
こんにちは。LiNKX株式会社のitoです。
異常検知について、その考え方や手法を調べ整理しました。特に参考文献[1]を参考にさせていただきました。ここでは、自分なりの解釈や理解も含めてまとめたいと思います。
このブログは、会社の考え方ではなく私個人の解釈です。もし、私の思い込みで間違った解釈や記述がありましたら、ご指摘いただけると幸いです。
今回は、以下のシリーズでまとめようと考えており、このブログは異常検知(1)の内容となっています。
- 異常検知(1)確率分布による基本の異常検知 <----- このブログ
- 異常検知(2)ガウス分布を仮定する異常検知、ホテリングのT2法
- 異常検知(3)データがガウス分布から外れていても使える、k近傍法
- 異常検知(4)時系列信号の変化の検知、特異スペクトル変換法など
- 異常検知アルゴリズムの評価方法 ROCAUC を分かりやすく説明
- 深層異常検知(1)Gaussian-AD; 学習時間ほぼなしの高性能異常検知アルゴリズム
1. 異常検知のパターン
はじめに、異常検知のパターンを整理して、本ブログのシリーズで対象とするパターンを明確にしたいと思います。
まず、異常検知器を作る前提として、使用できるデータの違いで2つのパターンが考えらます。
- 正常と異常のデータがある
- 正常のデータのみある
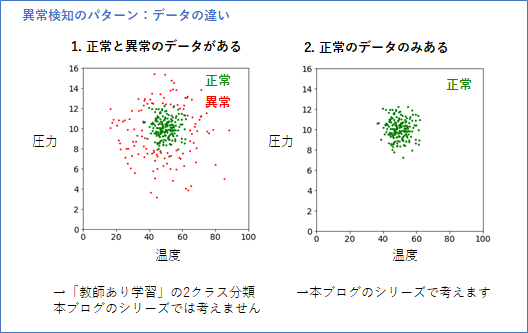
機械学習の立場から考えると、1.の場合は、観測したデータに正常と異常のラベルある「教師あり学習」の「2クラス分類」の問題に落とし込めることができます。ただし、異常のデータが正常のデータに比べて少ない場合がほとんどになると思いますので、そのバランスを考慮する工夫が必要になるでしょう。
一方、2. の場合はラベルがないので「教師なし学習」の枠組みになりますが、「異常検知」は、「教師なし学習」で扱われている「クラスター解析」でもなく「次元圧縮」の問題でもなく、「異常検知」でしかありません。よって、この記事は、この2の場合に焦点を当てて考えていきたいと思います。
もう一つ、検出に必要な観測の数で以下の2パターンが考えられます。
- 1回の観測で異常がわかる
- 複数の観測で初めて異常がわかる
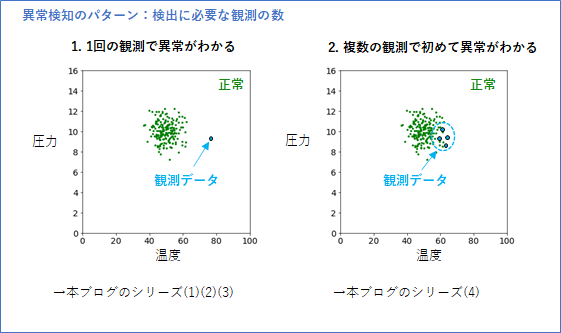
1.の場合は、分布と点を比べる問題となり、本記事(1)を含めて次回(2)と(3)で扱います。2.は、2つの分布を比べる問題となり、最後の(4)の時系列データの変化検知に応用します。
最後にもう一つ、扱うデータが時系列データかそうでないかというパターンがあります。
- 時系列データ
- 時系列でないデータ
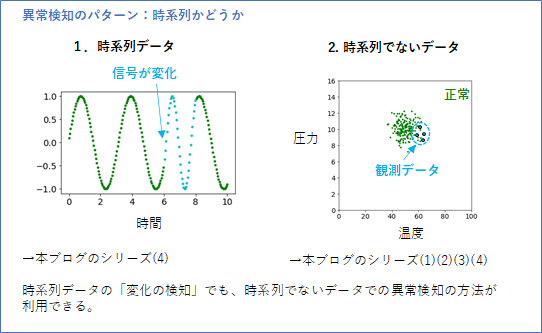
「時系列データ」の異常検知は、「時系列でないデータ」の異常検知の問題に変換して、そこでの方法を使う場合も多いようです。そこで、本記事では基本「時系列でないデータ」での方法を扱い、(4)の記事では、時系列データの変化検知を「時系列でないデータ」の問題に変換する方針で考えます。
2. なぜ異常検知の理論が必要なのか
