前回の前処理編に続き、今回はSplunk MLTKを使った学習編を書きたいと思います。やっと面白い機械学習に入ることができます。
その前に一旦、全体の流れのおさらいです。
1章:データ確認編:実際のデータを可視化して確認します。分析方針を決めるためにも重要なステップ
2章:処理編 :機械学習ができるように、データを整形します。もっとも手間がかかるが重要なパート
3章:学習編 :いくつかのアルゴリズムを利用して Train データを学習しモデルを作成します。
4章:実践編 :最もよかった学習器を Testデータに適用して、Kaggleに Submitします。
Splunk MLTK とは
MLTKでは、回帰・分類・クラスタリング分析などが可能です。Splunkには元々pythonが組み込まれており、appによってさらに sckit-learnのライブラリが追加されることで、python で実行するのと同じようなことが実行可能となります。利用できるアルゴリズムは、バージョンごとに更新されておりますが、日本語マニュアルに一覧がありましたので、まずはこちらを参考にするのがいいと思います。
https://docs.splunk.com/images/7/78/Splunk-MachineLearning-QuickRefGuide-web_JA.pdf
また、MLTKにないモデルも追加することができます。こちらの Appを追加する事で、有志により作られた追加のアルゴリズムを利用可能です。(サポート対象外)注意点としては全てSPLによるコマンド実行になります。
Splunk MLTK Algorithms on GitHub
https://splunkbase.splunk.com/app/4403/
追加されるアルゴリズムはこちらで確認できます。
https://github.com/splunk/mltk-algo-contrib/tree/master/src/bin/algos_contrib
