概要
PySpark 開発時に知っておくべき7つのテーマである次の項目を説明します。
- SparkSession 、 Spark Dataframe 、および、 Spark table
Dataframe in, Dataframe out- 変数とクラスの利用
- 変数からデータフレームを作成
- データフレームにおけるメタデータとデータを取得
- Spark SQL を PySpark で利用
- 制御フローによる PySpark処理の実行
本記事のコードを含むノートブックを以下のリンクに保存しておりますので、興味がある方は Databricks 等の環境にインポートして実行してみてください。
本記事の位置付け
次の開発ガイドシリーズにおけるSpark概要分野の1記事であり、リンク先には記事にて記事の全体像を整理している。
| GroupID | 分野 |
|---|---|
| T10 | Spark概要 |
| T20 | データエンジニアリング |
| T30 | データ品質チェック |
| T40 | データサイエンス |
| T50 | メタデータデプロイ |
| T60 | テスト |
| T70 | DevOps |
前提知識
- Spark (PySpark、Spark SQL)の基本的な知識
- データエンジニアリング の基本的な知識
- Python の基本的な知識
1. SparkSession 、 Spark Dataframe 、および、 Spark table
Sparkの処理は、SparkSessonにデータ処理を定義していき、アクションによりデータ処理が行われること(遅延評価)が特徴。Databricks 利用時にはノートブックをクラスターにアタッチする際に自動で定義されるため意識することはあまりないが、ノートブック外からテスト実行を行う際には手動の定義が必要となる。遅延評価により、処理内容の分割・共通化を分割することで単体テスト実施に合わせた構成とすることができ、システムにおける品質や拡張性が高くなる。
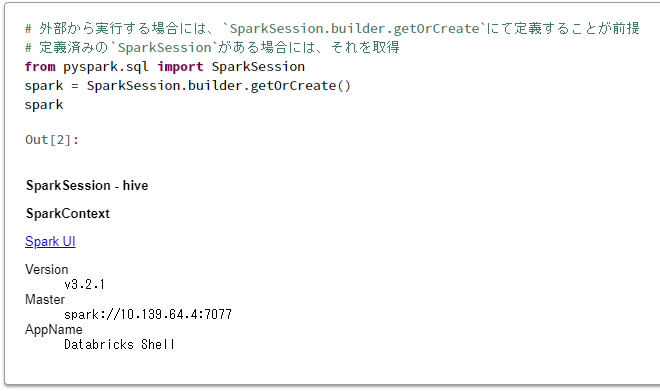
# Databricks では、ノートブックのアタッチ時に自動で`Spark`という変数に`SparkSession`が設定される
spark

# 外部から実行する場合には、`SparkSession.builder.getOrCreate`にて定義することが前提
# 定義済みの`SparkSession`がある場合には、それを取得
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
spark
data = [
{'int_col': '1'},
]
# `SparkSession`に処理(データの読み込み)を追加
spark.createDataFrame(data)

