はじめに
今回は会社のイベントで Advent Calendar に参加しての記事になります。
初参加なので、まずは 1 つ記事(「Flutter API 通信で Qiita の記事を GET !」)を書いて Advent Calendar に参加してみる予定でしたが、会社から 2 つ目、 3 つ目と Advent Calendar が追加されたので、2 つ目の記事を投稿させて頂きます!
※去年は 2 つの Advent Calendar で、今年は 3 つです。来年は 4 つなのか!?
今回は、「 Amazon Athena 」を利用したログ整理です。
以前は 「 Google Cloud Big Query 」を利用してログ整理を行ったのですが、諸事情により利用できなかったため「 Amazon Athena 」を利用して、大量ログを整理します。
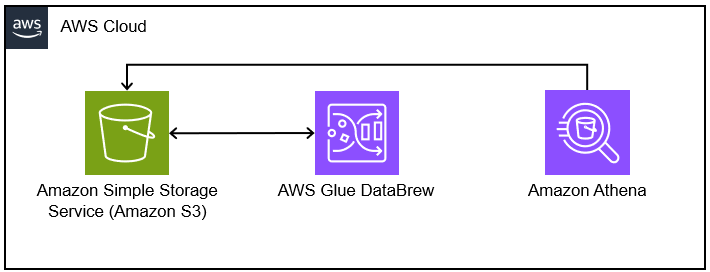
ざっくり手順
- ログ (CSV) ファイル
- Amazon S3 にバケット&フォルダ作成
- AWS Glue DataBrew でログを編集
- Amazon Athena で AWS Glue からテーブルを作成
- Amazon Athena で クエリを利用してログを整理
イメージ
ログ (CSV) ファイル
今回のログファイルは CSV (カンマ区切り)で、下記の項目のため、CONTENT 項目を編集して Amazon Athena へ渡す必要があります。
ログファイル項目
- DATE : 処理日時(ミリ秒まで)
- HOST : 処理ホスト名
- SERVICE : サービスレイヤー
- CONTENT : ログ詳細
-
A項目:AAA, B項目:BBB, C項目:CCC- B項目はキー項目で他のログと結合する
-
| DATE | HOST | SERVICE | CONTENT |
|---|---|---|---|
| yyyy-mm-dd HH:MM:SS.sss | abc-host | abc-service | A項目:AAA, B項目:BBB, C項目:CCC |
