概要
Databricks にて 値の前後に空白を含むすべてのカラムを trim する Python関数を共有します。
from pyspark.sql.functions import expr
def trim_space_values(
tgt_df,
trim_option='BOTH',
):
cur_dtypes = tgt_df.dtypes
# `string`のカラムのみを対象とする
tgt_cols = []
for tgt_dtyp in cur_dtypes:
if tgt_dtyp[1].lower() == 'string':
tgt_cols.append(tgt_dtyp[0])
for tgt_col in tgt_cols:
case_state = f"trim({trim_option} FROM {tgt_col})"
tgt_df = tgt_df.withColumn(tgt_col, expr(case_state))
return tgt_df
Spark 3.3 以降であれば、下記の関数を利用してください。
from pyspark.sql.functions import expr
def trim_space_values(
tgt_df,
trim_option='BOTH',
):
cur_dtypes = tgt_df.dtypes
# `string`のカラムのみを対象とする
tgt_cols = []
for tgt_dtyp in cur_dtypes:
if tgt_dtyp[1].lower() == 'string':
tgt_cols.append(tgt_dtyp[0])
with_conds = {}
for tgt_col in tgt_cols:
case_state = f"trim({trim_option} FROM {tgt_col})"
with_conds[tgt_col] = expr(case_state)
tgt_df = tgt_df.withColumns(with_conds)
return tgt_df
trim_optionにて、ドキュメントに記載のあるstrより前の箇所(例:LEADING)を指定できるようにしてあります。

引用元:trim 関数 (Databricks SQL) - Azure Databricks - Databricks SQL | Microsoft Learn
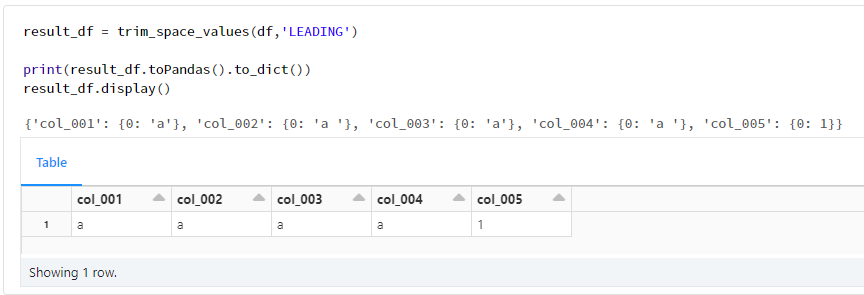
trim_optionにてLEADINGを指定する方法を下記に示します。
result_df = trim_space_values(df,'LEADING')
print(result_df.toPandas().to_dict())
result_df.display()
動作確認
1. 関数を定義
from pyspark.sql.functions import expr
def trim_space_values(
tgt_df,
trim_option='BOTH',
):
cur_dtypes = tgt_df.dtypes
# `string`のカラムのみを対象とする
tgt_cols = []
for tgt_dtyp in cur_dtypes:
if tgt_dtyp[1].lower() == 'string':
tgt_cols.append(tgt_dtyp[0])
for tgt_col in tgt_cols:
case_state = f"trim({trim_option} FROM {tgt_col})"
tgt_df = tgt_df.withColumn(tgt_col, expr(case_state))
return tgt_df
2. データフレームを作成
data = [
{
"col_001": "a",
"col_002": "a ",
"col_003": " a",
"col_004": " a ",
"col_005": 1,
}
]
df = spark.createDataFrame(data)
print(df.toPandas().to_dict())

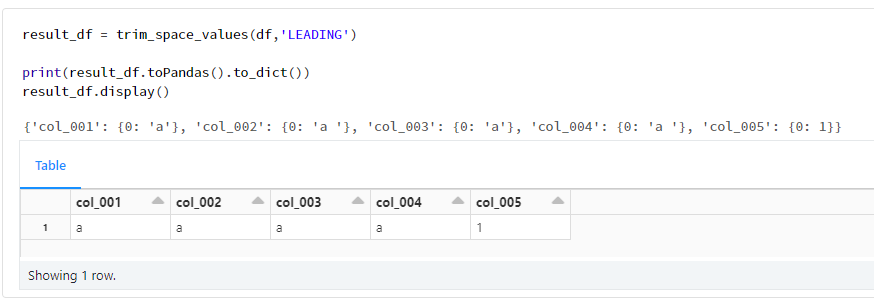
3. 関数の利用
result_df = trim_space_values(df)
print(result_df.toPandas().to_dict())
result_df.display()