はじめに
この記事は、機械学習とRaspberry Piを用いてレーザー加工機の動作状態を音で判定することに機械学習の非専門家がチャレンジするシリーズの3回目です(第1回、第2回)。前回まででmacOS上でのひとまずの動作確認ができましたので、今回は実際にRaspberry Pi上で動作させます。

準備
オーディオ関係のインストール
以前の記事「Raspberry Pi 3 Model BとReSpeaker 2-Mics Pi HATでGoogle Assistant SDKを活用する」で紹介した手順に従ってReSpeaker 2-Mics Pi HATを使用するための準備を済ませたあと、PyAudioとlibrosaのインストールを済ませます(librosaのインストール時に与えているオプションについてはこちらの記事で解説しています)。以上でオーディオ関係のインストールは完了です。
$ sudo apt-get install python3-pyaudio
...
Setting up python3-pyaudio (0.2.11-1) ...
$ sudo pip3 install resampy==0.1.5 librosa
...
Installing collected packages: Cython, scipy, resampy, joblib, decorator, audioread, scikit-learn, librosa
Successfully installed Cython-0.27.3 audioread-2.1.5 decorator-4.1.2 joblib-0.11 librosa-0.5.1 resampy-0.1.5 scikit-learn-0.19.1 scipy-1.0.0
機械学習関係のインストール
kazunori279さんの記事「RasPiでKeras/TensorFlowを動かす」からリンクされているPete Wardenのブログ記事「Cross-compiling TensorFlow for the Raspberry Pi」に書かれている方法でTensorFlowをインストールします。この記事は2017年8月の公開後に更新されており、以下のようにすることでPython 3.5が動作する環境にTensorFlow 1.4.0をインストールできます(記事中のpipはpip3に変更しています)。
$ sudo apt-get install libblas-dev liblapack-dev python-dev libatlas-base-dev gfortran python-setuptools
$ curl -O http://ci.tensorflow.org/view/Nightly/job/nightly-pi-python3/lastSuccessfulBuild/artifact/output-artifacts/tensorflow-1.4.0-cp34-none-any.whl
$ mv tensorflow-1.4.0-cp34-none-any.whl tensorflow-1.4.0-cp35-none-any.whl
$ sudo pip3 install tensorflow-1.4.0-cp35-none-any.whl
Processing ./tensorflow-1.4.0-cp35-none-any.whl
Requirement already satisfied: numpy>=1.12.1 in /usr/lib/python3/dist-packages (from tensorflow==1.4.0)
...
Successfully installed absl-py-0.1.6 bleach-1.5.0 html5lib-0.9999999 markdown-2.6.9 protobuf-3.5.0.post1 tensorflow-1.4.0 tensorflow-tensorboard-0.1.8
次に、Kerasをインストールします。Kerasが依存するh5pyはaptでインストールしたのち、Keras本体をpip3でインストールします。
$ sudo apt-get install python3-h5py
...
Setting up python3-h5py (2.7.0-1) ...
Processing triggers for libc-bin (2.24-11+deb9u1) ...
$ sudo pip3 install keras
...
Successfully installed keras-2.1.2 pyyaml-3.12
最後に、Kerasのためにスワップ領域を拡大しておきます。sudo nano /etc/dphys-swapfileで設定ファイルを開き、CONF_SWAPSIZE=100(約100 MB)となっている初期設定をCONF_SWAPSIZE=1000(約1 GB)に変更します。変更が終わったら、sudo /etc/init.d/dphys-swapfile restartでスワップ領域の変更を有効にします。
$ sudo nano /etc/dphys-swapfile
$ sudo /etc/init.d/dphys-swapfile restart
以上で一通りのインストールが終わりましたので、macOS上で動作確認していたサンプルをRaspberry Pi上に転送して動かしてみます。macOSとRaspberry Piの間でファイルをやり取りする場合には、オープンソースのAFPサーバ「Netatalk」をインストールしておくと、macOS上のFinderの移動メニュー>ネットワークで簡単にアクセスできるので便利です(Windowsのためにsambaをセットアップする方法は以前の記事で説明しています)。
$ sudo apt-get install netatalk
macOS上で動作するAtomなどのエディタで直接Raspberry Pi上のファイルを開いて編集することも可能ですので、使い慣れたエディタで変更を加えながら実機で動作確認できます。
検証
実機での動作検証
それでは、いよいよ実際に動かしてみましょう!すると、警告に続いてエラーが表示され終了してしまいます…。気を取り直して内容を確認します。
$ python3 predict.py
Using TensorFlow backend.
