イントロダクション
前置き
この記事は、機械学習とRaspberry Piを用いてレーザー加工機の動作状態を音で判定することに機械学習の非専門家がチャレンジするシリーズの初回です。私自身は、今までにGoogle Cloud Speech APIなど学習済みモデルベースのサービスはしばしば活用してきたものの、チュートリアル以外で実際に自分で学習させてモデルをつくるのはほぼ初めてです。ですので、大幅に間違っているところがあるかもしれません。もし、お気づきの点などあればコメント等で指摘していただけると助かります。
課題
ファブ施設に設置されているデジタル工作機械の中で代表的なものの一つに、レーザー光線で材料を切断したり、表面に彫刻したりするレーザー加工機があります。2次元のデータを元に短時間で加工できることから比較的手軽に使い始めることができ、使いこなせば高度な加工までできる、かなり奥の深い工作機械です。情報科学芸術大学院大学[IAMAS](イアマス)にも「イノベーション工房」というデジタル工作機械を備えた工房があり、その中に2台のレーザー加工機が設置されています。
この工房を管理するスタッフによると、初心者がレーザー加工機を使って加工する際に起きやすいミスとして焦点のズレがあるそうです。反りのある木材や薄い紙であるため一部で焦点を合わせても別のところで外れてしまう、短時間で複数の利用者が共有する場面でうっかり設定し忘れてしまう、などが主な原因です。
焦点が正確に合っていない状態で使用すると、本来意図したように切断できないだけでなく通常よりも多くの煙が発生します。このため、短時間の使用でもレーザー加工機のミラー・レンズに多くの汚れが付着する、集塵機のフィルターが詰まる、といったことが起きてしまいます。次の動画は加工中の様子を記録したものです。前半の焦点の合っている状態と比較すると、後半の焦点の合っていない状態では多くの煙が出ているのが分かると思います。

アイデア
スタッフによると、レーザー加工機の操作に熟練すれば加工中の動作音を聞くだけで焦点のズレやフィルターの状態がある程度判断できるそうです。もし、音だけでレーザー加工機の状態を推定できれば、焦点がズレているなど正しく使用できていないと思われる場合に注意を促せるようになります。また、ある期間中の稼働率や、どのような加工をどの程度の時間行なっているかを記録することもできるようになるでしょう。そこで、Raspberry Piと機械学習を用いてレーザー加工機の状態を推定することにチャレンジすることにしました。
実験
機械学習に用いるフレームワークの選定
機械学習に用いられる代表的なフレームワークとしては、Chainer、TensorFlow、PyTorch(リリース順)などがあります。今回は、最終的にRaspberry Piで実装することを決めていたため、この機会にIntelの機械学習プラットフォームMovidiusも試してみようと思いました(いろいろと制約はあるようですが…)。MovidiusでサポートされているフレームワークはTensorFlowとCaffeであるため、まず最初にTensorFlowを試し、次にChainerなどを試してみるという方針を立てました。
その後、もう少し調べていくと、TensorFlowで直接書くのでなく、TensorFlowをバックエンドの一つとして利用でき学習やモデルを簡潔に記述できる高水準のニューラルネットワークライブラリKerasのモデルをTensorFlowのモデルに変換できることが分かりました。そこで学習まではKerasで進めることにしました。
