概要
Databricks( Spark ) にて PySpark により開発する際のプラクティスの1つである Dataframe in, Dataframe outを実践することで、処理を共通化する方法を共有します。基本的な考え方を提示した上で、実践パターンを提示します。
基本的な考え方
Dataframe in, Dataframe outは、PySpark 開発時に知っておくべき7つのテーマという記事で紹介しておりますが、データフレームを引数としてデータフレームをリターン処理を行う方法論です。本記事のデータフレームとは、Spark データフレームです。
引用元:PySpark 開発時に知っておくべき7つのテーマ - Qiita
基本的な構文としては、下記のような関数(メソッド)を記述します。tgt_dfというデータフレームを引数として、データフレームに対する処理を行い、tgt_dfというデータフレームをリターンします。
def dataframe_in_dataframe_out(
tgt_df,
):
# 下記に処理を記載
return tgt_df
定義した関数は、ソースからデータを読み取ったデータフレームに対して実行します。eval という Python の組み込み関数を利用することで、関数を動的に呼び出すことができます。eval 関数はリターン値を取ることができ、データフレームがリターンとなる関数を実行しているためリターン結果はデータフレームです。
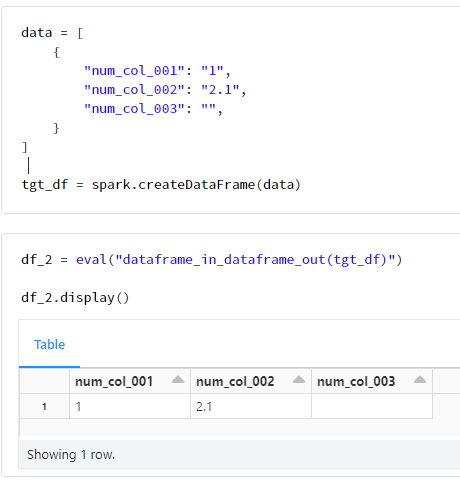
data = [
{
"num_col_001": "1",
"num_col_002": "2.1",
"num_col_003": "",
}
]
tgt_df = spark.createDataFrame(data)
df_2 = eval("dataframe_in_dataframe_out(tgt_df)")
df_2.display()
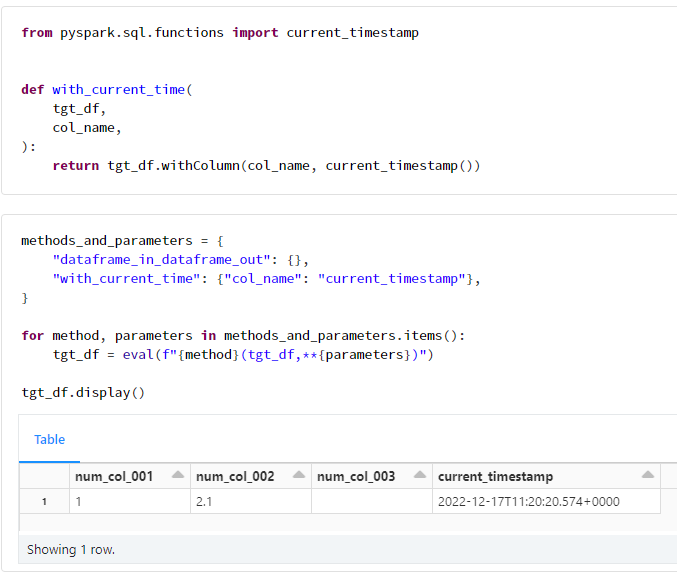