例えば、AdaBoostや、ExtraTreesClassifier。また CorrelationMatrixによる相関分析なども利用できます。
この他、自分で pythonコードを書いて、アルゴリズムをSplunkに追加することも可能です。(スキルのある人は是非挑戦してください)
ここでは、各アルゴリズムの詳細については解説しません。(というか知らないのも結構あるので出来ないというのが正解。。)
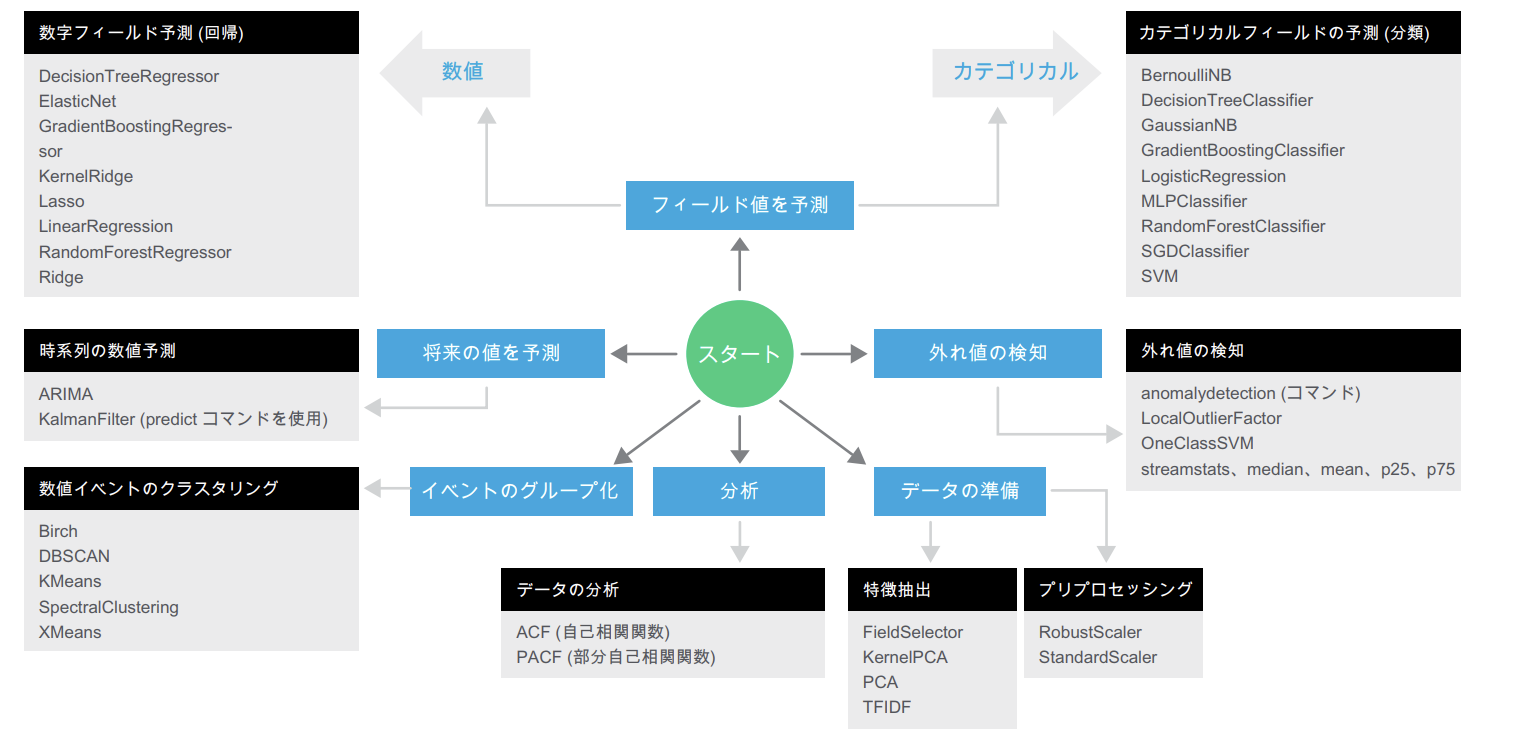
今回は生死の2択を予測するので、分類といわれる「カテゴリカルフィールドの予測」になります。パラメーターチューニングもあるので、対象のアルゴリズムについては簡単に調べておいた方がいいと思います。(もちろんデフォルトパラメータでもある程度の精度は出せますが)
学習開始
学習フェーズの大まかな流れはこちらです。
- 目的を決める(今回はカテゴリカルフィールドの予測)
- データを読み込む(2章で前処理が終わったデータ)
- MLTKにある前処理を実行するか検討する(標準化やフィールドセレクトなどが利用できる)