準備
Raspberry Piにはオンボードの音声入力がないため、何らかの外部デバイスが必要になります。ここでは、以前の記事「Raspberry Pi 3 Model BとReSpeaker 2-Mics Pi HATでGoogle Assistant SDKを活用する」で紹介したSeeed StudioのReSpeaker 2-Mics Pi HATを用いることにしました。
設置場所はスタッフのアドバイスに基づいて決定しました。レーザー加工機の動作中は本体のファンや集塵機の動作音がかなり大きいため、加工中の音を上手く拾うためには上面パネルに設置するのがベストです。しかしながら、上面パネルに設置してしまうと通常の操作時に邪魔になります。これらの制約条件を元に検討した結果、次の写真のように前面パネルの最上部にひとまず設置することにしました。この位置であれば、ファンや集塵機の動作音の影響が少ない状態で音を聞くことができ、かつ清掃時以外は邪魔になりません。

録音
収録はRaspberry Piで行いました。本番では計算時の負荷を考えてサンプリング周波数は16,000 Hzにする予定ですが、この段階では念のためCDと同じ44,100 Hzで収録しています。この設定で何回かテストした際、希にマイクロSDカードへの記録が間に合わずバッファのオーバーランが発生したため、--buffer-size=192000のようにしてバッファを大きめに設定しています。
arecord --channels=1 --file-type wav --format=S16_LE --rate=44100 --duration=480 --buffer-size=192000 20171129.wav
実際に収録したサウンドがこちらです(一般の方にとってはただのノイズなので大きな音で再生しないことを強くおすすめします)。
録音したサウンド(SoundCloudへのリンク)
1番目は焦点の合っている状態での切断加工、2番目は焦点の合っていない状態での切断加工、3番目は彫刻加工(マーキング)です。それぞれ、よく聞くと違いがあることが分かると思います。
実装
ここからの実験はmacOS上でJupyter Notebookを動かし、その上で試行錯誤しながら試していきました。ここで用いているlibrosaは音声を扱うのに特化したライブラリで、読み込みや特徴抽出、変換など、機械学習に必要となるデータを準備するのに便利な機能が数多く実装されています。
import glob
import numpy as np
import matplotlib.pyplot as plt
import keras
import librosa
以下が収録したサウンドファイルを読み込んでくるところまでのコードです。librosa.load()の引数としてサンプリング周波数と長さを指定することにより、自動的に指定したサンプリング周波数に変換した音声ファイルを指定した長さだけ読み込むことができます。
sampling_rate = 16000
raw_sounds = []
wav_file_names = []
path = 'data/*.wav'
for wav_file_name in sorted(glob.glob(path)):
