第2章では、前回の1章 で確認した情報を元に、データを整形していきます。
機械学習をする際に、もっとも時間がかかり面倒なステップになりますが、Splunkでどこまでできるか見ていきたいと思います。
その前に一旦、全体の流れのおさらいです。
1章:データ確認編:実際のデータを可視化して確認します。分析方針を決めるためにも重要なステップ
2章:処理編 :機械学習ができるように、データを整形します。もっとも手間がかかるが重要なパート
3章:学習編 :いくつかのアルゴリズムを利用して Train データを学習しモデルを作成します。
4章:実践編 :最もよかった学習器を Testデータに適用して、Kaggleに Submitします。
それでは、始めていきましょう。
データ整形(前処理)
通常データ解析をするためには、下記の前提条件が必要になるかと思います。
- データ欠損がないこと
- 必要に応じて数値がグループ化されていること
- 全て数値で表されている事
- 余計なデータが取り除かれている事
今回はこれに沿ってデータを整形していきたいと思います。
1. データ欠損がないこと
データ欠損があるデータは、1章で確認した通り Age(19.8%) / Cabin(77.1%) / Embarked(0.22%) です。
まずAgeですが、約20% が欠損されてます。20%はかなり多いのでNULLを削除するわけにはいきません。また1章で10才以下の子供は生存率が高いことがわかってます。なんとか子供か大人かを区別できれば、NULLにそれぞれの平均年齢を当てはめられそうです。