では、異常のデータがない場合の異常検知を考えていきますが、そもそも、「異常検知って理論とかいるの?」「閾値処理じゃだめなの?」と思われる方もいるかもしれません。正直私もそう思っていました。まずそこから考えていきたいと思います。
例えば、生産したネジの不良品を「重さ」でチェックすることを考えます。
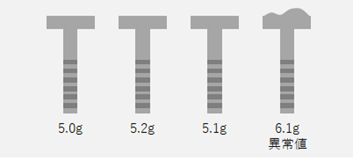
この場合は、あらかじめ正常値の範囲として「上限の閾値」と「下限の閾値」を決めておき、その範囲外となるネジがあったら異常値とし不良品とみなせばよいでしょう。上限と下限の2つの閾値さえ決めれば、この処理は簡単です。
しかし次の場合はどうでしょうか。
下のようなボイラーを考えます。水を温めて、その温水をパイプに通して床暖房をする温水暖房用ボイラーをイメージしましょう。
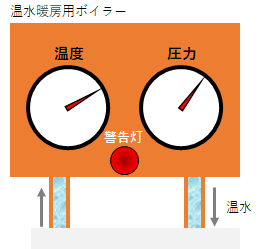
ボイラーのパネルには、「温度」と「圧力」の二つのメーターがあります。この二つのメーターをモニターして、異常が発生したら警告を出す機能を付けるという問題です。
正常時の温度と圧力のデータを集めてプロットしたら、下図のようになったとします。
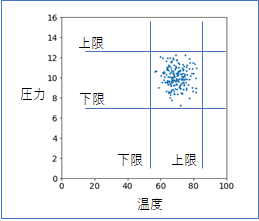
この場合も難しくはありません。温度と圧力に対して、それぞれ、上限と下限の閾値を設定すればいいだけです。そして、観測値が閾値を超えたら異常値とみなし、警告を出せばよいですね。この場合は4つ閾値を決めることになります。
しかし、さらに、「弱」と「強」の運転モードというものがあって、それぞれでデータ分布が異なるような場合はどうでしょうか。「弱」モードのデータ分布をオレンジで、「強」モードのデータを青で表しました(下図)。この場合、「弱」と「強」のモードに対して、それぞれ上限下限の閾値を決めればよいのですが、合計8つも閾値を決めなくてはいけません。こうなるとかなり面倒になってきます。
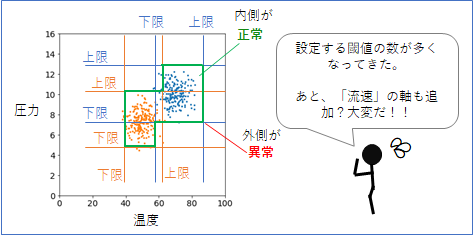
これはある意味、8つの縦線と横線によって、正常と異常の境界線を作る作業でもあります(緑の線)。そう考えると、分布の形によっては、なめらかな曲線で囲む方がよい場合もあるでしょう。しかし、この閾値の作戦では、縦線と横線でしか境界線を作れないという制限もあります。
さらに、「温度」、「圧力」以外にもモニターが必要な数値「流速」などがあったら、どうでしょうか。閾値の数はさらに倍の16個になります。こうなると、もう手動で上限下限を決めていくのはとても手間がかかりますし、場合によっては人手では無理になってきます。
このような時にこそ役に立つのが、「異常検知」の理論・技術なのです。さらに、時間的な信号の変化をとらえる、「変化検知」という手法もあります。
3. 異常検知の方針
異常検知・変化検知ではいろいろな方法が提案されていますが[1]、どの方法も基本的には、モニターしている観測値から「異常度」というものを計算し、その値が閾値を超えたら異常とみなすという方針となっています。
異常度は、「普段観測している観測値からはずれればずれるほど高くなる値」、と考えます。