data, sample_rate = librosa.load(wav_file_name,
sr=sampling_rate,
duration=30)
print('{} ({} Hz) '.format(wav_file_name, sample_rate))
raw_sounds.append(data)
wav_file_names.append(wav_file_name)
data/20171129_background.wav (16000 Hz) ☜背景ノイズ(換気扇も停止)
data/20171129_cutting_in_focus.wav (16000 Hz) ☜切断加工中(焦点OK)
data/20171129_cutting_out_focus.wav (16000 Hz) ☜切断加工中(焦点NG)
data/20171129_marking.wav (16000 Hz) ☜マーキング
data/20171129_sleeping.wav (16000 Hz) ☜スリープ中(換気扇は動作)
data/20171129_waiting.wav (16000 Hz)☜待機中
次に、読み込んだ音声ファイル全体について周波数を縦軸、時間を横軸で表すソノグラムをプロットしてみました。これにより、それぞれに周波数特性上の違いがある程度あるのと同時に、時間軸上での変化がかなり小さいことが分かります。
fig = plt.figure(figsize=(15, 5 * len(wav_file_names)))
for i, wav_file_name in enumerate(wav_file_names):
plt.subplot(len(wav_file_names), 1, 1 + i)
plt.specgram(np.array(raw_sounds[i]), Fs=sampling_rate)
plt.title(wav_file_name)
plt.show()
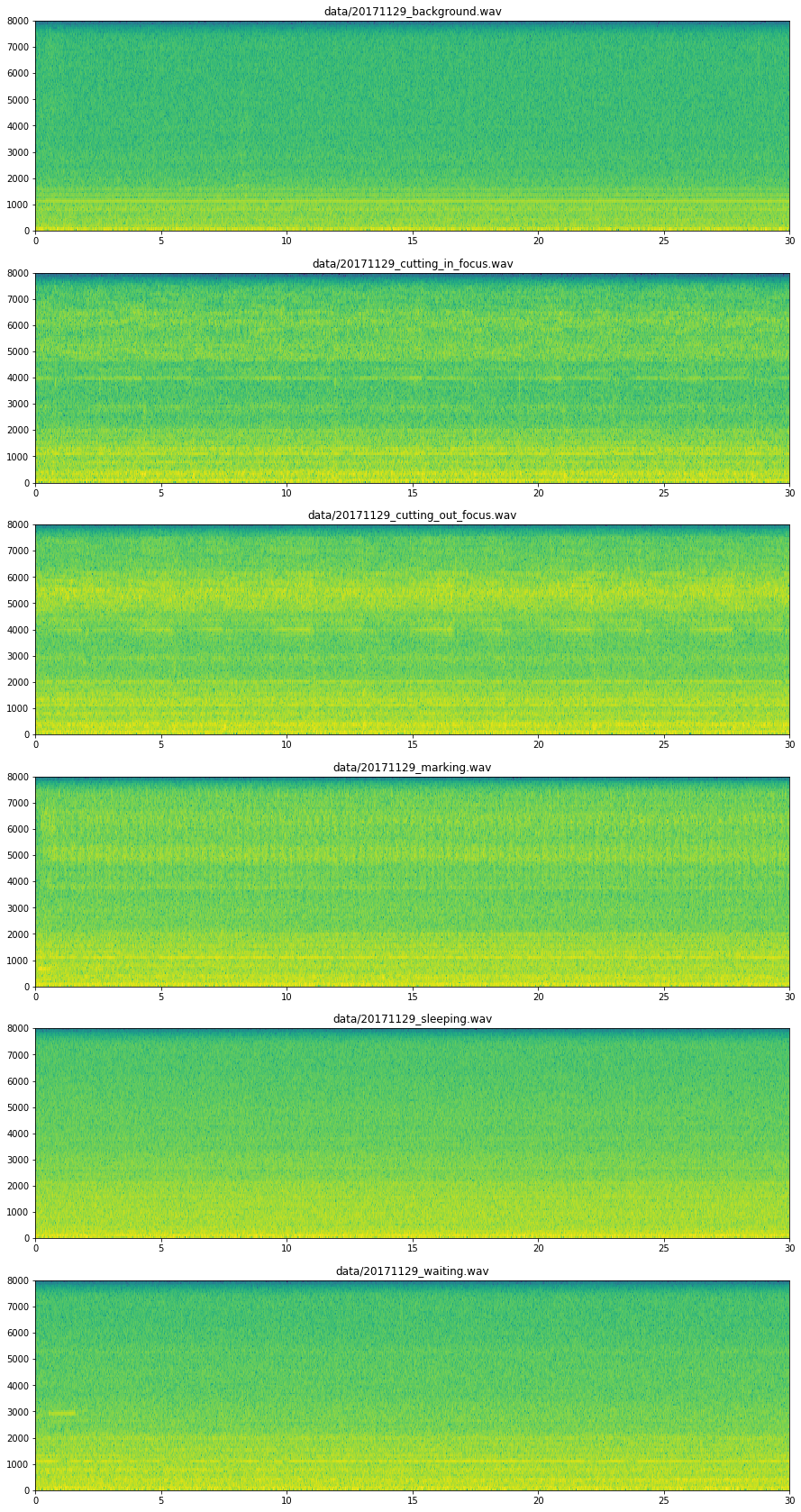
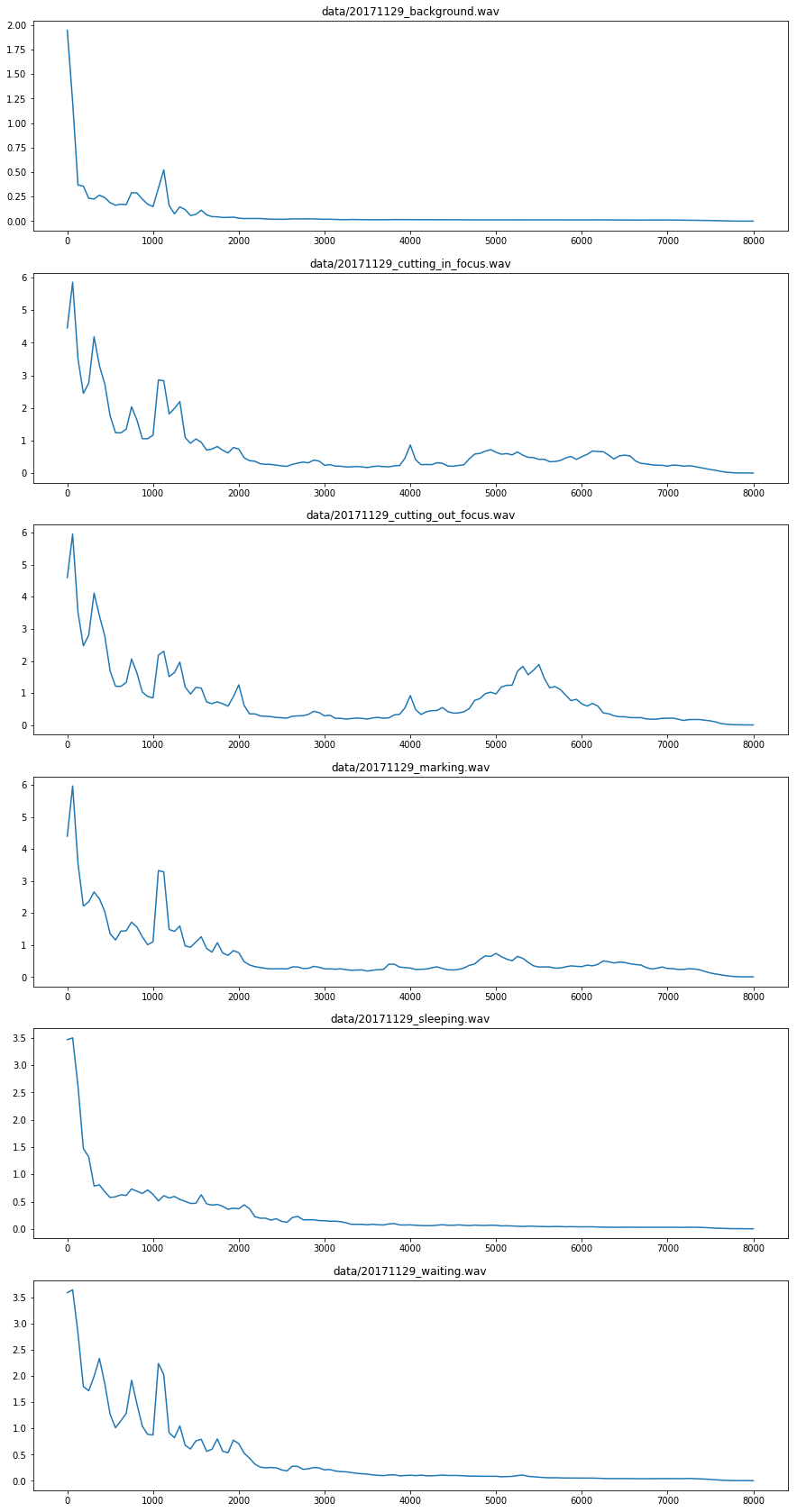
次に、FFTでそれぞれの音声ファイルを短い期間(サンプリング周波数16,000 Hzで256サンプルなので16 ms)ごとに分割して取得した周波数特性データを平均したものをプロットしてみました。これにより、同じカットでも焦点が合っている状態と合っていない状態で違いがあることがわかりました。
fft_size = 256
stft_matrix_size = 1 + fft_size // 2
X = np.empty((0, stft_matrix_size))
y = np.empty(0)
fig = plt.figure(figsize=(15, 5 * len(wav_file_names)))
for i, wav_file_name in enumerate(wav_file_names):
d = np.abs(librosa.stft(raw_sounds[i], n_fft=fft_size, window='hamming'))
X = np.vstack([X, d.transpose()])
y = np.hstack([y, [i] * d.shape[1]])
