概要
Databricks ( Spark ) にて 固定長テキストファイル(fixed-length text files)をソースとした場合のデータフレーム作成方法を共有します。
固定長テキストファイル(fixed-length text files)とは、下記のように1レコードの長さがスペースなどで固定(下記例では、全部で80字で固定)されているファイルです。
1 user_aaa user_aaa@test.com 53.5 180
2 user_bbb user_bbb@test.com 53.5 180
3 user_ccc user_ccc@test.com 53.5 180

単一列で取り込み後、substring 関数と trim 関数により新規列と追加することで、想定のデータフレームとなります。
from pyspark.sql.functions import substring, trim
def split_fixed_width_cols(
df,
col_num,
col_str_width,
base_col_name_prefix="_c",
should_drop_first_col=True,
):
first_col_name = df.columns[0]
counter = 1
for tgt_col_num in range(col_num):
new_col_name = f"{base_col_name_prefix}{str(counter)}"
pos = tgt_col_num * col_str_width
df = df.withColumn(
new_col_name, trim(substring(df[first_col_name], pos, col_str_width))
)
counter += 1
if should_drop_first_col:
df = df.drop(first_col_name)
return df
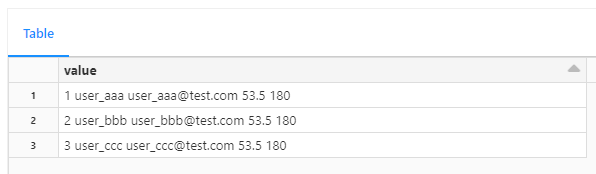
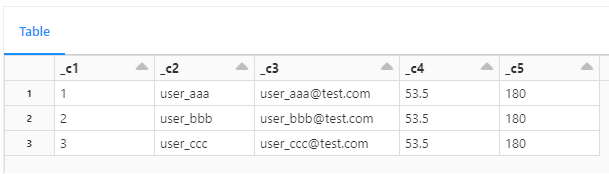
固定長テキストファイルのパターンとしては、文字数ではなく、バイト数が固定のファイルがあります。下記図がそのサンプルであり、1 行目の最初の値が あというマルチバイトであるため、その後のスペースが 2 行目や 3 行目より 1つ少なくなっております。その対応方法としては、バイナリーにエンコーディング後、バイト単位でバイナリーから値をを取得して、デコードすることで対応できます。

ただし、PySpark にて、shift_jis のバイト単位での固定ファイルを区切る場合には、対応しているエンコーディングが限られていることに注意してください。検証した際にはコードがに動作しましたが、想定外の動作をする可能性があります。また、Pandas API on Spark も、2022 年 11 月 7 日時点にて、サポート外のようです。性能に懸念がありますが、 Pandas で実装する方針がよさそうです。

引用元:pyspark.sql.functions.encode — PySpark 3.1.3 documentation (apache.org)

引用元:pyspark.pandas.Series.str.encode — PySpark 3.3.1 documentation (apache.org)
Windows の機種依存文字がソースに含まれる場合には、shift_jis ではなく、cp932 を指定したほうがいい場合があります。

実行例手順
1. すべてのカラムが共通の長さである場合の実行例
import inspect
from pyspark.sql import DataFrame, SparkSession
from pyspark.dbutils import DBUtils
def put_files_to_storage(
path,
content,
is_overwrite=True,
):
# 最初の行と最後の行を削除
content = inspect.cleandoc(content)
spark = SparkSession.getActiveSession()
dbutils = DBUtils(spark)
return dbutils.fs.put(path, content, is_overwrite)
# 検証用ファイルの配置
path = "dbfs:/test/test.txt"
csv_data_rows = """
1 user_aaa user_aaa@test.com 53.5 180
2 user_bbb user_bbb@test.com 53.5 180
3 user_ccc user_ccc@test.com 53.5 180
"""
put_files_to_storage(path, csv_data_rows)
# ファイルを確認
file_content = dbutils.fs.head(path)
print(file_content)

