更新情報
下記の記事にて同じような内容を投稿してありますので、参考にしてください。
概要
Databricks にて CAST できない場合にゼロに置換する Python関数を共有します。
from pyspark.sql.functions import expr
def replace_col_value_to_zero_when_cast_error(
tgt_df,
tgt_col_info,
value_after_replacement = "'0'",
):
for tgt_col, tgt_data_type in tgt_col_info.items():
case_state = f"""
CASE WHEN ISNULL(TRY_CAST({tgt_col} AS {tgt_data_type})) is false
THEN {tgt_col}
ELSE {value_after_replacement}
END
"""
tgt_df = tgt_df.withColumn(tgt_col, expr(case_state))
return tgt_df
Spark 3.3 以降であれば、下記の関数を利用してください。
from pyspark.sql.functions import expr
def replace_col_value_to_zero_when_cast_error(
tgt_df,
tgt_col_info,
value_after_replacement = "'0'",
):
with_conds = {}
for tgt_col, tgt_data_type in tgt_col_info.items():
case_state = f"""
CASE WHEN ISNULL(TRY_CAST({tgt_col} AS {tgt_data_type})) is false
THEN {tgt_col}
ELSE {value_after_replacement}
END
"""
with_conds[tgt_col] = expr(case_state)
tgt_df = tgt_df.withColumns(with_conds)
return tgt_df
ポイントは下記です。
-
tgt_col_infoではカラム名と想定のデータ型の辞書型変数を引数としてください。データ型にてnumericやdecimalを指定する場合には、有効桁数を多い設定(例:decimal(38,10))にしてください。 -
value_after_replacementにて、'0'となっているのは、ソースのデータフレームのカラムが文字列であることが前提であるためです。
今回の記事を記載する起因となったのは、オラクル Pro*C で利用されているatof関数と同等機能の実装が必要となったことです。atof関数では、変換できない場合には 0 に変換するという私が開発してきたデータベース(SQL Server 等)とは異なる動作( CAST できない場合にはエラーとなる動作)をします。

引用:atof - man pages section 3: Basic Library Functions (oracle.com)
Databricks(Spark) では、デフォルトでは変換できない場合には NULL に変換します。これも私が開発してきたデータベースとは異なる動きです。
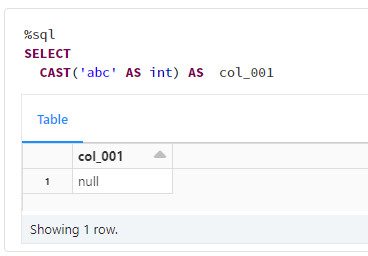
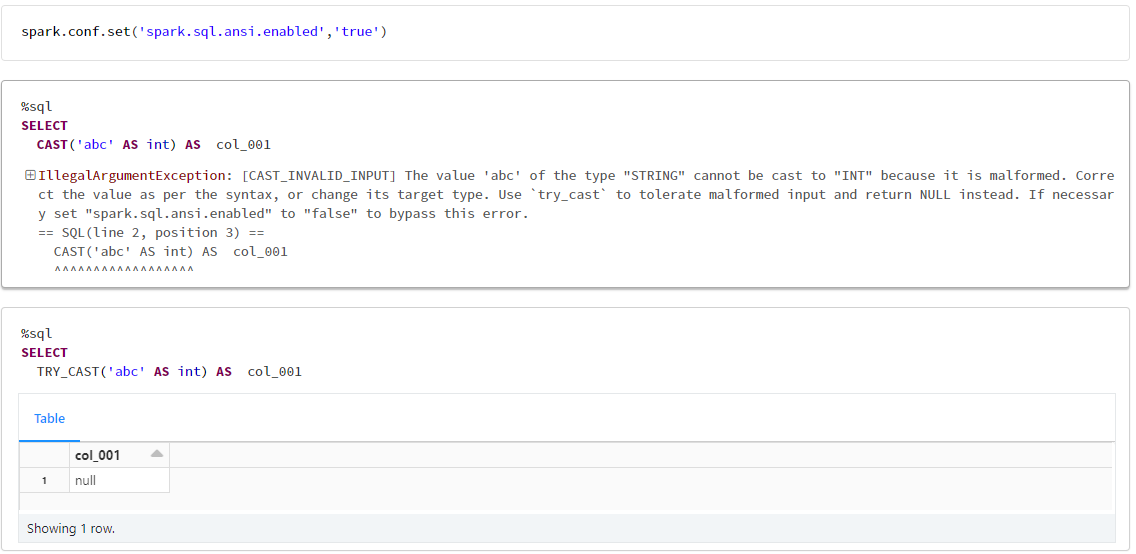
