いよいよ最後の章です。
ここでは、テストデータ(test.csv)に対して、3章で作成したもっとも精度の高いモデルを使って、実際に生存者を予測したいと思います。今回は Kaggleに挑戦ということですので、最後にKaggleに提出用のフォーマットに出力して、提出して結果を確認したいと思います。
その前にこれまでの流れをおさらいします。
1章:データ確認編:実際のデータを可視化して確認します。分析方針を決めるためにも重要なステップ
2章:処理編 :機械学習ができるように、データを整形します。もっとも手間がかかるが重要なパート
3章:学習編 :いくつかのアルゴリズムを利用して Train データを学習しモデルを作成します。
4章:実践編 :最もよかった学習器を Testデータに適用して、Kaggleに Submitします。
## テストデータの整形
モデルを適用する前に、訓練データ(train.csv)に施したように、テストデータ(test.csv)に対しても同じ処理をして上げる必要があります。まずはtest.csvをデータセットに取り込んで、同じように中身を確認してみます。
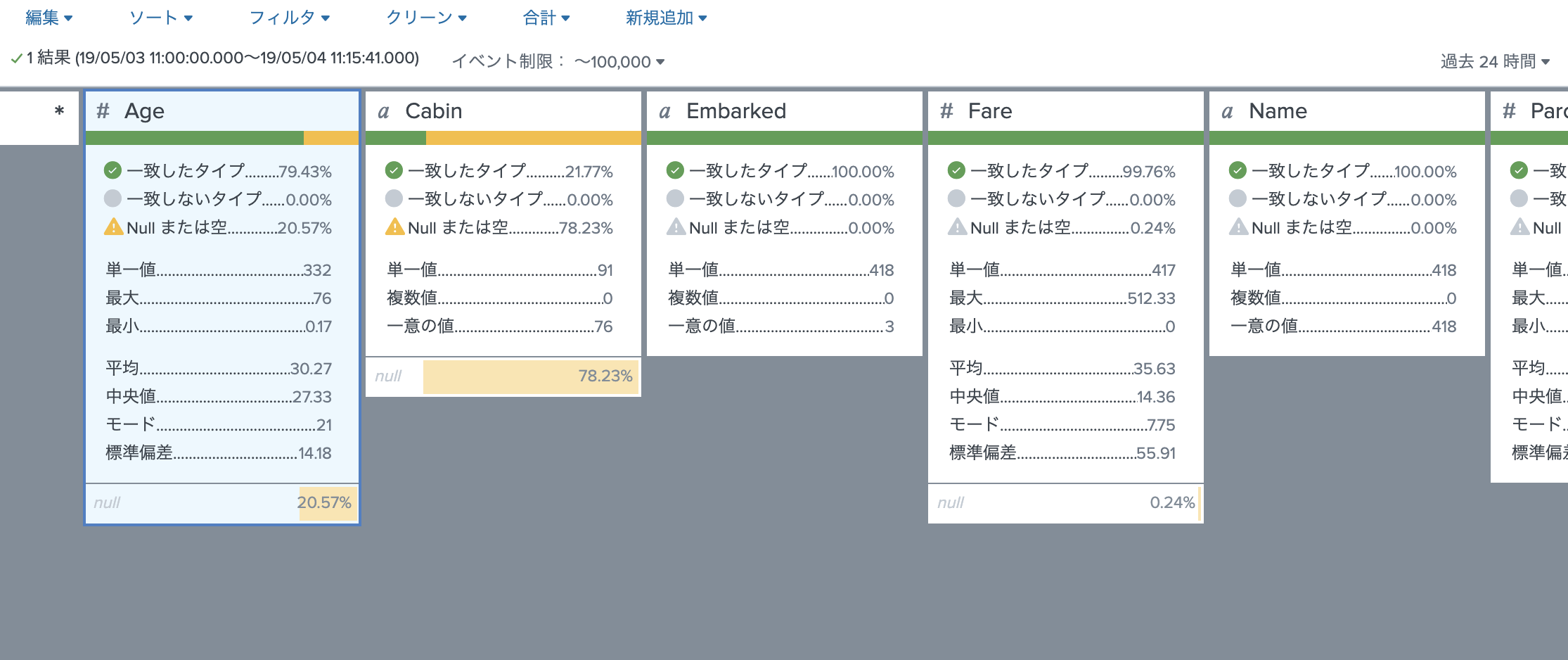
欠損データは、Age(20.5%), Cabin(78.2%)の2つです。これらは訓練データも同じだったので、同じように処理します。他は特に訓練データと大きな違いがないことを確認します。
それでは、2章の前処理を思い出して、どのような処理を施すか決めます。また3章で追加でPclassもOneHot Encodingしているので、そちらも同じように処理しておきます。
1)データ欠損処理
- AgeのNULLを名前のTitleを元に平均値で入力。(Miss/Masterには、9歳。他は27歳)
- Cabin列は、NULLかそれ以外で 0 or 1として新規のCabin-E 列を作成。
