概要
Databricks ( Spark ) にて withColumn メソッドを用いて処理を共通化する際に、懸念事項を共有します。withColumn のドキュメントにて、ループ処理により複数回呼び出すとパフォーマンスの問題が起こる可能性がある旨の記載がありますが、数百のカラムを持つテーブルへの処理や数百のカラムへの処理を行う場合を除き、過度におそれる必要はなさそうです。なお、Spark には遅延評価(アクションによりデータ処理が行われること)という特徴があるため、withColumnをループ処理で記述した場合とwithColumnを複数回記述した場合で、基本的にはデータ処理自体の性能がかわらないようです。
withColumn のドキュメントにて、下記のような記載があります。記述内容から、数回の利用で性能に問題がでてしまう可能性があると解釈できます。
This method introduces a projection internally. Therefore, calling it multiple times, for instance, via loops in order to add multiple columns can generate big plans which can cause performance issues and even StackOverflowException. To avoid this, use select() with the multiple columns at once.
引用元:pyspark.sql.DataFrame.withColumn — PySpark 3.3.1 documentation (apache.org)
このメソッドは、プロジェクションを内部的に導入します。 したがって、たとえば、複数の列を追加するためにループを介して複数回呼び出すと、パフォーマンスの問題や StackOverflowException を引き起こす可能性のある大きなプランが生成される可能性があります。 これを回避するには、select() を複数の列で一度に使用します。
上記の翻訳
Spark クエリプランを確認することで実際の懸念事項を確認できるそうで、withColumn メソッドによるループ処理のクエリプランを確認するコードを実行してみました。最初のロジカルプラン(Parsed Logical Plan)にて、ループ処理数分のネストを確認できます。
# Command took 0.70 seconds
from pyspark.sql.functions import expr
data = [
{
"1": "1",
"2": "1",
"3": "1",
"4": "1",
"5": "1",
"6": "1",
"7": "1",
"8": "1",
"9": "1",
"10": "1",
}
]
df = spark.createDataFrame(data)
with_conds = {}
for tgt_col in df.columns:
df = df.withColumn(tgt_col, expr(f"CAST({tgt_col} AS int)"))
df.display()
df.explain(extended=True)
== Parsed Logical Plan ==
Project [1#8461067, 10#8461078, 2#8461089, 3#8461100, 4#8461111, 5#8461122, 6#8461133, 7#8461144, 8#8461155, cast(9 as int) AS 9#8461166]
+- Project [1#8461067, 10#8461078, 2#8461089, 3#8461100, 4#8461111, 5#8461122, 6#8461133, 7#8461144, cast(8 as int) AS 8#8461155, 9#8461056]
+- Project [1#8461067, 10#8461078, 2#8461089, 3#8461100, 4#8461111, 5#8461122, 6#8461133, cast(7 as int) AS 7#8461144, 8#8461055, 9#8461056]
+- Project [1#8461067, 10#8461078, 2#8461089, 3#8461100, 4#8461111, 5#8461122, cast(6 as int) AS 6#8461133, 7#8461054, 8#8461055, 9#8461056]
+- Project [1#8461067, 10#8461078, 2#8461089, 3#8461100, 4#8461111, cast(5 as int) AS 5#8461122, 6#8461053, 7#8461054, 8#8461055, 9#8461056]
+- Project [1#8461067, 10#8461078, 2#8461089, 3#8461100, cast(4 as int) AS 4#8461111, 5#8461052, 6#8461053, 7#8461054, 8#8461055, 9#8461056]
+- Project [1#8461067, 10#8461078, 2#8461089, cast(3 as int) AS 3#8461100, 4#8461051, 5#8461052, 6#8461053, 7#8461054, 8#8461055, 9#8461056]
+- Project [1#8461067, 10#8461078, cast(2 as int) AS 2#8461089, 3#8461050, 4#8461051, 5#8461052, 6#8461053, 7#8461054, 8#8461055, 9#8461056]
+- Project [1#8461067, cast(10 as int) AS 10#8461078, 2#8461049, 3#8461050, 4#8461051, 5#8461052, 6#8461053, 7#8461054, 8#8461055, 9#8461056]
+- Project [cast(1 as int) AS 1#8461067, 10#8461048, 2#8461049, 3#8461050, 4#8461051, 5#8461052, 6#8461053, 7#8461054, 8#8461055, 9#8461056]
+- LogicalRDD [1#8461047, 10#8461048, 2#8461049, 3#8461050, 4#8461051, 5#8461052, 6#8461053, 7#8461054, 8#8461055, 9#8461056], false

