CNTK 2.2 Python API 解説 (5) - Seq2Seq Attention モデルによる、音声合成のための書記素-音素変換
0. はじめに
◆ CNTK ( Microsoft Cognitive Toolkit ) 2.2 の Python API 解説第5弾です。
Sequence-to-Sequence Attention モデルによる、北米英語の書記素-音素変換を扱います。
CNTK Python API の解説が主眼ですが、(RNN の) Attention メカニズムについての解説記事としても参考になります。
書記素-音素変換は、入力シークエンスとして単語の文字群を取り、相当する音素を出力する翻訳タスクです。
換言すれば、システムは与えられた入力単語をどのように発音するかの明確な表現を生成することを目的とし、音声合成の基礎技術の一つにもなっています。
※ 書記素は (自然言語の) 筆記システムの最小のユニットで、音素は言語を構成する音のユニットです。
Sequence-to-Sequence の基礎から Attention モデルの基礎理論を説明した上で、CNTK Python API で Attention モデルを実装してトレーニングします。更に、対話的に入力シークエンスを音素に変換して評価し、attention のヒートマップへの可視化まで遂行します。
題材としては CMU Pronouncing Dictionary からの CMUDict データセットを使用します。これは北米英語のためのオープンソースのコンピュータ可読な発音辞書です。

本記事の内容は :
- 動作環境と Jupyter Notebook について
- Sequence-to-Sequence Attention モデル
- 書記素-音素変換
- モデル作成
- トレーニング
- ネットワークをテストする
本記事は以下の CNTK チュートリアルと Andrej Karpathy 氏のブログ記事を参考にしています :
- CNTK 204: Sequence to Sequence Networks with Text Data
- CNTK 599A: Sequence to Sequence Networks with Text Data
- The Unreasonable Effectiveness of Recurrent Neural Networks (Andrej Karpathy)
1. 動作環境と Jupyter Notebook について
動作環境
動作環境の構築が必要な場合には、Cognitive Toolkit 2.2 を Azure Linux GPU 仮想マシンにインストール を参考にしてください。Azure ポータルと Ubuntu Linux にある程度慣れていれば、30 分程度で以下のような環境が構築できるかと思います :
- Azure NC 仮想マシン with NVIDIA Tesla® K80 GPU
- Ubuntu 16.04 LTS
- NVIDIA CUDA 8.0 & cuDNN 6.0
- Anaconda 3 4.1.1
- CNTK 2.2 (for GPU)
Jupyter Notebook
また、本記事でも CNTK チュートリアルでも Jupyter Notebook を多用します。
Jupyter Notebook の利用方法については「CNTK 2.2 Python API 入門 (2)」の記事中の Jupyter Notebook の活用 を参照してください。
2 Sequence-to-Sequence Attention モデル
2-1 Sequence-to-Sequence 概要
本記事は sequence-to-sequence ネットワークの基本を説明した上で、CNTK でどのように実装するかを示します。
特に、書記素-音素 (grapheme to phoneme, GTP, G2P) 変換を遂行するために、attention を持つ sequence-to-sequence モデルを実装します。
sequence-to-sequence の基礎理論の説明から始めて CNTK で attention モデルを実装し、そしてトレーニング・評価まで行ないます。
sequence-to-sequence を説明するにあたり、Andrej Karpathy 氏のブログ記事: The Unreasonable Effectiveness of Recurrent Neural Networks はニューラルネットワーク・アーキテクチャの5つの一般的なパラダイムの良い可視化を示していますのでそれを活用します :
from IPython.display import Image
Image(url="http://cntk.ai/jup/paradigms.jpg", width=750)

本記事では4番目のパラダイムを扱うことになります : 入力と出力が多対多 (many-to-many) のケースで、sequence-to-sequence ネットワークとしても知られています。
入力は動的な長さを持つシークエンスで、そして出力もまた動的な長さを持つシークエンスです。そこでは出力の長さは必ずしも入力の長さと同じではありません。これは多対一 (many-to-one) パラダイムの論理的な拡張でもあります。
Andrej Karpathy 氏の記事は RNN の紹介記事として有名です。(既に読まれた方も多いかもしれませんが)
示唆に富んだ記事ですので、シークエンスにふれている冒頭だけでも翻訳しておきます :
リカレント・ニューラルネットワーク
シークエンス。貴方の背景によっては次のような疑問を持つかもしれません: 何がリカレントネットワークをそれほど特別にしているのでしょう?
平凡なニューラルネットワーク (そして畳み込みネットワーク) のやけに目立つ制限はそれらの API が非常に束縛されていることです : それらは (画像のような) 固定サイズのベクトルを入力として受け取りそして (異なるクラスの確率のような) 固定サイズのベクトルを出力として生成します。それだけではありません : これらのモデルはこのマッピングを計算ステップの固定された総量を使用して遂行します (e.g. モデルの層数)。
リカレントネットがよりエキサイティングである主要な理由はそれらはベクトルのシークエンスに渡って演算することを可能にしてくれること です : 入力、出力、あるいは最も一般的なケースではその両者におけるシークエンスです。(上) 図の幾つかの例はこれをより具体的にするでしょう。
貴方が期待するように、演算のシークエンス体制は、(計算ステップの固定された数により最初から運命づけられた) 固定されたネットワークに比べて非常により強力で、そしてこうしてまたより知的なシステムを構築することを熱望する人々にとっては非常により魅力的です。
更に、もう少し先で見るように、RNN はその入力ベクトルを固定された (しかし学習された) 関数を持つそれらのステート・ベクトルと結合して新しいステート・ベクトルを生成します。これはプログラミング視点ではある入力とある内部変数を持つ固定されたプログラムを実行しているものとして解釈できます。
このように見ると、RNN は本質的にプログラムを記述しています。実際に、(適切な重みを持てば) 任意のプログラムをシミュレートできるという意味では RNN はチューリング完全である ことが知られています。しかしニューラルネットについての普遍近似定理 (universal approximation theorems) と同様に、これを深読みすべきではありません。(それどころか、私が言ったことは忘れてください。)
平凡なニューラルネットの訓練が関数に渡る最適化であるとすれば、リカレントネットの訓練はプログラムに渡る最適化です。
sequence-to-sequence ネットワークのアプリケーションは殆ど無限です。例えば次のような分野に対して自然で適切なモデルです :
- 機械翻訳 (e.g. 英語入力シークエンス, フランス語出力シークエンス);
- 自動テキスト要約 (e.g. 完全な文書入力シークエンス, 要約出力シークエンス);
- word-to-pronunciation (単語-to-発音) モデル (e.g.キャラクター [書記素] 入力シークエンス, 発音 [音素] 出力シークエンス);
- 解析木生成 (parse tree generation) (e.g. 標準テキスト入力, flat 解析木出力)
2-2 基礎理論 - Attention モデル
sequence-to-sequence モデルは2つの主要なピースから構成されます: (1) エンコーダ、そして (2) デコーダ です。
エンコーダとデコーダの両者はリカレント・ニューラルネットワーク (RNN) 層で、それは平凡な (= vanilla) RNN、LSTM、あるいは GRU ブロックを使用して実装可能です (ここでは LSTM を使用します)。
基本的な sequence-to-sequence モデルでは、エンコーダは入力シークエンスをコンテキストとして、(デコーダに供給される) 固定された表現に処理します。
そしてデコーダはその処理された情報を出力シークエンスにデコードするためにあるメカニズム (後述) を使用します。
英語からドイツ語への翻訳タスクのためには、最も基本的な構成は次のように見えるでしょう :
Image(url="http://cntk.ai/jup/s2s.png", width=700)
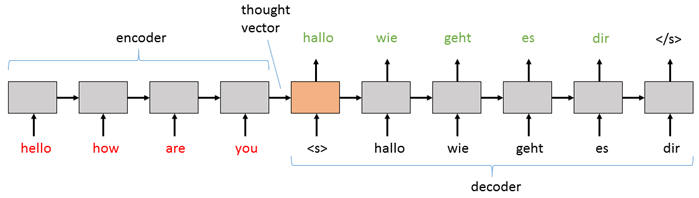
基本的な sequence-to-sequence ネットワークでは :
-
デコーダ RNN を (その初期隠れステートとして) エンコーダの最終的な隠れステートで初期化することによって、エンコーダからデコーダに情報を渡します。
-
そしてその後の入力は "シークエンス開始" タグ (上のダイアグラムでは <s>) で、これはデコーダに出力シークエンスを生成することを開始することを前もって教えておきます。
-
それから、そのステップで生成する単語 (あるいはノート、画像, etc.) がどのようなものであっても次のステップのための入力として供給されます。
-
デコーダはそれが特殊な "終了シークエンス" タグ (上のダイアグラムでは </s>) にヒットするまで出力を生成し続けます。
基本的な sequence-to-sequence ネットワークのより複雑でパワフルなバージョンとして attention モデル を使用します。
上の構成が上手く動作する一方で、入力シークエンスが長くなるにつれてそれは上手くいかなくなるかもしれません。
各ステップで、隠れステート h は最も最近の情報で更新されます、そのため各トークンを処理するときに h は情報の観点から "希釈 (= diluted)" されます (薄まります)。
さらに、比較的短い文でも、最後のトークンはいつも最終決定権がありますので、thought ベクトルは最後の単語に向けて幾分重み付けられます。
この問題に対処するために、"attention" メカニズムを使用します。このメカニズムはデコーダに、デコーディングの各ステップのために、(入力からの隠れステートの総てを見るだけでなく、) どの隠れステートに最も重みが置かれるかもまた学習することを可能にします。
本記事では attention が有効であってもなくても実行可能な sequence-to-sequence ネットワークを実装します。
Image(url="https://cntk.ai/jup/cntk204_s2s2.png", width=700)

上の attention 層は、デコーダの隠れステートの現在値、エンコーダの隠れステートの総てを取り、そして使用するための隠れステートの拡張版 (= augmented version) を計算します。
より具体的には、エンコーダの隠れステートからの寄与はその隠れステート総ての重み付けられた総計を表します、そこでは最も高い重みが、拡張隠れステートへの最も大きい寄与と、次の単語を生成するときにデコーダが考慮するためにもっとも重要となる拡張隠れステートの両者に相当します。
3. 書記素-音素変換
3-1 問題設定: 書記素-音素変換の概要
書記素 (grapheme) - 音素 (phoneme) 変換問題は、入力シークエンスとして単語の文字 (= letter) を取り、そして相当する音素を出力する、翻訳タスクです。
換言すれば、システムは与えられた入力単語をどのように発音するかの明確な表現を生成することを目的としています。
※ 書記素は (自然言語の) 筆記システムの最小のユニットで、音素は言語を構成する音のユニットです。
例
書記素、あるいは文字(群)は対応する音素に翻訳されます :
Grapheme : | T | A | N | G | E | R |
Phonemes : | ~T | ~AE | ~NG | ~ER |
モデル構造概要
このタスクは、入力としてシークエンスを取り、そして入力のコンテンツをベースとする出力シークエンスを生成するモデルを作成することです。
モデルのジョブは入力シークエンスからそれが生成する出力シークエンスへのマッピングを学習することです。
エンコーダのジョブは、デコーダが良い出力を生成するために使用できる、入力の良い表現を見つけることです。
エンコーダとデコーダの両者に対して、LSTM はこのジョブのために良い仕事をします。
CNTK Blocks ライブラリから LSTM 実装を使用します。
これは LSTM の "知性 (= smarts)" を実装しています、そしてこれを多かれ少なかれブラックボックスとして考えることもできますが、けれども理解する必要がある大切なことは、RNN を実装するときに考えるべき2つのピースがあることです :
- Recurrence、これはシークエンスに渡って展開された (= unrolled) ネットワークです、そして