2) グループ化
- Age を5グループに分けた
- Fareを5グループに分けた
3) 数値への変換
- Sex列は、男を0、女を1に変換
- Name 列は、titleを抜き出し、OneHotEncodingする
- Embarked 列を OneHotEncodingによりカテゴリー変換
- Ticket列は、PCという文字列が入っていれば1、それ以外は0として新規列(Ticket-E)を作成。
- Pclass列は、OneHotEncodingする
4) 不要な列の削除
- Cabin / Name / Embarked / Title &(ti) / Ticket /Pclass を削除
上記の処理を実行した SPLはこちらです。最後に kaggle-test.csvとして lookupに保存してます。
| from inputlookup:"titanic-test.csv"
| fields "Age", "Cabin", "Embarked", "Fare", "Name", "Parch", "PassengerId", "Pclass", "Sex", "SibSp", "Ticket"
| eval "Age"=case(isnum(Age),Age, like(Name,"%Miss%"),9, like(Name,"%Master%"),9,true(),27)
| eval "Cabin-E"=if(isnull(Cabin),0,1)
| eval "AgeRange"=case(Age<10,0,Age<20,1,Age<40,2,Age<60,3,Age>=60,4)
| eval "FareRange"=case(Fare<5,0,Fare<10,1,Fare<20,2,Fare<40,3,Fare<100,4,Fare>=100,5)
| eval "Sex-Num"=if(Sex="male",0,1)