eval 関数を実行する関数名とパラメータの辞書型変数(下記例ではmethods_and_parameters変数)によるループ処理を実行することで、リターン結果のデータフレームを引数として渡しているため、指定した処理が順次実行されます。下記例にて実行している関数はdataframe_in_dataframe_outとwith_current_timeであり、辞書型変数を**により展開して引数として渡しております。dataframe_in_dataframe_outでは引数は渡しておりませんが、with_current_timeでは引数としてcol_nameにcurrent_timestampを渡しています。いずれの関数においても第一引数をデータフレームとして指定することを前提としているため、methods_and_parametersではデータフレームを引数として指定しておりません。
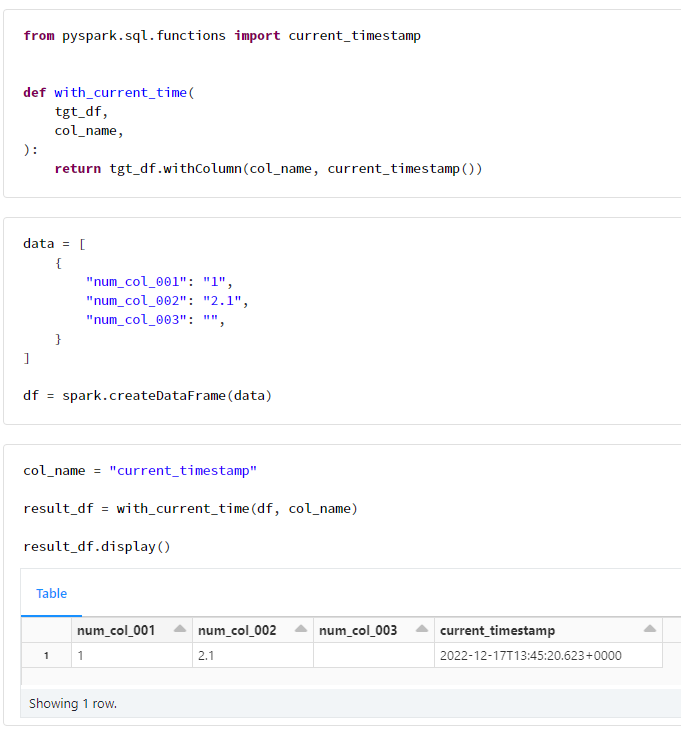
from pyspark.sql.functions import current_timestamp
def with_current_time(
tgt_df,
col_name,
):
return tgt_df.withColumn(col_name, current_timestamp())
methods_and_parameters = {
"dataframe_in_dataframe_out": {},
"with_current_time": {"col_name": "current_timestamp"},
}
for method, parameters in methods_and_parameters.items():
tgt_df = eval(f"{method}(tgt_df,**{parameters})")
tgt_df.display()
eval により順次処理を行う関数を定義しておくことで、プログラムがシンプルとなります。開発時には、それぞれの処理を関数(メソッド)として定義して、execute_methods_to_spark_dfのような関数経由で呼び出すことがおすすめです。
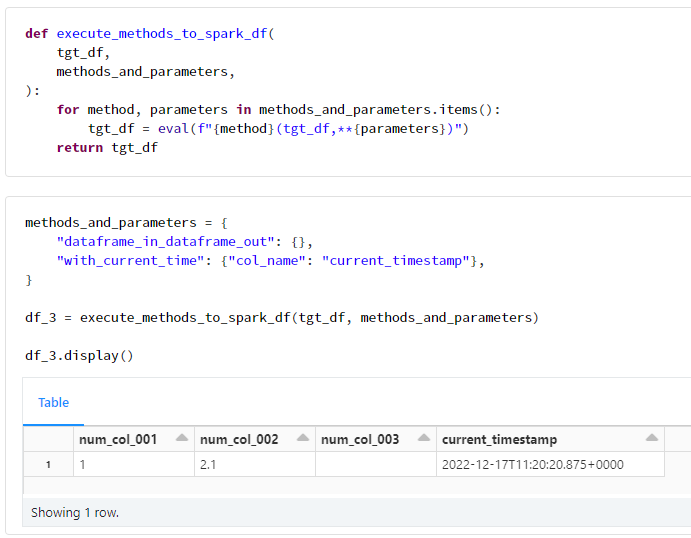
def execute_methods_to_spark_df(
tgt_df,
methods_and_parameters,
):
for method, parameters in methods_and_parameters.items():