# `show`というアクションを含めることでデータ処理(`Spark jobs`)が実行される
spark.createDataFrame(data).show()

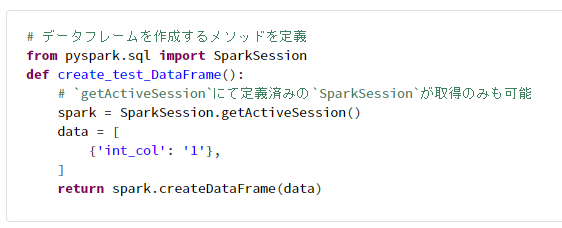
1-2. SparkSession を再利用した関数(メソッド)の定義
Spark処理開始時にSparkSessionを定義して、処理を共通化した関数内でgetActiveSessionにより定義済みのSparkSessionを取得。
# データフレームを作成するメソッドを定義
from pyspark.sql import SparkSession
def create_test_DataFrame():
# `getActiveSession`にて定義済みの`SparkSession`が取得のみも可能
spark = SparkSession.getActiveSession()
data = [
{'int_col': '1'},
]
return spark.createDataFrame(data)
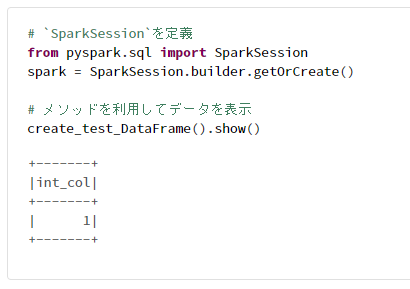
# `SparkSession`を定義
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
# メソッドを利用してデータを表示
create_test_DataFrame().show()
1-3. Spark.conf の設定
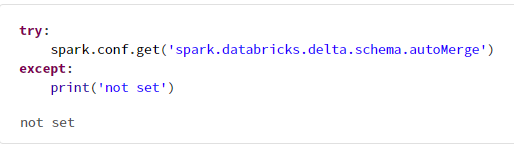
Spark の処理実行時のパラメータとしてspark.confがあり、SparkSessionにて設定を変更可能。
try:
spark.conf.get('spark.databricks.delta.schema.autoMerge')
except:
print('not set')
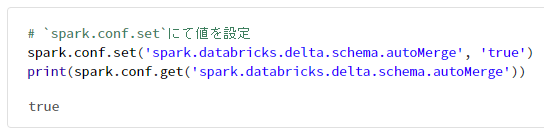
# `spark.conf.set`にて値を設定
spark.conf.set('spark.databricks.delta.schema.autoMerge', 'true')
print(spark.conf.get('spark.databricks.delta.schema.autoMerge'))
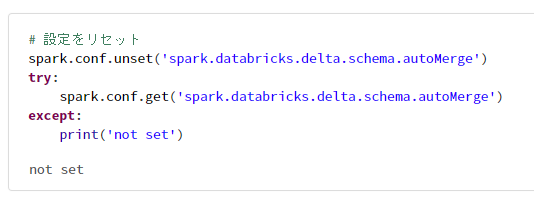
# 設定をリセット
spark.conf.unset('spark.databricks.delta.schema.autoMerge')
try:
spark.conf.get('spark.databricks.delta.schema.autoMerge')
except:
print('not set')
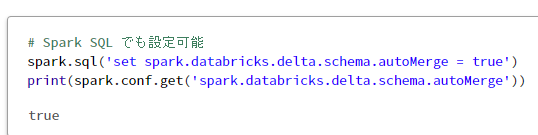
# Spark SQL でも設定可能
spark.sql('set spark.databricks.delta.schema.autoMerge = true')
print(spark.conf.get('spark.databricks.delta.schema.autoMerge'))
1-4. SparkSession の並列化処理時の注意事項
定義したSparkSessionを multiprocessing などの並列化ライブラリーで共有すると正常に動作しないことがあるため、処理ごとにSparkSessionの定義が必要となる。
Databricks ではdbutils.notebook.run()メソッドの利用が推奨されているなど、Spark プロバイダーごとに対応方法が異なる。
- ノートブックでコードをモジュール化またはリンクする - Azure Databricks | Microsoft Docs
- Microsoft Spark Utilities の概要 - Azure Synapse Analytics | Microsoft Docs
1-5. Spark table の永続化
Spark tableは、メタストアに格納されることで、セッション終了後にも利用すること(テーブルの永続化)ができる。
メタストアとして、 Hive メタストアが利用されることが多いが、Spark プロバイダー固有のメタストアが提供されていることもある。
- Unity Catalog - Azure Databricks | Microsoft Docs
- 共有メタデータ モデル - Azure Synapse Analytics | Microsoft Docs
1-6. テーブルとデータの分離
データレイクを理解するために、テーブルとデータが分離されているという概念を理解することが重要である。リレーショナルデータベース(RDB)ではテーブル = データとなっていることが多く、RDBに慣れている方はテーブルを管理すればデータも管理できると考える傾向にある。データレイクでは、1つのデータ(ディレクトリ)に複数のテーブルが紐づくことから、テーブルで管理する方法では重複操作が実施される可能性がある。管理単位を、テーブルとして捉えるのではなく、ディレクトリとして捉える必要がある。
# データベースとテーブルを作成
db_name = 'T10__L100__010'
spark.sql(f'''
CREATE DATABASE IF NOT EXISTS {db_name}
''')
tbl_name = 'nation'
tbl_full_name = f'{db_name}.{tbl_name}'
spark.sql(f'''
CREATE OR REPLACE TABLE {tbl_full_name}
(
N_NATIONKEY integer
,N_NAME string
,N_REGIONKEY integer
,N_COMMENT string
)
USING delta
''')
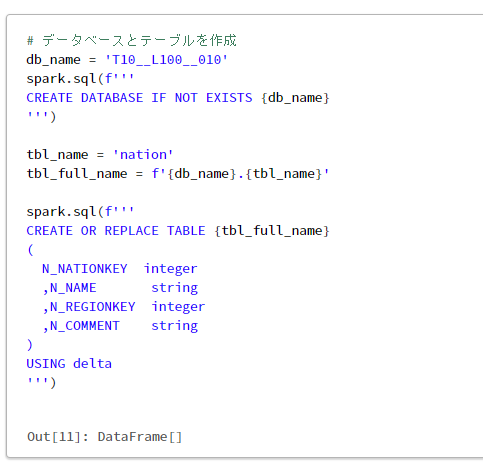
tbl_desc = spark.sql(f"DESC TABLE EXTENDED {tbl_full_name}")
tbl_desc.display()
tbl_location = (
tbl_desc
.filter('col_name = "Location"')
.select("data_type")
.collect()[0][0]
)
# テーブルへのデータ書き込み
filepath = "dbfs:/databricks-datasets/tpch/data-001/nation/"
schema = """
N_NATIONKEY integer
,N_NAME string
,N_REGIONKEY integer
,N_COMMENT string
"""
df = (spark
.read
.format("csv")
.schema(schema)
.option("inferSchema", "True")
.option("sep", "|")
.load(filepath)
)
df.write.format('delta').mode('overwrite').saveAsTable(tbl_full_name)
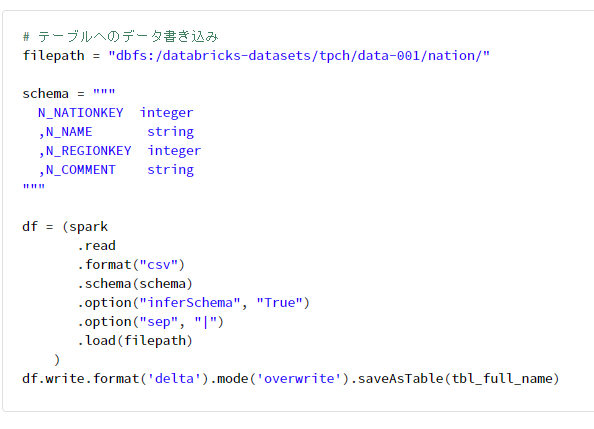
# データとディレクトリの確認
spark.table(tbl_full_name).display()
display(dbutils.fs.ls(tbl_location))
# 既存のデータからテーブルを作成
tbl_name_2 = 'nation_2'
tbl_full_name_2 = f'{db_name}.{tbl_name_2}'
spark.sql(f'''
DROP TABLE IF EXISTS {tbl_full_name_2}
''')
spark.sql(f'''
CREATE TABLE {tbl_full_name_2}
USING delta
LOCATION '{tbl_location}'
''')
print(spark.sql(f'SHOW CREATE TABLE {tbl_full_name_2}').collect()[0][0])