そこで、今回は名前に注目しました。名前には Mr. Miss. Mrs などのtitleがありますが、子供には Miss または Masterをつけるようです。https://kiwi-english.net/22784
そこで、一旦名前の title を抽出して数をカウントしてみたいと思います。
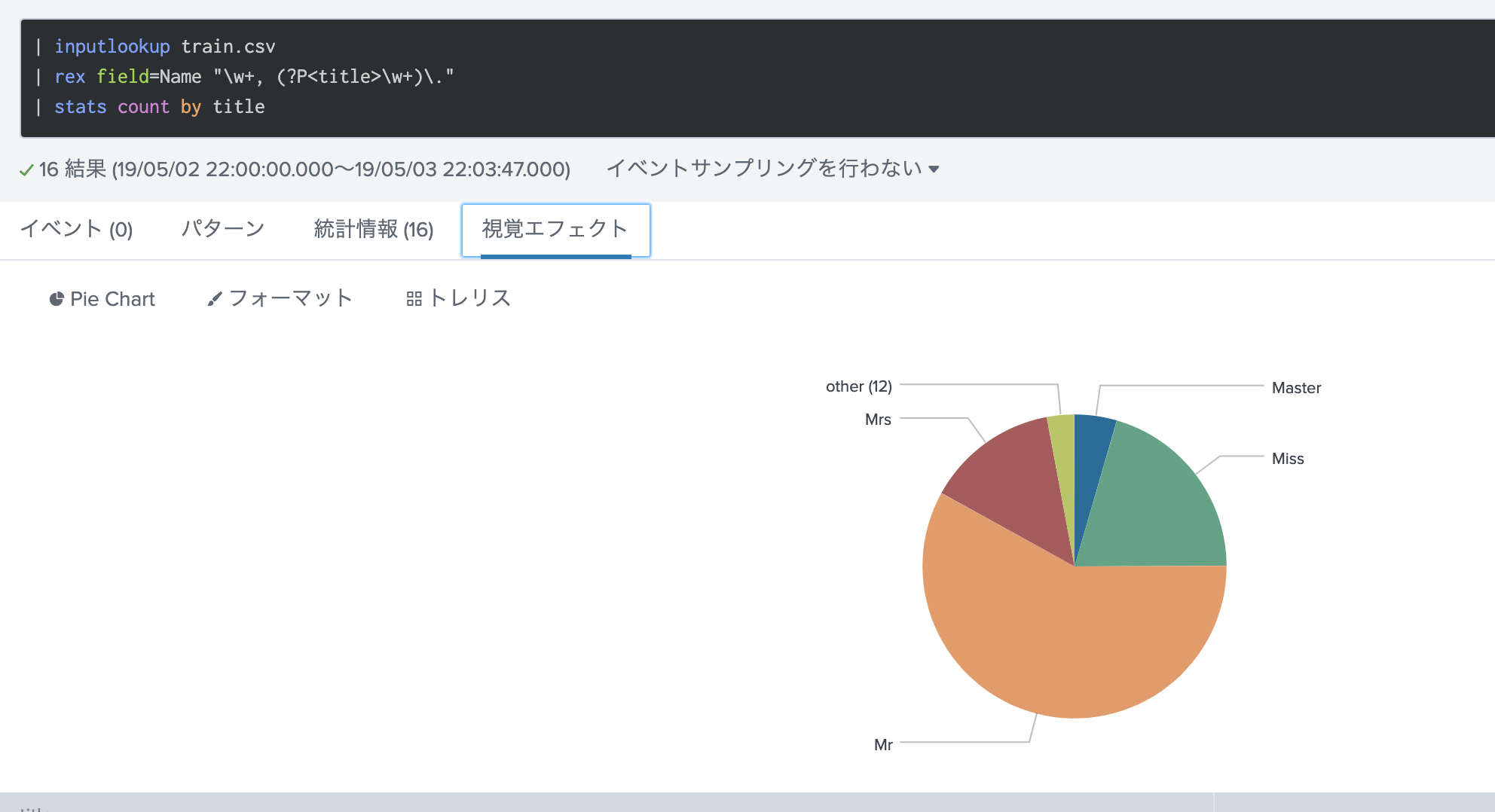
Other は見てみると、DrやSir などがありましたが、全体からみると少数なので大人としてカウントしておきます。MissとMasterはそこそこあるので、この敬称の場合は、20才以下の平均年齢を入力し、それ以外は全体の平均年齢を入力します。全体の平均年齢はデータセットから29.7才と出ているので、こちらを利用します。子供の平均年齢は18才以下の人を対象に平均値を出します。9.04才です。
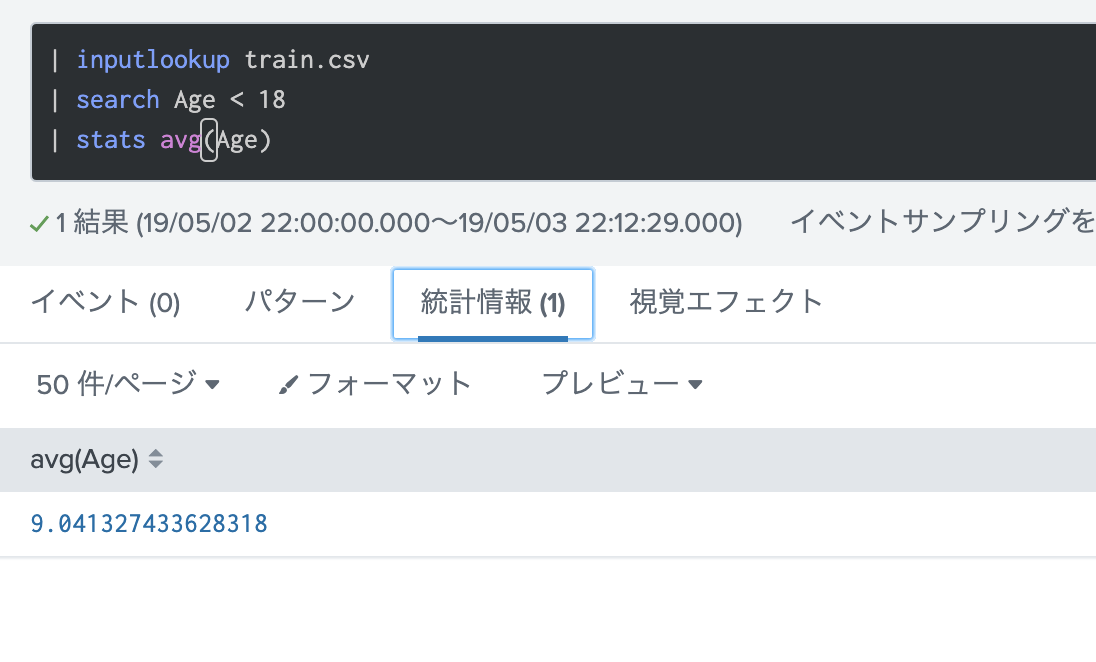
それでは、Age のNULL値を上記の条件で埋めていきます。
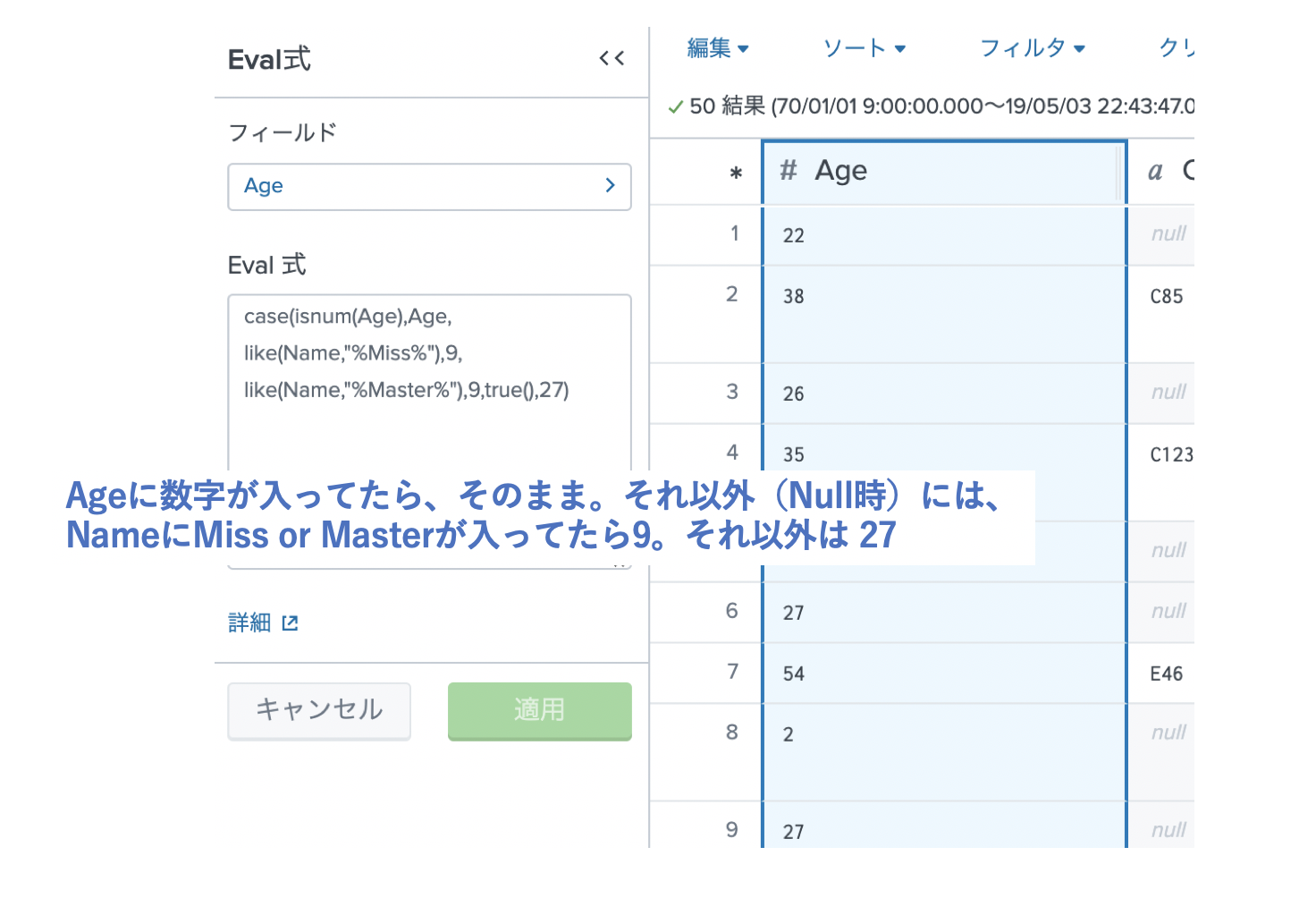
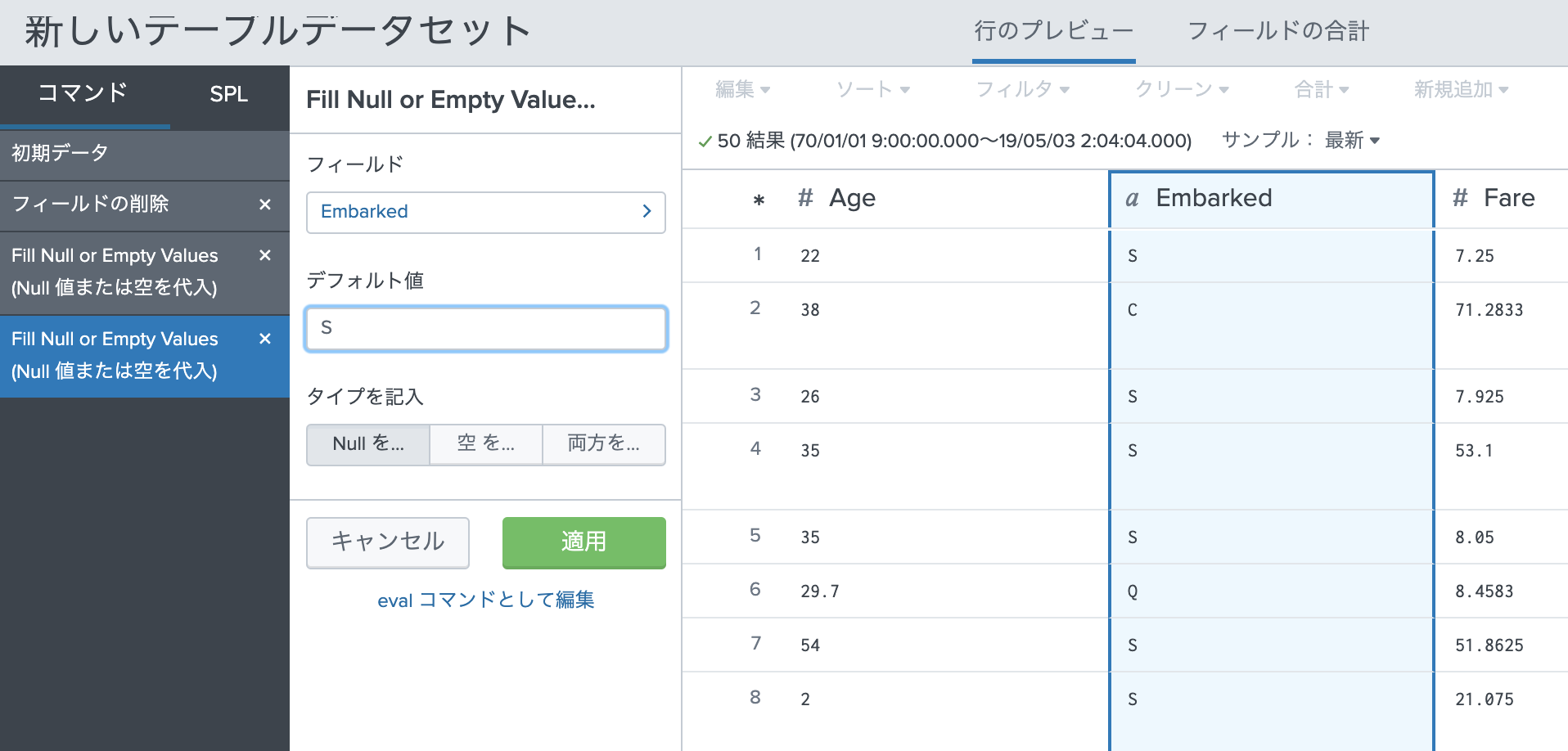
Embarked(乗船した港)のNULL率は、0.22%なので、それほど影響は出ないため、Nullの箇所を最も乗客数が多いS港で埋めたいと思います。(1章で確認済み)