| rex field="Name" "\w+, (?P<ti>\w+)\."
| eval "Title"=case(ti="Mr","Mr",ti="Mrs","Mrs",ti="Miss","Miss",ti="Master","Master",true(),"Other")
| eval "Ticket-E"=if(like(Ticket,"%PC%"),1,0)
| fields - "Ticket" , "Sex" , "ti" , "Name" , "Cabin"
| eval "{Embarked}"=1 | fillnull
| eval "{Title}" = 1| fillnull
| eval {Pclass} = 1 | fillnull
| fields - Embarked, Title, Pclass
| outputlookup kaggle-test.csv
テストデータへのモデルの適用
それでは、3章でもっとも結果のよかったモデルを、このテストデータ(kaggle-test.csv)に対して実行してみましょう。
モデルの適用方法はこちらです。保存してあるモデルを選択して、Publishを押すと下記の画面が現れます。基本的はこのコマンドをコピーするだけです。
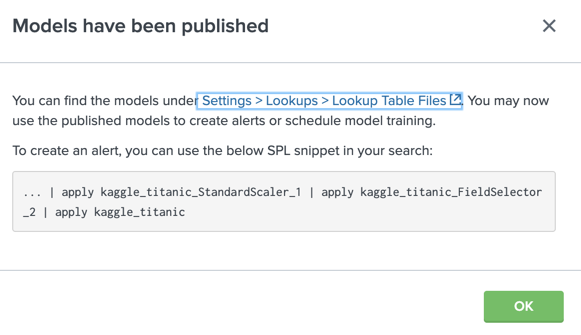
| inputlookup kaggle-test.csv
| apply kaggle_titanic_StandardScaler_1
| apply kaggle_titanic_FieldSelector_2
| apply kaggle_titanic
ついに、予測した Survivied フィールドが現れました。
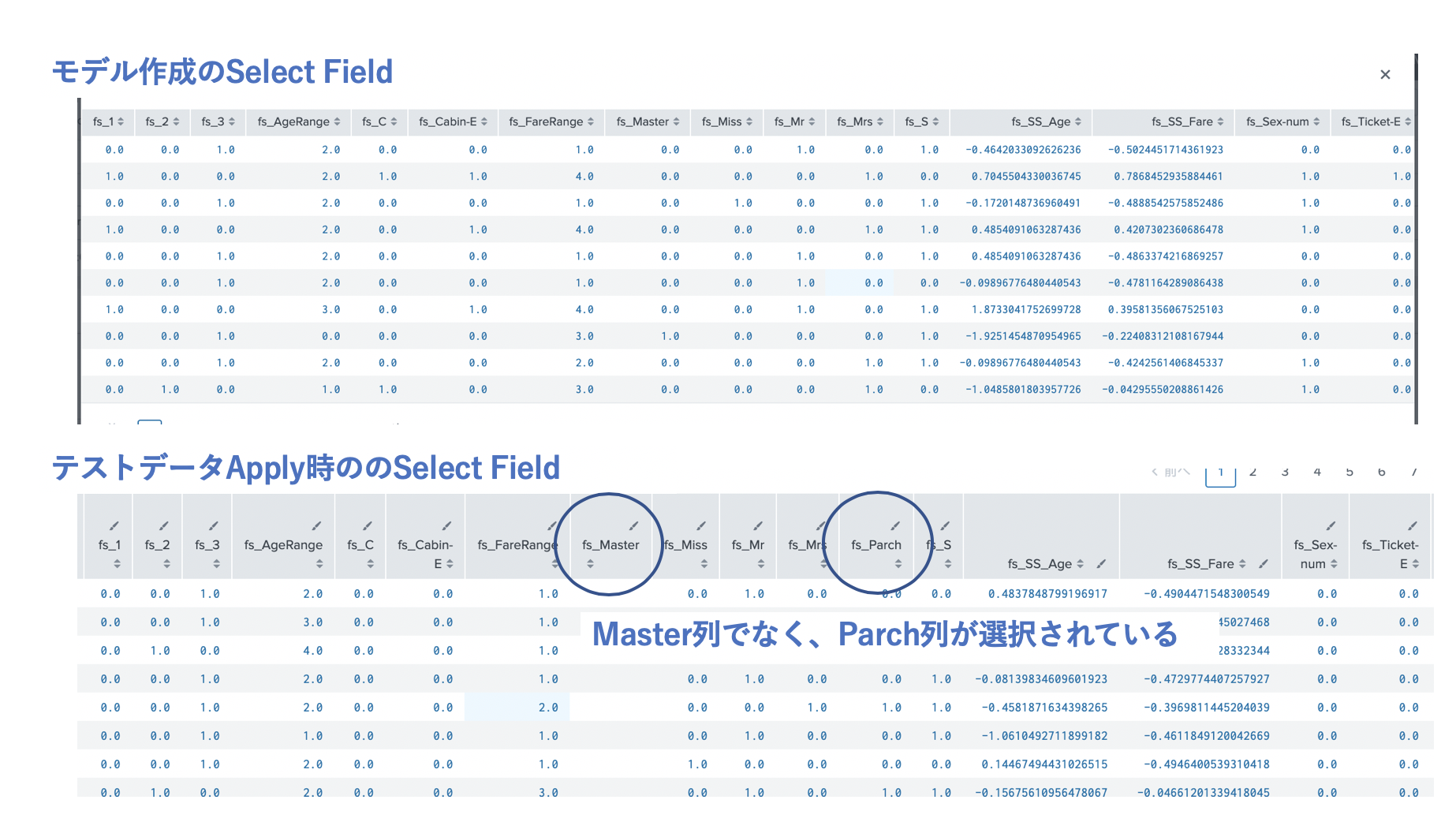
ただ、fs_Master の欄が空欄になってます(?)