tgt_df = eval(f"{method}(tgt_df,**{parameters})")
return tgt_df
methods_and_parameters = {
"dataframe_in_dataframe_out": {},
"with_current_time": {"col_name": "current_timestamp"},
}
df_3 = execute_methods_to_spark_df(tgt_df, methods_and_parameters)
df_3.display()
Dataframe in, Dataframe outのメリットの1つとしてテストのやりやすさがあり、テストの実践例をPySpark 開発時に知っておくべき7つのテーマ - Qiitaの記事にて紹介しております。Spark SQL により処理を実行する場合には複数の処理が混在することが多いことからテストの実施が困難となる場合があるため、単一の SQL ではなくexprメソッドにより処理を分割することが有効な場合があります。
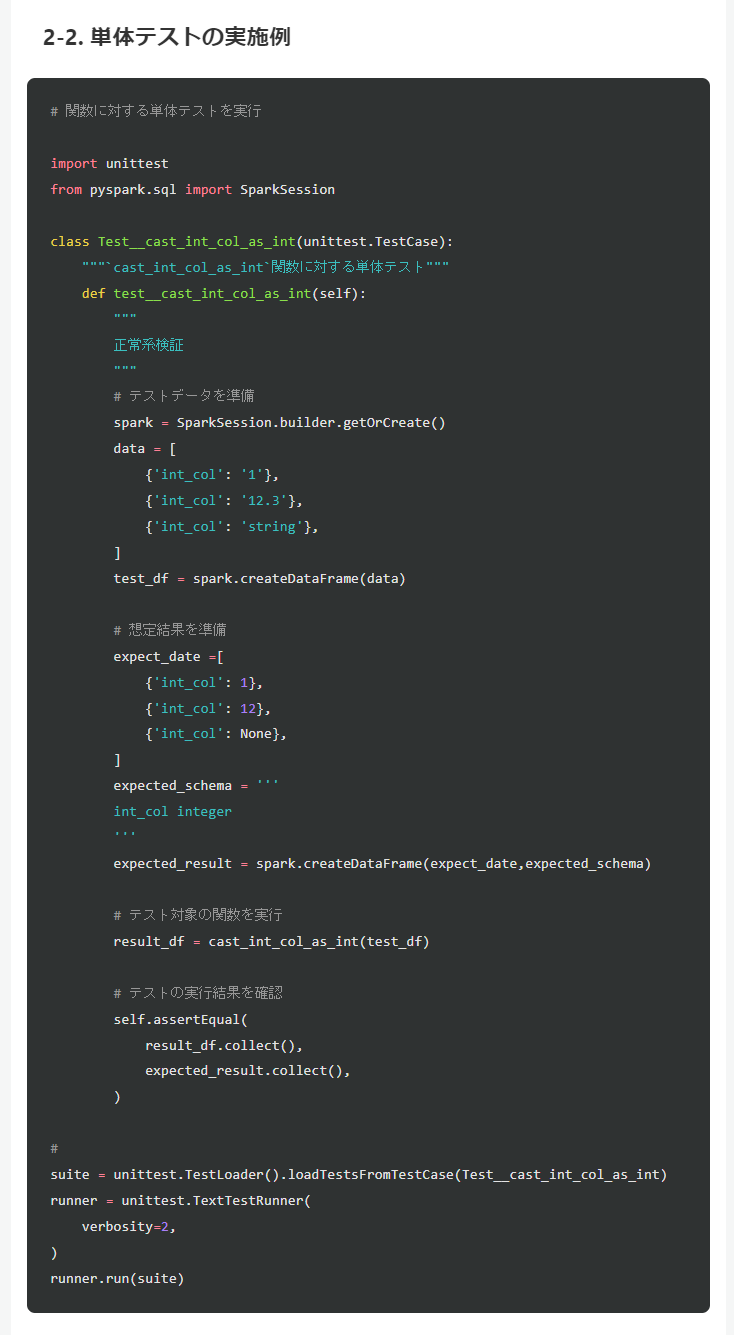
引用元:PySpark 開発時に知っておくべき7つのテーマ - Qiita
本記事では、withColumnメソッドをループ処理で利用しておりますが、数百のループ処理を行う場合には性能の観点で検証を行ってください。Spark 3.3 以降であれば、withColumnsメソッドを利用することで、性能の懸念が少なくなります。

引用元:Databricks ( Spark ) にて withColumn メソッドを用いて処理を共通化する際の懸念事項 - Qiita
実装パターン
1. データフレームのみを引数とするパターン
実践例
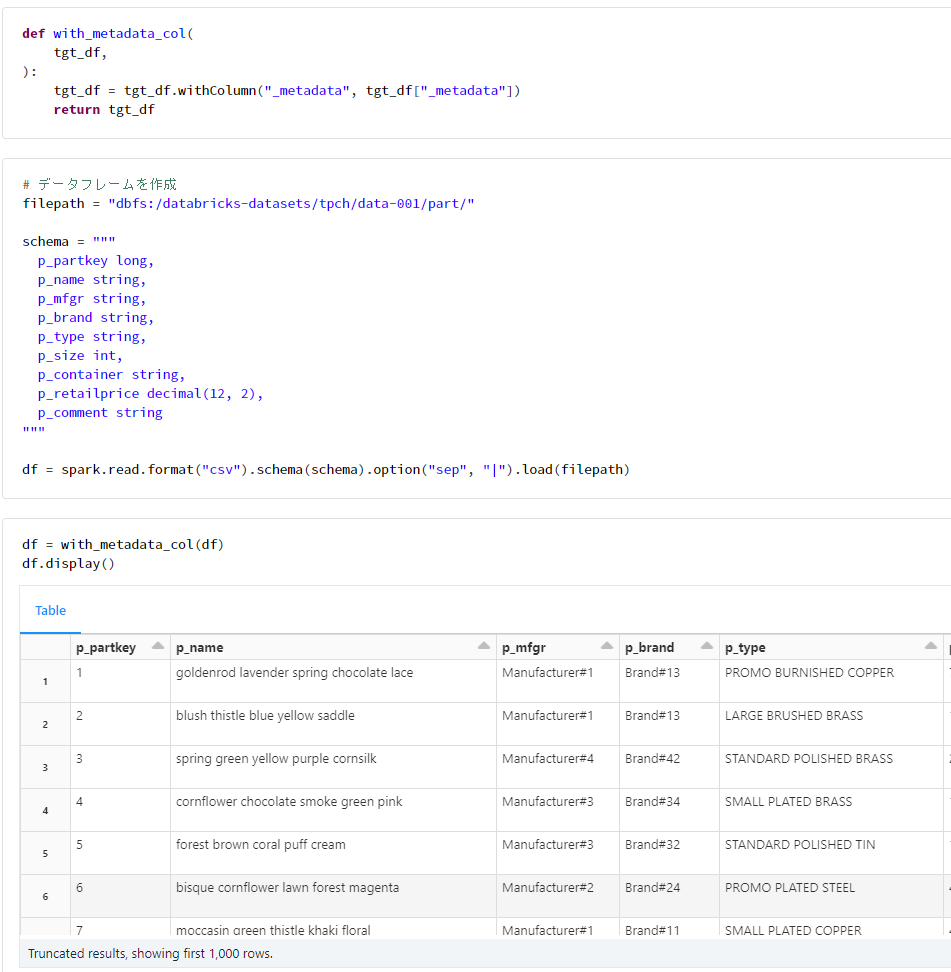
def with_metadata_col(
tgt_df,
):
tgt_df = tgt_df.withColumn("_metadata", tgt_df["_metadata"])
return tgt_df
# データフレームを作成
filepath = "dbfs:/databricks-datasets/tpch/data-001/part/"