- Block、これは recurrence 内部のブロックで、シークエンスの各要素のための実行ピースです。
recurrence をブロック (この場合は LSTM) 上で step(x) を呼び出し続ける関数として考えることは理解の助けになります。
この場合、LSTM は次のように見えます :
class LSTM {
float hidden_state
init(initial_value):
hidden_state = initial_value
step(x):
hidden_state = LSTM_function(x, hidden_state)
return hidden_state
}
ここで、step(x) 関数への各呼び出しは何某かの入力 x を取り、内部的な hidden_state を変更して、そしてそれを返します。
従って、総ての入力 x によって、hidden_state の値は進化します。
◆ LSTM は、RNN を実装するために使用可能なブロックの異なるタイプの全体のセットの単なる一つであることに注意してください。これは recurrence の各ステップのために実行されるコードです。
層ライブラリでは、3つの組み込みのリカレント・ブロックがあります : (平凡な) RNN, GRU, そして LSTM です。
各々はその入力を少し違って扱います。そしてそれぞれはタスクとネットワークの異なるタイプのためにそれ自身の利点と欠点を持ちます。
ネットワークで要素の各々のためにこれらのブロックをリカレントに実行するために、それらに渡る Recurrence を作成します。
これは、RNN 層のために与えられた入力にあるステップの数にネットワークを "展開 (= unroll)" します。
インポート
CNTK は幾つかの io, learner, graph, etc. のようなサブモジュールを含む Python モジュールです。NumPy もまた使用します :
from __future__ import print_function
import numpy as np
import os
import cntk as C
import cntk.tests.test_utils
cntk.tests.test_utils.set_device_from_pytest_env() # (only needed for our build system)
C.cntk_py.set_fixed_random_seed(1) # fix a random seed for CNTK components
3-2 データをダウンロードする
本記事では The CMU Pronouncing Dictionary からの CMUDict (version 0.7b) データセットの軽く前処理されたバージョンを使用します。CMUDict データは Carnegie Mellon University Pronouncing Dictionary を指し、これは北米英語 (= North American English) のためのオープンソースのコンピュータ可読な発音辞書です。
データセットは CNTKTextFormatReader フォーマットに前処理されています。
※ シークエンスを含む CNTK CTF フォーマットの仕様等ついては (必要であれば) 以下の記事を参照してください :
CNTK 2.2 Python API 解説 (3) - <言語理解> 双方向リカレント・ネットワークでスロットタギング
3. CNTK テキストフォーマット詳細
このデータセットからのサンプルのシークエンス・ペアを次に示します。
入力シークエンス (S0) は左カラムで、出力シークエンス (S1) は右側です :
0 |S0 3:1 |# <s> |S1 3:1 |# <s>
0 |S0 4:1 |# A |S1 32:1 |# ~AH
0 |S0 5:1 |# B |S1 36:1 |# ~B
0 |S0 4:1 |# A |S1 31:1 |# ~AE
0 |S0 7:1 |# D |S1 38:1 |# ~D
0 |S0 12:1 |# I |S1 47:1 |# ~IY
0 |S0 1:1 |# </s> |S1 1:1 |# </s>
下のコードは必要なファイル (トレーニング用、テスト用、視覚的な検証のための単一のシークエンス、そして小さな語彙 (= vocab) ファイル) をダウンロードして、そしてそれらをローカル・フォルダーに配置します (トレーニング用ファイルは ~34 MB、テスト用ファイルは ~4MB、そして検証ファイルと語彙ファイルは両者とも 1KB 以下です) :
import requests
def download(url, filename):
""" utility function to download a file """
response = requests.get(url, stream=True)
with open(filename, "wb") as handle:
for data in response.iter_content():
handle.write(data)
MODEL_DIR = "."
DATA_DIR = os.path.join('.', 'CMUDict', 'Data')
# DATA_DIR = os.path.join('..', 'Examples', 'SequenceToSequence', 'CMUDict', 'Data')
# If above directory does not exist, just use current.
if not os.path.exists(DATA_DIR):
os.makedirs(DATA_DIR)
#DATA_DIR = '.'
dataPath = {
'validation': 'tiny.ctf',
'training': 'cmudict-0.7b.train-dev-20-21.ctf',
'testing': 'cmudict-0.7b.test.ctf',
'vocab_file': 'cmudict-0.7b.mapping',
}
for k in sorted(dataPath.keys()):
path = os.path.join(DATA_DIR, dataPath[k])
if os.path.exists(path):
print("Reusing locally cached:", path)
else:
print("Starting download:", dataPath[k])
url = "https://github.com/Microsoft/CNTK/blob/release/2.2/Examples/SequenceToSequence/CMUDict/Data/%s?raw=true"%dataPath[k]
download(url, path)
print("Download completed")
dataPath[k] = path
Starting download: cmudict-0.7b.test.ctf
Download completed
Starting download: cmudict-0.7b.train-dev-20-21.ctf
Download completed
Starting download: tiny.ctf
Download completed
Starting download: cmudict-0.7b.mapping
Download completed
ダウンロードしたファイルはいずれもテキストファイルですので、内容を確認してみましょう :
$ ls -lh
total 38M
-rw-rw-r-- 1 masao masao 208 Nov 19 16:07 cmudict-0.7b.mapping
-rw-rw-r-- 1 masao masao 3.9M Nov 19 16:06 cmudict-0.7b.test.ctf
-rw-rw-r-- 1 masao masao 34M Nov 19 16:07 cmudict-0.7b.train-dev-20-21.ctf
-rw-rw-r-- 1 masao masao 220 Nov 19 16:07 tiny.ctf
$ file *
cmudict-0.7b.mapping: ASCII text
cmudict-0.7b.test.ctf: ASCII text
cmudict-0.7b.train-dev-20-21.ctf: ASCII text
tiny.ctf: ASCII text
$ wc -l *
69 cmudict-0.7b.mapping
122209 cmudict-0.7b.test.ctf
1034378 cmudict-0.7b.train-dev-20-21.ctf
7 tiny.ctf
1156663 total
以下はトレーニング用の CTF ファイルです :
$ head -n 20 cmudict-0.7b.train-dev-20-21.ctf
0 |S0 3:1 |# <s> |S1 3:1 |# <s>
0 |S0 0:1 |# ' |S1 49:1 |# ~K
0 |S0 6:1 |# C |S1 32:1 |# ~AH
0 |S0 4:1 |# A |S1 67:1 |# ~Z
0 |S0 24:1 |# U |S1 1:1 |# </s>
0 |S0 22:1 |# S
0 |S0 8:1 |# E
0 |S0 1:1 |# </s>
1 |S0 3:1 |# <s> |S1 3:1 |# <s>
1 |S0 0:1 |# ' |S1 49:1 |# ~K
1 |S0 6:1 |# C |S1 33:1 |# ~AO
1 |S0 18:1 |# O |S1 57:1 |# ~R
1 |S0 24:1 |# U |S1 58:1 |# ~S
1 |S0 21:1 |# R |S1 1:1 |# </s>
1 |S0 22:1 |# S
1 |S0 8:1 |# E
1 |S0 1:1 |# </s>
2 |S0 3:1 |# <s> |S1 3:1 |# <s>
2 |S0 0:1 |# ' |S1 32:1 |# ~AH
2 |S0 8:1 |# E |S1 51:1 |# ~M
$ tail -n 25 cmudict-0.7b.train-dev-20-21.ctf
108949 |S0 25:1 |# V |S1 67:1 |# ~Z
108949 |S0 0:1 |# ' |S1 1:1 |# </s>
108949 |S0 22:1 |# S
108949 |S0 1:1 |# </s>
108950 |S0 3:1 |# <s> |S1 3:1 |# <s>
108950 |S0 29:1 |# Z |S1 67:1 |# ~Z
108950 |S0 28:1 |# Y |S1 66:1 |# ~Y
108950 |S0 24:1 |# U |S1 63:1 |# ~UW
108950 |S0 10:1 |# G |S1 44:1 |# ~G
108950 |S0 4:1 |# A |S1 30:1 |# ~AA
108950 |S0 17:1 |# N |S1 52:1 |# ~N
108950 |S0 18:1 |# O |S1 30:1 |# ~AA
108950 |S0 25:1 |# V |S1 64:1 |# ~V
108950 |S0 0:1 |# ' |S1 67:1 |# ~Z
108950 |S0 22:1 |# S |S1 1:1 |# </s>
108950 |S0 1:1 |# </s>
108951 |S0 3:1 |# <s> |S1 3:1 |# <s>
108951 |S0 29:1 |# Z |S1 67:1 |# ~Z
108951 |S0 28:1 |# Y |S1 46:1 |# ~IH
108951 |S0 26:1 |# W |S1 65:1 |# ~W
108951 |S0 12:1 |# I |S1 46:1 |# ~IH
108951 |S0 6:1 |# C |S1 49:1 |# ~K
108951 |S0 14:1 |# K |S1 47:1 |# ~IY
108951 |S0 12:1 |# I |S1 1:1 |# </s>
108951 |S0 1:1 |# </s>
以下はテスト用の CTF ファイルです :
$ head -n 20 cmudict-0.7b.test.ctf
0 |S0 3:1 |# <s> |S1 3:1 |# <s>
0 |S0 4:1 |# A |S1 32:1 |# ~AH
0 |S0 5:1 |# B |S1 36:1 |# ~B
0 |S0 4:1 |# A |S1 31:1 |# ~AE
0 |S0 7:1 |# D |S1 38:1 |# ~D
0 |S0 12:1 |# I |S1 47:1 |# ~IY
0 |S0 1:1 |# </s> |S1 1:1 |# </s>
1 |S0 3:1 |# <s> |S1 3:1 |# <s>
1 |S0 4:1 |# A |S1 32:1 |# ~AH
1 |S0 5:1 |# B |S1 36:1 |# ~B
1 |S0 4:1 |# A |S1 42:1 |# ~EY
1 |S0 23:1 |# T |S1 60:1 |# ~T
1 |S0 12:1 |# I |S1 46:1 |# ~IH
1 |S0 17:1 |# N |S1 53:1 |# ~NG
1 |S0 10:1 |# G |S1 1:1 |# </s>
1 |S0 1:1 |# </s>
2 |S0 3:1 |# <s> |S1 3:1 |# <s>
2 |S0 4:1 |# A |S1 31:1 |# ~AE
2 |S0 5:1 |# B |S1 36:1 |# ~B
2 |S0 5:1 |# B |S1 32:1 |# ~AH