- モデルを選択して、学習開始
- パラメーターを変更して評価値の一番いいモデル・パラメーターを保存する
- 3-5 を繰り返し、一番いい結果のモデルを保存する
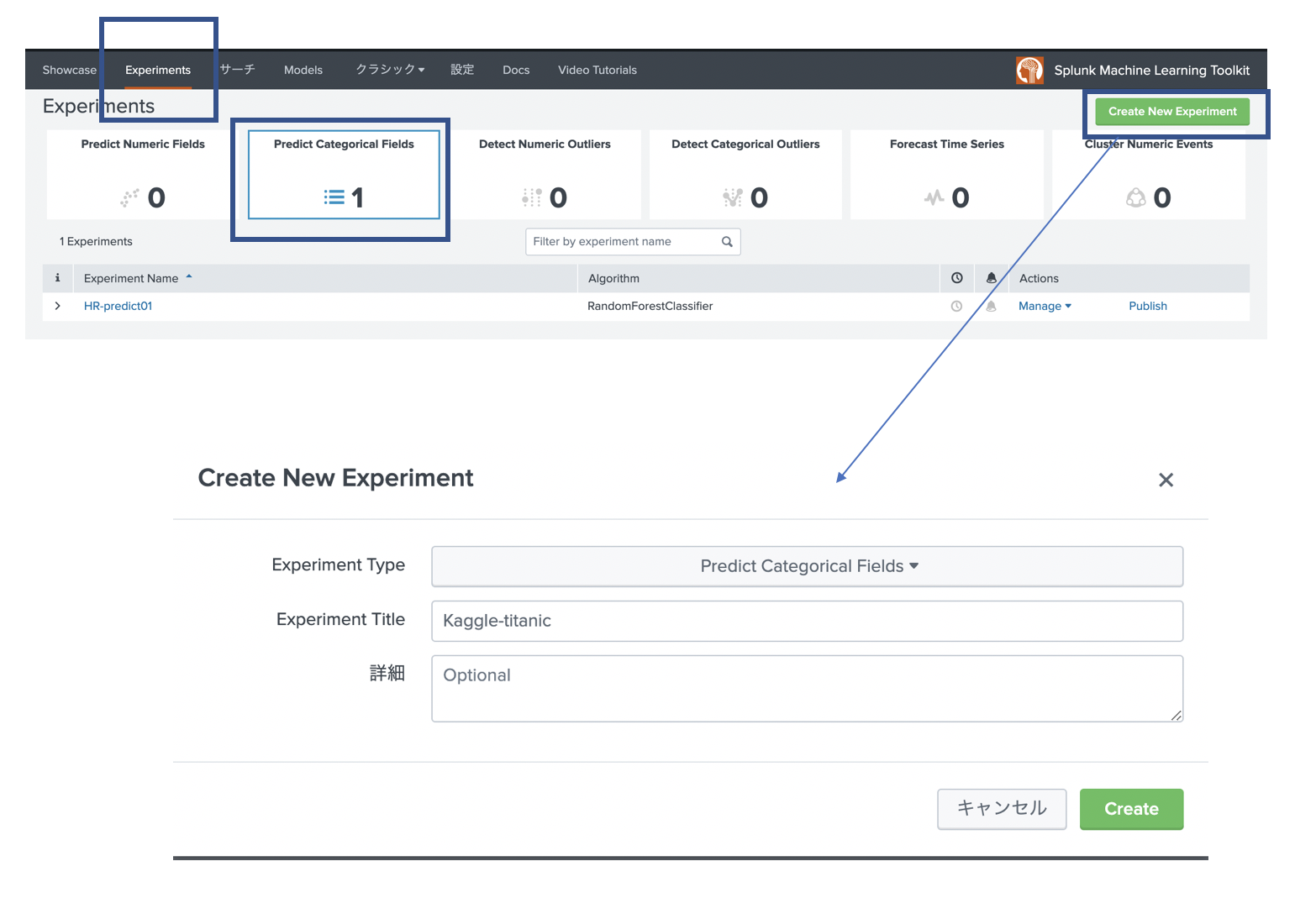
1. 目的を決める
MLTK を開いて、「Experiments」タブを選択します。今回は「カテゴリカルフィールドの予測」を選択し、「Create New Experiment」を押して新規作成します。これによって、必要なアルゴリズムが用意された状態で利用できますし、モデルを保存しておくことができます。
2. データを読み込む
今回は、2章で最後に保存した kaggle-train.csv を利用します。

3. MLTKにある前処理を実行するか検討する
MLTKに用意されている前処理はこちらです。
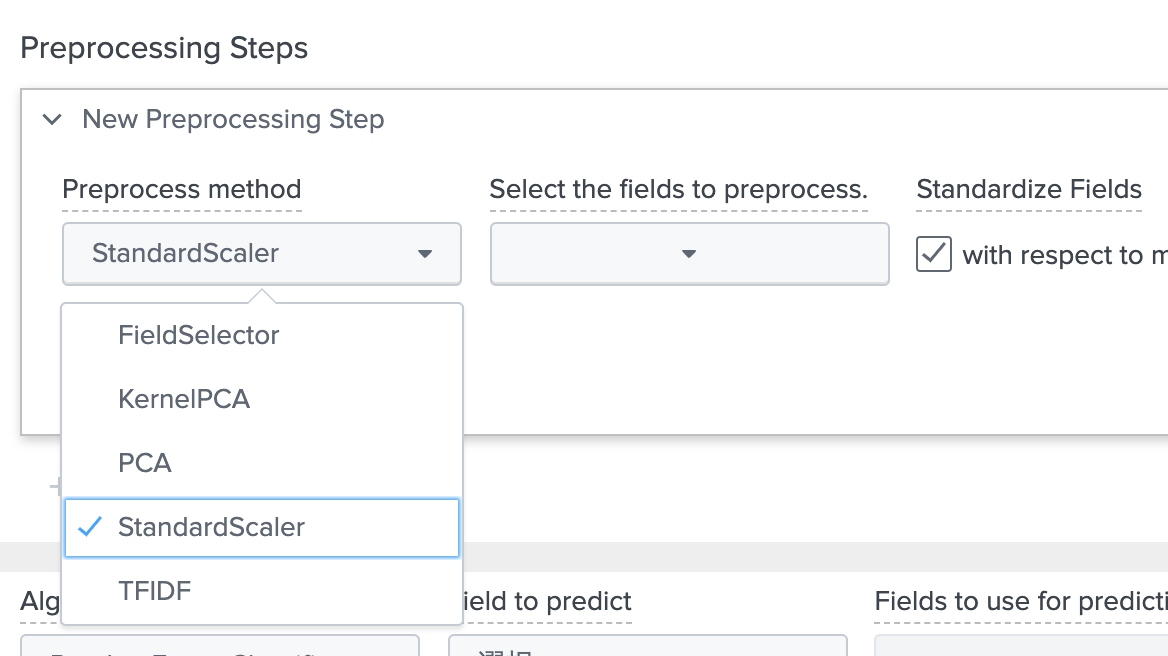