最後に Cabin(部屋番号)ですが、一見生存に関係なさそうですが、データある乗客の生存数をみてみます。すると、下のようにCabinデータがあるユーザーは生存率が7割となっており、データの有る無しがかなり影響しそうです。
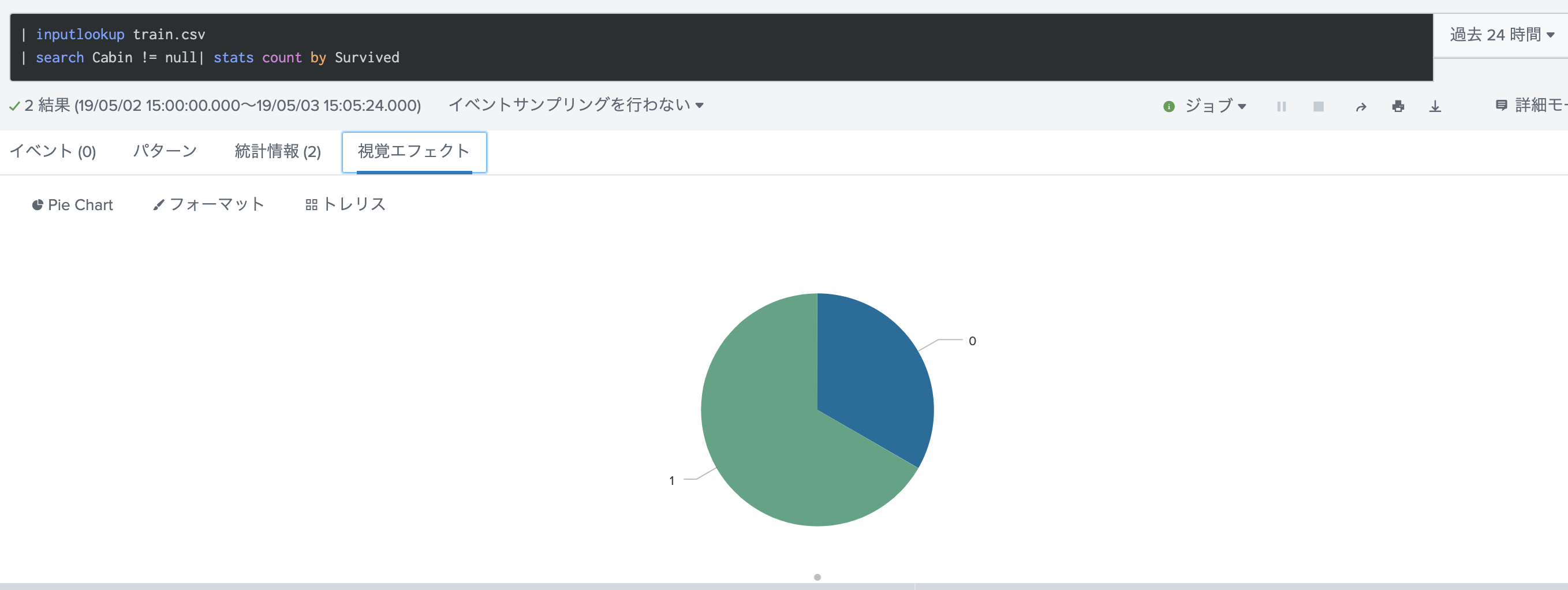
ここは新しくCabinデータがあるかどうかのフィールド(Cabin-E)を新しく作りましょう。
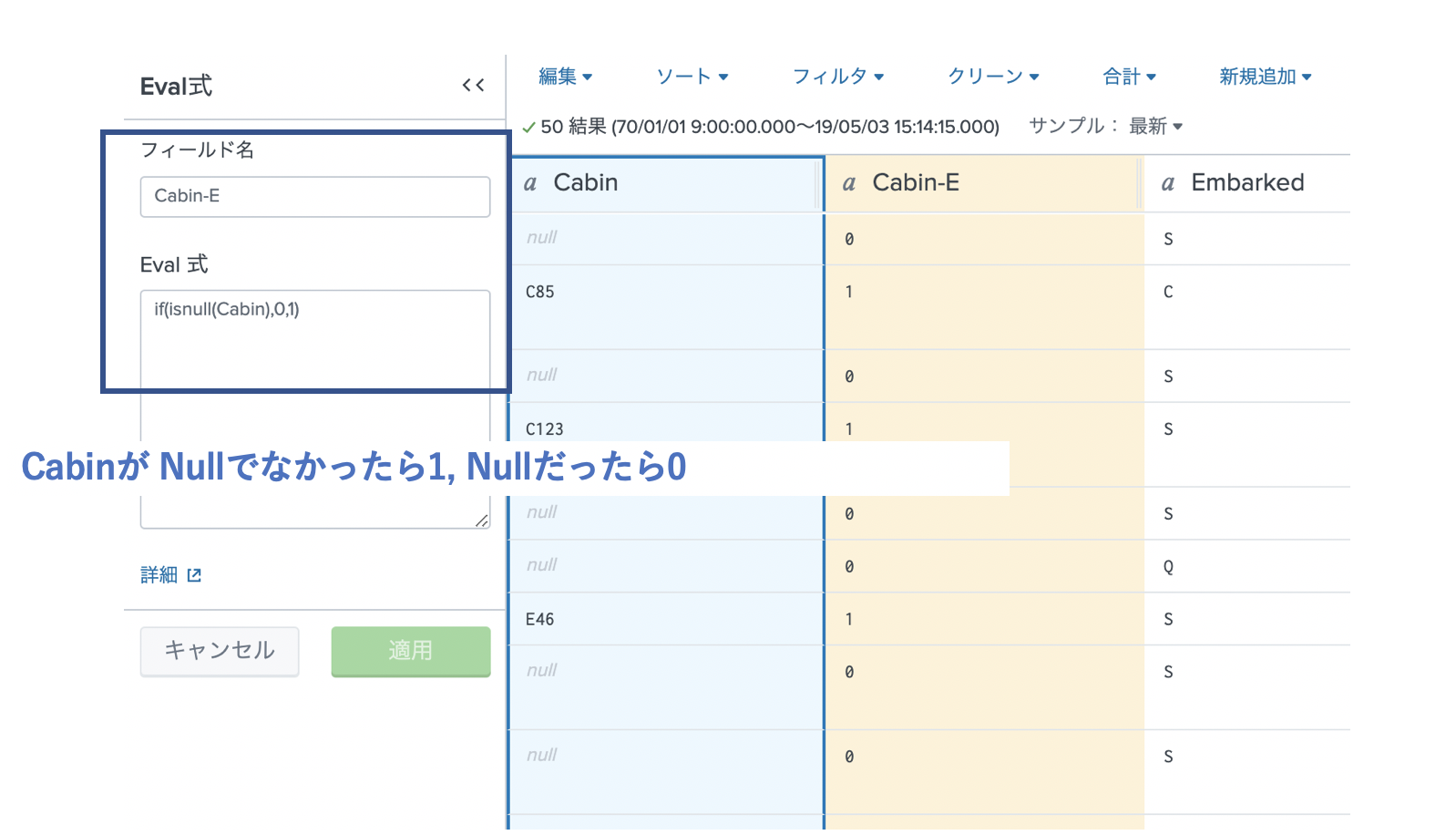
これで、NULLデータがあるフィールドはなくなりました。
2. 必要に応じて数値がグループ化されていること
データ数が891件とそれほど多くないため、念の為年齢と運賃に関してはグループわけしておきます。学習時に使うかどうかを試しながら検討します。
1章の結果を参考に、なるべく数が均等になるようにグループ分けしておきます。
・ Age ( 10才未満、 10 - 20 , 20-40, 40-60, 60以上)
・ Fare (5未満、5-10,10-20,20-40,40-100,100以上)
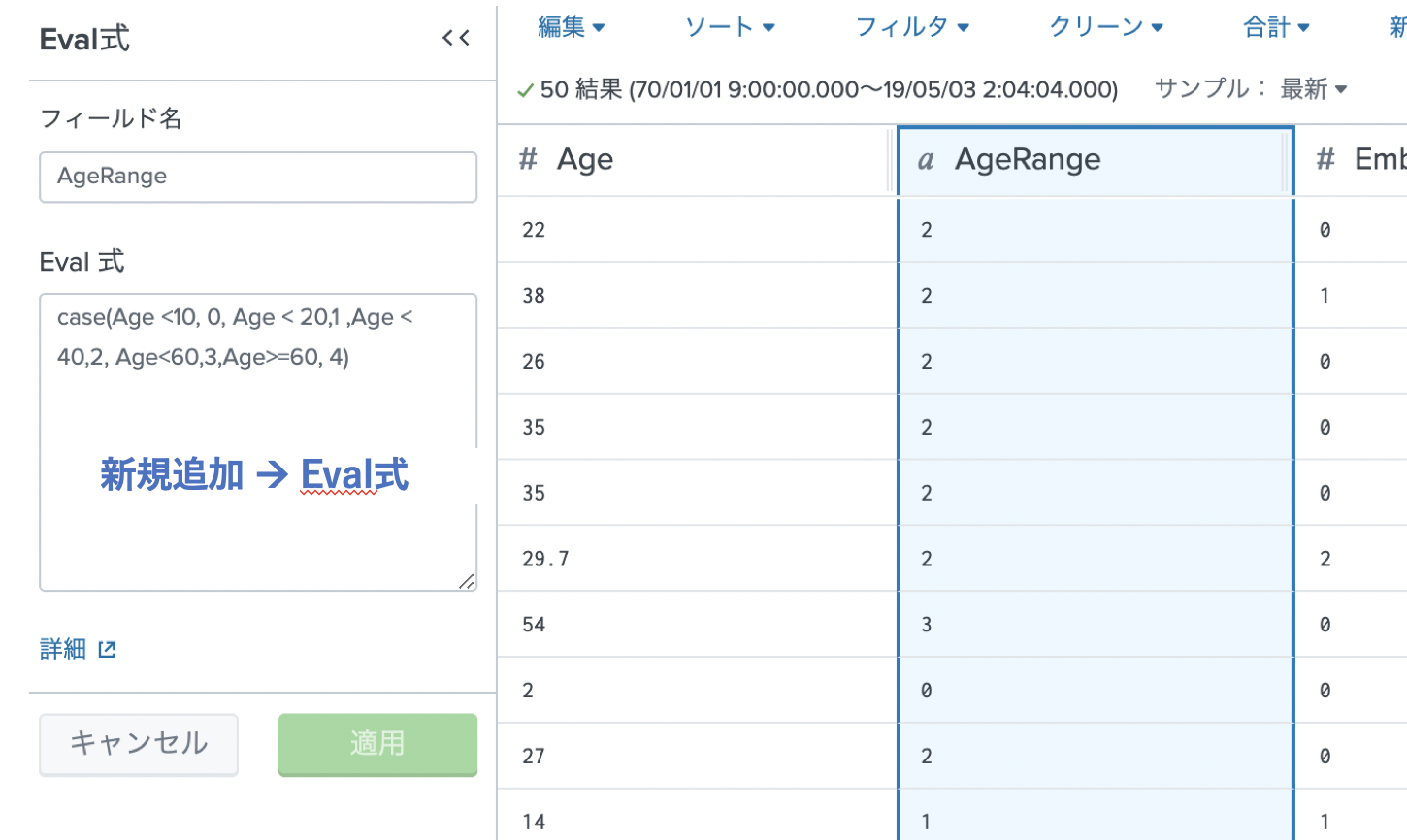
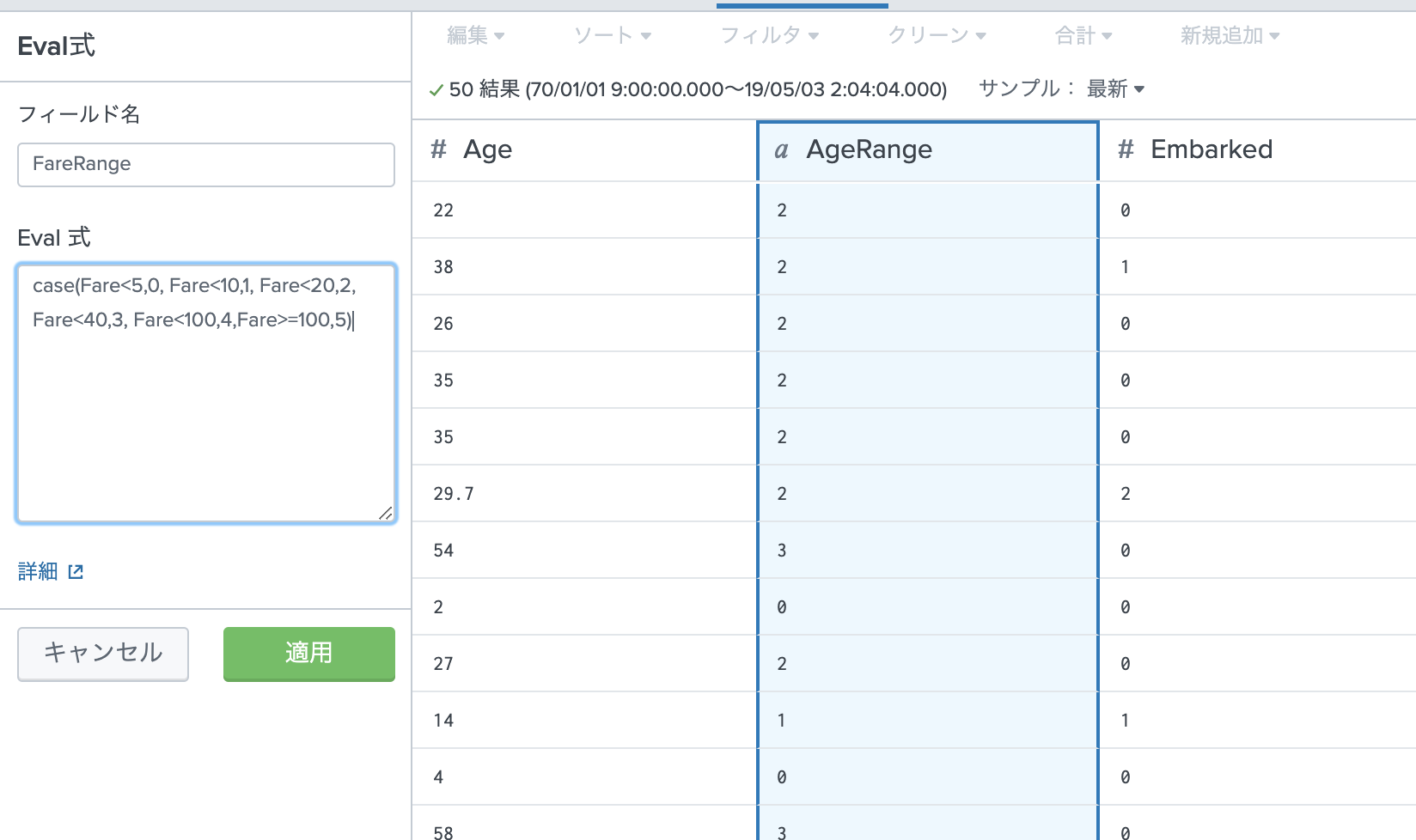
Age / Fare フィールドはもしかしたら利用するかもしれないので、ここでは削除せずに残しておきます。
3. 全て数値で表されていること