$ tail -n 20 cmudict-0.7b.test.ctf
12853 |S0 3:1 |# <s> |S1 3:1 |# <s>
12853 |S0 29:1 |# Z |S1 67:1 |# ~Z
12853 |S0 26:1 |# W |S1 65:1 |# ~W
12853 |S0 12:1 |# I |S1 47:1 |# ~IY
12853 |S0 8:1 |# E |S1 43:1 |# ~F
12853 |S0 9:1 |# F |S1 32:1 |# ~AH
12853 |S0 8:1 |# E |S1 50:1 |# ~L
12853 |S0 15:1 |# L |S1 45:1 |# ~HH
12853 |S0 11:1 |# H |S1 30:1 |# ~AA
12853 |S0 18:1 |# O |S1 43:1 |# ~F
12853 |S0 9:1 |# F |S1 41:1 |# ~ER
12853 |S0 8:1 |# E |S1 1:1 |# </s>
12853 |S0 21:1 |# R
12853 |S0 1:1 |# </s>
12854 |S0 3:1 |# <s> |S1 3:1 |# <s>
12854 |S0 29:1 |# Z |S1 67:1 |# ~Z
12854 |S0 28:1 |# Y |S1 35:1 |# ~AY
12854 |S0 6:1 |# C |S1 37:1 |# ~CH
12854 |S0 11:1 |# H |S1 1:1 |# </s>
12854 |S0 1:1 |# </s>
以下は検証用ファイルですが、本節の最初に掲載したサンプルと同一の内容です。
※ ここでいう検証は、サンプルを利用してトレーニングの進捗を確認することを意味しています :
$ cat tiny.ctf
0 |S0 3:1 |# <s> |S1 3:1 |# <s>
0 |S0 4:1 |# A |S1 32:1 |# ~AH
0 |S0 5:1 |# B |S1 36:1 |# ~B
0 |S0 4:1 |# A |S1 31:1 |# ~AE
0 |S0 7:1 |# D |S1 38:1 |# ~D
0 |S0 12:1 |# I |S1 47:1 |# ~IY
0 |S0 1:1 |# </s> |S1 1:1 |# </s>
以下は語彙ファイルです :
$ cat cmudict-0.7b.mapping
'
</s>
<s/>
<s>
A
B
C
D
E
F
G
H
I
J
K
L
M
N
O
P
Q
R
S
T
U
V
W
X
Y
Z
~AA
~AE
~AH
~AO
~AW
~AY
~B
~CH
~D
~DH
~EH
~ER
~EY
~F
~G
~HH
~IH
~IY
~JH
~K
~L
~M
~N
~NG
~OW
~OY
~P
~R
~S
~SH
~T
~TH
~UH
~UW
~V
~W
~Y
~Z
~ZH
データ・リーダー
データを効率的に収集して、トレーニングのためにそれをランダム化して、そしてそれをネットワークに渡すために、CNTKTextFormat リーダーを使用します。
リーダーを作成する前に、トレーニング (あるいはテスティング) 時に呼び出される小さなヘルパー関数を作成します、
これはデータのストリームの名前とそれらが生のトレーニングデータでどのように参照されるかを定義します :
# モデル語彙ファイルをロードするためのヘルパー関数。
def get_vocab(path):
# get the vocab for printing output sequences in plaintext
vocab = [w.strip() for w in open(path).readlines()]
i2w = { i:w for i,w in enumerate(vocab) }
w2i = { w:i for i,w in enumerate(vocab) }
return (vocab, i2w, w2i)
# 語彙データを読み、そして該当するインデックスを生成します。
vocab, i2w, w2i = get_vocab(dataPath['vocab_file'])
input_vocab_dim = 69
label_vocab_dim = 69
# Print vocab and the correspoding mapping to the phonemes
print("Vocabulary size is", len(vocab))
print("First 15 letters are:")
print(vocab[:15])
print()
print("Print dictionary with the vocabulary mapping:")
print(i2w)
Vocabulary size is 69
First 15 letters are:
["'", '</s>', '<s/>', '<s>', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K']
Print dictionary with the vocabulary mapping:
{0: "'", 1: '</s>', 2: '<s/>', 3: '<s>', 4: 'A', 5: 'B', 6: 'C', 7: 'D', 8: 'E', 9: 'F', 10: 'G', 11: 'H', 12: 'I', 13: 'J', 14: 'K', 15: 'L', 16: 'M', 17: 'N', 18: 'O', 19: 'P', 20: 'Q', 21: 'R', 22: 'S', 23: 'T', 24: 'U', 25: 'V', 26: 'W', 27: 'X', 28: 'Y', 29: 'Z', 30: '~AA', 31: '~AE', 32: '~AH', 33: '~AO', 34: '~AW', 35: '~AY', 36: '~B', 37: '~CH', 38: '~D', 39: '~DH', 40: '~EH', 41: '~ER', 42: '~EY', 43: '~F', 44: '~G', 45: '~HH', 46: '~IH', 47: '~IY', 48: '~JH', 49: '~K', 50: '~L', 51: '~M', 52: '~N', 53: '~NG', 54: '~OW', 55: '~OY', 56: '~P', 57: '~R', 58: '~S', 59: '~SH', 60: '~T', 61: '~TH', 62: '~UH', 63: '~UW', 64: '~V', 65: '~W', 66: '~Y', 67: '~Z', 68: '~ZH'}
そしてリーダーを作成しましょう :
def create_reader(path, is_training):
return C.io.MinibatchSource(C.io.CTFDeserializer(path, C.io.StreamDefs(
features = C.io.StreamDef(field='S0', shape=input_vocab_dim, is_sparse=True),
labels = C.io.StreamDef(field='S1', shape=label_vocab_dim, is_sparse=True)
)), randomize = is_training, max_sweeps = C.io.INFINITELY_REPEAT if is_training else 1)
# トレーニング用データリーダー
train_reader = create_reader(dataPath['training'], True)
# 検証用データリーダー
valid_reader = create_reader(dataPath['validation'], True)
4. モデル作成
ハイパー・パラメータの設定
ネットワークの複雑さを制御するための多くの設定を持ちます。
入力 shape や埋め込み (= embedding) を使用するか否か (そしてどのサイズを使用するか)、そして attention を使用するか否か、等々のオプションです。それらを、後でネットワークグラフを構築するときに使用されるものとして今ここで設定します :
hidden_dim = 512
num_layers = 2
attention_dim = 128
use_attention = True
use_embedding = True
embedding_dim = 200
vocab = ([w.strip() for w in open(dataPath['vocab_file']).readlines()]) # all lines of vocab_file in a list
length_increase = 1.5
次に、2つの特殊なパラメータを設定します: 文の最初 (BOS) と文の最後 (EOS) を示すために使用されるシンボルです。
この場合、シークエンス開始シンボルはタグ $<s>$、そしてシークエンス終了シンボルは終了タグ $</s>$ になります。
シークエンス開始と終了タグは sequence-to-sequence ネットワークにおいて次の理由で重要です。
-
シークエンス開始タグはデコーダに対して "前もって教えるもの (= primer)" です; 出力シークエンスを生成してそして RNN は何某かの入力を要求しますので、シークエンス開始トークンはデコーダにその最初に生成されたトークンを吐く (= emit) ようにさせることを "前もって教えます"。
-
シークエンス終了トークンもまた重要です。何故ならばデコーダは、シークエンスが終了したときにこのトークンを出力するために学習するからです。そうでなければ生成するためのシークエンスがどのくらいの長さであるかを知ることがないからです。
下のコードブロックで、シークエンス開始シンボルを Constant としてセットアップします、これはデコーダ LSTM にその initial_state として後で渡されます。更に、シークエンス終了シンボルのインデックスを得て、デコーダはトークンを生成するのをいつやめるかを知るためにそれを使用できます :
sentence_start = C.Constant(np.array([w=='<s>' for w in vocab], dtype=np.float32))
sentence_end_index = vocab.index('</s>')
4-1 ステップ 1 : ネットワークへの入力をセットアップする
CNTK の動的軸
CNTK を理解する際に重要なコンセプトの一つは軸の2つの型のアイデアです :
-
静的軸、これは変数の shape の伝統的な軸です、そして
-
動的軸、これは計算時に変数が実際のデータにバインドされるまで未知である次元を持ちます。
※ シークエンスの軸についての詳細は以下の記事を参考にしてください :
CNTK 2.2 Python API 入門 (4) - LSTM で時系列予測 : IoT データによる太陽光発電出力予測
3. シークエンスの理解
動的軸はリカレント・ニューラルネットワークの世界では取り分け重要です。
早期に最大シークエンス長を決定し、そのサイズにシークエンスをパディングし、そして計算を浪費する代わりに、
CNTK の動的軸は、できる限り効率的であるようにミニバッチに自動的にパックされるような可変なシークエンス長を可能にします。
シークエンスをセットアップするとき、考慮すべき重要な 2つの動的軸 があります。
1つ目はバッチ軸で、この軸に沿って複数のシークエンスがバッチ化されます。
2つ目はそのシークエンスに特有の動的軸です。
後者は、データの可変なシークエンス長ゆえに特定の入力に特有のものです。
例えば、sequence to sequence ネットワークでは、2つのシークエンスを持ちます: 入力シークエンス、そして 出力 (あるいは label) シークエンス です。
このタイプのネットワークをパワフルにするものの一つは、入力シークエンスと出力シークエンスの長さが互いに対応しなければならないというわけではないことです。(つまり長さが異なっていてもかまいません。)
それゆえに、入力シークエンスと出力シークエンスの両者はそれら自身の独自の動的軸を必要とします。
◆ 入力シークエンスのための inputAxis と出力シークエンスのための labelAxis を Axis で作成します。
それからモデルへの入力をこれら2つの独自な動的軸に渡るシークエンスを作成することにより定義します。
InputSequence と LabelSequence は SequenceOver による型宣言であることに注意してください。これは、InputSequence は inputAxis 軸に渡るシークエンスから構成される型であることを意味します :
# Source and target inputs to the model
inputAxis = C.Axis('inputAxis')
labelAxis = C.Axis('labelAxis')
InputSequence = C.layers.SequenceOver[inputAxis]
LabelSequence = C.layers.SequenceOver[labelAxis]
4-2 ステップ 2 : ネットワークを定義する
sequence-to-sequence ネットワークは、最も基本的なところで、 RNN (LSTM) エンコーダに RNN (LSTM) デコーダ、そして Dense 出力層が続きます。
CNTK 層ライブラリを使用してエンコーダとデコーダの両者を実装します。これらは CNTK Function として作成されます。
create_model() Python 関数は encode と decode CNTK Function の両者を作成します。