schema = """
p_partkey long,
p_name string,
p_mfgr string,
p_brand string,
p_type string,
p_size int,
p_container string,
p_retailprice decimal(12, 2),
p_comment string
"""
df = spark.read.format("csv").schema(schema).option("sep", "|").load(filepath)
df = with_metadata_col(df)
df.display()
実践記事
共有している記事なし
2. Spark SQL を利用するパターン
実践例
from pyspark.sql.functions import expr
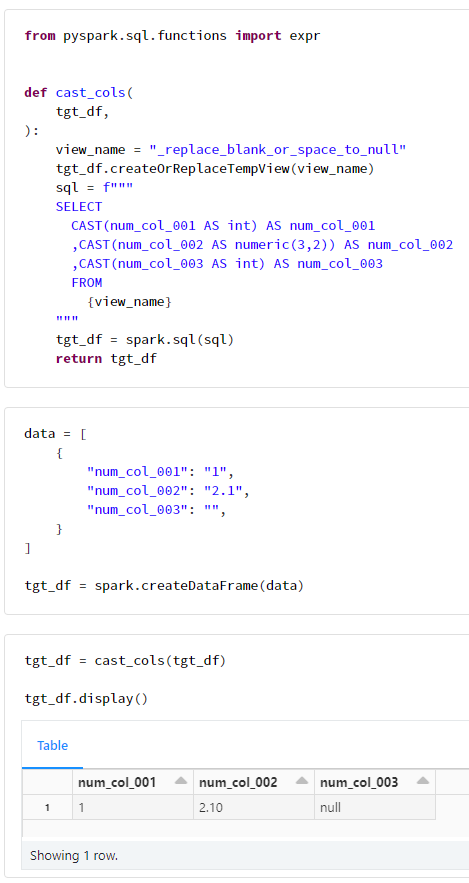
def cast_cols(
tgt_df,
):
view_name = "_replace_blank_or_space_to_null"
tgt_df.createOrReplaceTempView(view_name)
sql = f"""
SELECT
CAST(num_col_001 AS int) AS num_col_001
,CAST(num_col_002 AS numeric(3,2)) AS num_col_002
,CAST(num_col_003 AS int) AS num_col_003
FROM
{view_name}
"""
tgt_df = spark.sql(sql)
return tgt_df
data = [
{
"num_col_001": "1",
"num_col_002": "2.1",
"num_col_003": "",
}
]
tgt_df = spark.createDataFrame(data)
tgt_df = cast_cols(tgt_df)
tgt_df.display()
実践記事
共有している記事なし
3. カラムのリストにより処理するパターン
実践例
from pyspark.sql.functions import expr