ログファイルの編集
"CONTENT"項目に必要な項目が入っているので、分割して各項目単位に編集が必要
| DATE | HOST | SERVICE | CONTENT |
|---|---|---|---|
| yyyy-mm-dd HH:MM:SS.sss | abc-host | abc-service | A項目:AAA, B項目:BBB, C項目:CCC |
↓ 編集 ↓
| HOST | A項目 | B項目 | C項目 |
|---|---|---|---|
| abc-host | AAA+α | BBB+β | CCC-Θ |
Amazon S3 にバケット&フォルダ作成
- 「Amazon Athena のクエリ結果を保存」するフォルダを作成
- 「元ネタのログファイル」をアップロードするフォルダ、「編集した結果」をアップロードするフォルダを作成
作成イメージ
新規バケット
┣ athena 「Amazon Athena のクエリ結果を保存」するフォルダ
┣ in_log 「元ネタのログファイル」をアップロードするフォルダ
┃ ┗ ※Amazon Athena のテーブル単位にフォルダを作成
┗ out_glue「編集した結果」をアップロードするフォルダを作成
┗ ※Amazon Athena のテーブル単位にフォルダを作成
AWS Glue DataBrew でログを編集
ノーコードでサクッと編集ができる「 AWS Glue DataBrew 」で、ログを編集します。
今回は下記の順番で作業します。"レシピ"を作るのがメインになります。
- データセット
- プロジェクト
- レシピ
- ジョブ
データセット
インプットになる Amazon S3 のフォルダを選択します。
ログファイルの種類ごとに作成します。
入力項目
| 項目 | 入力値 |
|---|---|
| S3 からソースを入力 | インプットのログフォルダを Amazon S3 から選択 |
| 選択したファイルタイプ | CSV |
| CSV 区切り記号 | カンマ |