decode 関数は encode 関数を直接利用して create_model() の戻り値は CNTK Function decode それ自身になります。
エンコーダ
入力を Embedding (訓練プロセスの一部として学習されます) を通して渡すことから始めます。
この関数が埋め込みを望む場合でもそうでない場合でもエンコーダの Sequential ブロックとデコーダが使用できるように、
use_embedding パラメータが False である場合には identity 関数を使用します。
それからエンコーダ層を次のように宣言します :
最初に、入力を embed 関数を通して渡してそしてそれを安定させます (Stabilizer)。
これは学習にスカラー・パラメータを追加するもので、トレーニング中にネットワークがより迅速に収束することを助けます。
それから、エンコーダ内部に望む数の LSTM 層の各々に対して、最後の一つを除いて、LSTM recurrence をセットアップします。
attention を使用しない場合には最後の recurrence は Fold になるでしょう、何故ならば最後の隠れステートをデコーダに渡すだけだからです。
けれども、attention を使用する場合には、もう一つの通常の LSTM Recurrence を使用します、それに渡ってデコーダはその attention を後で配置します。
下図のダイアグラムは、attention を持つ sequence-to-sequence ネットワークの積層されたバージョンがどのように動作するかを示します。エンコーダとデコーダの各層の出力はそれのすぐ上の層への入力として使用されます。
Attention モデルはエンコーダのトップ層にフォーカスしてそしてデコーダの最初の層に情報を与えます :
Image(url="https://cntk.ai/jup/cntk204_s2s3.png", width=900)
デコーダ
デコーダに対しては最初に幾つかのサブ層を定義します : デコーダ入力のための Stabilizer、デコーダの層の各々のための Recurrence ブロック、LSTM のスタックの出力のための Stabilizer、そして最後の Dense 出力層です。
attention を使用する場合は、AttentionModel 関数 attention_model もまた作成します。これは、次の出力トークンを生成する間に与えられたステップに対してもっとも使用されるべき、エンコーダ隠れステートに置かれた重点を持つ、デコーダの隠れステートの拡張版 (= augmented version) を返します。
それから CNTK Function decode を構築します。
デコレータ @Function は標準的な Python 関数を与えられた引数と戻り値を持つ正当な CNTK Function に変えます。
デコーダはトレーニング中にはテスト時の間とは異なって動作します。
トレーニングの間、デコーダ Recurrence への history (i.e. 入力) は正解ラベルから成ります。これは、$y^{(t=2)}$ を生成する間、例えば、入力は $y^{(t=1)}$ であることを意味します。
けれども、評価あるいは "テスト時" の間には、デコーダへの入力はモデルの実際の出力でしょう。
それゆえに greedy デコーダ -- それはここで実装するものです -- についてはその入力は最終 Dense 層の hardmax です。
デコーダ Function decode は2つの引数を取ります : (1) input シークエンス; そして (2) デコーダ: history です。
最初に、デコーダは input シークエンスを先にセットアップしたエンコーダ関数 encode を通して走らせます。
それから history を得て必要であればそれをその埋め込みにマップします。
そしてデコーダの Recurrence を通してそれを実行する前に埋め込み表現は stabilize されます。
Recurrence の各々の層について、埋め込まれた history (今では r として表されます) を Recurrence の LSTM を通して実行します。
-
attention を使用しない場合は、エンコーダの最後の隠れステートの値にセットされたその初期ステートを持つ
Recurrenceを通してそれを実行します。(attention を使用しない時エンコーダを backwards に実行しますので、時系列的には "最後の (final)" 隠れステートは実際には最初の隠れステートであることに注意してください。) -
attention を使用する場合には、
attention_model関数を使用して補助 (= auxiliary) 入力h_attを計算します、そしてそれを入力x上に splice します。それからこの拡張されたxはデコーダのRecurrenceのための入力として使用されます。
最後に、デコーダの出力を stabilize します、それを最後の Dense 層 proj_out を通し、そして Label 層を使用します。これは後でその層への単純なアクセスを許可するダミー層です :
# s2s モデルを作成します。
def create_model(): # :: (history*, input*) -> logP(w)*
# 埋め込み (Embedding): (input*) --> embedded_input*
embed = C.layers.Embedding(embedding_dim, name='embed') if use_embedding else identity
# エンコーダ: (input*) --> (h0, c0)
# i-th 層の出力を (i+1)th 層に入力として渡すことにより LSTM の複数の層を作成します。
# Note: We go_backwards for the plain model, but forward for the attention model.
with C.layers.default_options(enable_self_stabilization=True, go_backwards=not use_attention):
LastRecurrence = C.layers.Fold if not use_attention else C.layers.Recurrence
encode = C.layers.Sequential([
embed,
C.layers.Stabilizer(),
C.layers.For(range(num_layers-1), lambda:
C.layers.Recurrence(C.layers.LSTM(hidden_dim))),
LastRecurrence(C.layers.LSTM(hidden_dim), return_full_state=True),
(C.layers.Label('encoded_h'), C.layers.Label('encoded_c')),
])
# デコーダ: (history*, input*) --> unnormalized_word_logp*
# ここで history はこれらの一つです、delayed by 1 step and <s> prepended:
# - training: labels
# - testing: its own output hardmax(z) (greedy デコーダ)
with C.layers.default_options(enable_self_stabilization=True):
# サブ層
stab_in = C.layers.Stabilizer()
rec_blocks = [C.layers.LSTM(hidden_dim) for i in range(num_layers)]
stab_out = C.layers.Stabilizer()
proj_out = C.layers.Dense(label_vocab_dim, name='out_proj')
# attention モデル
if use_attention: # maps a decoder hidden state and all the encoder states into an augmented state
attention_model = C.layers.AttentionModel(attention_dim,
name='attention_model') # :: (h_enc*, h_dec) -> (h_dec augmented)
# 層 function
@C.Function
def decode(history, input):
encoded_input = encode(input)
r = history
r = embed(r)
r = stab_in(r)
for i in range(num_layers):
rec_block = rec_blocks[i] # LSTM(hidden_dim) # :: (dh, dc, x) -> (h, c)
if use_attention:
if i == 0:
@C.Function
def lstm_with_attention(dh, dc, x):
h_att = attention_model(encoded_input.outputs[0], dh)
x = C.splice(x, h_att)
return rec_block(dh, dc, x)
r = C.layers.Recurrence(lstm_with_attention)(r)
else:
r = C.layers.Recurrence(rec_block)(r)
else:
# unlike Recurrence(), the RecurrenceFrom() layer takes the initial hidden state as a data input
r = C.layers.RecurrenceFrom(rec_block)(*(encoded_input.outputs + (r,))) # :: h0, c0, r -> h
r = stab_out(r)
r = proj_out(r)
r = C.layers.Label('out_proj_out')(r)
return r
return decode
上のブロックで定義したネットワークは、利用するためには最初にラップされなければならない "抽象 (abstract)" モデルとして考えることができます。この場合 :
-
最初にモデルの "トレーニング" バージョンを作成するためにそれを使用します (そこではデコーダのための history は正解ラベルです)。
-
そしてそれをモデルの greedy "デコーディング" バージョンを作成するために使用します。そこではデコーダのための history はネットワークの hardmax 出力です。
次の章ではこれらのモデル・ラッパーをセットアップします。
5. トレーニング
トレーニングを開始する前に、トレーニング・ラッパー、greedy デコーディング・ラッパー、そしてモデルをトレーニングするための評価 (= criterion) 関数を定義します。
トレーニング・ラッパーの定義から始めましょう :
def create_model_train(s2smodel):
# トレーニングで使用されるモデル (history は labels から知れます)
# note: labels は initial <s> を含んではなりません。
@C.Function
def model_train(input, labels): # (input*, labels*) --> (word_logp*)
# デコーダへの入力は常に特殊な label sequence start トークンで始まります。
# そして label sequence (for training) または出力 (for execution) の以前の値を使用します。
past_labels = C.layers.Delay(initial_state=sentence_start)(labels)
return s2smodel(past_labels, input)
return model_train
@Function デコレータを再度使用して CNTK Function model_train を作成します。
この関数は入力シークエンス input と出力シークエンス labels を引数として取ります。
Delay 層を通して past_labels は (先に作成された) モデルのための history としてセットアップされて使用されます。
これは sentence_start の initial_state を持ち、入力 labels のために以前の時系列ステップ値を返します。
それゆえに、labels ['a', 'b', 'c'] を与えた場合 past_labels は ['<s>', 'a', 'b', 'c'] を含み、
そして history past_labels と入力 input で呼び出された抽象 base モデルを返します。
先に進みます。greedy デコーディング・モデル・ラッパーもまた作成します :
def create_model_greedy(s2smodel):
# (greedy) デコーディングで使用されるモデル (history is decoder's own output)
@C.Function
@C.layers.Signature(InputSequence[C.layers.Tensor[input_vocab_dim]])
def model_greedy(input): # (input*) --> (word_sequence*)