def replace_blank_or_space_to_null(
tgt_df,
tgt_cols,
value_after_replacement="NULL",
):
for tgt_col in tgt_cols:
case_state = f"""
CASE WHEN TRIM({tgt_col}) != ''
THEN {tgt_col}
ELSE {value_after_replacement}
END
"""
tgt_df = tgt_df.withColumn(tgt_col, expr(case_state))
return tgt_df
Spark 3.3 以降の場合には下記の関数
from pyspark.sql.functions import expr
def replace_blank_or_space_to_null(
tgt_df,
tgt_cols,
value_after_replacement="NULL",
):
with_conds = {}
for tgt_col in tgt_cols:
case_state = f"""
CASE WHEN TRIM({tgt_col}) != ''
THEN {tgt_col}
ELSE {value_after_replacement}
END
"""
with_conds[tgt_col] = expr(case_state)
tgt_df = tgt_df.withColumns(with_conds)
return tgt_df
data = [
{
"col_001": "1",
"col_002": "",
"col_003": " ",
"col_004": " ",
}
]
df = spark.createDataFrame(data)
df.display()
tgt_col_info = {
"col_001",
"col_002",
"col_003",
"col_004",
}
result_df = replace_blank_or_space_to_null(df, tgt_col_info)
result_df.display()
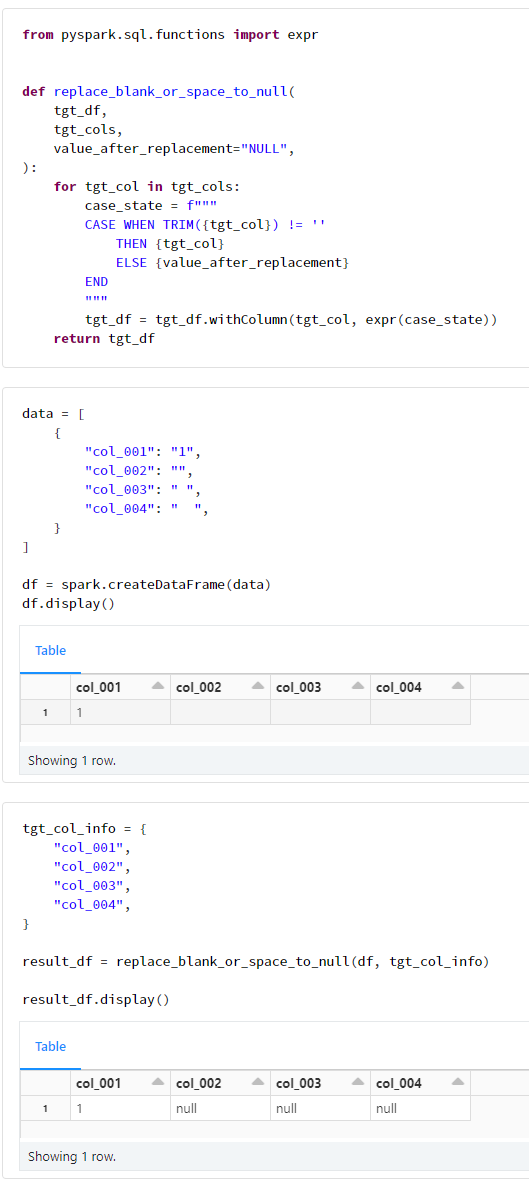
実践記事