Spark ではクエリプランの最適化が行われるため、上記の処理がそのまま行われるのではなく、最終的に下記のようなシンプルなクエリプランとなります。 withColumn メソッドをループ処理で用いる場合には、クエリプランの最適化に時間がかかる事象、あるいは、最適化を実施できないというエラーとなる事象が発生するようです。
== Physical Plan ==
*(1) Project [1 AS 1#8461067, 10 AS 10#8461078, 2 AS 2#8461089, 3 AS 3#8461100, 4 AS 4#8461111, 5 AS 5#8461122, 6 AS 6#8461133, 7 AS 7#8461144, 8 AS 8#8461155, 9 AS 9#8461166]
+- *(1) Scan ExistingRDD[1#8461047,10#8461048,2#8461049,3#8461050,4#8461051,5#8461052,6#8461053,7#8461054,8#8461055,9#8461056]

100回のループ処理、および、500回のループ処理を実行したところ、前者の処理時間が1.30秒であり、後者の処理時間が28.93秒でした。個人的には、500カラムをループで処理することはあまり多くないため、許容できる時間内で処理が完了しているという印象を持ちました。ただし、1000 回のループ処理を超える場合には、想定外の実行となる場合がありました。
# Command took 1.30 seconds
loop_num = 100
data = [
{
"a": "1",
}
]
df = spark.createDataFrame(data)
for i in range(0, loop_num):
df = df.withColumn(f"col_{i}", lit(0).cast("int"))
df.count()
# Command took 28.93 seconds
loop_num = 500
data = [
{
"a": "1",
}
]
df = spark.createDataFrame(data)
for i in range(0, loop_num):
df = df.withColumn(f"col_{i}", lit(0).cast("int"))
df.count()
withColumnは、既存カラムの更新(例:データ型の変更)を行う際によく使うことがあり、性能の限界を考慮しつつ、利用方法を模索する方針がよさそうです。既存カラムの更新を、selectメソッドにより、既存のカラムを考慮することなく処理を行う方法を確立できませんでした。withColumnメソッドであれば、更新対象のカラム名を指定するだけで既存カラムの更新ができます。

引用元:PySpark withColumn() Usage with Examples - Spark by {Examples} (github.com)
Spark のバージョンが 3.3 以降であれば、withColumnsメソッドを利用することで、パフォーマンスへの影響が小さくなりそうです。

引用元:pyspark.sql.DataFrame.withColumns — PySpark 3.3.1 documentation (apache.org)
withColumnsメソッドによるクエリプランを確認したところ、Parsed Logical Planの時点でシンプルのものとなっていることを確認できました。
# Command took 0.40 seconds
from pyspark.sql.functions import lit
data = [
{
"1": "1",
"2": "1",
"3": "1",
"4": "1",
"5": "1",
"6": "1",
"7": "1",
"8": "1",
"9": "1",
"10": "1",
}
]
df = spark.createDataFrame(data)
col_conds = {}
for tgt_col in df.columns:
col_conds[tgt_col] = df[tgt_col].cast('int').alias()
df = df.withColumns(col_conds)
df.display()
df.explain(extended=True)