# デコーディングは sentence_start から始まる unfold() 演算です。
# s2smodel (history*, input* -> word_logp*) をジェネレータ (history* -> output*) に変形しなければなりません。
# which holds 'input' in its closure.
unfold = C.layers.UnfoldFrom(lambda history: s2smodel(history, input) >> C.hardmax,
# stop once sentence_end_index was max-scoring output
until_predicate=lambda w: w[...,sentence_end_index],
length_increase=length_increase)
return unfold(initial_state=sentence_start, dynamic_axes_like=input)
return model_greedy
CNTK Function model_greedy を作成しますが、これは単一の引数のみを取ります。
これはもちろんテスト時にモデルを使用するときどのような labels も持たないからです -- それを作成するのはモデルのジョブです。
ここでは、UnfoldFrom 層を使用します、これは base モデルを current history で実行してそれを hardmax に注ぎます (i.e. lambda history: s2smodel(history, input) >> C.hardmax)。それから hardmax の出力は history の一部になりそして Reccurence を sentence_end_index に達するまで unfold し続けます。
出力シークエンスの最大長 (i.e. デコーダの最大 unfolding) は length_increase に渡される乗数により決定されます。
length_increase は 1.5 に設定されていますので、各出力シークエンスの最大長はその入力の 1.5 倍です。
訓練ループを設定する前に行なう最後のことは、モデルのための評価 (= criterion) 関数を作成する関数を定義することです :
def create_criterion_function(model):
@C.Function
@C.layers.Signature(input=InputSequence[C.layers.Tensor[input_vocab_dim]],
labels=LabelSequence[C.layers.Tensor[label_vocab_dim]])
def criterion(input, labels):
# criterion 関数は labels から <s> を drop しなければなりません。
postprocessed_labels = C.sequence.slice(labels, 1, 0) # <s> A B C </s> --> A B C </s>
z = model(input, postprocessed_labels)
ce = C.cross_entropy_with_softmax(z, postprocessed_labels)
errs = C.classification_error(z, postprocessed_labels)
return (ce, errs)
return criterion
評価 (= criterion) 関数を作成します。これは labels から sequence-start シンボルを drop して、与えられた input と labels でモデルを実行して、そして正解と比較するためにその出力を使用します。
損失関数としては cross_entropy_with_softmax を使用します。
そしてメトリクス classification_error は生成精度の単語毎のパーセント・エラーを与えます。
CNTK Function criterion はこれらの値をタプルとして返し、そして Python 関数 create_criterion_function(model) はその CNTK Function を返します。
次にトレーニング・ループの作成へ移行します :
def train(train_reader, valid_reader, vocab, i2w, s2smodel, max_epochs, epoch_size):
# s2smodel のためのトレーニング・ラッパーを作成します、そして criterion 関数も。
model_train = create_model_train(s2smodel)
criterion = create_criterion_function(model_train)
# そしてまた greedy デコーダも配線 (= wire) します。これによって検証サンプル上の進捗を適切にログ出力できます。
# これは実際の訓練プロセスのためには使用されません。
model_greedy = create_model_greedy(s2smodel)
# モデル訓練を駆動するための trainer オブジェクトをインスタンス化します。
minibatch_size = 72
lr = 0.001 if use_attention else 0.005
learner = C.fsadagrad(model_train.parameters,
lr = C.learning_rate_schedule([lr]*2+[lr/2]*3+[lr/4], C.UnitType.sample, epoch_size),
momentum = C.momentum_as_time_constant_schedule(1100),
gradient_clipping_threshold_per_sample=2.3,
gradient_clipping_with_truncation=True)
trainer = C.Trainer(None, criterion, learner)
# トレーニングするためのシークエンスのミニバッチを取得してモデル訓練を遂行します。
total_samples = 0
mbs = 0
eval_freq = 100
# 有用なトレーニング情報を出力表示します。
C.logging.log_number_of_parameters(model_train) ; print()
progress_printer = C.logging.ProgressPrinter(freq=30, tag='Training')
# a hack to allow us to print sparse vectors
sparse_to_dense = create_sparse_to_dense(input_vocab_dim)
for epoch in range(max_epochs):
while total_samples < (epoch+1) * epoch_size:
# 訓練データの次のミニバッチを得ます。
mb_train = train_reader.next_minibatch(minibatch_size)
# トレーニングを行ないます。
trainer.train_minibatch({criterion.arguments[0]: mb_train[train_reader.streams.features],
criterion.arguments[1]: mb_train[train_reader.streams.labels]})
progress_printer.update_with_trainer(trainer, with_metric=True) # log progress
# every N MBs evaluate on a test sequence to visually show how we're doing
if mbs % eval_freq == 0:
mb_valid = valid_reader.next_minibatch(1)
# デコーダ出力モデル (i.e. 正解を使用しないこと) 上で評価を実行します。
e = model_greedy(mb_valid[valid_reader.streams.features])
print(format_sequences(sparse_to_dense(mb_valid[valid_reader.streams.features]), i2w))
print("->")
print(format_sequences(e, i2w))
# attention window を可視化します。
if use_attention:
debug_attention(model_greedy, mb_valid[valid_reader.streams.features])
total_samples += mb_train[train_reader.streams.labels].num_samples
mbs += 1
# エポックのためのスタッツの要約をログ出力します。
progress_printer.epoch_summary(with_metric=True)
# done: save the final model
model_path = "model_%d.cmf" % epoch
print("Saving final model to '%s'" % model_path)
s2smodel.save(model_path)
print("%d epochs complete." % max_epochs)
トレーニングのためのモデルの一つのバージョン (及び、その関連する criterion 関数) と評価のためのモデルの一つのバージョンを作成しました。通常は後者のバージョンは必要ではありませんが、ここでそれを作成することでトレーニングが進むにつれてそのモデルが生成するシークエンス等を見ることができますので、モデルがどのように収束するかを視覚的に理解するために非トレーニング・モデルから定期的にサンプリングすることが可能です。
それから訓練ループのために必要な幾つかの標準的な変数をセットアップします。まずは minibatch_size と初期学習率 lr を設定します。そして fsadagrad アルゴリズム、ゆっくりと学習率を減じる learning_rate_schedule、勾配が爆発する制御を助けるために勾配クリッピング等を使用して learner を初期化します。
最終的に Trainer オブジェクト trainer を作成します。
CNTK の ProgressPrinter クラスも利用します、これは minibatch/epoch 毎の平均メトリクスを計算するケアをして 30 ミニバッチ毎に更新するように設定します。
そして最後にもう一つだけ、訓練ループを開始する前に sparse_to_dense と呼ばれる関数を初期化します。
この関数は検証のために使用する入力シークエンスデータを (それはスパースなので) 正しく出力表示するために使用します。
その関数は次のように定義されます :
# dummy for printing the input sequence below. Currently needed because input is sparse.
def create_sparse_to_dense(input_vocab_dim):
I = C.Constant(np.eye(input_vocab_dim))
@C.Function
@C.layers.Signature(InputSequence[C.layers.SparseTensor[input_vocab_dim]])
def no_op(input):
return C.times(input, I)
return no_op
訓練ループの内側では、多くの他の CNTK ネットワークと殆ど同様に進めます。
ミニバッチ・データの次の一束を要求して、トレーニングを遂行して、そして progress_printer を使用して進捗をスクリーンに出力表示します。
その後、標準的な流れから分岐しますが、そこではネットワークの model_greedy バージョンを使用して評価を実行します。
単一のシークエンス、"ABADI" を通してネットワークがその時点で予測するものを見るためにです。
訓練ループの他の違いはオプションの attention ウィンドウの可視化です。
(下のブロックで定義される) debug_attention 関数の呼び出しは、(生成された出力トークンの各々のために) エンコーダの隠れステートの各々にデコーダが置く重みを示してくれます。
また、format_sequences 関数は入出力シークエンスをスクリーンに出力表示するために必要とされます :
# Given a vocab and tensor, print the output
def format_sequences(sequences, i2w):
return [" ".join([i2w[np.argmax(w)] for w in s]) for s in sequences]
# to help debug the attention window
def debug_attention(model, input):
q = C.combine([model, model.attention_model.attention_weights])
#words, p = q(input) # Python 3
words_p = q(input)
words = words_p[0]
p = words_p[1]
output_seq_len = words[0].shape[0]
p_sq = np.squeeze(p[0][:output_seq_len,:,:]) # (batch, output_len, input_len, 1)
opts = np.get_printoptions()
np.set_printoptions(precision=5)
print(p_sq)
np.set_printoptions(**opts)
◆ エポックの小さなサブセットについてネットワークをトレーニングしましょう :
model = create_model()
train(train_reader, valid_reader, vocab, i2w, model, max_epochs=1, epoch_size=25000)
Training 8347832 parameters in 29 parameter tensors.