| 列ヘッダー値 | 最初の行をヘッダーとして扱う |
プロジェクト
データセットで取り込んだデータ項目に対して、画面のスプレッドシートで確認します。
また、後述する"レシピ"を追加して項目に編集を行います。
※項目だけではなく、結合などもできる
プロジェクト作成時に選択するデータセットから参照される Amazon S3 のフォルダにログファイルが必要。
ログファイルがアップロードされてないと、[Dataset Path] cannot find any objects matching [S3 Path] のエラーになるので注意。
※青塗ばかりでよく分からないですね。こんな感じの画面って思ってください。
入力項目
| 項目 | 入力値 |
|---|---|
| レシピ名 | プロジェクト名+"recipe"の自動生成 |
| データセットを選択 | "マイデータセット" -> 上記で登録したデータセット |
| ロール | 新しい IAM ロールを作成 ※以降は作成した IAM ロールを利用 |
レシピの登録
各項目を編集する作業をレシピにまとめます。
画面から編集操作を選択するのですが、結構な編集パターンが有ります。
レシピはバージョン管理できるので、後述する"ジョブ"への設定もバージョン単位です。
レシピの編集パターン
大項目だけで、こんなにある。
使ったこと無いですが「外れ数」「データのマスキング」は便利だなぁと思います。
| - | - | - | - | - |
|---|---|---|---|---|
| ソート | 列アクション | フィルター | フォーマット | クリーン |
| 値の抽出 | 欠落している値 | 無効な値 | 重複した値 | 外れ数 |
| 列を分割 | 列をマージ | 列を作成 | ネスト-ネスト解除 | ピボット |
| ユニオン | テキスト | 数値をスケール | カテゴリデータエンコード | エンコード |
| 数学関数 | 集計関数 | テキスト関数 | 日付関数 | ウィドウ関数 |
| データのマスキング | 暗号化 | 復号化 | ウェブ関数 | その他関数 |