文字列になっているのは以下のフィールドです。
・Embarked(乗船した港)
・Sex (性別)
・Name (氏名)
・Ticket (チケット番号)
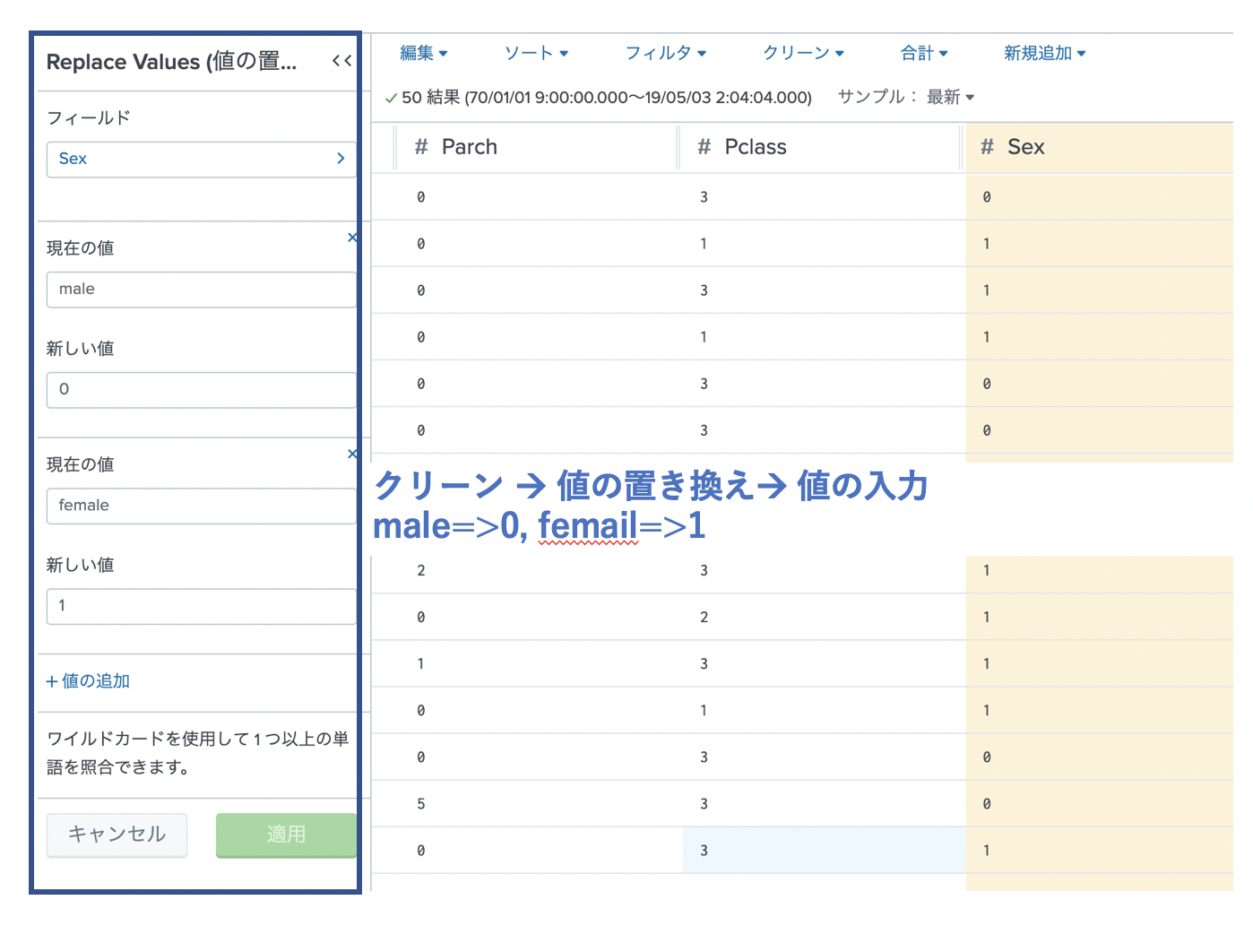
性別については、下記のように2つに分けられるので、数値変換しておきます。
・ Sex (Male -> 0, Female ->1)
Embarkedについては、S,C,Qはそれぞれ関連のない値なので、数値変換してしまうとその違いが説明できなくなってしまいます。ここでは OneHot Encodingを利用してカテゴリカル変換したいと思います。
しかし、このデータセットのアプリでは OneHot Encoding 的な変換の仕方が見つからなかったので、後ほどSPLを使って変換したいと思います。
Name に関しては、先ほどのtitle を抜き出しておきます。数の多かった "Mr", "Miss","Mrs","Master"と残りは"Other"としておき、こちらも Embarked同様に最後に OneHotEncodingしておきます。
| rex field=Name "\w+, (?P<ti>\w+)\."
| eval Title = case(ti="Mr","Mr",ti="Mrs","Mrs",ti="Miss","Miss",ti="Master","Master",true(),"Other")