/usr/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: compiletime version 3.4 of module 'tensorflow.python.framework.fast_tensor_util' does not match runtime version 3.5
return f(*args, **kwds)
/usr/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: builtins.type size changed, may indicate binary incompatibility. Expected 432, got 412
return f(*args, **kwds)
RuntimeError: module compiled against API version 0xb but this version of numpy is 0xa
RuntimeError: module compiled against API version 0xb but this version of numpy is 0xa
Traceback (most recent call last):
...
ImportError: numpy.core.multiarray failed to import
まず、ここで表示されている警告は既知の問題です。Pete Wardenのブログ記事でも以下のように説明されています。この警告に関してはひとまず無視することにします。
If you’re running Python 3.5, you can use the same wheel but with a slight change to the file name, since that encodes the version. You will see a couple of warnings every time you import tensorflow, but it should work correctly.
次に、numpyに関するエラーはlibrosaをインストールした時にインストールされたバージョン(1.12.1)と、Raspberry Pi用にあらかじめビルドされたTensorFlowが期待しているバージョンが適合しないために発生しているようです。この問題を解決するには、以下のようにしてnumpyを最新版へと更新します。
$ sudo pip3 install --upgrade numpy
...
Successfully installed numpy-1.13.3
再度試してみると、今度は無事にサンプルが動きました。
$ python3 predict.py
Using TensorFlow backend.
...
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 128) 16640
_________________________________________________________________
dense_2 (Dense) (None, 64) 8256
_________________________________________________________________
dense_3 (Dense) (None, 6) 390
=================================================================
Total params: 25,286
Trainable params: 25,286
Non-trainable params: 0
_________________________________________________________________
Background (0.993, processed in 0.271 seconds)
CHANGED: Unknown > Background
Background (1.000, processed in 0.085 seconds)
Background (0.819, processed in 0.072 seconds)
Background (0.875, processed in 0.085 seconds)
Background (0.716, processed in 0.085 seconds)
Background (0.896, processed in 0.085 seconds)
...
この状態で実際にレーザー加工機を動作させてみると、以下のように変化することが確認できました(変化の前後のみ抜粋しています)。実際に行った加工としてはBackground(背景音)>Sleeping(スリープ中)>Waiting(待機中)>Marking(マーキング)>Cutting in focus(切断加工・焦点OK)>Cutting out focus(切断加工・焦点NG)>Cutting in focus>Waiting>Sleeping>Backgroundです。途中の変化を確認すると、第2回で懸念していたようにCutting in focusと判断されるべき状態でMarkingと誤認識されることがしばしばありました。
Background (0.993, processed in 0.183 seconds)
CHANGED: Unknown > Background
Background (0.984, processed in 0.081 seconds)
...
Sleeping (0.931, processed in 0.084 seconds)
CHANGED: Background > Sleeping
Sleeping (0.958, processed in 0.085 seconds)
...
Background (0.855, processed in 0.084 seconds)
CHANGED: Sleeping > Background
Waiting (0.731, processed in 0.086 seconds)
Background (0.451, processed in 0.086 seconds)
Waiting (0.839, processed in 0.073 seconds)
CHANGED: Background > Waiting
Waiting (0.731, processed in 0.085 seconds)
...
Sleeping (0.859, processed in 0.087 seconds)
CHANGED: Waiting > Sleeping
Sleeping (0.888, processed in 0.092 seconds)
...
Background (0.843, processed in 0.084 seconds)
CHANGED: Sleeping > Background
Sleeping (0.488, processed in 0.090 seconds)
Sleeping (0.737, processed in 0.087 seconds)
Sleeping (0.837, processed in 0.077 seconds)
CHANGED: Background > Sleeping
Sleeping (0.756, processed in 0.089 seconds)
...
Waiting (0.910, processed in 0.085 seconds)
CHANGED: Sleeping > Waiting
Waiting (0.848, processed in 0.084 seconds)
...
Marking (0.887, processed in 0.087 seconds)
CHANGED: Waiting > Marking
Marking (0.783, processed in 0.084 seconds)
...
Marking (0.919, processed in 0.086 seconds)
Cutting in focus (0.544, processed in 0.085 seconds)
Marking (0.624, processed in 0.078 seconds)
...