検証
1. クエリプランの比較
1-1. withColumn メソッドを1回実行するコードの検証
# Command took 1.20 seconds
from pyspark.sql.functions import expr
data = [
{
"1": "1",
"2": "1",
"3": "1",
"4": "1",
"5": "1",
"6": "1",
"7": "1",
"8": "1",
"9": "1",
"10": "1",
}
]
df = spark.createDataFrame(data)
tgt_col = '1'
for i in range(0, 100):
df = df.withColumn(tgt_col, expr(f"CAST({tgt_col} AS int)"))
df.display()
df.explain(extended=True)

1-2. withColumn メソッドを100回実行するコードの検証
# Command took 1.20 seconds
from pyspark.sql.functions import expr
data = [
{
"1": "1",
"2": "1",
"3": "1",
"4": "1",
"5": "1",
"6": "1",
"7": "1",
"8": "1",
"9": "1",
"10": "1",
}
]
df = spark.createDataFrame(data)
tgt_col = '1'
for i in range(0, 100):
df = df.withColumn(tgt_col, expr(f"CAST({tgt_col} AS int)"))
df.display()
df.explain(extended=True)

1-3. withColumn メソッドを500回実行するコードの実行
# Command took 6.41 seconds
from pyspark.sql.functions import expr
data = [
{
"1": "1",
"2": "1",
"3": "1",
"4": "1",
"5": "1",
"6": "1",
"7": "1",
"8": "1",
"9": "1",
"10": "1",
}
]
df = spark.createDataFrame(data)
tgt_col = '1'
for i in range(0, 500):
df = df.withColumn(tgt_col, expr(f"CAST({tgt_col} AS int)"))
df.display()
df.explain(extended=True)

1-4. selectメソッドにて実行するコードの検証
# Command took 0.40 seconds
from pyspark.sql.functions import lit
data = [
{
"1": "1",
"2": "1",
"3": "1",
"4": "1",
"5": "1",
"6": "1",
"7": "1",
"8": "1",
"9": "1",
"10": "1",
}
]
df = spark.createDataFrame(data)
col_conds = []
for tgt_col in df.columns:
col_conds.append(df[tgt_col].cast('int').alias(tgt_col))
df = df.select(*col_conds)
df.display()
df.explain(extended=True)

