イントロダクション
この記事は「機械学習とRaspberry Piを用いてレーザー加工機の動作状態を判定する(第1回)」の続きです。第1回ではモデルに学習させて評価するところまでを紹介しました。第2回では、学習させたモデルを用いてRaspberry Pi上でレーザー加工機の動作状態を判定させる前段階での準備について紹介したいと思います。
検証
録音済みデータでの確認
まず、学習後に保存したモデルの読み込みます。これは非常に簡単でkeras.models.load_model()にファイル名を指定して読み込むだけです。model.summary()の結果より、保存したモデルが再現できていることが分かります。
import numpy as np
import keras
import librosa
model = keras.models.load_model('laser_machine.h5')
print(model.summary())
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 128) 16640
_________________________________________________________________
dense_2 (Dense) (None, 64) 8256
_________________________________________________________________
dense_3 (Dense) (None, 6) 390
=================================================================
Total params: 25,286
Trainable params: 25,286
Non-trainable params: 0
_________________________________________________________________
None
次に、このモデルを用いて学習時に与えたサウンドファイルで本当に判定できるかどうかを確認してみます。実行結果は以下のようになりました。model.predict_classes()でクラスを求めたものをヒストグラムで表した図からは、background、cutting_out_focus、sleepingに関してはほぼ正確に判別できているものの、cutting_in_focus、marking、waitingに関してはある程度の割合で他のクラスと誤判定されていることが分かります。
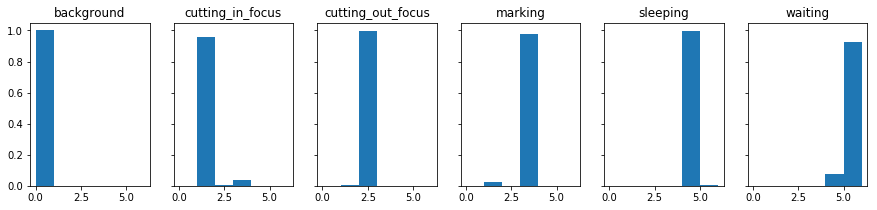
同じデータを時系列で表した図から、本来のクラス(赤線)以外への誤判定が発生している箇所が分かります。
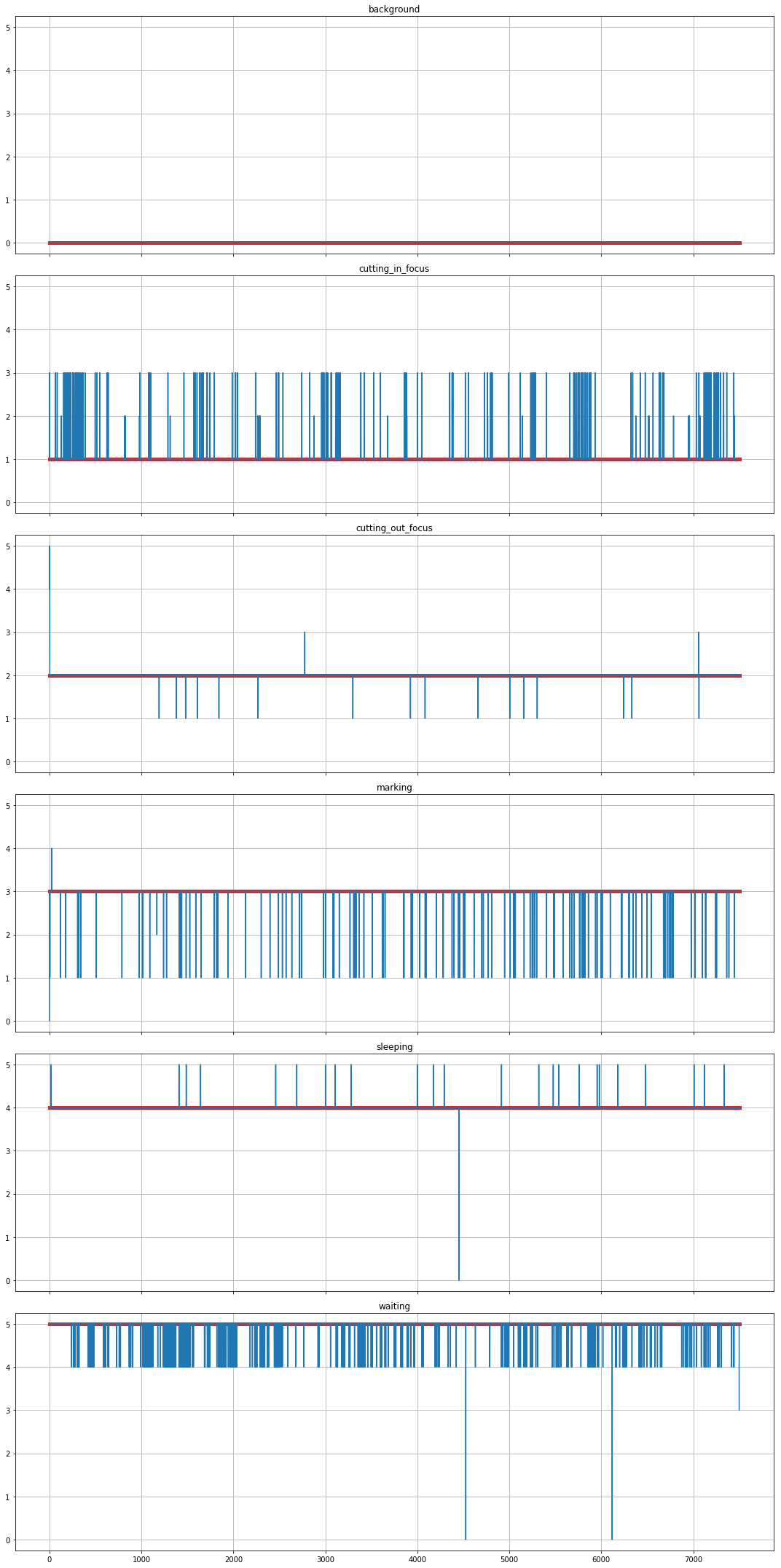
この結果より、誤判定を避けるために一定の区間(例:1秒間)ごとに判定結果の平均を取得し、その中で最も高いものが一定の閾値(例:0.8)を超えた場合のみその状態へと変化したと判断する、という方針で実装してみたいと思います。
リアルタイムでの確認
新たなライブラリとして、オーディオ入出力を扱うために開発されたライブラリ「PyAudio」と、時間を計測するためのライブラリ「time」を用います。
import numpy as np
import keras
import librosa
import pyaudio
import time
PyAudioを用いて以下のように実装しています。まず、1秒ごとにそれぞれのクラスに対する確率を求めた後に全体での平均を求め、最も値の大きなものをその区間での最有力候補とします。次に、最有力候補の確率が0.8を超えた場合のみ、その状態に遷移したとして扱います。
STATES = ['Background',
'Cutting in focus',
'Cutting out focus',
'Marking',
'Sleeping',
'Waiting',
'Unknown']
last_state = STATES.index('Unknown')
SAMPLING_RATE = 16000
CHUNK = 1 * SAMPLING_RATE
FFT_SIZE = 256
THRESHOLD = 0.8
audio_interface = pyaudio.PyAudio()
audio_stream = audio_interface.open(format=pyaudio.paInt16,
channels=1,
rate=SAMPLING_RATE,
input=True,
frames_per_buffer=CHUNK,
start=False)
audio_stream.start_stream()
try:
while True:
data = np.fromstring(audio_stream.read(CHUNK),
dtype=np.int16)
# Pause the audio stream
audio_stream.stop_stream()
start = time.time()