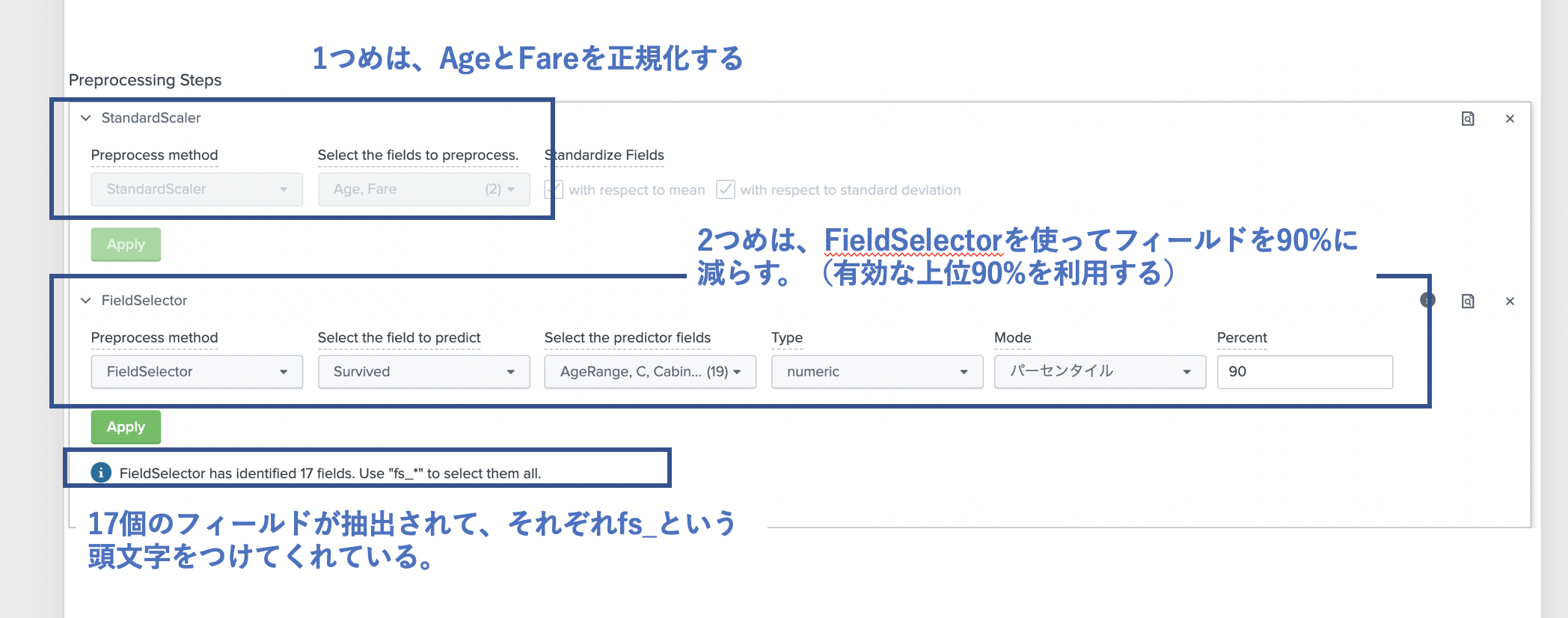
StandardScaler は、フィールド内のデータを正規化してくれます。これによりデータの大きさ・単位がバラバラでも同じスケールで分析できます。今回は、Ageと Fareに対して実行してみたいと思います。(すでにこの2つはグループ化してますが、特徴抽出でどれを利用するか決める事にします。)
残りの4つは特徴抽出とよばれるもので、基本的にはどれも目的は同じで、重要なフィールドを選択してくれます。選択するためのアルゴリズムがそれぞれ違う感じです。私も詳しくはわからないのですが、PCAなどは次元削減などで利用され、指定した数まで減らすことができますが、特徴量をみてもどのフィールドが有効だったかわかりづらくなります。FieldSelectorはその名の通りですが、有効なフィールドがそのまま残りますので、後から分析しやすいです。TFIDFは文章の重要な単語などを選択するときによく使われますが、それを特徴量抽出に利用しているのだと思います。重要な文字列を抽出して、それをOneHotEncoding とかするのかな。(正直、どう使っていいかわかってません)