Cutting in focus (0.849, processed in 0.085 seconds)
CHANGED: Marking > Cutting in focus
Marking (0.869, processed in 0.084 seconds)
CHANGED: Cutting in focus > Marking
Cutting in focus (0.558, processed in 0.086 seconds)
Marking (0.636, processed in 0.085 seconds)
Marking (0.580, processed in 0.086 seconds)
Cutting in focus (0.894, processed in 0.085 seconds)
CHANGED: Marking > Cutting in focus
Marking (0.875, processed in 0.086 seconds)
CHANGED: Cutting in focus > Marking
Marking (0.656, processed in 0.086 seconds)
Marking (0.546, processed in 0.087 seconds)
Marking (0.690, processed in 0.085 seconds)
Cutting in focus (0.844, processed in 0.079 seconds)
CHANGED: Marking > Cutting in focus
Marking (0.740, processed in 0.079 seconds)
Marking (0.502, processed in 0.087 seconds)
Marking (0.599, processed in 0.075 seconds)
Marking (0.571, processed in 0.087 seconds)
Cutting in focus (0.778, processed in 0.086 seconds)
Marking (0.815, processed in 0.080 seconds)
CHANGED: Cutting in focus > Marking
Marking (0.553, processed in 0.086 seconds)
...
Marking (0.886, processed in 0.083 seconds)
CHANGED: Cutting in focus > Marking
Waiting (0.615, processed in 0.070 seconds)
Cutting out focus (0.546, processed in 0.072 seconds)
Cutting out focus (0.958, processed in 0.081 seconds)
CHANGED: Marking > Cutting out focus
Cutting out focus (0.854, processed in 0.086 seconds)
...
Marking (0.810, processed in 0.072 seconds)
CHANGED: Cutting out focus > Marking
Marking (0.918, processed in 0.088 seconds)
Marking (0.630, processed in 0.086 seconds)
Marking (0.903, processed in 0.085 seconds)
Marking (0.729, processed in 0.088 seconds)
Cutting in focus (0.912, processed in 0.086 seconds)
CHANGED: Marking > Cutting in focus
Marking (0.536, processed in 0.085 seconds)
Marking (0.487, processed in 0.085 seconds)
Waiting (0.872, processed in 0.089 seconds)
CHANGED: Cutting in focus > Waiting
Waiting (0.918, processed in 0.070 seconds)
...
Background (0.872, processed in 0.086 seconds)
CHANGED: Waiting > Background
Waiting (0.910, processed in 0.075 seconds)
CHANGED: Background > Waiting
Waiting (0.852, processed in 0.084 seconds)
...
Sleeping (0.938, processed in 0.084 seconds)
CHANGED: Waiting > Sleeping
Sleeping (0.930, processed in 0.073 seconds)
...
Background (0.817, processed in 0.084 seconds)
CHANGED: Sleeping > Background
Background (0.756, processed in 0.087 seconds)
...
別データでの学習
この点についてスタッフと議論したところ、Cutting in focus(切断加工・焦点OK)とCutting out focus(切断加工・焦点NG)で使用したデータでは短い区間での移動が多く、そのためにマーキングとの差が出にくくなってしまっているのではないか、という仮説が浮上しました。
そこで、加工時のパスを変更し、急なヘッドの移動が発生しないようなスパイラル状のパスに変更しました。
この2つのパスで学習させた結果を比較したものが次のようになります。微妙な違いはあるものの、全体的な傾向は同じでした。
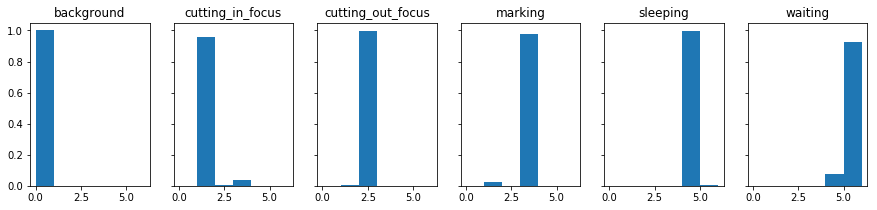

実験
ReSpeaker 2-Mics Pi HATに搭載されているLEDの制御
これまでは1秒ごとの判定結果をターミナル上で確認していました。レーザー加工機の動作中にReSpeaker 2-Mics Pi HATに搭載されているLEDの色で確認できるようにしました。