# テーブルにデータを書き込んでしまうと。。。
df.write.format('delta').mode('append').saveAsTable(tbl_full_name_2)

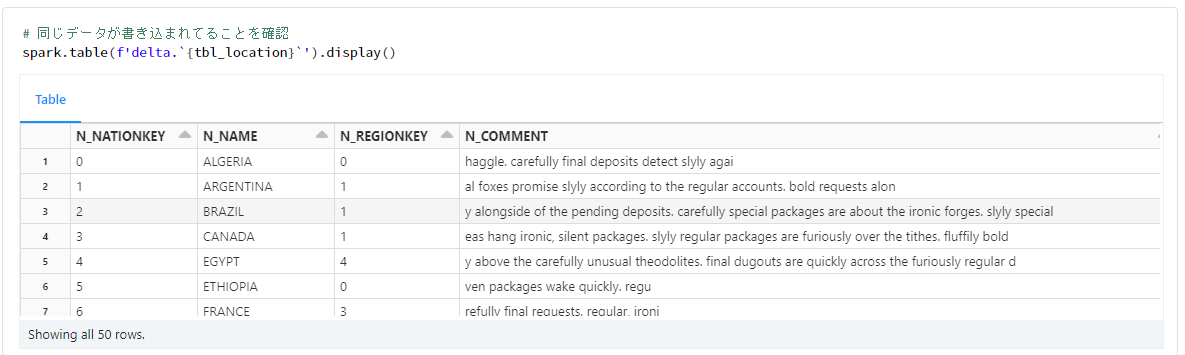
# 同じデータが書き込まれてしまう
spark.table(f'delta.`{tbl_location}`').display()
2. Dataframe in, Dataframe out
Spark のデータエンジニアリングを実施する際には、Dataframe in, Dataframe out、つまり、データフレームを引数としてデータフレームをリターンとするメソッドを組み合わせて開発を行うことが推奨されている。その理由の1つは、テストのやりやすさがある。
2-1. Dataframe in, Dataframe outの実施例
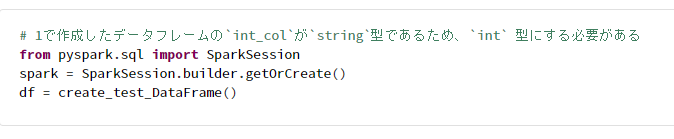
# 1で作成したデータフレームの`int_col`が`string`型であるため、`int` 型にする必要がある
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = create_test_DataFrame()
# データフレームの`int_col`カラムを`integer`型に変更する関数を定義
def cast_int_col_as_int(
df,
):
return df.withColumn('int_col', df.int_col.cast('int'))
# 関数により`int_col`カラムが`integer`型となることを確認
cast_int_col_as_int(df).printSchema()

2-2. 単体テストの実施例
# 関数に対する単体テストを実行
import unittest
from pyspark.sql import SparkSession
class Test__cast_int_col_as_int(unittest.TestCase):
"""`cast_int_col_as_int`関数に対する単体テスト"""
def test__cast_int_col_as_int(self):
"""
正常系検証
"""
# テストデータを準備
spark = SparkSession.builder.getOrCreate()
data = [
{'int_col': '1'},
{'int_col': '12.3'},
{'int_col': 'string'},
]
test_df = spark.createDataFrame(data)
# 想定結果を準備
expect_date =[
{'int_col': 1},
{'int_col': 12},
{'int_col': None},
]
expected_schema = '''
int_col integer
'''
expected_result = spark.createDataFrame(expect_date,expected_schema)
# テスト対象の関数を実行
result_df = cast_int_col_as_int(test_df)
# テストの実行結果を確認
self.assertEqual(
result_df.collect(),
expected_result.collect(),
)
#
suite = unittest.TestLoader().loadTestsFromTestCase(Test__cast_int_col_as_int)
runner = unittest.TextTestRunner(
verbosity=2,
)
runner.run(suite)

3. 変数とクラス
3-1. Spark Dataframeの不変性
PySpark における Spark データフレームは不変であるという特徴があり、処理の定義をリスト型変数や辞書型変数に格納できる。1つの変数に格納することで、開発時のデバックの実施が容易となる。
# `spark_dataframes` 変数に定義した Spark データフレームを格納
spark_dataframes = {}
df = create_test_DataFrame()
spark_dataframes['first_dataframe'] = df
df_2 = cast_int_col_as_int(df)
spark_dataframes['second_dataframe'] = df_2

# `spark_dataframes`にて保持しているデータフレームのスキーマをループ処理で表示
print(spark_dataframes)
for spark_dataframe in spark_dataframes.values():
spark_dataframe.printSchema()

3-2. f-stringによりリテラルの置換
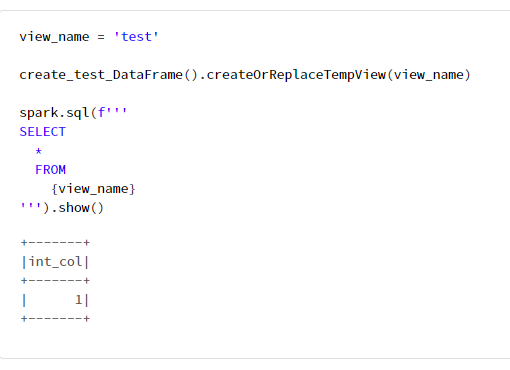
view_name = 'test'
create_test_DataFrame().createOrReplaceTempView(view_name)
spark.sql(f'''
SELECT
*
FROM
{view_name}
''').show()
3-3. Spark SQLにて変数を利用
spark.conf 経由で変数を渡すことが可能。
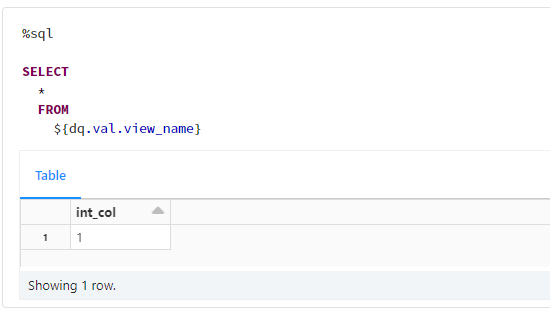
spark.conf.set('dq.val.view_name', view_name)