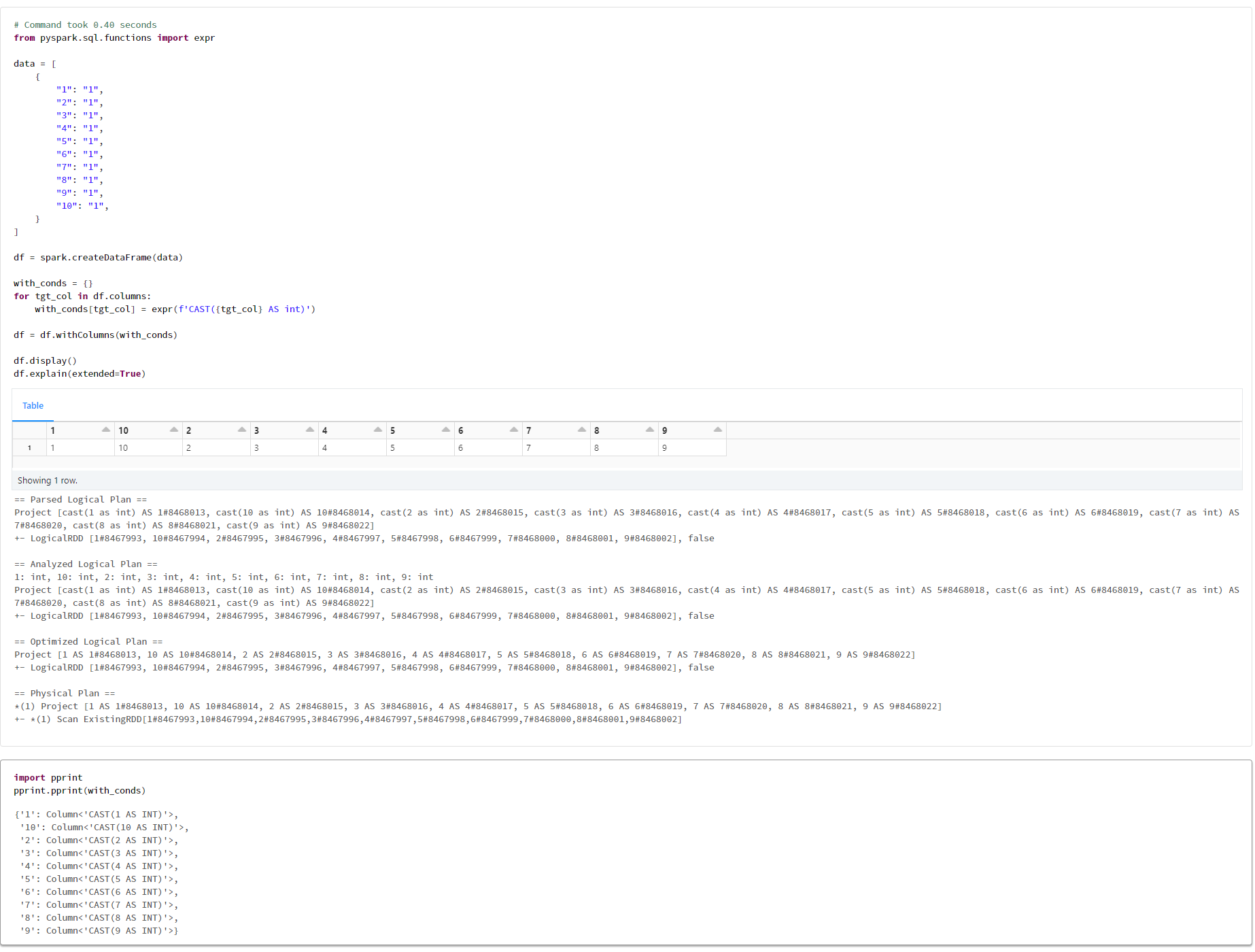
1-5. withColumnsメソッドにて実行するコードの検証
# Command took 0.40 seconds
from pyspark.sql.functions import expr
data = [
{
"1": "1",
"2": "1",
"3": "1",
"4": "1",
"5": "1",
"6": "1",
"7": "1",
"8": "1",
"9": "1",
"10": "1",
}
]
df = spark.createDataFrame(data)
with_conds = {}
for tgt_col in df.columns:
with_conds[tgt_col] = expr(f'CAST({tgt_col} AS int)')
df = df.withColumns(with_conds)
df.display()
df.explain(extended=True)
2. 実行時間の比較
2-1. withColumn メソッドを1回実行するコードの検証
from pyspark.sql.functions import lit
# Command took 0.30 seconds
loop_num = 1
data = [
{
"a": "1",
}
]
df = spark.createDataFrame(data)
for i in range(0, loop_num):
df = df.withColumn(f"col_{i}", lit(0).cast("int"))
df.count()
df.explain(extended=True)

2-2. withColumn メソッドを100回実行するコードの検証
# Command took 1.30 seconds
loop_num = 100
data = [
{
"a": "1",
}
]
df = spark.createDataFrame(data)
for i in range(0, loop_num):
df = df.withColumn(f"col_{i}", lit(0).cast("int"))
df.count()
df.explain(extended=True)

2-3. withColumn メソッドを500回実行するコードの検証
# Command took 28.93 seconds
loop_num = 500
data = [
{
"a": "1",
}
]
df = spark.createDataFrame(data)
for i in range(0, loop_num):
df = df.withColumn(f"col_{i}", lit(0).cast("int"))
df.count()
df.explain(extended=True)

2-4. withColumn メソッドを1000回実行するコードの検証
# Command took 3.03 minutes
loop_num = 1000
data = [
{
"a": "1",
}
]
df = spark.createDataFrame(data)
for i in range(0, loop_num):
df = df.withColumn(f"col_{i}", lit(0).cast("int"))
df.count()
df.explain(extended=True)