最後にTicket 列です。数値と文字列で分けて生存率をみたりしましたが、あまり違いはありませんでした。そこで文字列の中身に注目して、いくつかの文字列ごとの生存率を見てみたところ。PCという文字が入っていると生存率が高いことがわかりました。
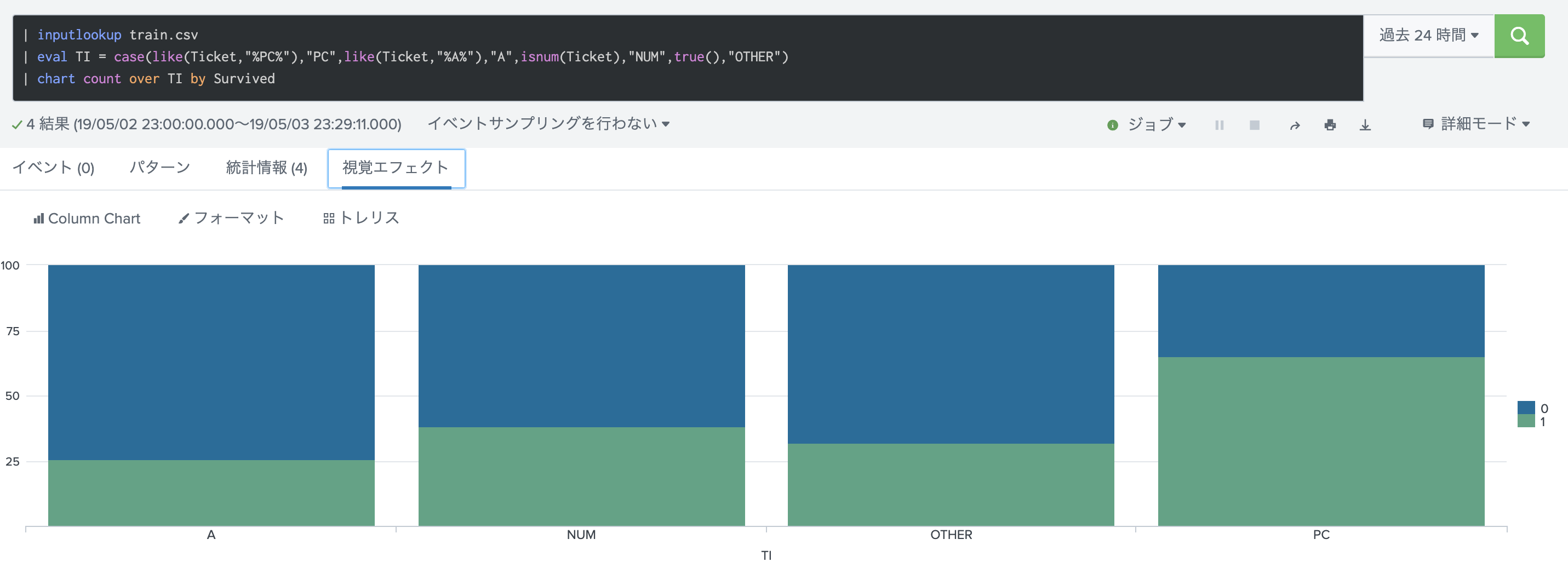
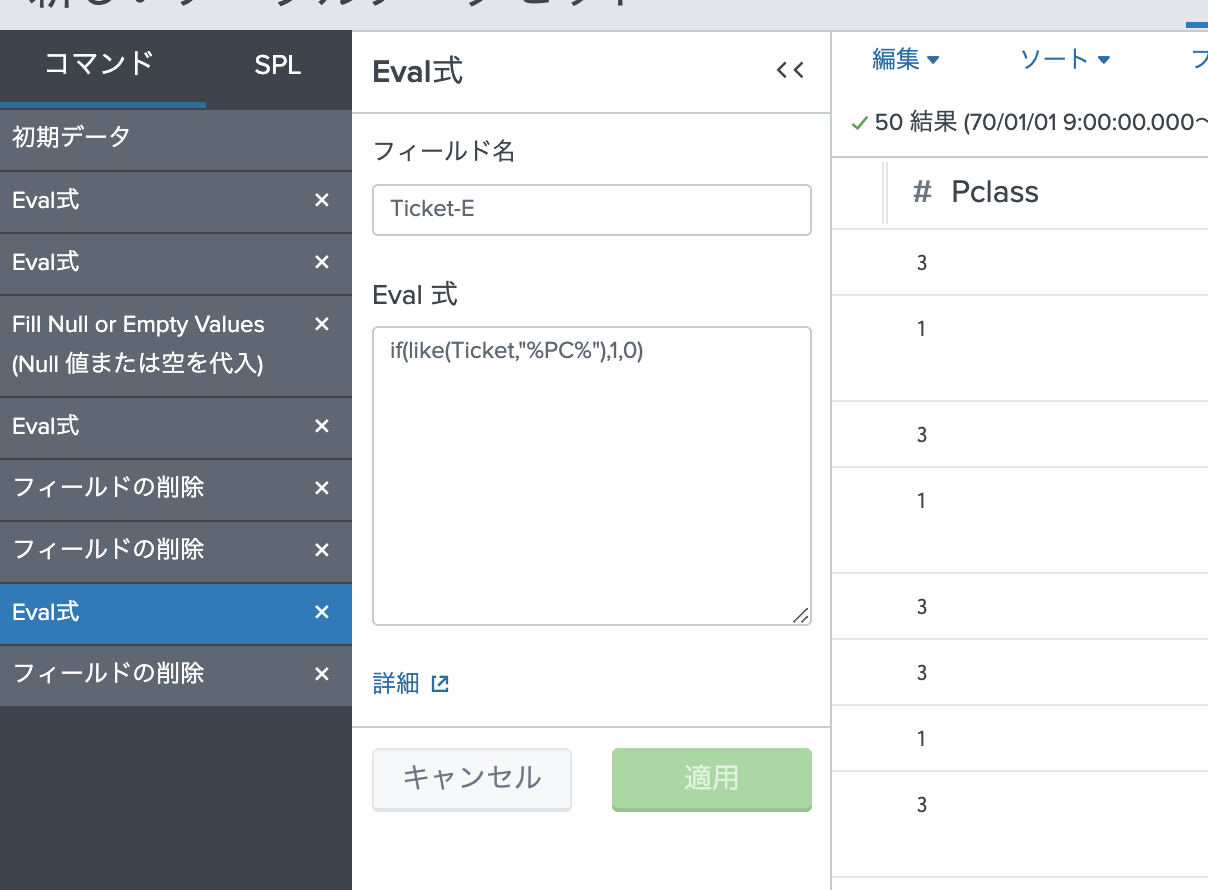
とりあえず、新しいチケット列(Ticket-E)を作成しておきます。
4. 余計なデータが取り除かれている事
データ分析に関係のなさそうなフィールドは、ここで取り除いておきます。以下のフィールドはここで削除しておきます。
- Cabin (Cabin-Eに変換済み)
- Name (titleとして抽出済み)
- Sex (Sex-numとして変換済み)
- Ticket (Ticket-Eとして抽出済み)
一旦、ここでデータを最終確認してます。Evalで追加したフィールドは文字列として認識されているので、「編集」から数値として指定しておきます。最後の Embarked列の OneHot Encoding については、データセットアプリの中でコマンドの追加方法が不明だったため、一旦保存して再度読み込むこととしました。
OneHot Encoding
OneHot Enconding https://ja.wikipedia.org/wiki/One-hot