SELECT
*
FROM
${dq.val.view_name}
3-4. staticmethod によるメソッドの整理
ノートブック型の開発環境では%runコマンドにより他ファイルで定義したクラスや関数を読み込むことができるが、関数をクラスのstaticmethod (暗黙の第一引数を受け取らないメソッド)として定義することで管理が容易となる。
参考リンク
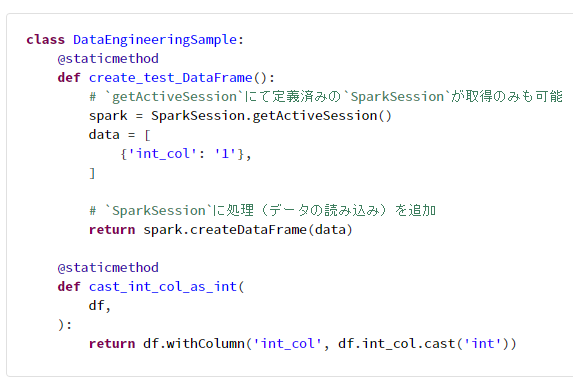
class DataEngineeringSample:
@staticmethod
def create_test_DataFrame():
# `getActiveSession`にて定義済みの`SparkSession`が取得のみも可能
spark = SparkSession.getActiveSession()
data = [
{'int_col': '1'},
]
# `SparkSession`に処理(データの読み込み)を追加
return spark.createDataFrame(data)
@staticmethod
def cast_int_col_as_int(
df,
):
return df.withColumn('int_col', df.int_col.cast('int'))
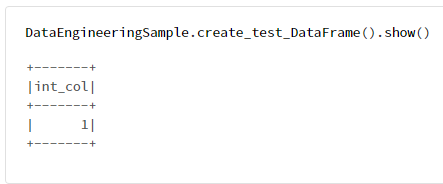
DataEngineeringSample.create_test_DataFrame().show()
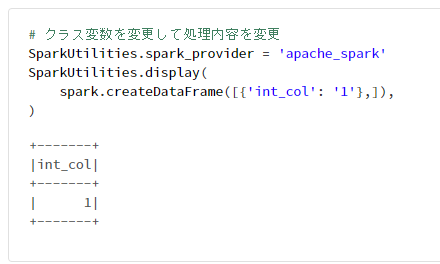
3-5. クラス変数を config として利用
# クラス変数を保持したクラスを定義
class SparkUtilities:
spark_provider = 'databricks'
@staticmethod
def display(tgt_df):
if SparkUtilities.spark_provider == 'databricks':
tgt_df.display()
if SparkUtilities.spark_provider == 'apache_spark':
tgt_df.show()

# クラス変数を変更して処理内容を変更
SparkUtilities.spark_provider = 'apache_spark'
SparkUtilities.display(
spark.createDataFrame([{'int_col': '1'},]),
)
4. 変数からデータフレームを作成
変数からデータフレームを作成する主な方法としては、次の3種類がある。単体テストのデータを用意する際などに利用する。
- 辞書型リストを用いる方法
- 多次元リストを用いる方法
-
pyspark.sql.Rowメソッドを用いる方法
4-1. 辞書型リストを用いる方法
import datetime
schema = '''
str_col string,
int_col integer,
date_col date
'''
data_001 = [
{
'str_col': 'abc',
'int_col': 123,
'date_col': datetime.date(2020, 1, 1),
},
{
'str_col': 'def',
'int_col': 456,
'date_col': datetime.date(2020, 1, 2),
},
]
df = spark.createDataFrame(
data_001,
schema,
)
df.show()