ボイラーの例で考えると、データ分布から離れた位置ほど異常値は高くなるので、下の図のような、等高線で表すことができると思います。その形は、お椀の底を真上から見ているような地形になるでしょう。データが分布しているあたりの異常値が最も低く、そこから外側に行くにつれて高くなっていきます。
ここで、異常値を判定する閾値を、例えば、1.0と決めれば、黒の実線が正常と異常を分ける境界線となります。
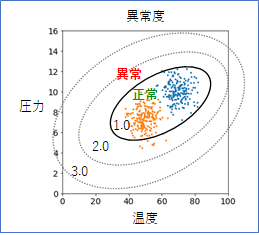
この境界線は、先ほどの8つの閾値で決めた「正常と異常の境界線」を作ることに対応します(境界線の形は違いますが)。このように、「異常度」があれば、観測の種類が何個あっても、観測地のデータ分布が複雑でも、異常度の閾値を一つ決めるだけで、異常と正常の境界線を引くことができるのです。
異常度の考え方、便利そうです。
4. 理想の異常値の作り方
それでは、「理想」の異常値の作り方を説明します。
まず、観測値を${\textbf x}$で表します。観測値は一般的にはベクトルです。各要素が、温度や圧力などの種類別の値を表します。
{\textbf x}=
\begin{bmatrix}
温度 \\
圧力 \\
\vdots
\end{bmatrix}
=
\begin{bmatrix}
x_1 \\
x_2 \\
\vdots
\end{bmatrix}
次に、「正常」の場合の${\textbf x}$の分布を考えていきます。まず簡単のため、ボイラーの例で、観測は温度だけとします。${\textbf x}$は一次元なので$x$とします(ベクトルは太字、単一の数値は細字で表す流儀です)。$x$の分布は、以下のようなグラフで表すことができます(「強」のモードだけ考えています)。
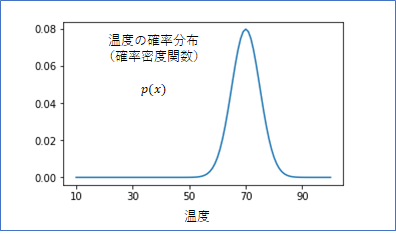
これは、「確率密度関数」と呼ばれる$x$のとりうる確率を表す関数です。確率密度関数は、とりうる$x$の範囲で積分すると1になる性質があります。この「確率密度関数」という言い方は長くて仰々しいので、以降、簡単に「確率分布」と言うことにします。
温度のデータは、$70$を中心にばらついていますので、$x=70$ 付近となる確率が最も高いということになります。よって、確率分布の値もそこがピークとなります。確率分布は一般的に、
p(x)
と表します。
ここで、「確率分布$p(x)$がわかっている」ことを前提に、異常値を考えていきたいと思います。
ちなみにこの「確率分布$p(x)$がわかっている」という前提が、初めに「理想」と強調した理由です。
実際には真の確率分布$p(x)$はわからないことが普通なので、これをどう推定するか、近似するか、計算を楽にするかがいろいろな異常検知手法のバリエーションとなってきますが、ここでの考え方が多くの手法の考え方の基本となります。結局のところ異常検知の真髄は「いかに$p(x)$を見出すか」ということに尽きるのではないかと思います。
さて、確率分布$p(x)$がわかっていれば、異常度$a(x)$を作るのは簡単です。