数字というのは、上下関係が発生してしまいますが、数値に変換するときにこれを無視して変換すると予測結果に悪影響が出てしまうことがあります。それを防ぐため、 0/1 (Flase/True)で表現できるように変換する仕組みが OneHot Encodingです。フィールドの数が増えてしまうデメリットがありますが、機械学習に取り込めるようになります。
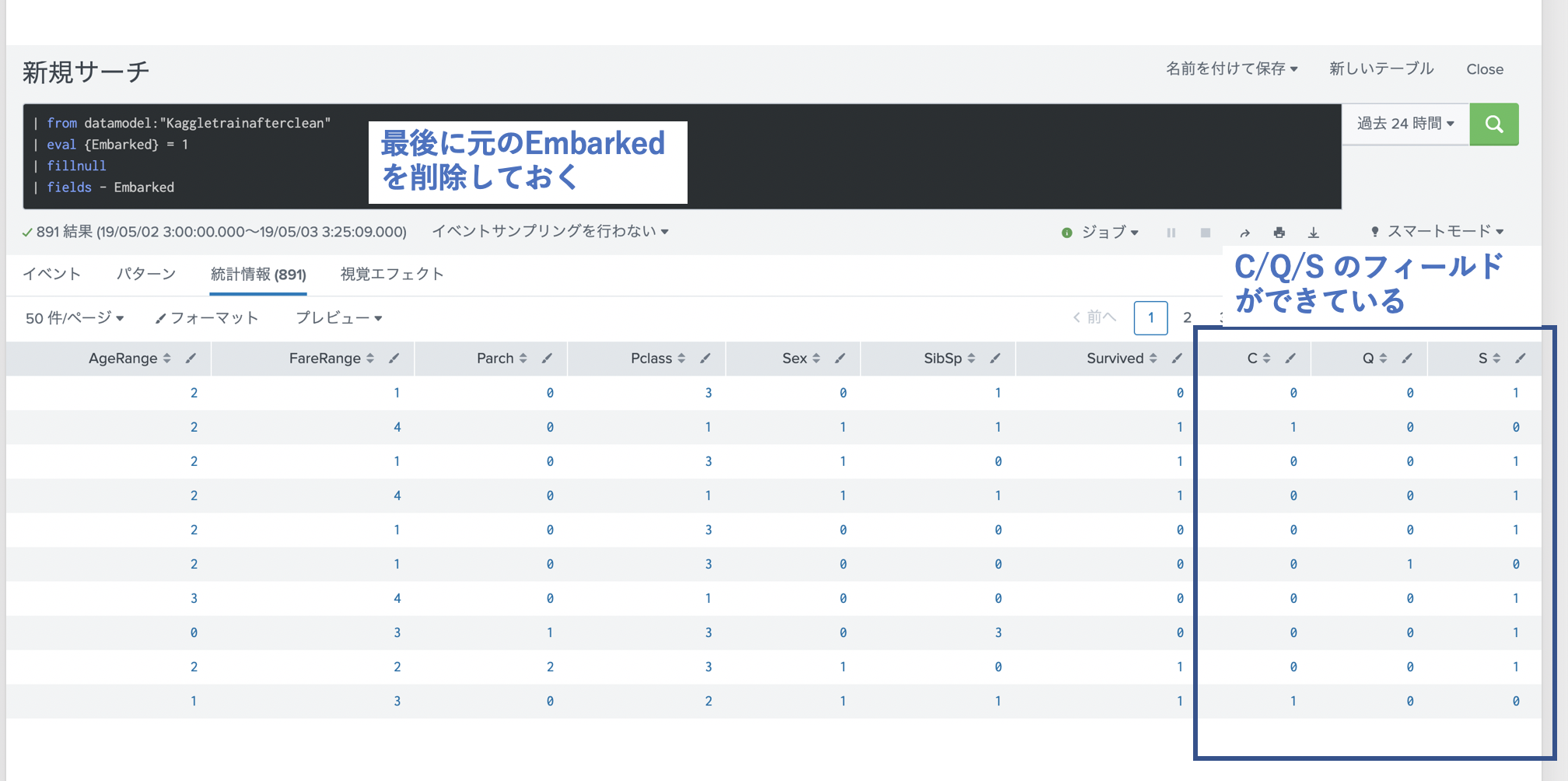
Splunkでは、以下のSPLコマンドで変換できます。(今回は Embarkedと Titleに対して変換します)
| eval {Field} = 1
| fillnull
実際に Embarked に対して実施した結果です。
これで、前処理は終了です。
最後に結果をlookupファイルに書き込んでおきます。
outputlookup kaggle-train.csv
これでようやく、MLTKで学習をさせることができるようになります。
本当にデータ分析って前処理が大変ですね。。
まとめ
解説がごちゃごちゃしてよくわからなくなったと思うので、最後にどのようなデータ前処理をしたかまとめておきます。
1)データ欠損処理
- AgeのNULLを名前のTitleを元に平均値で入力。(Miss/Masterには、9歳。他は27歳)
- Embarked のNULL値には Sを入力
- Cabin列は、NULLかそれ以外で 0 or 1として新規のCabin-E 列を作成。
2) グループ化
- Age を5グループに分けた
- Fareを5グループに分けた