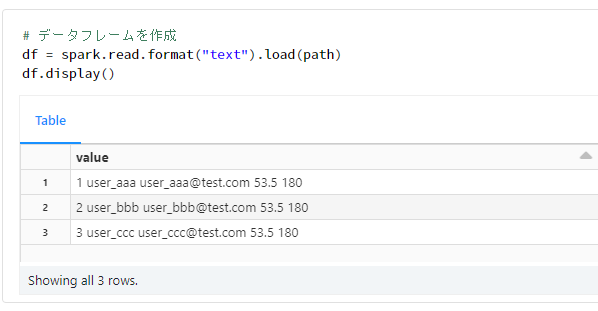
# データフレームを作成
df = spark.read.format("text").load(path)
df.display()
from pyspark.sql.functions import substring, trim
def split_fixed_width_cols(
df,
col_num,
col_str_width,
base_col_name_prefix="_c",
should_drop_first_col=True,
):
first_col_name = df.columns[0]
counter = 1
for tgt_col_num in range(col_num):
new_col_name = f"{base_col_name_prefix}{str(counter)}"
pos = tgt_col_num * col_str_width
df = df.withColumn(
new_col_name, trim(substring(df[first_col_name], pos, col_str_width))
)
counter += 1
if should_drop_first_col:
df = df.drop(first_col_name)
return df
col_num = 5
col_str_width = 20
df_2 = split_fixed_width_cols(df, col_num, col_str_width)

df_2.display()