- Databricks にて 空白の値、あるいは、スペースの値となっているカラムを NULL に置換する Python関数の作成方法 - Qiita
- Databricks ( Spark ) にてデータフレームのカラム名を一括で変更する方法 - 1. カラムのリスト型変数により置換する方法
4. カラム名をキーとした辞書型変数により処理するパターン
実践例
from pyspark.sql.functions import expr
def replace_col_value_to_zero_when_cast_error(
tgt_df,
tgt_col_info,
value_after_replacement="'0'",
):
for tgt_col, tgt_data_type in tgt_col_info.items():
case_state = f"""
CASE WHEN ISNULL(TRY_CAST({tgt_col} AS {tgt_data_type})) is false
THEN {tgt_col}
ELSE {value_after_replacement}
END
"""
tgt_df = tgt_df.withColumn(tgt_col, expr(case_state))
return tgt_df
Spark 3.3 以降の場合には下記の関数
from pyspark.sql.functions import expr
def replace_col_value_to_zero_when_cast_error(
tgt_df,
tgt_col_info,
value_after_replacement = "'0'",
):
with_conds = {}
for tgt_col, tgt_data_type in tgt_col_info.items():
case_state = f"""
CASE WHEN ISNULL(TRY_CAST({tgt_col} AS {tgt_data_type})) is false
THEN {tgt_col}
ELSE {value_after_replacement}
END
"""
with_conds[tgt_col] = expr(case_state)
tgt_df = tgt_df.withColumns(with_conds)