どうやら、FieldSelectorで実行した結果が、訓練データと異なっているようです。元のモデルの選択されたField と比較してみると、Master列でなく、Parch列が選ばれているのがわかりました。
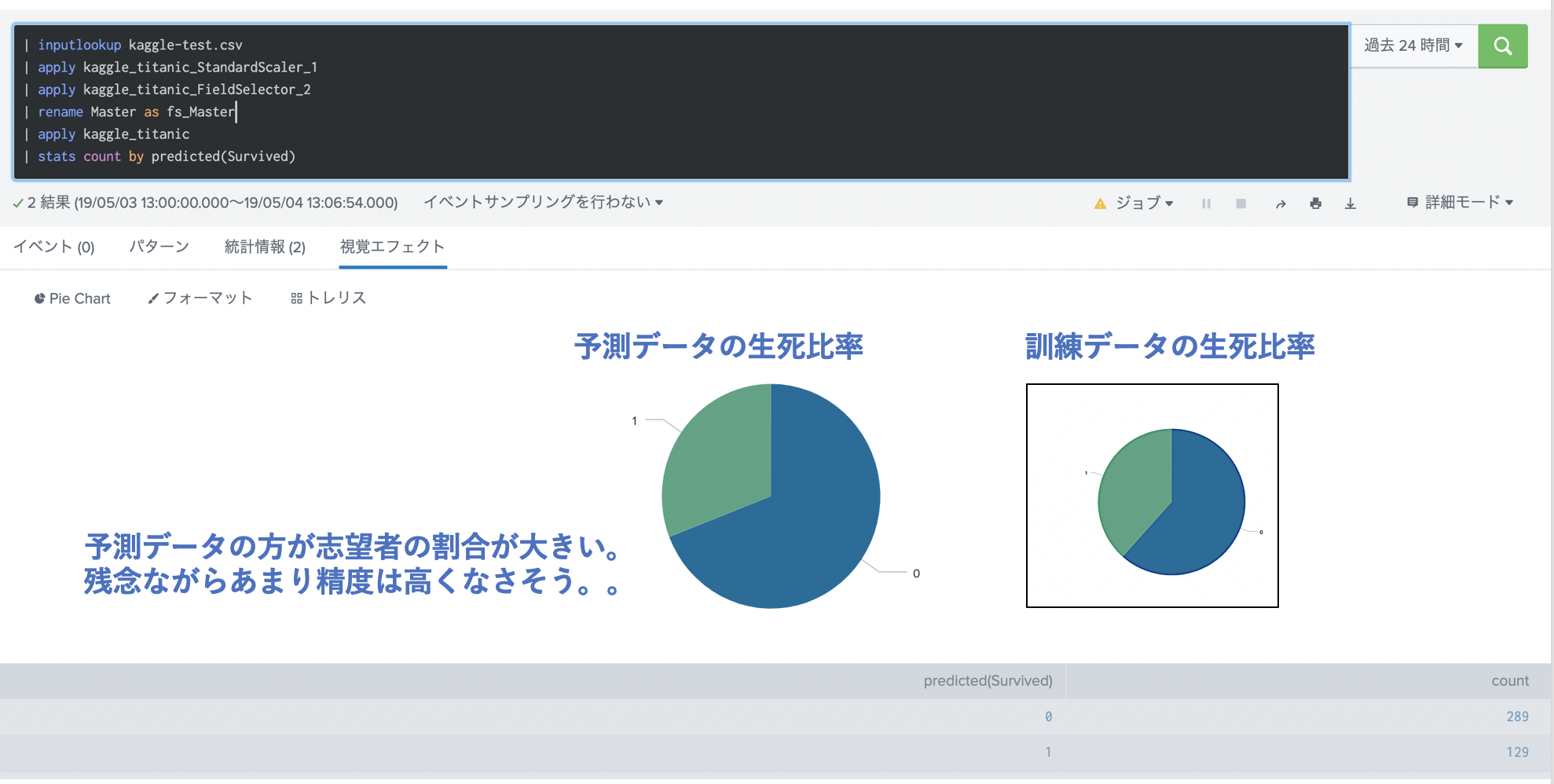
そのためMaster列を renameしてfs_Masterを用意して、再度適用します。適用後の生死割合を訓練データの生死比率と比較してみます。残念ながら比率はかなりずれているので、あまりいい結果は期待できませんが、今回はこのままKaggleに送信してみます。
KaggleにSubmitする
Kaggleの Submission Format をみると、下記のとおり "PassengerId" と "Survived" の2フィールドにして、csv形式で提出する必要があるみたいです。また提出フォーマットの gender_submission.csvもダウンロードできるとありますので、こちらをチェックして同じ内容で出力したいと思います。
| inputlookup kaggle-test.csv
| apply kaggle_titanic_StandardScaler_1
| apply kaggle_titanic_FieldSelector_2
| rename Master as fs_Master
| apply kaggle_titanic
| rename predicted(Survived) as Survived
| table PassengerId, Survived
| outputcsv gender_submission.csv
出力された csvは、$SPLUNK_HOME/var/run/splunk/csv に保存されてます。
このファイルを、kaggleに提出します。

スコアがでました。 77%....

このように全体の順位も出てきます。(あまりいい順位ではないですが)

最後に
予測結果に関しては平凡な結果に終わってしまいましたが、もう少しパラメータやアルゴリズムを変えたりすれば少しは上げることができるかなとは思います。これはどちらかというと Splunkの使い方というよりも、データ分析スキルの問題ですね。。