辞書型リストを用いる方法を、collectメソッドにより簡単に確認できる。
df_2 = spark.createDataFrame(
df.collect(),
schema,
)
df_dict = []
for row_data in df.collect():
df_dict.append(row_data.asDict())
df_2.show()
print(df_dict)
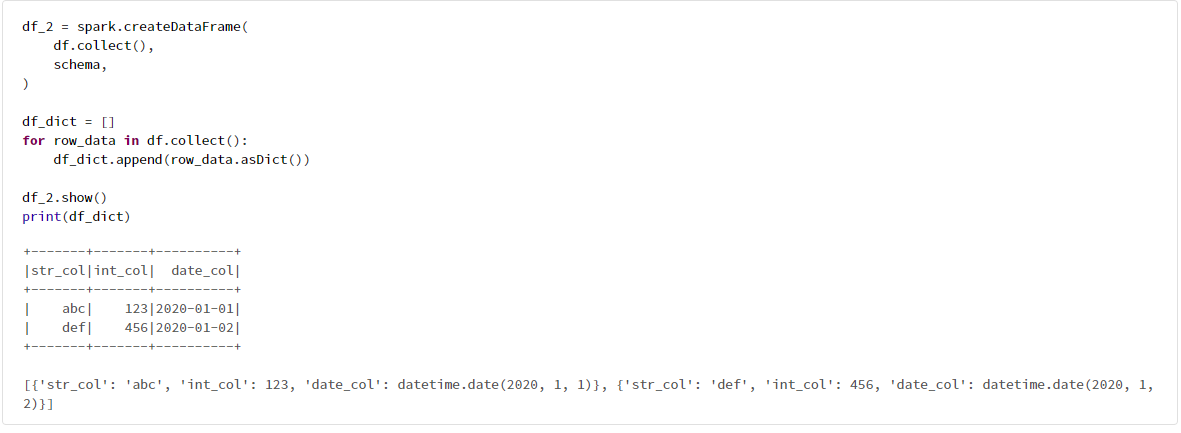
4-2. 多次元リストを用いる方法
import datetime
schema = '''
str_col string,
int_col integer,
date_col date
'''
data_002 = [
[
'abc',
123,
datetime.date(2020, 1, 1)
],
[
'def',
456,
datetime.date(2020, 1, 2)
],
]
df = spark.createDataFrame(
data_002,
schema,
)
df.show()
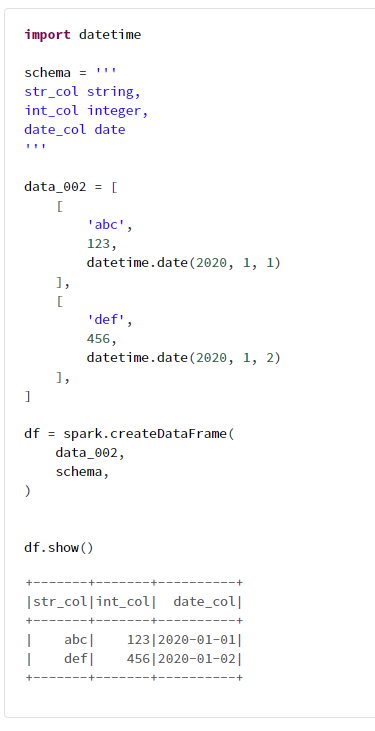
# tuple in list でも同様のことが可能
import datetime
schema = '''
str_col string,
int_col integer,
date_col date
'''
data_002 = [
(
'abc',
123,
datetime.date(2020, 1, 1)
),
(
'def',
456,
datetime.date(2020, 1, 2)
),
]
df = spark.createDataFrame(
data_002,
schema,
)
df.show()