まず、ReSpeaker 2-Mics Pi HATの説明に従い、raspi-configで5 Interfacing Options>P4 SPIとメニューをたどり、Would you like the SPI interface to be enabled?に対してYesで回答してSPIを有効に設定したのち、サンプルを取得します(今回セットアップした環境ではspidevは既にインストール済みでした)。
$ git clone https://github.com/respeaker/mic_hat.git
$ sudo pip install spidev
次に、サンプルで動作を確認します。以下のように実行してLEDが点灯すればSPIの設定およびspidevのインストールなどは正常に完了しています。
$ cd mic_hat
$ python pixels.py
ライブラリapa102の使い方はとても簡単で、以下のようにすることで0番目のLEDの色を赤に設定できます。
import apa102
leds = apa102.APA102(num_led=3)
leds.set_pixel(0, 255, 0, 0)
IFTTTとの連携
さらに、長期的に記録を取りつつ安定性などについても確認するため、60秒ごとに最も頻度が高かった状態を求め、Googleスプレッドシートで記録できるようにしたいと思います。Googleスプレッドシートを手軽に利用するために、ウェブサービス同士を組み合わせて自家製のサービスをつくれるウェブサービス「IFTTT」を使います。IFTTTは自家製のデバイスに対応できるサービスとしてWebhooksを提供しています。このサービスを有効に設定し、画面右上のDocumentationをクリックすることにより、このサービスを利用するためのキーと利用方法を同時に確認できます。


Pythonでの実装は非常に簡単で、イベント名をlaser_machine_state、value1をBackgroundでトリガーを発生させたいのであればrequestsライブラリを利用して以下のようにするだけです。
import requests
IFTTT_EVENT = 'laser_machine_state'
IFTTT_KEY = '*********************'
IFTTT_URL = 'https://maker.ifttt.com/trigger/{event}/with/key/{key}'.format(
event=IFTTT_EVENT, key=IFTTT_KEY)
data = {}
data['value1'] = 'Background'
response = requests.post(IFTTT_URL, data=data)
あとは、Webhooksをトリガー、Google Sheetsをアクションとするアプレットをつくることにより、トリガーが発生する度にGoogleスプレッドシートで記録できるようになります。
実装
以上を統合したものが以下のコードです。
import numpy as np
import keras
import librosa
import pyaudio
import time
import requests
import apa102
model = keras.models.load_model('laser_machine.h5')
print(model.summary())
IFTTT_EVENT = 'laser_machine_state'
IFTTT_KEY = '*********************'
IFTTT_URL = 'https://maker.ifttt.com/trigger/{event}/with/key/{key}'.format(
event=IFTTT_EVENT, key=IFTTT_KEY)
def make_web_request(state):
data = {}
data['value1'] = state
try:
response = requests.post(IFTTT_URL, data=data)
print('{0.status_code}: {0.text}'.format(response))
except:
print('Failed to make a web request')
leds = apa102.APA102(num_led=3)
def set_leds(state):
if state == STATES.index('Background'):
red, green, blue = 0, 0, 0
elif state == STATES.index('Cutting in focus'):
red, green, blue = 0, 0, 255
elif state == STATES.index('Cutting out focus'):
red, green, blue = 255, 0, 0
elif state == STATES.index('Marking'):
red, green, blue = 0, 255, 0
elif state == STATES.index('Sleeping'):
red, green, blue = 255, 255, 255
elif state == STATES.index('Waiting'):
red, green, blue = 255, 200, 80
elif state == STATES.index('Unknown'):
red, green, blue = 0, 0, 0
for led_num in range(3):
leds.set_pixel(led_num, red, green, blue)
leds.show()
SAMPLING_RATE = 16000
CHUNK = 1 * SAMPLING_RATE
FFT_SIZE = 256
THRESHOLD = 0.8
STATES = ['Background',
'Cutting in focus',
'Cutting out focus',
'Marking',
'Sleeping',
'Waiting',
'Unknown']
last_state = STATES.index('Unknown')
count = 0
predictions_in_60_sec = np.empty((0, len(STATES) - 1))
audio_interface = pyaudio.PyAudio()
audio_stream = audio_interface.open(format=pyaudio.paInt16,
channels=1,
rate=SAMPLING_RATE,
input=True,
frames_per_buffer=CHUNK)
try:
while True:
data = np.fromstring(audio_stream.read(CHUNK),