state = last_state
D = librosa.stft(librosa.util.normalize(data),
n_fft=FFT_SIZE,
window='hamming')
magnitude = np.abs(D)
predictions = model.predict_proba(magnitude.transpose(),
verbose=False)
predictions_mean = predictions.mean(axis=0)
elapsed_time = time.time() - start
print('{0:s} ({1:.3f}, processed in {2:.3f} seconds)'.format(
STATES[predictions_mean.argmax()],
predictions_mean.max(),
elapsed_time))
if predictions_mean.max() > THRESHOLD:
state = predictions_mean.argmax()
if last_state != state:
print('CHANGED: {0} > {1}'.format(
STATES[last_state], STATES[state]))
last_state = state
# Resume the audio stream
audio_stream.start_stream()
except KeyboardInterrupt:
print('Requested to terminate')
finally:
audio_stream.stop_stream()
audio_stream.close()
audio_interface.terminate()
print('Terminated')
BackgroundとCutting in focusの状態を録音したサウンドファイルを順に外部スピーカで再生した状態で動かしてみたところ、以下のような結果になりました(Jupyter Notebook上で終了するにはescキーを押した後に2回繰り返しでiキーを押すか、KernelメニューからInterruptを実行します)。最初のBackgroundに関しては期待通り取得できていますが、Cutting in focusに関してはWaitingと判定されてしまっています。
Background (0.957, processed in 0.012 seconds)
CHANGED: Unknown > Background
Background (0.830, processed in 0.007 seconds)
Background (0.632, processed in 0.012 seconds)
Background (0.826, processed in 0.012 seconds)
Background (0.698, processed in 0.011 seconds)
Background (0.832, processed in 0.012 seconds)
Background (0.775, processed in 0.011 seconds)
Background (0.766, processed in 0.012 seconds)
Background (0.872, processed in 0.012 seconds)
Background (0.703, processed in 0.012 seconds)
Background (0.778, processed in 0.012 seconds)
Background (0.911, processed in 0.012 seconds)
Background (0.971, processed in 0.013 seconds)
Waiting (0.748, processed in 0.011 seconds)
Waiting (0.985, processed in 0.011 seconds)
CHANGED: Background > Waiting
Waiting (0.989, processed in 0.011 seconds)
Waiting (0.988, processed in 0.011 seconds)
Waiting (0.986, processed in 0.012 seconds)
Waiting (0.977, processed in 0.008 seconds)
Waiting (0.989, processed in 0.012 seconds)
Requested to terminate
Terminated
Raspberry PiにReSpeaker 2-Mics Pi HATを搭載してレーザー加工機に直接貼り付けている状態と、外部スピーカから再生したものをMacBook(Retina, 12-inch, 2017)の内蔵マイクで録音している状態では大きく周波数特性が異なるため、ここから先は実機で確認する必要があります。第3回では、いよいよRaspberry Pi上で試してみたいと思います。