plt.subplot(len(wav_file_names), 1, 1 + i)
plt.plot(librosa.fft_frequencies(sr=sampling_rate, n_fft=fft_size),
np.mean(d, axis=1))
plt.title(wav_file_name)
plt.show()
音声を扱う場合、一定期間のソノグラムを画像のように入力として与えてCNNで扱う、時系列のデータ用に考案されたRNNを使うなどの方法があります。しかしながら、今回はソノグラムで見たように時間軸上での変化がほとんど無いため、ひとまずFTTの結果を全結合のネットワークにそのまま入れて試すことにしました。モデルの構成を決めた後は、活性化関数やFFTのサイズなどを何度か変更し、最も正解率が高くなる組み合わせを探しました。
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam
model = Sequential()
model.add(Dense(128, activation='sigmoid', input_dim=stft_matrix_size))
model.add(Dense(64, activation='sigmoid'))
model.add(Dense(len(wav_file_names), activation='softmax'))
model.compile(Adam(lr=0.01),
loss='categorical_crossentropy',
metrics=['accuracy'])
全体の20%をテスト用データとして分け、さらにその中で20%を検証用データとして与えた学習の結果は以下のようになりました。epoch数としては20を指定しましたが、早期終了のコールバック(EarlyStopping)が発動したため7回で終了しています。
from sklearn.model_selection import train_test_split
y_cat = keras.utils.to_categorical(y)
X_train, X_test, y_train, y_test = train_test_split(X, y_cat, test_size=0.2)
from keras.callbacks import EarlyStopping
es_callback = EarlyStopping(monitor='val_acc',
patience=2,
verbose=True,
mode='auto')
model.fit(X_train, y_train, epochs=20, batch_size=32,
validation_split=0.2, callbacks=[es_callback])
Train on 28803 samples, validate on 7201 samples
Epoch 1/20
28803/28803 [==============================] - 51s - loss: 0.2166 - acc: 0.9267 - val_loss: 0.1489 - val_acc: 0.9322
Epoch 2/20
28803/28803 [==============================] - 54s - loss: 0.1722 - acc: 0.9465 - val_loss: 0.1014 - val_acc: 0.9703
