],
#
# [[0.1704]]],
#
#
# [[[0.1806]],
#
# [[0.0054]]]], grad_fn=<MaxPool2DWithIndicesBackward>)
# viewを使って次元数を整頓します。
feature = feature.view(-1, 2)
print(feature.size())
# torch.Size([2, 2])
print(feature)
# tensor([[0.2434, 0.1704],
# [0.1806, 0.0054]], grad_fn=<ViewBackward>)
これで④を得ることができました。あとは同様のことを異なる畳み込みフィルターにも適用して、最後に要素を結合して全結合層にぶち込めばOKですね。
ネットワークの定義
上の処理をまとめて、残り⑤、⑥の処理を加えると以下のようなクラスとしてネットワークを実装できるかと思います。
(論文ではdropoutとかも入れてますが、今回は入れていません。)
class Net(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(Net, self).__init__()
# 単語分散表現はランダムベクトルを使う
self.embeddings = nn.Embedding(vocab_size, embedding_dim, padding_idx=TEXT.vocab.stoi['<pad>'])
# 図の黄色い畳み込みフィルター
self.conv1 = nn.Conv2d(1, 2, kernel_size=(2, embedding_dim))
# 図の緑色の畳み込みフィルター
self.conv2 = nn.Conv2d(1, 2, kernel_size=(3, embedding_dim))
# 図の赤色の畳み込みフィルター
self.conv3 = nn.Conv2d(1, 2, kernel_size=(4, embedding_dim))
# 3つ畳み込みの処理でそれぞれ2次元のベクトルが生成されるので、それらを全て結合して6次元のベクトルとなります。
# livedoorのカテゴリは9つなので、アウトプットサイズは9を指定
self.linear = nn.Linear(6, 9)
def forward(self, input_ids):
# ①文章の行列を取得
out = self.embeddings(input_ids)
# チャネル数1を挿入
out = out.unsqueeze(1)
# ②畳み込んでreluに通す
out1 = F.relu(self.conv1(out))
out2 = F.relu(self.conv2(out))
out3 = F.relu(self.conv3(out))
# ③poolingして、各特徴マップの最大要素を取得
out1 = F.max_pool2d(out1, kernel_size=(out1.size()[2], 1))
out2 = F.max_pool2d(out2, kernel_size=(out2.size()[2], 1))
out3 = F.max_pool2d(out3, kernel_size=(out3.size()[2], 1))
# ④viewして次元を整えてあげる
out1 = out1.view(-1, 2)
out2 = out2.view(-1, 2)
out3 = out3.view(-1, 2)
# ⑤全部結合して1本のベクトルにする
out = torch.cat([out1, out2, out3], dim=1)
# ⑥全結合層で9つのカテゴリー分類できるように変換
out = self.linear(out)
return out
学習
あとはこのネットワークでちゃんと学習できるか確かめて精度を確認して終わりです。
学習部分は以下のように実装しました。
学習データ、検証データともに順調に損失は減っていきますが、検証データの損失が最後らへんで増えてしまいます。エポック数30はちょっと多かったかもです。
import torch.optim as optim
VOCAB_SIZE = len(TEXT.vocab.stoi)
EMBEDDING_DIM = 200
net = Net(VOCAB_SIZE, EMBEDDING_DIM)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
# GPUの設定
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
# ネットワークをGPUへ送る
net.to(device)
train_loss = []
val_loss = []
train_accuracy = []
val_accuracy = []
for epoch in range(30):
# 学習
_train_loss = 0.0
_train_acc = 0.0
net.train()
for batch in train_loader:
inputs = batch.Text.to(device)
y = batch.Label.to(device)
optimizer.zero_grad()
out = net(inputs)
loss = loss_function(out, y)
_, preds = torch.max(out, 1)
loss.backward()
optimizer.step()
_train_loss += loss.item()
_train_acc += torch.sum(preds == y).item()
train_loss.append(_train_loss)
train_epoch_acc = _train_acc / len(train_loader.dataset)
train_accuracy.append(train_epoch_acc)
# 検証
_val_loss = 0.0
_val_acc = 0.0
net.eval()
with torch.no_grad():
for batch in val_loader:
inputs = batch.Text.to(device)
y = batch.Label.to(device)
out = net(inputs)
loss = loss_function(out, y)
_, preds = torch.max(out, 1)
_val_loss += loss.item()
_val_acc += torch.sum(preds == y).item()
val_loss.append(_val_loss)
val_epoch_acc = _val_acc / len(val_loader.dataset)
val_accuracy.append(val_epoch_acc)
print("epoch", epoch,
"\ttrain loss", round(_train_loss, 4), "\ttrain accuracy", round(train_epoch_acc, 4),
"\tval loss", round(_val_loss, 4), "\tval accuracy", round(val_epoch_acc, 4))
# cuda:0
# epoch 0 train loss 157.78 train accuracy 0.1205 val loss 47.3475 val accuracy 0.1858
# epoch 1 train loss 118.2377 train accuracy 0.3776 val loss 32.1798 val accuracy 0.5973
# epoch 2 train loss 85.6465 train accuracy 0.6454 val loss 26.0927 val accuracy 0.6739
# 〜省略〜
# epoch 26 train loss 6.5183 train accuracy 0.9853 val loss 14.9468 val accuracy 0.8203
# epoch 27 train loss 5.8604 train accuracy 0.9869 val loss 15.0671 val accuracy 0.8231
# epoch 28 train loss 5.3537 train accuracy 0.988 val loss 15.1578 val accuracy 0.8183
# epoch 29 train loss 5.0279 train accuracy 0.9896 val loss 15.6059 val accuracy 0.819
精度確認
最後にテストデータによる精度(Fスコア)を確認しましょう。
(30epoch学習した後に対する)全体のFスコアが0.77となりました。
BERT使えばFスコア0.9を超えるので、livedoorニュースコーパスの本文のカテゴリー分類問題としてはあまり良い値とは言えないですね。色々とチューニングが必要ですが、まぁ実装の確認という意味では良しとしましょう。
# 精度確認
from sklearn.metrics import classification_report
with torch.no_grad():
test_loss = 0.0
net.eval()
prediction = []
answer = []
for batch in test_loader:
input_ids = batch.Text.to(device)
y = batch.Label.to(device)
out = net(input_ids)
_, preds = torch.max(out, 1)
prediction += list(preds.cpu().numpy())
answer += list(y.cpu().numpy())
print(classification_report(prediction, answer, target_names=categories))
# precision recall f1-score support
#
# movie-enter 0.86 0.86 0.86 166
# it-life-hack 0.84 0.74 0.79 198
# kaden-channel 0.78 0.85 0.81 155
# topic-news 0.78 0.91 0.84 148
# livedoor-homme 0.58 0.44 0.50 141
# peachy 0.55 0.64 0.59 151
# sports-watch 0.79 0.76 0.77 174
# dokujo-tsushin 0.70 0.73 0.72 173
# smax 0.99 0.96 0.97 170
#
# accuracy 0.77 1476
# macro avg 0.76 0.76 0.76 1476
# weighted avg 0.77 0.77 0.77 1476
おわりに
自然言語処理に対するCNNの適用例ということでCNNによる文章分類の実装を確認しました。
正直今はAttentionだのBERTだの強力なアルゴリズムがあるので、CNNで文章分類する機会はあまりないかもしれませんが、急に文章を畳み込みたい衝動に駆られても対処できそうです。
おわり