| カスタム式関数 | - | - | - | - |
レシピのインポート
登録(バージョン発行)したレシピは他のプロジェクトへインポートができる。
同じようなレシピはインポートして修正でサクッと完成する。
レシピは登録しなくても、画面上は作業バージョンで見えるので、登録(バージョン発行)する事を忘れがちなので注意。
レシピ
レシピはデータセットへの編集テンプレートです。
バージョン管理できます。レシピから後述する"ジョブ"へレシピをバージョン単位で設定します。
ジョブ
ジョブはデータセットで登録した Amazon S3 のフォルダから、レシピのデータ編集を加えて新たにジョブで設定した Amazon S3 のフォルダへデータファイルを作成します。
※登録時に「ジョブ作成し実行する」をクリックして最初の実行を行います
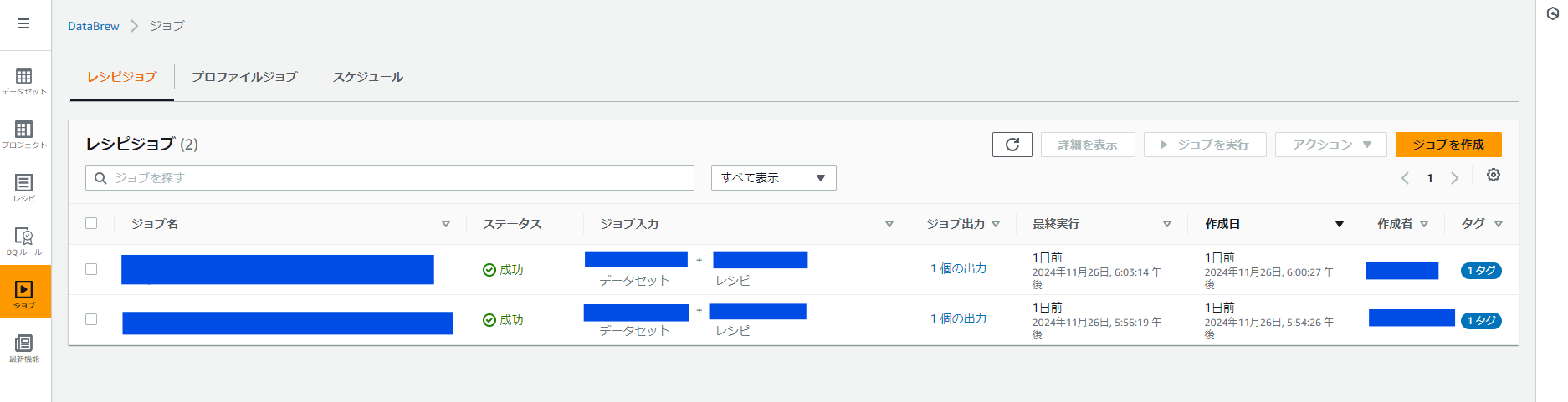
入力項目
| 項目 | 入力値 |
|---|---|
| ジョブタイプ | レシピジョブを作成 |
| ジョブ入力 | データセット |
| データセット | 上記で登録したデータセット |
| レシピ | 上記で登録したレシピ |
| 出力-出力先 | Amazon S3 |
| 出力-ファイルタイプ | CSV |
| 出力-区切り記号 | カンマ |
| 出力-圧縮 | None |
| S3 の場所 | 上記で登録した S3 out_glue フォルダ ※「編集した結果」をアップロードするフォルダ |
| ロール | 上記で登録したプロジェクトのロールを選択 |
ジョブの実行履歴
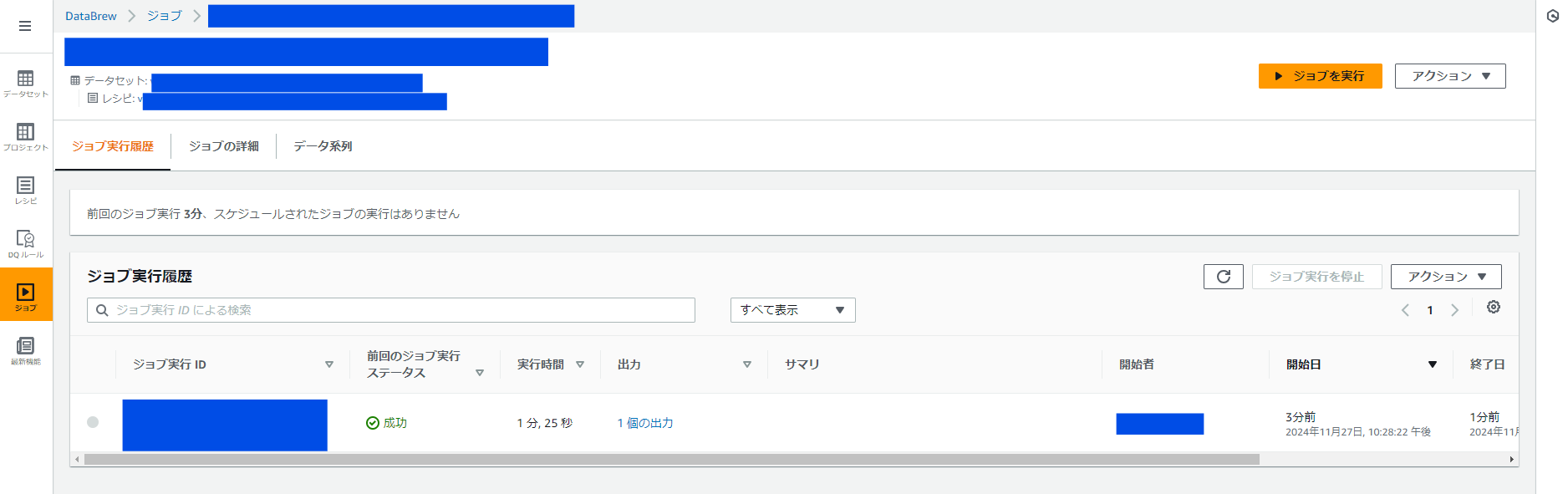
Amazon Athena で AWS Glue からテーブルを作成
Amazon Athena のクエリエディタからテーブルを作成。「AWS Glue クローラ」を選択する。
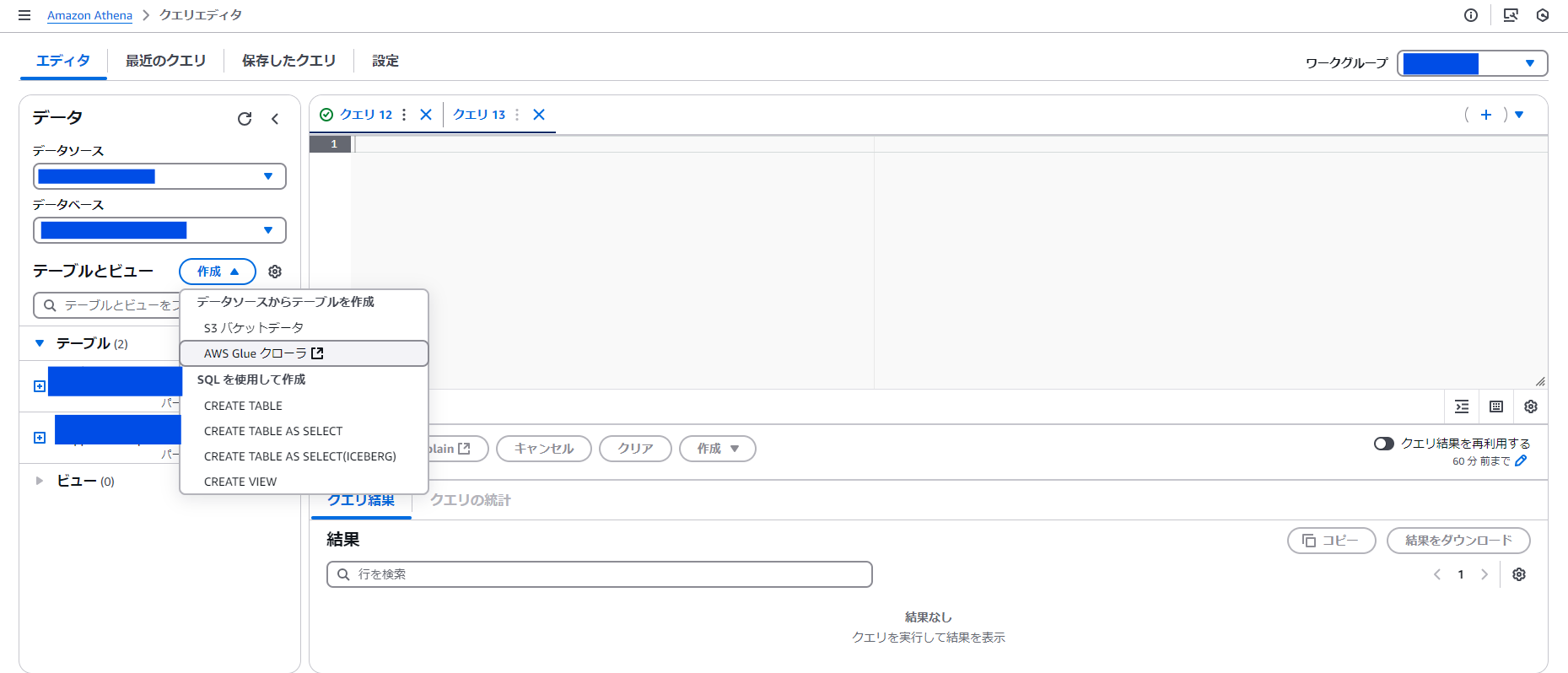
Crawler
クローラは登録した Amazon S3 のフォルダからデータを集めてテーブルを作成します。