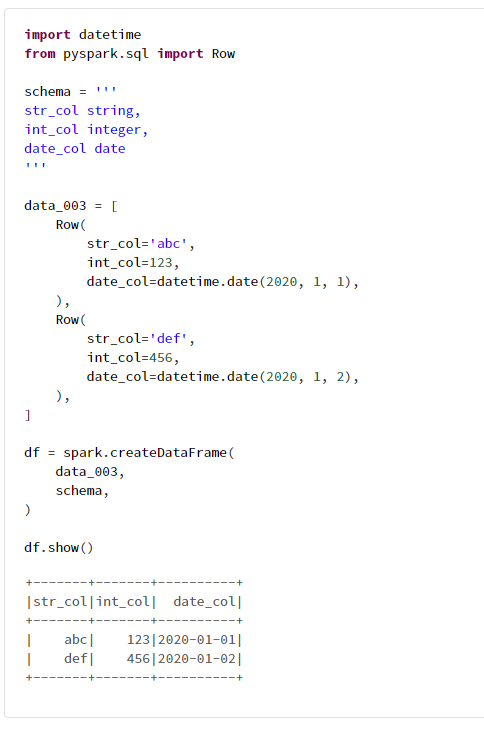
4-3. pyspark.sql.Rowメソッドを用いる方法
import datetime
from pyspark.sql import Row
schema = '''
str_col string,
int_col integer,
date_col date
'''
data_003 = [
Row(
str_col='abc',
int_col=123,
date_col=datetime.date(2020, 1, 1),
),
Row(
str_col='def',
int_col=456,
date_col=datetime.date(2020, 1, 2),
),
]
df = spark.createDataFrame(
data_003,
schema,
)
df.show()
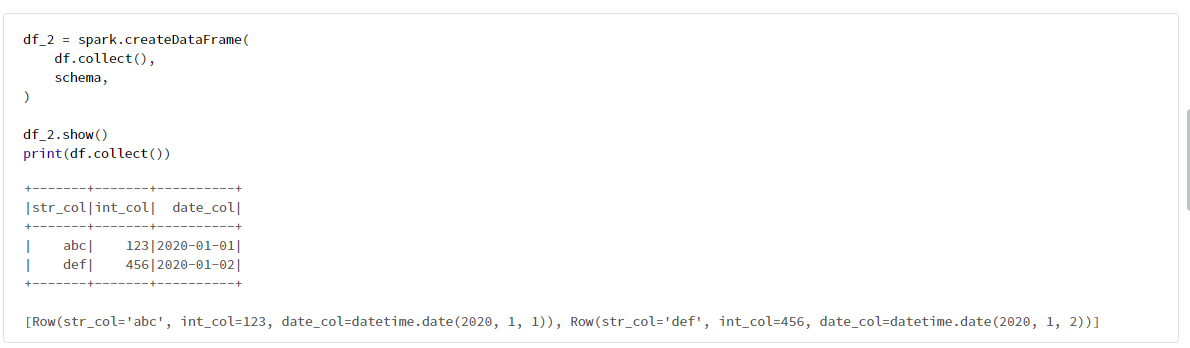
pyspark.sql.Rowの値の設定方法を、collectメソッドにより簡単に確認できる。
df_2 = spark.createDataFrame(
df.collect(),
schema,
)
df_2.show()
print(df.collect())
4-4. Spark のデータ型と Python 型の対応
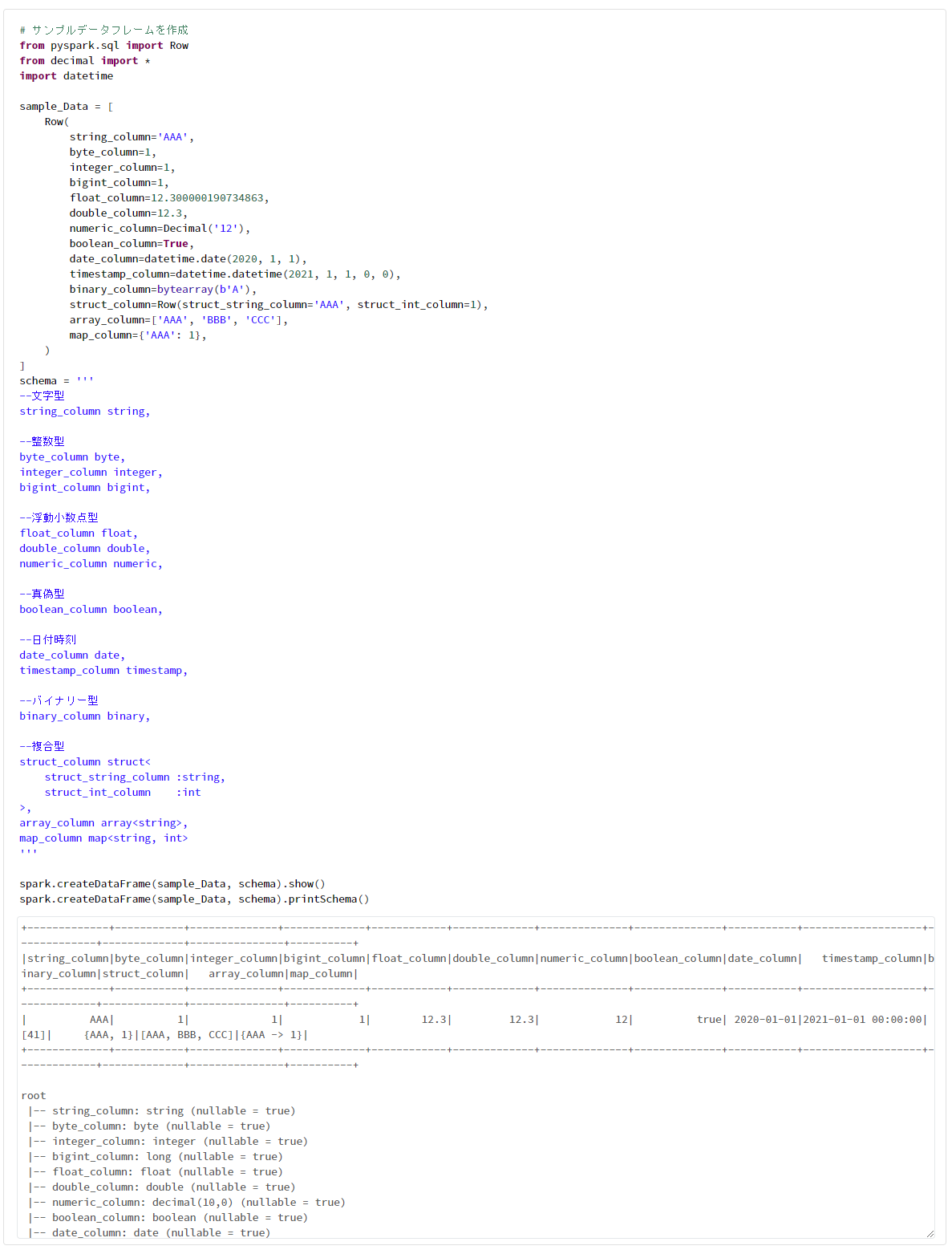
Spark データフレームのデータ型に対応する Python のデータ型は次のドキュメントに記載。
# サンプルデータフレームを作成
from pyspark.sql import Row
from decimal import *
import datetime
sample_Data = [
Row(
string_column='AAA',
byte_column=1,
integer_column=1,
bigint_column=1,
float_column=12.300000190734863,
double_column=12.3,
numeric_column=Decimal('12'),
boolean_column=True,
date_column=datetime.date(2020, 1, 1),
timestamp_column=datetime.datetime(2021, 1, 1, 0, 0),
binary_column=bytearray(b'A'),
struct_column=Row(struct_string_column='AAA', struct_int_column=1),
array_column=['AAA', 'BBB', 'CCC'],
map_column={'AAA': 1},
)
]
schema = '''
--文字型
string_column string,
--整数型
byte_column byte,
integer_column integer,
bigint_column bigint,
--浮動小数点型
float_column float,
double_column double,
numeric_column numeric,
--真偽型
boolean_column boolean,
--日付時刻
date_column date,
timestamp_column timestamp,
--バイナリー型
binary_column binary,
--複合型
struct_column struct<
struct_string_column :string,
struct_int_column :int
>,
array_column array<string>,
map_column map<string, int>
'''
spark.createDataFrame(sample_Data, schema).show()
spark.createDataFrame(sample_Data, schema).printSchema()
5. データフレームにおけるメタデータとデータを取得
Spark データフレームからカラム名等のメタデータを、次のメソッドを用いることで取得できる。2つのデータフレームを比較してその差分を変更するメソッドを開発する際などに利用。
DataFrame.schema.jsonValue()['fields']DataFrame.columnsDataFrame.dtypes
Scala のみで利用できる DDL 文字列を取得する場合には、次のように記載する。
json_data = df.schema.json()
ddl_string = spark.sparkContext._jvm.org.apache.spark.sql.types.DataType.fromJson(json_data).toDDL()
# サンプルデータフレームを作成
from pyspark.sql import Row
from decimal import *
import datetime
sample_Data = [
Row(
string_column='AAA',
byte_column=1,
integer_column=1,
bigint_column=1,
float_column=12.300000190734863,
double_column=12.3,
numeric_column=Decimal('12'),
boolean_column=True,
date_column=datetime.date(2020, 1, 1),
timestamp_column=datetime.datetime(2021, 1, 1, 0, 0),
binary_column=bytearray(b'A'),
struct_column=Row(struct_string_column='AAA', struct_int_column=1),
array_column=['AAA', 'BBB', 'CCC'],
map_column={'AAA': 1},
)
]
schema = '''
--文字型
string_column string,
--整数型
byte_column byte,
integer_column integer,
bigint_column bigint,
--浮動小数点型
float_column float,
double_column double,
numeric_column numeric,
--真偽型
boolean_column boolean,
--日付時刻
date_column date,
timestamp_column timestamp,
--バイナリー型
binary_column binary,
--複合型
struct_column struct<
struct_string_column :string,
struct_int_column :int
>,
array_column array<string>,
map_column map<string, int>
'''
df = spark.createDataFrame(sample_Data, schema)
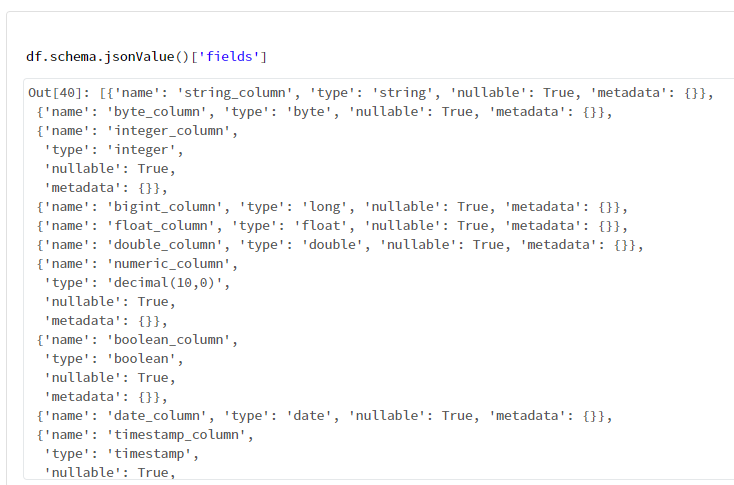
5-1. カラムの詳細情報を取得
df.schema.jsonValue()['fields']
5-2. カラム名のリストを取得
df.columns