['<s> A B A D I </s>']
->
['O O A ~M ~R </s>']
[[ 0.14166 0.1422 0.14248 0.14305 0.14337 0.14396 0.14327]
[ 0.14166 0.1422 0.14248 0.14305 0.14337 0.14396 0.14327]
[ 0.14166 0.1422 0.14248 0.14305 0.14337 0.14396 0.14328]
[ 0.14166 0.1422 0.14248 0.14305 0.14337 0.14396 0.14328]
[ 0.14166 0.1422 0.14248 0.14305 0.14337 0.14395 0.14327]
[ 0.14166 0.1422 0.14248 0.14305 0.14337 0.14396 0.14327]]
Minibatch[ 1- 30]: loss = 4.145851 * 1601, metric = 87.38% * 1601;
Minibatch[ 31- 60]: loss = 3.648529 * 1601, metric = 86.45% * 1601;
Minibatch[ 61- 90]: loss = 3.320425 * 1548, metric = 88.44% * 1548;
['<s> A B A D I </s>']
->
['~N ~N </s>']
[[ 0.1419 0.14222 0.14241 0.14298 0.14331 0.14392 0.14326]
[ 0.1419 0.14223 0.14241 0.14298 0.14331 0.14391 0.14326]
[ 0.1419 0.14223 0.14241 0.14298 0.14331 0.14391 0.14326]]
Minibatch[ 91- 120]: loss = 3.232078 * 1567, metric = 86.02% * 1567;
Minibatch[ 121- 150]: loss = 3.212716 * 1580, metric = 83.61% * 1580;
Minibatch[ 151- 180]: loss = 3.215528 * 1544, metric = 84.26% * 1544;
['<s> A B A D I </s>']
->
['~R ~R ~AH ~AH ~AH </s>']
[[ 0.14147 0.142 0.14236 0.14305 0.14347 0.14414 0.14352]
[ 0.14147 0.142 0.14236 0.14305 0.14347 0.14413 0.14352]
[ 0.14147 0.142 0.14236 0.14305 0.14347 0.14413 0.14352]
[ 0.14147 0.142 0.14236 0.14305 0.14347 0.14413 0.14352]
[ 0.14147 0.142 0.14236 0.14305 0.14347 0.14413 0.14352]
[ 0.14147 0.142 0.14236 0.14305 0.14347 0.14413 0.14352]]
Minibatch[ 181- 210]: loss = 3.145194 * 1565, metric = 82.81% * 1565;
Minibatch[ 211- 240]: loss = 3.186279 * 1583, metric = 83.26% * 1583;
Minibatch[ 241- 270]: loss = 3.127671 * 1562, metric = 83.10% * 1562;
Minibatch[ 271- 300]: loss = 3.152009 * 1551, metric = 83.69% * 1551;
['<s> A B A D I </s>']
->
['~R ~R ~R ~AH </s>']
[[ 0.1412 0.14181 0.14228 0.14308 0.14358 0.14431 0.14373]
[ 0.14121 0.14182 0.14228 0.14308 0.14358 0.14431 0.14373]
[ 0.14121 0.14181 0.14228 0.14308 0.14358 0.14431 0.14373]
[ 0.14121 0.14181 0.14228 0.14308 0.14358 0.14431 0.14373]
[ 0.14121 0.14181 0.14228 0.14308 0.14358 0.14431 0.14373]]
Minibatch[ 301- 330]: loss = 3.134388 * 1575, metric = 82.92% * 1575;
Minibatch[ 331- 360]: loss = 3.098724 * 1569, metric = 82.86% * 1569;
Minibatch[ 361- 390]: loss = 3.104150 * 1567, metric = 82.45% * 1567;
['<s> A B A D I </s>']
->
['~K ~R ~R ~AH </s>']
[[ 0.14097 0.14161 0.14217 0.14309 0.14369 0.14451 0.14396]
[ 0.14099 0.14162 0.14218 0.14309 0.14368 0.14449 0.14395]
[ 0.14098 0.14162 0.14218 0.14309 0.14368 0.1445 0.14395]
[ 0.14098 0.14162 0.14218 0.14309 0.14369 0.1445 0.14396]
[ 0.14098 0.14162 0.14218 0.14309 0.14368 0.1445 0.14396]]
Minibatch[ 391- 420]: loss = 3.123781 * 1601, metric = 82.26% * 1601;
Finished Epoch[1]: [Training] loss = 3.276010 * 22067, metric = 84.25% * 22067 22.261s (991.3 samples/s);
Saving final model to 'model_0.cmf'
1 epochs complete.
CPU times: user 1min 48s, sys: 4.28 s, total: 1min 52s
Wall time: 22.9 s
見て分かるように、損失はそこそこ下がりましたが、出力シークエンスは依然として期待するものとはかけ離れています。
フル・エポックについてトレーニングを実行するためには下のコード行をアンコメントして実行してください。
これによって非常に良い書記素-音素翻訳モデルが動作することを見ることができます :
# Uncomment the line below to train the model for a full epoch
# train(train_reader, valid_reader, vocab, i2w, model, max_epochs=1, epoch_size=908241)
以下は、上のコード行をアンコメントした上でトレーニングを再実行した際のログ出力の抜粋です。Tesla K-80 でおよそ 10 分間程度かかります。
※ 先にトレーニングしたモデル・ファイルに上書きされますので注意してください :
Training 8347832 parameters in 29 parameter tensors.
['<s> A B A D I </s>']
->
['~R ~R ~IH ~AH ~N </s>']
[[ 0.1409 0.14156 0.14215 0.14309 0.14371 0.14456 0.14402]
[ 0.14093 0.14158 0.14216 0.14309 0.14371 0.14454 0.144 ]
[ 0.14092 0.14157 0.14215 0.14309 0.14371 0.14455 0.14401]
[ 0.14092 0.14157 0.14215 0.14309 0.14371 0.14455 0.14402]
[ 0.14091 0.14156 0.14215 0.14309 0.14371 0.14455 0.14402]
[ 0.1409 0.14156 0.14215 0.14309 0.14372 0.14455 0.14402]]
Minibatch[ 1- 30]: loss = 3.067131 * 1563, metric = 81.96% * 1563;
Minibatch[ 31- 60]: loss = 3.046372 * 1547, metric = 80.87% * 1547;
Minibatch[ 61- 90]: loss = 3.044684 * 1552, metric = 80.54% * 1552;
['<s> A B A D I </s>']
->
['~K ~R ~AH ~N ~AH ~N </s>']
[[ 0.14035 0.14118 0.14197 0.14313 0.14393 0.14495 0.14449]
[ 0.14039 0.14121 0.14199 0.14313 0.14392 0.14491 0.14445]
[ 0.14037 0.14119 0.14198 0.14313 0.14392 0.14493 0.14447]
[ 0.14037 0.14119 0.14198 0.14313 0.14392 0.14493 0.14448]
[ 0.14035 0.14118 0.14198 0.14314 0.14393 0.14494 0.14448]
[ 0.14035 0.14118 0.14197 0.14313 0.14393 0.14495 0.14449]
[ 0.14036 0.14118 0.14198 0.14313 0.14393 0.14494 0.14448]]
Minibatch[ 91- 120]: loss = 2.987230 * 1577, metric = 78.19% * 1577;
Minibatch[ 121- 150]: loss = 2.990124 * 1536, metric = 79.17% * 1536;
Minibatch[ 151- 180]: loss = 2.911836 * 1576, metric = 77.41% * 1576;
...
['<s> A B A D I </s>']
->
['~AH ~B ~EY ~D ~IY </s>']
[[ 0.02075 0.06884 0.74875 0.08968 0.02135 0.02994 0.02068]
[ 0.01757 0.00352 0.0428 0.89391 0.03066 0.00768 0.00387]
[ 0.0299 0.01257 0.02315 0.04466 0.4676 0.25622 0.16589]
[ 0.01426 0.00419 0.00897 0.00664 0.14818 0.49428 0.32348]
[ 0.0035 0.00517 0.00745 0.00479 0.00711 0.11724 0.85474]
[ 0.00514 0.01768 0.01452 0.01208 0.01375 0.01245 0.92438]]
Minibatch[15181-15210]: loss = 0.287220 * 1545, metric = 10.29% * 1545;
Minibatch[15211-15240]: loss = 0.278089 * 1588, metric = 9.38% * 1588;
Minibatch[15241-15270]: loss = 0.261368 * 1519, metric = 9.41% * 1519;
Minibatch[15271-15300]: loss = 0.246407 * 1551, metric = 9.03% * 1551;
['<s> A B A D I </s>']
->
['~AE ~B ~AH ~D ~IY </s>']
[[ 0.03394 0.10725 0.67745 0.07971 0.01879 0.04419 0.03866]
[ 0.02775 0.00393 0.06235 0.86144 0.02913 0.00994 0.00546]
[ 0.02521 0.00406 0.00948 0.05991 0.35529 0.2981 0.24795]
[ 0.00982 0.00613 0.00406 0.00377 0.10282 0.49103 0.38237]
[ 0.00408 0.00703 0.00749 0.00495 0.00519 0.11312 0.85815]
[ 0.00818 0.02048 0.01748 0.0164 0.01652 0.01523 0.90571]]
Minibatch[15301-15330]: loss = 0.309396 * 1570, metric = 10.76% * 1570;
Finished Epoch[1]: [Training] loss = 0.671233 * 799258, metric = 20.66% * 799258 644.542s (1240.0 samples/s);
Saving final model to 'model_0.cmf'
1 epochs complete.