特徴抽出は特徴量が多すぎるときなどに利用することで精度があがります。今回はFieldSelector を使ってみました。
4. モデルを選択して、学習開始
あとは、アルゴリズムを選んで、先ほど抽出したフィールドを用いて学習させていく。またパラメーターなどを変更しながら精度をあげていく作業です。
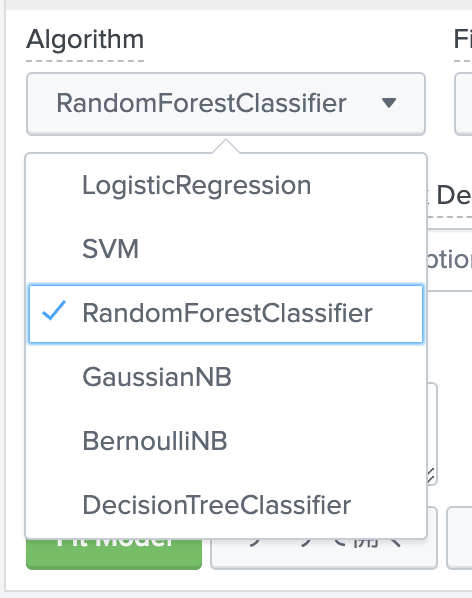
デフォルトで用意されている分類用のアルゴリズムはこちらです。
下の画面のとおり、アルゴリズムを決めたら、予測フィールドと利用するフィールドを選択して、train_test_split の割合を調整し、パラメーターを必要に応じて入力します。(空欄の場合はデフォルト値)
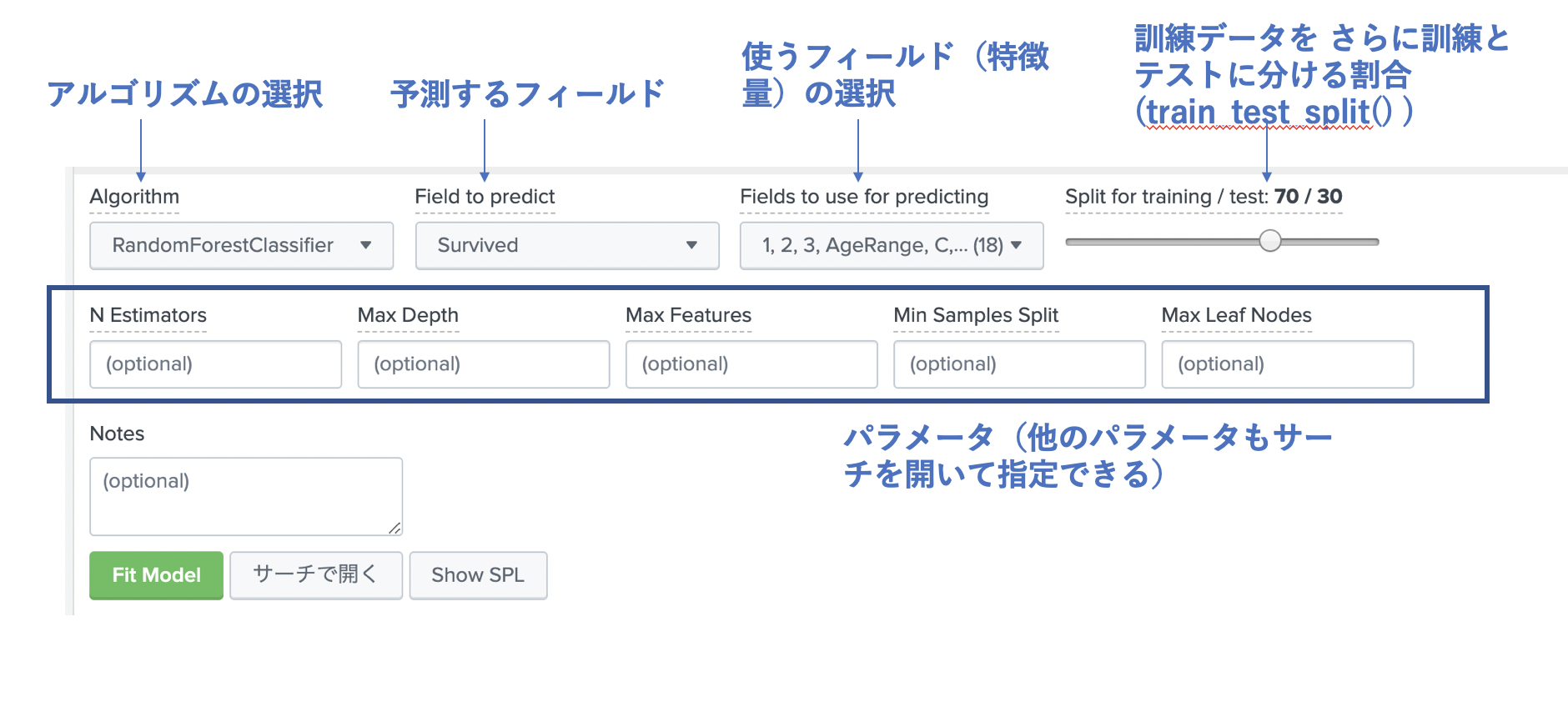