2. カラムごとに長さが異なる場合の実行例
import inspect
from pyspark.sql import DataFrame, SparkSession
from pyspark.dbutils import DBUtils
def put_files_to_storage(
path,
content,
is_overwrite=True,
):
# 最初の行と最後の行を削除
content = inspect.cleandoc(content)
spark = SparkSession.getActiveSession()
dbutils = DBUtils(spark)
return dbutils.fs.put(path, content, is_overwrite)
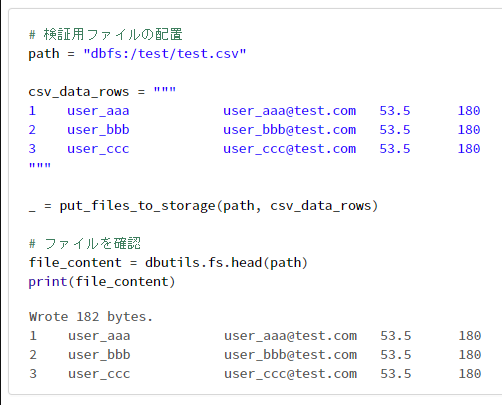
# 検証用ファイルの配置
path = "dbfs:/test/test.csv"
csv_data_rows = """
1 user_aaa user_aaa@test.com 53.5 180
2 user_bbb user_bbb@test.com 53.5 180
3 user_ccc user_ccc@test.com 53.5 180
"""
_ = put_files_to_storage(path, csv_data_rows)
```python
# ファイルを確認
file_content = dbutils.fs.head(path)
print(file_content)
# データフレームを作成
df = spark.read.format("text").load(path)
df.display()

from pyspark.sql.functions import substring, trim
def split_fixed_width_cols_with_col_width(
df,
col_str_widths,
base_col_name_prefix="_c",
should_drop_first_col=True,
):
first_col_name = df.columns[0]
pos = 0
counter = 1
for tgt_col_str_width in col_str_widths:
new_col_name = f"{base_col_name_prefix}{str(counter)}"
df = df.withColumn(
new_col_name, trim(substring(df[first_col_name], pos, tgt_col_str_width))
)
pos += tgt_col_str_width
counter += 1
if should_drop_first_col:
df = df.drop(first_col_name)
return df

col_str_widths = [5, 20, 20, 10, 5]
df_3 = split_fixed_width_cols_with_col_width(df, col_str_widths)

df_3.display()
3. すべてのカラムが共通のバイト数である場合の実行例(文字コードがshift_jis)
import inspect
from pyspark.sql import DataFrame, SparkSession
from pyspark.dbutils import DBUtils
def put_files_to_storage(
path,
content,
is_overwrite=True,
):
# 最初の行と最後の行を削除
content = inspect.cleandoc(content)
spark = SparkSession.getActiveSession()
dbutils = DBUtils(spark)
return dbutils.fs.put(path, content, is_overwrite)
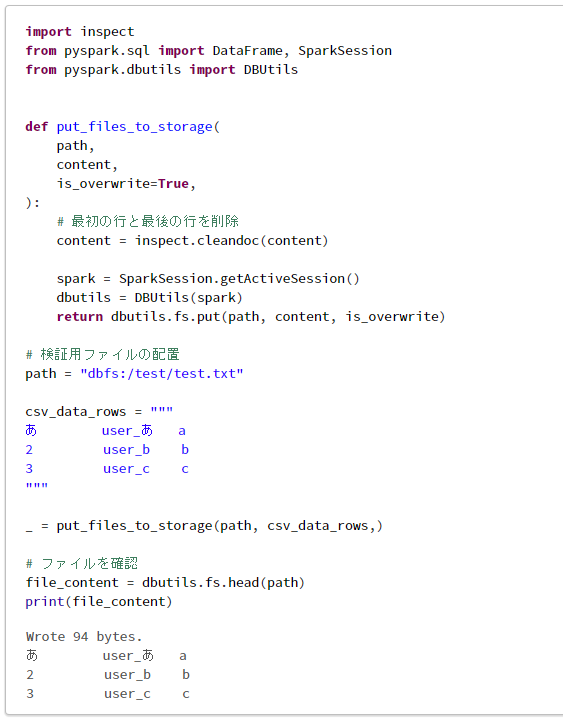
# 検証用ファイルの配置
path = "dbfs:/test/test.txt"
csv_data_rows = """
あ user_あ a
2 user_b b
3 user_c c
"""
_ = put_files_to_storage(path, csv_data_rows,)
# ファイルを確認
file_content = dbutils.fs.head(path)
print(file_content)
# データフレームを作成
df = spark.read.format("text").load(path)
df.display()

from pyspark.sql.functions import substring, trim, encode, decode
def split_fixed_byte_cols_with_encoding(
df,
col_num,
col_byte,
encoding = 'shift_jis',
errors = 'ignore',
base_col_name_prefix="_c",
should_drop_first_col=True,
):
first_col_name = df.columns[0]
counter = 1
pdf = df.toPandas()
for tgt_col_num in range(col_num):
start = tgt_col_num * col_byte
stop = counter * col_byte
new_col_name = f"{base_col_name_prefix}{str(counter)}"
pdf[new_col_name] = pdf[first_col_name].str.encode(encoding)
pdf[new_col_name] = pdf[new_col_name].str.slice(start, stop)
pdf[new_col_name] = pdf[new_col_name].str.decode(encoding, errors)
counter += 1
df = spark.createDataFrame(pdf)
counter = 1
for tgt_col_num in range(col_num):
tgt_col_name = f"{base_col_name_prefix}{str(counter)}"
df = df.withColumn(
tgt_col_name, trim(df[tgt_col_name])
)