登録後に「Run Crawler」をクリック。
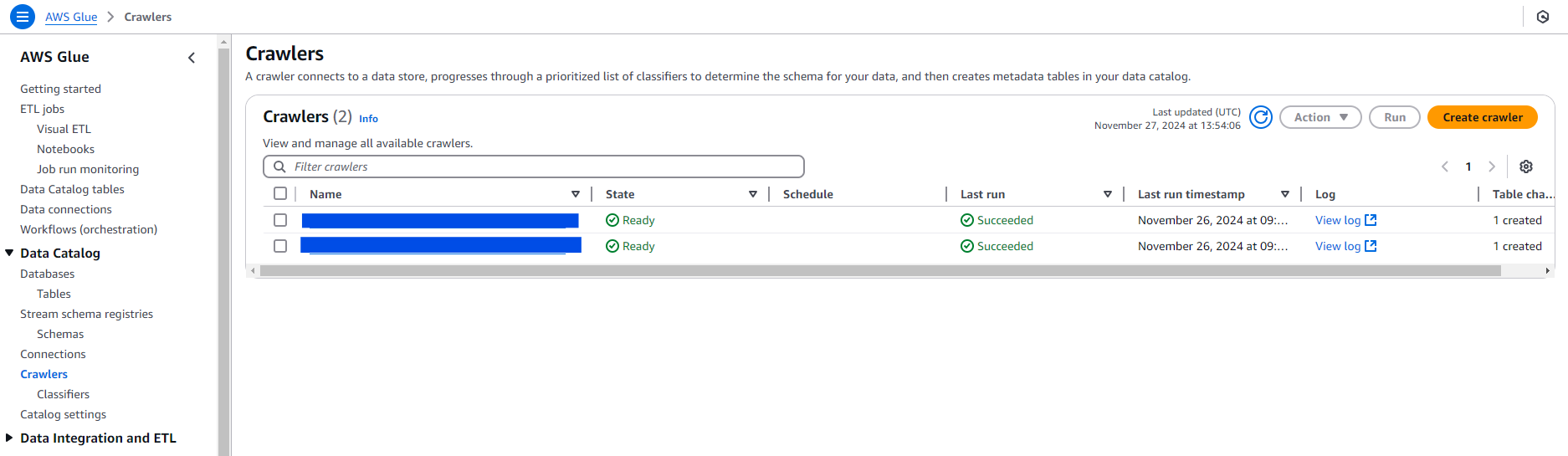
入力項目
| 項目 | 入力値 |
|---|---|
| Data source configuration | Not yet |
| Data sources | 上記で登録した S3 out_glue フォルダ ※「編集した結果」をアップロードするフォルダ |
| IAM role | 新しい IAM ロールを作成 ※以降は作成した IAM ロールを利用 |
| Target database | 上記で登録したデータセット |
| Table name prefix | プレフィックスを記載。プレフィックスなので注意 |
Crawler で作成した IAMロール(ポリシー)は、Amazon S3 のリソースを限定しているので、他のジョブから Crawler を登録した際には利用できません。そのため、ポリシーを更新して共用できるように修正しました。
Amazon Athena で クエリを利用してログを整理
ここまでで、ログファイルから必要なテーブルを作成できました。
後はテーブルから"煮るなり焼くなり"ログデータをクエリで整理します。
クエリは、ほとんど Big Query と変わりません。SQL ができれば大丈夫。
おわりに
全体として処理はイメージしやすかったのですが、AWS Glue DataBrew の編集項目の選択に悩みました。選択肢の数が多いので、どれがやりたい事なのか探しました。
レシピをコピーできるは楽ですが、もっと複雑な編集が必要な場合は、Aws Glue でコードを書いた方が良さそうです。
パッとログを整理する分には、今回のやり方で十分だと感じました。
また、今回は継続的なログ整理ではなかったので、コスト面を気にしていませんが、今後は Google Cloud (Big Query) と AWS (Athena) をコストなどを含め、総合的に比較して利用するサービスを検討したいと思います。
参考(感謝)