5-3. カラム名とデータ型のタプルのリストを取得
df.dtypes

5-4. DDL 文字列の取得
json_data = df.schema.json()
ddl_string = spark.sparkContext._jvm.org.apache.spark.sql.types.DataType.fromJson(json_data).toDDL()
print(ddl_string)

5-5. データフレームの単一のデータを取得
collectメソッドを利用するため、事前にデータフレーム操作によりデータを絞ることが重要
# データを準備
import datetime
from pyspark.sql import Row
sample_Data = [
Row(
string_column='AAA',
bigint_column=1,
date_column=datetime.date(2020, 1, 1),
),
Row(
string_column='bbb',
bigint_column=2,
date_column=datetime.date(2020, 2, 2),
),
Row(
string_column='CCC',
bigint_column=3,
date_column=datetime.date(2020, 3, 3),
),
]
df = spark.createDataFrame(sample_Data)
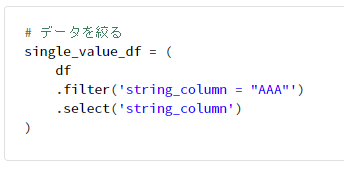
# データを絞る
single_value_df = (
df
.filter('string_column = "AAA"')
.select('string_column')
)
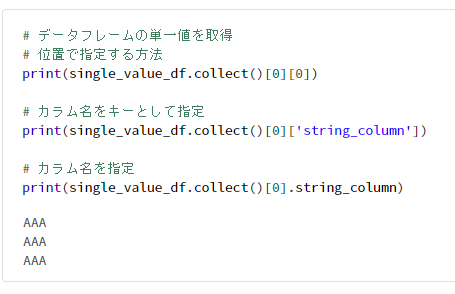
# データフレームの単一値を取得
# 位置で指定する方法
print(single_value_df.collect()[0][0])
# カラム名をキーとして指定
print(single_value_df.collect()[0]['string_column'])
# カラム名を指定
print(single_value_df.collect()[0].string_column)
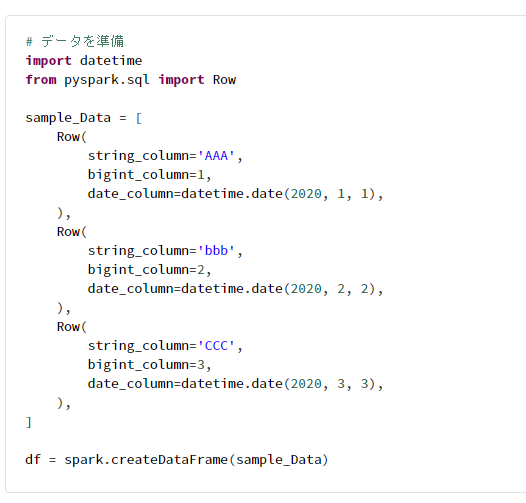
5-6. データフレームの複数のデータを取得
# データを準備
import datetime
from pyspark.sql import Row
sample_Data = [
Row(
string_column='AAA',
bigint_column=1,
date_column=datetime.date(2020, 1, 1),
),
Row(
string_column='bbb',
bigint_column=2,
date_column=datetime.date(2020, 2, 2),
),
Row(
string_column='CCC',
bigint_column=3,
date_column=datetime.date(2020, 3, 3),
),
]
df = spark.createDataFrame(sample_Data)
# データフレームの複数値を取得
# 位置で指定する方法
multi_values_df = (
df
.select('string_column')
)
df_values = []
for row_data in multi_values_df.collect():
df_values.append(row_data[0])
print(df_values)
# カラム名をキーとして指定
tgt_col = 'string_column'
df_values = []
for row_data in df.collect():
df_values.append(row_data[tgt_col])
print(df_values)