2-5. withColumns メソッドを実行するコードの検証
# Command took 6.41 seconds
loop_num = 1000
data = [
{
"a": "1",
}
]
df = spark.createDataFrame(data)
with_conds = {}
for i in range(0, loop_num):
with_conds[f"col_{i}"] = lit(0).cast("int")
df = df.withColumns(with_conds)
df.count()
df.explain(extended=True)

3. 一定のレコード数をもつデータフレームでの検証
3-1. withColumn メソッドを実行しないコードの検証
# Command took 40.84 seconds
filepath = "dbfs:/databricks-datasets/tpch/data-001/lineitem/lineitem.tbl"
schema = """
L_ORDERKEY INTEGER ,
L_PARTKEY INTEGER ,
L_SUPPKEY INTEGER ,
L_LINENUMBER INTEGER ,
L_QUANTITY DECIMAL(15,2) ,
L_EXTENDEDPRICE DECIMAL(15,2) ,
L_DISCOUNT DECIMAL(15,2) ,
L_TAX DECIMAL(15,2) ,
L_RETURNFLAG STRING ,
L_LINESTATUS STRING ,
L_SHIPDATE DATE ,
L_COMMITDATE DATE ,
L_RECEIPTDATE DATE ,
L_SHIPINSTRUCT STRING ,
L_SHIPMODE STRING ,
L_COMMENT STRING
"""
df = (spark
.read
.format("csv")
.schema(schema)
.option("sep", "|")
.load(filepath)
)
df.count()

3-2. withColumn メソッドを500回実行するコードの検証
# Command took 1.12 minutes
loop_num = 500
filepath = "dbfs:/databricks-datasets/tpch/data-001/lineitem/lineitem.tbl"
schema = """
L_ORDERKEY INTEGER ,
L_PARTKEY INTEGER ,
L_SUPPKEY INTEGER ,
L_LINENUMBER INTEGER ,
L_QUANTITY DECIMAL(15,2) ,
L_EXTENDEDPRICE DECIMAL(15,2) ,
L_DISCOUNT DECIMAL(15,2) ,
L_TAX DECIMAL(15,2) ,
L_RETURNFLAG STRING ,
L_LINESTATUS STRING ,
L_SHIPDATE DATE ,
L_COMMITDATE DATE ,
L_RECEIPTDATE DATE ,
L_SHIPINSTRUCT STRING ,
L_SHIPMODE STRING ,
L_COMMENT STRING
"""
df = (spark
.read
.format("csv")
.schema(schema)
.option("sep", "|")
.load(filepath)
)
for i in range(0, loop_num):
df = df.withColumn(f"col_{i}", lit(0).cast("int"))
df.count()

3-3. withColumn メソッドを1000回実行するコードの検証
# Command took 39.64 seconds
loop_num = 500
filepath = "dbfs:/databricks-datasets/tpch/data-001/lineitem/lineitem.tbl"
schema = """
L_ORDERKEY INTEGER ,
L_PARTKEY INTEGER ,
L_SUPPKEY INTEGER ,
L_LINENUMBER INTEGER ,
L_QUANTITY DECIMAL(15,2) ,
L_EXTENDEDPRICE DECIMAL(15,2) ,
L_DISCOUNT DECIMAL(15,2) ,
L_TAX DECIMAL(15,2) ,
L_RETURNFLAG STRING ,
L_LINESTATUS STRING ,
L_SHIPDATE DATE ,
L_COMMITDATE DATE ,
L_RECEIPTDATE DATE ,
L_SHIPINSTRUCT STRING ,
L_SHIPMODE STRING ,
L_COMMENT STRING
"""
df = (spark
.read
.format("csv")
.schema(schema)
.option("sep", "|")
.load(filepath)
)
with_conds = {}
for i in range(0, loop_num):
with_conds[f"col_{i}"] = lit(0).cast("int")
df = df.withColumns(with_conds)
df.count()