残念ながら Pythonにあるような GridSearch的なものが用意されていないため、マニュアルでそれぞれパラメーターを変更しながら精度をあげていく。(SPLコマンドもあるので、プログラムを作ればできると思うが、MLTKとしては用意されていない)
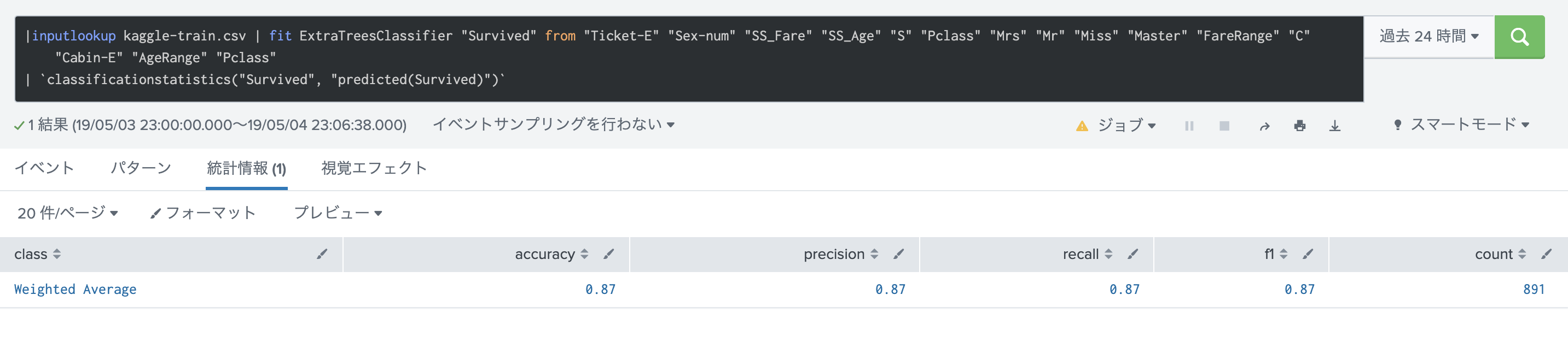
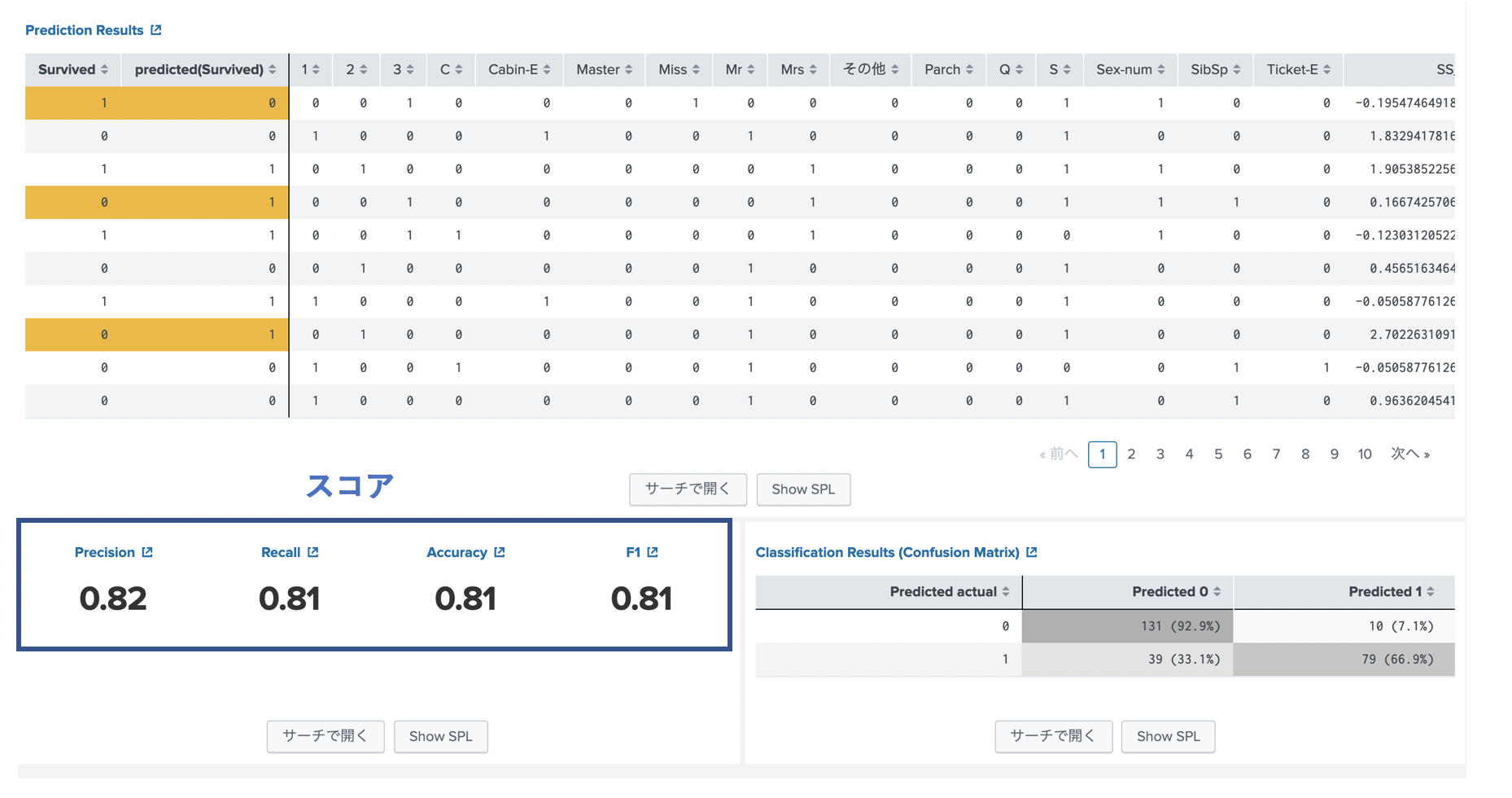
実行すると、下記のように結果が表示されます。このスコアを上げるようにアルゴリズムを変えたり、前処理を変えたり、パラメータを調整したりします。
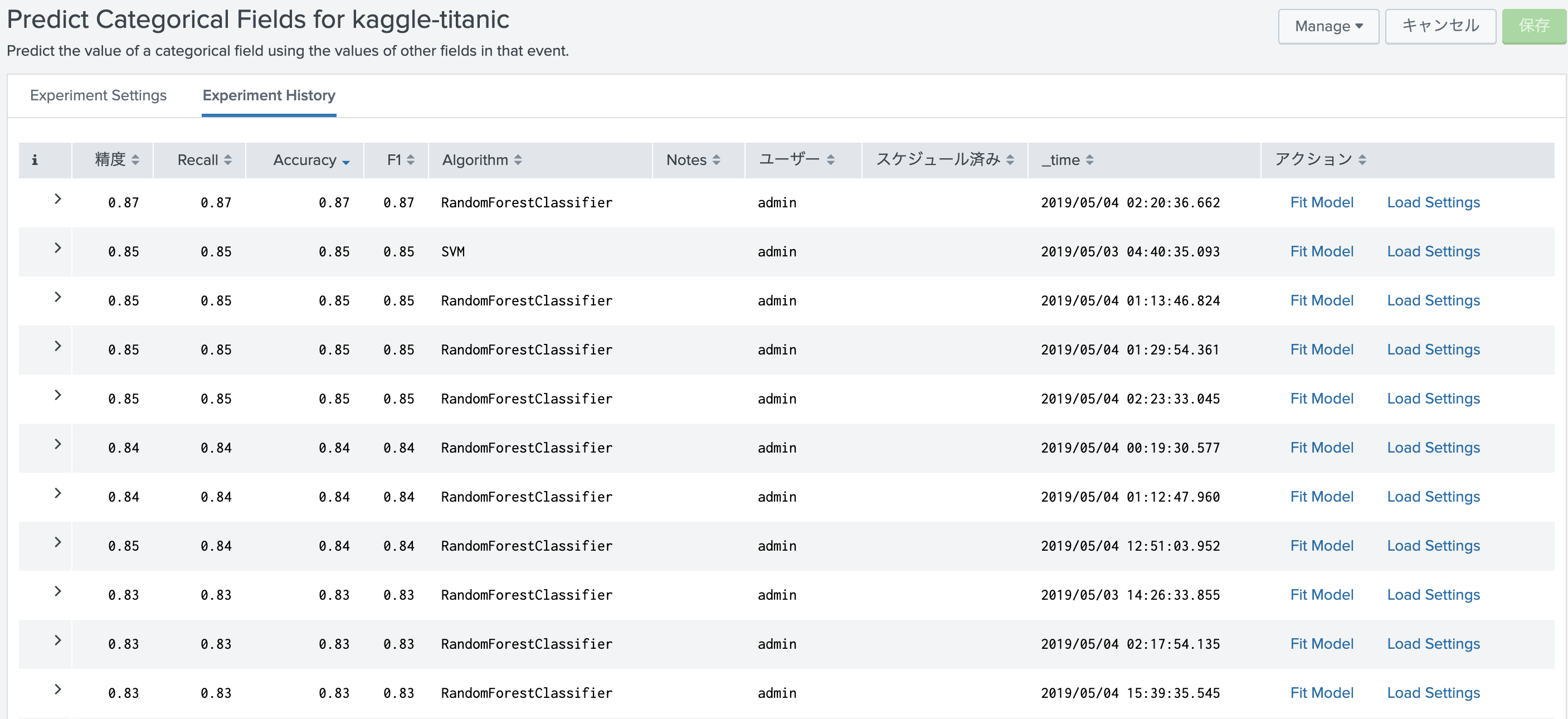
評価・保存
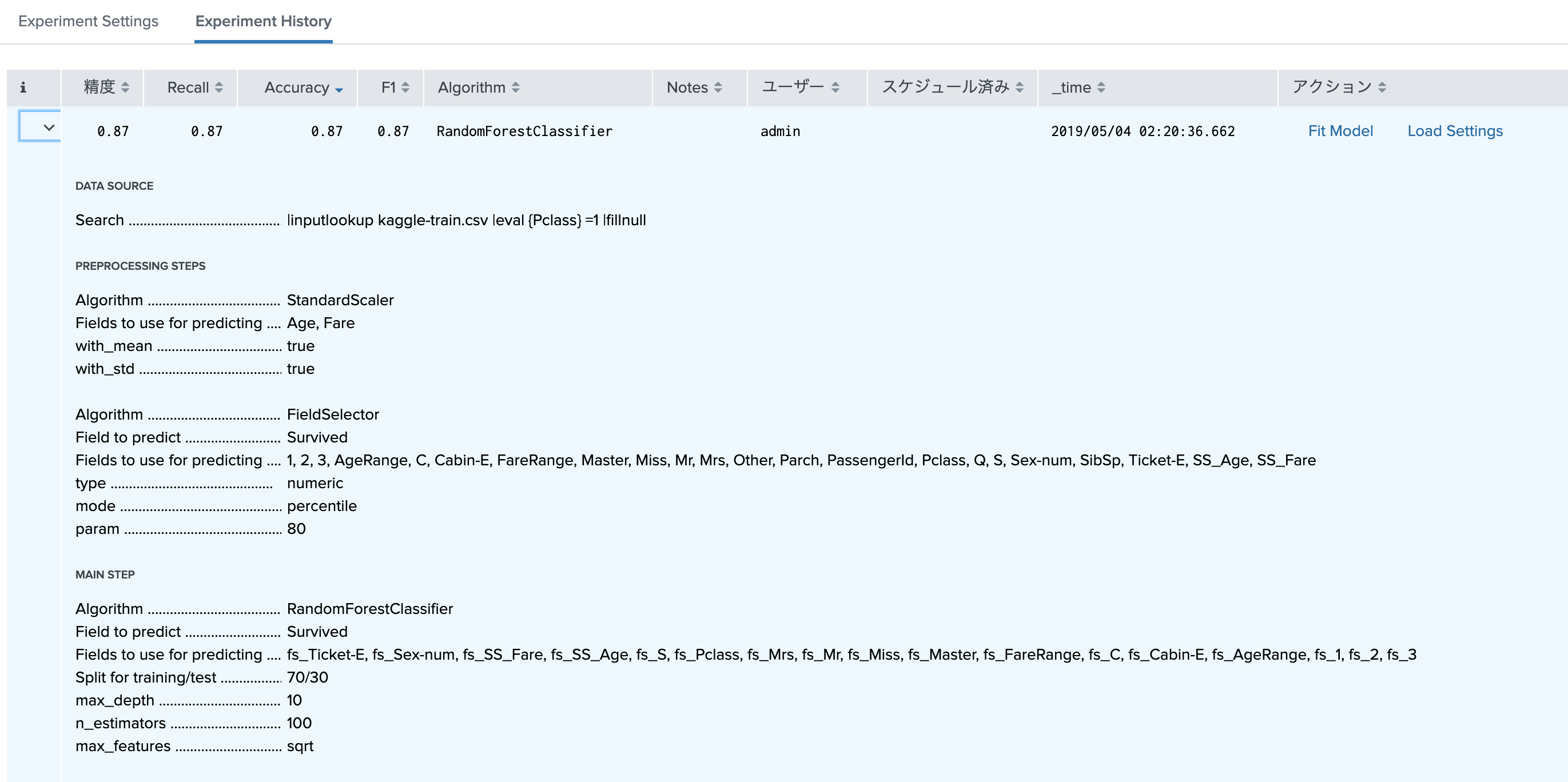
実行した結果については、History タブで、過去の結果一覧が確認できます。一番結果のよかったモデルを開くとさらに詳細なパラメータや利用したフィールドなどが確認できます。
このモデルを保存し、実際に使えるように Publishする必要があります。