return tgt_df
data = [
{
"col_001": "1.12",
"col_002": "1.121",
"col_003": "1.a",
"col_004": "abc",
"col_005": "",
"col_005": " ",
}
]
df = spark.createDataFrame(data)
df.display()
tgt_col_info = {
"col_001": "decimal(38,10)",
"col_002": "decimal(38,10)",
"col_003": "decimal(38,10)",
"col_004": "decimal(38,10)",
"col_005": "decimal(38,10)",
}
result_df = replace_col_value_to_zero_when_cast_error(df, tgt_col_info)
result_df.display()
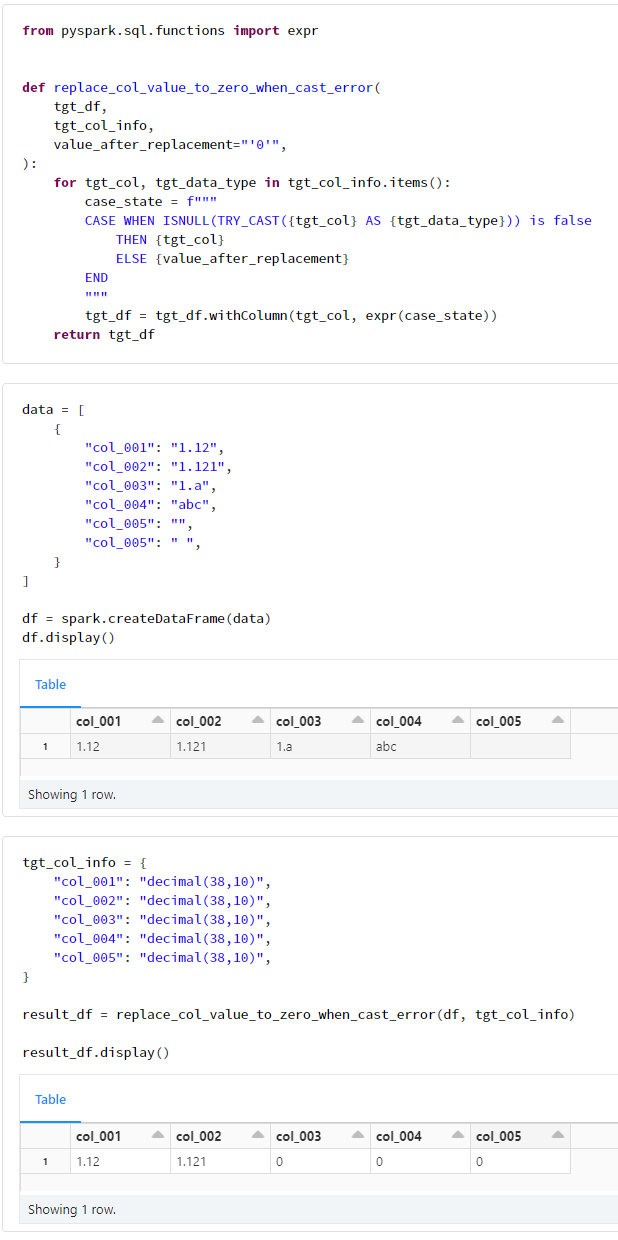
実践記事
- Databricks にて CAST できない場合にゼロに置換する Python関数の作成方法 - Qiita
- Databricks ( Spark ) にてデータフレームのカラム名を一括で変更する方法 - 2. カラムの辞書型変数により置換する方法
5. その他の引数により処理するパターン
実践例
from pyspark.sql.functions import current_timestamp
def with_current_time(
tgt_df,
col_name,
):
return tgt_df.withColumn(col_name, current_timestamp())
data = [
{
"num_col_001": "1",
"num_col_002": "2.1",
"num_col_003": "",
}
]
df = spark.createDataFrame(data)
col_name = "current_timestamp"
result_df = with_current_time(df, col_name)
result_df.display()