異常な値とは、確率で考えると、「めったに起きない値」、つまり、「確率が低い値」です。つまり、確率が低いほど高くなる値を、異常値と決めればよいのです。例えば、以下のように確率の逆数で異常度を定義すれば、その要件を満たします。
a(x) = \frac{1}{p(x)}
ただし、この定義だと確率がとても小さいとき$a(x)$がとても大きな値となってしまいます。これだと、数式的にもプログラム的にも扱いにくくなります。そこで、対数をとった数値を異常度とします(後々の計算も楽になるというメリットもあります)。
a(x)=\log \Bigl(\frac{1}{p(x)} \Bigr)
logの公式を思い出せば、以下のようにスマートな形に変形できます。
a(x)=-\log p(x)
これは、多次元の観測${\textbf x}$でも同じですので、最終的な異常値の定義式は以下のものとします。
a(x)=-\log p({\textbf x})
これで異常値を作ることができました。一見落着です。
それにしても、これでは少しあっけない感じがしますね。次でグラフを描いて、実感してみたいと思います。
5. データが1次元と2次元のときの異常度のグラフ
まず、温度の分布$p(x)$に対する異常度 $a(x)=-\log p(x)$のグラフを書いてみました(下の図の下段)。
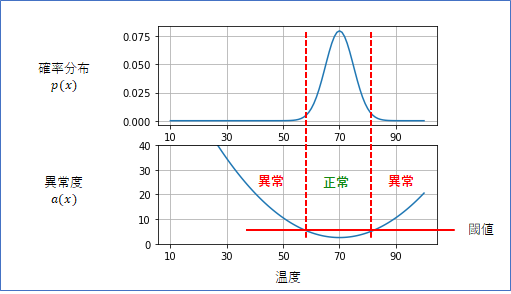
異常度$a(x)$に閾値を決めると、それよりも異常度が低い領域が「正常」の範囲となり、異常度が閾値よりも高い範囲が「異常」の範囲となるということです。この1次元$x$の場合は、閾値を1つ決めると、上限と下限の2つが決まるので少し得ですね。
では次に、観測値$x$を(温度、圧力)の2次元ベクトル${\textbf x}$ににもどした異常値$a({\textbf x})$を考えます。今度は、二つの「弱」と「強」モードのデータも混在している場合を考えます(下の図(1))。
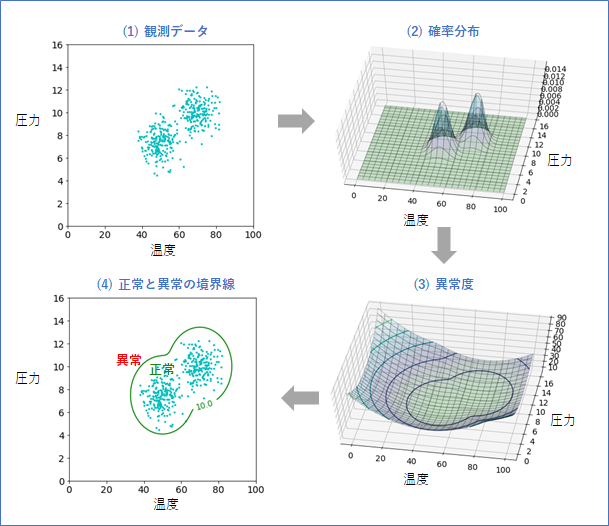
この場合の確率分布を3次元のグラフで表すことができます(2)。
ここから、異常値 $a({\textbf x})=-\log p({\textbf x})$を求めて、3次元のグラフで表したものが(3)です。等高線も描いています。想定通りに、分布のある個所で一番小さく、そこから離れるにつれ、大きい値をとなっています。
閾値を10として、正常と異常の境界線を書いたものが(4)になります。いい感じに、データが分布している領域を曲線で囲えていることがわかります。閾値8個で頑張ったときと比べて、かなり楽に見通しもよくなりました。
6. さいごに
今回の内容は以上です。お読みいただきありがとうざいました。
今回は$p({\textbf x})$を知っていると仮定した場合の理想の方法でしたが、次回からは、真の$p({\textbf x})$がわからない場合でも使える方法を紹介していきたいと思います。
次は、異常検知(2)ガウス分布を仮定する異常検知、ホテリングのT2法
参考文献
[1] 井出・杉山著「異常検知と変化検知」機械学習プロフェッショナルシリーズ(講談社)