最後に、今回の目的だった Splunk を使ってみての感想をまとめたいと思います。
####1. データの確認や可視化に関しては、非常に簡単にできることがわかった。
もともとそういうツールなので当たり前ですが、ピポットを使ったグラフ化や、データセットを使ったデータの確認。また多少のサーチコマンドを知っていれば、簡単に分析・可視化できるので、そのあとの戦略をたてやすくなると思います。
####2. 前処理も pythonよりも楽かも
データセットのアプリを使いながら操作できるので便利です。ただ eval の使い方は知っておいた方がいいかと思います。ただデータセットアプリはSPLを使った処理(OneHotEncoding など)は対応していないので、最後はSPLによる処理が必要になります。SPLに慣れている人は pythonよりも楽だと思います。
####3. 学習については、メリット・デメリットも。
データの読み込みから、アルゴリズムの適用までGUIでできる点はよかったです。目で確認しながらいくつも試せるので失敗しにくいなと思いました。
一方、最近流行りのアルゴリズムなどがデフォルトだと用意されてないのと、GridSearchのようなパラメーターチューニングができないので、毎回マニュアルで操作が必要なのが面倒でした。こちらはもう少し慣れたらCLIを使った自動化、あるいはこの部分のみ pythonを使うなどの検討が必要かと感じました。
総括
全体として、Splunkでも十分にMLデータ分析ができる事がわかりました。pythonの matplotlibなども非常に強力な可視化ツールですが、使い方が個人的には難しいので、Splunkの方がその点は有利だと思います。特に私みたいにpythonのコードをちゃんと覚えてなく、いつもコピペで対応している人には、GUIを使って分析できるのは非常に助かります。
ただ、pythonでできるような柔軟なコマンドなどは不足しているので、その部分は csvに吐き出して pythonで行うか、Splunkに pythonコードを取り込んで実行するなどの、カスタマイズは必要かなとも思いました。
最後に、4章にわたり長々と書いてしまいましたが、最後まで読んでいただいてありがとうございました。もし少しでもお役にたてたら「いいね。」してくれると嬉しいです。