3) 数値への変換
- Sex列は、男を0、女を1に変換
- Name 列は、titleを抜き出し、OneHotEncodingする。
- Embarked 列を OneHotEncodingによりカテゴリー変換
- Ticket列は、PCという文字列が入っていれば1、それ以外は0として新規列(Ticket-E)を作成。
4) 不要な列の削除
- Cabin / Name / Embarked / Title &(ti) / Ticket を削除
今回実行したSPLのコマンドを載せておきます。データセットアプリを使って編集しても、最終的にSPLコマンドに落としてくれます。(一部は自分で追加しました)
| from datamodel:"kaggletrain"
| fields "Age", "Cabin", "Embarked", "Fare", "Name", "Parch", "PassengerId", "Pclass", "Sex", "SibSp", "Survived", "Ticket"
| eval "Sex-num"=if(Sex="male",0,1)
| eval "Age"=case(isnum(Age),Age, like(Name,"%Miss%"),9, like(Name,"%Master%"),9,true(),27)
| eval "Embarked"=if(isnull('Embarked'), "S", 'Embarked')
| eval "Cabin-E"=if(isnull(Cabin),0,1)
| eval "Ticket-E"=if(like(Ticket,"%PC%"),1,0)
| eval "AgeRange"=case(Age<10,0,Age<20,1,Age<40,2,Age<60,3,Age>=60,4)
| eval "FareRange"=case(Fare<5,0,Fare<10,1,Fare<20,2,Fare<40,3,Fare<100,4,Fare>=100,5)
| rex field=Name "\w+, (?P<ti>\w+)\."
| eval Title = case(ti="Mr","Mr",ti="Mrs","Mrs",ti="Miss","Miss",ti="Master","Master",true(),"Other")
| eval {Embarked} = 1
| fillnull
| eval {Title} = 1
| fillnull
| fields - Embarked,ti,Name,Title,Sex,Cabin,Ticket
| outputlookup kaggle-train.csv
あと、テストデータ(test.csv)に対しても同じ処理を施しておく必要があります。そうしないと訓練データで学習させた学習器をテストデータに適用しても精度があがらないためです。ただし学習させながらデータ編集などもする可能性があるので、ここでは編集せずに最終章で実施します。