CPU times: user 1h 1min 47s, sys: 2min 23s, total: 1h 4min 11s
Wall time: 10min 44s
6. ネットワークをテストする
書記素-音素変換のための sequence-to-sequence ネットワークをトレーニングしたので、最初に手元のテストセットでその精度をテストしましょう。それから対話環境でも試してみます。これは私たち自身のシークエンスを入力してモデルが何を予測するかを見ることができます。
テスト文字列のエラー率を決定することから始めます。
トレーニングの最後に、s2smodel.save(model_path) 行を使用してモデルをセーブしました :
# done: save the final model
model_path = "model_%d.cmf" % epoch
print("Saving final model to '%s'" % model_path)
s2smodel.save(model_path)
print("%d epochs complete." % max_epochs)
テストするためには、最初にそのモデルをロードしてそれを通してテストデータを走らせる必要があります。
モデルを load したら、テストデータにアクセスするために構成されたリーダーを作成します。
今回は create_reader 関数の is_training 引数には False を渡します、これはテスト・モードであることを示し、データを一度だけ渡すことになります :
# エポック 0 のためのモデルをロードします。
model_path = "model_0.cmf"
model = C.Function.load(model_path)
# create a reader pointing at our testing data
test_reader = create_reader(dataPath['testing'], False)
次にテスト関数を定義する必要があります。
この関数には reader、学習された s2smodel、そして語彙マップ i2w を引数として渡します。
これによってモデルの予測をテストセット・ラベルと直接的に比較可能になります。
テストセットに渡りループして、効率のために 512 サイズのミニバッチ上でモデルを評価して、そしてエラー率を追跡します。
※ シークエンス毎にテストすることに注意してください。これは、シークエンスが正しいと考えられるためには、その生成されたシークエンスの総ての単一のトークンがラベルのトークンにマッチしなければならないことを意味します。
# これはテストセットをデコードして文字列エラー率をカウントします。
def evaluate_decoding(reader, s2smodel, i2w):
model_decoding = create_model_greedy(s2smodel) # wrap the greedy decoder around the model
progress_printer = C.logging.ProgressPrinter(tag='Evaluation')
sparse_to_dense = create_sparse_to_dense(input_vocab_dim)
minibatch_size = 512
num_total = 0
num_wrong = 0
while True:
mb = reader.next_minibatch(minibatch_size)
if not mb: # テストセットの終わりに達したら終了します。
break
e = model_decoding(mb[reader.streams.features])
outputs = format_sequences(e, i2w)
labels = format_sequences(sparse_to_dense(mb[reader.streams.labels]), i2w)
# prepend sentence start for comparison
outputs = ["<s> " + output for output in outputs]
num_total += len(outputs)
num_wrong += sum([label != output for output, label in zip(outputs, labels)])
rate = num_wrong / num_total
print("string error rate of {:.1f}% in {} samples".format(100 * rate, num_total))
return rate
上の関数を使用してデコーディングを評価します。
訓練データの小さなサブセットだけでトレーニングしたモデルを使用する場合にはエラー率が 100 % になります。
何故ならばそのような少量のトレーニング総量では総ての各々のトークンが正しくなる結果を得ることができないからです。
けれども、フル・エポックについてネットワークをトレーニングするための、
前章のブロックの行をアンコメントしてトレーニングした場合は、遥に改善されたモデルで完了しているでしょう。
さて、モデルのテストセット上の性能を評価しましょう :
# print the string error rate
evaluate_decoding(test_reader, model, i2w)
string error rate of 50.9% in 12855 samples
0.5089070400622326
フル・エポックのトレーニングを実行していないならば、上の出力は 100 % の文字列エラー率を意味する 1.0 になるでしょう。
けれども、もし (前章で該当行をアンコメントして) フル・エポックのトレーニングを遂行していたならば、より良いエラー率を得るでしょう。
上の 50.8 % の文字列エラー率は実際には悪くない数字です。
次に、上の evaluate_decoding 関数を音素毎のエラー率を出力するように変更しましょう。
これはより高い精度でエラーを計算することを意味しますが、そしてまたある意味では物事をより簡単にします。
何故ならば文字列エラー率では各サンプルで一つを除いて総ての音素が正しい場合でも依然として 100 % のエラー率になっていたからです。
次のブロックはその関数の修正版です :
# This decodes the test set and counts the string error rate.
def evaluate_decoding(reader, s2smodel, i2w):
model_decoding = create_model_greedy(s2smodel) # wrap the greedy decoder around the model
progress_printer = C.logging.ProgressPrinter(tag='Evaluation')
sparse_to_dense = create_sparse_to_dense(input_vocab_dim)
minibatch_size = 512
num_total = 0
num_wrong = 0
while True:
mb = reader.next_minibatch(minibatch_size)
if not mb: # finish when end of test set reached
break
e = model_decoding(mb[reader.streams.features])
outputs = format_sequences(e, i2w)
labels = format_sequences(sparse_to_dense(mb[reader.streams.labels]), i2w)
# prepend sentence start for comparison
outputs = ["<s> " + output for output in outputs]
for s in range(len(labels)):
for w in range(len(labels[s])):
num_total += 1
if w < len(outputs[s]): # in case the prediction is longer than the label
if outputs[s][w] != labels[s][w]:
num_wrong += 1
rate = num_wrong / num_total
print("{:.1f}".format(100 * rate))
return rate
# print the phoneme error rate
test_reader = create_reader(dataPath['testing'], False)
evaluate_decoding(test_reader, model, i2w)
10.5
0.10522915993790438
もしフル・エポック 1 回分の間トレーニングされたモデルを使用しているならば、
10 % 程度の音素エラー率を得るでしょう。これは悪くありません。
※ モデルの簡易トレーニング版を使用した場合には 45 % 程度のエラー率を得るでしょう。
対話的セッション
最後に、訓練されたモデルと簡単に相互作用できるような、対話的関数を作成します。
これはテストセットに含まれていない、ユーザ自身の入力シークエンスを試すことができます。
1 (フル) エポックの間トレーニングされたモデルを利用すればこれについても良い仕事を行ないますが、
更に時間をかけて 30 エポックの間トレーニングすれば、非常に素晴らしく遂行するでしょう。
最初に seaborn を含む、幾つかのグラフィクス・ライブラリをインポートします。これは attention の可視化を可能にします。
そして translate 関数を定義します。これは入力として NumPy ベースの表現を取り、そしてモデルを実行します :
# attention weight ヒートマップを表示するために必要なインポート。
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
%matplotlib inline
def translate(tokens, model_decoding, vocab, i2w, show_attention=False):
vdict = {v:i for i,v in enumerate(vocab)}
try:
w = [vdict["<s>"]] + [vdict[c] for c in tokens] + [vdict["</s>"]]
except:
print('Input contains an unexpected token.')
return []
# one_hot に変換します。
query = C.Value.one_hot([w], len(vdict))
pred = model_decoding(query)
pred = pred[0] # first sequence (we only have one) -> [len, vocab size]
if use_attention:
pred = np.squeeze(pred) # attention has extra dimensions
# print out translation and stop at the sequence-end tag
prediction = np.argmax(pred, axis=-1)
translation = [i2w[i] for i in prediction]
# attention ウィンドウを表示します (requires matplotlib, seaborn, として pandas)
if use_attention and show_attention:
q = C.combine([model_decoding.attention_model.attention_weights])
att_value = q(query)
# get the attention data up to the length of the output (subset of the full window)
att_value = np.squeeze(att_value[0][0:len(prediction),0:len(w)])
# set up the actual words/letters for the heatmap axis labels
columns = [i2w[ww] for ww in prediction]
index = [i2w[ww] for ww in w]
dframe = pd.DataFrame(data=np.fliplr(att_value.T), columns=columns, index=index)
sns.heatmap(dframe)
plt.show()
return translation
上の translate 関数は、ユーザによって入力された letters のリスト tokens、モデルの greedy デコーディング・バージョン model_decoding、語彙 vocab、vocab へのインデックス・マップ i2w、そして (attention ベクトルを可視化するか否かを決定する) オプション show_attention をとります。
入力を one_hot 表現に変換して、model_decoding(query) でモデルを通してそれを実行して、そして、各予測は実際には語彙全体に渡る確率分布ですから、各ステップのために最もあり得るトークンを得るために argmax を使用します。
attention ウィンドウを可視化するために、 attention_weights を (期待するような入力をとる) CNTK 関数に変えるために combine を使用します。このようにして得られた、関数 q を実行するとき、出力は attention_weights の値です。
このデータを sns (seaborn) が期待するフォーマットにするためるデータ操作を行なった上で可視化を示します。
最後に、ユーザに入力を反復することを可能にする、ユーザインタラクション・ループを書く必要があります :
def interactive_session(s2smodel, vocab, i2w, show_attention=False):
model_decoding = create_model_greedy(s2smodel) # wrap the greedy decoder around the model
import sys
print('Enter one or more words to see their phonetic transcription.')
while True:
line = input("> ")
#if isTest(): # Testing a prefilled text for routine testing
# line = "psychology"
#else:
# line = input("> ")
if line.lower() == "quit":
break
# tokenize. Our task is letter to sound.
out_line = []
for word in line.split():
in_tokens = [c.upper() for c in word]
out_tokens = translate(in_tokens, model_decoding, vocab, i2w, show_attention=True)
out_line.extend(out_tokens)
out_line = [" " if tok == '</s>' else tok[1:] for tok in out_line]
print("=", " ".join(out_line))
sys.stdout.flush()
#if isTest(): #If test environment we will test the translation only once
# break
上の関数は単純にモデルをラップする greedy デコーダを作成してそして連続的にユーザに入力を要求するものです。
そしてその入力は translate 関数に渡されます。
interactive_session(model, vocab, i2w, show_attention=True)
Enter one or more words to see their phonetic transcription.