dtype=np.int16)
audio_stream.stop_stream()
start = time.time()
state = last_state
D = librosa.stft(librosa.util.normalize(data),
n_fft=FFT_SIZE,
window='hamming')
magnitude = np.abs(D)
predictions = model.predict_proba(magnitude.transpose(),
verbose=False)
predictions_in_60_sec = np.vstack([predictions_in_60_sec,
predictions])
count = count + 1
predictions_mean = predictions.mean(axis=0)
elapsed_time = time.time() - start
localtime = time.localtime(time.time())
print('{0.tm_hour:02d}:{0.tm_min:02d}:{0.tm_sec:02d} {1:s} ({2:.3f}, processed in {3:.3f} seconds)'.format(
localtime,
STATES[predictions_mean.argmax()],
predictions_mean.max(),
elapsed_time))
if predictions_mean.max() > THRESHOLD:
state = predictions_mean.argmax()
if last_state != state:
print('CHANGED: {0} > {1}'.format(
STATES[last_state], STATES[state]))
set_leds(state)
last_state = state
if (count == 60):
start = time.time()
state_in_60_sec = predictions_in_60_sec.mean(axis=0).argmax()
make_web_request(STATES[state_in_60_sec])
predictions_in_60_sec = np.empty((0, len(STATES) - 1))
count = 0
elapsed_time = time.time() - start
print('Made a request in {0:.3f} seconds)'.format(elapsed_time))
audio_stream.start_stream()
except KeyboardInterrupt:
print('Requested to terminate')
finally:
audio_stream.stop_stream()
audio_stream.close()
audio_interface.terminate()
leds.clear_strip()
leds.cleanup()
print('Terminated')
このコードを実際に動作させた状態で撮影した動画です。この動画で行っている実際の加工は切断加工中(焦点NG)>切断加工中(焦点OK)>待機中です。それぞれの状態に対応するLEDの色として赤、青、白を割り当てています。本来は赤>青>白と変化すべきところ、赤のあとで緑に変わっているのはマーキングと誤判定されていることを示しています。

このように、まだまだ完璧とは言えませんが、ある程度の精度でレーザー加工機の動作状態を判定しつつ、Googleスプレッドシートに記録できるようになりました。

ディスカッション
Raspberry Piでの処理時間
1秒分のデータに関して、デュアルコアの1.4 GHz Intel Core i7を搭載したMacBook(Retina, 12-inch, 2017)での処理時間が約0.01秒だったのに対して、Raspberry Pi 3 Model Bでの処理時間は約0.09秒でした。このような違いはありますが、十分にリアルタイムで動作させることが可能な処理時間です。現在のコードでは、解析やウェブへの投稿を行っている最中にはバッファのオーバーランを避けるためにオーディオストリームを一次停止するようにしていますが、さらに実装を進めることでリアルタイムにすることも可能でしょう。
さらに精度を上げるために
今回は限定されたデータセットのみを与えて学習させましたが、もう少しバリエーションを増やしてどのような変化があるかを試してみる必要がありそうです。例えば、同じ材料、同じ加工用データであったとしても、どの位置で加工するかによって音に変化はありそうですし、今回使用した2.5 mm厚のMDFから材料が変わればさらに音は変化するでしょう。次の段階では、複数の条件で収録したサンプルを学習させて再度検証してみたいと思います。
また、今回用いたのは3つの全結合層のみから構成される簡単なネットワークでした。LSTMなどのRNNや、スペクトログラムを入力とするCNNなど、他の構成との比較も試してみたいと思います。さらに、今回使用したTensorFlowをバックエンドとするKerasと、Chainerなどの比較も試してみたいところです。
おわりに
ひとまずここまではたどり着きましたが、まだまだ課題は山積みです。もし、お気づきの点などあればコメントなどいただけるととても助かります!
リファレンス
- Warden, Pete. "Cross-compiling TensorFlow for the Raspberry Pi." Pete Warden's blog. August 20, 2017. Accessed December 03, 2017. https://petewarden.com/2017/08/20/cross-compiling-tensorflow-for-the-raspberry-pi/.
- RasPiでKeras/TensorFlowを動かす
- Raspberry Pi 3 Model BとReSpeaker 2-Mics Pi HATでGoogle Assistant SDKを活用する
- Raspbian Stretch with Desktopにlibrosaをインストールする
- Seeed Development Limited. "ReSpeaker 2-Mics Pi HAT." Seeed Wiki. Accessed December 07, 2017. http://wiki.seeed.cc/ReSpeaker_2_Mics_Pi_HAT/.