6. Spark SQL を PySpark で利用
PySparkでは主にpyspark.sql.functionsを利用するのですが、次のメソッドでは Spark SQL(Spark SQL, Built-in Functions)が利用可能。
- spark.sql
- selectExpr
- expr
次のメソッドでは、SQL とほぼ同じ記法が利用可能。
- filter
データフレームに別名(alias)を設定する際には次のメソッドを利用
- alias
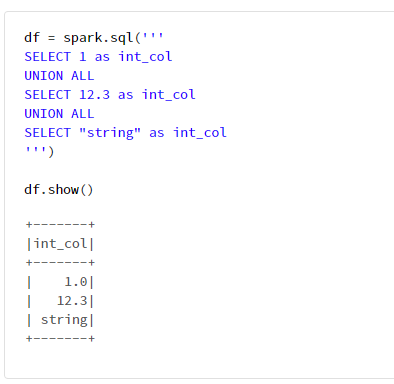
6-1. spark.sqlの利用例
df = spark.sql('''
SELECT 1 as int_col
UNION ALL
SELECT 12.3 as int_col
UNION ALL
SELECT "string" as int_col
''')
df.show()
6-2. selectExprの利用例
df.selectExpr('CAST(int_col as int) as int_col').show()

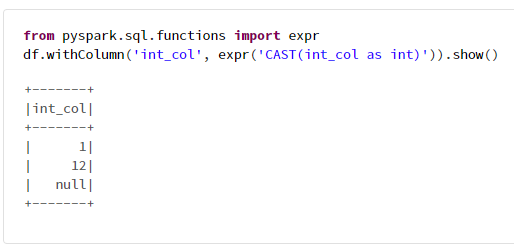
6-3. exprの利用例
from pyspark.sql.functions import expr
df.withColumn('int_col', expr('CAST(int_col as int)')).show()
6-4. filterの利用例
(
df
.filter('int_col = "string"')
.show()
)

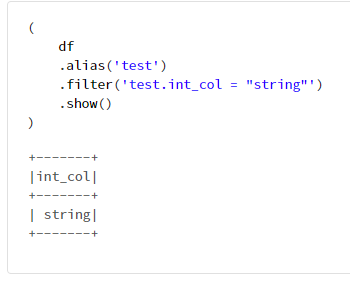
6-5. aliasの利用例
(
df
.alias('test')
.filter('test.int_col = "string"')
.show()
)
7. 制御フローによる PySpark 処理の実行
7-1. データフレームのデータ型を他のデータフレームに基づき変換
schema_01 = '''
str_col string,
int_col string,
date_col string
'''
schema_02 = '''
str_col string,
int_col integer,
date_col date
'''
schema_03 = '''
str_col string,
int_col integer
'''
data_01 = [
[
'abc',
'123',
'2020-01-01'
],
[
'def',
'456',
'2020-01-01'
],
]
df_1 = spark.createDataFrame(data_01,schema_01)
df_2 = spark.createDataFrame([],schema_02)
df_3 = spark.createDataFrame([],schema_03)

# `df_2`のデータ型に、`df_1`のデータ型を変更
df_2_schema = df_2.schema.jsonValue()['fields']
df_2_col_names_and_data_types = {}
for df_2_col in df_2_schema:
df_2_col_names_and_data_types[df_2_col['name']] = df_2_col['type']
print(df_2_col_names_and_data_types)

# 変換対象のデータフレームを準備
tgt_df = df_1
tgt_df.printSchema()
# `df_1`のスキーマと`df_2`のスキーマが異なるカラムのデータ型を変更
df_1_schema = df_1.schema.jsonValue()['fields']
for df_1_col in df_1_schema:
df_1_col_name = df_1_col['name']
df_1_col_type = df_1_col['type']
df_2_col_type = df_2_col_names_and_data_types.get(df_1_col_name, '')
if df_1_col_type != df_2_col_type:
if df_1_col_type == 'date':
tgt_df = tgt_df.withColumn(df_1_col_name, to_date(tgt_df[df_1_col_name], date_format))
else:
tgt_df = tgt_df.withColumn(df_1_col_name, tgt_df[df_1_col_name].cast(df_2_col_type))
tgt_df.printSchema()

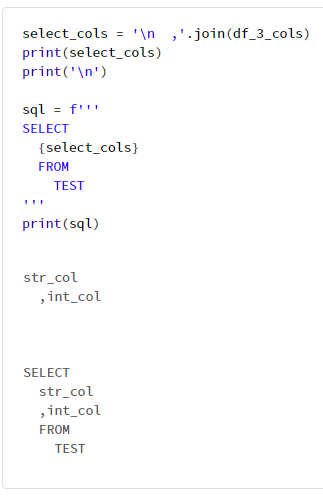
7-2. カラムのリストから SELECT 文の カラム名を生成
# `df_3`でのみ保持している2つのカラムを取得する SELECT 文を生成
df_3_cols = df_3.columns
print(df_3_cols)

select_cols = '\n ,'.join(df_3_cols)
print(select_cols)
print('\n')
sql = f'''
SELECT
{select_cols}
FROM
TEST
'''
print(sql)
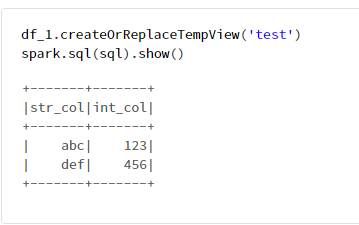
df_1.createOrReplaceTempView('test')
spark.sql(sql).show()