counter += 1
if should_drop_first_col:
df = df.drop(first_col_name)
return df

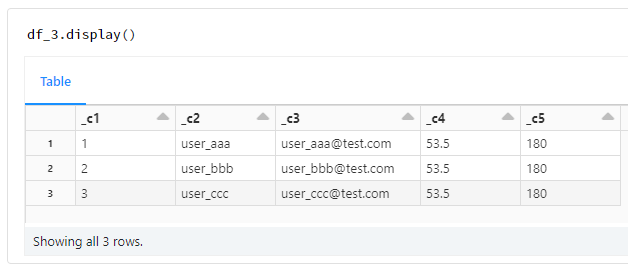
col_num = 3
col_byte = 10
df_2 = split_fixed_byte_cols_with_encoding(df, col_num, col_byte)
df_2.display()

下記のように PySpark での動作を確認済みだが、前述のようにサポート外。
from pyspark.sql.functions import substring, trim, encode, decode
def split_fixed_byte_cols(
df,
col_num,
col_byte,
charset = 'shift_jis',
errors = 'ignore',
base_col_name_prefix="_c",
should_drop_first_col=True,
):
first_col_name = df.columns[0]
counter = 1
df = df.withColumn(first_col_name, encode(df[first_col_name], charset))
for tgt_col_num in range(col_num):
new_col_name = f"{base_col_name_prefix}{str(counter)}"
start = 1 + (tgt_col_num * col_byte)
df = df.withColumn(new_col_name, substring(df[first_col_name], start, col_byte))
df = df.withColumn(new_col_name, decode(df[new_col_name], charset))
counter += 1
df = df.withColumn(first_col_name, decode(df[first_col_name], charset))
if should_drop_first_col:
df = df.drop(first_col_name)
return df
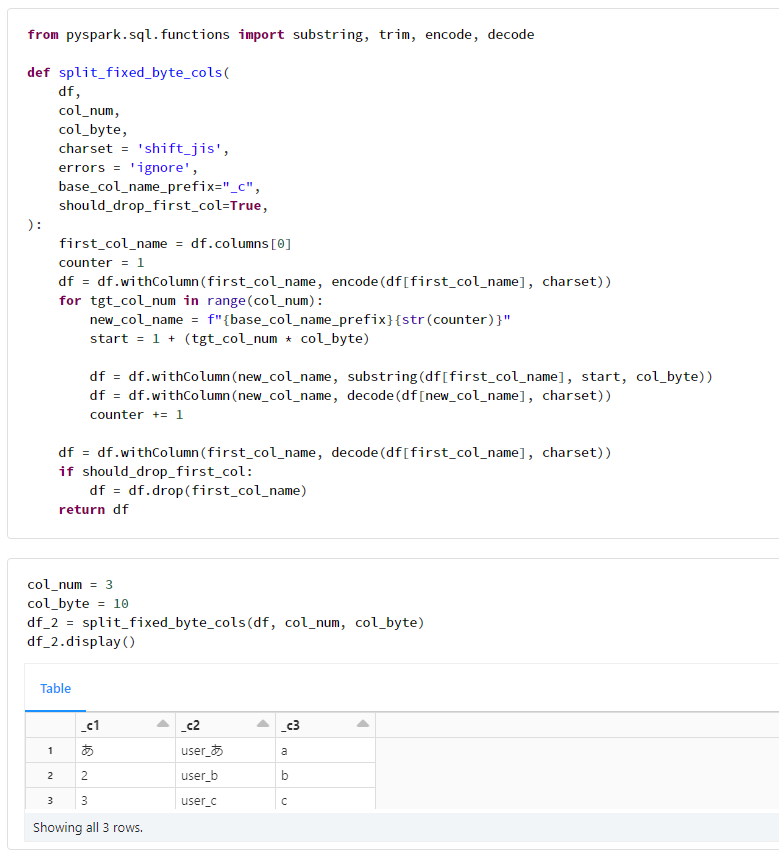
col_num = 3
col_byte = 10
df_2 = split_fixed_byte_cols(df, col_num, col_byte)
df_2.display()
4. カラムごとにバイト数が異なる場合の実行例(文字コードがshift_jis)
import inspect
from pyspark.sql import DataFrame, SparkSession
from pyspark.dbutils import DBUtils
def put_files_to_storage(
path,
content,
is_overwrite=True,
):
# 最初の行と最後の行を削除
content = inspect.cleandoc(content)
spark = SparkSession.getActiveSession()
dbutils = DBUtils(spark)
return dbutils.fs.put(path, content, is_overwrite)
# 検証用ファイルの配置
path = "dbfs:/test/test.txt"
csv_data_rows = """
あ user_あ a
2 user_b b
3 user_c c
"""
_ = put_files_to_storage(path, csv_data_rows,)
# ファイルを確認
file_content = dbutils.fs.head(path)
print(file_content)

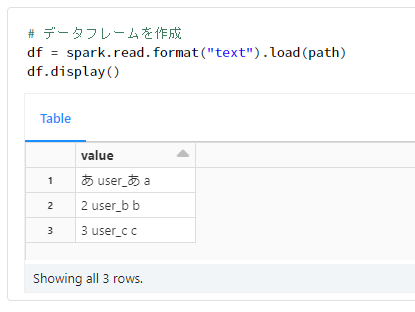
# データフレームを作成
df = spark.read.format("text").load(path)
df.display()
from pyspark.sql.functions import substring, trim, encode, decode
def split_fixed_bytes_cols_with_encoding(
df,
col_bytes,
encoding = 'shift_jis',
errors = 'ignore',
base_col_name_prefix="_c",
should_drop_first_col=True,
):
first_col_name = df.columns[0]
start = 0
stop = 0
pdf = df.toPandas()
counter = 1
for tgt_col_byte in col_bytes:
stop += tgt_col_byte
new_col_name = f"{base_col_name_prefix}{str(counter)}"
pdf[new_col_name] = pdf[first_col_name].str.encode(encoding)
pdf[new_col_name] = pdf[new_col_name].str.slice(start, stop)
pdf[new_col_name] = pdf[new_col_name].str.decode(encoding, errors)
start += tgt_col_byte
counter += 1
df = spark.createDataFrame(pdf)
counter = 1
for tgt_col_byte in col_bytes:
tgt_col_name = f"{base_col_name_prefix}{str(counter)}"
df = df.withColumn(
tgt_col_name, trim(df[tgt_col_name])
)
counter += 1
if should_drop_first_col:
df = df.drop(first_col_name)
return df

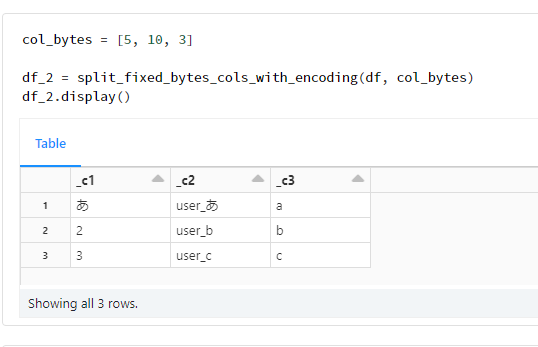
col_bytes = [5, 10, 3]
df_2 = split_fixed_bytes_cols_with_encoding(df, col_bytes)
df_2.display()
事後処理
# 本手順で作成したリソースを削除
dbutils.fs.rm(path, True)