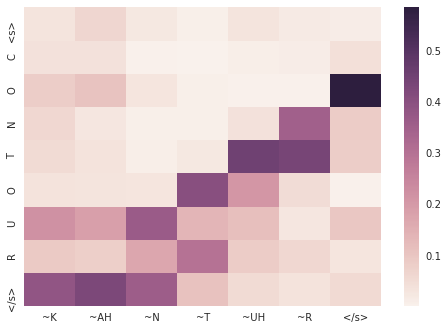
> blah
= B L AE
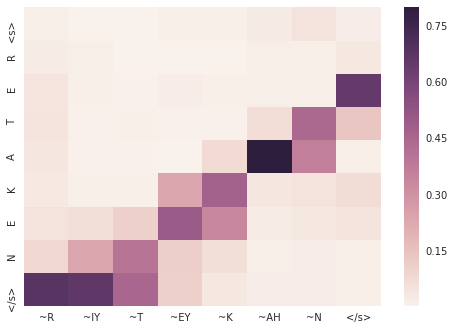
入力の異なるパートが出力の異なるトークンを生成するためにどのように重要かを、attention 重みがどのように示すか、見て取れるでしょう。
◆ 最後に、(正解が分かっている) テストセットの中から幾つか試しておきます。
出力結果とともに、テストセットの該当シークエンスも併せて掲載します :
contour
> contour
= K AH N T UH R
2333 |S0 3:1 |# <s> |S1 3:1 |# <s>
2333 |S0 6:1 |# C |S1 49:1 |# ~K
2333 |S0 18:1 |# O |S1 30:1 |# ~AA
2333 |S0 17:1 |# N |S1 52:1 |# ~N
2333 |S0 23:1 |# T |S1 60:1 |# ~T
2333 |S0 18:1 |# O |S1 62:1 |# ~UH
2333 |S0 24:1 |# U |S1 57:1 |# ~R
2333 |S0 21:1 |# R |S1 1:1 |# </s>
2333 |S0 1:1 |# </s>
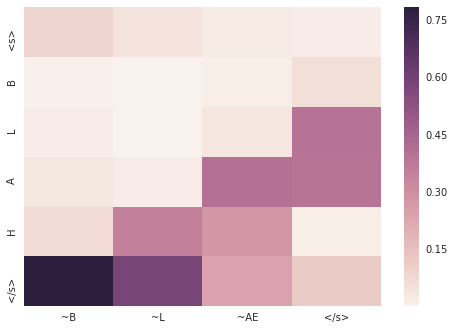
earthenware
> earthenware
= ER TH AH N W EH R
3363 |S0 3:1 |# <s> |S1 3:1 |# <s>
3363 |S0 8:1 |# E |S1 41:1 |# ~ER
3363 |S0 4:1 |# A |S1 61:1 |# ~TH
3363 |S0 21:1 |# R |S1 32:1 |# ~AH
3363 |S0 23:1 |# T |S1 52:1 |# ~N
3363 |S0 11:1 |# H |S1 65:1 |# ~W
3363 |S0 8:1 |# E |S1 40:1 |# ~EH
3363 |S0 17:1 |# N |S1 57:1 |# ~R
3363 |S0 26:1 |# W |S1 1:1 |# </s>
3363 |S0 4:1 |# A
3363 |S0 21:1 |# R
3363 |S0 8:1 |# E
3363 |S0 1:1 |# </s>
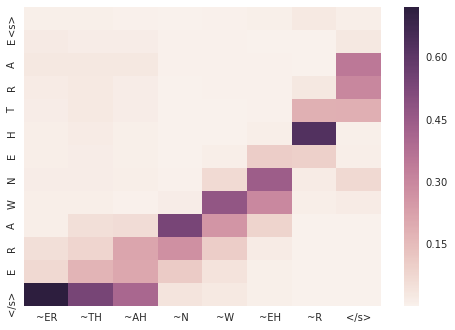
fair
> fair
= F EH R
3858 |S0 3:1 |# <s> |S1 3:1 |# <s>
3858 |S0 9:1 |# F |S1 43:1 |# ~F
3858 |S0 4:1 |# A |S1 40:1 |# ~EH
3858 |S0 12:1 |# I |S1 57:1 |# ~R
3858 |S0 21:1 |# R |S1 1:1 |# </s>
3858 |S0 1:1 |# </s>
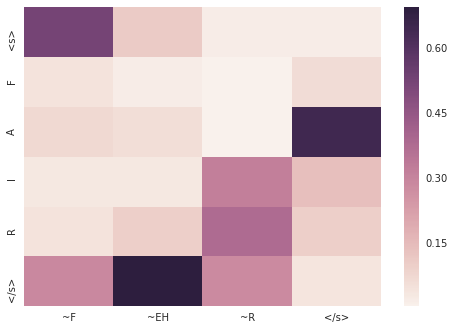
laundries
> laundries
= L AO N D R IY Z
6554 |S0 3:1 |# <s> |S1 3:1 |# <s>
6554 |S0 15:1 |# L |S1 50:1 |# ~L
6554 |S0 4:1 |# A |S1 33:1 |# ~AO
6554 |S0 24:1 |# U |S1 52:1 |# ~N
6554 |S0 17:1 |# N |S1 38:1 |# ~D
6554 |S0 7:1 |# D |S1 57:1 |# ~R
6554 |S0 21:1 |# R |S1 47:1 |# ~IY
6554 |S0 12:1 |# I |S1 67:1 |# ~Z
6554 |S0 8:1 |# E |S1 1:1 |# </s>
6554 |S0 22:1 |# S
6554 |S0 1:1 |# </s>
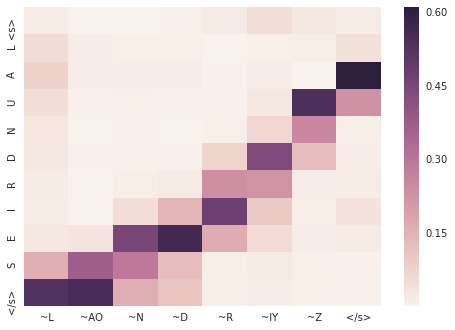
mismatch
> mismatch
= M IH S M AE CH
7610 |S0 3:1 |# <s> |S1 3:1 |# <s>
7610 |S0 16:1 |# M |S1 51:1 |# ~M
7610 |S0 12:1 |# I |S1 46:1 |# ~IH
7610 |S0 22:1 |# S |S1 58:1 |# ~S
7610 |S0 16:1 |# M |S1 51:1 |# ~M
7610 |S0 4:1 |# A |S1 31:1 |# ~AE
7610 |S0 23:1 |# T |S1 37:1 |# ~CH
7610 |S0 6:1 |# C |S1 1:1 |# </s>
7610 |S0 11:1 |# H
7610 |S0 1:1 |# </s>
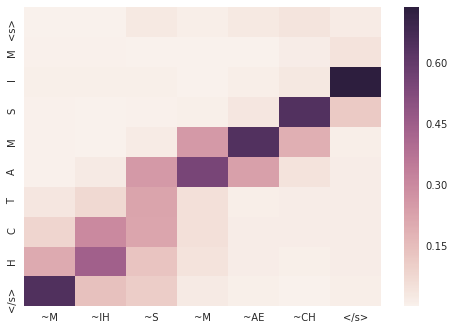
personnel
> personnel
= P ER S AH N AH L
8683 |S0 3:1 |# <s> |S1 3:1 |# <s>
8683 |S0 19:1 |# P |S1 56:1 |# ~P
8683 |S0 8:1 |# E |S1 41:1 |# ~ER
8683 |S0 21:1 |# R |S1 58:1 |# ~S
8683 |S0 22:1 |# S |S1 32:1 |# ~AH
8683 |S0 18:1 |# O |S1 52:1 |# ~N
8683 |S0 17:1 |# N |S1 40:1 |# ~EH
8683 |S0 17:1 |# N |S1 50:1 |# ~L
8683 |S0 8:1 |# E |S1 1:1 |# </s>
8683 |S0 15:1 |# L
8683 |S0 1:1 |# </s>
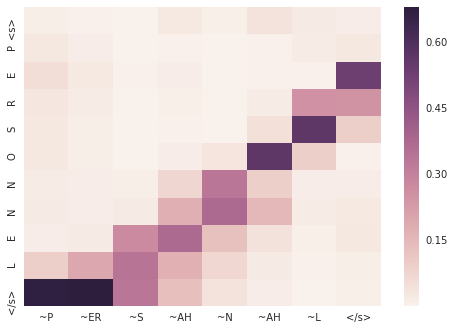
retaken
> retaken
= R IY T EY K AH N
9686 |S0 3:1 |# <s> |S1 3:1 |# <s>
9686 |S0 21:1 |# R |S1 57:1 |# ~R
9686 |S0 8:1 |# E |S1 47:1 |# ~IY
9686 |S0 23:1 |# T |S1 60:1 |# ~T
9686 |S0 4:1 |# A |S1 42:1 |# ~EY
9686 |S0 14:1 |# K |S1 49:1 |# ~K
9686 |S0 8:1 |# E |S1 32:1 |# ~AH
9686 |S0 17:1 |# N |S1 52:1 |# ~N
9686 |S0 1:1 |# </s> |S1 1:1 |# </s>
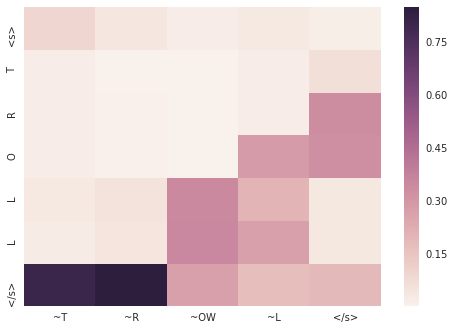
troll
> troll
= T R OW L
11799 |S0 3:1 |# <s> |S1 3:1 |# <s>
11799 |S0 23:1 |# T |S1 60:1 |# ~T
11799 |S0 21:1 |# R |S1 57:1 |# ~R
11799 |S0 18:1 |# O |S1 54:1 |# ~OW
11799 |S0 15:1 |# L |S1 50:1 |# ~L
11799 |S0 15:1 |# L |S1 1:1 |# </s>
11799 |S0 1:1 |# </s>
以上