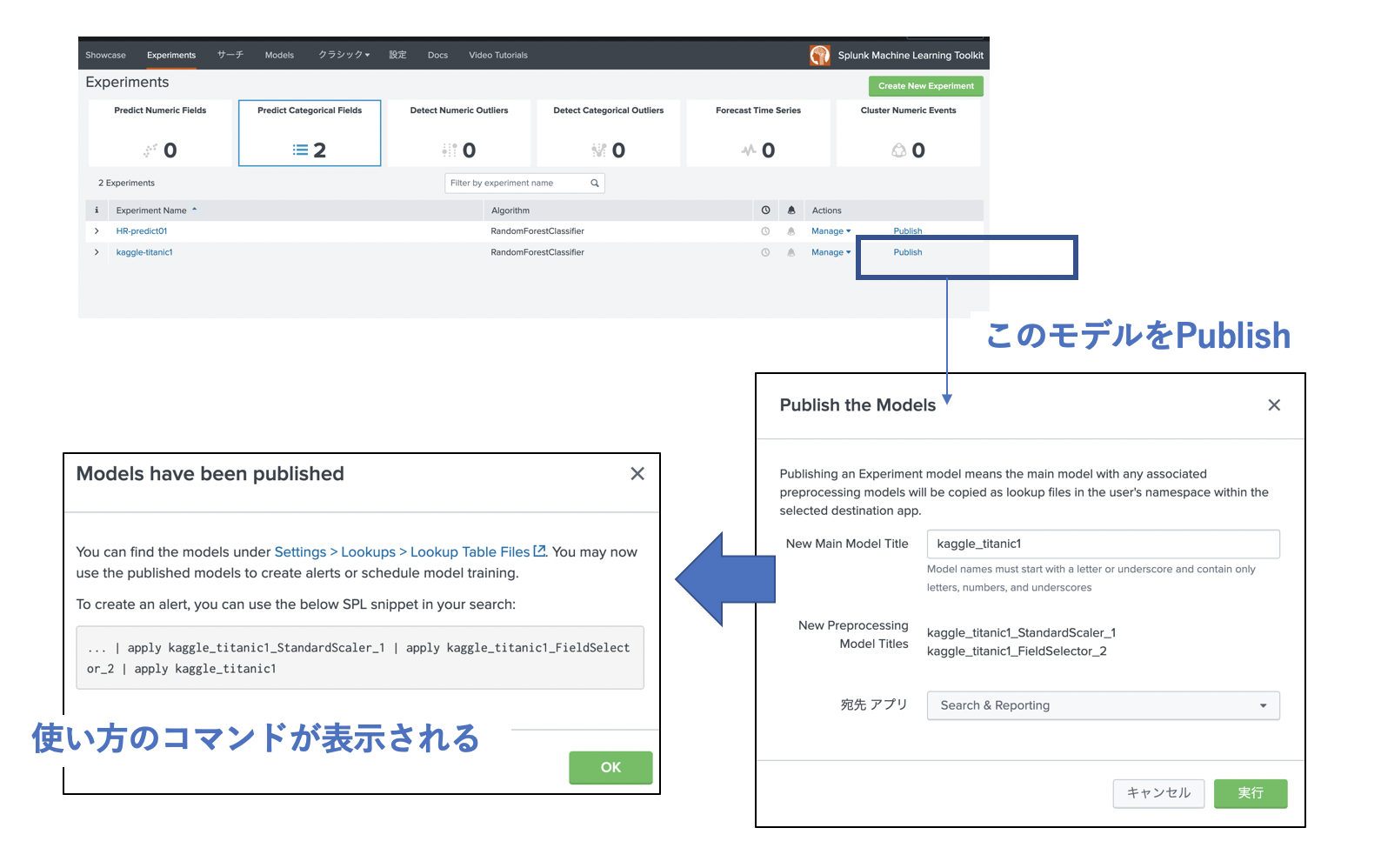
これで、テストデータに対して、このモデルを適用することができます。
おまけ(Splunk MLTK Algorithms on GitHub)
このページの最初の方でも解説しましたが、デフォルトのMLTKにないアルゴリズムも追加でき、最近GitHubにアップされているアルゴリズムを取り込むアプリがあります。(もちろん、GitHubから直接コピーしてもOKです)
今回、いくつか試してみたので書いておきます。
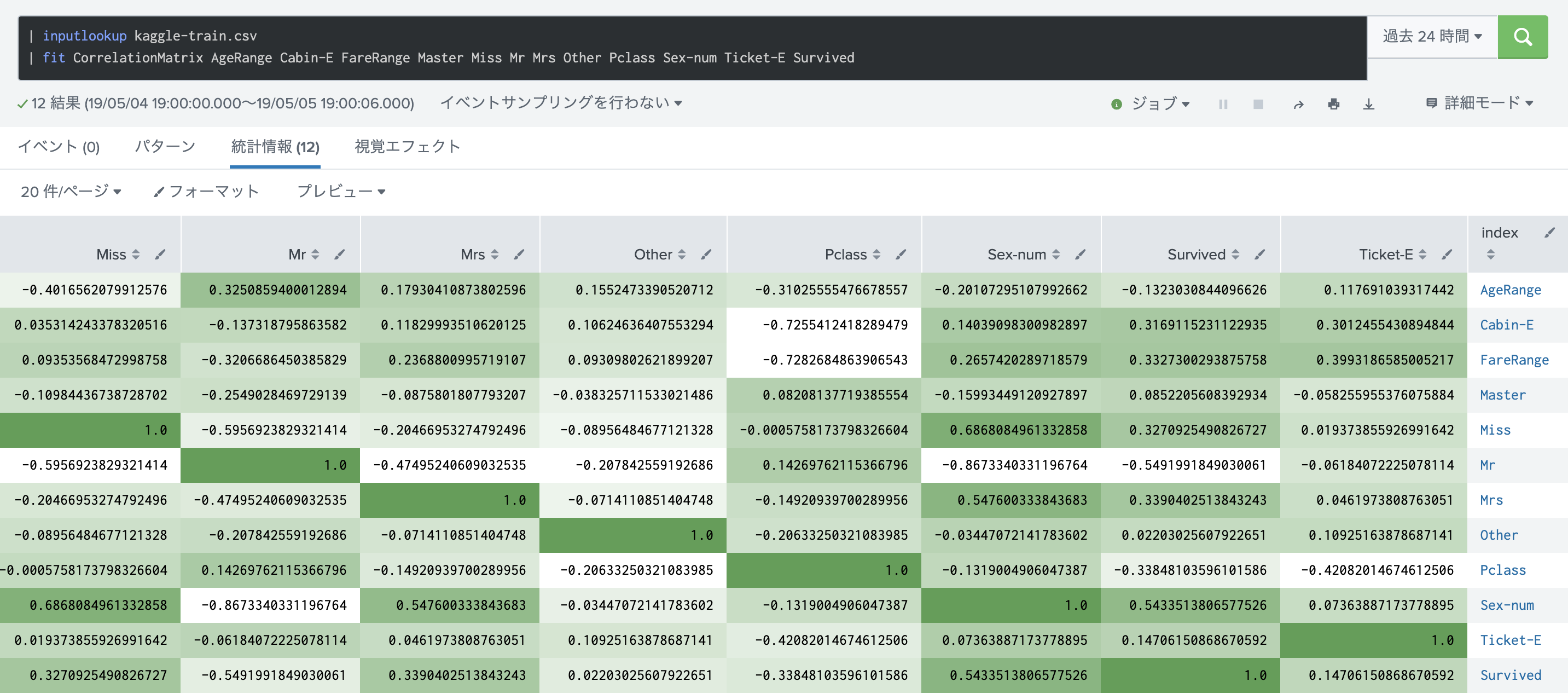
- CorrelationMatrix
各特徴量同士の相関をチェックするのに使います。通常最初のデータ確認時に試したりします。
- ExtraTreesClassifier
分類で利用されるアルゴリズムで、ツリー系の拡張アルゴリズムです。実際に試してみました。結構いいスコアがでました。