Databricks(Spark) でも、spark.sql.ansi.enabledプロパティをtrueにすると、エラーとなります。TRY_CASTという関数を利用すれば NULL に置換することもできます。
動作確認
1. 関数を定義
from pyspark.sql.functions import expr
def replace_col_value_to_zero_when_cast_error(
tgt_df,
tgt_col_info,
value_after_replacement = "'0'",
):
for tgt_col, tgt_data_type in tgt_col_info.items():
case_state = f"""
CASE WHEN ISNULL(TRY_CAST({tgt_col} AS {tgt_data_type})) is false
THEN {tgt_col}
ELSE {value_after_replacement}
END
"""
tgt_df = tgt_df.withColumn(tgt_col, expr(case_state))
return tgt_df
Spark 3.3 以降の場合
from pyspark.sql.functions import expr
def replace_col_value_to_zero_when_cast_error(
tgt_df,
tgt_col_info,
value_after_replacement = "'0'",
):
with_conds = {}
for tgt_col, tgt_data_type in tgt_col_info.items():
case_state = f"""
CASE WHEN ISNULL(TRY_CAST({tgt_col} AS {tgt_data_type})) is false
THEN {tgt_col}
ELSE {value_after_replacement}
END
"""
with_conds[tgt_col] = expr(case_state)
tgt_df = tgt_df.withColumns(with_conds)
return tgt_df
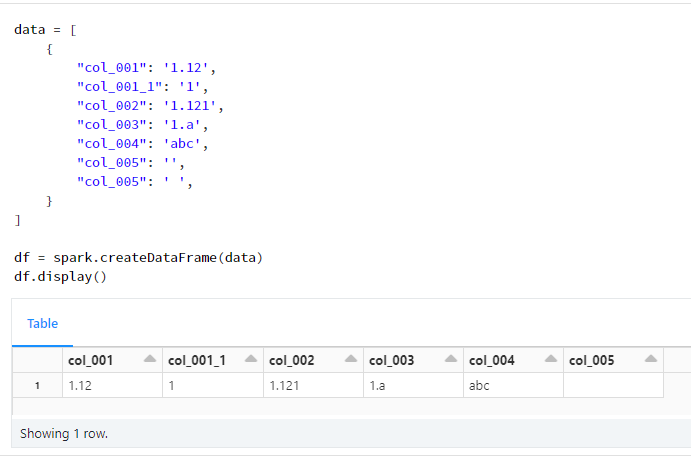
2. データフレームを作成
data = [
{
"col_001": '1.12',
"col_002": '1.121',
"col_003": '1.a',
"col_004": 'abc',
"col_005": '',
"col_005": ' ',
}
]
df = spark.createDataFrame(data)
df.display()
3. 関数の利用
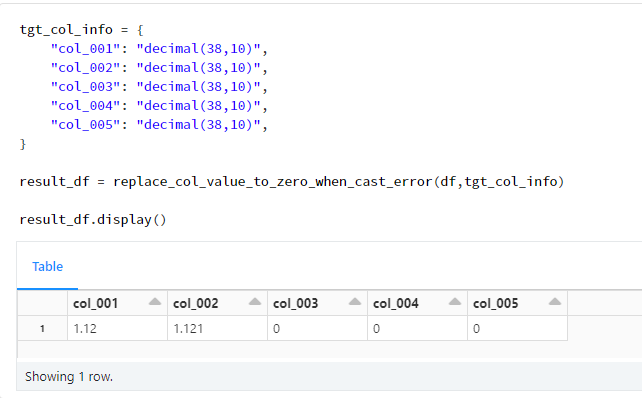
置換できない値をもつcol_003、col_004、及び、col_005が0となっていること確認
tgt_col_info = {
"col_001": "decimal(38,10)",
"col_002": "decimal(38,10)",
"col_003": "decimal(38,10)",
"col_004": "decimal(38,10)",
"col_005": "decimal(38,10)",
}
result_df = replace_col_value_to_zero_when_cast_error(df,tgt_col_info)
result_df.display()