Epoch 3/20
28803/28803 [==============================] - 55s - loss: 0.1632 - acc: 0.9517 - val_loss: 0.1416 - val_acc: 0.9603
Epoch 4/20
28803/28803 [==============================] - 57s - loss: 0.1662 - acc: 0.9537 - val_loss: 0.0743 - val_acc: 0.9811
Epoch 5/20
28803/28803 [==============================] - 57s - loss: 0.1637 - acc: 0.9530 - val_loss: 0.2457 - val_acc: 0.9667
Epoch 6/20
28803/28803 [==============================] - 59s - loss: 0.1609 - acc: 0.9597 - val_loss: 0.0960 - val_acc: 0.9775
Epoch 7/20
28803/28803 [==============================] - 59s - loss: 0.1652 - acc: 0.9566 - val_loss: 0.1512 - val_acc: 0.9660
Epoch 00006: early stopping
最後にテスト用データで評価すると97%弱の正解率となりました。
model.evaluate(X_test, y_test)
8448/9002 [===========================>..] - ETA: 0s
[0.14626707485530396, 0.96867362808264834]
Kerasの学習したモデルはmodel.save()で簡単に保存できますので、学習が終わった状態で保存しておきます。
model.save('laser_machine.h5')
恐らく、実際に動かしてみるといろいろな問題が出てくると思います。第2回では、Raspberry Pi上で動作させる前段階の準備について紹介したいと思います。
リファレンス
- Saeed, Aaqib. "Urban Sound Classification, Part 1." Aaqib Saeed. September 3, 2016. Accessed November 25, 2017. http://aqibsaeed.github.io/2016-09-03-urban-sound-classification-part-1/.
- Shaikh, Faizan. "Getting Started with Audio Data Analysis (Voice) using Deep Learning." Analytics Vidhya. August 23, 2017. Accessed November 25, 2017. https://www.analyticsvidhya.com/blog/2017/08/audio-voice-processing-deep-learning/.